
NG-GAN: A Robust Noise-Generation Generative Adversarial Network for Generating Old-Image Noise



Abstract
:1. Introduction
- We propose a noise-generation framework for old images and videos using a no-reference PIQE metric and an unpaired clean image to generate a noisy image based on the value of the PIQE metric.
- We introduce a recurrent residual convolutional and attention mechanism-based robust framework, NG-GAN, that successfully imitates the noisy pattern of degraded images.
- When state-of-the-art (SOTA) video restorers are trained on the datasets generated by the NG-GAN, they can effectively produce clean videos from noisy ones in terms of the peak signal-to-noise (PSNR) and structural similarity index measure (SSIM).
2. Related Works
3. Proposed Method
3.1. Problems in Degraded Old Images
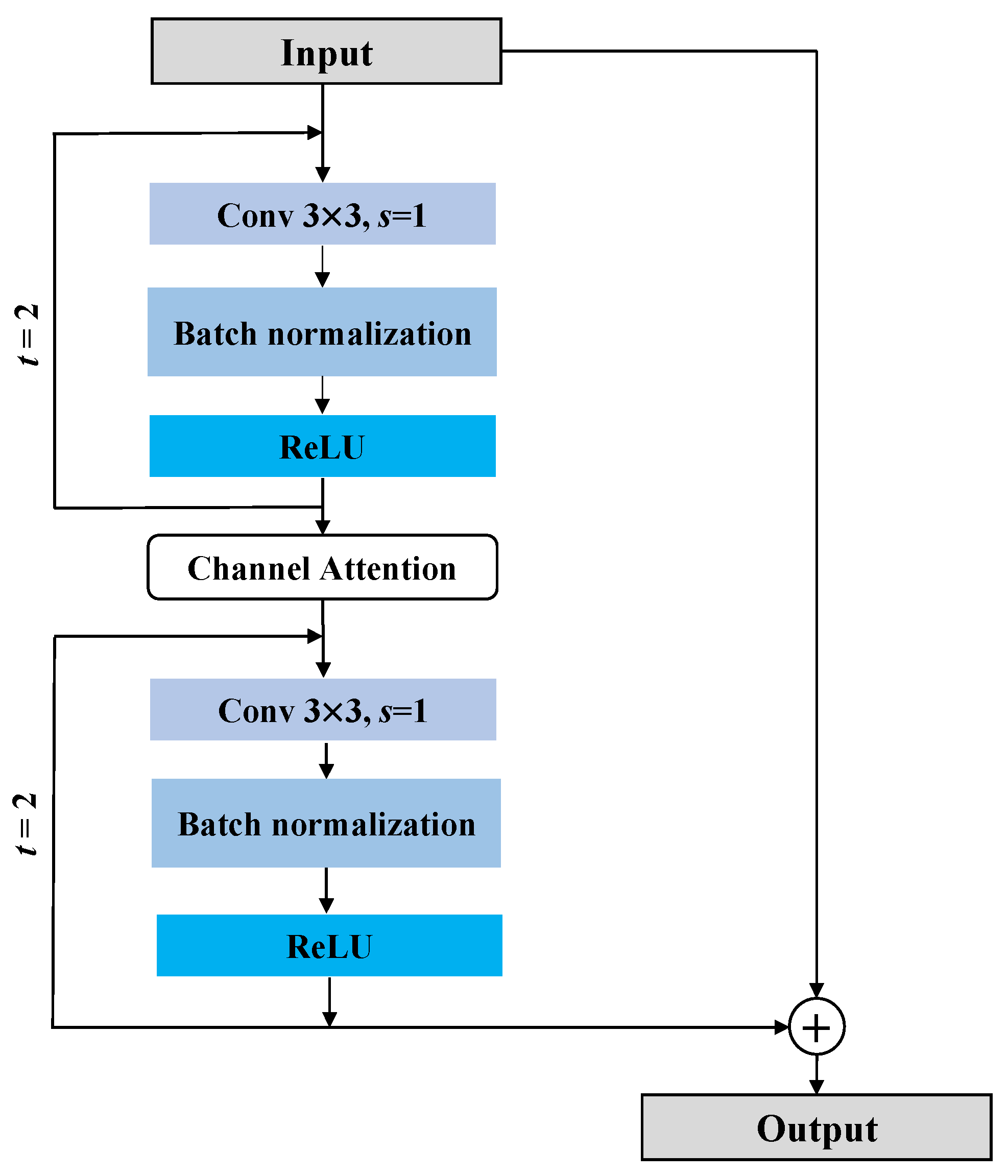
3.2. Proposed Network Architecture
3.3. Generator Architecture
3.4. Discriminator Architecture
4. Experimental Results
4.1. Datasets
4.2. Qualitative Comparison of Denoised Videos
4.3. Quantitative Comparisons for Denoised Old Images
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buades, A.; Coll, B.; Morel, J.-M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, C.; Xiong, Z.; Tian, X.; Wu, F. Deep Boosting for Image Denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11215. [Google Scholar]
- Liu, Y.; Anwar, S.; Zheng, L.; Tian, Q. GradNet Image Denoising. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2140–2149. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, PI, USA, 16–21 June 2012. [Google Scholar]
- Lefkimmiatis, S. Non-local Color Image Denoising with Convolutional Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Restoration. IEEE Trans. Pattern. Anal. Mach. Intell. 2021, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning Delicate Local Representations for Multi-person Pose Estimation. In Lecture Notes in Computer Science (LNCS); Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Volume 12348. [Google Scholar]
- Luo, Z.; Wang, Z.; Cai, Y.; Wang, G.; Wang, L.; Huang, Y.; Zhou, E.; Tan, T.; Sun, J. Efficient Human Pose Estimation by Learning Deeply Aggregated Representations. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Cai, Y.; Lin, J.; Hu, X.; Wang, H.; Yuan, X.; Zhang, Y.; Timofte, R.; Gool, L.V. Mask-guided spectral-wise transformer for efficient hyperspectral image reconstruction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Cha, S.; Park, T.; Kim, B.; Baek, J.; Moon, T. GAN2GAN: Generative noise learning for blind denoising with single noisy images. arXiv 2019, arXiv:1905.10488. [Google Scholar] [CrossRef]
- Krull, A.; Buchholz, T.-O.; Jug, F. Noise2Void—Learning denoising from single noisy images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1692–1700. [Google Scholar]
- Plötz, T.; Roth, S. Benchmarking denoising algorithms with real photographs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2750–2759. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network based noise modeling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hong, Z.; Fan, X.; Jiang, T.; Feng, J. End-to-end unpaired image denoising with conditional adversarial networks. Proc. AAAI Conf. Artif. Intell. 2020, 34, 4140–4149. [Google Scholar] [CrossRef]
- Abdelhamed, A.; Brubaker, M.; Brown, M. Noise Flow: Noise modeling with conditional normalizing flows. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 16 April 2015. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA; Volume 2, pp. 2672–2680. [Google Scholar]
- Hu, X.; Wang, H.; Cai, Y.; Zhao, X.; Zhang, Y. Pyramid orthogonal attention network based on dual self-similarity for accurate mr image super-resolution. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzen, China, 5–9 July 2021. [Google Scholar]
- Zheng, C.; Cham, T.-J.; Cai, J. Pluralistic image completion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, C.; Wand, M. Combining Markov random fields and convolutional neural networks for image synthesis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2479–2486. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised dual learning for image-to-image translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Zhao, R.; Lun, D.P.-K.; Lam, K.-M. NTGAN: Learning blind image denoising without clean reference. In Proceedings of the British Machine Vision Conference (BMVC), Virtual. 7–10 September 2020. [Google Scholar]
- Yue, Z.; Zhao, Q.; Zhang, L.; Meng, D. Dual adversarial network: Toward real-world noise removal and noise generation. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part X; Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–58. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar]
- Wei, K.; Fu, Y.; Yang, J.; Huang, H. A physics-based noise formation model for extreme low-light raw denoising. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2755–2764. [Google Scholar]
- Holst, G.C. CCD Arrays, Cameras, and Displays; Society of Photo Optical: Bellingham, WA, USA, 1996. [Google Scholar]
- Nah, S.; Baik, S.; Hing, S.; Moon, G.; Son, S.; Timofte, R.; Lee, K.M. NTIRE 2019 Challenge on Video Deblurring and Super-Resolution: Dataset and Study. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on single image super-resolution: Dataset and study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chan, K.C.K.; Wang, X.; Yu, K.; Dong, C.; Loy, C.C. BasicVSR: The search for essential components in video super-resolution and beyond. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4945–4954. [Google Scholar]
- Zhou, S.; Xiao, T.; Yang, Y.; Feng, D.; He, Q.; He, W. GeneGAN: Learning object transfiguration and object subspace from unpaired data. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017; Kim, T.K., Zafeiriou, S., Brostow, G., Mikolajczyk, K., Eds.; BMVA Press: Blue Mountains, ON, Canada, 2017; pp. 111.1–111.13. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration with Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Jang, G.; Lee, W.; Son, S.; Lee, K. C2N: Practical generative noise modeling for real-world denoising. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual. 11–17 October 2021. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Chan, K.C.K.; Zhou, S.; Xu, X.; Loy, C.C. BasicVSR++: Improving video super-resolution with enhanced propagation and alignment. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5962–5971. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video Enhancement with Task-Oriented Flow. Int. J. Comput. Vis. 2019, 127, 1106–1125. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | PSNR (dB) | SSIM | |
|---|---|---|---|
| BasicVSR | Pretrained BasicVSR [32] | 24.91 | 0.703 |
| BasicVSR (CycleGAN) [18] | 24.93 | 0.698 | |
| BasicVSR (C2N) [45] | 25.27 | 0.736 | |
| BasicVSR (Proposed NG-GAN) | 25.48 | 0.739 | |
| BasicVSR++ | Pretrained BasicVSR++ [50] | 25.21 | 0.727 |
| BasicVSR++ (CycleGAN) [18] | 25.03 | 0.705 | |
| BasicVSR++ (C2N) [45] | 25.81 | 0.768 | |
| BasicVSR++ (Proposed NG- GAN) | 25.89 | 0.781 | |
| Others | GCBD [44] | 24.22 | 0.726 |
| UIDNet [14] | 25.17 | 0.694 | |
| Metric | CycleGAN | C2N | NG-GAN (Proposed Method) |
|---|---|---|---|
| KL-divergence | 0.3436 | 0.2195 | 0.1879 |
| Methods | Proposed NG-GAN | PIQE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Network | Loss Functions | ||||||||
| R2CL | CBAM | PIQE Guided | Cycle Consistency Loss | VGG-19 Loss | PIQE Loss | SSIM Loss | Discriminator Loss | ||
| Baseline (CycleGAN) | ✖ | ✖ | ✖ | ✓ | ✖ | ✖ | ✖ | ✓ | 22.73 |
| (a) | ✓ | ✖ | ✖ | ✓ | ✓ | ✖ | ✓ | ✓ | 24.49 |
| (b) | ✓ | ✓ | ✖ | ✓ | ✓ | ✖ | ✓ | ✓ | 27.36 |
| (c) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 29.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, S.; Lee, B. NG-GAN: A Robust Noise-Generation Generative Adversarial Network for Generating Old-Image Noise. Sensors 2023, 23, 251. https://doi.org/10.3390/s23010251
Hossain S, Lee B. NG-GAN: A Robust Noise-Generation Generative Adversarial Network for Generating Old-Image Noise. Sensors. 2023; 23(1):251. https://doi.org/10.3390/s23010251
Chicago/Turabian StyleHossain, Sadat, and Bumshik Lee. 2023. "NG-GAN: A Robust Noise-Generation Generative Adversarial Network for Generating Old-Image Noise" Sensors 23, no. 1: 251. https://doi.org/10.3390/s23010251
APA StyleHossain, S., & Lee, B. (2023). NG-GAN: A Robust Noise-Generation Generative Adversarial Network for Generating Old-Image Noise. Sensors, 23(1), 251. https://doi.org/10.3390/s23010251