


Abdominal Aortic Thrombus Segmentation in Postoperative Computed Tomography Angiography Images Using Bi-Directional Convolutional Long Short-Term Memory Architecture
 , ,
, ,  ,
,  , and
, and
Abstract
:1. Introduction
- The intensity values of thrombus ROIs tend to overlap with those of adjacent tissues and organs (Figure 1a);
- The geometric shape of thrombus ROIs tends to be irregular, and its position could appear across any part of the abdominal aortic passway (Figure 1b,c);
- Parts of ROIs tend to be occluded by metal artifacts introduced by stent grafts. (Figure 1c,d).
2. Related work
2.1. Segmentation Methods for Thrombus ROIs in CTA Image Volumes
2.2. CLSTM for ROI Segmentation
3. Bi-CLSTM-Based Segmentation Method for Thrombus ROIs
3.1. Mask R-CNN for Spatial Attention Map
3.2. Bi-CLSTM for Volumetric Coherence between an Image Sequence
3.3. Experiment Settings
4. Results
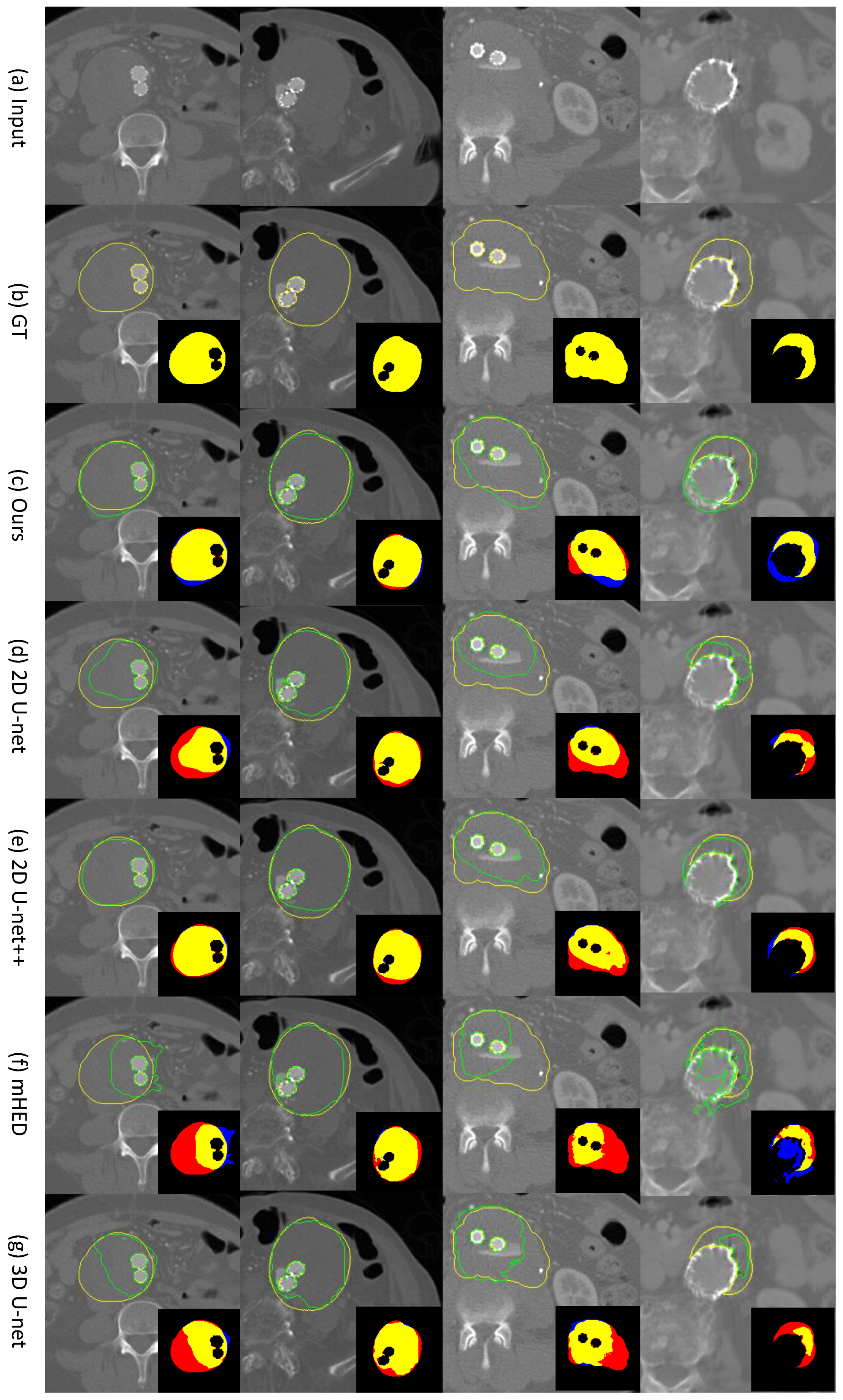
4.1. Comparison of Our Bi-CLSTM Method with Different 2D and 3D-Based CNN Methods for Thrombus ROI Segmentation
4.2. Ablation Study of Our Bi-CLSTM-Based Method
5. Discussion and Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, L.J.; Prabhakar, A.M.; Kwolek, C.J. Current status of the treatment of infrarenal abdominal aortic aneurysms. Cardiovasc. Diagn. Ther. 2018, 8, S191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Acosta, S.; Ögren, M.; Bengtsson, H.; Bergqvist, D.; Lindblad, B.; Zdanowski, Z. Increasing incidence of ruptured abdominal aortic aneurysm: A population-based study. J. Vasc. Surg. 2006, 44, 237–243. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vorp, D.A.; Geest, J.P.V. Biomechanical determinants of abdominal aortic aneurysm rupture. Arterioscler. Thromb. Vasc. Biol. 2005, 25, 1558–1566. [Google Scholar] [CrossRef] [Green Version]
- Tuns, F.; Iurcut, A.; Chirilean, I.; Crivii, C.; Damian, A. Comparative Bibliographic Study Regarding the Collaterals of Ascending Aorta and Aortic Cross in Humans, Swine and Equine. Sci. Work Ser. C Vet. Med. 2013, 59, 47–50. [Google Scholar]
- National Institute for Health and Care Excellence. Abdominal Aortic Aneurysm: Diagnosis and Management; NICE Guideline [NG156]; National Institute for Health and Care Excellence: London, UK, 2020. [Google Scholar]
- Varkevisser, R.R.; O’Donnell, T.F.; Swerdlow, N.J.; Liang, P.; Li, C.; Ultee, K.H.; Pothof, A.B.; De Guerre, L.E.; Verhagen, H.J.; Schermerhorn, M.L. Fenestrated endovascular aneurysm repair is associated with lower perioperative morbidity and mortality compared with open repair for complex abdominal aortic aneurysms. J. Vasc. Surg. 2019, 69, 1670–1678. [Google Scholar] [CrossRef]
- De Bruin, J.L.; Baas, A.F.; Buth, J.; Prinssen, M.; Verhoeven, E.L.; Cuypers, P.W.; van Sambeek, M.R.; Balm, R.; Grobbee, D.E.; Blankensteijn, J.D. Long-term outcome of open or endovascular repair of abdominal aortic aneurysm. N. Engl. J. Med. 2010, 362, 1881–1889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, K.; Johnson, R.K.; Yin, Y.; Wahle, A.; Olszewski, M.E.; Scholz, T.D.; Sonka, M. Three-dimensional thrombus segmentation in abdominal aortic aneurysms using graph search based on a triangular mesh. Comput. Biol. Med. 2010, 40, 271–278. [Google Scholar] [CrossRef] [Green Version]
- Freiman, M.; Esses, S.J.; Joskowicz, L.; Sosna, J. An iterative model-constrained graph-cut algorithm for abdominal aortic aneurysm thrombus segmentation. In Proceedings of the 2010 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Rotterdam, The Netherlands, 14–17 April 2010; pp. 672–675. [Google Scholar]
- Lareyre, F.; Adam, C.; Carrier, M.; Dommerc, C.; Mialhe, C.; Raffort, J. A fully automated pipeline for mining abdominal aortic aneurysm using image segmentation. Sci. Rep. 2019, 9, 13750. [Google Scholar] [CrossRef] [Green Version]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Seo, H.; Huang, C.; Bassenne, M.; Xiao, R.; Xing, L. Modified U-Net (mU-Net) with incorporation of object-dependent high level features for improved liver and liver-tumor segmentation in CT images. IEEE Trans. Med. Imaging 2019, 39, 1316–1325. [Google Scholar] [CrossRef] [Green Version]
- López-Linares, K.; Aranjuelo, N.; Kabongo, L.; Maclair, G.; Lete, N.; Ceresa, M.; García-Familiar, A.; Macía, I.; Ballester, M.A.G. Fully automatic detection and segmentation of abdominal aortic thrombus in post-operative CTA images using deep convolutional neural networks. Med. Image Anal. 2018, 46, 202–214. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.T.; Brooks, R.; Hahn, S.; Chen, J.; Buch, V.; Kotecha, G.; Andriole, K.P.; Ghoshhajra, B.; Pinto, J.; Vozila, P.; et al. DeepAAA: Clinically applicable and generalizable detection of abdominal aortic aneurysm using deep learning. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin, Germany, 2019; pp. 723–731. [Google Scholar]
- Caradu, C.; Spampinato, B.; Vrancianu, A.M.; Bérard, X.; Ducasse, E. Fully automatic volume segmentation of infrarenal abdominal aortic aneurysm computed tomography images with deep learning approaches versus physician controlled manual segmentation. J. Vasc. Surg. 2021, 74, 246–256. [Google Scholar] [CrossRef] [PubMed]
- Lareyre, F.; Adam, C.; Carrier, M.; Raffort, J. Automated segmentation of the human abdominal vascular system using a hybrid approach combining expert system and supervised deep learning. J. Clin. Med. 2021, 10, 3347. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Hwang, B.; Kim, J.; Lee, S.; Kim, E.; Kim, J.; Jung, Y.; Hwang, H. Automatic Detection and Segmentation of Thrombi in Abdominal Aortic Aneurysms Using a Mask Region-Based Convolutional Neural Network with Optimized Loss Functions. Sensors 2022, 22, 3643. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin, Germany, 2016; pp. 424–432. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin, Germany, 2018; pp. 3–11. [Google Scholar]
- Lalys, F.; Yan, V.; Kaladji, A.; Lucas, A.; Esneault, S. Generic thrombus segmentation from pre-and post-operative CTA. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1501–1510. [Google Scholar] [CrossRef]
- Maiora, J.; Graña, M. Abdominal CTA image analisys through active learning and decision random forests: Aplication to AAA segmentation. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Hong, H.A.; Sheikh, U. Automatic detection, segmentation and classification of abdominal aortic aneurysm using deep learning. In Proceedings of the 2016 IEEE 12th International Colloquium on Signal Processing & Its Applications (CSPA), Melaka, Malaysia, 4–6 March 2016; pp. 242–246. [Google Scholar]
- Ali, F.; El-Sappagh, S.; Kwak, D. Fuzzy ontology and LSTM-based text mining: A transportation network monitoring system for assisting travel. Sensors 2019, 19, 234. [Google Scholar] [CrossRef] [Green Version]
- Crivellari, A.; Beinat, E. Trace2trace—A feasibility study on neural machine translation applied to human motion trajectories. Sensors 2020, 20, 3503. [Google Scholar] [CrossRef]
- Sagheer, A.; Hamdoun, H.; Youness, H. Deep LSTM-based transfer learning approach for coherent forecasts in hierarchical time series. Sensors 2021, 21, 4379. [Google Scholar] [CrossRef]
- Seydgar, M.; Alizadeh Naeini, A.; Zhang, M.; Li, W.; Satari, M. 3-D convolution-recurrent networks for spectral-spatial classification of hyperspectral images. Remote Sens. 2019, 11, 883. [Google Scholar] [CrossRef] [Green Version]
- Kitrungrotsakul, T.; Han, X.H.; Iwamoto, Y.; Takemoto, S.; Yokota, H.; Ipponjima, S.; Nemoto, T.; Xiong, W.; Chen, Y.W. A cascade of 2.5 D CNN and bidirectional CLSTM network for mitotic cell detection in 4D microscopy image. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 18, 396–404. [Google Scholar] [CrossRef] [PubMed]
- Jeong, J.G.; Choi, S.; Kim, Y.J.; Lee, W.S.; Kim, K.G. Deep 3D attention CLSTM U-Net based automated liver segmentation and volumetry for the liver transplantation in abdominal CT volumes. Sci. Rep. 2022, 12, 6370. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Vardulaki, K.; Walker, N.; Day, N.; Duffy, S.; Ashton, H.; Scott, R. Quantifying the risks of hypertension, age, sex and smoking in patients with abdominal aortic aneurysm. J. Br. Surg. 2000, 87, 195–200. [Google Scholar] [CrossRef]
- Harthun, N.L. Current issues in the treatment of women with abdominal aortic aneurysm. Gend. Med. 2008, 5, 36–43. [Google Scholar] [CrossRef] [PubMed]
- Torchvision. Available online: https://pytorch.org/vision/stable/index.html (accessed on 9 November 2022).
- Burt, T.; Button, K.; Thom, H.; Noveck, R.; Munafò, M.R. The Burden of the “False-Negatives” in Clinical Development: Analyses of Current and Alternative Scenarios and Corrective Measures. Clin. Transl. Sci. 2017, 10, 470–479. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| TO ↑ | Dice ↑ | Jaccard ↑ | FN ↓ | FP ↓ | |
|---|---|---|---|---|---|
| Our Bi-CLSTM | 0.8931 | 0.8730 | 0.7809 | 0.1069 | 0.1358 |
| 2D Segmentation Approaches | |||||
| 2D U-net | 0.8297 | 0.8375 | 0.7334 | 0.1703 | 0.1277 |
| 2D U-net++ | 0.8600 | 0.8655 | 0.7703 | 0.1400 | 0.1141 |
| mHED | 0.6210 | 0.6488 | 0.4949 | 0.3790 | 0.2610 |
| 3D Segmentation Approaches | |||||
| 3D U-net | 0.7545 | 0.7145 | 0.5768 | 0.2455 | 0.2687 |
| TO ↑ | Dice ↑ | Jaccard ↑ | FN ↓ | FP ↓ | ||
|---|---|---|---|---|---|---|
| Mask R-CNN (ours) | Without Bi-CLSTM | 0.8762 | 0.8636 | 0.7666 | 0.1238 | 0.1383 |
| With Bi-CLSTM | 0.8931 | 0.8730 | 0.7809 | 0.1069 | 0.1358 | |
| 2D U-net | Without Bi-CLSTM | 0.8297 | 0.8375 | 0.7334 | 0.1703 | 0.1277 |
| With Bi-CLSTM | 0.8399 | 0.8319 | 0.7253 | 0.1601 | 0.1483 | |
| 2D U-net++ | Without Bi-CLSTM | 0.8600 | 0.8655 | 0.7703 | 0.1400 | 0.1141 |
| With Bi-CLSTM | 0.8856 | 0.8570 | 0.7563 | 0.1144 | 0.1567 | |
| mHED | Without Bi-CLSTM | 0.6210 | 0.6488 | 0.4949 | 0.3790 | 0.2610 |
| With Bi-CLSTM | 0.7234 | 0.7110 | 0.5671 | 0.2766 | 0.2459 |
| Image Sequence Length of Bi-CLSTM | TO | Dice | Jaccard | FN | FP |
|---|---|---|---|---|---|
| 3 | 0.8921 | 0.8723 | 0.7798 | 0.1079 | 0.1365 |
| 5 | 0.8931 | 0.8730 | 0.7809 | 0.1069 | 0.1358 |
| 7 | 0.8937 | 0.8712 | 0.7782 | 0.1063 | 0.1390 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, Y.; Kim, S.; Kim, J.; Hwang, B.; Lee, S.; Kim, E.Y.; Kim, J.H.; Hwang, H. Abdominal Aortic Thrombus Segmentation in Postoperative Computed Tomography Angiography Images Using Bi-Directional Convolutional Long Short-Term Memory Architecture. Sensors 2023, 23, 175. https://doi.org/10.3390/s23010175
Jung Y, Kim S, Kim J, Hwang B, Lee S, Kim EY, Kim JH, Hwang H. Abdominal Aortic Thrombus Segmentation in Postoperative Computed Tomography Angiography Images Using Bi-Directional Convolutional Long Short-Term Memory Architecture. Sensors. 2023; 23(1):175. https://doi.org/10.3390/s23010175
Chicago/Turabian StyleJung, Younhyun, Suhyeon Kim, Jihu Kim, Byunghoon Hwang, Sungmin Lee, Eun Young Kim, Jeong Ho Kim, and Hyoseok Hwang. 2023. "Abdominal Aortic Thrombus Segmentation in Postoperative Computed Tomography Angiography Images Using Bi-Directional Convolutional Long Short-Term Memory Architecture" Sensors 23, no. 1: 175. https://doi.org/10.3390/s23010175
APA StyleJung, Y., Kim, S., Kim, J., Hwang, B., Lee, S., Kim, E. Y., Kim, J. H., & Hwang, H. (2023). Abdominal Aortic Thrombus Segmentation in Postoperative Computed Tomography Angiography Images Using Bi-Directional Convolutional Long Short-Term Memory Architecture. Sensors, 23(1), 175. https://doi.org/10.3390/s23010175