1. Introduction
In recent years, the COVID-19 pandemic has unexpectedly emerged, causing the deaths of millions of people in all countries of the world. Almost two years since the first appearance of the pandemic, COVID-19 is not fully defeated and it still negatively influences our lives. Personal hygiene is the main measure to prevent the spread of the virus and the use of a mask is considered necessary and even mandatory in many countries.
While the automated identification and classification of faces in realtime, based on deep learning techniques, have concerned many researchers, the problem of identifying people wearing a mask in crowded places is not sufficiently resolved yet [
1]. One of the reasons for this fact is the lack of the existence of annotated image datasets, which is a prerequisite for the training of deep learning algorithms.
For face-identification algorithms to work well, it is a prerequisite that they are trained and tested on a large set of collected images. Moreover, such images should also be captured under different lighting conditions and at different viewpoints [
2]. The largest collections have been gathered online. A dataset, called MegaFace, consists of 3.3M facial images gathered from Flickr [
3], while the well-known dataset MSCeleb [
4] consists of 10M images of nearly 100,000 individual subjects, collected from the Web.
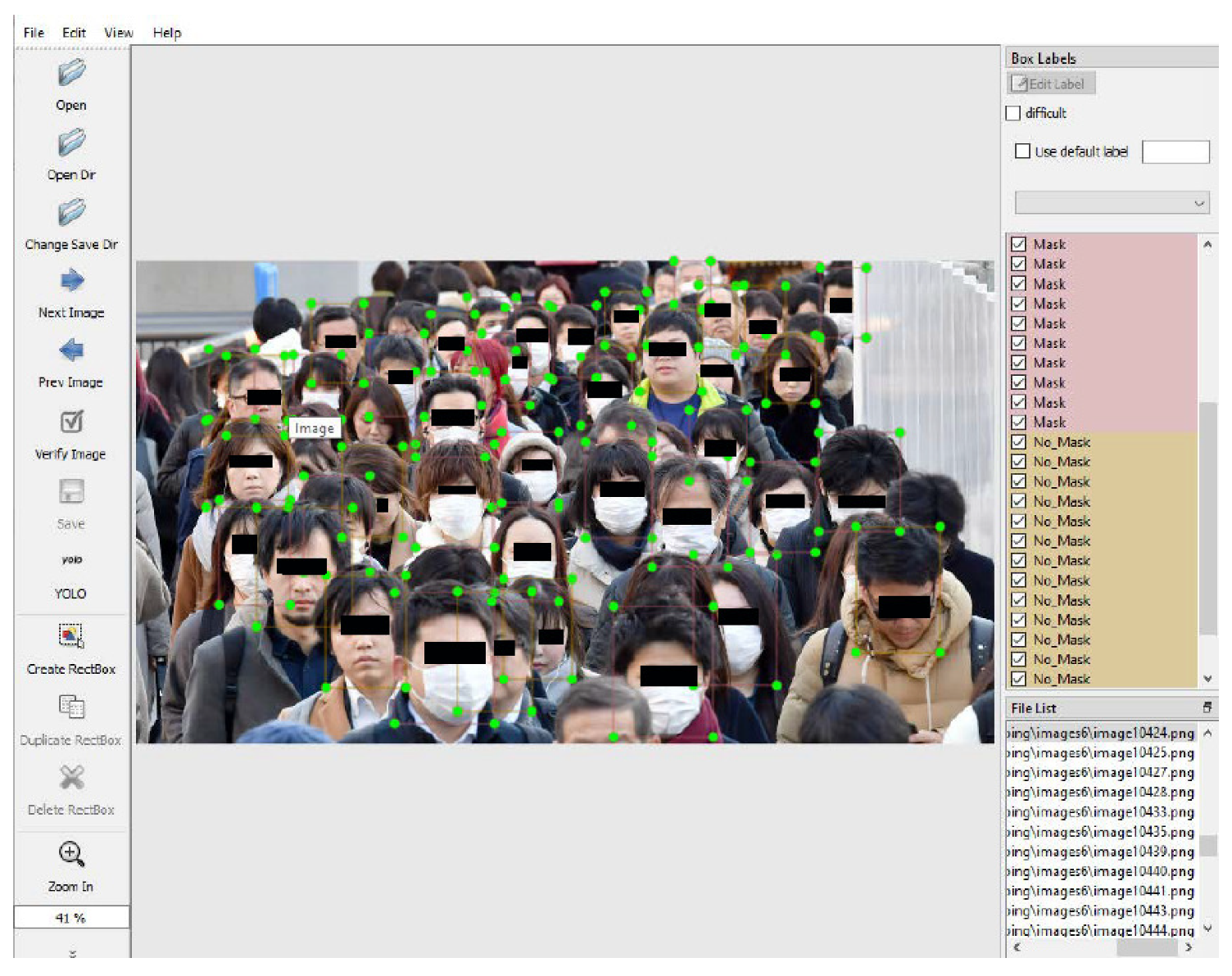
In this work, we present a systematic process for the construction of a new image dataset and we introduce the novel publicly available image dataset FaceMask, which consists of 4866 annotated images. To stimulate further research, we will make the data publicly available [
5]. The images contain people wearing a mask and people without a mask in indoor and public places. This dataset is used for the training and evaluation of automated techniques for the detection of human faces and their classification into two categories, faces with a mask and faces without a mask. The algorithms are based on different versions of YOLO [
6] using the Darknet [
7]. More specifically, we trained the YOLOv3 [
8], YOLOv4 [
9], and YOLOv4-tiny versions. Finally, we provide evaluation results on both static images and video sequences, and some remarks on the discriminative ability of each classifier are presented.
2. Related Work
In the field of computer vision, there is often confusion between the concepts of image classification, object localization, and object detection. Applications benefiting from image classification, object localization, and object detection cover a wide range such as social media, security control systems, autonomous driving, and even the most up-to-date SARS-CoV-2 virus spread assessment systems. Image categorization refers to the assignment of an image tag, which identifies the class of the object. On the other hand, spatial detection involves the design of a bounding box around each object of interest in the photograph. Finally, the term object detection includes both of the above concepts, assigning a class tag to each bounding box that is created.
Object detection and localization models: The YOLO network [
6] is the first CNN model that solves the problem of simultaneous identification and detection of objects in images, with a forward pass. Unlike other models, YOLO treats this problem as a setback rather than a categorization problem. One peculiarity of this network is that it aims mainly at the speed of object recognition. This results in a reduction in recognition accuracy, which is lower than other models, such as Fast-RCNN [
10] or Faster-RCNN [
11]. In addition, YOLO uses the entire image during the training and testing process and does not use area-based techniques, such as the sliding window.
Regions-based convolutional neural network (R-CNN) [
12] is one of the first to use CNNs to detect objects. R-CNN managed to achieve quite high performance when it made its appearance; however, it had several drawbacks that were improved in later implementations. The main disadvantages of R-CNN include: (i) the training takes place in several stages, (ii) the features extracted from the area suggestions are stored on disk, taking up a large volume and is a very time-consuming process, and (iii) object detection is slow, even when running on the GPU.
Spatial pyramid pooling (SSP-net) [
13] is a network structure that can create fixed-length representations regardless of the size and scale of the image. SPP-net is resistant to object distortion and improves all CNN-based classification methods. With this structure, one can calculate feature maps from the image only once and then group the features into arbitrary areas (subimages) to create fixed-length representations for image detection training.
Fast R-CNN [
10] is also an object detection model and is an evolution of R-CNN, solving several of its problems. The main change offered by the fast R-CNN model is that instead of feeding the area suggestions to the network, we feed the entire CNN image to create a single map of convolutional features. Fast R-CNN offers better performance in terms of speed, accuracy, and training times compared to previous implementations.
Faster R-CNN [
11] is a development of the R-CNN family of models. The algorithm solved many problems of the previous versions by using a new detection network called the Region Proposal Network(RPN). Faster R-CNN achieved higher efficiency and much shorter object detection times than the aforementioned models, making it more efficient and able to detect objects even in realtime.
Mask R-CNN [
14] is a very effective, accurate, and flexible solution to the problem of object detection. The specific architecture creates frames with which it surrounds the detected objects and at the same time creates segmentation masks for these objects, thus providing their exact outline. Finally, Mask R-CNN provides convenience in the field of education.
Single shot multibox detector (SSD) [
15] is a method for detecting objects that uses only one neural network. Instead of first creating area suggestions and then categorizing them, as is performed in the R-CNN algorithm, the SSD simultaneously performs these functions on a single network. This is also a feature of the method that makes training quite easy.
Face-mask detection models: There has been a plethora of recent methods [
16,
17,
18,
19,
20] that explore neural networks to perform deep face recognition tasks under the existence of facial masks.
The masked face recognition (MFR) challenge [
17] explored the performance of different face recognition models under the existence of facial masks. The MFR challenge contains two main tracks, namely, the InsightFace track and the WebFace260M track [
16]. Each of the two tracks is a collection of large-scale face data sets that includes images of masked and unmasked adults and children with multiracial captures.
If deployed correctly, the face-mask detector may be used to help ensure the safety of the public. To this end, Zhang et al. [
21] implemented a face-mask detection model including 500 faces with masks and 500 faces without masks. Moreover, Yang et al. [
22] deployed YOLOv5 [
23] as an object detector model to train a supervised model that recognizes persons wearing masks in public places. Du et al. [
24] defined the problem of masked face recognition in the near-infrared to visible space and built a semi-siamese network to cope with the information from the two domains. The authors stated that the masked face recognition in the near-infrared probe images is a quite difficult challenge.
Mask occlusion may lead to obstruction of the feature structure of the face as certain parts of the face are hidden; thus, detecting facial masks is an important step for effectively recognizing masked and occluded faces in the wild. Wang and Kim [
25] trained a convolutional neural network in real and simulated data of masked and unmasked faces to alleviate the problem of facial-mask detection. A novel approach that addressed the problem of masked face recognition by extracting deep features from the unmasked regions of the face and then using the bag-of-features paradigm to the learned feature maps was proposed in [
26]. Finally, the visual attention mechanism was also employed in [
27] to enhance the recognition accuracy by focusing on the regions around the eyes.
Generative adversarial networks (GANs) have also been used to train robust models for the identity-preserved masked face recognition task [
19,
28,
29,
30]. Geng et al. [
28] deployed a GAN-based method to generate masked faces and trained a domain constrained loss to bring the inpainted masked faces as close as possible to their corresponding identity full faces. In the same spirit, the work of Ge et al. [
29] proposed an identity-preserved inpainting model based on GANs to alleviate the task of occluded face recognition. To cope with the lack of the existence of a large-scale training and test data with ground truth for the tasks of mask-face detection and recognition, Ding et al. [
30] created two datasets of synthetic masked face images designed for mask-face detection and recognition, which contain 400 pairs of 200 identities for verification, and 4916 images of 669 identities for identification.
Difference to previous face-mask detection datasets: This paper presents the methodology for constructing a new image dataset consisting of people with or without a mask in indoor and outdoor environments. Existing datasets of masked people identification (e.g., masked face recognition (MFR) challenge [
17], Zhang et al. [
21], and Ding et al. [
30]) created two datasets of synthetic masked face images designed for mask-face detection and consist of a significantly fewer number of individual subjects and images (i.e., 500 faces with masks and 500 faces without masks) mostly captured under controlled pose and illumination circumstances. In comparison to these datasets, the proposed FaceMask dataset contains thousands of faces with various face poses and illuminations and people in indoor and outdoor places, individual faces, partially occluded faces, and crowded images with blurred faces that play a vital role in the success of masked face recognition algorithms. Moreover, the collected images depict people of different ages and nationalities who may or may not wear a face mask. In addition, there was a need to cover a wide range of mask detection cases in the wild. For this reason, all images were selected to show blurry and distant faces of people in either indoor or outdoor environments, while at the same time the faces can be individual or there can be an overlap of other objects or persons. The diversity of the data tries to approach the real-world conditions that the detector will be called to cope with.
4. Evaluation of Detection Algorithms Using FaceMasK
We tested several classification schemes on the FaceMask dataset to evaluate their performance on the discrimination of the two classes of images. More specifically we performed experiments with three versions of the YOLO network [
6], which is the first model of convolutional neural network that simultaneously addresses the problem of object detection and object localization, with a single forward pass. It is able to recognize objects with high performance and in a fast way, as it takes as input the whole image, avoiding cropping of the image and the use of a sliding window. The YOLO detector is fast and effective, which makes its use attractive in realtime applications.
All experiments were conducted on a graphic workstation with Intel i7-9750H 2.6 GHz CPU (6 cores, 12 threads), 16 GB DDR4 RAM 2666MHz, and Nvidia GeForce RTX 2060 (1920 CUDA cores and 6 GB GDDR6) GPU. In the following paragraphs, a detailed description of each classification scheme is provided.
4.1. YOLO
The architecture of YOLO consists of 24 convolutional layers and 2 fully connected layers (
Figure 4). The procedure that is followed includes the separation of the image in a grid of a specific size. The network predicts in every cell of the grid several bounding boxes with the corresponding confidence score, which represents the accuracy that a detected object belongs to the specific bounding box. The confidence score is given by:
The term corresponds to the intersection over union, which is a number between zero and one, and defines, for each bounding box, the percentage of overlap between the predicted frames and the ground truth.
In every grid cell, a prediction of the probability
of the class of the object is provided. In the case that no object is detected in the specific cell, the confidence score is zero, otherwise the confidence score for a given class
i is given by:
Finally, in each bounding box, four more predictions are also provided, namely the center of the bounding box, its width w, and height h.
4.2. YOLOv3
The first version of YOLO was quickly evolved for the enhancement of its performance. Thus, the third version of YOLO was proposed in [
8]. The basic functions of YOLOv3 were the same as YOLO, but it exhibits several different specifications. The first involves the definition of the bounding box. The network predicts four coordinates
,
,
, and
. If a cell offset
occurs, in terms of the upper left corner of the image, and the bounding box prior has width and height
, then the predictions are given by [
8]:
The objectness score (according to the confidence score) represents an indication of the overlapping of the bounding box and the object. Only one bounding box is assigned to each object, based on the maximum percentage of overlapping of the object (IoU). The loss function of YOLOv3 consists of three parts:
Classification loss: in the case of the detection of an object, for every cell of the grid, the sum of squares of the probabilities that the object belongs to a class is calculated;
Localization loss: the error between the predicted bounding boxes and the ground truth is calculated;
Confidence loss: it measures the objectness of a bounding box, in the cases where an object is either detected or not in this bounding box.
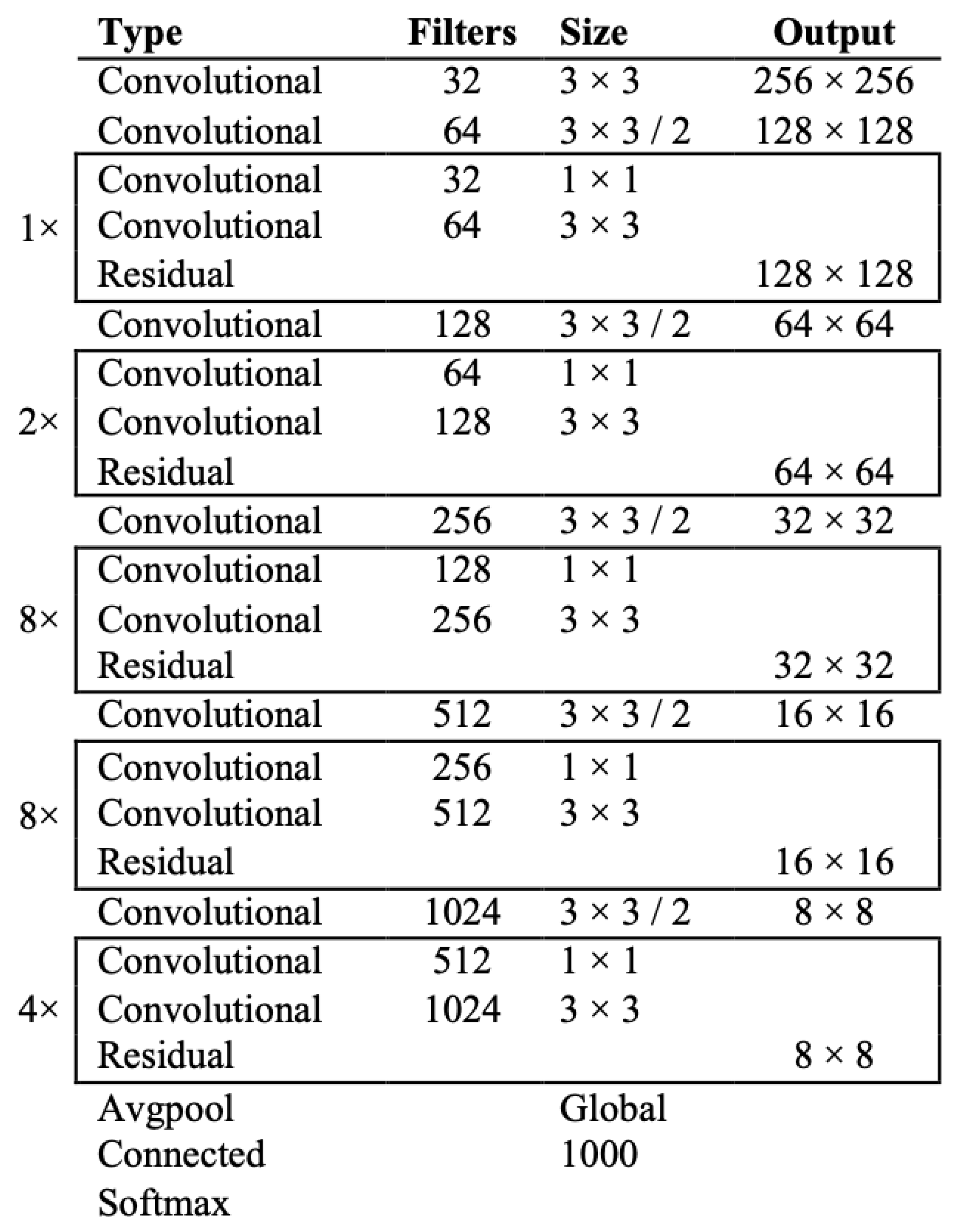
Another improvement of YOLOv3 is that it provides multilabel classifications, and it uses shortcut connections, for the detection of small objects. Furthermore, a new network for feature extraction is included. This network contains 53 convolutional layers and it is called Darknet-53 [
7]. Its architecture is depicted in
Figure 5.
As described in [
8], the limitations of YOLOv3 are (a) anchor box x, y offset predictions, (b) linear x, y predictions instead of logistic, (c) focal loss, and (d) dual IOU thresholds and truth assignment.
4.3. YOLOv4 and YOLOv4-Tiny
YOLOv4 [
9] is an improved version of YOLOv3 in terms of two metrics, which are extensively used for the evaluation of the performance of a classification algorithm: the Average Precision and the processing time (frames per second). In YOLOv4, the Cross-Stage-Partial Darknet-53(CSPDarknet53) is used as a feature extractor, and its training can be easily performed in a single GPU. Furthermore, the techniques Bag-Of-Freebies (BoF) and Bag-Of-Specials (BoS) were developed in the detector and the backbone part of the network. These techniques aim to increase of the accuracy of the predictions.
Table 2 shows the parameter set used for training YOLOv4.
In addition, YOLOv4-tiny is based on a light computational version of YOLOv4, which results in faster detection of the objects. This is achieved because the architecture of YOLOv4-tiny is simpler. Thus, the convolutional layers in the backbone part of the network are compressed. Furthermore, there are only two (instead of three) YOLO layers, and it uses fewer anchor boxes for the prediction of the bounding boxes. However, the reduction in computational time usually introduces limitations in the performance of the network, but it still presents comparable results with the other versions of YOLO.
5. Experiments and Results
We performed several experiments for the training of YOLOv3, YOLOv4, and YOLOv4-tiny. Furthermore, a k-fold cross-validation scheme was used for the evaluation of the performance of the method.
More specifically, the image set is composed of 4866 images, which were randomly separated into three subsets, the training set, the validation set, and the test set. In
Table 3, the number of faces in each subset and their class is provided. In each experiment the metrics mAP, Average IoU (for
), and AP (Average Precision) for the classes
Mask and
No_Mask are calculated, corresponding to different value weights, which were calculated in 1000 iterations and present the highest performance.
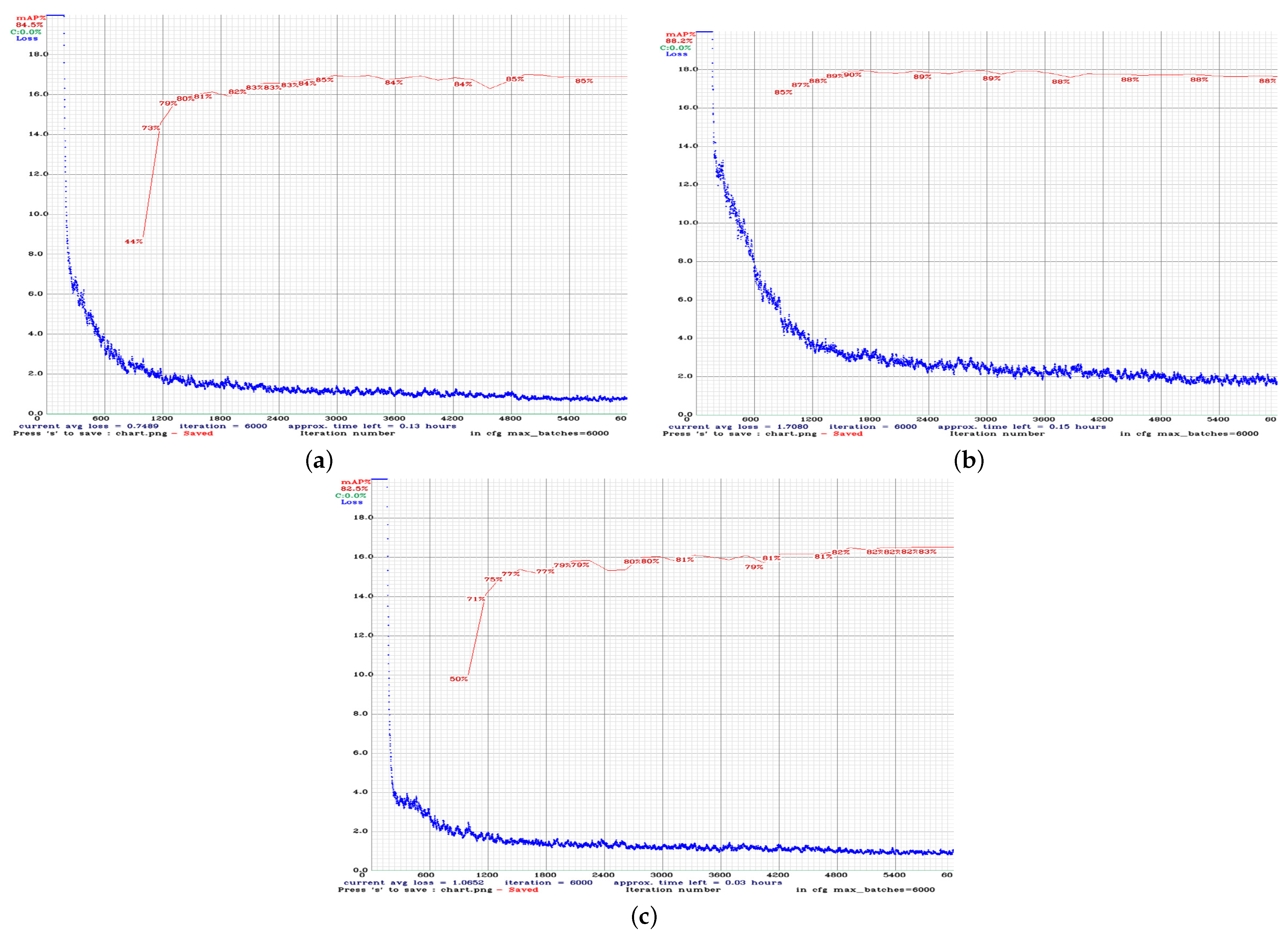
The training procedure for all models was performed for 6000 iterations. The average loss and mAP during the iterations for YOLOv3, YOLOv4, and YOLOv4-tiny models are depicted in
Figure 6, where the mAP metric was calculated on the validation set every four epochs. Each epoch was determined as a fraction of (images in the training dataset)/batch_size. This metric is considered the most important metric, based on the documentation of the Darknet. After 1000 iterations, we saved the weight values and the values with the highest performance (
Table 4). The same procedure was followed for YOLOv4 (
Table 5) and YOLOv4-tiny (
Table 6). For YOLOv3 and YOLOv4 the learning rate was set to
, and for YOLOv4-tiny the learning rate was set to 0.00261.
5.1. Comparison between Different Models
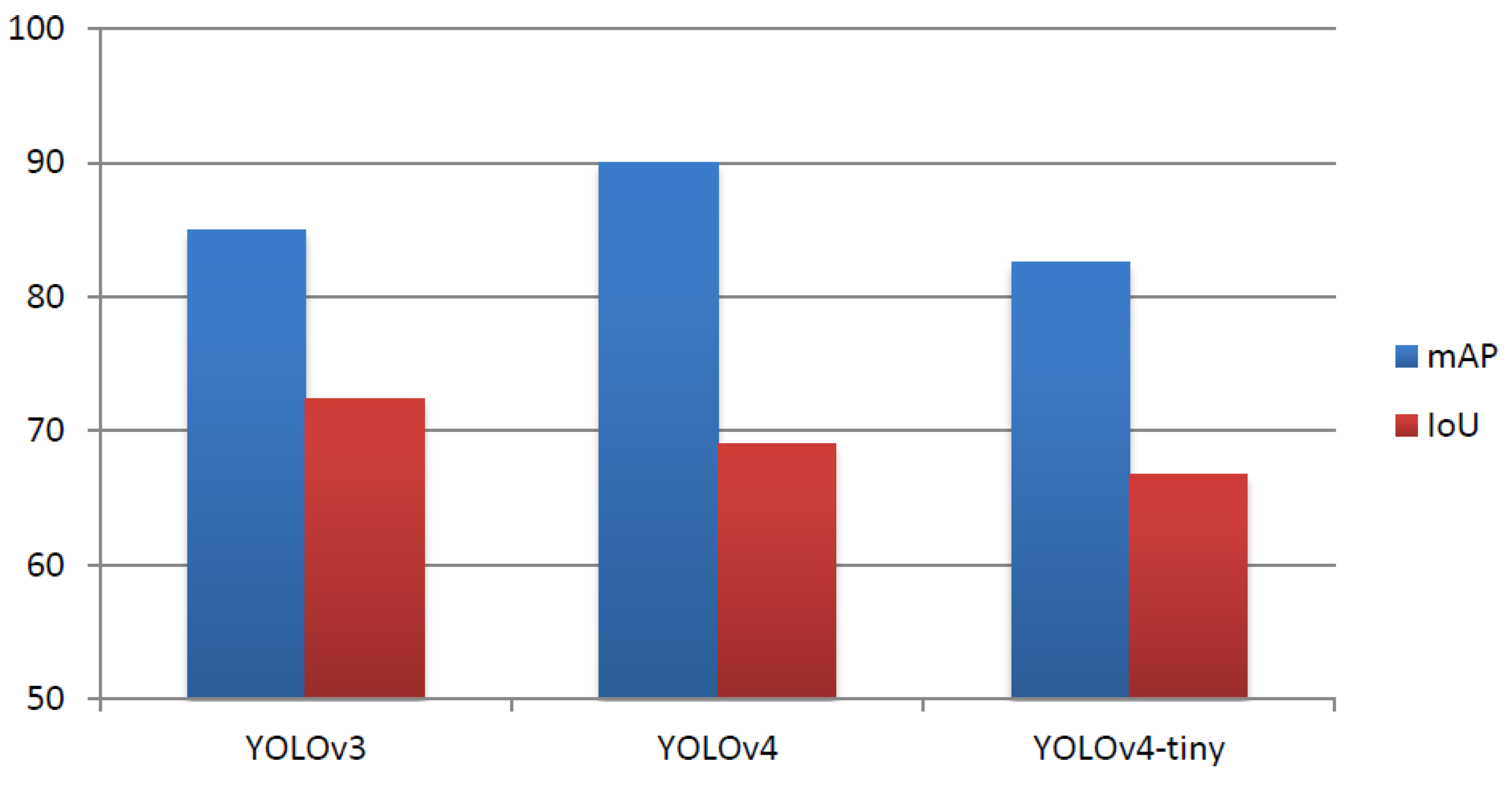
As verified by the experimental results, we observe that considering Average Precision, the performance of YOLOv4 was higher by
and
than the corresponding performance of YOLOv3 and YOLOv4-tiny, respectively. Furthermore, YOLOv3 performed better by
in terms of mAP than YOLOv4-tiny, and it exhibited higher performance than all models in terms of Average IoU. More specifically, its performance was
higher than YOLOv4 and by
higher than YOLOv4-tiny in terms of IoU. Finally, the performance in terms of average loss after 6000 iterations for YOLOv3, YOLOv4, and YOLOv4-tiny was
,
, and
, respectively.
Figure 7 depicts the comparison of the three models in terms of IoU and mAP metrics.
If we take for granted that the metric that characterizes the performance of each network is the mAP metric, we can conclude that YOLOv4 outperforms all the other versions of YOLO. This can be explained because it includes the BoF and BoS techniques in the backbone and in the neck part of the network, and it uses the CSPDarknet53 method for the extraction of the features. These techniques are not included in the previous version of YOLOv3. Furthermore, YOLOv4-tiny converges faster than YOLOv4, and this leads to a decrease in precision. Some examples of the classification results of the different models in real images are depicted in
Figure 8 and
Figure 9.
In addition, for the evaluation of the data set, a two-fold cross-validation scheme was performed, and the comparison of the results is presented in
Table 7. As we can see, the models exhibited higher performance with the two-fold cross-validation scheme, in terms of average mAP. Observing the results, we can conclude that with this random data partition, we achieve better performance at an average accuracy of
in YOLOv3,
in YOLOv4, and
in YOLOv4-tiny models. Since as mentioned above, the mAP value is the one that determines to a greater extent the performance, we conclude that with the two-fold cross-validation partitioning process the results produced were better than with the original set data.
The evaluation of our data shows that the classification task is quite accurate in the whole range of the dataset, and regardless of the division, the obtained results are equally accurate and satisfying. The same conclusion is reached for the network, which achieves good performance even in data that are unknown to it.
5.2. Failure-Cases Analysis
It must be noted that the cases of misclassification are commonly observed in images that contain people that are not wearing the mask correctly or the mask is different than the specific type of mask (i.e., surgical mask). Furthermore, images containing faces that are highly occluded and images of low resolution may not be correctly classified to the underlying category.
Figure 10 demonstrates some failure case examples with regard to the suggested categories.
To cope with these failure cases, the evaluation policy should be revised to take into account examples that belong to classes that may hold similar semantic characteristics, from the database perspective. Furthermore, from the training model perspective, it is important to improve the model itself so as to take into account the inter-class similarity. When there are examples that obtain high-prediction weights, then similar examples that may contain faces in which the mouth and/or the nose are not fully covered by the mask, or faces that are occluded by scarfs, neckbands, or other objects may also be assigned with high-prediction weights.
Moreover, there are cases where it is hard to say that the prediction model is incorrect because faces may not be salient in the image. These cases are considered to be supplemented, thus a revision of the original dataset or the evaluation policy is necessary.
There are also challenging cases that are difficult to predict the underlying category even by humans. For example, faces may be covered by a neckband used as a mask as shown in
Figure 10b; thus, it is quite difficult to identify the correct class without contextual knowledge.
Finally, incorrect ground truth images in the dataset may also lead to mis-classification cases. These incorrect ground truth images should be complemented by the strict revision of the dataset. Images that are out of the regular range of imaging distribution (i.e., images with high distortion of illumination and motion blur) may also lead to incorrect classification. To classify these images correctly, the FaceMask dataset should be extended and training models should be improved so that during training images with irregular illumination and motion blur are also present.
7. Conclusions
In this work, the publicly available FaceMask image dataset was introduced, which was created for the recent requirement of the automated detection of people wearing a mask in crowded places, due to the COVID-19 pandemic. It contains 4866 images of two categories, Mask and No_Mask, which were carefully selected in order to correspond to real conditions. We have used three versions of the YOLO network, i.e., the YOLOv3, YOLOv4, and YOLOv4-tiny for the automated detection of people wearing masks using the FaceMask image dataset, and the results indicate that YOLOv4 presents the best performance. The results of the classification schemes provide a reference point for the evaluation of future approaches for the automated identification of people wearing a mask.
As future work, we intend to extend our image dataset with images containing people of different nationalities, in order to enhance the performance of the correct identification of each face. Furthermore, we can include images of different kinds of masks except for the surgical mask, such as helms or shield masks. In addition, we intend to comprise another class of images, containing the images which depict people wearing a mask in a correct way. Finally, the installation of the trained models in smartphones and the use of input images from the camera preview will lead to realtime classification.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}