
Early Detection of Grapevine (Vitis vinifera) Downy Mildew (Peronospora) and Diurnal Variations Using Thermal Imaging



Abstract
:1. Introduction
2. Materials and Methods
2.1. Plant Material and Experimental Design
- For each stem, the second unfolded leaf from the apex was selected for inoculation and was marked with a color clip or aluminum foil (2–6 leaves in each plant);
- On the first day of the campaign, images of the healthy leaves were acquired;
- The leaves were spray-inoculated with concentration of P. viticola onto the lower surface using a hand sprayer;
- The inoculated plants were incubated in a high humidity chamber under optimal environmental conditions in order to allow the pathogen to infect the host tissue and cause DM to develop;
- In the period of 1–7 days after inoculation, images of healthy and infected leaves were acquired. Images were only acquired on sunny days with a clear sky, meaning that, if weather conditions were not suitable on a particular date, images were not acquired. Table 1 depicts the dates when image acquisition was conducted for each campaign;
- After the last imaging day (day number 7), the leaves were placed in Petri dishes in order to evaluate the level of the developed disease, which was visually rated by an expert between 0 and 10 (0—healthy, 10—severe disease).
2.2. Thermal and RGB Image Acquisition
2.3. Datasets
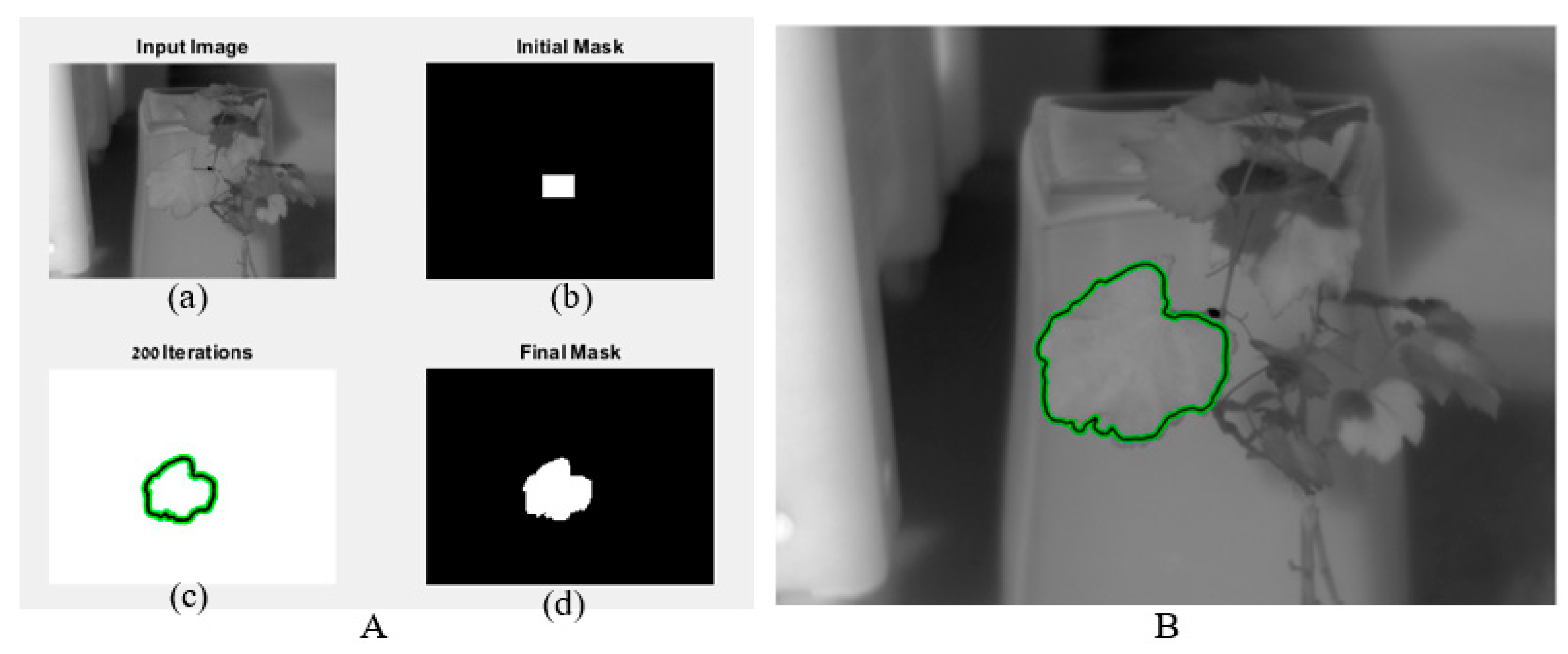
2.4. Algorithm for Leaf Delineation
2.5. Feature Extraction
2.6. Analysis
2.7. Classification Models
- Decision tree—one of the most widely used and practical methods for inference and classification. It has a fast prediction speed and is easy to interpret. This information gain method does not assume any statistical properties of the data itself (e.g., normal distribution) and, as such, it is best suited to this case where the statistical distribution is unknown. When building a decision tree, overfitting may arise, which is represented in the decision tree as a deep tree with many levels. To avoid over-fitting, the maximum number of splits has been limited [24,25].
- Logistic regression—a statistical model that uses a logistic function to model a binary dependent variable and is suitable in this case where there are two classes [26].
- Naïve Bayes (NB)—a statistical classification technique based on Bayes Theorem. A simple supervised learning algorithm which provides fast and accurate classification. The classifier assumes that the effect of a particular feature in a class is independent of other features. However, the algorithm still appears to work well when the independence assumption is not valid [27,28].
- Ensemble—The technique combines predictions from multiple machine-learning algorithms. In this work, the decision tree ensemble algorithm using the Boosting method was used. Boosting refers to a group of algorithms that trains weak learners sequentially, each trying to correct its predecessor [31].
2.8. Performance Measures
- True positive (TP): the leaf was infected, and it was classified as infected;
- False-negative (FN): the leaf was infected, but it was classified as healthy;
- True negative (TN): the leaf was healthy, and it was classified as healthy;
- False-positive (FP): the leaf was healthy, but it was classified as
- Recall (also TPR);
- False Positive Rate (FPR).
3. Results and Discussion
3.1. Classification of Healthy and Infected Leaves
3.1.1. Feature Selection
3.1.2. Classification Analysis
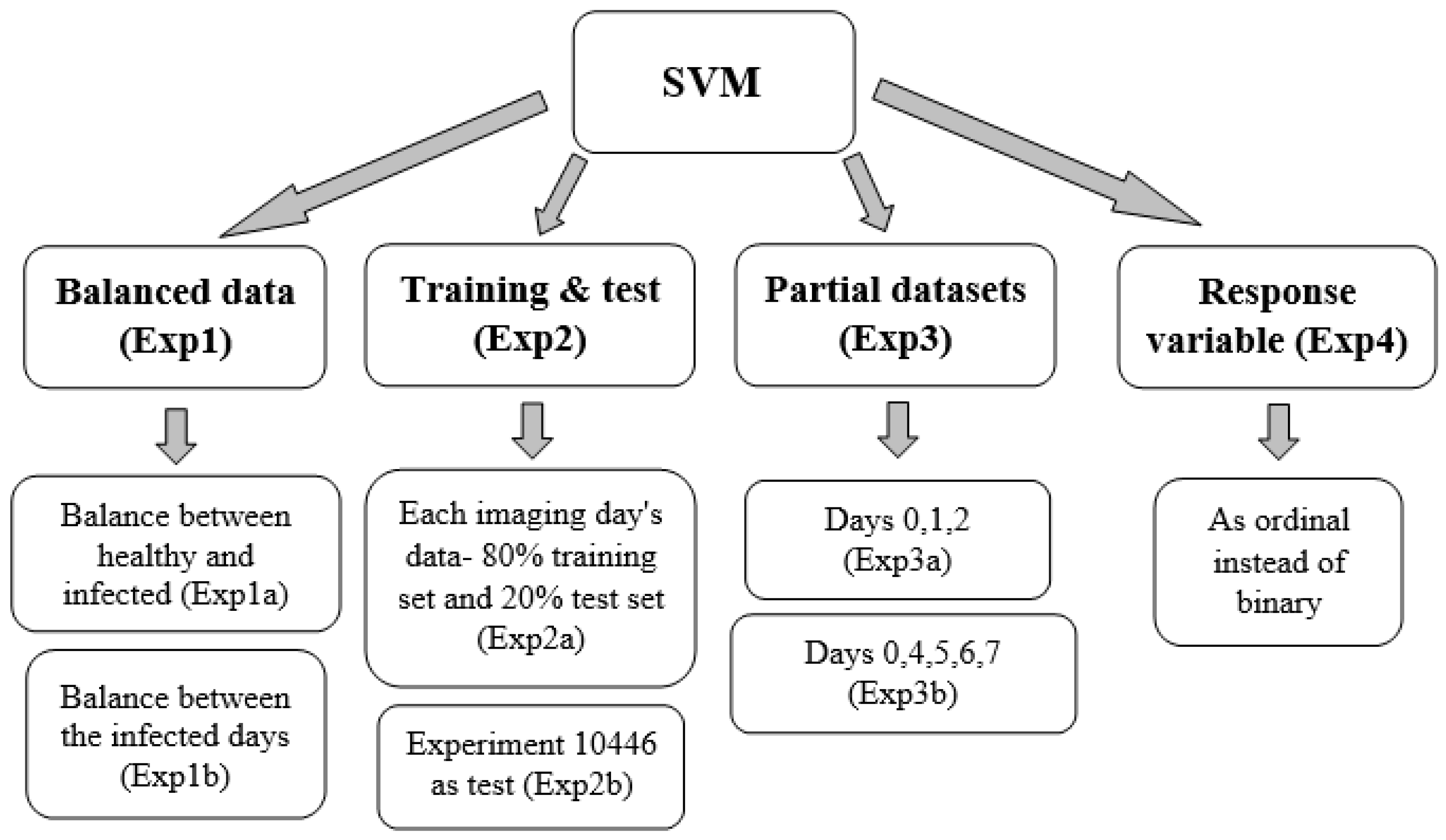
- Exp1
- To avoid bias, the dataset was balanced.
- By removing records from the healthy leaves, the samples number between the diseased and healthy leaves was balanced. The accuracy achieved with these balance results was 79.1%, the F1 score was 77.9%, and the AUC was 0.86. The model’s accuracy of the later days after inoculation improved (Table 8).
- Besides taking similar numbers of samples from healthy and infected leaves, the number of samples taken each day after inoculation was also balanced. The accuracy achieved was 73.8%, the F1 score was 71%, and the AUC was 0.756. This did not yield improvement in the model’s results, but the accuracy of the later days after inoculation improved greatly.
- Exp2
- To examine the effects of different climatic conditions on the results, the data were divided into different training and test sets.
- As the climatic conditions differed between imaging days, it was difficult to classify the data. Each imaging day’s data were split in two: 80% from the data for the training set and 20% from the data for the test set. The accuracy of the training set was 82.5%, with an F1 score of 78.3% and an AUC of 0.886. The test set accuracy was 76.5%, with an F1 score of 70.8% and an AUC of 0.827. Some days’ results improved, while others did not. The model’s performance did not improve.
- The test set included one specific experiment (No. 10446), and the training set included the rest. Experiment 10,446 included the days 0, 4, 5, 6, 7 after inoculation. Days 5, 6 were not included in any other experiments, so they appear only in the test set. The accuracy of the training set was 86.4%, the F1 score was 82%, and the AUC was 0.892. The test set accuracy was 57.8%, with an F1 score of 48.9% and an AUC of 0.593. The training and test sets were very different in their accuracy. Even on the days that appear in the training set (0, 4, 7), the results are poor. According to this analysis, it is not possible to classify healthy and DM infected from images acquired on an imaging day that is not included in the training set.
- Exp3
- Considering that the accuracy on days 1 and 2 after inoculation was greater than that of the other days, it was tested whether these days affect the prediction.
- The following hypothesis was tested: whether with a dataset of leaves from healthy and 1 and 2 days after inoculation, the accuracy of the prediction for these days still remains high (Table 9). The data for this analysis were balanced. The accuracy achieved was 91.9%, the F1 score was 92.1%, and the AUC was 0.961. The results showed that, even without the later days, the early days’ predictions held true very well.
- The same was done by using a dataset of days 0, 4, 5, 6, and 7 after inoculation. Here also the data were balanced (Table 10). The accuracy achieved was 79.1%, with an F1 score of 78.4% and an AUC of 0.856. The results showed that, when days 1 and 2 after inoculation were removed, the classification results of the later days improved.
- Exp4
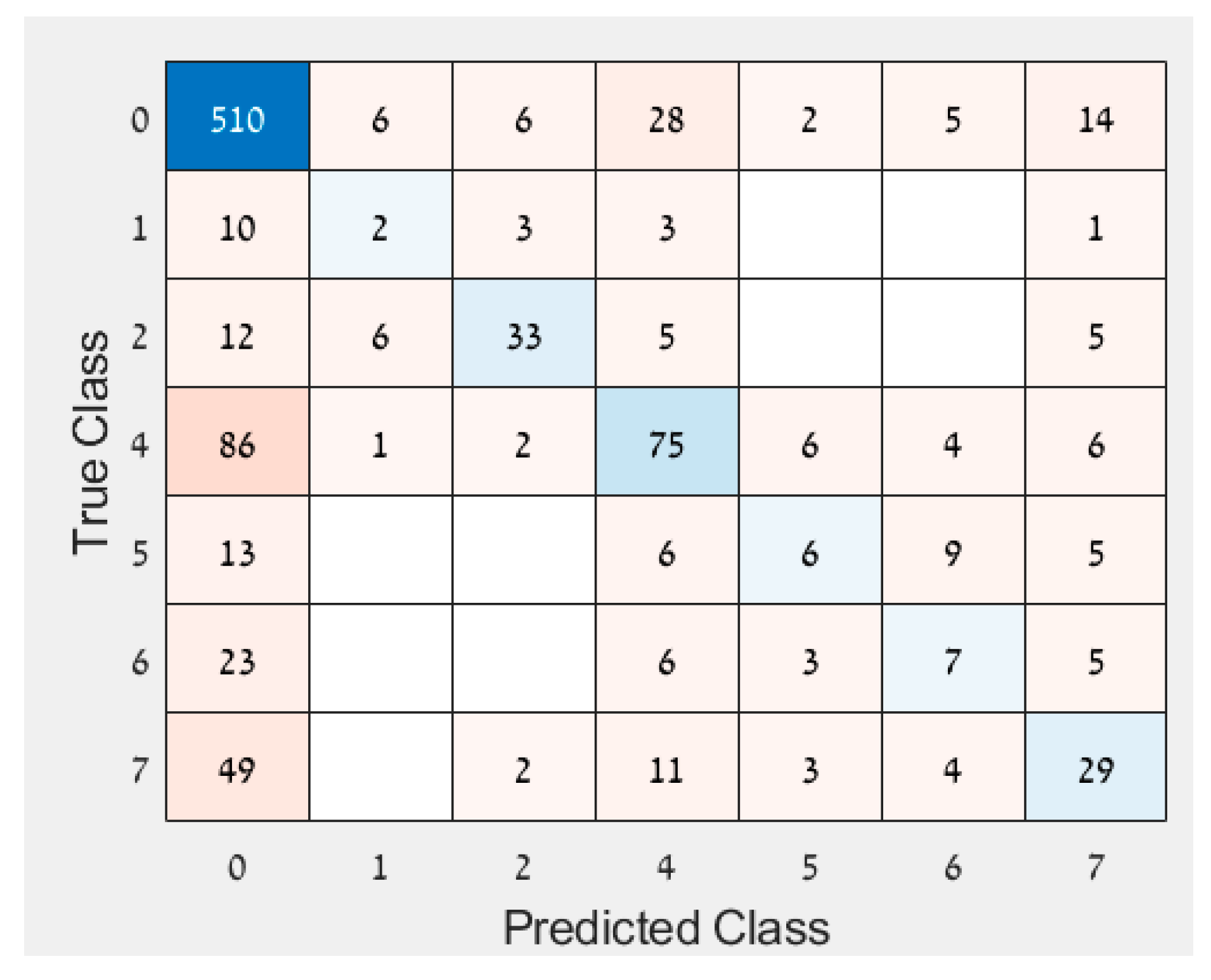
- Since the results of the other approaches varied each day after inoculation, an analysis was performed to examine if the response variable should be ordinal instead of binary. The assumption was that disease development increased every day, suggesting some kind of order as imaging days progressed. Therefore, an ordinal regression was performed on the imbalanced data. A new feature selection was conducted to accommodate for the new response variable and resulted in the following features: MTD, IQR, MAD, median, perc10, perc90, and CV. The accuracy of the ordinal classification was 65.4% with many observations classified as healthy even though they were infected (and were not classified as infected on another day, Figure 5). Since it does not matter which day after inoculation was classified, but whether the leaf was healthy or infected, the results were converted to binary so all days that were not classified as 0 (healthy) were deemed infected. This classification of the converted response variable resulted in an accuracy of 74.9%. The binary response variable performed better than both the ordinal response variable and the converted response variable and hence was selected.
3.2. Best Acquisition Time
4. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Savary, S.; Ficke, A.; Aubertot, J.N.; Hollier, C. Crop Losses Due to Diseases and Their Implications for Global Food Production Losses and Food Security. Food Secur. 2012, 4, 519–537. [Google Scholar] [CrossRef]
- Cui, S.; Ling, P.; Zhu, H.; Keener, H.M. Plant Pest Detection Using an Artificial Nose System: A Review. Sensors 2018, 18, 378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sankaran, S.; Mishra, A.; Ehsani, R.; Davis, C. A Review of Advanced Techniques for Detecting Plant Diseases. Comput. Electron. Agric. 2010, 72, 1–13. [Google Scholar] [CrossRef]
- Mahlein, A.K. Plant Disease Detection by Imaging Sensors- Parallels and Specific Demands for Precision Agriculture and Plant Phenotyping. Plant Dis. 2016, 100, 241–251. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mulla, D.J. Twenty Five Years of Remote Sensing in Precision Agriculture: Key Advances and Remaining. Knowl. Gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Khanal, S.; Fulton, J.; Shearer, S. An Overview of Current and Potential Applications of Thermal Remote Sensing in Precision Agriculture. Comput. Electron. Agric. 2017, 139, 22–32. [Google Scholar] [CrossRef]
- Falkenberg, N.R.; Piccinni, G.; Cothren, J.T.; Leskovar, D.I.; Rush, C.M. Remote Sensing of Biotic and Abiotic Stress for Irrigation Management of Cotton. Agric. Water Manag. 2007, 87, 23–31. [Google Scholar] [CrossRef]
- Kiefer, B.; Riemann, M.; Büche, C.; Kassemeyer, H.H.; Nick, P. The Host Guides Morphogenesis and Stomatal Targeting in the Grapevine Pathogen Plasmopara Viticola. Planta 2002, 215, 387–393. [Google Scholar] [CrossRef]
- Gessler, C.; Pertot, I.; Perazzolli, M. Plasmopara Viticola: A Review of Knowledge on Downy Mildew of Grapevine and Effective Disease Management. Phytopathol. Mediterr. 2011, 50, 3–44. [Google Scholar] [CrossRef]
- Kennelly, M.M.; Gadoury, D.M.; Wilcox, W.F.; Magarey, P.A.; Seem, R.C. Primary Infection, Lesion Productivity, and Survival of Sporangia in the Grapevine Downy Mildew Pathogen Plasmopara Viticola. Phytopathology 2007, 97, 512–522. [Google Scholar] [CrossRef] [Green Version]
- Calderón, R.; Montes-Borrego, M.; Landa, B.B.; Navas-Cortés, J.A.; Zarco-Tejada, P.J. Detection of Downy Mildew of Opium Poppy Using High-Resolution Multi-Spectral and Thermal Imagery Acquired with an Unmanned Aerial Vehicle. Precis. Agric. 2014, 15, 639–661. [Google Scholar] [CrossRef]
- Caro, S.G. Infection and Spread of Peronospora Sparsa on Rosa Sp.(Berk.)—A Microscopic and a Thermographic Approach. Ph.D. Thesis, University in Bonn, Bonn, Germany, 2014. [Google Scholar]
- Wen, D.M.; Chen, M.X.; Zhao, L.; Ji, T.; Li, M.; Yang, X.T. Use of Thermal Imaging and Fourier Transform Infrared Spectroscopy for the Pre-Symptomatic Detection of Cucumber Downy Mildew. Eur. J. Plant Pathol. 2019, 155, 405–416. [Google Scholar] [CrossRef]
- Grant, O.M.; Chaves, M.M.; Jones, H.G. Optimizing Thermal Imaging as a Technique for Detecting Stomatal Closure Induced by Drought Stress under Greenhouse Conditions. Physiol. Plant. 2006, 127, 507–518. [Google Scholar] [CrossRef]
- Alchanatis, V.; Cohen, Y.; Cohen, S.; Moller, M.; Sprinstin, M.; Meron, M.; Tsipris, J.; Saranga, Y.; Sela, E. Evaluation of Different Approaches for Estimating and Mapping Crop Water Status in Cotton with Thermal Imaging. Precis. Agric. 2010, 11, 27–41. [Google Scholar] [CrossRef]
- Cohen, B.; Edan, Y.; Levi, A.; Alchanatis, V. Early detection of grapevine downy mildew using thermal imaging. Precis. Agric. 2021, 33, 283–290. [Google Scholar] [CrossRef]
- Chinchor, N. MUC-4 Evaluation Metrics. In Proceedings of the 4th Message Understanding Conference MUC 1992, San Diego, CA, USA; 1992; pp. 22–29. [Google Scholar] [CrossRef] [Green Version]
- Chan, T.F.; Vese, L.A. Active Contours without Edges. IEEE Trans. Image Process. 2001, 10, 266–277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jones, H.G. Use of Infrared Thermometry for Estimation of Stomatal Conductance as a Possible Aid to Irrigation Scheduling. Agric. For. Meteorol. 1999, 95, 139–149. [Google Scholar] [CrossRef]
- Frank, K.A. Impact of a Confounding Variable on a Regression Coefficient. Sociol. Methods Res. 2000, 29, 147–194. [Google Scholar] [CrossRef]
- Lemeshow, S.; Hosmer, D.W. A Review of Goodness of Fit Statistics for Use in the Development of Logistic Regression Models. Am. J. Epidemiol. 1982, 116, 732–733. [Google Scholar] [CrossRef]
- Taylor, R. Interpretation of the Correlation Coefficient: A Basic Review. J. Diagnostic Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- Dhaka, V.S.; Meena, S.V.; Rani, G.; Sinwar, D.; Kavita; Ijaz, M.F.; Woźniak, M. A Survey of Deep Convolutional Neural Networks Applied for Prediction of Plant Leaf Diseases. Sensors 2021, 21, 4749. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Li, Z.; Yan, Y.; Chen, H. A Survey of Fuzzy Decision Tree Classifier Methodology. Adv. Soft Comput. 2007, 40, 959–968. [Google Scholar] [CrossRef]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An Introduction to Decision Tree Modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Scott, A.J.; Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression. Biometrics 1991, 47, 1632. [Google Scholar] [CrossRef]
- Zhang, H. The Optimality of Naive Bayes. Int. J. Pattern Recognit. Artif. Intell. 2005, 19, 183–198. [Google Scholar] [CrossRef]
- Rish, I. An Empirical Study of the Naive Bayes Classifie. Phys. Chem. Chem. Phys. 2001, 3, 4863–4869. [Google Scholar] [CrossRef]
- Amari, S.; Wu, S. Improving Support Vector Machine Classifiers by Modifying Kernel Functions. Neural Netw. 1999, 12, 783–789. [Google Scholar] [CrossRef]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-Based Classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Myerson, J.; Green, L.; Warusawitharana, M. Area Under the Curve As a Measure of Discounting. J. Exp. Anal. Behav. 2001, 76, 235–243. [Google Scholar] [CrossRef] [Green Version]
- Stoll, H.R.M.; Baecker, S.G.; Berkelmann-Loehnertz, B. Early pathogen detection under different water status and the assessment of spray application in vineyards through the use of thermal imagery. Precis. Agric. 2008, 9, 407–417. [Google Scholar] [CrossRef]
- Granum, E.; Pérez-Bueno, M.L.; Calderón, C.E.; Ramos, C.; de Vicente, A.; Cazorla, F.M.; Barón, M. Metabolic Responses of Avocado Plants to Stress Induced by Rosellinia Necatrix Analysed by Fluorescence and Thermal Imaging. Eur. J. Plant Pathol. 2015, 142, 625–632. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Campaign | Date | Days after Inoculation | Number of Infected Leaf Samples | Number of Healthy Leaf Samples |
|---|---|---|---|---|
| 1 | 30 December 2019 | 1 | 71 | 17 |
| 1 | 31 December 2019 | 2 | 74 | - |
| 2 | 16 January 2020 | 4 | 60 | - |
| 3 | 26 January 2020 | 7 | 52 | - |
| 4 | 3 March 2020 | 2 | 94 | 85 |
| 4 | 5 March 2020 | 4 | 86 | - |
| 4 | 8 March 2020 | 7 | 86 | - |
| 5 | 26 March 2020 | 0 | - | 323 |
| 5 | 2 April 2020 | 4 | 101 | - |
| 6 | 25 October 2020 | 4 | 45 | 45 |
| 6 | 26 October 2020 | 5 | 45 | 45 |
| 6 | 27 October 2020 | 6 | 45 | 43 |
| 6 | 28 October 2020 | 7 | 45 | 41 |
| Round Number | Acquisition Time | Number of Samples |
|---|---|---|
| 1 | 7:15–8:25 | 88 |
| 2 | 9:00–9:45 | 88 |
| 3 | 10:40–11:30 | 88 |
| 4 | 12:25–13:15 | 87 |
| 5 | 14:15–15:05 | 86 |
| 6 | 15:20–16:00 | 86 |
| 7 | 16:00–16:30 | 52 |
| Variable Name | Description | Range | Symbol | Calculation |
|---|---|---|---|---|
| Minimum temperature | The minimum temperature in the leaf, minus the air temperature measured at the same time | (−6.3)–10.7 | Tmin | Tmin-Tair |
| Maximum temperature | The maximum temperature in the leaf, minus the air temperature measured at the same time | (−4.2)–14.6 | Tmax | Tmax-Tair |
| Average temperature | The average of the leaf temperatures values, minus the air temperature measured at the same time | (−5.11)–12.98 | Tavg | Tavg-Tair |
| Median temperature | The median of the leaf temperatures values, minus the air temperature measured at the same time | (−5.06)–13.11 | median | median-Tair |
| Maximum temperature difference | The difference between the maximum and minimum temperature in the leaf | 0.5–7.1 | MTD | Tmax-Tmin |
| Standard deviation | The standard deviation value of the leaf temperature values | 0.1–1.73 | STD | std |
| Interquartile range | A measure of statistical dispersion and equal to the difference between 75th and 25th percentiles | 0.17–3.28 | IQR | T0.75-T0.25 |
| Mean absolute deviation | A robust measure of the variability. Defined as the mean of the absolute deviations from the mean of the data | 0.1–1.53 | MAD | |
| Coefficient of variation | Or relative standard deviation, a standardized measure of the dispersion of a probability distribution or frequency distribution. | 0.004–0.061 | CV | |
| Percentile 10 | The percentile is a score at or below which a given percentage fall, minus the air temperature measured | (−5.9)–11.9 | perc10 | T0.1-Tair |
| Percentile 90 | (−4.8)–13.9 | perc90 | T0.9-Tair | |
| Crop water stress index | A means of irrigation scheduling and crop water stress quantification based on leaf temperature measurements and prevailing meteorological conditions [19] | 0.37–1.53 | CWSI |
| Variable | Estimated Coefficients | Standard Errors | p-Value |
|---|---|---|---|
| MTD | 0.6543 | 0.1782 | 0.00024 |
| STD | −2.4373 | 1.1323 | 0.03136 |
| CV | 79.2226 | 24.7641 | 0.00138 |
| percentile 90 | 0.2709 | 0.0388 | 3.06 × 10−12 |
| CWSI | 1.6405 | 0.4575 | 0.00034 |
| Model | Hyperparameter | Range | Optimal |
|---|---|---|---|
| Decision Tree | Maximum number of splits | [1, 1011] | 17 |
| Split criterion | Gini’s diversity index, Twoing rule, and Maximum deviance reduction | Maximum deviance reduction | |
| Naive Bayes | Distribution names | Gaussian and Kernel | Kernel |
| Kernel type | Gaussian, Box, Epanechnikov, and Triangle | Box | |
| SVM | Kernel function | Gaussian, Linear, Quadratic, and Cubic | Cubic |
| Box constraint level | [0.001, 1000] | 1 | |
| Ensemble | Ensemble method | AdaBoost, RUSBoost, LogitBoost, GentleBoost, and Bag | GentleBoost |
| Maximum number of splits | [1, 1011] | 960 | |
| Number of learners | [10, 500] | 498 | |
| Learning rate | [0.001, 1] | 0.057385 |
| Model Measure | Decision Tree | Logistic Regression | NB | SVM | Ensemble |
|---|---|---|---|---|---|
| F1 score | 60.5% | 64.9% | 66.9% | 77.5% | 66.7% |
| Precision | 70.5% | 70.8% | 70.4% | 83.1% | 69.3% |
| Recall | 53.1% | 59.9% | 64.2% | 71.6% | 64.4% |
| AUC | 0.728 | 0.762 | 0.782 | 0.874 | 0.782 |
| Accuracy | 69.9% | 71.7% | 72.6% | 81.6% | 72% |
| Days after Inoculation | Number of Samples | Number of Misses | Accuracy |
|---|---|---|---|
| 0 | 571 | 65 | 88.6% |
| 1 | 19 | 2 | 89.5% |
| 2 | 61 | 3 | 95.1% |
| 4 | 180 | 55 | 69.4% |
| 5 | 39 | 4 | 89.7% |
| 6 | 44 | 17 | 61.4% |
| 7 | 98 | 40 | 59.2% |
| Model | - | - | 81.6% |
| Days after Inoculation | Number of Samples | Number of Misses | Accuracy |
|---|---|---|---|
| 0 | 441 | 68 | 84.6% |
| 1 | 19 | 1 | 94.7% |
| 2 | 61 | 5 | 91.8% |
| 4 | 180 | 55 | 69.4% |
| 5 | 39 | 5 | 87.2% |
| 6 | 44 | 14 | 68.2% |
| 7 | 98 | 36 | 63.3% |
| Model | - | - | 79.1% |
| Days after Inoculation | Number of Samples | Number of Misses | Accuracy |
|---|---|---|---|
| 0 | 99 | 10 | 89.9% |
| 1 | 21 | 1 | 95.2% |
| 2 | 78 | 5 | 93.6% |
| Model | - | - | 91.9% |
| Days after Inoculation | Number of Samples | Number of Misses | Accuracy |
|---|---|---|---|
| 0 | 399 | 72 | 81.9% |
| 4 | 197 | 54 | 72.6% |
| 5 | 45 | 5 | 88.9% |
| 6 | 45 | 9 | 80% |
| 7 | 112 | 27 | 75.9% |
| Model | - | - | 79.1% |
| Approach | F1 Score | AUC | Accuracy |
|---|---|---|---|
| SVM—all data | 77.5% | 0.874 | 81.6% |
| Balance between healthy and infected (Exp1a) | 77.9% | 0.86 | 79.1% |
| Balance between the infected days (Exp1b) | 71% | 0.756 | 73.8% |
| Each imaging day’s data—80% training set and 20% test set (Exp2a) | 70.8% | 0.827 | 76.5% |
| Experiment 10446 as test (Exp2b) | 48.9% | 0.593 | 57.8% |
| Days 0,1,2 (Exp3a) | 92.1% | 0.961 | 91.9% |
| Days 0,4,5,6,7 (Exp3b) | 78.4% | 0.856 | 79.1% |
| As ordinal instead of binary (Exp4) | - | - | 74.9% |
| Measure | |||
|---|---|---|---|
| Round No./Time | Accuracy | F1 Score | AUC |
| (1) 7:15–8:25 | 75% | 75.6% | 0.774 |
| (2) 9:00–9:45 | 72.7% | 72.7% | 0.794 |
| (3) 10:40–11:30 | 80.7% | 80.5% | 0.895 |
| (4) 12:25–13:15 | 59.8% | 61.5% | 0.676 |
| (5) 14:15–15:05 | 65.1% | 67.4% | 0.691 |
| (6) 15:20–16:00 | 58.1% | 61.7% | 0.644 |
| (7) 16:00–16:30 | 57.7% | 59.3% | 0.557 |
| Model | Number of Samples | F1 score | AUC | Accuracy |
|---|---|---|---|---|
| Hours 10:40–11:30 | 239 | 72.7% | 0.764 | 67.4% |
| New features | 239 | 80.8% | 0.826 | 76.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cohen, B.; Edan, Y.; Levi, A.; Alchanatis, V. Early Detection of Grapevine (Vitis vinifera) Downy Mildew (Peronospora) and Diurnal Variations Using Thermal Imaging. Sensors 2022, 22, 3585. https://doi.org/10.3390/s22093585
Cohen B, Edan Y, Levi A, Alchanatis V. Early Detection of Grapevine (Vitis vinifera) Downy Mildew (Peronospora) and Diurnal Variations Using Thermal Imaging. Sensors. 2022; 22(9):3585. https://doi.org/10.3390/s22093585
Chicago/Turabian StyleCohen, Bar, Yael Edan, Asher Levi, and Victor Alchanatis. 2022. "Early Detection of Grapevine (Vitis vinifera) Downy Mildew (Peronospora) and Diurnal Variations Using Thermal Imaging" Sensors 22, no. 9: 3585. https://doi.org/10.3390/s22093585
APA StyleCohen, B., Edan, Y., Levi, A., & Alchanatis, V. (2022). Early Detection of Grapevine (Vitis vinifera) Downy Mildew (Peronospora) and Diurnal Variations Using Thermal Imaging. Sensors, 22(9), 3585. https://doi.org/10.3390/s22093585