
End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC



Abstract
:1. Introduction
2. Proposed Architecture
2.1. Convolutional Layer
2.2. Recurrent Layer
2.3. Transcription Layer
3. Experimental Evaluation
3.1. Dataset
3.2. Data Preprocessing and Augmentation
3.3. Implementation
3.4. Performance Evaluation Metrics
4. Results
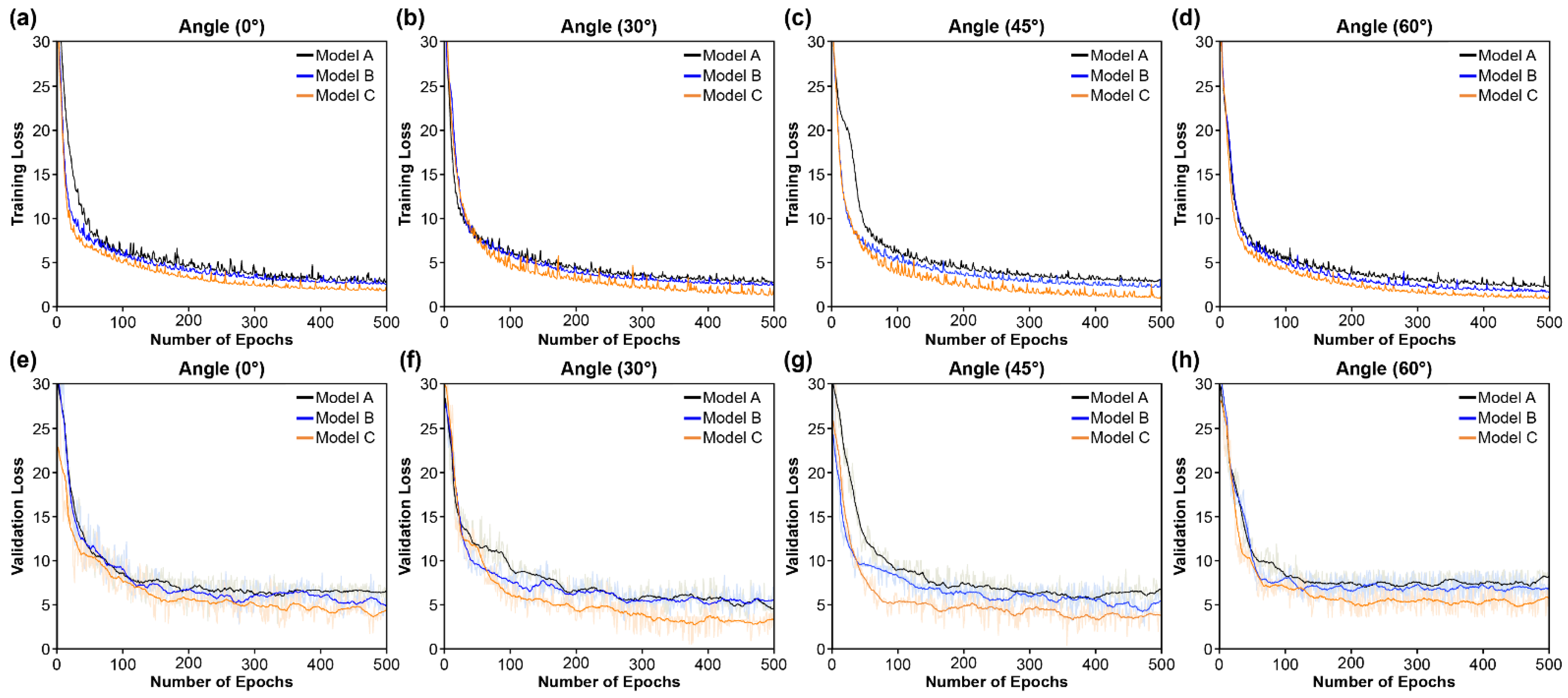
4.1. Learning Loss and Convergence Rate
4.2. Optimization
4.3. Performance and Accuracy
4.4. Statistical Analysis and Model Efficiency
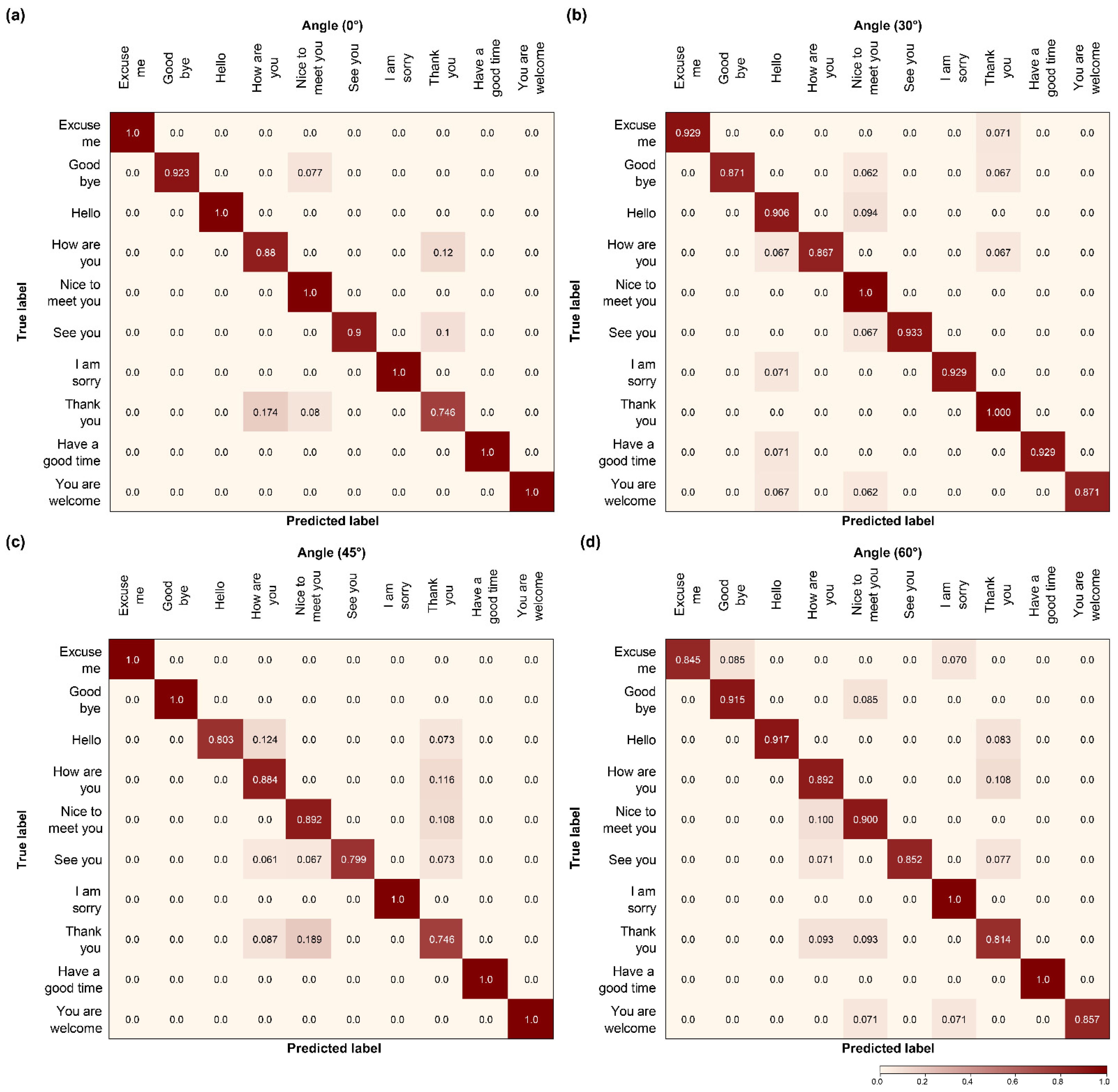
4.5. Confusion Matrix
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Antonakos, E.; Roussos, A.; Zafeiriou, S. A survey on mouth modeling and analysis for sign language recognition. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–7. [Google Scholar]
- Seymour, R.; Stewart, D.; Ming, J. Comparison of image transform-based features for visual speech recognition in clean and corrupted videos. EURASIP J. Image Video Process. 2007, 2008, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Potamianos, G. Audiovisual automatic speech recognition: Progress and challenges. J. Acoust. Soc. Am. 2008, 123, 3939. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhao, G.; Hong, X.; Pietikäinen, M. A review of recent advances in visual speech decoding. Image Vis. Comput. 2014, 32, 590–605. [Google Scholar] [CrossRef]
- Akhtar, Z.; Micheloni, C.; Foresti, G.L. Biometric liveness detection: Challenges and research opportunities. IEEE Secur. Priv. 2015, 13, 63–72. [Google Scholar] [CrossRef]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing Obama: Learning lip sync from audio. ACM Trans. Graphics (ToG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Koller, O.; Camgoz, N.C.; Ney, H.; Bowden, R. Weakly supervised learning with multi-stream CNN-LSTM-HMMs to discover sequential parallelism in sign language videos. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2306–2320. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Zhou, W.; Zhou, Y.; Li, H. Spatial-temporal multi-cue network for continuous sign language recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York City, NY, USA, 7–12 February 2020; Volume 34, pp. 13009–13016. [Google Scholar]
- Fenghour, S.; Chen, D.; Guo, K.; Xiao, P. Lip reading sentences using deep learning with only visual cues. IEEE Access 2020, 8, 215516–215530. [Google Scholar] [CrossRef]
- Yang, C.; Wang, S.; Zhang, X.; Zhu, Y. Speaker-independent lipreading with limited data. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2181–2185. [Google Scholar]
- Lu, Y.; Yan, J. Automatic lip reading using convolution neural network and bidirectional long short-term memory. Int. J. Pattern. Recognit. Artif. Intell. 2020, 34, 2054003. [Google Scholar] [CrossRef]
- Chen, X.; Du, J.; Zhang, H. Lipreading with DenseNet and resBi-LSTM. Signal Image Video Process. 2020, 14, 981–989. [Google Scholar] [CrossRef]
- Petridis, S.; Li, Z.; Pantic, M. End-to-end visual speech recognition with LSTMs. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2592–2596. [Google Scholar]
- Xu, K.; Li, D.; Cassimatis, N.; Wang, X. LCANet: End-to-end lipreading with cascaded attention-CTC. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 548–555. [Google Scholar]
- Margam, D.K.; Aralikatti, R.; Sharma, T.; Thanda, A.; Roy, S.; Venkatesan, S.M. LipReading with 3D-2D-CNN BLSTM-HMM and word-CTC models. arXiv 2019, arXiv:1906.12170. [Google Scholar]
- Bauman, S.L.; Hambrecht, G. Analysis of view angle used in speechreading training of sentences. Am. J. Audiol. 1995, 4, 67–70. [Google Scholar] [CrossRef]
- Lan, Y.; Theobald, B.-J.; Harvey, R. View independent computer lip-reading. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 432–437. [Google Scholar]
- Assael, Y.M.; Shillingford, B.; Whiteson, S.; De Freitas, N. Lipnet: End-to-end sentence-level lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]
- Santos, T.I.; Abel, A.; Wilson, N.; Xu, Y. Speaker-independent visual speech recognition with the Inception V3 model. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 613–620. [Google Scholar]
- Lucey, P.; Potamianos, G. Lipreading using profile versus frontal views. In Proceedings of the 2006 IEEE Workshop on Multimedia Signal Processing, Victoria, BC, Canada, 3–6 October 2006; pp. 24–28. [Google Scholar]
- Saitoh, T.; Zhou, Z.; Zhao, G.; Pietikäinen, M. Concatenated frame image based CNN for visual speech recognition. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 277–289. [Google Scholar]
- Zimmermann, M.; Ghazi, M.M.; Ekenel, H.K.; Thiran, J.-P. Visual speech recognition using PCA networks and LSTMs in a tandem GMM-HMM system. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 264–276. [Google Scholar]
- Koumparoulis, A.; Potamianos, G. Deep view2view mapping for view-invariant lipreading. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 588–594. [Google Scholar]
- Petridis, S.; Wang, Y.; Li, Z.; Pantic, M. End-to-end multi-view lipreading. arXiv 2017, arXiv:1709.00443. [Google Scholar]
- Zimmermann, M.; Ghazi, M.M.; Ekenel, H.K.; Thiran, J.-P. Combining multiple views for visual speech recognition. arXiv 2017, arXiv:1710.07168. [Google Scholar]
- Sahrawat, D.; Kumar, Y.; Aggarwal, S.; Yin, Y.; Shah, R.R.; Zimmermann, R. “Notic My Speech”—Blending speech patterns with multimedia. arXiv 2020, arXiv:2006.08599. [Google Scholar]
- Anina, I.; Zhou, Z.; Zhao, G.; Pietikäinen, M. OuluVS2: A multi-view audiovisual database for non-rigid mouth motion analysis. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–5. [Google Scholar]
- Estellers, V.; Thiran, J.-P. Multipose audio-visual speech recognition. In Proceedings of the 2011 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; pp. 1065–1069. [Google Scholar]
- Isobe, S.; Tamura, S.; Hayamizu, S. Speech recognition using deep canonical correlation analysis in noisy environments. In Proceedings of the ICPRAM, Online. 4–6 February 2021; pp. 63–70. [Google Scholar]
- Komai, Y.; Yang, N.; Takiguchi, T.; Ariki, Y. Robust AAM-based audio-visual speech recognition against face direction changes. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1161–1164. [Google Scholar]
- Lee, D.; Lee, J.; Kim, K.-E. Multi-view automatic lip-reading using neural network. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany; pp. 290–302. [Google Scholar]
- Jeon, S.; Elsharkawy, A.; Kim, M.S. Lipreading architecture based on multiple convolutional neural networks for sentence-level visual speech recognition. Sensors 2022, 22, 72. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order Boltzmann machine. Adv. Neural Inf. Process. Syst. 2010, 23, 1243–1251. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, T.; He, L.; Li, X.; Feng, G. Efficient end-to-end sentence-level lipreading with temporal convolutional networks. Appl. Sci. 2021, 11, 6975. [Google Scholar] [CrossRef]
- Hlaváč, M.; Gruber, I.; Železný, M.; Karpov, A. Lipreading with LipsID. In Proceedings of the International Conference on Speech and Computer, St. Petersburg, Russia, 7–9 October 2020; Springer: Berlin/Heidelberg, Germany; pp. 176–183. [Google Scholar]
- Luo, M.; Yang, S.; Shan, S.; Chen, X. Pseudo-convolutional policy gradient for sequence-to-sequence lip-reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 273–280. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Operat. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Tran, Q.-K.; Song, S.-K. Water level forecasting based on deep learning: A use case of Trinity River-Texas-The United States. J. KIISE 2017, 44, 607–612. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Learning to lip read words by watching videos. Comput. Vis. Image Understand. 2018, 173, 76–85. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip reading sentences in the wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 26 July 2017; pp. 3444–3453. [Google Scholar]
- Cheng, J.; Dong, L.; Lapata, M. Long short-term memory-networks for machine reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. Disan: Directional self-attention network for RNN/CNN-free language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhang, Y.; Chan, W.; Jaitly, N. Very deep convolutional networks for end-to-end speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4845–4849. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar]
- Chiu, C.-C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Zeyer, A.; Irie, K.; Schlüter, R.; Ney, H. Improved training of end-to-end attention models for speech recognition. arXiv 2018, arXiv:1805.03294. [Google Scholar]
- Chen, Z.; Droppo, J.; Li, J.; Xiong, W. Progressive joint modeling in unsupervised single-channel overlapped speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 26, 184–196. [Google Scholar] [CrossRef]
- Erdogan, H.; Hayashi, T.; Hershey, J.R.; Hori, T.; Hori, C.; Hsu, W.N.; Kim, S.; Le Roux, J.; Meng, Z.; Watanabe, S. Multi-channel speech recognition: Lstms all the way through. In Proceedings of the CHiME-4 Workshop, San Francisco, CA, USA, 13 September 2016; pp. 1–4. [Google Scholar]
- Liu, P.J.; Saleh, M.; Pot, E.; Goodrich, B.; Sepassi, R.; Kaiser, L.; Shazeer, N. Generating Wikipedia by summarizing long sequences. arXiv 2018, arXiv:1801.10198. [Google Scholar]
- Huang, C.-Z.A.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.; Simon, I.; Hawthorne, C.; Dai, A.M.; Hoffman, M.D.; Dinculescu, M.; Eck, D. Music transformer. arXiv 2018, arXiv:1809.04281. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Sagonas, C.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: The first facial landmark localization challenge. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 397–403. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Schaul, T.; Antonoglou, I.; Silver, D. Unit tests for stochastic optimization. arXiv 2013, arXiv:1312.6055. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; PMLR. pp. 1139–1147. [Google Scholar]
- Zhou, Z.; Hong, X.; Zhao, G.; Pietikäinen, M. A compact representation of visual speech data using latent variables. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.S.; Zisserman, A. Out of time: Automated lip sync in the wild. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany; pp. 251–263. [Google Scholar]
- Chung, J.S.; Zisserman, A. Lip reading in profile. In Proceedings of the British Machine Vision Conference (BMVC), Imperial College London, London, UK, 4–7 September 2017; pp. 1–11. [Google Scholar]
- Petridis, S.; Wang, Y.; Li, Z.; Pantic, M. End-to-end audiovisual fusion with LSTMs. arXiv 2017, arXiv:1709.04343. [Google Scholar]
- Han, H.; Kang, S.; Yoo, C.D. Multi-view visual speech recognition based on multi task learning. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3983–3987. [Google Scholar]
- Fung, I.; Mak, B. End-to-end low-resource lip-reading with maxout CNN and LSTM. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2511–2515. [Google Scholar]
- Fernandez-Lopez, A.; Sukno, F.M. Lip-reading with limited-data network. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Isobe, S.; Tamura, S.; Hayamizu, S.; Gotoh, Y.; Nose, M. Multi-angle lipreading using angle classification and angle-specific feature integration. In Proceedings of the 2020 International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 16–18 March 2021; pp. 1–5. [Google Scholar]
- Isobe, S.; Tamura, S.; Hayamizu, S.; Gotoh, Y.; Nose, M. Multi-angle lipreading with angle classification-based feature extraction and its application to audio-visual speech recognition. Future Internet 2021, 13, 182. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Size/Stride/Pad | Dimension Order | |
|---|---|---|---|---|
| Input Layer | 40 × 100 × 50 × 3 | - | T × C × H × W | |
| Convolution 3D Layer | 40 × 50 × 25 × 64 | [3 × 5 × 5]/(1, 2, 2)/(1, 2, 2) | ||
| [1 × 2 × 2] max pool/(1 × 2 × 2) | ||||
| 3D Dense Block (1) | 40 × 25 × 13 × 96 | [3 × 1 × 1] 3D Conv | (×6) | |
| [3 × 3 × 3] 3D Conv | ||||
| 3D Transition Block (1) | 40 × 12 × 6 × 6 | [3 × 1 × 1] 3D Conv | ||
| [1 × 2 × 2] average pool/(1 × 2 × 2) | ||||
| 3D Dense Block (2) | 40 × 12 × 6 × 38 | [3 × 1 × 1] 3D Conv | (×12) | |
| [3 × 3 × 3] 3D Conv | ||||
| 3D Transition Block (2) | 40 × 6 × 3 × 3 | [3 × 1 × 1] 3D Conv | ||
| [1 × 2 × 2] average pool/(1 × 2 × 2) | ||||
| 3D Dense Block (3) | 40 × 6 × 3 × 35 | [3 × 1 × 1] 3D Conv | (×24) | |
| [3 × 3 × 3] 3D Conv | ||||
| 3D Transition Block (3) | 40 × 3 × 1 × 1 | [3 × 1 × 1] 3D Conv | ||
| [1 × 2 × 2] average pool/(1 × 2 × 2) | ||||
| 3D Dense Block (4) | 40 × 3 × 1 × 33 | [3 × 1 × 1] 3D Conv | (×16) | |
| [3 × 3 × 3] 3D Conv | ||||
| Multi-scale 3D CNN (1) | 40 × 3 × 1 × 32 | [3 × 5 × 5]/(1, 2, 2)/(1, 2, 2) | ||
| Multi-scale 3D CNN (2) | 40 × 3 × 1 × 64 | [3 × 5 × 5]/(1, 2, 2)/(1, 2, 2) | ||
| Multi-scale 3D CNN (3) | 40 × 3 × 1 × 192 | [3 × 5 × 5]/(1, 2, 2)/(1, 2, 2) | ||
| Spatial Attention (1) | 40 × 3 × 1 × 32 | [1 × 2 × 2] max pool/(1 × 2 × 2) | ||
| [1 × 2 × 2] average pool/(1 × 2 × 2) | ||||
| [3 × 7 × 7]/(1, 2, 2)/(1, 2, 2) | ||||
| Spatial Attention (2) | 40 × 3 × 1 × 64 | [1 × 2 × 2] max pool/(1 × 2 × 2) | ||
| [1 × 2 × 2] average pool/(1 × 2 × 2) | ||||
| [3 × 7 × 7]/(1, 2, 2)/(1, 2, 2) | ||||
| Spatial Attention (3) | 40 × 3 × 1 × 96 | [1 × 2 × 2] max pool/(1 × 2 × 2) | ||
| [1 × 2 × 2] average pool/(1 × 2 × 2) | ||||
| [3 × 7 × 7]/(1, 2, 2)/(1, 2, 2) | ||||
| Bidirectional GRU Layer | 40 × 512 | 256 | T × F | |
| Bidirectional GRU Layer | 40 × 512 | 256 | T × F | |
| Local Self-Attention Layer | 40 × 512 | 15 | T × F | |
| Dense Layer | 40 × 28 | 27 + blank | T × F | |
| SoftMax Layer | 40 × 28 | T × V | ||
| Model | Method | Top 10 Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| 0° | 30° | 45° | 60° | Mean | ||
| A * | 3D dense connection CNN + Bi-GRU + CTC | 90.44 | 88.73 | 86.93 | 87.72 | 88.45 |
| B * | 3D dense connection CNN + Multi-scale 3D CNN + Bi-GRU + CTC | 92.72 | 91.02 | 88.02 | 88.09 | 89.62 |
| C * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-GRU + CTC | 94.14 | 92.86 | 91.34 | 89.97 | 92.08 |
| D * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + RNN + CTC | 88.51 | 85.74 | 83.93 | 83.04 | 85.31 |
| E * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + LSTM + CTC | 89.42 | 87.42 | 86.01 | 85.71 | 87.14 |
| F * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-LSTM + CTC | 89.78 | 88.84 | 87.26 | 86.18 | 88.02 |
| G * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + GRU + CTC | 92.85 | 91.23 | 90.91 | 89.67 | 91.14 |
| H * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-GRU + Global self-attention + CTC | 95.08 | 93.29 | 92.81 | 90.93 | 93.03 |
| Our * | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-GRU + Local self-attention + CTC | 98.31 | 97.89 | 97.21 | 96.78 | 97.55 |
| Year | Model | 0° (%) | 30° (%) | 45° (%) | 60° (%) | Mean (%) |
|---|---|---|---|---|---|---|
| 2014 | RAW-PLVM [69] | 73.00 | 75.00 | 76.00 | 75.00 | 74.75 |
| 2016 | CNN * [21] | 85.60 | 82.50 | 82.50 | 83.30 | 83.48 |
| CNN + LSTM [31] | 81.10 | 80.00 | 76.90 | 69.20 | 76.80 | |
| CNN + LSTM, Cross-view Training [31] | 82.80 | 81.10 | 85.00 | 83.60 | 83.13 | |
| PCA Network + LSTM + GMM–HMM [22] | 74.10 | 76.80 | 68.70 | 63.70 | 70.83 | |
| CNN pretrained on BBC dataset * [52] | 93.20 | - | - | - | - | |
| CNN pretrained on BBC dataset + LSTM * [70] | 94.10 | - | - | - | - | |
| 2017 | End-to-End Encoder + BLSTM [24] | 94.70 | 89.70 | 90.60 | 87.50 | 90.63 |
| Multi-view SyncNet + LSTM * [71] | 91.10 | 90.80 | 90.00 | 90.00 | 90.48 | |
| End-to-End Encoder + BLSTM [13] | 84.50 | - | - | - | 84.50 | |
| End-to-End Encoder + BLSTM [72] | 91.80 | 87.30 | 88.80 | 86.40 | 88.58 | |
| 2018 | CNN + Bi-LSTM [73] | 90.30 | 84.70 | 90.60 | 88.60 | 88.55 |
| CNN + Bi-LSTM [73] | 95.00 | 93.10 | 91.70 | 90.60 | 92.60 | |
| Maxout-CNN-BLSTM * [74] | 87.60 | - | - | - | - | |
| CNN + LSTM with view classifier * [23] | - | 86.11 | 83.33 | 81.94 | - | |
| CNN + LSTM without view classifier * [23] | - | 86.67 | 85.00 | 82.22 | - | |
| 2019 | VGG-M + LSTM * [75] | 91.38 | - | - | - | 91.38 |
| 2020 | CNN(2D + 3D) without view classifier [76] | 91.02 | 90.56 | 91.20 | 90.00 | 90.70 |
| CNN with view classifier [76] | 91.02 | 90.74 | 92.04 | 90.00 | 90.95 | |
| 2021 | CNN without view classifier [77] | 91.02 | 90.56 | 91.20 | 90.00 | 90.70 |
| CNN with view classifier * [77] | 91.02 | 91.38 | 92.21 | 90.09 | 91.18 |
| Model | Method | Number of Parameters | Epoch Time (s) | |||
|---|---|---|---|---|---|---|
| 0° | 30° | 45° | 60° | |||
| A | 3D dense connection CNN + Bi-GRU + CTC | 2,247,537 | 34.57 | 36.07 | 34.43 | 33.97 |
| B | 3D dense connection CNN + Multi-scale 3D CNN + Bi-GRU + CTC | 3,456,369 | 36.48 | 36.58 | 34.93 | 35.43 |
| C | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-GRU + CTC | 5,273,457 | 43.37 | 41.44 | 40.01 | 43.03 |
| D | 3D dense connection CNN + Multi-scale 3D CNN + SAM + RNN + CTC | 2,429,362 | 35.27 | 36.78 | 36.15 | 35.86 |
| E | 3D dense connection CNN + Multi-scale 3D CNN + SAM + LSTM + CTC | 3,905,458 | 38.16 | 39.13 | 38.94 | 37.45 |
| F | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-LSTM + CTC | 6,421,426 | 54.35 | 53.18 | 53.04 | 57.86 |
| G | 3D dense connection CNN + Multi-scale 3D CNN + SAM + GRU + CTC | 3,413,426 | 34.18 | 32.98 | 33.48 | 33.48 |
| H | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-GRU + Global self-attention + CTC | 5,306,290 | 40.95 | 42.13 | 41.78 | 43.48 |
| Our | 3D dense connection CNN + Multi-scale 3D CNN + SAM + Bi-GRU + Local self-attention + CTC | 5,306,290 | 40.46 | 41.39 | 41.97 | 42.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, S.; Kim, M.S. End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC. Sensors 2022, 22, 3597. https://doi.org/10.3390/s22093597
Jeon S, Kim MS. End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC. Sensors. 2022; 22(9):3597. https://doi.org/10.3390/s22093597
Chicago/Turabian StyleJeon, Sanghun, and Mun Sang Kim. 2022. "End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC" Sensors 22, no. 9: 3597. https://doi.org/10.3390/s22093597
APA StyleJeon, S., & Kim, M. S. (2022). End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC. Sensors, 22(9), 3597. https://doi.org/10.3390/s22093597