




Robust Iris-Localization Algorithm in Non-Cooperative Environments Based on the Improved YOLO v4 Model



Abstract
:1. Introduction
2. Related Works
2.1. Traditional Iris-Localization Algorithm
2.2. Localization Algorithm Based on Deep Learning
3. Methods
3.1. Dataset
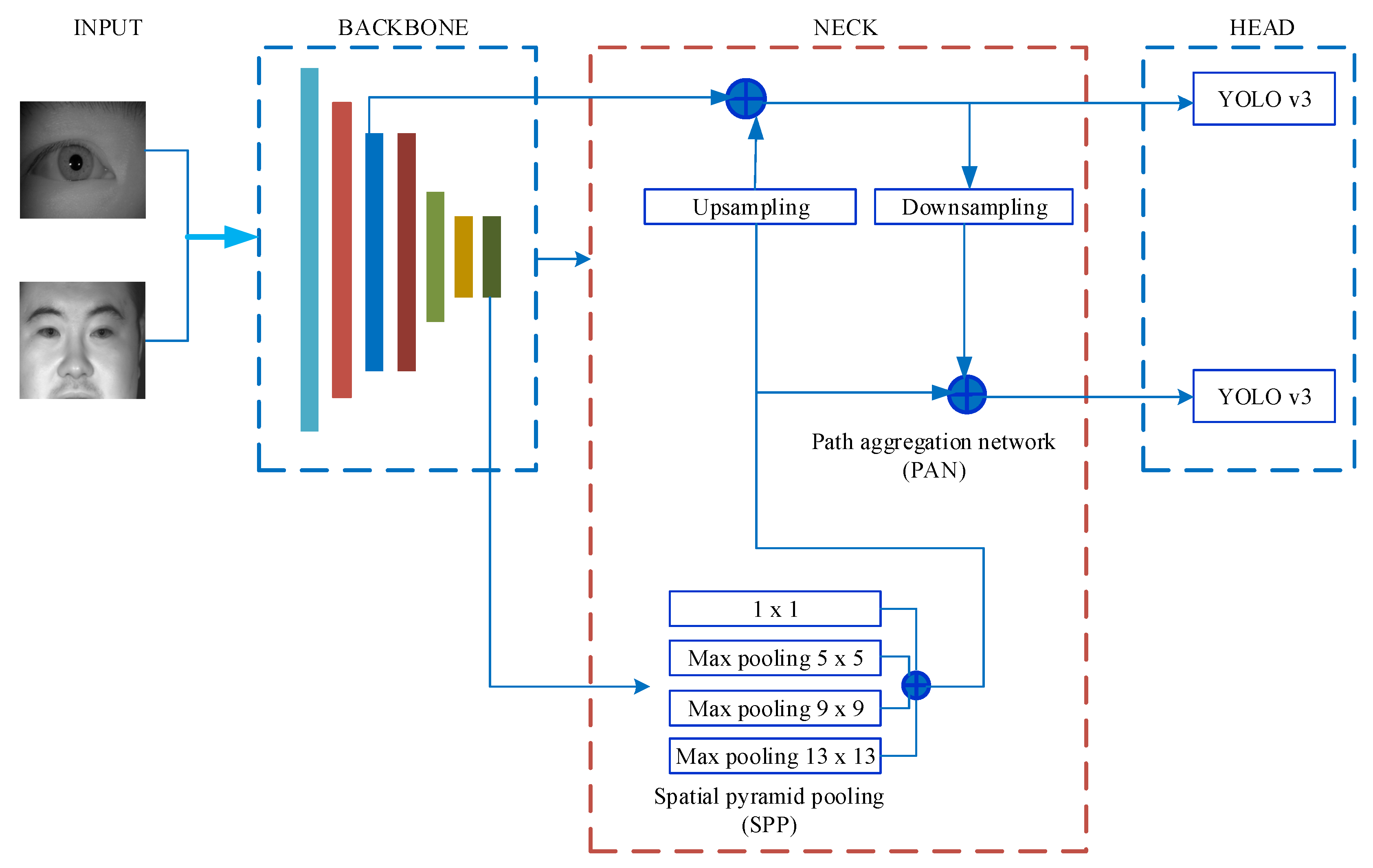
3.2. The Modified YOLO v4 Network
3.2.1. The Backbone
3.2.2. The Neck
3.2.3. The Head
3.3. Denoising an Iris Image
3.4. Precise Localization of Iris Inner and Outer Boundaries Based on Improved Calculus Operator
3.4.1. Daugman’s Integro-Differential Operator
3.4.2. The Modified Integro-Differential Operator
3.4.3. Localization of the Iris Inner Boundary
3.4.4. Localization of Iris Outer Boundary
4. Experimental Results and Analysis
4.1. Iris Images Pre-Processing
4.2. The Experimental Platform and the Evaluation Indicators
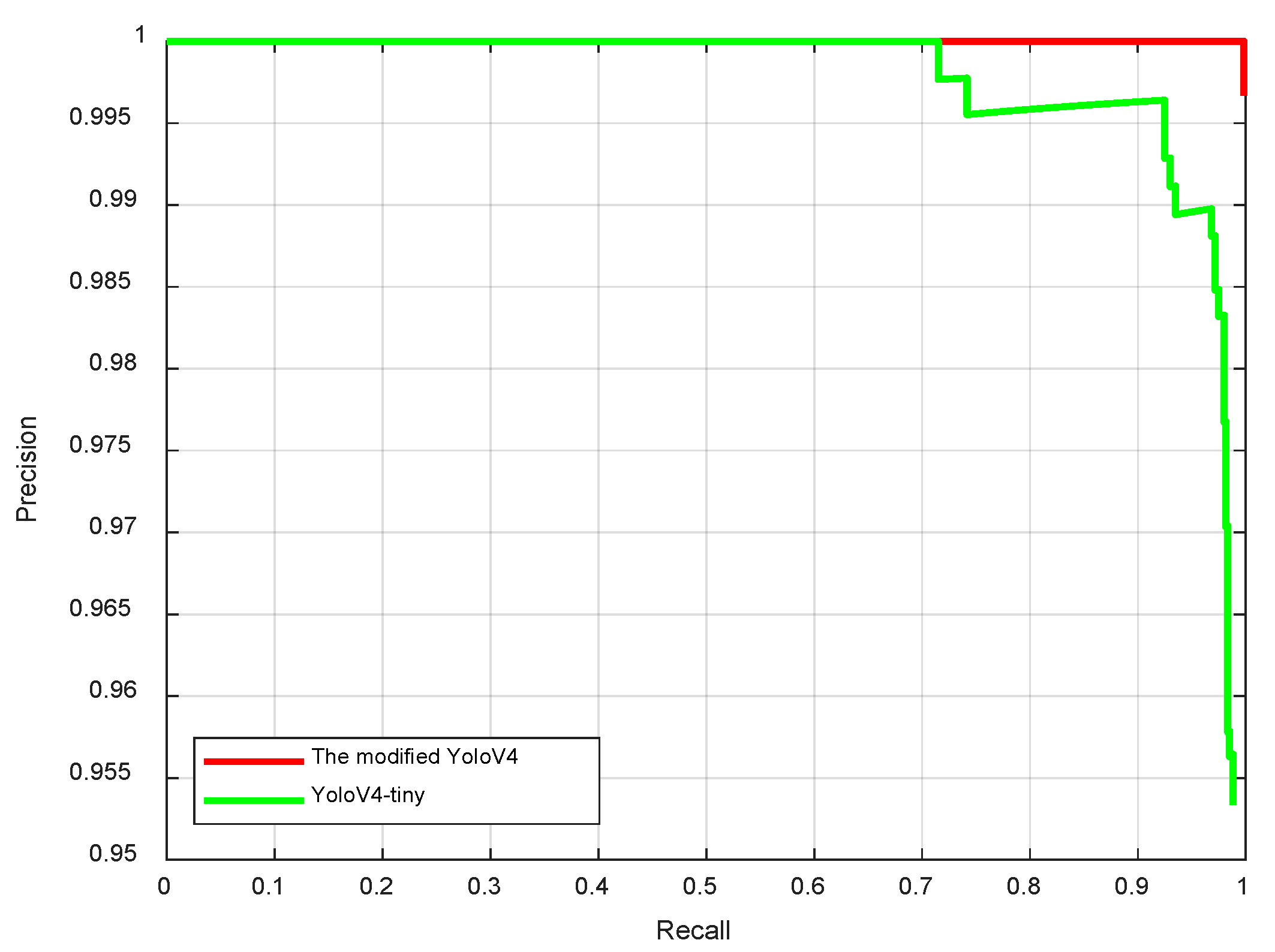
4.3. Comparison Experiment with Traditional YOLO v4
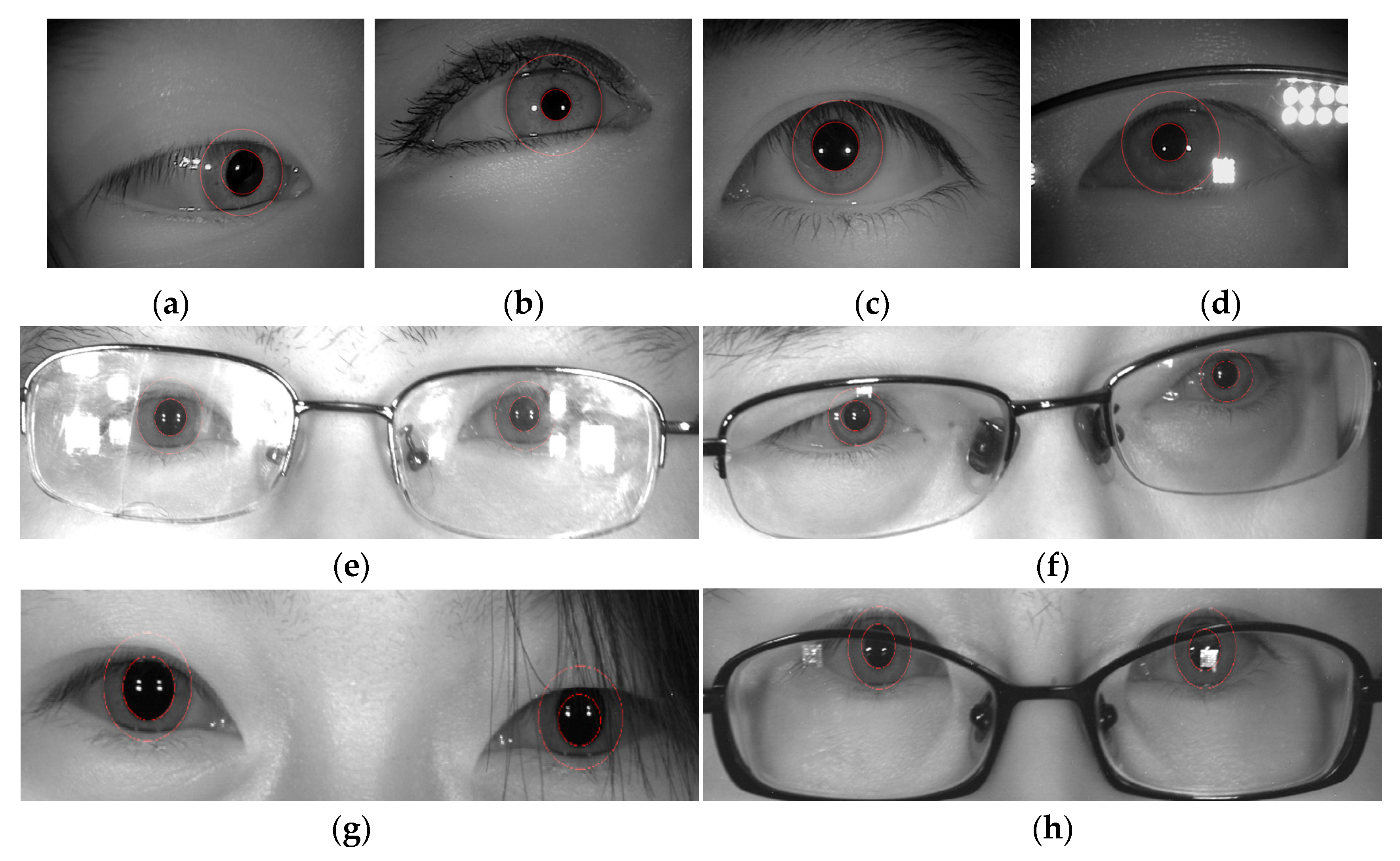
4.4. Experiment with Inner and Outer Iris Circle Localization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | you only look once |
| AP | average precision |
| mAP | mean AP |
| TP | true positives |
| FP | false positive |
| FN | false negative |
| IoU | intersection over union |
| CASIA | Chinese Academy of Sciences Institute of Automation |
| CNN | convolutional neural network |
| R-CNN | region-based CNN |
| SPP | spatial pyramid pool |
| PAN | path aggregation network |
References
- Jain, A.K.; Ross, A.; Pankanti, S. Biometrics: A tool for information security. IEEE Trans. Inf. Forensics Secur. 2006, 1, 125–143. [Google Scholar] [CrossRef] [Green Version]
- Best-Rowden, L.; Jain, A. Longitudinal Study of Automatic Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 148–162. [Google Scholar] [CrossRef] [PubMed]
- He, R.; Tan, T.; Davis, L.; Sun, Z. Learning structured ordinal measures for video based face recognition. Pattern Recognit. 2018, 75, 4–14. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Shen, Y.; Bergmann, N.; Hu, W. Sensor-Assisted Multi-View Face Recognition System on Smart Glass. IEEE Trans. Mob. Comput. 2018, 17, 197–210. [Google Scholar] [CrossRef]
- Cao, K.; Jain, A.K. Automated Latent Fingerprint Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 788–800. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Zhang, B.; Chen, C.P. Joint deep convolutional feature representation for hyperspectral palmprint recognition. Inf. Sci. 2019, 489, 167–181. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, B. Learning salient and discriminative descriptor for palmprint feature extraction and identification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5219–5230. [Google Scholar] [CrossRef]
- Xiong, Q.; Zhang, X.; He, S.; Shen, J. A Fractional-Order Chaotic Sparrow Search Algorithm for Enhancement of Long Distance Iris Image. Mathematics 2021, 9, 2790. [Google Scholar] [CrossRef]
- Xiong, Q.; Zhang, X.; Xu, X.; He, S. A modified chaotic binary particle swarm optimization scheme and its application in face-iris multimodal biometric identification. Electronics 2021, 10, 217. [Google Scholar] [CrossRef]
- Alwawi, B.K.O.C.; Althabhawee, A.F. Towards more accurate and efficient human iris recognition model using deep learning technology. TELKOMNIKA (Telecommun. Comput. Electron. Control.) 2022, 20, 817–824. [Google Scholar] [CrossRef]
- Drozdowski, P.; Rathgeb, C.; Busch, C. Computational workload in biometric identification systems: An overview. IET Biom. 2019, 8, 351–368. [Google Scholar] [CrossRef] [Green Version]
- Muroo, A. The human iris structure and its usages. Physica 2000, 39, 87–95. [Google Scholar]
- Bowyer, K.W.; Burge, M.J. Handbook of Iris Recognition; Springer: London, UK, 2016. [Google Scholar]
- Pillai, J.K.; Patel, V.M.; Chellappa, R.; Ratha, N.K. Secure and robust iris recognition using random projections and sparse representations. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1877–1893. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Zhao, L. Study on iris segmentation algorithm based on dense U-Net. IEEE Access 2019, 7, 123959–123968. [Google Scholar] [CrossRef]
- Jan, F. Segmentation and localization schemes for non-ideal iris biometric systems. Signal Process. 2017, 133, 192–212. [Google Scholar] [CrossRef] [Green Version]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Owais, M.; Park, K.R. FRED-Net: Fully residual encoder–decoder network for accurate iris segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Bazrafkan, S.; Thavalengal, S.; Corcoran, P. An end to end deep neural network for iris segmentation in unconstrained scenarios. Neural Netw. 2018, 106, 79–95. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Liu, W.; Li, J.; Meng, Z.; Sun, Y.; Feng, C. Iris R-CNN: Accurate iris segmentation and localization in non-cooperative environment with visible illumination. Pattern Recognit. Lett. 2022, 155, 151–158. [Google Scholar] [CrossRef]
- Basit, A.; Javed, M.Y. Localization of iris in gray scale images using intensity gradient. Opt. Lasers Eng. 2007, 45, 1107–1114. [Google Scholar] [CrossRef]
- Mei-Sen, P.; Qi, X. A New Iris Location Method. Biomed. Eng. Appl. Basis Commun. 2020, 32, 2050046. [Google Scholar] [CrossRef]
- CASIA Iris Image Database. Available online: http://biometrics.idealtest.org/findTotalDbByMode.do?mode=Iris#/ (accessed on 30 November 2022).
- Peng, H.; Li, B.; He, D.; Wang, J. End-to-End Anti-Attack Iris Location Based on Lightweight Network. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 821–827. [Google Scholar]
- Yang, K.; Xu, Z.; Fei, J. Dualsanet: Dual spatial attention network for iris recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 889–897. [Google Scholar]
- Susitha, N.; Subban, R. Reliable pupil detection and iris segmentation algorithm based on SPS. Cogn. Syst. Res. 2019, 57, 78–84. [Google Scholar] [CrossRef]
- Pan, M.S.; Xiong, Q. Iris location method based on mathematical morphology and improved hough transform. Biomed. Eng. Appl. Basis Commun. 2021, 33, 2150001. [Google Scholar] [CrossRef]
- Daugman, J. Statistical richness of visual phase information: Update on recognizing persons by iris patterns. Int. J. Comput. Vis. 2001, 45, 25–38. [Google Scholar] [CrossRef]
- Daugman, J. The importance of being random: Statistical principles of iris recognition. Pattern Recognit. 2003, 36, 279–291. [Google Scholar] [CrossRef] [Green Version]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Tan, T.; Wang, Y.; Zhang, D. Personal identification based on iris texture analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1519–1533. [Google Scholar]
- Li, Y.H.; Huang, P.J.; Juan, Y. An efficient and robust iris segmentation algorithm using deep learning. Mob. Inf. Syst. 2019, 2019, 4568929. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Cui, Y.; Yang, L.; Liu, D. Dynamic proposals for efficient object detection. arXiv 2022, arXiv:2207.05252. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4, Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4–5D: An effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Clust. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Naranpanawa, D.N.U.; Gu, Y.; Chandra, S.S.; Betz-Stablein, B.; Sturm, R.A.; Soyer, H.P.; Eriksson, A.P. Slim-YOLO: A Simplified Object Detection Model for the Detection of Pigmented Iris Freckles as a Potential Biomarker for Cutaneous Melanoma. In Proceedings of the Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 29 November 2021–1 December 2021; pp. 1–8. [Google Scholar]
- Severo, E.; Laroca, R.; Bezerra, C.S.; Zanlorensi, L.A.; Weingaertner, D.; Moreira, G.; Menotti, D. A benchmark for iris location and a deep learning detector evaluation. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Garea-Llano, E.; Morales-Gonzalez, A. Framework for biometric iris recognition in video, by deep learning and quality assessment of the iris-pupil region. J. Ambient. Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Lian, S.; Luo, Z.; Zhong, Z.; Lin, X.; Su, S.; Li, S. Attention guided U-Net for accurate iris segmentation. J. Vis. Commun. Image Represent. 2018, 56, 296–304. [Google Scholar] [CrossRef]
- Wang, C.; Muhammad, J.; Wang, Y.; He, Z.; Sun, Z. Towards complete and accurate iris segmentation using deep multi-task attention network for non-cooperative iris recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2944–2959. [Google Scholar] [CrossRef]
- Li, Y.H.; Putri, W.R.; Aslam, M.S.; Chang, C.C. Robust iris segmentation algorithm in non-cooperative environments using interleaved residual U-Net. Sensors 2021, 21, 1434. [Google Scholar] [CrossRef] [PubMed]
- Loy, G.; Zelinsky ASandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2, Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- MathWorks Help Center: Getting Started with YOLO v4. Available online: https://ww2.mathworks.cn/help/vision/ug/getting-started-with-yolo-v4.html (accessed on 30 November 2022).
- Wu, Y. Research on Iris Location and Authentication. Bachelor Thesis, Xi’an Jiaotong University, Xi’an, China, 12 June 2018. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IoU | 0.5 | 0.6 | 0.7 | 0.8 |
|---|---|---|---|---|
| mAP of YOLO v4-tiny (%) | 98.66 | 94.80 | 86.31 | 60.44 |
| mAP of the proposed method (%) | 99.83 | 98.49 | 90.57 | 41.50 |
| Dataset | Number of Images without Glasses | Number of Images with Glasses |
|---|---|---|
| CASIA-Iris-Thousand | 4000 | 500 |
| CASIA-Iris-Distance | 500 | 100 |
| Method | Images without Glasses | Images with Glasses | ||
|---|---|---|---|---|
| Location Accuracy | Time Cost (s) | Location Accuracy | Time Cost (s) | |
| Daugman’s operator | 94.98% | 0.215 | 89.85% | 0.216 |
| Proposed method | 97.72% | 0.227 | 93.91% | 0.196 |
| Method | Images without Glasses | Images with Glasses | ||
|---|---|---|---|---|
| Location Accuracy | Time Cost (s) | Location Accuracy | Time Cost (s) | |
| Daugman’s operator | 78.46% | 2.162 | 7% | N/A |
| Proposed method | 98.32% | 2.213 | 84% | 2.248 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Q.; Zhang, X.; Wang, X.; Qiao, N.; Shen, J. Robust Iris-Localization Algorithm in Non-Cooperative Environments Based on the Improved YOLO v4 Model. Sensors 2022, 22, 9913. https://doi.org/10.3390/s22249913
Xiong Q, Zhang X, Wang X, Qiao N, Shen J. Robust Iris-Localization Algorithm in Non-Cooperative Environments Based on the Improved YOLO v4 Model. Sensors. 2022; 22(24):9913. https://doi.org/10.3390/s22249913
Chicago/Turabian StyleXiong, Qi, Xinman Zhang, Xingzhu Wang, Naosheng Qiao, and Jun Shen. 2022. "Robust Iris-Localization Algorithm in Non-Cooperative Environments Based on the Improved YOLO v4 Model" Sensors 22, no. 24: 9913. https://doi.org/10.3390/s22249913
APA StyleXiong, Q., Zhang, X., Wang, X., Qiao, N., & Shen, J. (2022). Robust Iris-Localization Algorithm in Non-Cooperative Environments Based on the Improved YOLO v4 Model. Sensors, 22(24), 9913. https://doi.org/10.3390/s22249913