
Challenges of Large-Scale Multi-Camera Datasets for Driver Monitoring Systems

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
- Large amounts of data for training and validation of DL methods.
- Realistic data of relevant situations (e.g., safety related such as drowsy drivers, talking on the phone, etc.).
- Spatio-temporal labels, including visual features (e.g., face landmarks) but also actions as frame intervals with a semantic load.
- Captured data need to represent physiological states for fatigue, behaviour and distraction, and thus several cameras might be needed to monitor the face, hands and body of the driver.
- Preparation of multiple environments (real car and simulator for simulation of non-safe driving behaviours or physiological states).
- Creation of complex annotation or metadata schemes to host heterogeneous labelling data.
- Organisation of recording sessions and management of volunteers.
- Data preparation: recording, transferring and compressing large volumes of raw data.
- Data processing: synchronization, alignment, calibration, labelling, etc.
- Privacy and ethical aspects (GDPR compliance).
- Dissemination aspects, including website preparation, management of updates, GitHub repositories, user manuals, samples, etc.
- Definition of a multi-sensor set-up architecture (multi-modal and multi-camera) for capturing large-scale video footage in the context of driving monitoring.
- Organisational approach to manage human volunteers and recording sessions: environments, scripting, recording, privacy and ethical aspects, etc.
- Orchestration of data preparation and data processing stages considering the DMS requirements: storage, containers, transmission, compression, synchronization, alignment, calibration and labelling.
- Taxonomy of driver monitoring labels for multi-level dataset annotation.
2. Driver Monitoring Methods and Datasets
2.1. Datasets in the Automotive Sector
2.2. Driver Monitoring Systems and Data Requirements
2.3. Datasets for Application of Driver Monitoring Systems
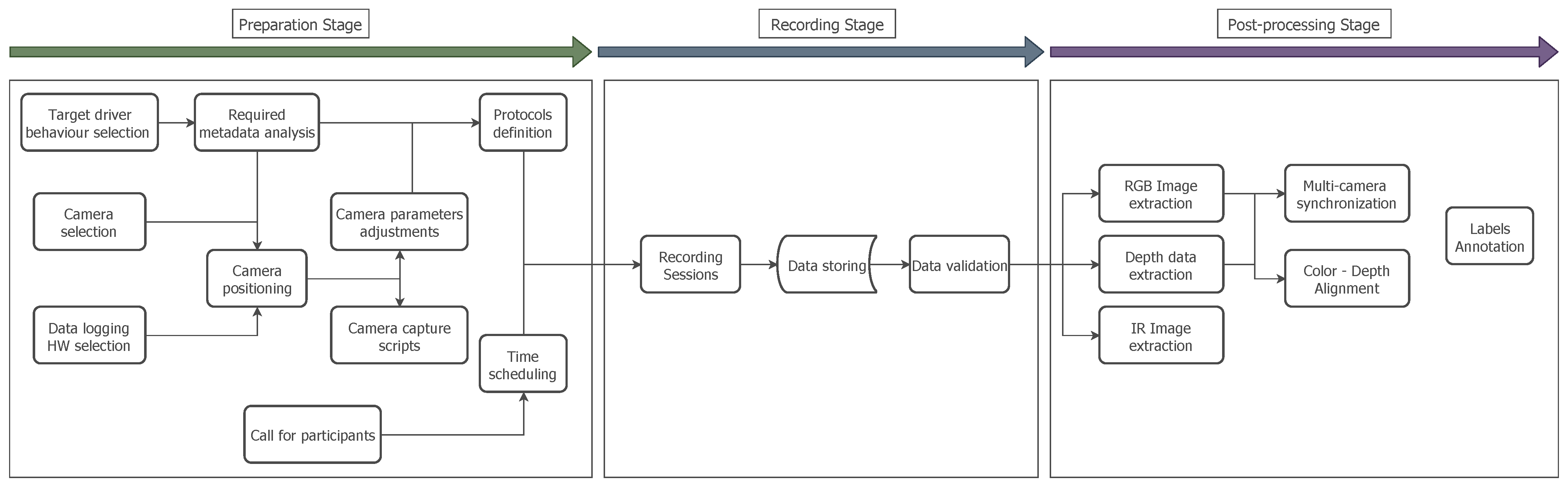
3. Dataset Definition and Creation
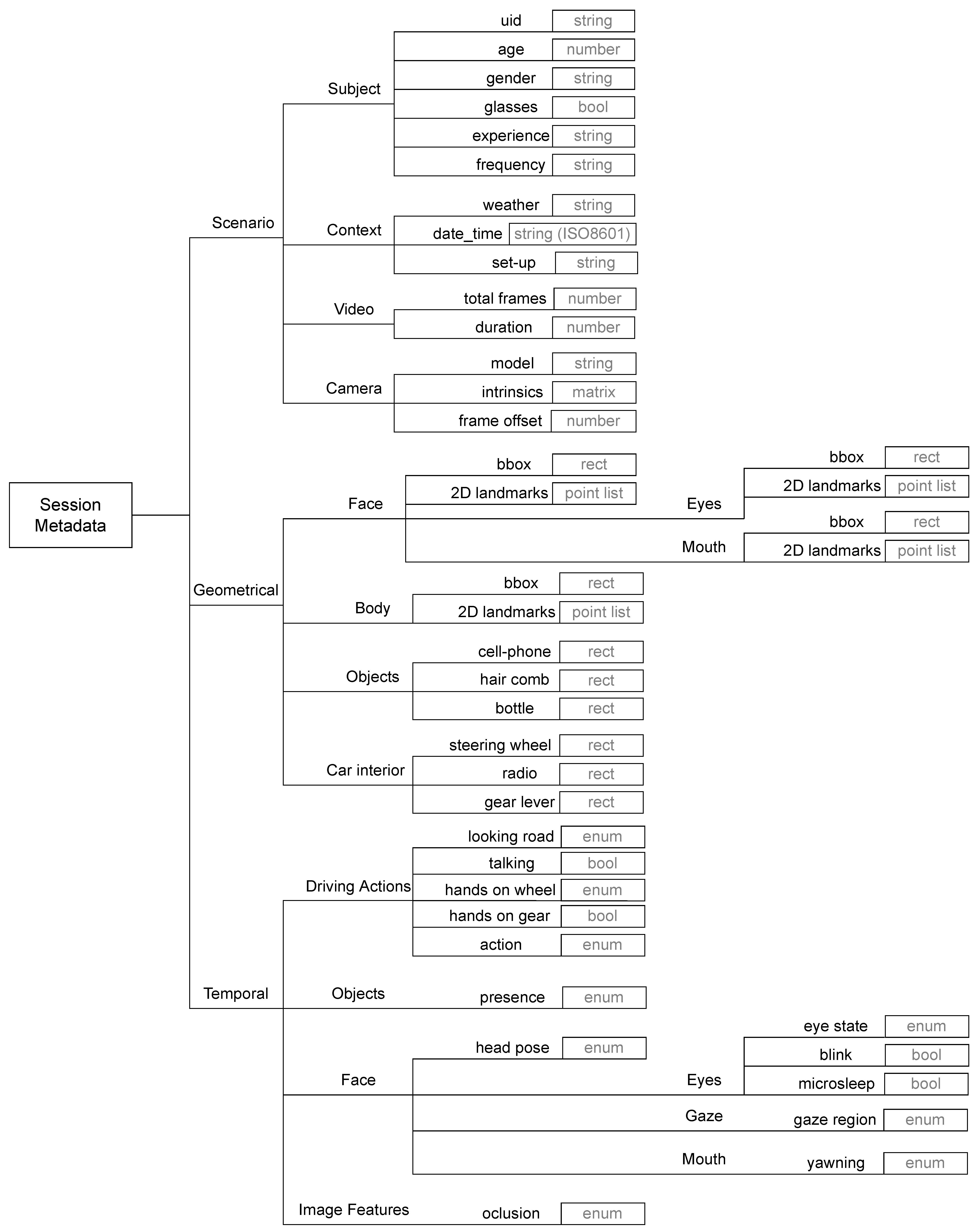
3.1. Metadata Taxonomy Definition
3.1.1. Scenario Metadata
3.1.2. Geometrical Features
3.1.3. Temporal Features
3.2. Scripted Protocols
- Participant welcoming: Check which participant is programmed, call him/her and welcome him/her. A description of the context of the experiment must be explained to the participants, along with the legal privacy terms and a brief description of their function: perform the indicated activities in the most natural way while driving (real or acting) and if required with a certain state (drowsy or attentive).
- Rehearsal and technology check: A quick practice of the activities to perform is necessary, both to verify that the participant has understood the activities to perform and that the recording equipment (cameras, microphones, etc.) is working correctly.
- Recording activities to perform: The actual recording is carried out following a predefined list of actions to be performed or acted by the driver, specifying the time (seconds) that each activity should last, approximately. The person in charge of carrying out the experiment is the person who controls these times and indicates to the participant what action and when to perform it.
- Final check: It is proposed to conduct a quick check of the recorded material to verify that the recording session went well and prepare everything for the next participant.
3.2.1. Distraction Protocol
3.2.2. Drowsiness Protocol
3.2.3. Gaze and Hands Protocol
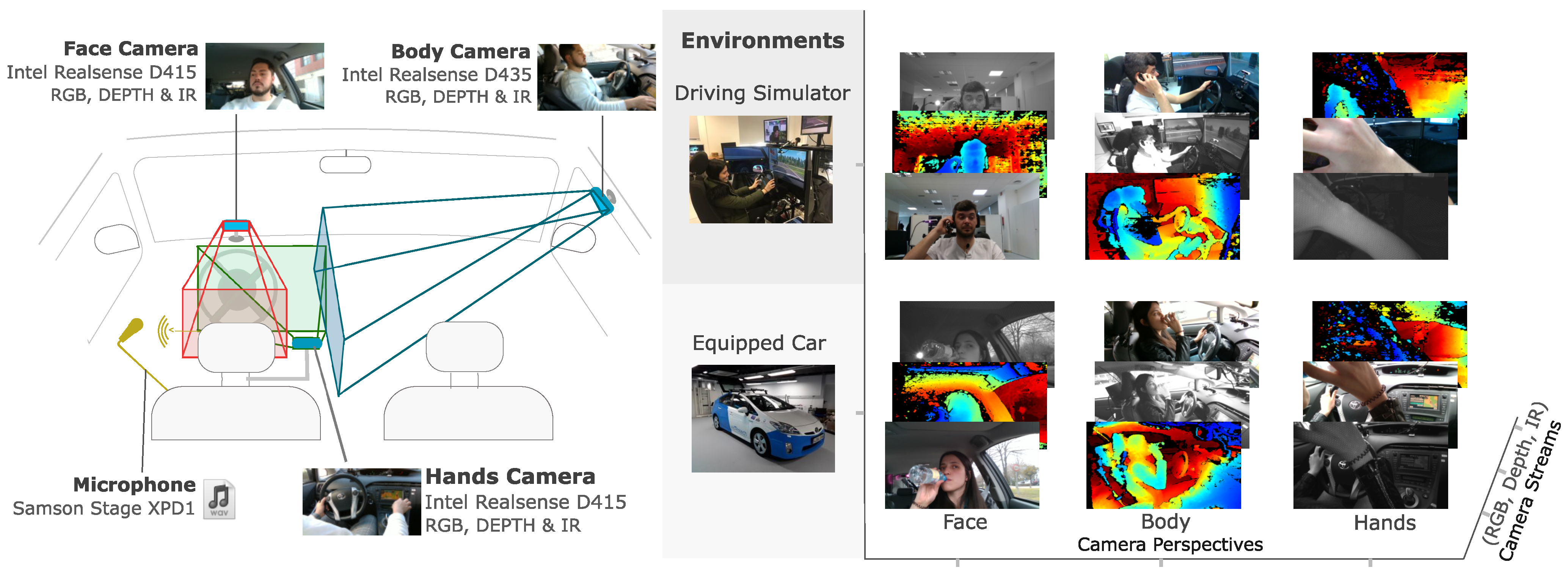
3.3. Multi-Sensor Setup Architecture
- Camera-based sensors: Data extracted from the sensors primarily relies on a visible feature inside the vehicle and driver.
- Multi-modal camera sensors: For a diverse and richer collection of data, the different modalities include RGB images, IR images and depth data.
- Multi-camera arrange setup: To capture several characteristics of the driver, multiple views of the inside of the vehicle are required.
- Synchronized images: Data from the different cameras and multi-modal streams are timestamped, synchronized and aligned.
3.4. Participants Selection
3.5. Recording Sessions
- CPU: Intel i9 7940X series X 4.30 GHz
- RAM: 64 GB
- HD: 2 × SSD 1 TB M2
- GPU: 2 × NVIDIA GeForceTM RTX 2080Ti 11 GB GDDR6 PCIe 3.0
4. Dataset Post-Processing
4.1. Stream Compression
- RGB and IR: The images are extracted and saved in PNG format with a size of pixels. After having the total number of images per stream extracted, they are encoded in a video with libx264 encoder and saved in MP4 format with a bit rate of 15,000 kbps and a frame rate of 29.98 FPS for hands and face camera videos and 29.76 FPS for body camera video. These frame rates were the ones stored by the cameras during the recordings.
- Depth: Depth data contains information of distance (in millimetres), indicating how far the object is from the camera, or the driver in this case, in every pixel. Therefore, this information can be extracted as an image where each pixel contains a distance value instead of a colour value. This image is in 16UC1 format, which allows each pixel to have a 16-bit value in one channel. This pixel format is equivalent to gray16le.To save as an image and preserve this pixel format, depth frames were saved in TIFF format (.tif). After exporting all images, the videos were encoded with FFV1 codec and saved in AVI format. The FFV1 codec is lossless and supports gray16le pixel format (images in 16UC1).The resulting video does not have a visualization purpose; the images are not recognizable with conventional video players, they contain distance information. This effort was made to make the distribution task simpler, since the IR and RGB are also distributed in video format.
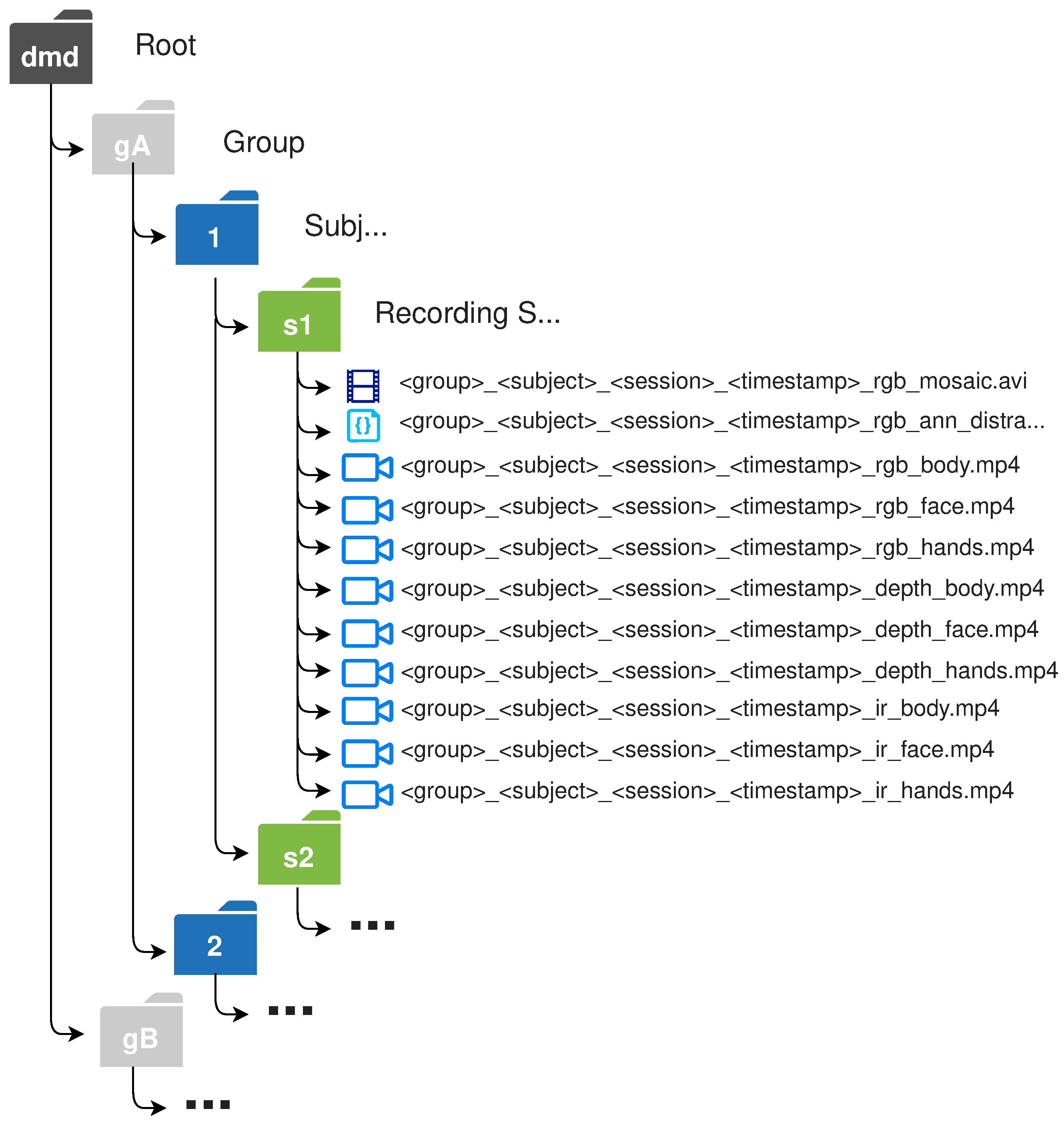
- Metadata: Inside the rosbag, there was also information about the recordings that were extracted and saved in the annotation file. This data is considered in the annotations list as scenario metadata (subject, context, video and camera information), shown in Figure 3.
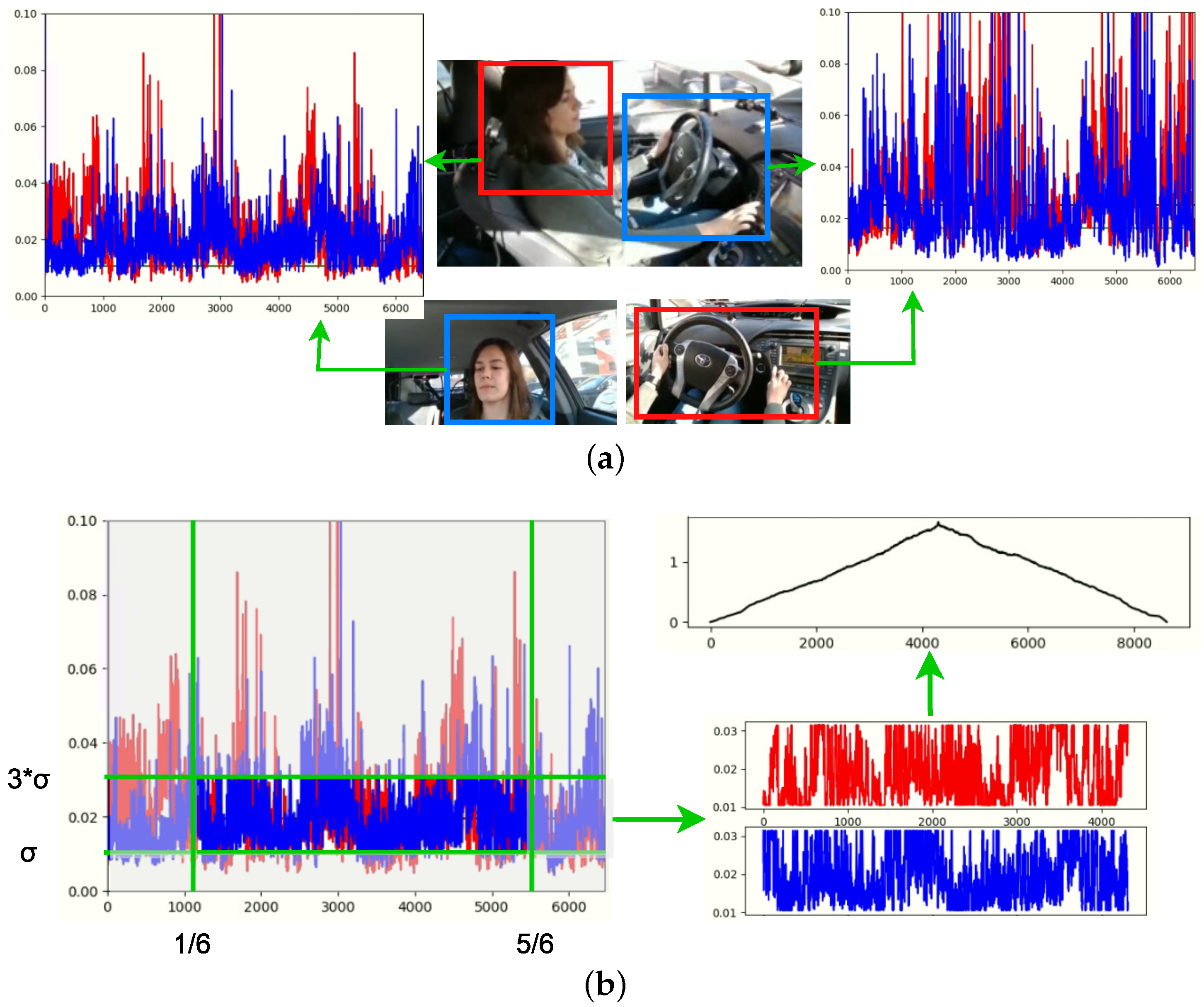
4.2. Multi-Sensor Stream Synchronization
4.3. Semi-Automatic Labelling
- Pre-annotations predicted by model: We only performed manual annotation for the driver actions of a few samples of the DMD with TaTo. These were then prepared to become training material. Then, we trained a model using transfer learning from a Mobilenet [8] originally trained with ImageNet [12]. The predictions were taken as pre-annotations and the annotator’s job was to correct and continue annotating instead of starting from zero.
- Logical relations among levels of annotations: There exist some logical relations between levels of annotations that, taken into account, could save time in the labelling process. For example, if the driver is sending a message with their left hand, this should be annotated in the driver_actions level as “texting-left”, but this action also could imply that the person is only using his/her right hand to drive (since he/she is using the left hand to text). Therefore, in the hands_using_wheel level, there should be the “only right” label. Other relations are the talking-related labels as “phonecall-left” in the driver_actions level and “talking” in the talking level. In TaTo, we implemented this function of applying logical annotations; once the annotations from the driver action level were completed, by pressing the “x” key, these logical annotations were propagated to the rest of the levels. This way, the annotator did not have to start annotating from zero.
5. Discussion
5.1. Sample Utilization of the DMD: Action Recognition
5.2. Ongoing and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CV | computer vision |
| DMS | driver monitoring system |
| DMD | driver monitoring dataset |
| DL | deep learning |
References
- Wang, W.; Liu, C.; Zhao, D. How much data are enough? A statistical approach with case study on longitudinal driving behavior. IEEE Trans. Intell. Veh. 2017, 2, 85–98. [Google Scholar] [CrossRef] [Green Version]
- Terzi, R.; Sagiroglu, S.; Demirezen, M.U. Big Data Perspective for Driver/Driving Behavior. IEEE Intell. Transp. Syst. Mag. 2020, 12, 20–35. [Google Scholar] [CrossRef]
- Saab. Saab Driver Attention Warning System; The Saab Network: Brussels, Belgium, 2007. [Google Scholar]
- Toyota Motor Corporation. Toyota Enhances Pre-Crash Safety System with Eye Monitor; Toyota Motor Corporation: Aichi, Japan, 2008. [Google Scholar]
- Volvo Car Group. Volvo Cars Conducts Research into Driver Sensors in Order to Create Cars That Get to Know Their Drivers; Volvo Car Group: Gothenburg, Sweden, 2014. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 712–733. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany; Volume 9905 LNCS, pp. 21–37. [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2443–2451. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Kesten, R.; Usman, M.; Houston, J.; Pandya, T.; Nad-hamuni, K.; Ferreira, A.; Yuan, M.; Low, B.; Jain, A.; On-druska, P.; et al. Lyft level 5 Perception Dataset 2020. 2019. Available online: https://level-5.global/data/ (accessed on 22 March 2022).
- Regan, M.A.; Strayer, D.L. Towards an understanding of driver inattention: Taxonomy and theory. In Annals of Advances in Automotive Medicine; Association for the Advancement of Automotive Medicine: Chicago, IL, USA, 2014; Volume 58, pp. 5–14. [Google Scholar]
- Chowdhury, A.; Shankaran, R.; Kavakli, M.; Haque, M.M. Sensor Applications and Physiological Features in Drivers’ Drowsiness Detection: A Review. IEEE Sensors J. 2018, 18, 3055–3067. [Google Scholar] [CrossRef]
- Sikander, G.; Anwar, S. Driver Fatigue Detection Systems: A Review. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2339–2352. [Google Scholar] [CrossRef]
- Jacobé de Naurois, C.; Bourdin, C.; Stratulat, A.; Diaz, E.; Vercher, J.L. Detection and prediction of driver drowsiness using artificial neural network models. Accid. Anal. Prev. 2019, 126, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Sahayadhas, A.; Sundaraj, K.; Murugappan, M. Detecting driver drowsiness based on sensors: A review. Sensors 2012, 12, 16937–16953. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ebrahim, P.; Stolzmann, W.; Yang, B. Eye movement detection for assessing driver drowsiness by electrooculography. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2013, Manchester, UK, 13–16 October 2013; pp. 4142–4148. [Google Scholar] [CrossRef]
- El Basiouni El Masri, A.; Artail, H.; Akkary, H. Toward self-policing: Detecting drunk driving behaviors through sampling CAN bus data. In Proceedings of the International Conference on Electrical and Computing Technologies and Applications, ICECTA, Ras Al Khaimah, United Arab Emirates, 21–23 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Shirazi, M.M.; Rad, A.B. Detection of intoxicated drivers using online system identification of steering behavior. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1738–1747. [Google Scholar] [CrossRef]
- Liang, Y.; Reyes, M.L.; Lee, J.D. Real-time detection of driver cognitive distraction using support vector machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 340–350. [Google Scholar] [CrossRef]
- Miyajima, C.; Takeda, K. Driver-Behavior Modeling Using On-Road Driving Data: A new application for behavior signal processing. IEEE Signal Process. Mag. 2016, 33, 14–21. [Google Scholar] [CrossRef]
- Kaplan, S.; Guvensan, M.A.; Yavuz, A.G.; Karalurt, Y. Driver Behavior Analysis for Safe Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3017–3032. [Google Scholar] [CrossRef]
- Halin, A.; Verly, J.G.; Van Droogenbroeck, M. Survey and synthesis of state of the art in driver monitoring. Sensors 2021, 21, 5558. [Google Scholar] [CrossRef]
- Moslemi, N.; Soryani, M.; Azmi, R. Computer vision-based recognition of driver distraction: A review. In Concurrency and Computation: Practice and Experience; Wiley: Hoboken, NJ, USA, 2021; pp. 1–25. [Google Scholar] [CrossRef]
- Deo, N.; Trivedi, M.M. Looking at the Driver/Rider in Autonomous Vehicles to Predict Take-Over Readiness. IEEE Trans. Intell. Veh. 2019, 5, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Borghi, G.; Fabbri, M.; Vezzani, R.; Calderara, S.; Cucchiara, R. Face-from-Depth for Head Pose Estimation on Depth Images. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 596–609. [Google Scholar] [CrossRef] [Green Version]
- Gavrilescu, M.; Vizireanu, N. Feedforward neural network-based architecture for predicting emotions from speech. Data 2019, 4, 101. [Google Scholar] [CrossRef] [Green Version]
- Roth, M.; Gavrila, D.M. DD-pose—A large-scale driver head pose benchmark. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; Volume 2019, pp. 927–934. [Google Scholar] [CrossRef] [Green Version]
- Ohn-Bar, E.; Trivedi, M.M. Looking at Humans in the Age of Self-Driving and Highly Automated Vehicles. IEEE Trans. Intell. Veh. 2016, 1, 90–104. [Google Scholar] [CrossRef]
- Vora, S.; Rangesh, A.; Trivedi, M.M. On generalizing driver gaze zone estimation using convolutional neural networks. In Proceedings of the IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017; pp. 849–854. [Google Scholar] [CrossRef]
- Fridman, L.; Lee, J.; Reimer, B.; Victor, T. Owl and Lizard: Patterns of Head Pose and Eye Pose in Driver Gaze Classification. IET Comput. Vis. 2016, 10, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Yuen, K.; Trivedi, M.M. Looking at Hands in Autonomous Vehicles: A ConvNet Approach Using Part Affinity Fields. IEEE Trans. Intell. Veh. 2019, 5, 361–371. [Google Scholar] [CrossRef] [Green Version]
- Ortega, J.D.; Cañas, P.; Nieto, M.; Otaegui, O.; Salgado, L. Open your eyes: Eyelid aperture estimation in Driver Monitoring Systems. In SMARTGREENS 2020, VEHITS 2020. Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1475. [Google Scholar] [CrossRef]
- Jabon, M.; Bailenson, J.; Pontikakis, E.; Takayama, L.; Nass, C. Facial-expression analysis for predicting unsafe driving behavior. IEEE Pervasive Comput. 2011, 10, 84–95. [Google Scholar] [CrossRef]
- Martin, M.; Popp, J.; Anneken, M.; Voit, M.; Stiefelhagen, R. Body Pose and Context Information for Driver Secondary Task Detection. IEEE Intell. Veh. Symp. Proc. 2018, 2018, 2015–2021. [Google Scholar] [CrossRef]
- Ghoddoosian, R.; Galib, M.; Athitsos, V. A Realistic Dataset and Baseline Temporal Model for Early Drowsiness Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Diaz-Chito, K.; Hernández-Sabaté, A.; López, A.M. A Reduced Feature Set for Driver Head Pose Estimation. Appl. Soft Comput. 2016, 45, 98–107. [Google Scholar] [CrossRef]
- Ohn-Bar, E.; Trivedi, M.M. The power is in your hands: 3d analysis of hand gestures in naturalistic video. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 912–917. [Google Scholar] [CrossRef] [Green Version]
- Borghi, G.; Venturelli, M.; Vezzani, R.; Cucchiara, R. POSEidon: Face-from-Depth for driver pose estimation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HA, USA, 21–26 July 2017; Volume 2017, pp. 5494–5503. [Google Scholar] [CrossRef] [Green Version]
- Martin, M.; Roitberg, A.; Haurilet, M.; Horne, M.; Reiss, S.; Voit, M.; Stiefelhagen, R. Drive & Act: A Multi-modal Dataset for Fine-Grained Driver Behavior Recognition in Autonomous Vehicles. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2801–2810. [Google Scholar]
- Massoz, Q.; Langohr, T.; Francois, C.; Verly, J.G. The ULg multimodality drowsiness database (called DROZY) and examples of use. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver Drowsiness Detection via a Hierarchical Temporal Deep Belief Network. In Proceedings of the Computer Vision—ACCV 2016 Workshops. Lecture Notes in Computer Science, Taipei, Taiwan, 20–24 November 2016; Volume 10118. [Google Scholar] [CrossRef]
- Schwarz, A.; Haurilet, M.; Martinez, M.; Stiefelhagen, R. DriveAHead—A Large-Scale Driver Head Pose Dataset. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HA, USA, 21–26 July 2017; Volume 2017, pp. 1165–1174. [Google Scholar] [CrossRef]
- Eraqi, H.M.; Abouelnaga, Y.; Saad, M.H.; Moustafa, M.N. Driver distraction identification with an ensemble of convolutional neural networks. J. Adv. Transp. 2019, 2019, 4125865. [Google Scholar] [CrossRef]
- Ortega, J.D.; Nieto, M.; Cañas, P.; Otaegui, O.; Salgado, L. A real-time software framework for driver monitoring systems: Software architecture and use cases. In Real-Time Image Processing and Deep Learning 2021; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2021; Volume 11736, p. 13. [Google Scholar] [CrossRef]
- Trivedi, M.M.; Gandhi, T.; McCall, J. Looking-in and looking-out of a vehicle: Computer-vision-based enhanced vehicle safety. IEEE Trans. Intell. Transp. Syst. 2007, 8, 108–120. [Google Scholar] [CrossRef] [Green Version]
- Fridman, L.; Ding, L.; Seaman, S.; Mehler, A.; Sipperley, A.; Pettinato, A.; Seppelt, B.D.; Angell, L.; Mehler, B.; Reimer, B.; et al. MIT Advanced Vehicle Technology Study: Large-Scale Naturalistic Driving Study of Driver Behavior and Interaction With Automation. IEEE Access 2019, 7, 102021–102038. [Google Scholar] [CrossRef]
- Garney, J. An Analysis of Throughput Characteristics of Universial Serial Bus. Technical Report. 1996. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.163.7407 (accessed on 3 February 2022).
- Sánchez-Carballido, S.; Senderos, O.; Nieto, M.; Otaegui, O. Semi-Automatic Cloud-Native Video Annotation for Autonomous Driving. Appl. Sci. 2020, 10, 4301. [Google Scholar] [CrossRef]
- Cañas, P.; Ortega, J.; Nieto, M.; Otaegui, O. Detection of Distraction-related Actions on DMD: An Image and a Video-based Approach Comparison. In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 5: VISAPP, Online Conference, 8–10 February 2021; pp. 458–465. [Google Scholar] [CrossRef]
- Nieto, M.; Senderos, O.; Otaegui, O. Boosting AI applications: Labeling format for complex datasets. SoftwareX 2021, 13, 100653. [Google Scholar] [CrossRef]
- Ortega, J.D.; Kose, N.; Cañas, P.; Chao, M.A.; Unnervik, A.; Nieto, M.; Otaegui, O.; Salgado, L. DMD: A Large-Scale Multi-modal Driver Monitoring Dataset for Attention and Alertness Analysis. In ECCV Workshops, Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Bartoli, A., Fusiello, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12538, pp. 387–405. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Drivers a | Views b | Size c | GT d | Streams | Scenarios | Usage |
|---|---|---|---|---|---|---|---|---|
| CVRR-Hands [48] | 2013 | 8 (1/7) | 1 | 7 k | Hands, Actions | RGB Depth | Car | Normal driving, Distraction |
| DrivFace [47] | 2016 | 4 (2/2) | 1 | 0.6 k | Face/Head | RGB | Car | Normal driving, Head pose |
| DROZY [51] | 2016 | 14 (11/3) | 1 | 7 h | Face/Head Physiological | IR | Laboratory | Drowsiness |
| NTHU-DDD [52] | 2017 | 36 (18/18) | 1 | 210 k | Actions | RGB IR | Simulator | Normal driving, Drowsiness |
| Pandora [49] | 2017 | 22 (10/12) | 1 | 250 k | Face/Head, Body | RGB Depth | Simulator | Head/Body pose |
| DriveAHead [53] | 2017 | 20 (4/16) | 1 | 10.5 h | Face/Head, Objects | Depth IR | Car | Normal driving, Head/Body pose |
| UTA-RLDD [46] | 2019 | 60 (9/51) | 1 | 30 h | Subjective KSS labels | RGB | Laboratory | Drowsiness |
| DD-Pose [38] | 2019 | 24 (6/21) | 2 | 6 h | Face/Head, Objects | RGB e Depth f IR f | Car | Normal driving, Head/Body pose |
| AUC-DD [54] | 2019 | 44 (15/29) | 1 | 144 k | Actions | RGB | Car | Normal driving, Distraction |
| Drive&Act [50] | 2019 | 15 (4/11) | 6 | 12 h | Hands/Body, Actions, Objects | RGB e Depth e IR | Car | Autonomous driving, Distraction |
| DMD (ours) | 2021 | 37 (10/27) | 3 | 41 h | Face/Head, Eyes/Gaze, Hands/Body, Actions, Objects | RGB Depth IR | Car, Simulator | Normal driving, Distraction, Drowsiness |
| Level | Labels |
|---|---|
| Camera Occlusion | - Face camera - Body camera - Hands camera |
| Gaze on Road | - Looking road - Not looking road |
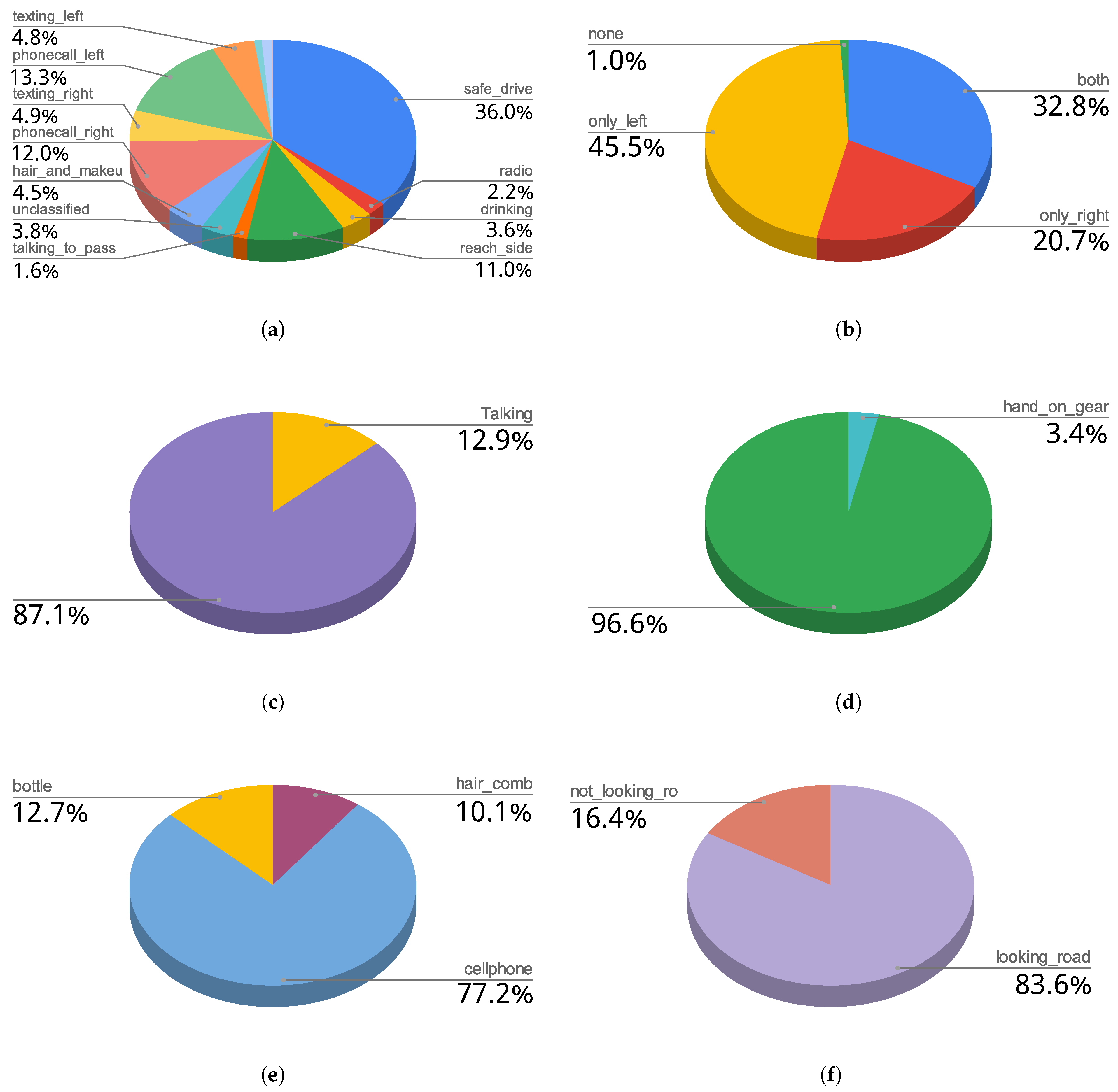
| Talking | - Talking |
| Hands Using Wheel | - Both - Only right - Only left - None |
| Hand on Gear | - Hand on gear |
| Objects in Scene | - Cellphone - Hair comb - Bottle |
| Driver Actions | - Safe drive - Texting right - Texting left - Phone call right - Phone call left - Radio - Drinking - Reach side - Hair and Makeup - Talking to passenger - Reach backseat - Change gear - Standstill/Waiting - Unclassified |
| Car Stopped | Car Driving | Simulator Driving |
|---|---|---|
| Safe driving | Safe driving | Safe driving |
| Reach object backseat | Operating the radio | Brush the hair |
| Reach object side | Drinking | Phone call—right hand |
| Brush the hair | Talk to passenger | Phone call—left hand |
| Phone call—right hand | Texting—right hand | |
| Phone call—left hand | Texting—left hand | |
| Texting—right hand | Drinking | |
| Texting—left hand |
| Car Stopped and Simulator Driving |
|---|
| Drive normally |
| Sleepy driving |
| Yawn without hand |
| Yawn with hand |
| Micro-sleep |
| Car–Simulator–Driving | |
|---|---|
| Gaze Zones | Hand Actions |
 | Both hands on (not moving) |
| Right hand on (not moving) | |
| Left hand on (not moving) | |
| Both hands off (not moving) | |
| Both hands on (moving) | |
| Right hand on (moving) | |
| Left hand on (moving) | |
| D415 | D435 | |
|---|---|---|
| Use Environment | Indoor/Outdoor | Indoor/Outdoor |
| Depth FOV () | ||
| Depth Resolution | Up to | Up to |
| Depth Frame Rate | Up to 90 FPS | Up to 90 FPS |
| RGB FOV () | ||
| RGB Resolution | Up to | Up to |
| RGB Frame Rate | 30 FPS | 30 FPS |
| Min. Depth Distance at Max Resolution | ∼45 cm | ∼28 cm |
| Ideal Range | 0.5 m to 3 m | 0.3 m to 3 m |
| RGB W × H × FPS (24 bits) | Depth W × H × FPS (16 bits) | IR W × H × FPS (8 bits) | Bandwidth 1 Camera (Mbps) | Bandwidth 3 Cameras (Mbps) |
|---|---|---|---|---|
| 1920 × 1080 × 30 | 1280 × 720 × 30 | 1280 × 720 × 30 | 2157 | 6470 |
| 1280 × 720 × 30 | 1280 × 720 × 30 | 1280 × 720 × 30 | 1327 | 3981 |
| 848 × 480 × 30 | 848 × 480 × 30 | 848 × 480 × 30 | 586 | 1758 |
| 848 × 480 × 60 | 848 × 480 × 60 | 848 × 480 × 60 | 1172 | 3517 |
| 640 × 480 × 30 | 640 × 480 × 30 | 640 × 480 × 30 | 442 | 1327 |
| 640 × 480 × 60 | 640 × 480 × 60 | 640 × 480 × 60 | 885 | 2654 |
| 640 × 360 × 90 | 640 × 480 × 90 | 640 × 480 × 90 | 1161 | 3484 |
| Session | TaTo Version | # Videos | Total Time (h:min:s) | Time/Video (h:min:s) | Improvement |
|---|---|---|---|---|---|
| s1 | V1 | 4 | 13:02:00 | 3:25:00 | 56.10% |
| V2 | 1 | 1:30:00 | 1:30:00 | ||
| s2 | V1 | 3 | 16:10:00 | 5:36:00 | 63.69% |
| V2 | 2 | 4:04:00 | 2:02:00 | ||
| s3 | V1 | 2 | 2:20:00 | 1:10:00 | 81.43% |
| V2 | 3 | 0:41:00 | 0:13:00 | ||
| s4 | V1 | 2 | 19:45:00 | 8:22:00 | 63.55% |
| V2 | 3 | 9:10:00 | 3:03:00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortega, J.D.; Cañas, P.N.; Nieto, M.; Otaegui, O.; Salgado, L. Challenges of Large-Scale Multi-Camera Datasets for Driver Monitoring Systems. Sensors 2022, 22, 2554. https://doi.org/10.3390/s22072554
Ortega JD, Cañas PN, Nieto M, Otaegui O, Salgado L. Challenges of Large-Scale Multi-Camera Datasets for Driver Monitoring Systems. Sensors. 2022; 22(7):2554. https://doi.org/10.3390/s22072554
Chicago/Turabian StyleOrtega, Juan Diego, Paola Natalia Cañas, Marcos Nieto, Oihana Otaegui, and Luis Salgado. 2022. "Challenges of Large-Scale Multi-Camera Datasets for Driver Monitoring Systems" Sensors 22, no. 7: 2554. https://doi.org/10.3390/s22072554
APA StyleOrtega, J. D., Cañas, P. N., Nieto, M., Otaegui, O., & Salgado, L. (2022). Challenges of Large-Scale Multi-Camera Datasets for Driver Monitoring Systems. Sensors, 22(7), 2554. https://doi.org/10.3390/s22072554