
American Sign Language Words Recognition of Skeletal Videos Using Processed Video Driven Multi-Stacked Deep LSTM


Abstract
:1. Introduction
- (a)
- Acquisition and processing of skeletal video images acquired by means of a portable leap motion controller (LMC) sensor.
- (b)
- The development of an EKF-tracking to address hand motion tracking errors and uncertainties across each frame in obtaining hand motion trajectories.
- (c)
- The development of an innovative algorithm based on WLS to control noise across video frames.
- (d)
- The design of a BiRNN network that is able to extract the proposed features from raw skeletal video frames.
- (e)
- The development of an MIC scheme to select the most significant features from raw video images. These are used as input to the multi-stacked deep BiLSTM recognition network to discriminate among similar double-hand dynamic ASL words.
- (f)
- Intensive evaluation using Jaccard, Mathew correlation and Fowlkes–Mallows indices is carried out to analyze the reliability of recognition results. These indices estimate the confusion matrix via known parameters for assessing the probability that the performance would be achieved by chance, due to the assumption of randomness of the k-fold and LOSO cross-validation protocol.
- (f)
- Investigation of the best recognition network by comparing the performance of Adam, AdaGrad and Stochastic gradient descent on loss function, for ubiquitous applications.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Name | Methodology | Results (%) | Limitations |
|---|---|---|---|
| 1. DEEP LEARNING-BASED SYSTEM | |||
| Konstantinidis et al. [8] | Meta-learner + stacked LSTMs | 99.84 and 69.33 | Computational complexity |
| Ye et al. [10] | 3DRCNN + FC-RNN | 69.2 for 27 ASL words | annotation and labeling is required |
| Parelli et al. [36] | Attention-based CNN | 94.56 and 91.38 | large-scale data set required |
| Asl-3dcnn [11] | cascaded 3-D CNN | 96.0, 97.1, 96.4 | spatial transformation |
| B3D ResNet [7] | 3D-ResConVNet + BLSTM | 89.8 and 86.9 | Misclassification + large data require |
| Rastgoo et al. [9] | SSD + 2DCNN + 3DCNN + LSTM | 99.80 and 91.12 | complex background + large data |
| 2. FEATURE-BASED SYSTEM | |||
| 2.1 Static sign words | |||
| Mohandes et al. [12] | MLP + Naïve Bayes | 98 and 99 | Not very useful for daily interact |
| Nguyen and Do [13] | HOG + LBP + SVM | 98.36 | Not very useful for daily interact |
| 2.2 Dynamic Sign words | |||
| 2.2.1 single-hand dynamic sign words recognition | |||
| Naglot and Kulkarni [14] | LMC + MLP | 96.15 | Misclassification |
| Chopuk et al. [16] | LMC + polygon region + Decision tree | 96.1 | Misclassfication |
| Chong and Lee [15] | LMC + SVM + DNN | 80.30 and 93.81 | Occlusion and similarity |
| Massey 99.39, | |||
| Shin et al. [17] | SVM + GBM | ASL alphabet 87.60 | error in estimated 3D coordinates |
| FingerspellingA 98.45. | |||
| Vaitkevicius et al. [37] | SOAP + MS SQL + HMC | 86.1 ± 8.2 | Misclassfication |
| Lee et al. [5] | LSTM + k-NN | 99.44, at 5-fold 91.82 | limited extensibility due to tracking |
| Chophuk and Kosin [31] | BiLSTM | 96.07 | limited extensibility to double hand |
| 2.2.2 double-hand dynamic sign words recognition | |||
| Igari and Fukumura [38] | minimum jerk trajectory + | 98 | Cumbersome + limited number |
| DP-matching + Via-points + CC | of features | ||
| Dutta and GS [18] | Minimum EigenValue + COM | Text + Speech | Poor extensibility to word |
| Server | |||
| Demrcioglu et al. [19] | Heuristics + RF + MLP | 99.03, 93.59, and 96.67 | insufficient hand features |
| Deriche [20] | CyberGlove + SVM | 99.6 | Cumbersome + intrusive |
| DLMC-based ArSLRs [39] | LDA + GMM bayes classifier | 94.63 | sensor fusion complexity |
| separate feature learning | |||
| Deriche et al. [40] | Dempster-Shaper + LDA + GMM | 92 | Misclassification and not mobile |
| Haque et al. [21] | Eigenmage + PCA + k-NN | 77.8846 | complex segmentation + few feature |
| Raghuveera et al. [22] | SURF + HOG + LBP +SVM | 71.85 | non-scalable features + segmentaton |
| Mittal et al. [30] | CNN + LSTM | Word 89.5 | low accuracy due to weak learning |
| Katilmis and Karakuzu [41] | LDA + SVM + RF | 93, 95 and 98 | letters are not very useful for daily |
| communication | |||
| Karaci et al. [23] | LR + k-NN + RF + DNN + ANN | cascade voting achieve | letters are not very useful for daily |
| 98.97 | Fails to track double hands | ||
| Kam and Kose [25] | Expert systems + LMC + WinApp | SLR App | Mobility is not actualized |
| Katilmis and Karakuzu [24] | ELM + ML-KELM | 96 and 99 | complex feature extension may |
| fall into over-fitting | |||
| Hisham and Hamouda [26] | Latte Panda + Ada-Boosting | double hand accuracy 93 | similarity due to tracking issues |
| Avola et al. [32] | Multi-stacked LSTM | 96 | insufficient hand features |
2. Materials and Methods
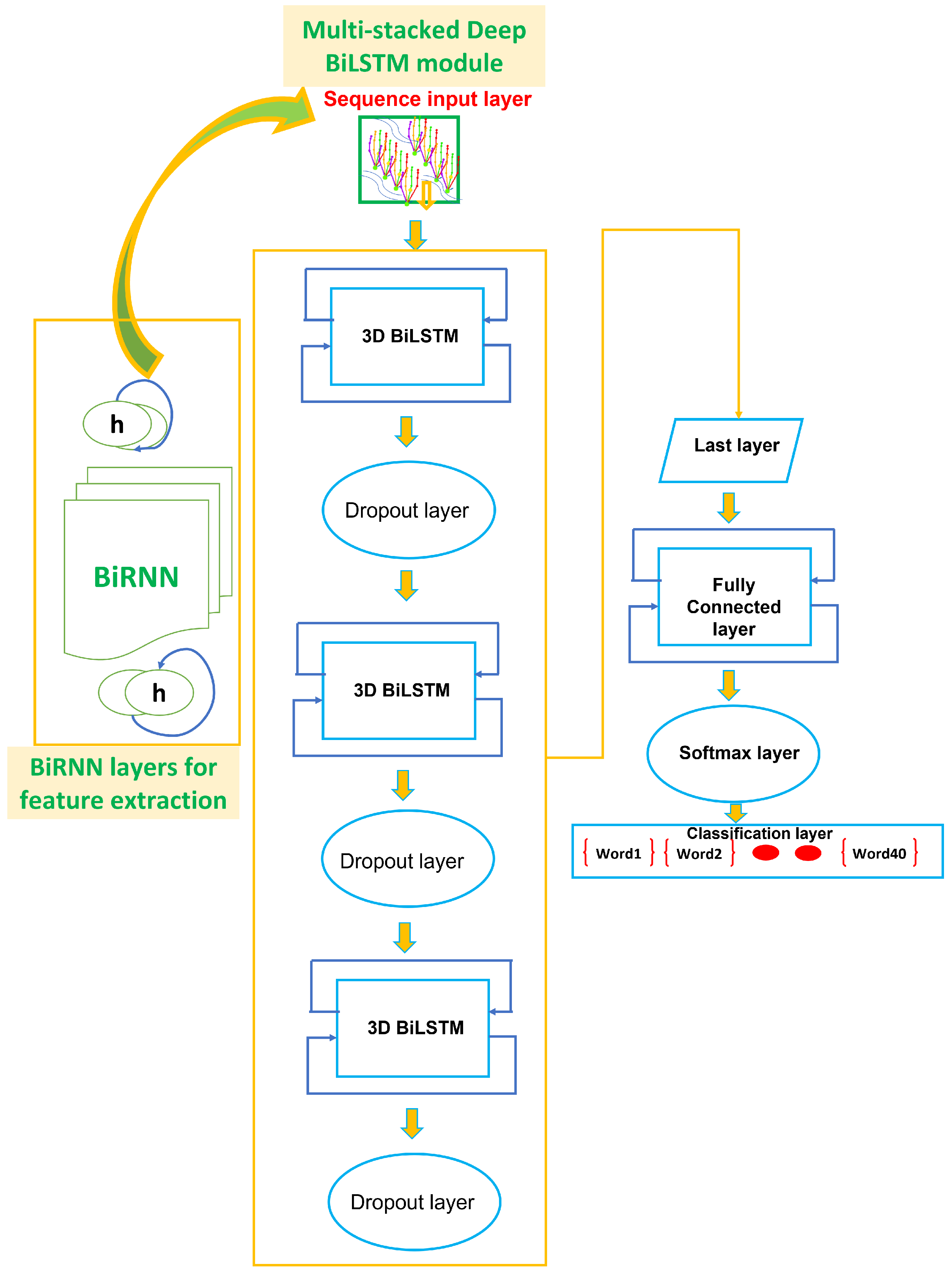
2.1. Basic Definition of Multi-Stacked Deep BiLSTM Feature
2.2. Skeletal Video Preprocessing
2.2.1. Weighted Least Square (WLS)
| Algorithm 1: (WLS). |
|
2.2.2. Hand Tracking Using Kalman Extended Filter (EKF)
| Algorithm 2: (EKF). |
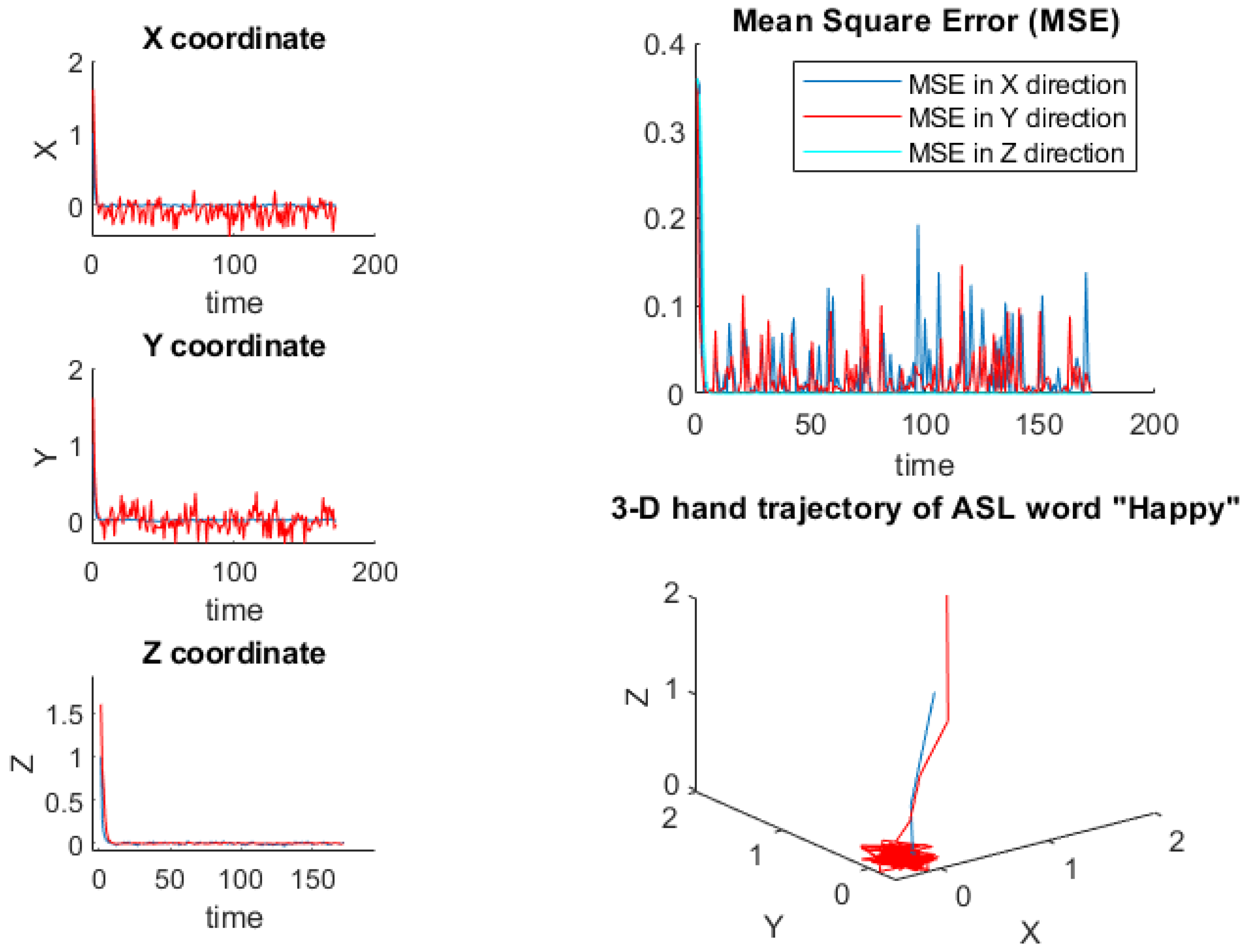
Input. Choose any arbitrary actual initial conditions w, initial observations m, assumed initial conditions j, covariance of estimation initial value h, the sampling time t, indx = 0, and n = 1:170. Initial setting. Let , , h and S be covariance matrix of process noise, measurement noise, estimation error and original information. Output. 3D EKF estimate . Step 1. Determine process and observation along X, Y, and Z coordinates, from Step 2. Compute prediction function Step 4. Computes Kalman gain Step 5. Compute overall estimate where Step 6. G is the filter specialty, estimates from Step 7. Compute covariance estimation error Step 8. Compute MSE along X, Y, and Z. as shown in Figure 3 Step 9. Finally, we set and return to step 1. |
2.2.3. Maximal Information Correlation (MIC)
2.2.4. Features Scaling
2.2.5. Skeletal Video Frames Correction
2.3. ASL Word Recognition from Skeletal Video Features
2.3.1. BiRNN Features Extraction
2.3.2. Long-Short Term Memory (LSTM)
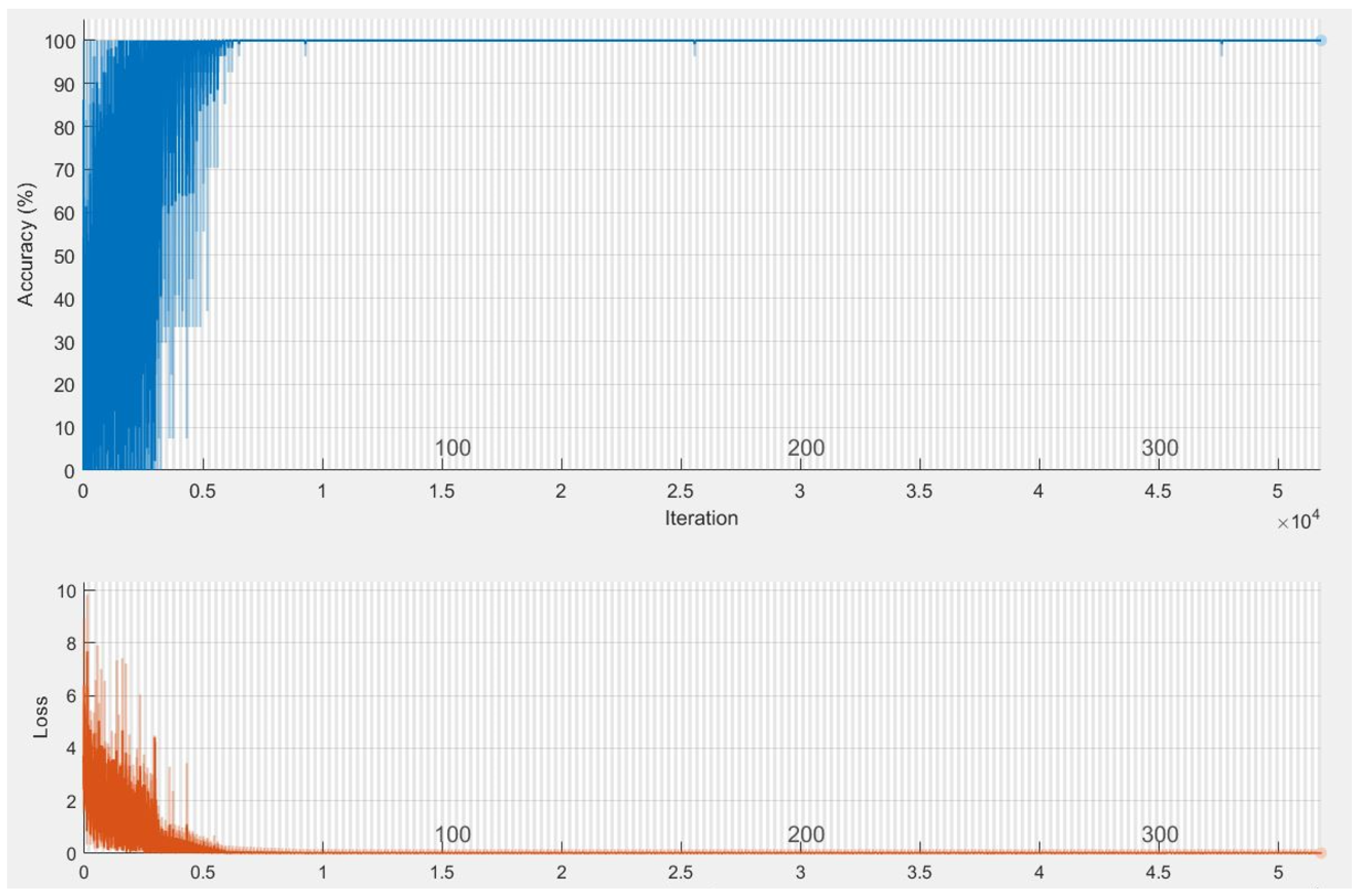
2.3.3. Multi-Stacked Deep BiLSTM Training from Transfer Learning
2.4. Model Parameters
2.5. Evaluation Metrics
2.5.1. Accuracy Metrics
2.5.2. Fowlkes–Mallows (FI) Index
2.5.3. Matthew Correlation Coefficient (MC)
2.5.4. Sensitivity
2.5.5. Specificity
2.5.6. Bookmaker Informedness (BI)
2.5.7. Jaccard Similarity Index (JI)
2.6. Experiment
2.6.1. Dataset Design
- Avola et al. [32] data set: the data set is comprised of static and dynamic skeletal hand gestures captured from 20 signers, and it is repeated twice. Due to the nature of our approach, we selected dynamic gestures, including bathroom, blue, finish, green, hungry, milk, past, pig, store and where.
- LMDHG [64] data set: comprised of dynamic skeletal hand gestures collected from 21 signers, each signer performed at least one sign, resulting in 13 ± 1 words.
- Shape Retrieval Contest (SHREC) [65] data set: Comprised of 14 and 28 challenging dynamic skeletal hand gestures, respectively. The gestures were performed using one finger and the entire hand.
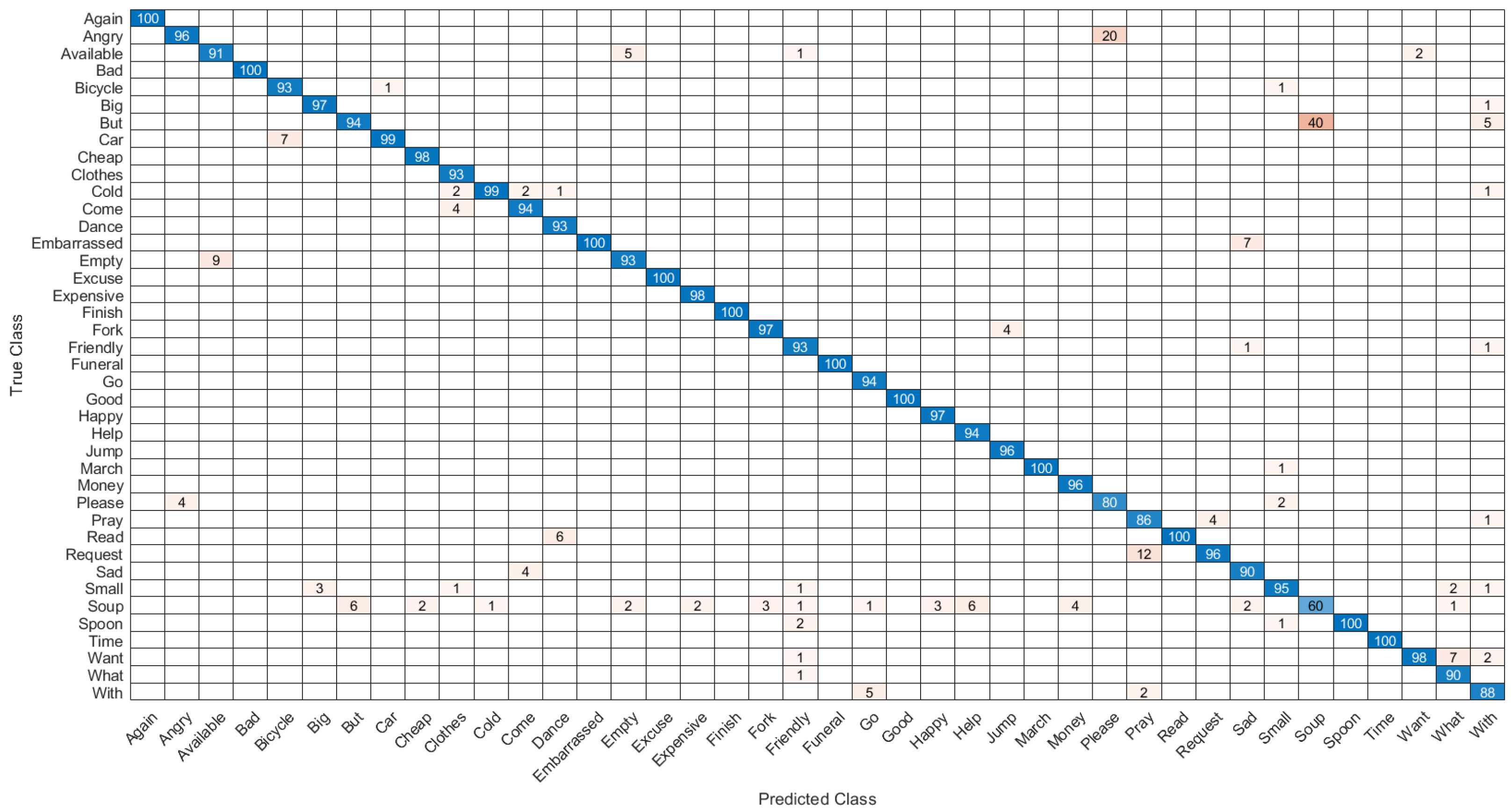
3. Results
Performance Comparison with Baseline Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Valli, C.; Lucas, C. Linguistics of American Sign Language: An Introduction; Gallaudet University Press: Washington, DC, USA, 2000. [Google Scholar]
- Brentari, D. Sign Languages, 1st ed.; Cambridge University Press: Cambridge, UK, 2010; pp. 405–432. [Google Scholar]
- Mitchell, R.E.; Young, T.A.; Bachelda, B.; Karchmer, M.A. How many people use ASL in the United States? Why estimates need updating. Sign Lang. Stud. 2021, 6, 306–335. [Google Scholar] [CrossRef]
- Gokce, C.; Ozdemir, O.; Kindiro, A.A.; Akarun, L. Score-level Multi Cue Fusion for Sign Language Recognition. In Proceedings of the Lecture Notes in Computer Science, European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Lee, C.K.; Ng, K.K.; Chen, C.H.; Lau, H.C.; Chung, S.; Tsoi, T. American sign language recognition and training method with recurrentneural network. Expert Syst. Appl. 2021, 167, 114403. [Google Scholar] [CrossRef]
- Frishberg, N. Arbitrariness and iconicity: Historical change in American Sign Language. Language 1975, 51, 696–719. [Google Scholar] [CrossRef]
- Liao, Y.; Xiong, P.; Min, W.; Min, W.; Lu, J. Dynamic sign language recognition based on video sequence with BLSTM-3D residual networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Konstantinidis, D.; Dimitropoulos, K.; Daras, P. A Deep Learning Approach for Analyzing Video and Skeletal Features in Sign Language Recognition. In Proceedings of the 2018 IEEE International Conference on Imaging Systems and Techniques (IST), Krakow, Poland, 16–18 October 2018; pp. 1–6. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Hand sign language recognition using multi-view hand skeleton. Expert Syst. Appl. 2020, 150, 113336. [Google Scholar] [CrossRef]
- Ye, Y.; Tian, Y.; Huenerfauth, M.; Liu, J. Recognizing american sign language gestures from within continuous videos. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2018. [Google Scholar]
- Sharma, S.; Kumar, K. Asl-3dcnn: American sign language recognition technique using 3-d convolutional neural networks. Multimed. Tools Appl. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Mohandes, M.; Aliyu, S.; Deriche, M. Arabic sign language recognition using the leap motion controller. In Proceedings of the 2014 IEEE 23rd International Symposium on Industrial Electronics (ISIE), Istanbul, Turkey, 1–4 June 2014; pp. 960–965. [Google Scholar]
- Nguyen, H.B.; Do, H.N. Deep learning for american sign language fingerspelling recognition system. In Proceedings of the 2019 26th International Conference on Telecommunications (ICT), Hanoi, Vietnam, 8–10 April 2019; pp. 314–318. [Google Scholar]
- Naglot, D.; Kulkarni, M. Real time sign language recognition using the leap motion controller. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; pp. 314–318. [Google Scholar]
- Chong, T.W.; Lee, B.G. American sign language recognition using leap motion controller with machine learning approach. Sensors 2018, 18, 3554. [Google Scholar] [CrossRef] [Green Version]
- Chophuk, P.; Pattanaworapan, K.; Chamnongthai, K. Fist american sign language recognition using leap motion sensor. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar]
- Shin, J.; Matsuoka, A.; Hasan, M.; Mehedi, A.; Srizon, A.Y. American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef]
- Dutta, K.K.; Satheesh Kumar Raju, K.; Anil Kumar, G.S.; Sunny Arokia Swamy, B. Double handed Indian Sign Language to speech and text. In Proceedings of the 2015 Third International Conference on Image Information Processing (ICIIP), Waknaghat, India, 21–24 December 2015; pp. 589–592. [Google Scholar]
- Demircioglu, B.; Bulbul, G.; Kose, H. Turkish sign language recognition with leap motion. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 24–26 June 2020; pp. 589–592. [Google Scholar]
- Mohandes, M.A. Recognition of two-handed arabic signs using the cyberglove. Arab. J. Sci. Eng. 2013, 38, 669–677. [Google Scholar] [CrossRef]
- Haque, P.; Das, B.; Kaspy, N.N. Two-Handed Bangla Sign Language Recognition Using Principal Component Analysis (PCA) and KNN Algorithm. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 181–186. [Google Scholar]
- Raghuveera, T.; Deepthi, R.; Mangalashri, R.; Akshaya, R. A depth-based Indian sign language recognition using microsoft kinect. Sadhana 2020, 45, 1–13. [Google Scholar] [CrossRef]
- Karacı, A.; Akyol, K.; Turut, M.U. Real-Time Turkish Sign Language Recognition Using Cascade Voting Approach with Handcrafted Features. Appl. Comput. Syst. 2021, 26, 12–21. [Google Scholar] [CrossRef]
- Katılmıs, Z.; Karakuzu, C. ELM Based Two-Handed Dynamic Turkish Sign Language (TSL) Word Recognition. Expert Syst. Appl. 2021, 2021, 115213. [Google Scholar] [CrossRef]
- Kam, B.D.; Kose, H. A New Data Collection Interface for Dynamic Sign Language Recognition with Leap Motion Sensor. In Proceedings of the Game Design Education: Proceedings of PUDCAD 2020, Virtual Conference, 24–26 June 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 353–361. [Google Scholar]
- Hisham, B.; Hamouda, A. Arabic sign language recognition using Ada-Boosting based on a leap motion controller. Int. J. Inf. Technol. 2021, 13, 1221–1234. [Google Scholar] [CrossRef]
- Fang, B.; Co, J.; Zhang, M. Deepasl: Enabling ubiquitous and non-intrusive word and sentence-level sign language translation. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, SenSys’17, Delft, The Netherlands, 5–8 November 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Masood, S.; Srivastava, A.; Thuwal, H.C.; Ahmad, M. Real-time sign language gesture (word) recognition from video sequences using cnn and rnn. Intell. Eng. Inform. 2018, 2018, 623–632. [Google Scholar]
- Yang, L.; Chen, J.; Zhu, W. Dynamic hand gesture recognition based on a leap motion controller and two-layer bidirectional recurrent neural network. Sensors 2020, 20, 2106. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Kumar, P.; Roy, P.P.; Balasubramanian, R.; Chaudhuri, B.B. A modified LSTM model for continuous sign language recognition using leap motion. IEEE Sens. J. 2019, 19, 7056–7063. [Google Scholar] [CrossRef]
- Chophuk, P.; Chamnongthai, K. Backhand-view-based continuous-signed-letter recognition using a rewound video sequence and the previous signed-letter information. IEEE Access 2021, 9, 40187–40197. [Google Scholar] [CrossRef]
- Avola, D.; Bernadi, L.; Cinque, L.; Foresti, G.L.; Massaroni, C. Exploiting recurrent neural networks and leap motion controller for the recognition of sign language and semaphoric hand gestures. IEEE Trans. Multimed. 2018, 21, 234–245. [Google Scholar] [CrossRef] [Green Version]
- Itauma, I.I.; Kivrak, H.; Kose, H. Gesture imitation using machine learning techniques. In Proceedings of the 2012 20th Signal Processing and Communications Applications Conference (SIU), Mugla, Turkey, 30 May 2012. [Google Scholar]
- Azar, G.; Wu, H.; Jiang, G.; Xu, S.; Liu, H. Dynamic gesture recognition in the internet of things. IEEE Access 2018, 7, 23713–23724. [Google Scholar]
- Lupinetti, K.; Ranieri, A.; Giannini, F.; Monti, M. 3d dynamic hand gestures recognition using the leap motion sensor and convolutional neural networks. In Lecture Notes in Computer Science, Proceedings of the International Conference on Augmented Reality, Virtual Reality and Computer Graphics, Genova, Italy, 22–24 August 2020; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Parelli, M.; Papadimitriou, K.; Potamianos, G.; Pavlakos, G.; Maragos, P. Exploiting 3d hand pose estimation in deep learning-based sign language recognition from rgb videos. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 249–263. [Google Scholar]
- Vaitkevicius, A.; Taroza, M.; Blazauskas, T.; Damasevicius, R.; Maskeliūnas, R.; Wozniak, M. Recognition of American sign language gestures in a virtual reality using leap motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef] [Green Version]
- Igari, S.; Fukumura, N. Sign language word recognition using via-point information and correlation of they bimanual movements. In Proceedings of the 2014 International Conference of Advanced Informatics: Concept, Theory and Application (ICAICTA), Bandung, Indonesia, 20–21 August 2014; pp. 75–80. [Google Scholar]
- Aliyu, S.; Mohandes, M.; Deriche, M. Dual LMCs fusion for recognition of isolated Arabic sign language words. In Proceedings of the 2017 14th International Multi-Conference on Systems, Signals and Devices (SSD), Marrakech, Morocco, 28–31 March 2017; pp. 310–321. [Google Scholar]
- Deriche, M.; Aliyu, S.O.; Mohandes, M. An intelligent arabic sign language recognition system using a pair of LMCs with GMM based classification. IEEE Sens. J. 2019, 19, 8067–8078. [Google Scholar] [CrossRef]
- Katılmıs, Z.; Karakuzu, C. Recognition of Two-Handed Posture Finger Turkish Sign Language Alphabet. In Proceedings of the 2020 5th International Conference on Computer Science and Engineering (UBMK), Diyarbakir, Turkey, 9–11 September 2020; pp. 181–186. [Google Scholar]
- Goldin-Meadow, S.; Brentari, D. Gesture, sign, and language: The coming of age of sign language and gesture studies. Behav. Brain Sci. 2017, 2017, 1–60. [Google Scholar] [CrossRef]
- Abdullahi, S.B.; Chamnongthai, K. American Sign Language Words Recognition using Spatio-Temporal Prosodic and Angle Features: A sequential learning approach. IEEE Access 2022, in press. [CrossRef]
- Huber, P.J. The Basic Types of Estimates. In Robust Statistics; A John Wiley and Sons, Inc.: Hoboken, NJ, USA, 2004; pp. 43–68. [Google Scholar]
- Song, C.; Zhao, H.; Jing, W.; Zhu, H. Robust video stabilization based on particle filtering with weighted feature points. IEEE Trans. Consum. Electron. 2012, 58, 570–577. [Google Scholar]
- Kiani, M.; Sim, K.S.; Nia, M.E.; Tso, C.P. Signal-to-noise ratio enhancement on sem images using a cubic spline interpolation with savitzky–golay filters and weighted least squares error. J. Microsc. 2015, 258, 140–150. [Google Scholar] [CrossRef]
- Balcilar, M.; Sonmez, A.C. Background estimation method with incremental iterative re-weighted least squares. Signal Image Video Process. 2016, 10, 85–92. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, A.C. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar]
- Xia, K.; Gao, H.; Ding, L.; Liu, G.; Deng, Z.; Liu, Z.; Ma, C. Trajectory tracking control of wheeled mobile manipulator based on fuzzy neural network and extended Kalman filtering. Neural Comput. Appl. 2018, 30, 447–462. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 6062, 1518–1524. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Jia, S.; Huang, H.; Qiu, J.; Zhou, C. A novel algorithm for the precise calculation of the maximal information coefficient. Sci. Rep. 2014, 1, 6662. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Wu, L.; Wang, H.; Han, C.; Quan, W.; Zhao, J. Hand gesture recognition enhancement based on spatial fuzzy matching in leap motion. IEEE Trans. Ind. Informatics 2019, 16, 1885–1894. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1999, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Keren, G.; Schuller, B. Convolutional rnn: An enhanced model for extracting features from sequential data. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Rastgoo, K.; Kiani, K.; Escalera, S. Real-time isolated hand sign language recognition using deep networks and svd. J. Ambient. Intell. Humaniz. Comput. 2021, 16, 1–21. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Bishop, C.M. Pattern recognition. Mach. Learn. 2006, 4, 738. [Google Scholar]
- Mocialov, B.; Turner, G.; Hastie, H. Transfer learning for british sign language modelling. arXiv 2020, arXiv:2006.02144. [Google Scholar]
- Bird, J.J.; Ekárt, A.; Faria, D.R. British sign language recognition via late fusion of computer vision and leap motion with transfer learning to american sign language. Sensors 2020, 20, 5151. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Tosch, N.; Jurman, G. The matthews correlation coefficient (mcc) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 1–22. [Google Scholar] [CrossRef]
- Depaolini, M.R.; Ciucci, D.; Calegari, S.; Dominoni, M. External Indices for Rough Clustering. In Rough Sets, Lecture Notes in Computer Science, Proceedings of the International Joint Conference on Rough Sets (IJCRS) 2018, Quy Nhon, Vietnam, 20–24 August 2018; Nguyen, H., Ha, Q.T., Li, T., Przybyła-Kasperek, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Boulahia, S.Y.; Anquetil, E.; Multon, F.; Kulpa, R. Dynamic hand gesture recognition based on 3D pattern assembled trajectories. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 November–1 December 2017. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P. 3d hand gesture recognition by analysing set-of-joints trajectories. In Proceedings of the International Workshop on Understanding Human Activities through 3D Sensors, Cancun, Mexico, 4 December 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Chui, K.T.; Fung, D.C.L.; Lytras, M.D.; Lam, T.M. Predicting at-risk university students in a virtual learning environment via a machine learning algorithm. Comput. Hum. Behav. 2020, 107, 105584. [Google Scholar] [CrossRef]
- Li, Y.; Ma, D.; Yu, Y.; Wei, G.; Zhou, Y. Compact joints encoding for skeleton-based dynamic hand gesture recognition. Comput. Graph. 2021, 97, 191–199. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Y.; Wang, Y.; Prinet, V.; Xiang, S.; Pan, C. Decoupled representation learning for skeleton-based gesture recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5751–5760. [Google Scholar]
- Boulahia, S.Y.; Anquetil, E.; Kulpa, R.; Multon, F. HIF3D: Handwriting-Inspired Features for 3D skeleton-based action recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-d human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2014, 45, 1340–1352. [Google Scholar] [CrossRef] [Green Version]
- Hou, J.; Wang, G.; Chen, X.; Xue, J.H.; Zhu, R.; Yang, H. Spatial-temporal attention res-TCN for skeleton-based dynamic hand gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C.; Wang, H.; Zhang, L. Mfa-net: Motion feature augmented network for dynamic hand gesture recognition from skeletal data. Sensors 2019, 19, 239. [Google Scholar] [CrossRef] [Green Version]
- Caputo, F.M.; Prebianca, P.; Carcangiu, A.; Spano, L.D.; Giachetti, A. Comparing 3D trajectories for simple mid-air gesture recognition. Comput. Graph. 2018, 73, 17–25. [Google Scholar] [CrossRef]
- Maghoumi, M.; LaViola, J.J. DeepGRU: Deep gesture recognition utility. In Proceedings of the International Symposium on Visual Computing, Nevada, CA, USA, 7–9 October 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]














| Shape | Motion | Position | Angles | Pause | Relative Trajectories | |
|---|---|---|---|---|---|---|
| Shape | 1 | |||||
| Motion | 0.9444 | 1 | ||||
| Position | 0.8781 | 0.9351 | 1 | |||
| Angles | 0.86728 | 0.93985 | 0.84453 | 1 | ||
| Pause | 0.87361 | 0.71931 | 0.90719 | 0.89857 | 1 | |
| Relative trajectories | 0.95351 | 0.94203 | 0.89075 | 0.90681 | 0.81375 | 1 |
| Features | Point of Interest | Description |
|---|---|---|
| Angle points | Pitch, yaw and roll | Hand orientation; 44 skeletal hand joints |
| Relative trajectories | Motion | Hand motion trajectories, frame speed and velocity. |
| Positions | Direction | Arm, palm, wrist and five fingers; (thumb, index, middle, ringy and pinky) |
| Finger joints | Coordinates | Coordinate of five fingers’ tip, metacarpal, proximal, distal and interdistal. |
| Hand pause | Motion | Hand preparation and retraction. |
| Network Layers | Parameter Options | Selection |
|---|---|---|
| Input layer | Sequence length | Longest |
| Batch size | 27 | |
| Input per sequence | 170 | |
| Feature vector | 1 dimension | |
| Hidden layer | 3 Bi-LSTM layers | Longest |
| Hidden state | 200 | |
| Activation function | Softmax | |
| Output layer | LSTM model | Many to one |
| Number of classes | 40 |
| Deployment | Descriptions |
|---|---|
| PC | Dell |
| CPU: Intel Core i7-9th Gen | |
| Memory Size: 8 GB DDR4 | |
| SSD: 500 GB | |
| LMC sensor | Frame rate: 64 fps |
| Weight: 32 g | |
| Infrared camera: 2 × 640 × 240 | |
| Range: 80 cm | |
| Participants | Ten |
| Selections | 40 ASL words |
| 10 times number of occurrence |
| Classes | Amount |
|---|---|
| Frames | 524,000 |
| Samples | 4000 |
| Duration (sec) | 8200 |
| Models | Epochs | Execution Time (s) | |
|---|---|---|---|
| Features Combination | Model Depth | ||
| Shape + Motion + Position + Angles + | 3-BiLSTM layers | 300 | 1.05 |
| Pause + Relative trajectory | |||
| Shape + Motion + Position + Angles | 3-BiLSTM layers | 300 | 1.01 |
| Word Classes | Accuracy | FI | MC | BI | JI | ||
|---|---|---|---|---|---|---|---|
| Again | 0.98 | 0.7 | 1 | 0.98 | 0.992361 | 0.972361 | 0.494949 |
| Angry | 0.92 | 0.707721 | 0.842701 | 0.888889 | 0.956522 | 0.845411 | 0.510638 |
| Available | 0.986486 | 0.582301 | 0.970193 | 0.970874 | 0.994819 | 0.965692 | 0.341297 |
| Bad | 0.99 | 0.703562 | 0.959462 | 0.99 | 0.985622 | 0.975622 | 0.497487 |
| Bicycle | 0.993197 | 0.579324 | 0.984886 | 0.98 | 0.972569 | 0.952569 | 0.335616 |
| Big | 0.984772 | 0.707251 | 0.969581 | 0.99 | 0.979381 | 0.969381 | 0.505102 |
| But | 0.980198 | 0.989899 | 0.489899 | 0.989899 | 0.5 | 0.489899 | 0.98 |
| Car | 1 | 1 | 0.899994 | 1 | 0.989457 | 0.989457 | 1 |
| Cheap | 0.975 | 0.701793 | 0.943489 | 0.970297 | 0.999673 | 0.96997 | 0.497462 |
| Clothes | 0.97 | 0.703599 | 1 | 0.960784 | 0.986117 | 0.946902 | 0.5 |
| Cold | 0.994898 | 0.716115 | 0.989841 | 0.990099 | 1 | 0.990099 | 0.512821 |
| Come | 1 | 1 | 0.959284 | 1 | 0.98884 | 0.98884 | 1 |
| Dance | 0.975 | 0.701793 | 0.963497 | 0.970297 | 0.989916 | 0.960213 | 0.497462 |
| Embarrassed | 0.955 | 0.709103 | 0.976592 | 0.933333 | 0.979465 | 0.912798 | 0.507772 |
| Empty | 0.98 | 0.7 | 0.965484 | 0.98 | 0.969476 | 0.949476 | 0.494949 |
| Excuse | 0.98 | 0.7 | 1 | 0.98 | 0.981238 | 0.961238 | 0.494949 |
| Expensive | 0.98 | 0.7 | 0.974596 | 0.98 | 0.961296 | 0.941296 | 0.494949 |
| Finish | 1 | 1 | 0.958249 | 1 | 0.952948 | 0.952948 | 1 |
| Fork | 0.975 | 0.701793 | 0.976222 | 0.970297 | 0.983176 | 0.953473 | 0.497462 |
| Friendly | 0.993103 | 0.571305 | 0.984467 | 0.979167 | 1 | 0.979167 | 0.326389 |
| Funeral | 0.985 | 0.698221 | 0.965785 | 0.989899 | 0.976355 | 0.966254 | 0.492462 |
| Go | 1 | 1 | 1 | 1 | 0.954389 | 0.954389 | 1 |
| Good | 1 | 1 | 0.969829 | 1 | 0.965481 | 0.965481 | 1 |
| Happy | 0.975 | 0.701793 | 0.949985 | 0.970297 | 0.968367 | 0.938664 | 0.497462 |
| Help | 0.98 | 0.7 | 0.947892 | 0.98 | 0.983923 | 0.963923 | 0.494949 |
| Jump | 0.975 | 0.701793 | 0.928965 | 0.970297 | 0.976583 | 0.94688 | 0.497462 |
| March | 0.994898 | 0.716115 | 0.989841 | 0.990099 | 1 | 0.990099 | 0.512821 |
| Money | 0.975 | 0.701793 | 0.939785 | 0.970297 | 0.954873 | 0.92517 | 0.497462 |
| Please | 0.912458 | 0.485965 | 0.801818 | 0.930233 | 0.905213 | 0.835446 | 0.274914 |
| Pray | 0.984694 | 0.705419 | 0.969432 | 0.989899 | 0.979381 | 0.96928 | 0.502564 |
| Read | 0.98 | 0.7 | 0.985672 | 0.98 | 0.972345 | 0.952345 | 0.494949 |
| Request | 0.98 | 0.7 | 0.925498 | 0.98 | 0.991438 | 0.971438 | 0.494949 |
| Sad | 0.979899 | 0.712525 | 0.960582 | 0.961165 | 1 | 0.961165 | 0.507692 |
| Small | 0.989712 | 0.444416 | 0.968427 | 0.95 | 1 | 0.95 | 0.197505 |
| Soup | 0.935 | 0.694709 | 0.977349 | 0.92233 | 0.965481 | 0.887811 | 0.494792 |
| Spoon | 0.979452 | 0.573573 | 0.954375 | 0.97 | 0.984375 | 0.954375 | 0.33564 |
| Time | 0.98 | 0.7 | 0.982396 | 0.98 | 0.974928 | 0.954928 | 0.494949 |
| Want | 0.994819 | 0.714435 | 0.989686 | 0.989899 | 1 | 0.989899 | 0.510417 |
| What | 0.994819 | 0.714435 | 0.989686 | 0.989899 | 1 | 0.989899 | 0.510417 |
| With | 0.984694 | 0.697926 | 0.969432 | 0.979381 | 0.989899 | 0.96928 | 0.489691 |
| AVERAGE | 0.979827 | 0.723467 | 0.949372 | 0.974941 | 0.967648 | 0.942588 | 0.54476 |
| Network Models | Top-1 | Top-2 | Top-3 | Features Combination | Model Depth |
|---|---|---|---|---|---|
| Deep BiLSTM | 0.954 | 0.971 | 0.989 | Shape + Motion + Position + Angles + Pause + Relative trajectory | 3-BiLSTM layers |
| Deep BiLSTM | 0.912 | 0.929 | 0.945 | Shape + Motion + Position + Angles | 3-BiLSTM layers |
| Methods | Type of Deep Learning | No. of Epochs | Depth of LSTM | Convergence Rate | Execution Time |
|---|---|---|---|---|---|
| Avola et al. [32] | Deep Bi-LSTM | 800 | 4 units | 100,000 iter | not reported |
| Our proposal | Deep Bi-LSTM | 300 | 3 units | 10,000 iter | GPU 1002 |
| Optimization Scheme | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| AdaGrad | 94.701 | 94.006 | 94.869 | 94.003 |
| SGD | 95.011 | 94.998 | 95.01 | 94.786 |
| Adam | 97.983 | 96.765 | 97.494 | 96.968 |
| ASL Data Set | ||||
|---|---|---|---|---|
| Approach | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Avola et al. [32] | 96.4102 | 96.6434 | 96.4102 | 96.3717 |
| Ours | 97.881 | 98.007 | 97.879 | 97.998 |
| LMDHG Data Set | ||||
| Avola et al. [32] | 97.62 | |||
| Ours | 97.99 | |||
| SHREC Data Set | ||||
| Accuracy (%) | ||||
| 14 Hand Gestures | 28 Hand Gestures | |||
| Avola et al. [32] | 97.62 | 91.43 | ||
| Ours | 96.99 | 92.99 | ||
| Approach | Algorithms | Accuracy (%) | |
|---|---|---|---|
| 14 Hand Gestures | 28 Hand Gestures | ||
| De Smedt et al. [65] | SVM | 88.62 | 81.9 |
| Boulahia et al [69] | SVM | 90.5 | 80.5 |
| Ohn-Bar and Trivedi [70] | SVM | 83.85 | 76.53 |
| HON4D [71] | SVM | 78.53 | 74.03 |
| Devanne et al. [72] | KNN | 79.61 | 62 |
| Hou et al. [73] | Attention-Res-CNN | 93.6 | 90.7 |
| MFA-Net [74] | MFA-Net, LSTM | 91.31 | 86.55 |
| Caputo et al. [75] | NN | 89.52 | - |
| DeepGRU [76] | DeepGRU | 94.5 | 91.4 |
| Liu et al. [68] | CNN | 94.88 | 92.26 |
| Li et al. [67] | 2D-CNN | 96.31 | 93.33 |
| Ours | Multi-stack deep BiLSTM | 96.99 | 92.99 |
| Approach | Algorithms | Accuracy (%) |
|---|---|---|
| Boulahia et al. [64] | SVM | 84.78 |
| Devanne et al. [72] | KNN | 79.61 |
| Lupinetti et al. [35] | CNN-ResNet50 | 92 |
| Hisham and Hamouda [26] | Ada-boosting | 91.2 |
| Ours | Multi-stack deep BiLSTM | 97.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullahi, S.B.; Chamnongthai, K. American Sign Language Words Recognition of Skeletal Videos Using Processed Video Driven Multi-Stacked Deep LSTM. Sensors 2022, 22, 1406. https://doi.org/10.3390/s22041406
Abdullahi SB, Chamnongthai K. American Sign Language Words Recognition of Skeletal Videos Using Processed Video Driven Multi-Stacked Deep LSTM. Sensors. 2022; 22(4):1406. https://doi.org/10.3390/s22041406
Chicago/Turabian StyleAbdullahi, Sunusi Bala, and Kosin Chamnongthai. 2022. "American Sign Language Words Recognition of Skeletal Videos Using Processed Video Driven Multi-Stacked Deep LSTM" Sensors 22, no. 4: 1406. https://doi.org/10.3390/s22041406
APA StyleAbdullahi, S. B., & Chamnongthai, K. (2022). American Sign Language Words Recognition of Skeletal Videos Using Processed Video Driven Multi-Stacked Deep LSTM. Sensors, 22(4), 1406. https://doi.org/10.3390/s22041406