

The Development of Symbolic Expressions for Fire Detection with Symbolic Classifier Using Sensor Fusion Data





Abstract
:1. Introduction
1.1. Fire Detection Systems Based on Fire/Smoke Detectors and AI
1.2. Fire Detection Systems Based on Sensor-Fusion and AI
1.3. Definition of Novelty, Research Hypotheses, and Scientific Contribution
- Is it possible to utilize the GPSC to obtain symbolic expression that could detect fire with high classification accuracy?
- Is it possible to balance the dataset class samples using different undersampling/ oversampling methods, and do balancing methods influence the classification accuracy of obtained symbolic expressions?
- Is it possible to achieve high calcification accuracy using a random hyperparameter search method for GPSC algorithm with 5-fold cross-validation?
- Is it possible to achieve high classification accuracy with the application of the best symbolic expression obtained with one of the balancing datasets on the original dataset?
- Investigate the possibility of GPSC application to the publicly available dataset for the detection of fire.
- Investigate if dataset balancing methods have any influence on classification accuracy of obtained symbolic expressions.
- Investigate if GPSC with random hyperparameter search method and 5-fold cross-validation can produce the symbolic expression with high classification accuracy in fire detection.
- Investigate if using the best symbolic expression can produce high classification accuracy in fire detection on the original dataset.
2. Materials and Methods
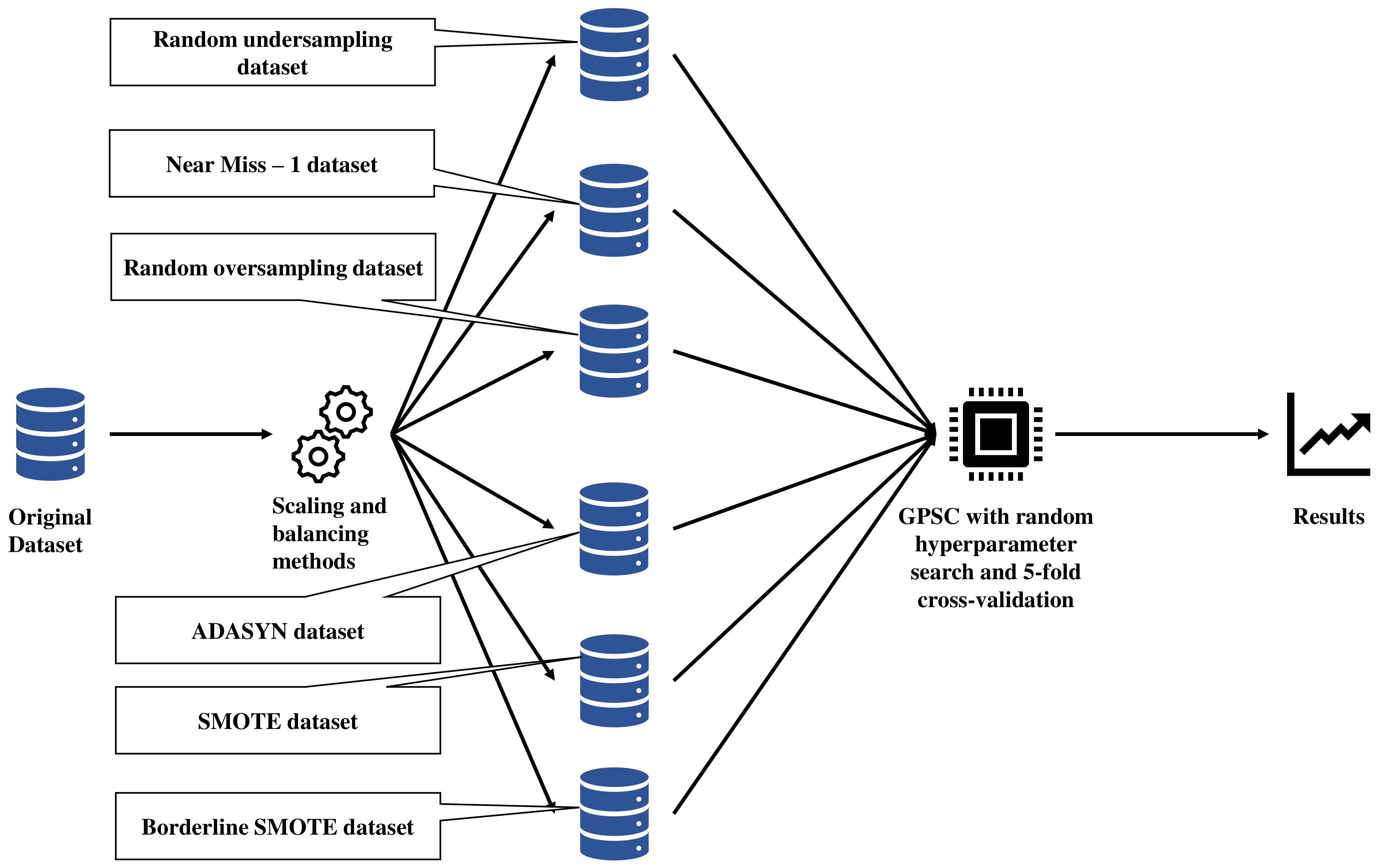
2.1. Research Methodology
- Random undersampling,
- Random oversampling,
- Near miss-1,
- Adaptive Synthetic (ADASYN),
- Synthetic Minority Over-sampling (SMOTE),
- Borderline Synthetic Minority Over-sampling (Borderline SMOTE).
2.2. Dataset Description
- Normal indoor,
- Normal outdoor,
- Indoor wood fire,
- Indoor gas fire,
- Outdoor wood, coal, and gas grill,
- Outdoor high humidity.
- Timestep UTC [s],
- Air temperature [C],
- Air humidity [%],
- Total volatile organic compounds (TVOC) [ppb],
- CO equivalent concentration [ppb],
- Raw H—raw molecular hydrogen,
- Raw ethanol gas,
- Air pressure [hPa],
- Particulate matter size 1.0 m (PM 1.0),
- Particulate matter size 2.5 m (PM 2.5),
- Number of concentration of particulate matter (NC 1.0),
- Number of concentration of particulate matter (NC 2.5),
- Sample counter CNT,
- Fire alarm (fire alarm not activated—0, fire alarm activated—1).
2.3. Data Balancing Methods
2.3.1. Undersampling Method: Random Undersampling
2.3.2. Undersampling Method: Near Miss
2.3.3. Oversampling Method: Random Oversampling
2.3.4. Oversampling Method: ADASYN
2.3.5. Oversampling Method: SMOTE
- Take the difference between the feature vector(sample) under consideration and its nearest neighbor,
- Multiply the difference by a random number in the 0–1 range, and
- Adds the result to the feature vector under consideration.
2.3.6. Oversampling Method: Borderline SMOTE
2.4. Genetic Programming Symbolic Classifier
- Calculate the output using the values of the input variables from the dataset,
- Use the output as the argument of the Sigmoid function that can be written as:
- Calculate the log loss of the sigmoid output and the real output (for each instance).
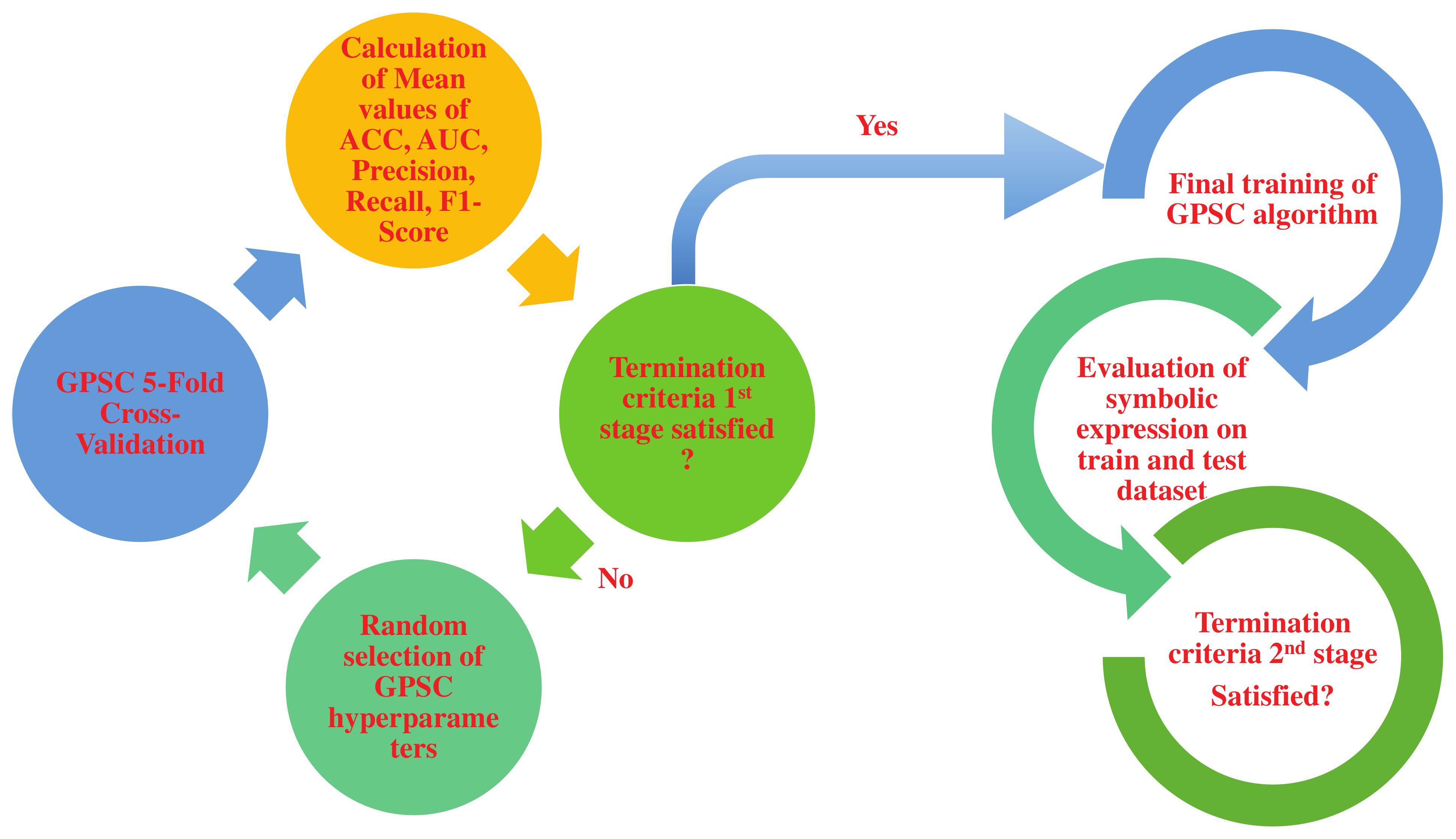
2.5. Random Hyperparameter Search
2.6. 5-Fold Cross-Validation
- Select random hyperparameters of GPSC algorithm from their predefined range.
- Perform 5-fold cross-validation and obtained mean values of accuracy, area under the receiver operating characteristic curve, precision, recall, and F1-Score.
- Termination criteria 1st stage—if the values of previously mentioned metric values are greater than 0.99 then proceed to final analysis, otherwise, start from the beginning by randomly selecting new GPSC hyperparameters and performing GPSC 5-fold cross-validation analysis all over again.
- Final evaluation—if the termination criteria are satisfied the same parameters that were used for GPSC, 5-fold cross-validation is used in this final stage. The final evaluation consists of the final training of GPSC and final testing of obtained symbolic expression on a train and test dataset to obtain mean and standard deviation values of accuracy, area under the receiver characteristic operating curve, precision, recall, and f1-score values.
- Final evaluation 2nd stage—if the mean values of previously mentioned evaluation metrics are above 0.99, the process is completed, otherwise the process starts from the beginning.
2.7. Evaluation Metrics and Methodology
2.7.1. Evaluation Metrics
2.7.2. Evaluation Methodology
- First step: during the 5-fold cross-validation on the train part of the dataset (70%) obtain evaluation metric values on the train and fold dataset packets to calculate the mean values of evaluation metrics that are used in termination criteria. If all mean evaluation metric values are greater than 0.97 after the 5-fold cross-validation process is completed, then the final training/testing is performed (step two). Otherwise, the hyperparameters are randomly selected and the 5-fold cross-validation process starts again.
- Second step: after mean values of evaluation metrics obtained during the 5-fold cross-validation process passed the termination criteria, the final training/ testing is performed. Training is performed using GPSC on 70% of the dataset, and during this step, the symbolic expression is obtained. After obtaining the symbolic expression, the evaluation metric values are obtained on the training dataset, and on the test dataset, i.e., train and test datasets are applied to the symbolic expression to evaluate its performance. Obtained values of evaluation metric on train/test dataset are used to calculate the mean and standard deviation values.
2.8. Computational Resources
3. Results and Discussion
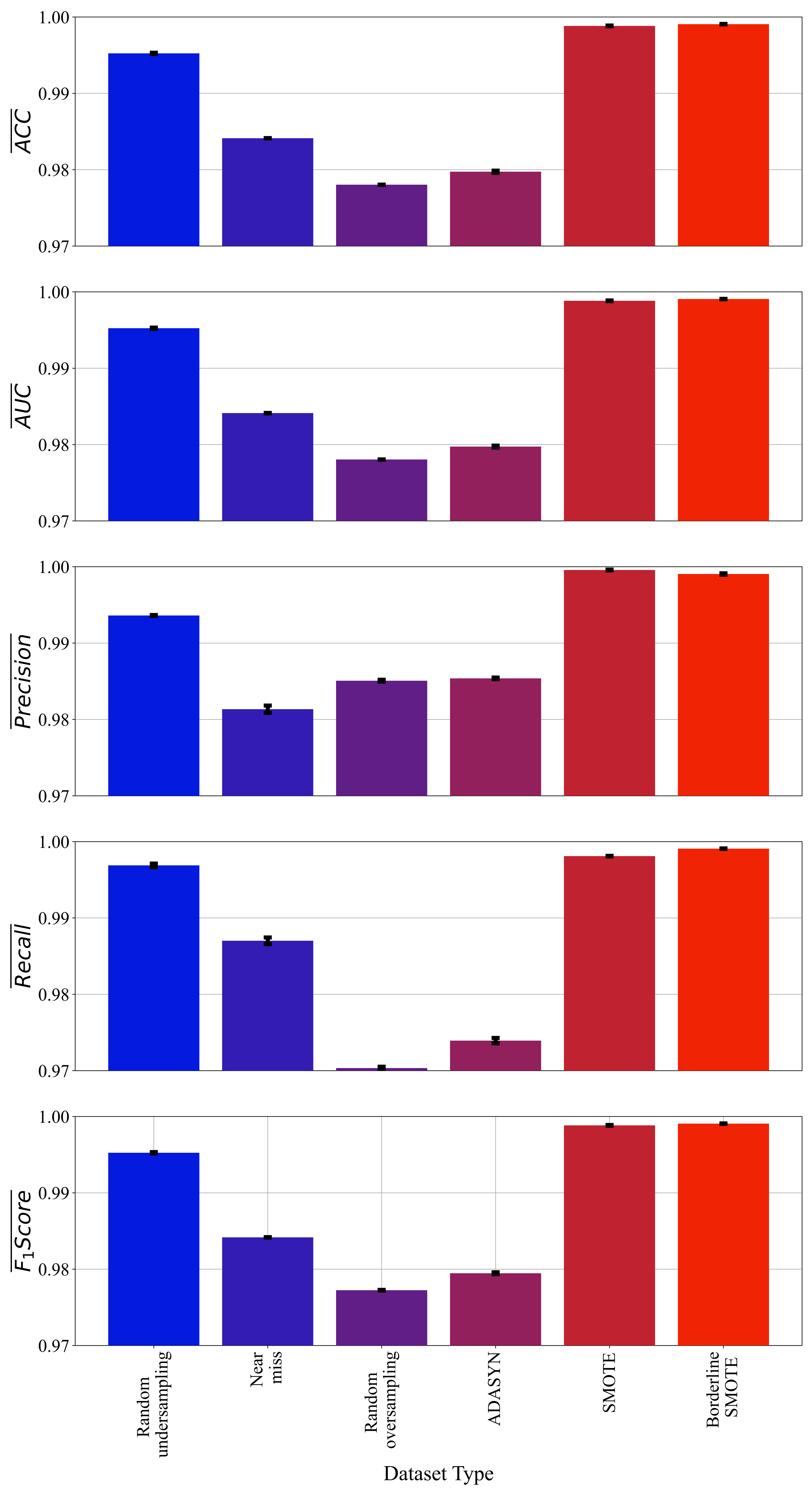
3.1. Results Achieved with GPSC Using Random Hyperparameter Search Method and 5-Fold Cross-Validation
3.2. The Final Evaluation of the Best Symbolic Expression
- The values of input variables of the original dataset are used to calculate the output of the symbolic expression,
- The output values of symbolic expression is used as input in Sigmoid function (Equation (3)) to calculate the output,
- The output of the Sigmoid function is then transformed to an integer value to obtain a 0 or 1 value.
3.3. Results Summary
- The GPSC can be used to obtain symbolic expression which can be used to detect fire using sensory data obtained from the sensor fusion system. However, to achieve high classification accuracy tuning of GPSC hyperparameters is mandatory and was achieved with a random hyperparameter search method.
- The random hyperparameter search method is a good method for obtaining the combination of GPSC hyperparameters using which the highest classification accuracy of obtained symbolic expression can be achieved. However, due to the dataset size, computational resources used, and required average CPU time, this method is slow, but generates good results.
- Since the dataset was greatly imbalanced, i.e., a large number of samples in one class and a small number of samples in another class, the original dataset could not be used in the investigation and dataset balancing methods were applied. The application of the balancing method created a great starting point for analysis and in the end, the symbolic expressions with high classification accuracy were obtained.
- The best symbolic expressions were obtained on datasets balanced with SMOTE and Borderline SMOTE methods. However, in the case of the Borderline SMOTE method, the symbolic expression is three times larger in terms of length than in the case of SMOTE. So, the best symbolic expression based on size and accuracy was obtained in the case of SMOTE.
- The final evaluation of the best symbolic expression on the original dataset showed that this procedure is the procedure of handling imbalanced datasets, i.e., balance the dataset using different balancing methods, using them to train the ML algorithm and perform a final evaluation on the original imbalanced dataset.
4. Conclusions
- After application of GPSC, the symbolic expression is obtained that can be easily used regardless of its size since it requires lower computational resources to produce the solution when compared to other ML algorithms,
- The dataset balancing methods created a good starting point for the implementation of GPSC and using GPSC symbolic expressions with high classification performance were obtained,
- The GPSC with random hyperparameter search method and 5-fold cross-validation generated the symbolic expressions that are robust and have high classification accuracy.
- To implement a random hyperparameter search method, the ranges of each hyperparameter have to be defined by initial testing of GPSC. The population size, maximum number of generations, tournament size, and parsimony coefficient have a great influence on the execution time. The bigger the size of the population, tournament size, and larger maximum number of generations, the longer it will take the GPSC to execute. However, the parsimony coefficient is the most sensitive GPSC hyperparameter, and the range should be carefully defined. If the value of the parsimony coefficient is too small, it can result in a bloat phenomenon, while a very large value can prevent the growth of the symbolic expression, which will result in a small symbolic expression with poor classification performance.
- The dataset oversampling methods greatly influence the GPSC execution time since the dataset used to obtain symbolic expression using GPSC is much larger than the original one.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khan, F.; Xu, Z.; Sun, J.; Khan, F.M.; Ahmed, A.; Zhao, Y. Recent Advances in Sensors for Fire Detection. Sensors 2022, 22, 3310. [Google Scholar] [CrossRef] [PubMed]
- Seo, B.K.; Nam, S.G. Study of the improvement of false fire alarms in analog photoelectric type smoke detectors. Fire Sci. Eng. 2016, 30, 108–115. [Google Scholar] [CrossRef]
- Newman, J.S. Modified theory for the characterization of ionization smoke detectors. Fire Saf. Sci. 1994, 4, 785–792. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, K.R. A real-time forest fire and smoke detection system using deep learning. Int. J. Nonlinear Anal. Appl. 2022, 13, 2053–2063. [Google Scholar]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Ryu, J.; Kwak, D. A Study on a Complex Flame and Smoke Detection Method Using Computer Vision Detection and Convolutional Neural Network. Fire 2022, 5, 108. [Google Scholar] [CrossRef]
- Masoom, S.M.; Zhang, Q.; Dai, P.; Jia, Y.; Zhang, Y.; Zhu, J.; Wang, J. Early Smoke Detection Based on Improved YOLO-PCA Network. Fire 2022, 5, 40. [Google Scholar] [CrossRef]
- Sarwar, B.; Bajwa, I.S.; Jamil, N.; Ramzan, S.; Sarwar, N. An intelligent fire warning application using IoT and an adaptive neuro-fuzzy inference system. Sensors 2019, 19, 3150. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, K.; Khan, S.; Palade, V.; Mehmood, I.; De Albuquerque, V.H.C. Edge intelligence-assisted smoke detection in foggy surveillance environments. IEEE Trans. Ind. Inform. 2019, 16, 1067–1075. [Google Scholar] [CrossRef]
- Choueiri, S.; Daoud, D.; Harb, S.; Achkar, R. Fire and Smoke Detection Using Artificial Neural Networks. In Proceedings of the 2020 IEEE 14th International Conference on Open Source Systems and Technologies (ICOSST), Lahore, Pakistan, 16–17 December 2020; pp. 1–6. [Google Scholar]
- Andrew, A.; Shakaff, A.; Zakaria, A.; Gunasagaran, R.; Kanagaraj, E.; Saad, S. Early stage fire source classification in building using artificial intelligence. In Proceedings of the 2018 IEEE Conference on Systems, Process and Control (ICSPC), Melaka, Malaysia, 14–15 December 2018; pp. 165–169. [Google Scholar]
- Solórzano, A.; Eichmann, J.; Fernandez, L.; Ziems, B.; Jiménez-Soto, J.M.; Marco, S.; Fonollosa, J. Early fire detection based on gas sensor arrays: Multivariate calibration and validation. Sens. Actuators Chem. 2022, 352, 130961. [Google Scholar] [CrossRef]
- Sasiadek, J.Z. Sensor fusion. Annu. Rev. Control. 2002, 26, 203–228. [Google Scholar] [CrossRef]
- Sucuoglu, H.S.; Bogrekci, I.; Demircioglu, P. Development of mobile robot with sensor fusion fire detection unit. IFAC-PapersOnLine 2018, 51, 430–435. [Google Scholar] [CrossRef]
- Chen, S.; Bao, H.; Zeng, X.; Yang, Y. A fire detecting method based on multi-sensor data fusion. In Proceedings of the SMC’03 Conference Proceedings, 2003 IEEE International Conference on Systems, Man and Cybernetics, Conference Theme-System Security and Assurance (Cat. No. 03CH37483), Washington, DC, USA, 8 October 2003; Volume 4, pp. 3775–3780. [Google Scholar]
- Liang, Y.H.; Tian, W.M. Multi-sensor fusion approach for fire alarm using BP neural network. In Proceedings of the 2016 International Conference on Intelligent Networking and Collaborative Systems (INCoS), Ostrawva, Czech Republic, 7–9 September 2016; pp. 99–102. [Google Scholar]
- Solórzano, A.; Fonollosa, J.; Fernández, L.; Eichmann, J.; Marco, S. Fire detection using a gas sensor array with sensor fusion algorithms. In Proceedings of the 2017 ISOCS/IEEE International Symposium on Olfaction and Electronic Nose (ISOEN), Montreal, QC, Canada, 28–31 May 2017; pp. 1–3. [Google Scholar]
- Ting, Y.Y.; Hsiao, C.W.; Wang, H.S. A data fusion-based fire detection system. IEICE Trans. Inf. Syst. 2018, 101, 977–984. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Chen, L.; Hao, X. Multi-sensor data fusion algorithm for indoor fire early warning based on BP neural network. Information 2021, 12, 59. [Google Scholar] [CrossRef]
- Hsu, Y.L.; Chou, P.H.; Chang, H.C.; Lin, S.L.; Yang, S.C.; Su, H.Y.; Chang, C.C.; Cheng, Y.S.; Kuo, Y.C. Design and implementation of a smart home system using multisensor data fusion technology. Sensors 2017, 17, 1631. [Google Scholar] [CrossRef]
- Jondhale, S.R.; Sharma, M.; Maheswar, R.; Shubair, R.; Shelke, A. comparison of neural network training functions for rssi based indoor localization problem in WSN. In Handbook of Wireless Sensor Networks: Issues and Challenges in Current Scenario’s; Springer: Berlin, Germany, 2020; pp. 112–133. [Google Scholar]
- Farooqui, N.A.; Tyagi, A. Data Mining and Fusion Techniques for Wireless Intelligent Sensor Networks. In Handbook of Wireless Sensor Networks: Issues and Challenges in Current Scenario’s; Singh, P.K., Bhargava, B.K., Paprzycki, M., Kaushal, N.C., Hong, W.C., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 592–615. [Google Scholar] [CrossRef]
- Butt, F.A.; Chattha, J.N.; Ahmad, J.; Zia, M.U.; Rizwan, M.; Naqvi, I.H. On the Integration of Enabling Wireless Technologies and Sensor Fusion for Next-Generation Connected and Autonomous Vehicles. IEEE Access 2022, 10, 14643–14668. [Google Scholar] [CrossRef]
- Yusuf, A.; Sulaiman, T.A.; Alshomrani, A.S.; Baleanu, D. Optical solitons with nonlinear dispersion in parabolic law medium and three-component coupled nonlinear Schrödinger equation. Opt. Quan. Electron. 2022, 54, 1–13. [Google Scholar] [CrossRef]
- Ren, X.; Li, C.; Ma, X.; Chen, F.; Wang, H.; Sharma, A.; Gaba, G.S.; Masud, M. Design of multi-information fusion based intelligent electrical fire detection system for green buildings. Sustainability 2021, 13, 3405. [Google Scholar] [CrossRef]
- Singh, N.; Gunjan, V.K.; Chaudhary, G.; Kaluri, R.; Victor, N.; Lakshmanna, K. IoT enabled HELMET to safeguard the health of mine workers. Comput. Commun. 2022, 193, 1–9. [Google Scholar] [CrossRef]
- Rahate, A.; Mandaokar, S.; Chandel, P.; Walambe, R.; Ramanna, S.; Kotecha, K. Employing multimodal co-learning to evaluate the robustness of sensor fusion for industry 5.0 tasks. Soft Comput. 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Vakil, A.; Liu, J.; Zulch, P.; Blasch, E.; Ewing, R.; Li, J. A survey of multimodal sensor fusion for passive RF and EO information integration. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 44–61. [Google Scholar] [CrossRef]
- Mian, T.; Choudhary, A.; Fatima, S. A sensor fusion based approach for bearing fault diagnosis of rotating machine. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 236, 661–675. [Google Scholar] [CrossRef]
- Contractor, D. Kaggle: Smoke Detection Dataset. 2022. Available online: https://www.kaggle.com/datasets/deepcontractor/smoke-detection-dataset (accessed on 22 November 2022).
- Sensirion Company. Sensor for HVAC and Air Quality Applications SPS30 Datasheet. Available online: https://cdn.sparkfun.com/assets/2/d/2/a/6/Sensirion_SPS30_Particulate_Matter_Sensor_v0.9_D1__1_.pdf (accessed on 22 November 2022).
- Bosch. BME688 4-in-1 Air Quality Breakout (Gas, Temperature, Pressure, Humidity) Datasheet. Available online: https://www.bosch-sensortec.com/products/environmental-sensors/gas-sensors/bme688/ (accessed on 22 November 2022).
- ±2% (0–100%RH) Digital Humidity and Temperature Sensor. Available online: https://sensirion.com/products/catalog/SHT31DISB/ (accessed on 22 November 2022).
- Bosch BMP390 Barometric Pressure Sensor. Available online: https://eu.mouser.com/new/bosch/bosch-bmp390-pressure-sensor/ (accessed on 22 November 2022).
- Available online: https://www.bosch-sensortec.com/products/environmental-sensors/pressure-sensors/bmp388/ (accessed on 22 November 2022).
- Multi-Gas (VOC and CO2eq) Sensor. Available online: https://sensirion.com/products/catalog/SGP30/ (accessed on 22 November 2022).
- Arduino Officia: NICLA Sense Me. Available online: https://store.arduino.cc/products/nicla-sense-me (accessed on 22 November 2022).
- Raju, V.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the influence of normalization/transformation process on the accuracy of supervised classification. In Proceedings of the 2020 IEEE Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 729–735. [Google Scholar]
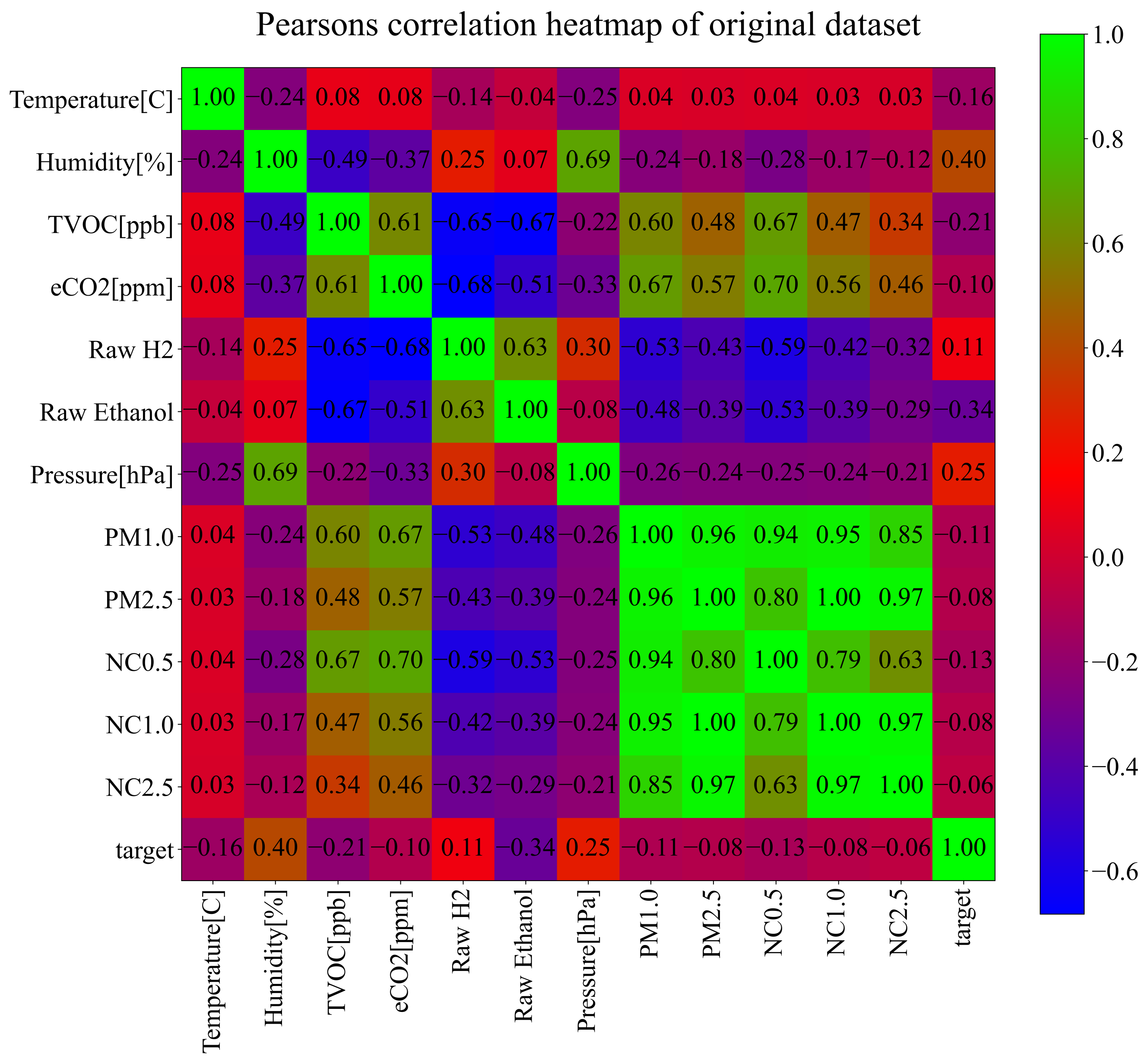
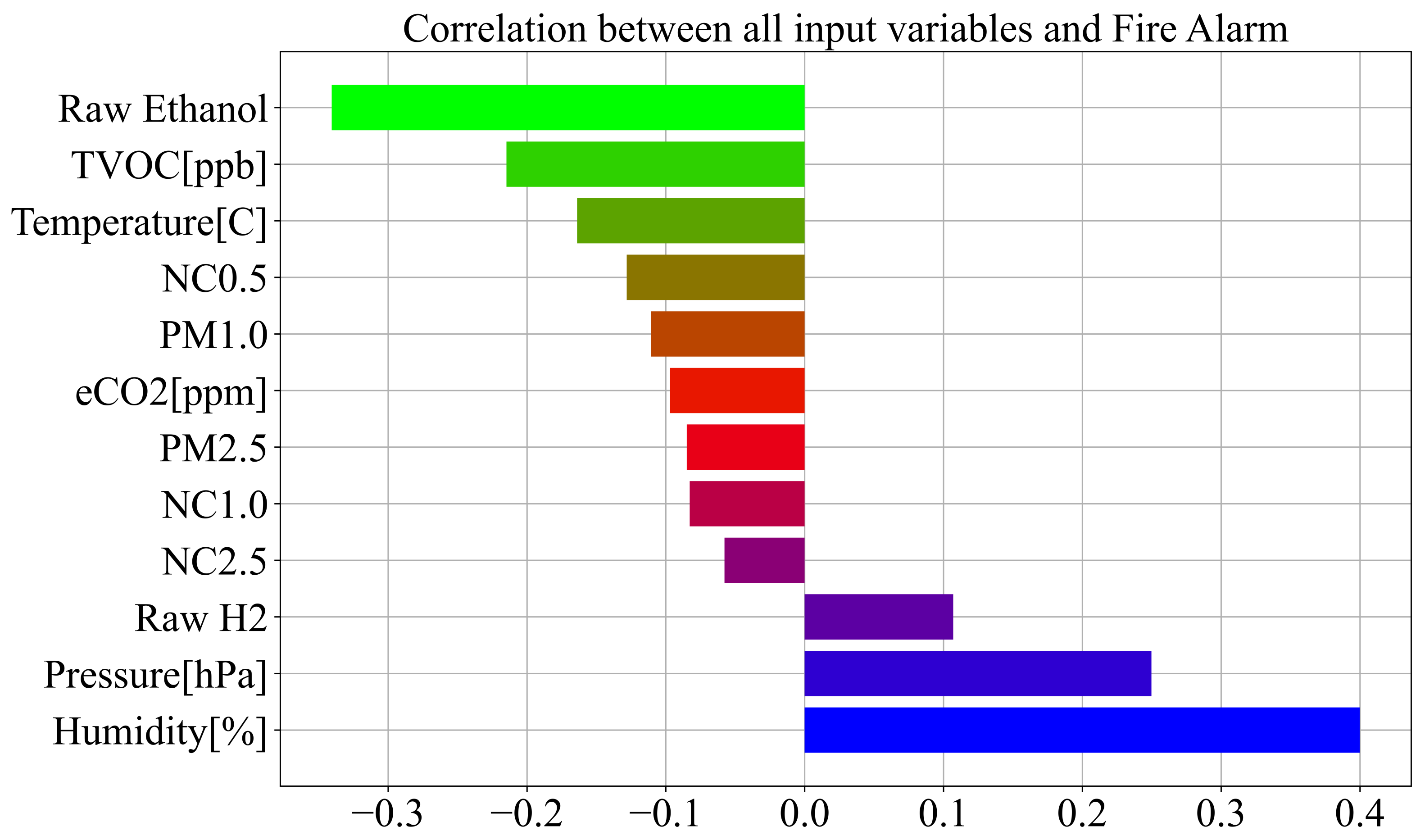
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin, Germany, 2009; pp. 1–4. [Google Scholar]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing imbalanced data–Recommendations for the use of performance metrics. In Proceedings of the 2013 IEEE Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar]
- Prusa, J.; Khoshgoftaar, T.M.; Dittman, D.J.; Napolitano, A. Using random undersampling to alleviate class imbalance on tweet sentiment data. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015; pp. 197–202. [Google Scholar]
- Babikir, M. Imbalanced Data Classification Enhancement Using SMOTE and NearMiss Sampling Techniques. Ph.D. Thesis, Sudan University of Science & Technology, Khartoum, Sudan, 2021. [Google Scholar]
- Pang, Y.; Chen, Z.; Peng, L.; Ma, K.; Zhao, C.; Ji, K. A signature-based assistant random oversampling method for malware detection. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 256–263. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Intelligent Computing, Springer, Shenzhen, China, 12–15 August 2005; pp. 878–887. [Google Scholar]
- Lorencin, I.; Baressi Šegota, S.; Anđelić, N.; Mrzljak, V.; Ćabov, T.; Španjol, J.; Car, Z. On urinary bladder cancer diagnosis: Utilization of deep convolutional generative adversarial networks for data augmentation. Biology 2021, 10, 175. [Google Scholar] [CrossRef] [PubMed]
- Lorencin, I.; Anđelić, N.; Mrzljak, V.; Car, Z. Genetic algorithm approach to design of multi-layer perceptron for combined cycle power plant electrical power output estimation. Energies 2019, 12, 4352. [Google Scholar] [CrossRef] [Green Version]
- Anđelić, N.; Lorencin, I.; Glučina, M.; Car, Z. Mean Phase Voltages and Duty Cycles Estimation of a Three-Phase Inverter in a Drive System Using Machine Learning Algorithms. Electronics 2022, 11, 2623. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Sturm, B.L. Classification accuracy is not enough. J. Intell. Inf. Syst. 2013, 41, 371–406. [Google Scholar] [CrossRef] [Green Version]
- Hand, D.J.; Till, R.J. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- Flach, P.; Kull, M. Precision-recall-gain curves: PR analysis done right. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Count | Mean | Std | Min | Max | GPSC Variable Representation |
|---|---|---|---|---|---|---|
| Temperature [C] | 62,630 | 15.97042 | 14.35958 | −22.01 | 59.93 | |
| Humidity [%] | 48.5395 | 8.865367 | 10.74 | 75.2 | ||
| TVOC [ppl | 1942.058 | 7811.589 | 0 | 60,000 | ||
| eCO [ppm] | 670.021 | 1905.885 | 400 | 60,000 | ||
| Raw H | 12,942.45 | 272.4643 | 10,668 | 13,803 | ||
| Raw Ethanol | 19,754.26 | 609.5132 | 15,317 | 21,410 | ||
| Pressure [hPa] | 938.6276 | 1.331344 | 930.852 | 939.861 | ||
| PM1.0 | 100.5943 | 922.5242 | 0 | 14,333.69 | ||
| PM2.5 | 184.4678 | 1976.306 | 0 | 45,432.26 | ||
| NC0.5 | 491.4636 | 4265.661 | 0 | 61,482.03 | ||
| NC1.0 | 203.5865 | 2214.739 | 0 | 51,914.68 | ||
| NC2.5 | 80.04904 | 1083.383 | 0 | 30,026.44 | ||
| target | 0.714626 | 0.451596 | 0 | 1 | y |
| Count | Mean | Std | Min | Max | |
|---|---|---|---|---|---|
| Temperature [C] | 17,873 | 19.6948031 | 14.9829319 | −22.01 | 59.93 |
| Humidity [%] | 42.9300767 | 11.9628544 | 10.74 | 75.2 | |
| TVOC [ppb] | 4596.58725 | 14,255.5756 | 0 | 60,000 | |
| eCO [ppm] | 962.587255 | 2921.74993 | 400 | 39,185 | |
| Raw H | 12,896.3168 | 432.44162 | 10,668 | 13,803 | |
| Raw Ethanol | 20,082.8235 | 956.339624 | 15,317 | 21,410 | |
| Pressure [hPa] | 938.101383 | 1.23795718 | 931.131 | 939.861 | |
| PM1.0 | 261.982706 | 1439.7256 | 0 | 13,346.69 | |
| PM2.5 | 450.034639 | 2828.77478 | 0 | 41,262.98 | |
| NC0.5 | 1356.28382 | 7155.12266 | 0 | 61,482.03 | |
| NC1.0 | 493.872027 | 3150.39016 | 0 | 47,089.598 | |
| NC2.5 | 178.982259 | 1446.59579 | 0 | 26,916.836 |
| Count | Mean | Std | Min | Max | |
|---|---|---|---|---|---|
| Temperature [C] | 44,757 | 14.4831516 | 13.8255854 | −22.01 | 41.41 |
| Humidity [%] | 50.7795337 | 5.93723882 | 13.36 | 70.28 | |
| TVOC [ppb] | 882.013071 | 548.606072 | 0 | 18,062 | |
| eCO [ppm] | 553.189356 | 1275.26098 | 400 | 60,000 | |
| Raw H | 12,960.8781 | 167.385665 | 10,939 | 13,637 | |
| Raw Ethanol | 19,623.0504 | 307.123385 | 17,809 | 21,109 | |
| Pressure [hPa] | 938.837806 | 1.3090303 | 930.852 | 939.771 | |
| PM1.0 | 36.1464057 | 590.458583 | 0.15 | 14,333.69 | |
| PM2.5 | 78.4178419 | 1493.57607 | 0.16 | 45,432.26 | |
| NC0.5 | 146.111337 | 2144.94205 | 1.06 | 60,442.71 | |
| NC1.0 | 87.6655491 | 1689.24266 | 0.165 | 51,914.68 | |
| NC2.5 | 40.5416272 | 895.171419 | 0.004 | 30,026.438 |
| Dataset Balancing Method | Class 0 | Class 1 | Total |
|---|---|---|---|
| Random undersampling | 17,873 | 17,873 | 35,746 |
| Near Miss-1 | 17,873 | 17,873 | 35,746 |
| Random Oversampling | 44,757 | 44,757 | 89,514 |
| SMOTE | 44757 | 44,757 | 89,514 |
| Borderline SMOTE | 44,757 | 44,757 | 89,514 |
| ADASYN | 44,759 | 44,757 | 89,516 |
| Hyperparameter Name | Lower Bound | Upper Bound |
|---|---|---|
| Population_size | 500 | 2000 |
| number_of_generations | 200 | 300 |
| tournament_size | 100 | 500 |
| init_depth | (3,7) | (7,12) |
| crossover | 0.95 | 1 |
| subtree_mutation | 0.001 | 0.1 |
| point_mutation | 0.001 | 0.1 |
| hoist_mutation | 0.001 | 0.1 |
| stopping_criteria | ||
| max_samples | 0.99 | 1 |
| constant_range | −100,000 | 100,000 |
| parsimony_coeff |
| Dataset Type | GPSC Hyperparameters (Population_Size, Number_of_Generations, Tournament_Size, Initial_Depth, Crossover, Subtree_Muation, Hoist_Mutation, point_Mutation, Stopping_Criteria, Max_Samples, Constant_Range, Parsimony_Coefficient) |
|---|---|
| Random Undersampling | 1477, 221, 406, (5, 12), 0.96, 0.013, 0.013, 0.012, , 0.99, (−13467.47, 36155.63), |
| Near Miss-1 | 1422,173,290, (6, 10), 0.96, 0.0059, 0.0075, 0.021, , 0.99, (−46197.99, 30568.98), |
| Random Oversampling | 654,250, 383, (7, 11), 0.96, 0.023, 0.013, 0.0019, , 0.99, (−76506.62, 63083.63), |
| ADASYN | 952, 252, 290, (7, 8), 0.96, 0.0051, 0.0016, 0.024, , 0.99, (−47945.94, 94095.29), |
| SMOTE | 1111,217,190, (6, 11), 0.97,0.005,0.01,0.0085, ,0.99, (−12456.11, 25100.79), |
| Borderline SMOTE | 1194,108,180, (5, 8), 0.95, 0.014, 0.011, 0.013, , 0.99, (−87036.2, 28148.73), |
| Data Type | Average CPU Execution Time [min] | Length/Depth of Symbolic Expression | |||||
|---|---|---|---|---|---|---|---|
| Random Undersampling | 0.9952 | 0.9952 | 0.9936 | 0.996 | 0.995 | 360 | 188/32 |
| Near Miss-1 | 0.984 | 0.984 | 0.981 | 0.987 | 0.984 | 360 | 460/51 |
| Random Oversampling | 0.978 | 0.978 | 0.985 | 0.97 | 0.977 | 600 | 83/23 |
| ADASYN | 0.979 | 0.979 | 0.985 | 0.973 | 0.979 | 600 | 727/38 |
| SMOTE | 0.998 | 0.998 | 0.999 | 0.998 | 0.998 | 600 | 140/25 |
| Borderline SMOTE | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 600 | 450/43 |
| Evaluation Metric | Value |
|---|---|
| 0.9984 | |
| 0.9986 | |
| 0.9997 | |
| 0.998 | |
| 0.9988 |
| References | Method | Fire or Smoke | Results |
|---|---|---|---|
| [8] | ANFIS | Fire | ACC: 100% |
| [9] | ANN, Naive Bayes | Smoke/Fire | ACC: 97–100% |
| [10] | ANN | Fire/Smoke | ACC: 98.3% |
| [11] | PNN | Fire | ACC: 94.8% |
| [17] | PLS-DA | Fire | Sensitivity: 97% |
| [14] | PLS | Fire | ACC: 92% |
| [15] | Neural Network | Fire | classification error |
| [16] | BP Neural Network | Fire | ACC: 98% |
| [18] | Dempster-Shafer Theory | Fire | ACC: 97–98% |
| [20] | PNN | Fire | ACC: 98.81% |
| This investigation | GPSC | Fire | ACC: 99.84% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Car, Z. The Development of Symbolic Expressions for Fire Detection with Symbolic Classifier Using Sensor Fusion Data. Sensors 2023, 23, 169. https://doi.org/10.3390/s23010169
Anđelić N, Baressi Šegota S, Lorencin I, Car Z. The Development of Symbolic Expressions for Fire Detection with Symbolic Classifier Using Sensor Fusion Data. Sensors. 2023; 23(1):169. https://doi.org/10.3390/s23010169
Chicago/Turabian StyleAnđelić, Nikola, Sandi Baressi Šegota, Ivan Lorencin, and Zlatan Car. 2023. "The Development of Symbolic Expressions for Fire Detection with Symbolic Classifier Using Sensor Fusion Data" Sensors 23, no. 1: 169. https://doi.org/10.3390/s23010169
APA StyleAnđelić, N., Baressi Šegota, S., Lorencin, I., & Car, Z. (2023). The Development of Symbolic Expressions for Fire Detection with Symbolic Classifier Using Sensor Fusion Data. Sensors, 23(1), 169. https://doi.org/10.3390/s23010169