
Towards Enhancing Traffic Sign Recognition through Sliding Windows




Abstract
:1. Introduction
- a deep literature review about ML-based TSR;
- presentation of an approach based on sliding windows of frames to be processed either by meta-learners or LSTM;
- an experimental campaign that relies on heterogeneous and public datasets of traffic signs; and finally
- a discussion of results that clearly shows how a sliding window of at least two items, deep base-level classifiers and K-NN as stacking meta-learner allow achieving perfect TSR on all datasets considered in the study, dramatically improving the state of the art.
2. Background on Traffic Sign Recognition
2.1. Classifiers for TSR
2.2. Related Works on Single-Frame TSR
2.3. Background on Comparative Studies
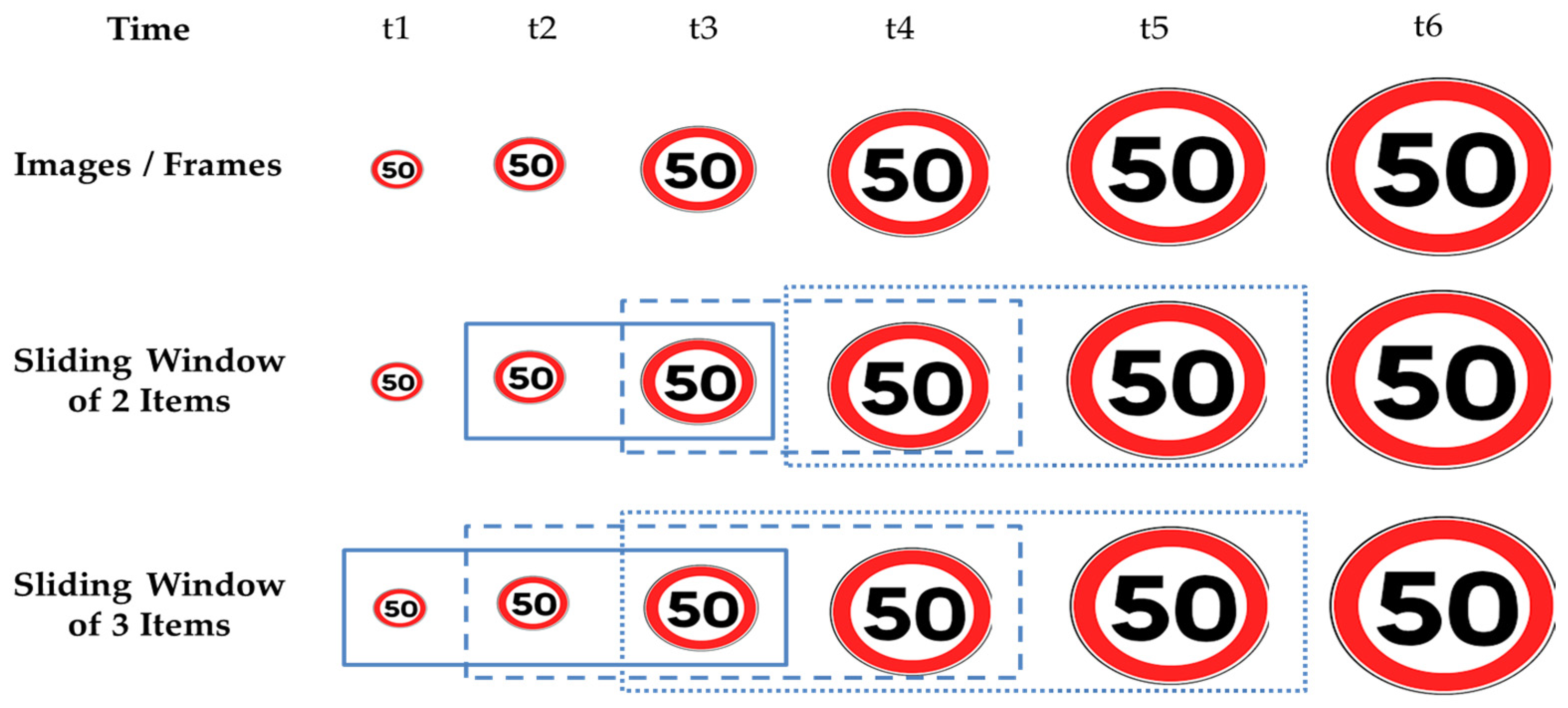
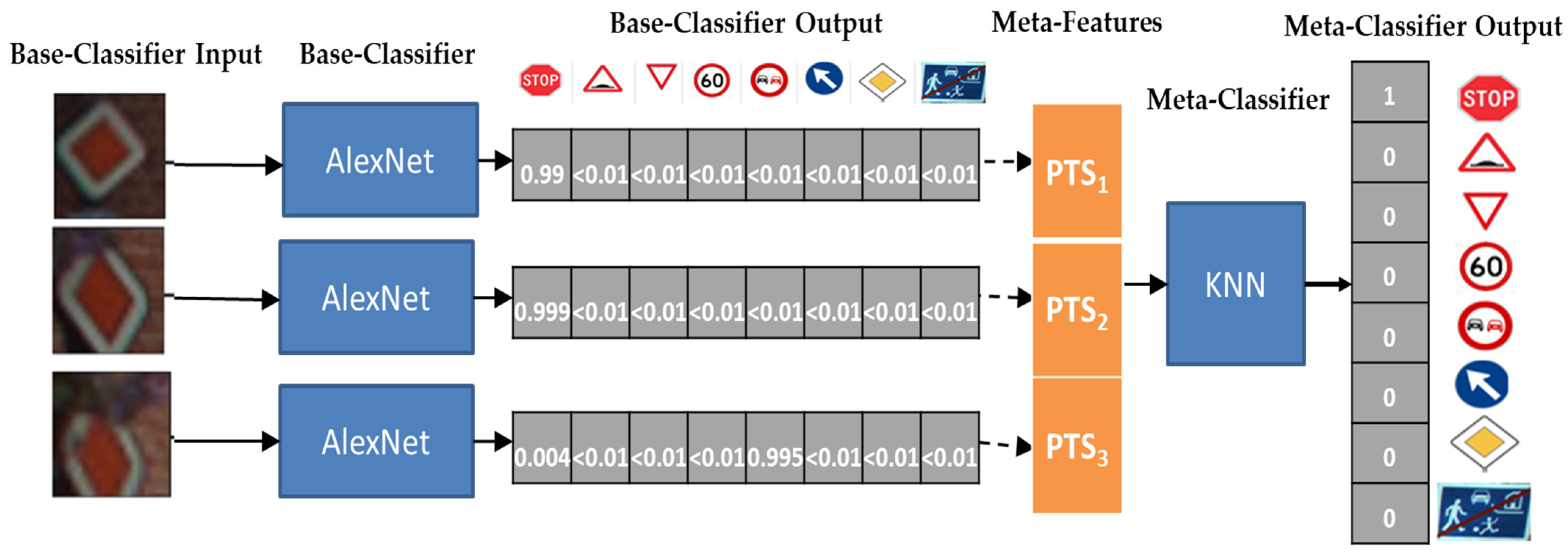
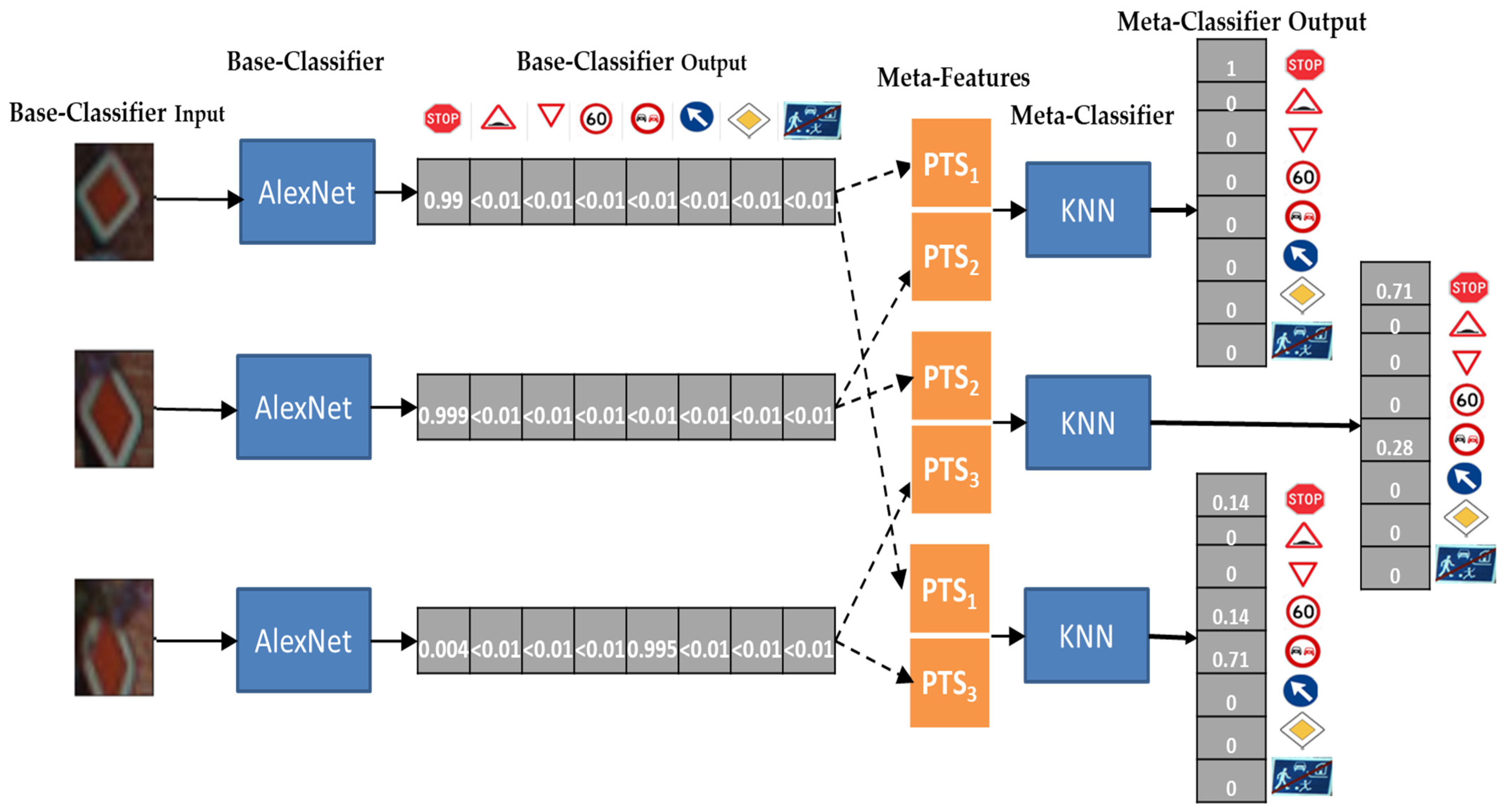
3. Sliding Windows to Improve TSR
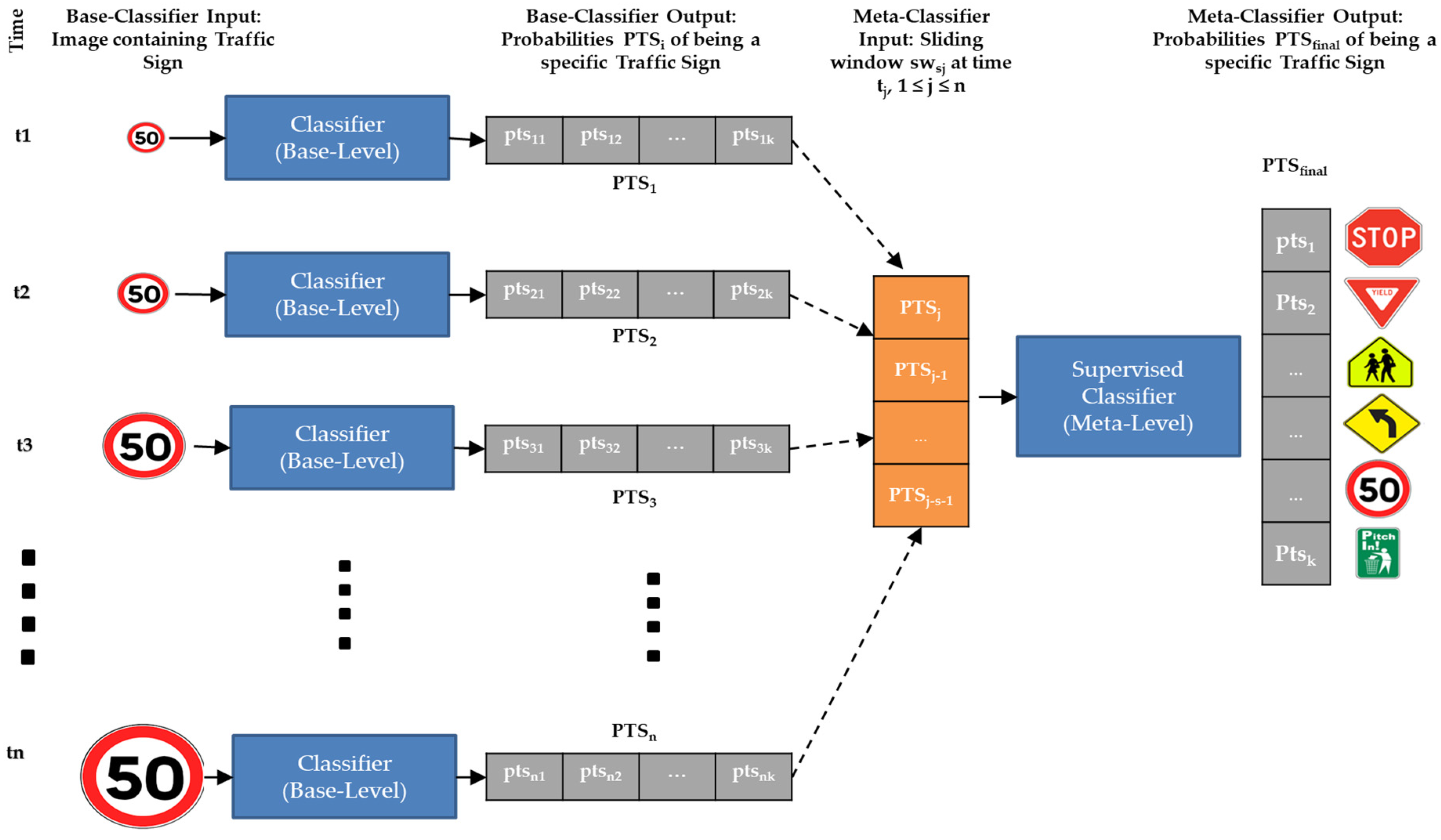
3.1. Sliding Windows and Meta-Learning
3.2. A Stacking Meta-Learner
3.3. Long Short-Term Memory Networks (LSTM)
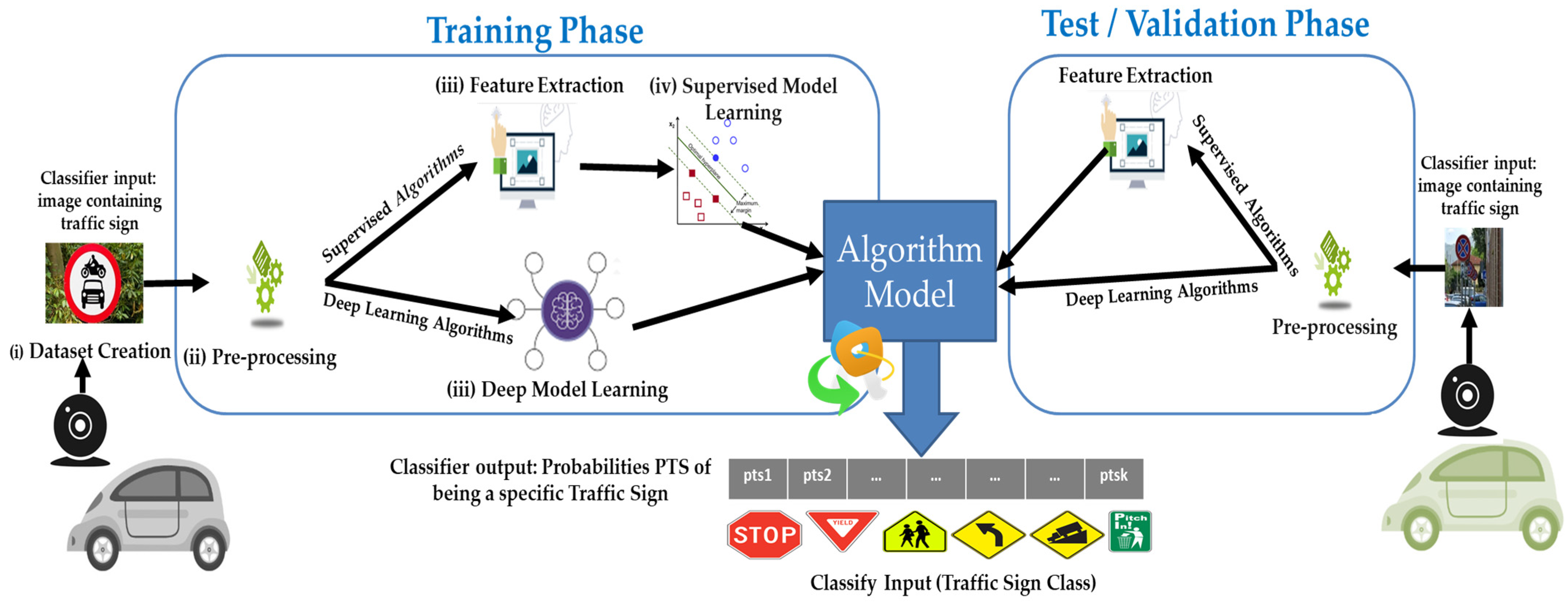
4. Methodology, Inputs and Experimental Setup
4.1. Methodology for a Fair Comparison of TSR Systems
- Datasets and Pre-processing. Images go through a pre-processing phase to resize them to the same scale and enhance the contrast between background and foreground through histogram equalization.
- Feature Extraction (Section 4.3). Then, each pre-processed image is analyzed to extract features: these will be used with traditional supervised classifiers, while deep learners will be directly fed with pre-processed images.
- Classification Metrics (Section 4.4). Before exercising classifiers, we select metrics to measure the classification capabilities of ML algorithms which apply both to single-frame classifiers and to others based on sliding windows.
- Single-Frame Classification. Both supervised (Section 4.5) classifiers and deep learners (Section 4.6) will be trained and tested independently, executing grid searches to identify proper values for hyper-parameters.
- Sliding Windows with Stacking Meta-Learners (Section 4.7). Results of single-frame classifiers will then be used to build Stacking learners as described in Section 3.2 and by adopting different meta-level classifiers.
- Sliding Windows with LSTM (Section 4.8). Furthermore, sliding windows will be used to exercise LSTM networks as described in Section 3.3.
4.2. TSR Datasets and Traffic Sign Categories
4.2.1. German Traffic Signs Recognition Benchmark Dataset
4.2.2. BelgiumTSC Dataset
4.2.3. Dataset of Italian Traffic Signs Dataset
4.3. Feature Descriptors
- Histogram of Oriented Gradients (HOG) mostly provides information about key points in images. The process partitions an image into small squares and computes the normalized HOG histogram for each key point in each square [17].
- Local Binary Patterns (LBP) encode local textures [16] by partitioning each image into non-overlapping cells. Then, LBP isolates local binary patterns and uses small gray-scale discrepancies to identify specific features. Its behavior is invariant to the monotonic transformation of grayscale.
- AlexNet Features (AFeat) are extracted through a pre-trained AlexNet [34], composed of five convolutional layers and three fully connected layers. Convolutional layers are basically extracting deep features from RGB images of size 227 × 227. We extract a feature vector of 4096 items by fetching data at the fully connected layer “fc7”.
- ResNet Features (RFeat) are extracted from a ResNet-18 [35], a convolutional neural network with 18 hidden layers. Convolutional layers are extracting deep features from RGB images of size 224 × 224 Similarly to AlexNet, we extract 512 features by extracting data at the global average pooling layer “pool5”.
4.4. Classification Metrics
4.5. Traditional Supervised Classifiers and Hyper-Parameters
- K Nearest Neighbors (K-NN) algorithm [13] classifies a data point based on the class of its neighbors, or rather other data points that have a small Euclidean Distance with respect to the novel data point. The size k of the neighborhood has a major impact on classification, and therefore, needs careful tuning, which is mostly achieved through grid or random searches.
- Support Vector Machines (SVMs) [14], instead, separate the input space through hyperplanes, whose shape is defined by a kernel. This allows performing either linear or non-linear (e.g., radial basis function RBF kernel) classification. When SVM is used for multi-class classification, the problem is divided into multiple binary classification problems [79].
- Decision Tree provides a branching classification of data and is widely used to approximate discrete functions [36]. The split of internal nodes is usually driven by the discriminative power of features, measured either with Gini or Entropy Gain. Training of decision trees employs a given number of iterations and a final pruning step to limit overfitting.
- Boosting (AdaBoostM2) [39] ensembles combine multiple (weak) learners to build a strong learner by weighting the results of individual weak learners. Those are created iteratively by building specialized decision stumps that focus on “hard” areas of input space.
- Linear Discriminant Analysis (LDA) is used to find out the linear combination of features that efficiently separates different classes by distributing samples into the same type of category [38]. This process uses a derivation of Fisher discriminant to fit multi-class problems.
- Random Forests [37] build ensembles of Decision Trees, each of them trained with a subset of the training set extracted by random sampling with replacement of examples.
- K-NN with different values of k, i.e., different odd values of k from 1 to 25. Additionally, we observe that DITS contains nine categories of traffic signs: therefore, we disregard the usage of k = 9 to further avoid ties.
- SVM: we used three different kernels: Linear, RBF and Polynomial (quadratic), leaving other parameters (e.g., nu) as default.
- Decision Tree: we used the default configuration of MATLAB which assigns MaxNumSplits = training sample size 1, with no depth limits on decision trees.
- Boosting: we created boosting ensembles with AdaBoostM2 by building 25, 50, 75, and 100 trees (decision stumps) independently.
- Random Forest: we build forests of 25, 50, 75, or 100 decision trees.
- LDA: we Trained LDA using different discriminants, namely: pseudo-linear, diag-linear, diag-quadratic, and pseudo-quadratic.
4.6. Deep Learners and Hyper-Parameters
- AlexNet [34] is composed of eight layers, i.e., five convolutional layers and three fully connected layers that were previously trained on the ImageNet database [80], which contains images of 227 × 227 pixels with RGB channels. The output of the last fully connected layer is provided to the SoftMax function, which provides the distribution of overall categories of images.
- InceptionV3 is a deep convolutional neural network built by 48 layers that were trained using the ImageNet database [80], which includes images (299 × 299 with RGB channels) belonging to 1000 categories. InceptionV3 builds on (i) the basic convolutional block, (ii) the Inception module and finally (iii) the classifier. A 1x1 convolutional kernel is used in the Inceptionv3 model to accelerate the training process by decreasing the number of feature channels; further speedup is achieved by partitioning large convolutions into small convolutions [40].
- MobileNet-v2 [41] embeds 53 layers trained on ImageNet database [80]. Differently from others, it can be considered a lightweight and efficient deep convolutional neural network with fewer parameters to tune for mobile and embedded computer vision applications. MobileNet-v2 embeds two types of blocks: the residual block and a downsizing block, with three layers each.
4.7. Stacking Meta-Level Learners
- Discrete Hidden Markov Model (DHMM) [43]. For each class, a separate Discrete HMM returns the probability of an image belonging to that class. The classification result of the frames within the sliding window is given as input to all three DHMMs. Each DHMM returns the likelihood of the sequence to a specific class. The higher the likelihood to a specific class is decided as a final label for that specific sequence.
- Supervised Classifiers in Section 4.5. These classifiers can be employed as meta-level learners as meta-data resembles a set of features coming from base-learning episodes.
- Majority Voting: no parameter is needed.
- Each DHMM model was trained with 500 iterations.
- Supervised Classifiers: we used the same parameter values we already presented in Section 4.5.
4.8. Long-Short Term Memory (LSTM) Networks
5. Results and Discussion
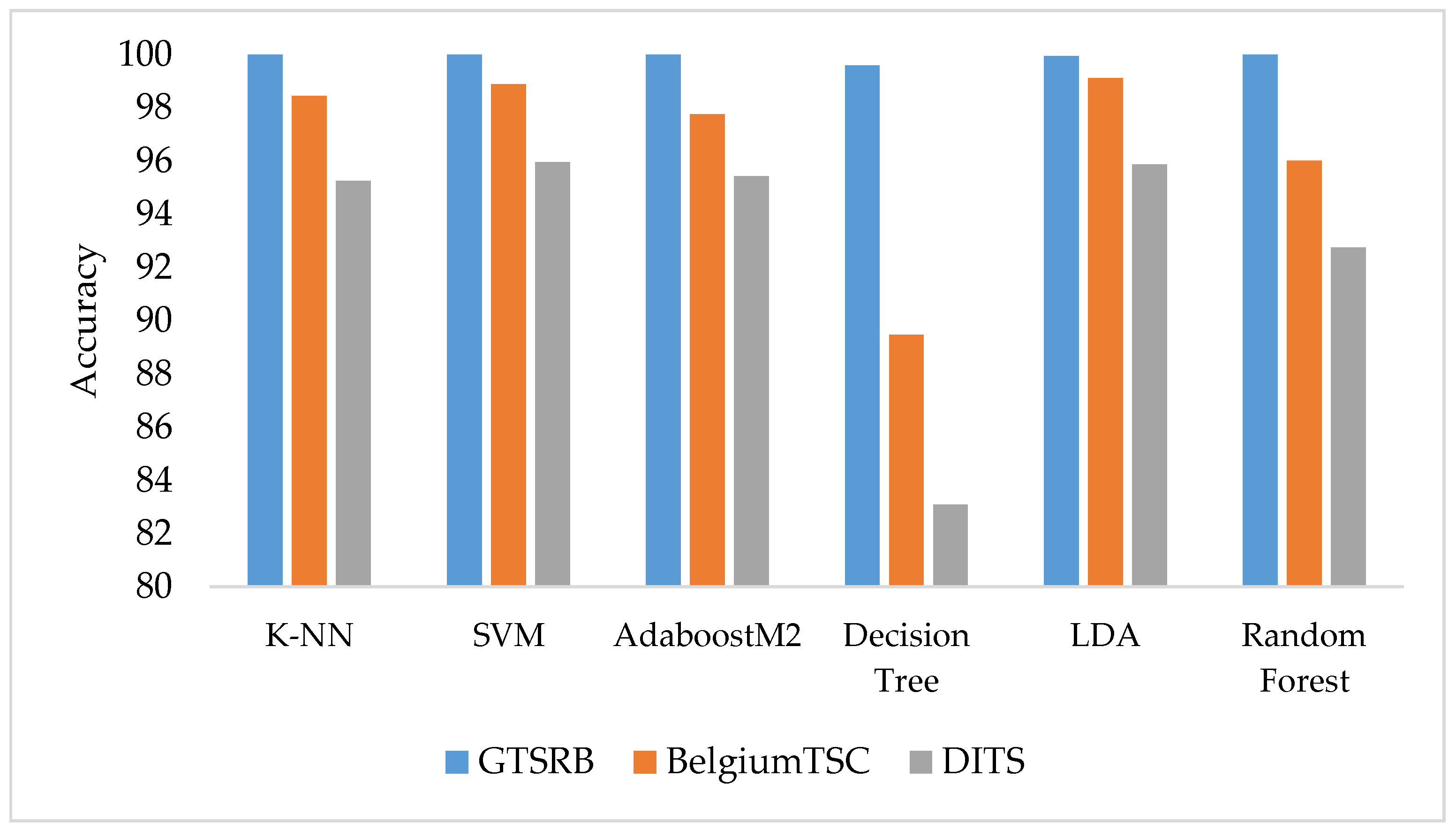
5.1. TSR Based on Single Frame
5.1.1. Highest Accuracy for Each Dataset
5.1.2. Impact of Feature Descriptors
5.1.3. Results of Deep Classifiers
5.2. TSR Based on Sliding Windows
5.2.1. Meta Learning with Traditional Base Classifiers
5.2.2. Meta Learning with Base-Level Deep Classifiers
5.2.3. Results of LSTM Networks
5.3. Comparing Sliding Windows and Single-Frame Classifiers
5.4. In-Depth View of BelgiumTSC
5.5. Timing Analysis
5.6. Comparison to the State of the Art TSR
6. Concluding Remarks
6.1. Limitations to Validity
6.1.1. Usage of Public Data
6.1.2. Parameters of Classifiers
6.2. Lessons Learned
- We observed that classifying images in the DITS dataset is harder than classifying the BelgiumTSC and GTSRB datasets as both base-level traditional supervised and deep classifiers’ performances are low comparatively. This is mostly due to the amount of training images and their quality, which is higher in the GTSRB compared to the other two datasets.
- Combining feature descriptors allows for improving classification performance. Particularly, we found that the {AFeat ∪ RFeat} descriptor allows traditional classifiers to maximize accuracy.
- Single-frame traditional supervised classifiers achieved perfect classification on the GTSRB dataset, while on the BelgiumTSC and DITS they show a non-zero amount of misclassifications. To the best of our knowledge, this result is due to the number of training samples, which is higher in the GTSRB with respect to the BelgiumTSC and DITS, and image quality, which again is better for the GTSRB. On the other hand, we achieved 100% accuracy by adopting a sliding windows based TSR strategy on all three considered datasets.
- There is no clear benefit in adopting deep classifiers over traditional classifiers for single-frame classification as they show similar accuracy scores. Additionally, both are outperformed, when using sliding windows for TSR.
- LSTM networks often, but not always, outperform single-frame classifiers but show lower accuracy than stacking meta-learners in orchestrating sliding windows.
- A stacking meta-learner with deep base-level classifiers and K-NN as meta-level classifier can perfectly classify traffic signs on all three datasets with any window size WS ≥ 2.
- For datasets that contain sequences (time-series) of images, enlarging the sliding window never decreases accuracy and, in most cases, raises the number of correct classifications.
- Deep learning models require more time compared to traditional supervised classifiers, especially because there are many layers, e.g., InceptionV3.
- Sliding windows based classification takes more time compared to single-frame classifiers but has remarkably higher classification performance across all three datasets.
- Overall, adopting classifiers that use a sliding window rather than a single-frame classifier allows reducing misclassifications, consequently raising accuracy.
6.3. Current and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Mathias, M.; Timofte, R.; Benenson, R.; Van Gool, L. Traffic Sign Recognition—How Far Are We from the Solution? In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Mammeri, A.; Boukerche, A.; Almulla, M. Design of Traffic Sign Detection, Recognition, and Transmission Systems for Smart Vehicles. IEEE Wirel. Commun. 2013, 20, 36–43. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z. Real-Time Traffic Sign Recognition Based on Efficient CNNs in the Wild. IEEE Trans. Intell. Transp. Syst. 2019, 20, 975–984. [Google Scholar] [CrossRef]
- Avizienis, A.; Laprie, J.C.; Randell, B.; Landwehr, C. Basic Concepts and Taxonomy of Dependable and Secure Computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- Carvalho Barbosa, R.; Shoaib Ayub, M.; Lopes Rosa, R.; Zegarra Rodríguez, D.; Wuttisittikulkij, L. Lightweight PVIDNet: A Priority Vehicles Detection Network Model Based on Deep Learning for Intelligent Traffic Lights. Sensors 2020, 20, 6218. [Google Scholar] [CrossRef]
- Application of Machine Learning Algorithms in Lane-Changing Model for Intelligent Vehicles Exiting to off-Ramp: Transportmetrica A: Transport Science: Volume 17, No 1. Available online: https://www.tandfonline.com/doi/abs/10.1080/23249935.2020.1746861 (accessed on 18 March 2022).
- Sasikala, G.; Ramesh Kumar, V. Development of Advanced Driver Assistance System Using Intelligent Surveillance. In International Conference on Computer Networks and Communication Technologies; Springer: Singapore, 2019; pp. 991–1003. [Google Scholar] [CrossRef]
- Jose, A.; Thodupunoori, H.; Nair, B.B. A Novel Traffic Sign Recognition System Combining Viola–Jones Framework and Deep Learning. In Soft Computing and Signal Processing; Springer: Singapore, 2019; pp. 507–517. [Google Scholar] [CrossRef]
- Kuo, C.Y.; Lu, Y.R.; Yang, S.M. On the Image Sensor Processing for Lane Detection and Control in Vehicle Lane Keeping Systems. Sensors 2019, 19, 1665. [Google Scholar] [CrossRef] [Green Version]
- McDonald, A.; Carney, C.; McGehee, D.V. Vehicle Owners’ Experiences with and Reactions to Advanced Driver Assistance Systems (Technical Report); AAA Foundation for Traffic Safety: Washington, DC, USA, 2018. [Google Scholar]
- Hurtado, S.; Chiasson, S. An Eye-Tracking Evaluation of Driver Distraction and Unfamiliar Road Signs. In Proceedings of the 8th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, (AutomotiveUI ’16), Ann Arbor, MI, USA, 24–26 October 2016; pp. 153–160. [Google Scholar]
- Wali, S. Comparative Survey on Traffic Sign Detection and Recognition: A Review. Prz. Elektrotech. 2015, 1, 40–44. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification. In On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A Comparison of Methods for Multiclass Support Vector Machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef] [Green Version]
- Wahyono; Jo, K.H. A Comparative Study of Classification Methods for Traffic Signs Recognition. In Proceedings of the 2014 IEEE International Conference on Industrial Technology (ICIT), Busan, Korea, 26 February 2014; pp. 614–619. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef]
- Yang, X.; Qu, Y.; Fang, S. Color Fused Multiple Features for Traffic Sign Recognition. In Proceedings of the 4th International Conference on Internet Multimedia Computing and Service, Wuhan, China, 9–11 September 2012; pp. 84–87. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Manisha, U.K.D.N.; Liyanage, S.R. An Online Traffic Sign Recognition System for Intelligent Driver Assistance. In Proceedings of the 2017 Seventeenth International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 6–9 September 2017; pp. 1–6. [Google Scholar]
- Matoš, I.; Krpić, Z.; Romić, K. The Speed Limit Road Signs Recognition Using Hough Transformation and Multi-Class Svm. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 89–94. [Google Scholar]
- Liu, C.; Li, S.; Chang, F.; Wang, Y. Machine Vision Based Traffic Sign Detection Methods: Review, Analyses and Perspectives. IEEE Access 2019, 7, 86578–86596. [Google Scholar] [CrossRef]
- Soni, D.; Chaurasiya, R.K.; Agrawal, S. Improving the Classification Accuracy of Accurate Traffic Sign Detection and Recognition System Using HOG and LBP Features and PCA-Based Dimension Reduction; Social Science Research Network: Rochester, NY, USA, 2019. [Google Scholar]
- Hasan, N.; Anzum, T.; Jahan, N. Traffic Sign Recognition System (TSRS): SVM and Convolutional Neural Network. In Inventive Communication and Computational Technologies; Springer: Singapore, 2021; pp. 69–79. [Google Scholar] [CrossRef]
- Rahmad, C.; Rahmah, I.F.; Asmara, R.A.; Adhisuwignjo, S. Indonesian Traffic Sign Detection and Recognition Using Color and Texture Feature Extraction and SVM Classifier. In Proceedings of the 2018 International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 50–55. [Google Scholar]
- Cao, J.; Song, C.; Peng, S.; Xiao, F.; Song, S. Improved Traffic Sign Detection and Recognition Algorithm for Intelligent Vehicles. Sensors 2019, 19, 4021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, W.; Li, D.; Zeng, S. Traffic Sign Recognition with a Small Convolutional Neural Network. IOP Conf. Ser. Mater. Sci. Eng. 2019, 688, 044034. [Google Scholar] [CrossRef]
- Atif, M.; Zoppi, T.; Gharib, M.; Bondavalli, A. Quantitative Comparison of Supervised Algorithms and Feature Sets for Traffic Sign Recognition. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, Virtual, 22–26 March 2021; Association for Computing Machinery: Gwangju, Korea, 2021; pp. 174–177. [Google Scholar] [CrossRef]
- Vilalta, R.; Drissi, Y. A Perspective View and Survey of Meta-Learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. The German Traffic Sign Recognition Benchmark: A Multi-Class Classification Competition. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1453–1460. [Google Scholar]
- Timofte, R.; Zimmermann, K.; Van Gool, L. Multi-View Traffic Sign Detection, Recognition, and 3D Localisation. Mach. Vis. Appl. 2014, 25, 633–647. [Google Scholar] [CrossRef]
- Youssef, A.; Albani, D.; Nardi, D.; Bloisi, D.D. Fast Traffic Sign Recognition Using Color Segmentation and Deep Convolutional Networks. In Advanced Concepts for Intelligent Vision Systems; Springer: Lecce, Italy, 2016; pp. 205–216. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Carbonell, J.G.; Michalski, R.S.; Mitchell, T.M. 1—An Overview of Machine Learning. In Machine Learning; Michalski, R.S., Carbonell, J.G., Mitchell, T.M., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1983; pp. 3–23. ISBN 978-0-08-051054-5. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Freund, Y. A More Robust Boosting Algorithm. arXiv 2009, arXiv:0905.2138. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Lam, L.; Suen, S.Y. Application of Majority Voting to Pattern Recognition: An Analysis of Its Behavior and Performance. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 1997, 27, 553–568. [Google Scholar] [CrossRef] [Green Version]
- Yasuda, H.; Takahashi, K.; Matsumoto, T. A Discrete Hmm for Online Handwriting Recognition. Int. J. Pattern Recognit. Artif. Intell. 2000, 14, 675–688. [Google Scholar] [CrossRef]
- Huang, Z.; Yu, Y.; Gu, J. A Novel Method for Traffic Sign Recognition Based on Extreme Learning Machine. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; pp. 1451–1456. [Google Scholar]
- Agrawal, S.; Chaurasiya, R.K. Ensemble of SVM for Accurate Traffic Sign Detection and Recognition. In Proceedings of the International Conference on Graphics and Signal Processing, Singapore, 24–27 June 2017; pp. 10–15. [Google Scholar]
- Myint, T.; Thida, L. Real-Time Myanmar Traffic Sign Recognition System Using HOG and SVM. Int. J. Trend Sci. Res. Dev. 2019, 3, 2367–2371. [Google Scholar] [CrossRef]
- Abedin, M.Z.; Dhar, P.; Deb, K. Traffic Sign Recognition Using SURF: Speeded up Robust Feature Descriptor and Artificial Neural Network Classifier. In Proceedings of the 2016 9th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 20–22 December 2016; pp. 198–201. [Google Scholar]
- Farag, W. Traffic Signs Classification by Deep Learning for Advanced Driving Assistance Systems. Intell. Decis. Technol. 2019, 13, 305–314. [Google Scholar] [CrossRef]
- Kamal, U.; Tonmoy, T.I.; Das, S.; Hasan, M.K. Automatic Traffic Sign Detection and Recognition Using SegU-Net and a Modified Tversky Loss Function With L1-Constraint. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1467–1479. [Google Scholar] [CrossRef]
- Liu, C.; Chang, F.; Chen, Z.; Liu, D. Fast Traffic Sign Recognition via High-Contrast Region Extraction and Extended Sparse Representation. IEEE Trans. Intell. Transp. Syst. 2016, 17, 79–92. [Google Scholar] [CrossRef]
- Lin, C.; Li, L.; Luo, W.; Wang, K.C.P.; Guo, J. Transfer Learning Based Traffic Sign Recognition Using Inception-v3 Model. Period. Polytech. Transp. Eng. 2019, 47, 242–250. [Google Scholar] [CrossRef] [Green Version]
- Zaki, P.S.; William, M.M.; Soliman, B.K.; Alexsan, K.G.; Khalil, K.; El-Moursy, M. Traffic Signs Detection and Recognition System Using Deep Learning. arXiv 2020, arXiv:2003.03256. [Google Scholar]
- Abdel-Salam, R.; Mostafa, R.; Abdel-Gawad, A.H. RIECNN: Real-Time Image Enhanced CNN for Traffic Sign Recognition. Neural Comput. Appl. 2022, 34, 6085–6096. [Google Scholar] [CrossRef]
- Mangshor, N.N.A.; Paudzi, N.P.A.M.; Ibrahim, S.; Sabri, N. A Real-Time Malaysian Traffic Sign Recognition Using YOLO Algorithm. In 12th National Technical Seminar on Unmanned System Technology 2020; Lecture Notes in Electrical Engineering; Springer: Singapore, 2022; pp. 283–293. [Google Scholar]
- Naim, S.; Moumkine, N. LiteNet: A Novel Approach for Traffic Sign Classification Using a Light Architecture. In WITS 2020, Proceedings of the 6th International Conference on Wireless Technologies, Embedded, and Intelligent Systems; Springer: Singapore, 2022; pp. 37–47. [Google Scholar]
- Nartey, O.T.; Yang, G.; Asare, S.K.; Wu, J.; Frempong, L.N. Robust Semi-Supervised Traffic Sign Recognition via Self-Training and Weakly-Supervised Learning. Sensors 2020, 20, 2684. [Google Scholar] [CrossRef]
- Vennelakanti, A.; Shreya, S.; Rajendran, R.; Sarkar, D.; Muddegowda, D.; Hanagal, P. Traffic Sign Detection and Recognition Using a CNN Ensemble. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–4. [Google Scholar]
- Lu, X.; Wang, Y.; Zhou, X.; Zhang, Z.; Ling, Z. Traffic Sign Recognition via Multi-Modal Tree-Structure Embedded Multi-Task Learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 960–972. [Google Scholar] [CrossRef]
- Bi, Z.; Yu, L.; Gao, H.; Zhou, P.; Yao, H. Improved VGG Model-Based Efficient Traffic Sign Recognition for Safe Driving in 5G Scenarios. Int. J. Mach. Learn. Cybern. 2021, 12, 3069–3080. [Google Scholar] [CrossRef]
- Bayoudh, K.; Hamdaoui, F.; Mtibaa, A. Transfer Learning Based Hybrid 2D–3D CNN for Traffic Sign Recognition and Semantic Road Detection Applied in Advanced Driver Assistance Systems. Appl. Intell. 2021, 51, 124–142. [Google Scholar] [CrossRef]
- Sermanet, P.; LeCun, Y. Traffic Sign Recognition with Multi-Scale Convolutional Networks. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2809–2813. [Google Scholar]
- Yang, Y.; Luo, H.; Xu, H.; Wu, F. Towards Real-Time Traffic Sign Detection and Classification. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2022–2031. [Google Scholar] [CrossRef]
- Islam, K.T.; Raj, R.G. Real-Time (Vision-Based) Road Sign Recognition Using an Artificial Neural Network. Sensors 2017, 17, 853. [Google Scholar] [CrossRef] [PubMed]
- Luo, H.; Yang, Y.; Tong, B.; Wu, F.; Fan, B. Traffic Sign Recognition Using a Multi-Task Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1100–1111. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental Framework for Video-Based Traffic Sign Detection, Tracking, and Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Park, J.; Lee, K.; Kim, H.Y. Recognition Assistant Framework Based on Deep Learning for Autonomous Driving: Restoring Damaged Road Sign Information; Social Science Research Network: Rochester, NY, USA, 2022. [Google Scholar]
- Zakir Hussain, K.M.; Kattigenahally, K.N.; Nikitha, S.; Jena, P.P.; Harshalatha, Y. Traffic Symbol Detection and Recognition System. In Emerging Research in Computing, Information, Communication and Applications; Springer: Singapore, 2022; pp. 885–897. [Google Scholar]
- Lahmyed, R.; Ansari, M.E.; Kerkaou, Z. Automatic Road Sign Detection and Recognition Based on Neural Network. Soft Comput. 2022, 26, 1743–1764. [Google Scholar] [CrossRef]
- Gautam, S.; Kumar, A. Automatic Traffic Light Detection for Self-Driving Cars Using Transfer Learning. In Intelligent Sustainable Systems; Springer: Singapore, 2022; pp. 597–606. [Google Scholar]
- Schuszter, I.C. A Comparative Study of Machine Learning Methods for Traffic Sign Recognition. In Proceedings of the 2017 19th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 21–24 September 2017; pp. 389–392. [Google Scholar]
- Brazdil, P.; Carrier, C.G.; Soares, C.; Vilalta, R. Metalearning: Applications to Data Mining; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; ISBN 978-3-540-73262-4. [Google Scholar]
- Vanschoren, J. Understanding Machine Learning Performance with Experiment Databases. Ph.D. Thesis, Katholieke Universiteit Leuven—Faculty of Engineering Address, Leuven, Belgium, May 2010. [Google Scholar]
- Wolpert, D.H. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Kong, D.; Han, H.; Zhao, Y. EA-LSTM: Evolutionary Attention-Based LSTM for Time Series Prediction. Knowl.-Based Syst. 2019, 181, 104785. [Google Scholar] [CrossRef] [Green Version]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Mortaz, E. Imbalance Accuracy Metric for Model Selection in Multi-Class Imbalance Classification Problems. Knowl.-Based Syst. 2020, 210, 106490. [Google Scholar] [CrossRef]
- Chamasemani, F.F.; Singh, Y.P. Multi-Class Support Vector Machine (SVM) Classifiers—An Application in Hypothyroid Detection and Classification. In Proceedings of the 2011 Sixth International Conference on Bio-Inspired Computing: Theories and Applications, Penang, Malaysia, 27–29 September 2011; pp. 351–356. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Popov, G.; Raynova, K. Diversity in Nature and Technology—Tool for Increase the Reliability of Systems. In Proceedings of the 2017 15th International Conference on Electrical Machines, Drives and Power Systems (ELMA), Sofia, Bulgaria, 1–3 June 2017; pp. 464–466. [Google Scholar]
- Shang, R.; Xu, K.; Shang, F.; Jiao, L. Sparse and Low-Redundant Subspace Learning-Based Dual-Graph Regularized Robust Feature Selection. Knowl.-Based Syst. 2020, 187, 104830. [Google Scholar] [CrossRef]
- Zeng, Y.; Xu, X.; Shen, D.; Fang, Y.; Xiao, Z. Traffic Sign Recognition Using Kernel Extreme Learning Machines With Deep Perceptual Features. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1647–1653. [Google Scholar] [CrossRef]
- Jiménez, Á.B.; Lázaro, J.L.; Dorronsoro, J.R. Finding Optimal Model Parameters by Discrete Grid Search. In Innovations in Hybrid Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2007; pp. 120–127. [Google Scholar] [CrossRef]
- Secci, F.; Ceccarelli, A. On Failures of RGB Cameras and Their Effects in Autonomous Driving Applications. In Proceedings of the 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE), Coimbra, Portugal, 12–15 October 2020; pp. 13–24. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train Images | Test Images | Images per Sequence | Training Sequences | Test Sequences |
|---|---|---|---|---|---|
| GTSRB | 39210 | 12570 | 30 | 1307 | 419 |
| DITS | 7500 | 1159 | 15 | 500 | 123 |
| BelgiumTSC | 4581 | 2505 | 3 | 1527 | 835 |
| Category | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Traffic Signs |  |  |  |  |  |  |  |  |  |
| GTSRB |  |  |  |  |  |  |  |  |  |
| BelgiumTSC |  |  | |||||||
| DITS |  |  |
| Feature Descriptor (s) | GTSRB | DITS | BelgiumTSC |
|---|---|---|---|
| AFeat | 100.00 | 95.51 | 98.84 |
| RFeat | 100.00 | 94.13 | 97.76 |
| LBP | 100.00 | 79.98 | 93.49 |
| HOG | 100.00 | 87.92 | 96.24 |
| HOG ∪ LBP | 100.00 | 88.26 | 96.56 |
| AFeat ∪ RFeat | 100.00 | 95.94 | 99.12 |
| AFeat ∪ HOG | 100.00 | 95.68 | 98.96 |
| AFeat ∪ LBP | 100.00 | 95.85 | 98.96 |
| RFeat ∪ HOG | 100.00 | 95.51 | 98.72 |
| RFeat ∪ LBP | 100.00 | 95.85 | 98.80 |
| AFeat ∪ HOG ∪ LBP | 100.00 | 95.42 | 98.88 |
| RFeat ∪ HOG ∪ LBP | 100.00 | 95.34 | 98.84 |
| InceptionV3 | MobileNet-v2 | AlexNet | ||||
|---|---|---|---|---|---|---|
| LR | Acc | LR | Acc | LR | Acc | |
| GTSRB | 0.01 | 96.62 | 0.01 | 96.11 | 0.0001 | 95.98 |
| 0.05 | 93.56 | 0.05 | 93.38 | 0.0005 | 94.92 | |
| 0.001 | 96.95 | 0.001 | 99.35 | 0.00001 | 94.86 | |
| 0.005 | 97.06 | 0.005 | 96.42 | 0.00005 | 95.64 | |
| 0.0001 | 96.81 | 0.0001 | 96.83 | 0.000001 | 95.83 | |
| 0.0005 | 98.03 | 0.0005 | 96.65 | 0.000005 | 96.07 | |
| DITS | 0.01 | 80.06 | 0.01 | 93.52 | 0.0001 | 87.40 |
| 0.05 | 80.67 | 0.05 | 85.93 | 0.0005 | 86.45 | |
| 0.001 | 88.17 | 0.001 | 94.99 | 0.00001 | 95.51 | |
| 0.005 | 84.98 | 0.005 | 88.78 | 0.00005 | 92.06 | |
| 0.0001 | 96.03 | 0.0001 | 95.77 | 0.000001 | 92.23 | |
| 0.0005 | 91.88 | 0.0005 | 95.94 | 0.000005 | 95.16 | |
| BelgiumTSC | 0.01 | 89.58 | 0.01 | 97.16 | 0.0001 | 99.24 |
| 0.05 | 14.97 | 0.05 | 94.49 | 0.0005 | 92.57 | |
| 0.001 | 98.12 | 0.001 | 98.72 | 0.00001 | 99.52 | |
| 0.005 | 14.97 | 0.005 | 94.73 | 0.00005 | 99.72 | |
| 0.0001 | 99.64 | 0.0001 | 99.24 | 0.000001 | 97.92 | |
| 0.0005 | 99.68 | 0.0005 | 98.96 | 0.000005 | 99.24 | |
| Dataset | Base-Level Classifier | Single Frame Accuracy | WS | Stacking Meta-Level Classifier | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Majority Voting | K-NN | SVM | LDA | Decision Tree | AdaBoostM2 | Random Forest | DHMM | ||||
| BelgiumTSC | KNN | 98.44 | 2 | 99.40 | 99.04 | 98.8 | 98.80 | 98.68 | 98.80 | 51.86 | 98.56 |
| SVM | 98.88 | 99.52 | 99.64 | 99.76 | 98.68 | 99.64 | 99.28 | 98.80 | 99.04 | ||
| LDA | 99.12 | 99.64 | 99.40 | 99.28 | 99.28 | 98.32 | 98.92 | 97.84 | 99.40 | ||
| KNN | 98.44 | 3 | 99.40 | 99.40 | 99.04 | 98.92 | 98.44 | 98.32 | 63.47 | 98.20 | |
| SVM | 98.88 | 99.52 | 99.52 | 99.64 | 99.40 | 98.56 | 14.97 | 99.28 | 98.80 | ||
| LDA | 99.12 | 99.64 | 99.64 | 99.40 | 98.2 | 99.28 | 97.96 | 98.32 | 98.80 | ||
| DITS | KNN | 95.25 | 2 | 97.56 | 97.56 | 97.56 | 96.75 | 97.56 | 97.56 | 82.93 | 96.75 |
| SVM | 95.94 | 96.75 | 97.56 | 98.37 | 97.56 | 95.12 | 31.71 | 95.12 | 95.93 | ||
| LDA | 95.85 | 98.37 | 98.37 | 97.56 | 97.56 | 98.37 | 95.93 | 96.75 | 96.75 | ||
| KNN | 95.25 | 3 | 99.00 | 99.00 | 99.00 | 99.00 | 99.00 | 99.00 | 85.00 | 98.00 | |
| SVM | 95.94 | 99.00 | 100.00 | 99.00 | 99.00 | 97.00 | 36.00 | 97.00 | 96.00 | ||
| LDA | 95.85 | 99.00 | 100.00 | 98.00 | 100.00 | 99.00 | 98.00 | 99.00 | 98.00 | ||
| Dataset | Base-Level Classifier | Single Frame Accuracy | WS | Majority Voting | K-NN | SVM | LDA | Decision Tree | AdaBoostM2 | Random Forest | DHMM |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BelgiumTSC | AlexNet | 99.72 | 2 | 99.88 | 100.00 | 99.64 | 99.88 | 99.88 | 99.40 | 99.16 | 99.76 |
| InceptionV3 | 99.68 | 99.88 | 99.88 | 99.64 | 99.88 | 99.52 | 99.88 | 99.64 | 99.64 | ||
| MobileNetv2 | 99.24 | 99.52 | 99.88 | 99.64 | 99.04 | 99.64 | 99.52 | 98.68 | 99.64 | ||
| AlexNet | 99.72 | 3 | 100.00 | 100.00 | 99.28 | 99.88 | 99.88 | 99.76 | 99.76 | 99.28 | |
| InceptionV3 | 99.68 | 99.88 | 99.88 | 99.40 | 99.52 | 99.40 | 14.97 | 99.76 | 99.52 | ||
| MobileNetv2 | 99.24 | 99.88 | 99.88 | 98.80 | 99.16 | 99.40 | 14.97 | 99.76 | 99.52 | ||
| DITS | AlexNet | 95.51 | 2 | 96.75 | 97.56 | 97.56 | 97.56 | 96.74 | 96.74 | 96.74 | 98.37 |
| InceptionV3 | 96.03 | 98.37 | 100.00 | 97.56 | 98.37 | 98.37 | 96.74 | 95.93 | 99.19 | ||
| MobileNetv2 | 95.94 | 97.56 | 99.18 | 99.18 | 99.18 | 99.18 | 100.00 | 98.37 | 99.19 | ||
| AlexNet | 95.51 | 3 | 97.00 | 99.00 | 99.00 | 99.00 | 99.00 | 99.00 | 99.00 | 99.00 | |
| InceptionV3 | 96.03 | 98.00 | 100.00 | 99.00 | 98.00 | 99.00 | 100.00 | 99.00 | 98.00 | ||
| MobileNetv2 | 95.94 | 98.00 | 100.00 | 99.00 | 100.00 | 99.00 | 100.00 | 100.00 | 100.00 | ||
| GTSRB | AlexNet | 96.07 | 2 | 97.37 | 100.00 | 99.76 | 100.00 | 98.09 | 100.00 | 100.00 | 98.09 |
| InceptionV3 | 98.03 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 99.76 | ||
| MobileNetv2 | 99.35 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | ||
| AlexNet | 96.07 | 3 | 0.9737 | 100.00 | 99.76 | 100.00 | 98.09 | 100.00 | 100.00 | 98.09 | |
| InceptionV3 | 98.03 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 99.76 | ||
| MobileNetv2 | 99.35 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Dataset | WS | Optimizer | ||
|---|---|---|---|---|
| adam | sgdm | rmsprop | ||
| DITS | 2 | 97.56 | 97.56 | 96.74 |
| DITS | 3 | 99.00 | 99.00 | 98.00 |
| BelgiumTSC | 2 | 99.40 | 99.16 | 99.16 |
| BelgiumTSC | 3 | 99.64 | 99.28 | 99.40 |
| Feature Extractor | Time in Seconds Avg ± St. Dev | Individual Classifier | Time in Seconds Avg ± St. Dev | TSR Strategy | Average Time in Seconds | |
|---|---|---|---|---|---|---|
| (Sequential) | (Parallel) | |||||
| HOG | 0.0204 ± 0.0024 | SVM | 0.1344 ± 0.0364 | Single-frame (AFeat ∪ RFeat + SVM) | 0.1974 | 0.1756 |
| LBP | 0.0196 ± 0.0023 | KNN | 0.1205 ± 0.0302 | Single-frame (InceptionV3) | 1.4205 | 1.4205 |
| AFeat | 0.0218 ± 0.0023 | LDA | 0.1034 ± 0.0256 | Stacking with WS = 2 (AFeat ∪ RFeat + SVM + KNN) | 0.4036 | 0.3636 |
| RFeat | 0.0412 ±0.0034 | InceptionV3 | 1.4205 ± 0.6613 | |||
| MobileNetV2 | 0.6391 ± 0.2180 | Stacking with WS = 2 (AlexNet + KNN) | 0.5621 | 0.5621 | ||
| AlexNet | 0.3749 ± 0.1407 | Stacking with WS = 2 (InceptionV3 + KNN) | 1.6085 | 1.6085 | ||
| Studies | Sequences of Frames | Achieved Accuracy (%) | ||
|---|---|---|---|---|
| GTSRB | BelgiumTSC | DITS | ||
| Stallkamp et al. [31] | No | 98.98 | ||
| Atif et al. [29] | No | 100.00 | 99.80 | 99.31 |
| Agrawal et al. [45] | No | * 77.43 | ||
| Youssef et al. [33] | No | 95.00 | 98.20 | |
| Mathias et al. [1] | No | 97.83 | ||
| Huang et al. [44] | No | * 95.56 | ||
| Lin et al. [51] | No | * 99.18 | ||
| Li et al. [28] | No | 97.40 | 98.10 | |
| Li and Wang [3] | No | 99.66 | ||
| Zeng et al. [83] | No | 95.40 | ||
| Our Approach | No | 100.00 | 99.72 | 96.03 |
| Yes | 100.00 | 100.00 | 100.00 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atif, M.; Zoppi, T.; Gharib, M.; Bondavalli, A. Towards Enhancing Traffic Sign Recognition through Sliding Windows. Sensors 2022, 22, 2683. https://doi.org/10.3390/s22072683
Atif M, Zoppi T, Gharib M, Bondavalli A. Towards Enhancing Traffic Sign Recognition through Sliding Windows. Sensors. 2022; 22(7):2683. https://doi.org/10.3390/s22072683
Chicago/Turabian StyleAtif, Muhammad, Tommaso Zoppi, Mohamad Gharib, and Andrea Bondavalli. 2022. "Towards Enhancing Traffic Sign Recognition through Sliding Windows" Sensors 22, no. 7: 2683. https://doi.org/10.3390/s22072683
APA StyleAtif, M., Zoppi, T., Gharib, M., & Bondavalli, A. (2022). Towards Enhancing Traffic Sign Recognition through Sliding Windows. Sensors, 22(7), 2683. https://doi.org/10.3390/s22072683