
Spatial-Temporal Speckle Variance in the En-Face View as a Contrast for Optical Coherence Tomography Angiography (OCTA)


Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition Parameters and Pre-Processing
2.2. The En-Face OCTA Algorithm
2.3. Visualizing the Angiography: 3D and Projection Selection
2.4. Methods for Animal Care
3. Results and Discussion
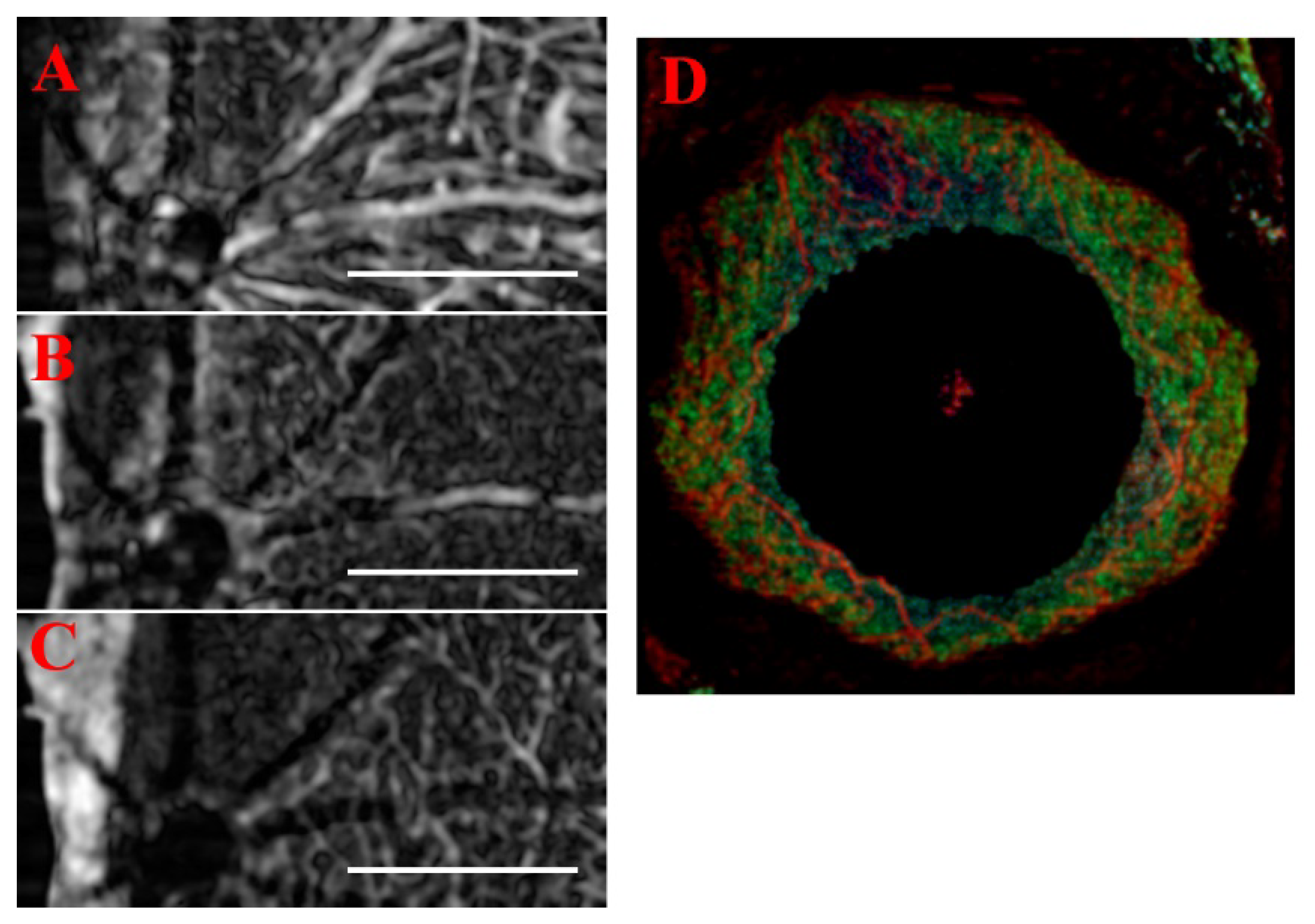
3.1. Single Frame Widefield: Assessment of the Algorithm
3.2. Frame Averaging by Mean Approach
3.3. Frame Averaging by Standard Deviation
3.4. Comparisons of Averaging Methods
3.5. Performance Comparison
3.6. CNR Performance Metrics
3.7. Volumetric Analysis and High-Resolution B-Scans
3.8. Generalizability and Alternate Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical Coherence Tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alonso-Caneiro, D.; Read, S.A.; Collins, M.J. Speckle reduction in optical coherence tomography imaging by affine-motion image registration. J. Biomed. Opt. 2011, 16, 116027–1160275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mayer, M.A.; Borsdorf, A.; Wagner, M.; Hornegger, J.; Mardin, C.Y.; Tornow, R.P. Wavelet denoising of multiframe optical coherence tomography data. Biomed. Opt. Express 2012, 3, 572–589. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Bailey, S.T.; Wilson, D.J.; Tan, O.; Klein, M.L.; Flaxel, C.J.; Potsaid, B.; Liu, J.J.; Lu, C.D.; Kraus, M.F.; et al. Quantitative Optical Coherence Tomography Angiography of Choroidal Neovascularization in Age-Related Macular Degeneration. Ophthalmology 2014, 121, 1435–1444. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ang, M.; Cai, Y.; Shahipasand, S.; Sim, D.A.; Keane, P.A.; Sng, C.C.A.; Egan, C.A.; Tufail, A.; Wilkins, M.R. En face optical coherence tomography angiography for corneal neovascularisation. Br. J. Ophthalmol. 2015, 100, 616–621. [Google Scholar] [CrossRef]
- Jia, Y.; Tan, O.; Tokayer, J.; Potsaid, B.M.; Wang, Y.; Liu, J.J.; Kraus, M.F.G.; Subhash, H.; Fujimoto, J.G.; Hornegger, J.; et al. Split-spectrum amplitude-decorrelation angiography with optical coherence tomography. Opt. Express 2012, 20, 4710–4725. [Google Scholar] [CrossRef] [Green Version]
- Choi, B.; Kang, N.M.; Nelson, J. Laser speckle imaging for monitoring blood flow dynamics in the in vivo rodent dorsal skin fold model. Microvasc. Res. 2004, 68, 143–146. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Chen, S.; Soetikno, B.; Liu, W.; Tong, S.; Zhang, H.F. Monitoring Acute Stroke in Mouse Model Using Laser Speckle Imaging-Guided Visible-Light Optical Coherence Tomography. IEEE Trans. Biomed. Eng. 2017, 65, 2136–2142. [Google Scholar] [CrossRef]
- Mahmud, M.S.; (Ryerson University, Toronto, Ontario M5B 2K3, Canada). Speckle Variance Optical Coherence Tomography (svOCT). 26 June 2013; Unpublished Presentation. [Google Scholar]
- Shi, W.; Gao, W.; Chen, C.; Yang, V.X.D. Differential standard deviation of log-scale intensity based optical coherence tomography angiography. J. Biophotonic 2017, 10, 1597–1606. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, M.; Hwang, T.S.; Bailey, S.T.; Huang, D.; Wilson, D.J.; Jia, Y. Reflectance-based projection-resolved optical coherence tomography angiography. Biomed. Opt. Express 2017, 8, 1536–1548. [Google Scholar] [CrossRef]
- Lee, P.-H.; Chan, C.-C.; Huang, S.-L.; Chen, A.; Chen, H.H. Extracting Blood Vessels From Full-Field OCT Data of Human Skin by Short-Time RPCA. IEEE Trans. Med. Imaging 2018, 37, 1899–1909. [Google Scholar] [CrossRef] [PubMed]
- Le, N.; Song, S.; Zhang, Q.; Wang, R.K. Robust principal component analysis in optical micro-angiography. Quant. Imaging Med. Surg. 2017, 7, 654–667. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spaide, R.F.; Klancnik, J.M.; Cooney, M.J. Retinal Vascular Layers Imaged by Fluorescein Angiography and Optical Coherence Tomography Angiography. JAMA Ophthalmol. 2015, 133, 45–50. [Google Scholar] [CrossRef]
- Hormel, T.T.; Wang, J.; Bailey, S.T.; Hwang, T.S.; Huang, D.; Jia, Y. Maximum value projection produces better en face OCT angiograms than mean value projection. Biomed. Opt. Express 2018, 9, 6412–6424. [Google Scholar] [CrossRef]
- Liu, W.; Luisi, J.; Liu, H.; Motamedi, M.; Zhang, W. OCT-Angiography for Non-Invasive Monitoring of Neuronal and Vascular Structure in Mouse Retina: Implication for Characterization of Retinal Neurovascular Coupling. EC Ophthalmol. 2017, 5, 89–98. [Google Scholar] [PubMed]
- De Carlo, T.E.; Romano, A.; Waheed, N.K.; Duker, J.S. A review of optical coherence tomography angiography (OCTA). Int. J. Retin. Vitr. 2015, 1, 5. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.-L.; Wang, R. Optical coherence tomography based angiography [Invited]. Biomed. Opt. Express 2017, 8, 1056–1082. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Wang, J.; Jiang, H.; Yang, X.; Feng, L.; Hu, L.; Wang, L.; Lu, F.; Shen, M. Retinal microvasculature alteration in high myopia. Invest. Ophthalmol. Vis. Sci. 2016, 57, 6020–6030. [Google Scholar] [CrossRef] [Green Version]
- Bhanushali, D.; Anegondi, N.; Gadde, S.G.K.; Srinivasan, P.; Chidambara, L.; Yadav, N.K.; Roy, A.S. Linking retinal microvasculature features with severity of diabetic retinopathy using optical coherence tomography angiography. Investig. Ophthalmol. Vis. Sci. 2016, 57, OCT519–OCT525. [Google Scholar] [CrossRef]
- Wakabayashi, T.; Sato, T.; Hara-Ueno, C.; Fukushima, Y.; Sayanagi, K.; Shiraki, N.; Sawa, M.; Ikuno, Y.; Sakaguchi, H.; Nishida, K. Retinal microvasculature and visual acuity in eyes with branch retinal vein occlusion: Imaging analysis by optical coherence tomography angiography. Investig. Ophthalmol. Vis. Sci. 2017, 58, 2087–2094. [Google Scholar] [CrossRef]
- Xiao, M.; Zou, C.; Sheppard, K.; Krebs, M. OCT Image Stack Alignment: One more important preprocessing step. In Proceedings of the BioImage Informatics Conference 2015, Gaithersburg, MD, USA, 14–16 October 2015. [Google Scholar]
- Ewald, A.J.; Werb, Z.; Egeblad, M. Monitoring of Vital Signs for Long-Term Survival of Mice under Anesthesia: FIGURE 1. Cold Spring Harb. Protoc. 2011, 2011, pdb-rot5563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ho, D.; Zhao, X.; Gao, S.; Hong, C.; Vatner, D.E.; Vatner, S.F. Heart Rate and Electrocardiography Monitoring in Mice. Curr. Protoc. Mouse Biol. 2011, 1, 123–139. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salas, M.; Augustin, M.; Ginner, L.; Kumar, A.; Baumann, B.; Leitgeb, R.; Drexler, W.; Prager, S.; Hafner, J.; Schmidt-Erfurth, U.; et al. Visualization of micro-capillaries using optical coherence tomography angiography with and without adaptive optics. Biomed. Opt. Express 2016, 8, 207–222. [Google Scholar] [CrossRef] [Green Version]
- Rha, J.; Jonnal, R.S.; Thorn, K.E.; Qu, J.; Zhang, Y.; Miller, D.T. Adaptive optics flood-illumination camera for high speed retinal imaging. Opt. Express 2006, 14, 4552–4569. [Google Scholar] [CrossRef] [PubMed]
- Weinhaus, R.S.; Burke, J.M.; Delori, F.C.; Snodderly, D.M. Comparison of fluorescein angiography with microvascular anatomy of macaque retinas. Exp. Eye Res. 1995, 61, 1–16. [Google Scholar] [CrossRef]
- Thevenaz, P.; Ruttimann, U.; Unser, M. A pyramid approach to subpixel registration based on intensity. IEEE Trans. Image Process. 1998, 7, 27–41. [Google Scholar] [CrossRef] [Green Version]
- Sherfuddin, M.; Vijay, K.; Prashanthi, H.M.G.; Sathya, G. Skeletonization of 3D Images using 2.5D and 3D Algorithms. In Proceedings of the 2015 1st International Conference on Next Generation Computing Technologies (NGCT), Dehradun, India, 4–5 September 2015; pp. 971–975. [Google Scholar]
- Jia, Y.; Wei, E.; Wang, X.; Zhang, X.; Morrison, J.C.; Parikh, M.; Lombardi, L.H.; Gattey, D.M.; Armour, R.L.; Edmunds, B.; et al. Optical Coherence Tomography Angiography of Optic Disc Perfusion in Glaucoma. Ophthalmology 2014, 121, 1322–1332. [Google Scholar] [CrossRef] [Green Version]
- Mariampillai, A.; Standish, B.A.; Moriyama, E.H.; Khurana, M.; Munce, N.R.; Leung, M.K.K.; Jiang, J.; Cable, A.; Wilson, B.C.; Vitkin, A.; et al. Speckle variance detection of microvasculature using swept-source optical coherence tomography. Opt. Lett. 2008, 33, 1530–1532. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, M.S.; Cadotte, D.W.; Vuong, B.; Sun, C.; Luk, T.W.H.; Mariampillai, A.; Yang, V. Review of speckle and phase variance optical coherence tomography to visualize microvascular networks. J. Biomed. Opt. 2013, 18, 050901. [Google Scholar] [CrossRef] [Green Version]
- Braaf, B.; Donner, S.; Nam, A.S.; Bouma, B.E.; Vakoc, B.J. Complex differential variance angiography with noise-bias correction for optical coherence tomography of the retina. Biomed. Opt. Express 2018, 9, 486–506. [Google Scholar] [CrossRef]
- Zhang, A.; Zhang, Q.; Chen, C.-L.; Wang, R. Methods and algorithms for optical coherence tomography-based angiography: A review and comparison. J. Biomed. Opt. 2015, 20, 100901. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reif, R.; Qin, J.; An, L.; Zhi, Z.; Dziennis, S.; Wang, R. Quantifying Optical Microangiography Images Obtained from a Spectral Domain Optical Coherence Tomography System. Int. J. Biomed. Imaging 2012, 2012, 509783. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Idoughi, R.; Choudhury, B.; Heidrich, W. Statistical model for OCT image denoising. Biomed. Opt. Express 2017, 8, 3903–3917. [Google Scholar] [CrossRef] [Green Version]
- Luisi, J.; Kraft, E.R.; Giannos, S.A.; Patel, K.; Schmitz-Brown, M.E.; Reffatto, V.; Merkley, K.H.; Gupta, P.K. Longitudinal Assessment of Alkali Injury on Mouse Cornea Using Anterior Segment Optical Coherence Tomography. Transl. Vis. Sci. Technol. 2021, 10, 6. [Google Scholar] [CrossRef] [PubMed]
- Pi, S.; Camino, A.; Wei, X.; Simonett, J.; Cepurna, W.; Huang, D.; Morrison, J.C.; Jia, Y. Rodent retinal circulation organization and oxygen metabolism revealed by visible-light optical coherence tomography. Biomed. Opt. Express 2018, 9, 5851–5862. [Google Scholar] [CrossRef]
- Rocholz, R.; Teussink, M.M.; Dolz-Marco, R.; Holzhey, C.; Dechent, J.F.; Tafreshi, A.; Schulz, S. SPECTRALIS Optical Coherence Tomography Angiography (OCTA): Principles and Clinical Applications. Heidelb. Eng. Acad. 2018, 9, 1–10. [Google Scholar]
- Aguirre-Ramos, H.; Avina-Cervantes, J.G.; Cruz-Aceves, I.; Ruiz-Pinales, J.; Ledesma, S. Blood vessel segmentation in retinal fundus images using Gabor filters, fractional derivatives, and Expectation Maximization. Appl. Math. Comput. 2018, 339, 568–587. [Google Scholar] [CrossRef]
- Rapolu, M.; Niedzwiedziuk, P.; Borycki, D.; Wnuk, P.; Wojtkowski, M. Enhancing microvasculature maps for Optical Coherence Tomography Angiography (OCT-A). Photon-Lett. Pol. 2018, 10, 61–63. [Google Scholar] [CrossRef]
- Gardner, M.R.; Katta, N.; Rahman, A.S.; Rylander, H.; Milner, T.E. Design Considerations for Murine Retinal Imaging Using Scattering Angle Resolved Optical Coherence Tomography. Appl. Sci. 2018, 8, 2159. [Google Scholar] [CrossRef] [Green Version]
- Ploner, S.B.; Moult, E.M.; Choi, W.; Waheed, N.K.; Lee, B.; Novais, E.A.; Cole, E.D.; Potsaid, B.; Husvogt, L.; Schottenhamml, J.; et al. Toward quantitative optical coherence tomography angiography. Retina 2016, 36, S118–S126. [Google Scholar] [CrossRef] [Green Version]
- Alam, M.; Lim, J.I.; Toslak, D.; Yao, X. Differential Artery–Vein Analysis Improves the Performance of OCTA Staging of Sickle Cell Retinopathy. Transl. Vis. Sci. Technol. 2019, 8, 3. [Google Scholar] [CrossRef] [PubMed]
- Schottenhamml, J.; Moult, E.M.; Ploner, S.; Lee, B.; Novais, E.A.; Cole, E.; Dang, S.; Lu, C.D.; Husvogt, L.; Waheed, N.K.; et al. An automatic, intercapillary area-based algorithm for quantifying diabetes-related capillary dropout using optical coherence tomography angiography. Retina 2016, 36, S93–S101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, J.; Luisi, J.; Kraft, E.R.; Giannos, S.A.; Schmitz-Brown, M.E.; Gupta, P.; Motamedi, M. Single-frame optical coherence tomography angiography for the quantification of corneal neovascularization in a mouse model. In Ophthalmic Technologies XXXI; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; Volume 11623, p. 116231U. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | SV | PV | CDV | SF ST-OCTA | MF ST-OCTA |
|---|---|---|---|---|---|
| Signal-to-Noise Ratio | 0.235 | 0.0817 | 0.168 | 0.304 | 0.381 |
| Computation Time (s) | 6.05 | 170.37 | 23.17 | 12.39 | 14.49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luisi, J.D.; Lin, J.L.; Ameredes, B.T.; Motamedi, M. Spatial-Temporal Speckle Variance in the En-Face View as a Contrast for Optical Coherence Tomography Angiography (OCTA). Sensors 2022, 22, 2447. https://doi.org/10.3390/s22072447
Luisi JD, Lin JL, Ameredes BT, Motamedi M. Spatial-Temporal Speckle Variance in the En-Face View as a Contrast for Optical Coherence Tomography Angiography (OCTA). Sensors. 2022; 22(7):2447. https://doi.org/10.3390/s22072447
Chicago/Turabian StyleLuisi, Jonathan D., Jonathan L. Lin, Bill T. Ameredes, and Massoud Motamedi. 2022. "Spatial-Temporal Speckle Variance in the En-Face View as a Contrast for Optical Coherence Tomography Angiography (OCTA)" Sensors 22, no. 7: 2447. https://doi.org/10.3390/s22072447
APA StyleLuisi, J. D., Lin, J. L., Ameredes, B. T., & Motamedi, M. (2022). Spatial-Temporal Speckle Variance in the En-Face View as a Contrast for Optical Coherence Tomography Angiography (OCTA). Sensors, 22(7), 2447. https://doi.org/10.3390/s22072447