1. Introduction
Following the discovery of single-celled organisms by Antonie van Leeuwenhoek [
1] using his hand-crafted microscope, the use of microscopy in biological research has evolved greatly with the use of modern technology that has drastically enhanced microscope imaging capabilities. For example in the case of light microscopes, fluorescence microscopes allow for the identification and localization of fluorescent molecules in the given sample, whereas confocal microscopes which are an extended version of fluorescent microscopes allow for the acquisition of z-depth layer images of the same samples (if they have any) with higher resolution and later reconstruct those slices into 3D images [
2,
3].
Furthermore, since the advent of high-resolution digital microscopes over the decade, digital images have become one of the most significant groupings of linked data in automated analysis of various information related to biological structures and activities of living organisms which as a result shows studies on cell biology via cellular imaging have gained steadily increasing importance [
4]. In addition to digital images, fluorescent probes and an electron and light beam were the other two astounding advances that have led to this increase. Likewise, the importance of cell imaging in pathogen niche research has grown significantly and this includes investigations on living cells such as cell phase identification, cell tracking, and tracking of subcellular components [
5,
6,
7].
Despite the fact that microscope technology has made great advances in the field of life science, still, this sector faces substantial challenges in data processing and sharing due to the many digital file formats that are employed [
8]. Furthermore, despite the fact that the functioning principles of numerous scanners are equivalent (like applying compression function, etc.), there are hundreds of microscope scanners on the market today that employ distinct digital file formats [
4]. There are no universally accepted file formats for microscopy images. Many open-source and commercial software solutions for reading these diverse proprietary digital file formats have been created in order to mitigate the issue of distinct digital file formats [
9,
10,
11]. These software programs differ in terms of their targeted application, usability, and source code accessibility [
8]. Furthermore, the wide range of open-source and commercial solutions available today for determining which tool is ideal for a certain task may be tricky. Additionally, these solutions only provide access to image pixel data; sample clinical context (and acquisition process) information remain inaccessible [
12]. As more competing vendor solutions emerge, the number of proprietary formats grows, posing a barrier to interoperability and maintainability. As a result, the open-source solution developers struggle to bridge the gaps between several proprietary formats, while the open-source image analysis software developer and commercial microscopy companies frequently engage in format conflicts [
8,
13]. Therefore, there is a strong demand in the microscopy sector for data standardization in order to improve clinical integration and support the computational development streams [
4].
In the 1990s, different digital medical imaging modalities which were used in the hospital premises faced similar interoperability issues but after the acceptance of the Digital Imaging and Communication in Medicine (DICOM) standard protocol for data storage and communication that reality was transformed [
14]. At the initial phase, DICOM gateways were required to integrate legacy systems and then convert their analogue media and proprietary digital formats into the standard DICOM and later integrate them with the institutional Picture Archiving Communication System (PACS) which facilitates the features of study sharing with other institutions for visualization or analysis [
15].
Figure 1 shows the advantages of converting proprietary file formats into the standard DICOM. Aside from holding the actual image data, also known as pixel data, a DICOM object can also include a wide variety of metadata as well as properties that are part of the standard’s communication layers, thus enabling numerous services such as query and retrieval, data storage, acquisition scheduling, security profiles and print management [
16]. Therefore, it is rightful to say that “DICOM standardization has completely addressed the issue of interoperability in the field of radiology”.
In this paper, we offer a conversion pipeline based on the standard DICOM environment that can efficiently convert several microscope imaging modalities from different scanners into the standard DICOM from proprietary imaging file formats that were gathered from confocal laser scanner microscope (CLSM), whole side imaging (WSI), and focused ion beam scanning electron microscopes (FIB-SEM) [
17,
18,
19]. Later for validation reasons, the system was connected with the Dicoogle open-source PACS [
20]. As a result, a vendor-neutral archive was created with the ability to receive studies from various equipment manufacturers and microscopy modalities, index and validate the accompanying information, streamline web-based viewing services, and provide access to third-party DICOM compliant applications.
3. Overview of the Proposed Framework
The proposed framework, seen in
Figure 2, consists of three conversion pipelines that convert various proprietary file formats received from CLSM, WSI, and FIB-SEM microscope scanners into DICOM format by following the standard DICOM protocol.
3.1. CLSM and FIB-SEM Conversion Pipeline
Figure 4 depicts the DICOMization pathway for the CLSM and FIB-SEM imaging modalities. The conversion pipeline consists of two main processing steps. The first is to choose an image file reader based on the provided proprietary files given. In our experiment, we used the open-source OME-Bioformats library to read several proprietary files generated from microscope scanners. According to the OME-Bioformats website
https://docs.openmicroscopy.org/bio-formats/6.8.1/supported-formats.html (accessed on 20 February 2022), their library presently supports 159 different formats. While OME-Bioformats code is written in java, with the help of Java-bridge, we can use their library in a Python environment. Furthermore, in the second stage, the Pydicom 2.0.0 library is utilized to transform provided proprietary files to the standard DICOM. This library reads and writes DICOM files in a Python environment very quickly. It will generate new dataset main object files, which will contain file meta information for dictionary files such as
Media Storage SOP Class UID,
Implementation Class UID,
Transfer Syntax UID, and so on.
In terms of image structure, FIB-SEM scanners create serial 2D images of the provide samples, but CLSM scanners may produce single, double, triple, or multi-wavelength illumination mode images from the provided sequence of individual optical sections, which is a basic image unit. Later, created multi-wavelength mode images are blended with one another to observe all imaging modes in one; each mode is also referred to as a channel. In addition, each channel is acquired at a certain time interval with a sequence of z-series data of individual optical sections. So, in general, the dimensions of CLSM images are on the order of four (XYCZT).
In terms of image conversion, proprietary files of FIB-SEM and CLSM imaging modalities [
17,
18] were first sent to the OME-bioformats library, which then chose an appropriate image reader depending on the provided sample. If the OME-bioformats library recognizes the files, it will read the image pixel data and the metadata of the given sample. Later, this gathered data will then be sent to the Pydicom library. Before converting the acquired 2D slices from the first phase into DICOM, we must first construct new dataset main object files that encompass the dictionary files such as
File Meta Information Group Length,
Media Storage SOP Class UID,
File Meta Information Version,
Implementation Class UID,
Media Storage SOP Instance UID, and
Transfer Syntax UID, as well as file meta information. Moreover, we selected the Class UID module as
1.2.840.10008.5.1.4.1.1.77.1.2 (VL Microscopic Image Storage) and
1.2.840.10008.1.2.1 (Explicit VR Little-endian) as a Transfer Syntax UID for both imaging modalities (since the provided CLSM and FIB-SEM images were uncompressed, furthermore, the pipeline could be easily adjusted to use another encoding, as a trade-off between image quality, data size and conversion time). The “MONOCHROME2” option was chosen for Photometric interpretation attributes since the given sample was grayscale with a sample per pixel of one. In the following step, we created some private tags to fill the newly created DICOM image metadata with microscope image information such as the channel name, image dimension order, illumination types, pixel size, channel ID, magnification range, and so on, because the DICOM normalization committee’s defined DICOM file header does not provide public tags to insert this type of information inside the metadata. Similarly, the SHA-1 hash function library was used to establish a unique patient ID for each and every sample. Our pipeline can transform both 8-bit and 16-bit imaging modalities into standard DICOM according to standard tags (
Bits Allocated,
Bits Stored,
High Bit).
3.2. WSI Conversion Pipeline
Figure 5a illustrates the DICOMization pathway for the WSI imaging modalities. The proposed WSI conversion pipeline is divided into three stages: Image file reader and unrecognized file conversion to the OME.tiff file format; the internal processing stage includes multiple steps such as image series count, channel count, z-series layer count, splitting the image into a number of tiles, pyramid layer extrapolation and others, and DICOMization stage.
The conversion approach starts by sending the original WSI samples to the OME-Bioformats file reader, which decode image pixel data and their metadata if the file format is recognized [
19]. If the provided WSI file format is not recognized by this library, then the proposed pipeline will use a different process, activating the OME-tiff function, which will convert an unrecognized file to a pyramidal OME-tiff file by reading image tiles with the TIFFFile Python library and then stitching these tiles back together to reconstruct the original WSI image into pyramidal OME.tiff file format with their metadata.
Following the successful decoding of the sample by the OME-Bioformats file reader, the pipeline counts the number of resolution levels (or image series count) contained in the original image, followed by a count of z-series layers to decide if the passed image contains a z-axis plane or not. If the provided sample lacks a z-series plane, then our pipeline will bypass the z-stack loop and send the acquired image (x and y) coordinates from the first step (image series count) to the function-1 (process-1) and function-2 (process-2) without z-stack loop for further processing. After finishing the first layer’s processing, the process will return to the resolution layer count loop to load the next layer. This operation will be repeated until all resolution layers have been processed from functions (1 and 2). Furthermore, if the provided sample had z-series data then our pipeline will bypass without z-stack loop and send the collected image (x and y) coordinates of the first z-series from the first step (image series count) to the function-1 (process-1) and function-2 (process-2) of with z-stack loop for further processing. This loop will repeat over each z-axis resolution layer while simultaneously passing each z-depth resolution layer via function-1 and function-2 for additional processing. After it has completed running for each z-series of the first image series count, it will return to the image series count loop to read another resolution layer; this process will be repeated until all stacked resolution layers have been passed from function (1 and 2) for conversion into standard DICOM.
Overall, to address the zoom gap problem between resolution layers that often happens in WSI images as shown in
Figure 6a,b, we designed two functions: function-1 and function-2, in the internal processing stage. Function-1 operates by dividing the input image into a number of small tiles, the size of which is determined by the user. In our pipeline, we have set the tile size to be 512 × 512. After cropping a passed input image into a number of tiles (the number of tiles depends on the size of the resolution layer, it varies within resolution layers, as shown in
Figure 7); these cropped tiles will be appended one by one to form a list of tiles, which will then be passed to the DICOM encapsulate function to create an encoded multi-frame DICOM image. Like function-1, function-2 will crop the provided input image in 1024 × 1024 dimensions, which is twice the cropped dimension of function-1, and then down-sample (or resize) these cropped tiles by dividing their width and height by two, as illustrated in
Figure 5b. Later, it will add each tile into a single form for multi-frame encoding.
While converting stack or non-stack WSI images into standard DICOM, we utilized the SHA-1 function from the hashfile library to generate a unique identifier for each sample. As a result, the newly generated DICOM files will contain unique UIDs for series, study, and SOP instance (tags SeriesInstanceUID, StudyInstanceUID, and SOPInstanceUID). Furthermore, we passed JPEG baseline (1.2.840.10008.1.2.4.50) as the transfer syntax for serialized multi-frame encoding of multi-frame DICOM images. Similarly, for the SOP Class UID, we provide virtual light (VL) whole slide microscopy image storage (1.2.840.10008.5.1.4.1.1.77.1.6), which was published by DICOM committee members. The YBR_FULL_422 option was chosen for photometric interpretation attributes since the given sample was RGB with a sample per pixel of three. Later, we generated some private tag dictionaries to fill the information collected from the provided samples, such as Device Maker, Capture Mode, Device Model, into the newly formed DICOM image metadata.
4. Result and Discussion
Here, we intend to build an automated process that can convert a variety of microscope proprietary data into standard DICOM format, which would address not just interoperability but also sharing, maintainability (across institutions), and visualization. The Python environment was chosen as a programming platform for this project due to its versatility and available resources. The above-mentioned pipeline was performed on an Intel Core i7 10th generation CPU with 16 GB RAM and the Ubuntu 18.04 LTS operating system.
In this section, we will present the findings obtained after evaluating the performance and reliability of our proposed pipeline for converting distinct proprietary file format inputs into standard DICOM as input samples were gathered from distinct scanners belonging to CLSM, FIB-SEM, and WSI microscope systems.
As shown in
Table 1, we collected four distinct proprietary file formats belonging to the CLSM microscope. The Zeiss scanner has two files extension, .czi and .lsm, but the Nikon and Leica scanners have one each, .nd2 and .lif. The obtained .czi and .lsm samples were 16 and 8 bits per pixel, respectively, whereas .lif and .nd2 were 8 and 12 bits per pixel, showing that the CLSM pipeline was tested with a varying range of bits per pixel samples.
Furthermore, the number of channels and image size of the gathered input samples varies, and each of them has a series of z-stack planes. In the instance of the .lif sample, which is a four-channel sample with 64 z-series planes on each channel, in total there are 256 image slices stacked on top of one another. To convert this into DICOM, our proposed pipeline took 9.56 s as the size of the Leica image was 900 MB. Similarly, with a .czi image with a file size of 431 MB and 138 slices in total, our proposed pipeline took 2.12 s to convert to the standard DICOM.
Figure 8 shows the DICOMized results of all four selected proprietary files from CLSM microscopes.
Additionally,
Table 2 shows the generated unique identifier for the .czi extension file. These unique identifiers were generated for each input sample while converting them to DICOM using the SHA-1 function from the hashfile library (which are globally unique values). As shown in
Table 2, the newly produced DICOM file of .czi includes the following number in a patient ID tag:
186355337916212766286352571899677090176885900481. It also has distinct
StudyInstanceUID,
SeriesInstanceUID, and
SOPInstanceUID values. Overall, in the instance of CLSM proprietary files, our proposed pipeline effectively converted passed distinct CLSM proprietary files into DICOM by following the standard DICOM protocol.
Figure 9a shows the biological information of the first channel .nd2 image, which is stored inside the DICOM metadata.
In the instance of the FIB-SEM microscope, we obtained two distinct proprietary input samples, one with the .tif extension and the other with the .mrc extension, as shown in
Table 3. Both files have an 8 bit per pixel resolution. The .tif input sample size was 2.7 GB and contained 447 series of 2D images, whilst the .mrc input sample size was 948 MB and contained 361 series of 2D images. To convert these two files into DICOM, our proposed pipeline took 14.76 and 5.74 s, respectively.
Figure 10 depicts the DICOMized result and
Figure 9b shows the biological information of .tif image, which is stored inside the DICOM metadata. As OME-bioformats was unable to read .mrc files, we first pass .mrc files from the mrcfiles library in Python to read the image array, and then we send those arrays to the OME-bioformats library internally to convert them to DICOM files.
To evaluate the conversion performance and reliability of the proposed pipeline for WSI samples, we utilized nine distinct proprietary files, two of which were stacked while the remaining sample files were non-stack (non-stack: .svs, .scn, .tif, .tiff, .ome.tiff, .bif, .vis, and stack: .ndpi). Furthermore, the OME-Bioformats library successfully read all nine provided proprietary files, including their image pixel data and metadata. It was chosen as a file reader for this pipeline over other open-source libraries such as openslide [
10] because it can read both stack and non-stack image files.
Despite the fact that OME-Bioformats read all passed proprietary files efficiently, it could not always read the pyramidal resolution layer of .tiff and .tif files other than the base resolution layer. To overcome this issue, we build a function that uses the Tifffile Python module to convert these unrecognized resolution layer image files into pyramidal OME.tiff files. To test the function’s effectiveness of the above-mentioned OME.tiff conversion technique, we send two WSI files (.tif and .tiff, both downloaded from the cytomine website) to the above-mentioned technique whose files resolution layer is unrecognized by the OME-Bioformats image reader except for the base one. These are terabyte and gigabyte image files that have been compressed to 158 GB and 847 MB, respectively, using a JPEG code stream of quality 70 and 92 percent, as shown in
Table 4.
Furthermore, it took 10 h for our OME.tiff conversion algorithm to convert 158 GB of sample data into pyramidal OME.tiff file and 2.72 min to convert 847 MB of image data into a pyramidal OME.tiff file. For this function, we encoded each image using lossy JPEG compression at 90% quality [
34,
35] (level 90 JPEG compression produces typically compression ratios of about 1:10 in pathology WSIs), so the first image size increased to 247.2 GB from 158 GB because it was originally compressed at 70%, and the second image size decreased to 713.5 MB from 847 MB because it was originally compressed at 92 percent quality. After completing the OME.tiff conversion, the transformed images were forwarded to the internal processing section for the conversion into standard DICOM, as shown in
Figure 5a.
Additionally, as seen in
Figure 6c with pink color, certain WSI samples had a resolution gap between each layer. For example, in the .ndpi samples obtained from Hamamatsu scanners, the base layer was zoomed at 40× and its size was 166,656 × 60,928 × 11, but the second layer was scanned at 10× and its size was 41,664 × 15,232 × 11, resulting in a zoom gap of 30×. These types of images can be DICOMized and visualized, but without the addition of more resolution layers, the viewer will need to request a significantly larger number of tiles for the next magnification level in order to show the contents of the viewport with high fidelity, but at a higher network performance cost. To address this issue, we proposed two functions as their workflow is already described in the
WSI Conversion Pipeline section. We found the missing resolution gaps using the algorithms described above, as indicated by the green color in
Figure 6c.
Table 5 shows the proposed method’s performance and conversion time for converting both stack and non-stack proprietary WSI sample files into standard DICOM. While encapsulating, each pixel data was encoded to the multi-frame using lossy JPEG compression at 90% [
34,
35]. As seen in
Table 5, converting 11 stacks of WSI images into DICOM took more than 10 h. In addition, the resolution layer of the stacked images was increased from five to 10.
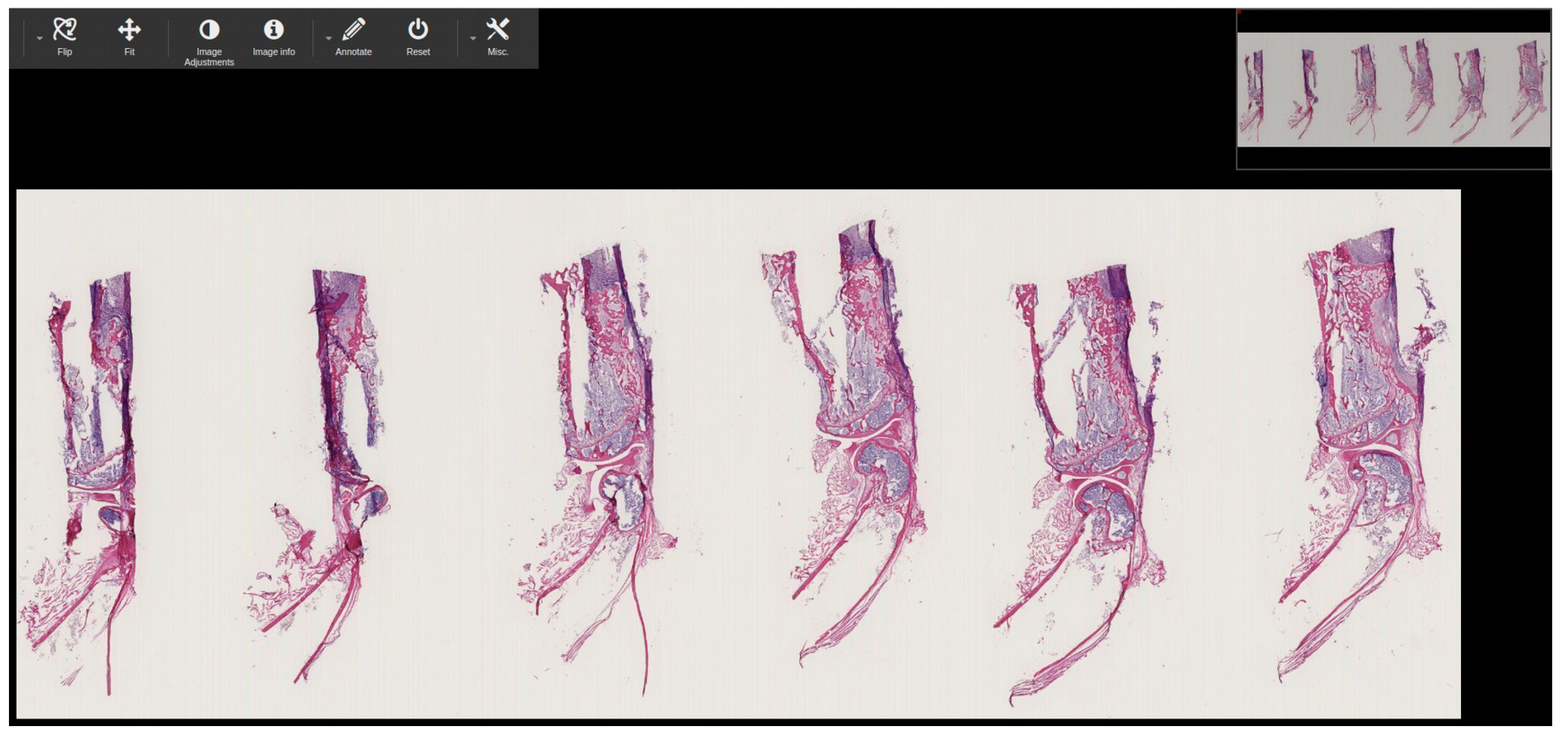
Figure 11 shows the 11 stack .ndpi WSI pyramid image that has been successfully converted to standard DICOM and
Figure 9c shows the biological information of the base layer of .ndpi (patient name: DCM_1D_1c-6c) WSI sample, which is stored inside the DICOM metadata. In the instance of the .ndpi WSI sample, which was an 11 stack image, after passing it through our proposed pipeline, as shown in
Figure 5a, the internal process function and DICOMization algorithm will automatically produce 11 folders (folders depend on the number of stacks of the sample), each of which contains ten DICOMized images, as shown in
Figure 11. Likewise,
Figure 12 shows the DICOMized image of the first stack from the 11 stack .ndpi image.
In this experiment, to check whether the generated DICOM files were readable or not, we passed each DICOM file from the Pydicom library to read it in a Python environment, and we passed each generated DICOM file to the open-source PACS archive Dicoogle, to be opened by the PACScenter viewer.
Figure 13 shows that all nine WSI, four CLSM, and two FIB-SEM DICOMized files were successfully indexed by the Dicoogle archive. The DICOMized result is available online [
36].
5. Conclusions
In the present context, there are not any decentralized open-source applications that can provide interoperability solutions in the domain of microscope imaging since there is no universal standard for this. Therefore, in this scenario, we believe that adopting the universal DICOM standard is the best way to address interoperability and proprietary concerns.
As a result, the goal of this article was to develop an automated DICOMization pipeline that can take distinct proprietary microscope imaging files and efficiently convert them into standard DICOM with their biological information stored inside their metadata, allowing for interoperability between proprietary files as well as the flexibility to share and visualize in any local DICOM viewer. To test the performance and reliability of our proposed pipeline, we pass 15 distinct proprietary files, four of which belong to the CLSM scanner, two to the FIB-SEM scanner, and the other nine to the WSI scanner.
Table 1,
Table 3 and
Table 5 show the outcomes. As illustrated in
Figure 13, our proposed pipelines successfully converted all 15 distinct proprietary files into standard DICOM.
The number of successfully verified proprietary files in our study is modest due to a lack of publicly available data, so we could not evaluate our pipeline performance to the maximum height, but we believe it can convert all extension files supported by OME-Bioformats. Furthermore, in order to simplify the complexity and breadth of the results, the current study was restricted to the use of a baseline JPEG encoding for the compression of a number of tiles into a multi-frame DICOM in a WSI pipeline. Nonetheless, the application and analysis of different image encoding formats is an area of future study that should be pursued. In addition, we would like to test our pipeline with other microscope imaging modalities that are not presently included here (namely, .oib, .mirax, and .svslide). These methods are part of our vision towards the creation of an open-source N-dimensional viewer for modern microscopy DICOM images.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}