
Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition



Abstract
:1. Introduction
2. Related Works
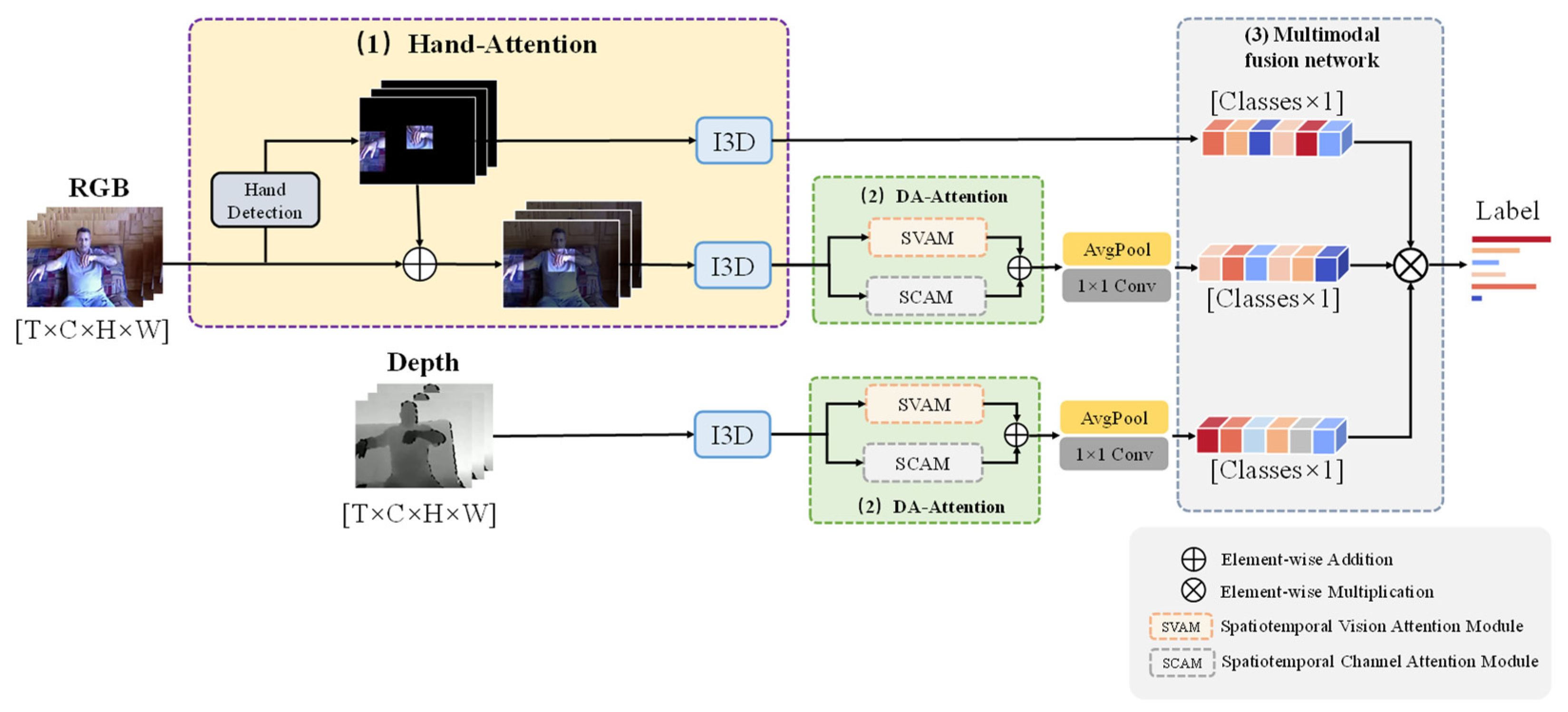
3. Approach
3.1. Local Attention Module
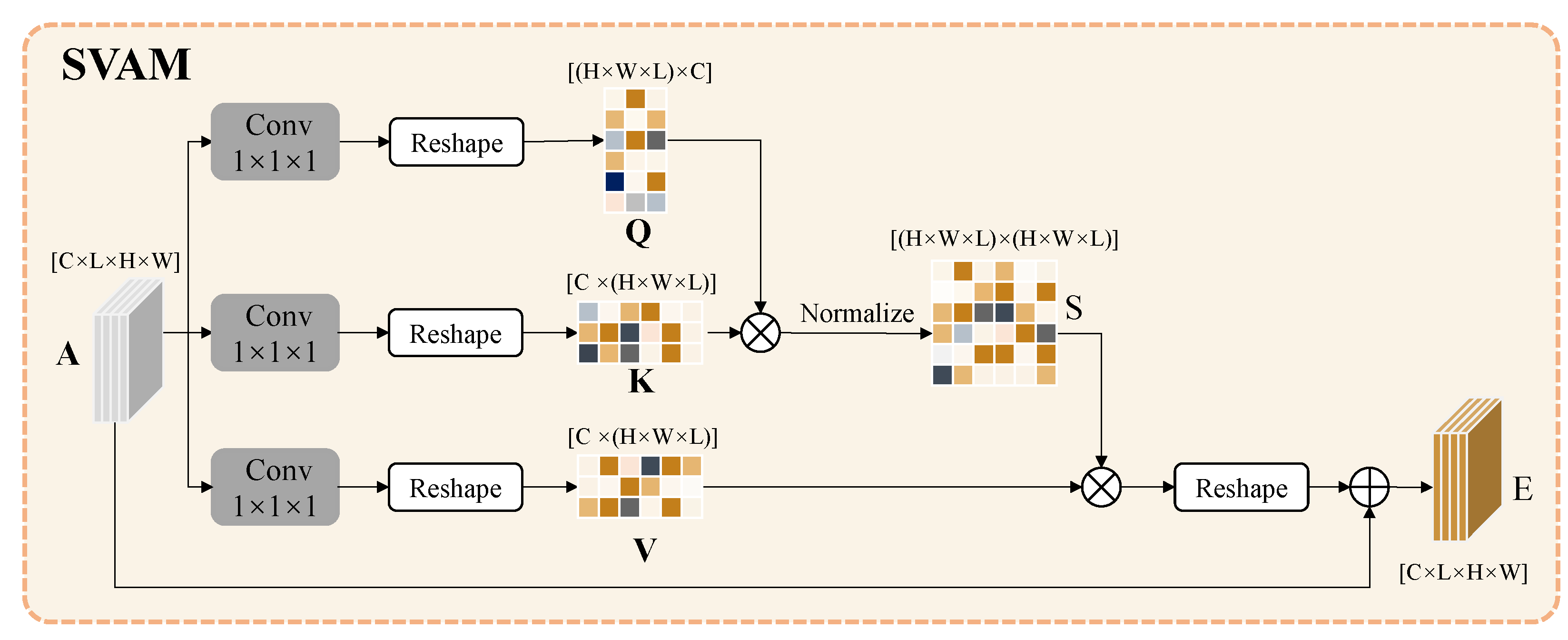
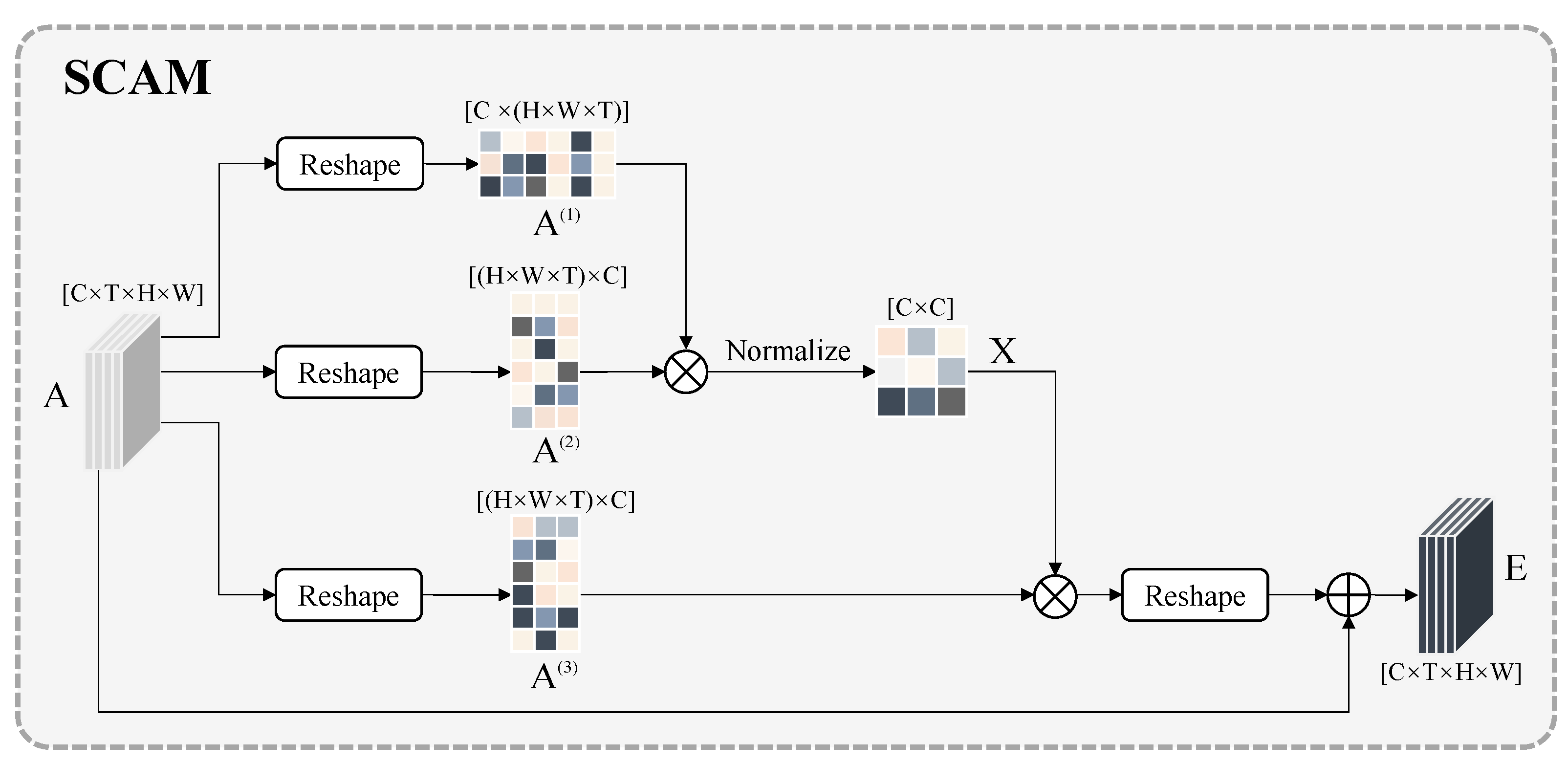
3.2. Dual Spatiotemporal Attention Module
3.3. Multimodal Fusion Module
4. Experiments and Results
4.1. Dataset
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods on the IsoGD Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modality | Acc (%) |
|---|---|---|
| Wang et al. [28] | RGB | 36.60 |
| Li et al. [15] | RGB | 37.28 |
| Hu, Lin and Hsiu [29] | RGB | 44.88 |
| Miao et al. [14] | RGB | 45.07 |
| Duan et al. [16] | RGB | 46.08 |
| Zhang et al. [30] | RGB | 51.31 |
| Zhang et al. [31] | RGB | 55.98 |
| Zhu et al. [27] | RGB | 57.42 |
| Zhou et al. [1] | RGB | 62.66 |
| proposed | RGB | 62.73 |
| Wang et al. [28] | Depth | 40.08 |
| Miao et al. [14] | Depth | 40.49 |
| Li et al. [13] | Depth | 48.44 |
| Hu, Lin and Hsiu [29] | Depth | 48.96 |
| Zhang et al. [30] | Depth | 49.81 |
| Zhang et al. [31] | Depth | 53.28 |
| Zhu et al. [27] | Depth | 54.18 |
| Duan et al. [16] | Depth | 54.95 |
| Zhou et al. [1] | Depth | 60.66 |
| proposed (DA-3D) | Depth | 61.72 |
| Wang et al. [28] | RGB-D | 44.80 |
| Hu, Lin and Hsiu [29] | RGB-D | 54.14 |
| Zhang et al. [31] | RGB-D | 55.29 |
| Zhu et al. [27] | RGB-D | 61.05 |
| Zhou et al. [1] | RGB-D | 66.62 |
| proposed | RGB-D | 68.15 |
4.4. Comparison with State-of-the-Art Methods on the Briareo Dataset
4.5. Ablation Studies
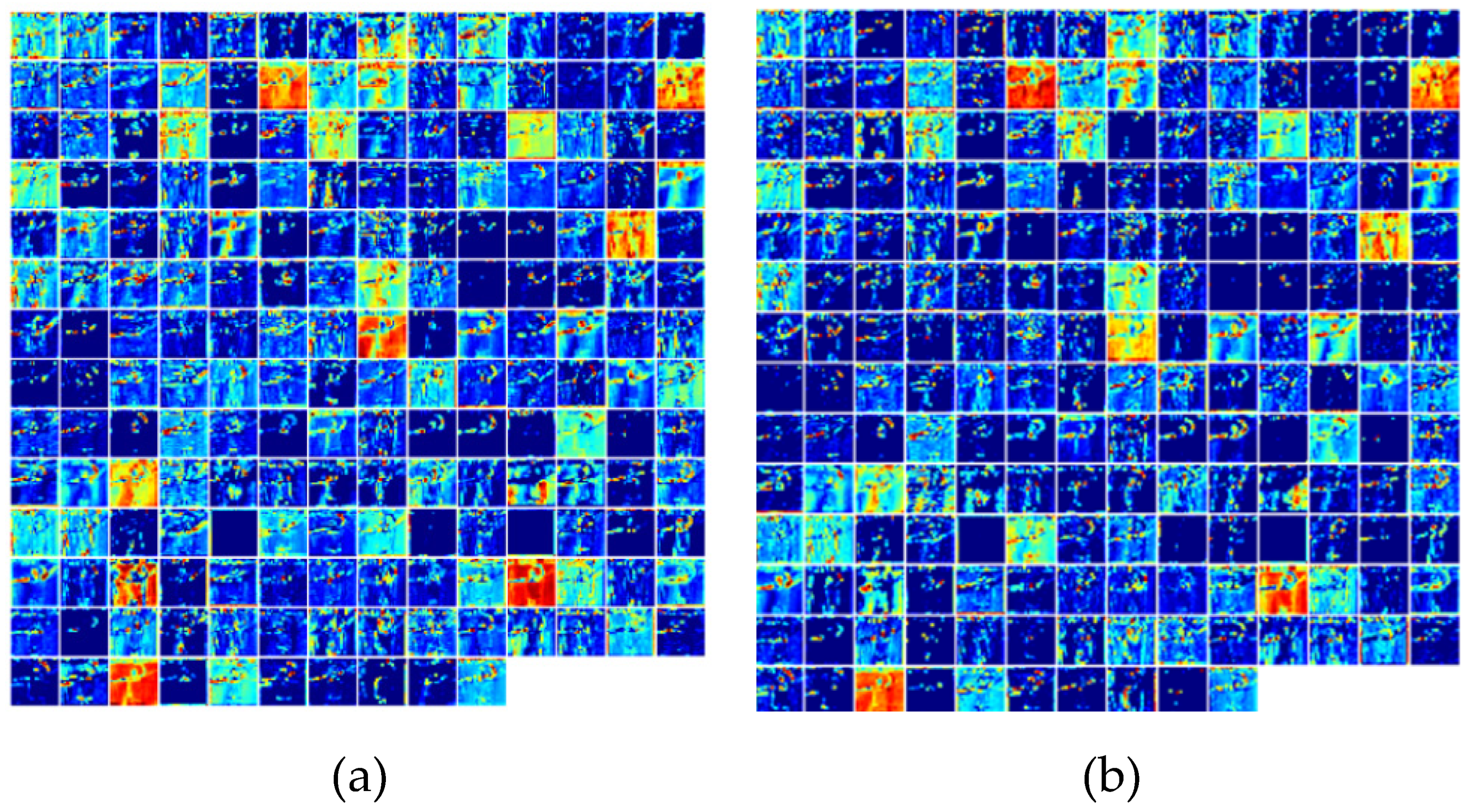
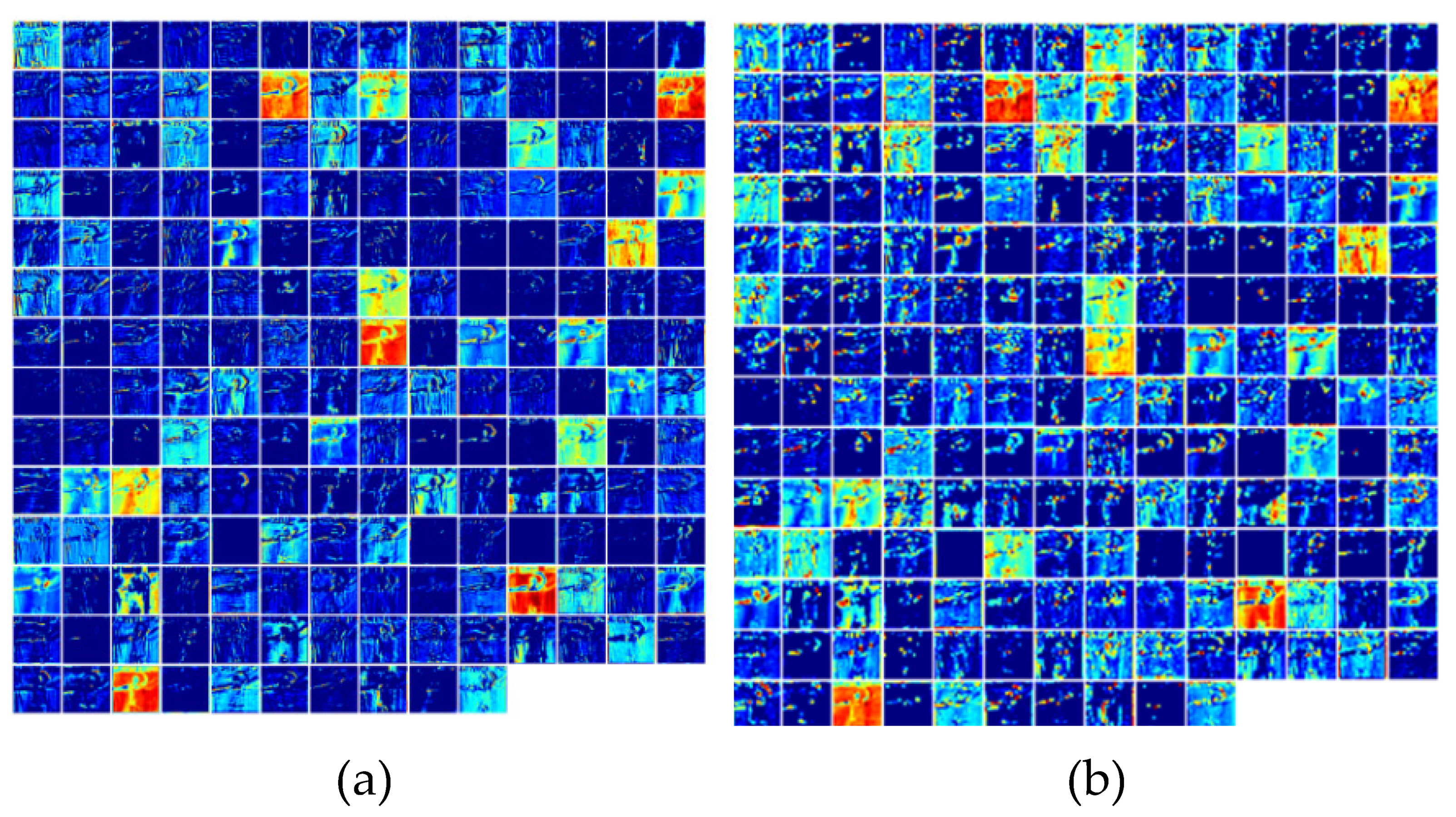
4.6. Visual Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, B.; Li, Y.; Wan, J. Regional Attention with Architecture-Rebuilt 3D Network for RGB-D Gesture Recognition. arXiv 2021, arXiv:2102.05348. [Google Scholar]
- Cui, R.; Cao, Z.; Pan, W.; Zhang, C.; Wang, J. Deep gesture video generation with learning on regions of interest. IEEE Trans. Multimed. 2019, 22, 2551–2563. [Google Scholar] [CrossRef]
- Zhang, T.; Lin, H.; Ju, Z.; Yang, C. Hand Gesture recognition in complex background based on convolutional pose machine and fuzzy Gaussian mixture models. Int. J. Fuzzy Syst. 2020, 22, 1330–1341. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Hsieh, C.; Liou, D. Novel Haar features for real-time hand gesture recognition using SVM. J. Real-Time Image Process. 2015, 10, 357–370. [Google Scholar] [CrossRef]
- Gurjal, P.; Kunnur, K. Real time hand gesture recognition using SIFT. Int. J. Electron. Electr. Eng. 2012, 2, 19–33. [Google Scholar]
- Bao, J.; Song, A.; Guo, Y.; Tang, H. Dynamic hand gesture recognition based on SURF tracking. In Proceedings of the 2011 International Conference on Electric Information and Control Engineering, Wuhan, China, 5–17 April 2011; pp. 338–341. [Google Scholar]
- Ghafouri, S.; Seyedarabi, H. Hybrid method for hand gesture recognition based on combination of Haar-like and HOG features. In Proceedings of the 2013 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013; pp. 1–4. [Google Scholar]
- Konečný, J.; Hagara, M. One-shot-learning gesture recognition using hog-hof features. J. Mach. Learn. Res. 2014, 15, 2513–2532. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Donahue, J.; Anne, H.L.; Guadarrama, S.; Rohrbach, M. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Li, Y.; Miao, Q.; Tian, K.; Fan, Y.; Xu, X.; Ma, Z.; Song, J. Large-scale gesture recognition with a fusion of RGB-D data based on optical flow and the C3D model. Pattern Recognit. Lett. 2019, 119, 187–194. [Google Scholar] [CrossRef]
- Miao, Q.; Li, Y.; Ouyang, W.; Ma, Z.; Xu, X.; Shi, W.; Cao, X. Multimodal gesture recognition based on the resc3d network. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3047–3055. [Google Scholar]
- Li, Y.; Miao, Q.; Tian, K.; Fan, Y.; Xu, X.; Li, R.; Song, J. Large-scale gesture recognition with a fusion of RGB-D data based on saliency theory and C3D model. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2956–2964. [Google Scholar] [CrossRef]
- Duan, J.; Wan, J.; Zhou, S.; Guo, X.; Li, S.Z. A unified framework for multimodal isolated gesture recognition. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–16. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Liu, S.; Gao, Z.; Tang, C.; Ogunbona, P. Large-scale isolated gesture recognition using convolutional neural networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 7–12. [Google Scholar]
- Liu, Z.; Chai, X.; Liu, Z.; Chen, X. Continuous gesture recognition with hand-oriented spatiotemporal feature. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3056–3064. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narayana, P.; Beveridge, R.; Draper, B.A. Gesture recognition: Focus on the hands. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5235–5244. [Google Scholar]
- YOLO v5. Available online: https://github.com/ultralytics/yolov5 (accessed on 15 March 2022).
- Mittal, A.; Zisserman, A.; Torr, P.H.S. Hand detection using multiple proposals. In Proceedings of the The British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; p. 5. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Wan, J.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S.; Li, S.Z. Chalearn looking at people rgb-d isolated and continuous datasets for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 56–64. [Google Scholar]
- Guyon, I.; Athitsos, V.; Jangyodsuk, P.; Escalante, H. The chalearn gesture dataset (cgd 2011). Mach. Vis. Appl. 2014, 25, 1929–1951. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Zisserman, A.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Zhu, G.; Zhang, L.; Yang, L.; Mei, L.; Shah, S.A.A.; Ben-namoun, M.; Shen, P. Redundancy and attention in convolutional LSTM for gesture recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1323–1335. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Li, W.; Wan, J.; Ogunbona, P.; Liu, X. Cooperative training of deep aggregation networks for RGB-D action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Hu, T.K.; Lin, Y.Y.; Hsiu, P.C. Learning adaptive hidden layers for mobile gesture recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, L.; Zhu, G.; Shen, P.; Song, J.; Shah, S.A.; Ben-namoun, M. Learning spatiotemporal features using 3dcnn and convolutional lstm for gesture recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3120–3128. [Google Scholar]
- Zhang, L.; Zhu, G.; Mei, L.; Shen, P.; Shah, S.A.A.; Bennamoun, M. Attention in convolutional LSTM for gesture recognition. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1957–1966. [Google Scholar]
- Manganaro, F.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Hand gestures for the human-car interaction: The briareo dataset. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; Springer: Cham, Switzerland, 2019; pp. 560–571. [Google Scholar]
- D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. A transformer-based network for dynamic hand gesture recognition. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 623–632. [Google Scholar]






| Method | Modality | Acc (%) |
|---|---|---|
| Manganaro et al. [32] | RGB | 72.2% |
| Manganaro et al. [32] | Depth | 76.0% |
| D’Eusanio et al. [33] | RGB | 90.6% |
| D’Eusanio et al. [33] | Depth | 92.4% |
| D’Eusanio et al. [33] | RGB-D | 94.1% |
| proposed | RGB | 91.3% |
| proposed (DA-3D) proposed | Depth | 92.7% |
| RGB-D | 94.1% |
| Method | Acc (%) |
|---|---|
| I3D | 61.28 |
| DA-3D 1 | 61.70 |
| MSA-3D 2 | 62.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Li, Y.; Fang, H.; Xin, W.; Lu, Z.; Miao, Q. Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition. Sensors 2022, 22, 2405. https://doi.org/10.3390/s22062405
Chen H, Li Y, Fang H, Xin W, Lu Z, Miao Q. Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition. Sensors. 2022; 22(6):2405. https://doi.org/10.3390/s22062405
Chicago/Turabian StyleChen, Huizhou, Yunan Li, Huijuan Fang, Wentian Xin, Zixiang Lu, and Qiguang Miao. 2022. "Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition" Sensors 22, no. 6: 2405. https://doi.org/10.3390/s22062405
APA StyleChen, H., Li, Y., Fang, H., Xin, W., Lu, Z., & Miao, Q. (2022). Multi-Scale Attention 3D Convolutional Network for Multimodal Gesture Recognition. Sensors, 22(6), 2405. https://doi.org/10.3390/s22062405