1. Introduction
Industrial maintenance inspection is a critical task for ensuring the efficient and safe operation of industrial facilities. The inspection process entails diagnosing, inspecting and repairing equipment and machinery to prevent breakdowns and extend their operational lifetime. However, traditional inspection methods are becoming increasingly ineffective and time-consuming as the complexity and automation of industrial systems is increasing. Because of this, innovative solutions are required to improve the efficiency and effectiveness of industrial inspection [
1].
In recent years, Computer Vision (CV) has become increasingly important for industrial applications. It has been identified as a key technology for increasing productivity, lowering costs and improving safety in a variety of industries. In industry, CV is used to extract relevant information from visual data using cameras, sensors, Machine Learning (ML) and Deep Learning (DL) algorithms. These data can then be used for decision making, quality control, predictive maintenance and other industrial applications [
2].
With the rapid advancements in Artificial Intelligence (AI) and CV, DL models have emerged as a viable alternative to manual inspection methods. These models can analyze large amounts of visual data quickly and accurately, allowing the detection and localization of defects, anomalies and other problems with more precision and consistency than human inspectors. In recent years, DL models have demonstrated promising results in various industrial inspection tasks, such as defect detection, anomaly localization and quality control [
3].
DL models employ object detection and classification techniques to identify anomalies and defects in infrastructure and various industrial equipment. By analyzing images or video streams, these techniques can pinpoint and locate specific features or flaws in the equipment or infrastructure. These models are trained utilizing extensive datasets of labeled images. Object detection constitutes a fundamental challenge in computer vision, with the primary objective of identifying objects of interest within images or videos [
4].
In fact, several object detectors have been proposed in the literature in recent years, such as YOLO [
5], SSD [
6], RetinaNet [
7], Faster R-CNN [
8], Mask R-CNN [
9] and Cascade R-CNN [
10]. Moreover, significant progress has been made in computer vision and object detection over the years, with DL models achieving State-of-the-Art (SoTA) results on benchmark datasets. However, these models are frequently evaluated in controlled settings using high-quality, well-annotated images that may not accurately represent real-world conditions.
SoTA object detection models are not specifically designed for industrial inspection tasks and their performance in complex, real-world scenarios may be sub-optimal. In manufacturing environments, for example, DL models may struggle to detect minor defects on surfaces or locate objects that are partially hidden by other items. Similarly, in warehouse settings, these models may struggle to identify objects that are partially hidden or at different distances from the camera. Such challenges highlight the importance of an object detection architecture that excels at accurately identifying and locating objects in industrial inspection tasks, regardless of the complexities inherent in real-world situations.
The You Only Look Once (YOLO) object detector family is a well-known group of single-stage DL models that enable real-time object detection in images and videos. The YOLO detector family has evolved over time, with different iterations achieving SoTA performance on object detection benchmarks [
11]. Despite the improvements in YOLO versions and other object detectors, they are based only on CNN traditional architectures. Although CNNs can extract relevant information from input data, their ability to selectively focus on the most important information is often limited [
12].
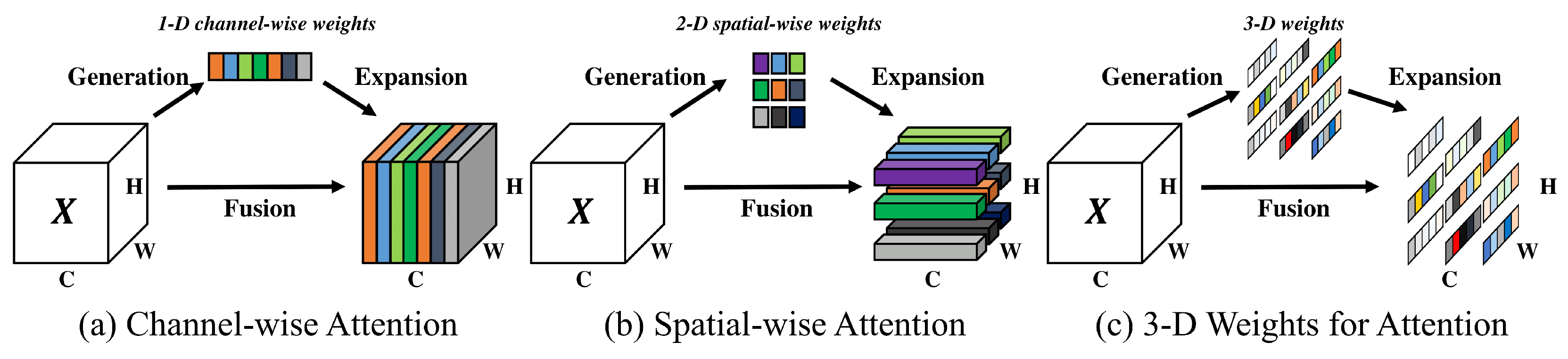
Attention Mechanisms are a fundamental component of DL models, particularly for tasks such as natural language processing and CV. Attention mechanisms are designed to help models selectively focus on relevant parts of input data, allowing them to learn important patterns and features in a more efficient manner [
13]. In CV, attention mechanisms have shown significant improvements in tasks such as object detection, image classification and image segmentation. By selectively attending to parts of an image, attention mechanisms can help models focus on relevant features, such as object boundaries or salient regions and ignore irrelevant information, such as background noise or occlusions. This can lead to improved accuracy and faster training times [
13,
14].
Recent advances in attention mechanisms have also resulted in the creation of novel attention modules, such as the Simple Parameter-free Attention Module (SimAM), a lightweight and efficient attention mechanism that can be easily incorporated into existing DL architectures. Such attention mechanisms have been shown to significantly improve the performance of object detection models, particularly for small object detection and multi-scale object detection, both of which are critical for industrial inspection applications [
15].
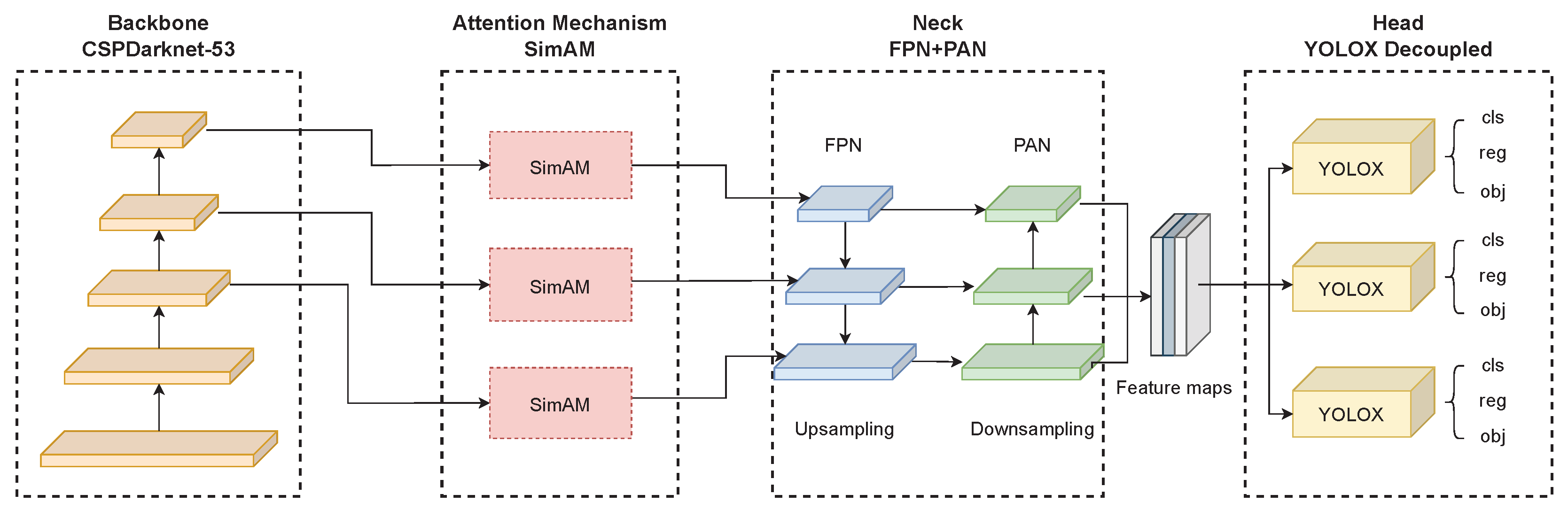
In this paper, we propose the ‘YOLOX-Ray’, a novel DL architecture that is built upon the YOLO family of detectors and designed specifically for industrial maintenance tasks. The main contributions of this paper are as follows:
We introduce the SimAM attention mechanism into the YOLOX’s backbone. This enables a better feature extraction and feature fusion on the architecture’s neck;
The proposed architecture implements a novel loss function, Alpha-IoU, which enables better bounding-box regression for small object detection.
The remaining sections of this paper are structured as follows:
Section 2 provides a review of related work within the topic under study. The proposed method is detailed in
Section 3.
Section 4 presents the case studies, experimental tests, results and analysis of the ablation study. Finally, conclusions are outlined in
Section 5.
4. Experimental Tests and Results
This section discusses the experimental tests that were performed in order to evaluate the proposed architecture’s performance in real-world industrial inspection tasks.
Given the multiple challenges and complexities inherent in industrial inspection tasks, such as changing lighting conditions, occlusions and the detection of small objects, it is critical to evaluate the proposed architecture in real-world scenarios. These experiments were carried out on three datasets representing various industrial applications to ensure that the YOLOX-Ray architecture performs effectively across a wide range of industrial inspection tasks.
The three case studies of industrial inspections are as follows:
Case Study A: Solar Farm Thermal Inspection (available in [
41]);
Case Study B: Infrastructure Integrity Inspection (available in [
42]);
Case Study C: Bridge Cables Inspection (available in [
43]).
To train and test the YOLOX-Ray architecture, a GPU-powered machine was used. The experiments were carried out on a machine equipped with the following resources:
When compared to a CPU, using a GPU significantly accelerates DL model training and inference because GPUs are optimized for parallel computations, which are critical for the numerous operations required by DL algorithms. Furthermore, the open-source machine learning framework PyTorch was used to create the YOLOX-Ray architecture.
This section will also cover the YOLOX-Ray network hyperparameter specification, dataset structure for each case study, experimental tests and results and an ablation study to evaluate the impact of different components on overall performance.
4.1. Datasets Structure
The datasets for each case study were obtained from the Roboflow-100, a collection of curated multi-domain object detection datasets made available for research purposes. The Roboflow-100 datasets are diverse and cover a wide range of object detection applications, making them a popular choice among computer vision researchers and practitioners [
44]. In contrast to other widely used benchmark datasets like COCO and PASCAL VOC, Roboflow-100 offers a wider variety of object classes, leading to a more flexible environment for object detection.
Furthermore, the images in the datasets were divided into three subsets, training, validation and testing, with 70% allocated to training, 20% allocated to validation and 10% allocated to testing. This division enables a more thorough evaluation of the model’s performance as well as a more precise estimation of its effectiveness on new data.
One of the main purposes of this study is to demonstrate the effectiveness and adaptability of the YOLOX-Ray architecture in several industrial inspection scenarios. Since there is no direct correlation between the proposed method and the characteristics of the dataset, the ability of the architecture to have a good perform on diverse datasets is a proof its versatility. The implementation of the Alpha-
IoU loss function helps in multi-scale object detection [
38], making the architecture suitable for detecting objects with different sizes and scales. Additionally, by resizing all images to a consistent size of 640 × 640, it is ensured that the architecture would focus on detecting relevant objects within the images while maintaining a consistent input size for each dataset.
The annotations were provided in the PASCAL VOC format, which is a widely used format for object detection annotations. Considering the dataset and the annotation format selection, the YOLOX-Ray was evaluated in a more realistic and practical context rather than in a controlled benchmark environment.
Table 2 presents the technical details of the datasets used in each case study.
Figure 4 illustrates the datasets sample images of each case study, where (a), (b) and (c) correspond to Case Studies A, B and C, respectively.
In
Figure 4, image (a) serves as an example for Case Study A; image (b) represents a sample for Case Study B; and image (c) illustrates a sample from the Case Study C dataset.
4.2. Network Hyperparameters
The YOLOX-Ray architecture’s hyperparameters, which are essential configuration choices that can significantly impact the model’s performance, were meticulously selected to achieve optimal results.
Table 3 illustrates the network hyperparameters configured for the training process.
The data augmentation techniques used for training the YOLOX-Ray model are MOSAIC and MixUP, which are the original YOLOX architecture’s base augmentations. Hue, Saturation and Value (HSV) enhancements, as well as horizontal and vertical flip augmentations, were also included. These methods are commonly used in CV tasks to improve the model’s ability to generalize to previously unseen data [
45].
The authors of the Alpha-
IoU loss function proved that a
value of 3 produced the best results [
36].
The hyperparameters were chosen based on their proven effectiveness in previous DL research and were also further optimized during the training process to ensure optimal performance for the YOLOX-Ray architecture.
In this work, the original YOLOX pre-trained models were not used as initial weights, since the usage of initial weights led to overfitting during the initial epochs of the training process. The problem of overfitting may manifest itself when it turns out that the pre-trained models are not directly related to the datasets used for such study. Consequently, to avoid this problem, we opted to train the algorithm from scratch for each case study, allowing the model to learn relevant features without being influenced by unrelated pre-existing weights.
4.3. Model Size
The performance of the YOLOX-Ray model was evaluated using four distinct model sizes: YOLOX-Ray-s, YOLOX-Ray-m, YOLOX-Ray-l and YOLOX-Ray-x. In CV, the depth of a DNN refers to the number of layers in the network architecture. A deeper network has more layers, which allows it to learn more complex data representations. In contrast, the network’s width refers to the number of neurons in each layer. A larger network has more neurons, allowing it to learn more detailed data information [
46].
As a result, the depth and the width of the network are determined by the available computational resources, where the model will be deployed. The four models (YOLOX-Ray-s, YOLOX-Ray-m, YOLOX-Ray-l and YOLOX-Ray-x) were created by changing the network depth and width values in order to provide a set of models with different computational requirements and expected performance. The lightest and fastest model (YOLOX-Ray-s) has the lowest expected values. The largest model, on the other hand (YOLOX-Ray-x), is the heaviest and slowest, but has the best expected performance in terms of .
Table 4 presents the network depth and width values for each model size.
The depth and width values presented in
Table 4 were derived from the model scaling techniques proposed in YOLOv5 by Ultralytics [
19] and subsequently adopted in YOLOX by its authors [
23]. In this work, the same logic for model scaling was applied to define the values for depth and width, considering different model sizes of the YOLOX-Ray architecture.
4.4. Performance Metrics
For the evaluation metrics, the
IoU score is used as a threshold for determining whether a prediction is considered a True Positive (TP), True Negative (TN), False Positive (FP) or False Negative (FN). For example, if the
IoU score between a predicted bounding box and the corresponding
GT bounding box is greater than a certain threshold (e.g., 0.5), the prediction is considered a TP. On the other hand, if the
IoU score is below the threshold, the prediction is considered an FP [
47].
In this paper, the YOLOX-Ray models in terms of Precision (
P), Recall (
R),
over an
score of 0.5 (
),
on an
threshold of 0.5 to 0.95 (
)
where
is the number of false negative detections,
is the number of correctly predicted positive instances and
is the number of false positive predictions.
For calculating
[
47], Equation (
17) is used,
Equation (
18) is used for calculating
scores.
where
N is the number of classes in the target dataset and
is the average precision for class
i.
The
metric is widely used as a primary evaluation measure in object detection. It provides an overall evaluation of the performance of an object detection algorithm by incorporating precision and recall information. The
metric is used to compare the performance of various algorithms on well-known benchmark datasets such as COCO and PASCAL VOC. This metric has been widely adopted as a standard for comparing different object detection algorithms and it has been featured in numerous research publications [
47].
4.5. Experimental Results
The YOLOX-Ray architecture’s experimental tests were carried out on three distinct case studies, as previously outlined in the present section. Consequently, the performance of the YOLOX-Ray architecture was evaluated across four different model sizes. These various model sizes were analyzed to find the optimal trade-off between performance and computational efficiency.
Conducting experimental results for different model sizes in different use cases (Case studies A, B and C) is essential for assessing the YOLOX-Ray architecture in a variety of real-world situations since different use cases present unique challenges and requirements. The YOLOX-Ray architecture must be resilient, robust and effective in detecting anomalies of varying sizes and shapes in different environments, which can only be achieved through testing on a range of use cases.
Furthermore, this section includes a comparison of image predictions (object detection) for each case study and every YOLOX-Ray model size. These images display the YOLOX-Ray architecture’s capacity to detect and to localize objects within images. The object detection scores are presented as bounding boxes surrounding each detected object, with the scores indicating the confidence level that the object belongs to the identified class. The images illustrate the YOLOX-Ray architecture’s performance in various industrial inspection use cases and with different model sizes.
The images were selected from the test subset of each case study and they represent only a single example prediction. Other predictions were made, but only the presented ones were chosen to emphasize certain strengths, limitations and differences of the YOLOX-Ray models.
Figure 5,
Figure 6 and
Figure 7 have four images, (a), (b), (c) and (d), which are the same image but with different detection scores, each for a different model. Image (a) illustrates the detection scores for the smallest model, YOLOX-Ray-s, while image (b) depicts the medium-sized model, YOLOX-Ray-m. Image (c) depicts the large model, YOLOX-Ray-l and image (d) illustrates the detection scores for the extra-large model, YOLOX-Ray-x.The evaluation results are presented in
Table 5,
Table 6 and
Table 7, each showing the performance of the YOLOX-Ray models in terms of
P,
R,
over an
score of 0.5 (
),
on an
threshold of 0.5 to 0.95 (
), inference times in ms (
) and the number of parameters in millions (
).
4.6. Case Study A: Experimental Results and Predictions
Table 5 demonstrates the evaluation metrics and their values for Case Study A.
Examining
Table 5 and beginning with the
P metric, the YOLOX-Ray-m and YOLOX-Ray-l models achieved higher values (0.829 and 0.806, respectively) compared to the small model (0.73). This indicates that the medium and large models are more accurate in detecting hotspots. Curiously, the extra-large model had one of the lowest
p values (0.733).
In terms of R, all models achieved high values, with YOLOX-Ray-s reaching the highest at 0.917 and YOLOX-Ray-x obtaining the lowest at 0.879. This suggests that the models were successful in identifying most anomalies present in the images, regardless of their size.
In terms of , YOLOX-Ray-l performed the best with a value of 0.89, followed by YOLOX-Ray-s with 0.877. YOLOX-Ray-m and YOLOX-Ray-x achieved similar scores (0.872 and 0.845, respectively), with the extra-large model having the lowest score. This implies that larger models may not be optimal for this specific use case.
Regarding , YOLOX-Ray-l achieved the highest score of 0.427, closely followed by YOLOX-Ray-s and YOLOX-Ray-m with 0.422 and 0.426, respectively. YOLOX-Ray-x obtained the lowest score of 0.376. This metric indicates that YOLOX-Ray-l and YOLOX-Ray-s are the most accurate models in detecting hotspots with a high score.
Inference time is a crucial factor in real-time object detection applications. In this instance, YOLOX-Ray-s had the fastest inference time at 11.95 ms, followed by YOLOX-Ray-m (19.55 ms), YOLOX-Ray-l (29.22 ms) and YOLOX-Ray-x (46.56 ms). As expected, this suggests that smaller models are more efficient regarding inference time, making them better suited for real-time object detection.
Finally, the number of parameters for each model varied significantly. YOLOX-Ray-s had the fewest parameters with 8.94 million, followed by YOLOX-Ray-m with 25.28 million, YOLOX-Ray-l with 54.15 million and YOLOX-Ray-x with 99 million. This indicates that smaller models are more lightweight and may be more appropriate for resource-limited environments.
As expected, the inference time and number of parameters for each model also increased as the model’s size grew. Overall, the YOLOX-Ray architecture demonstrated solid performance in this case study, which allows for potential further improvement if the model size is not a concern.
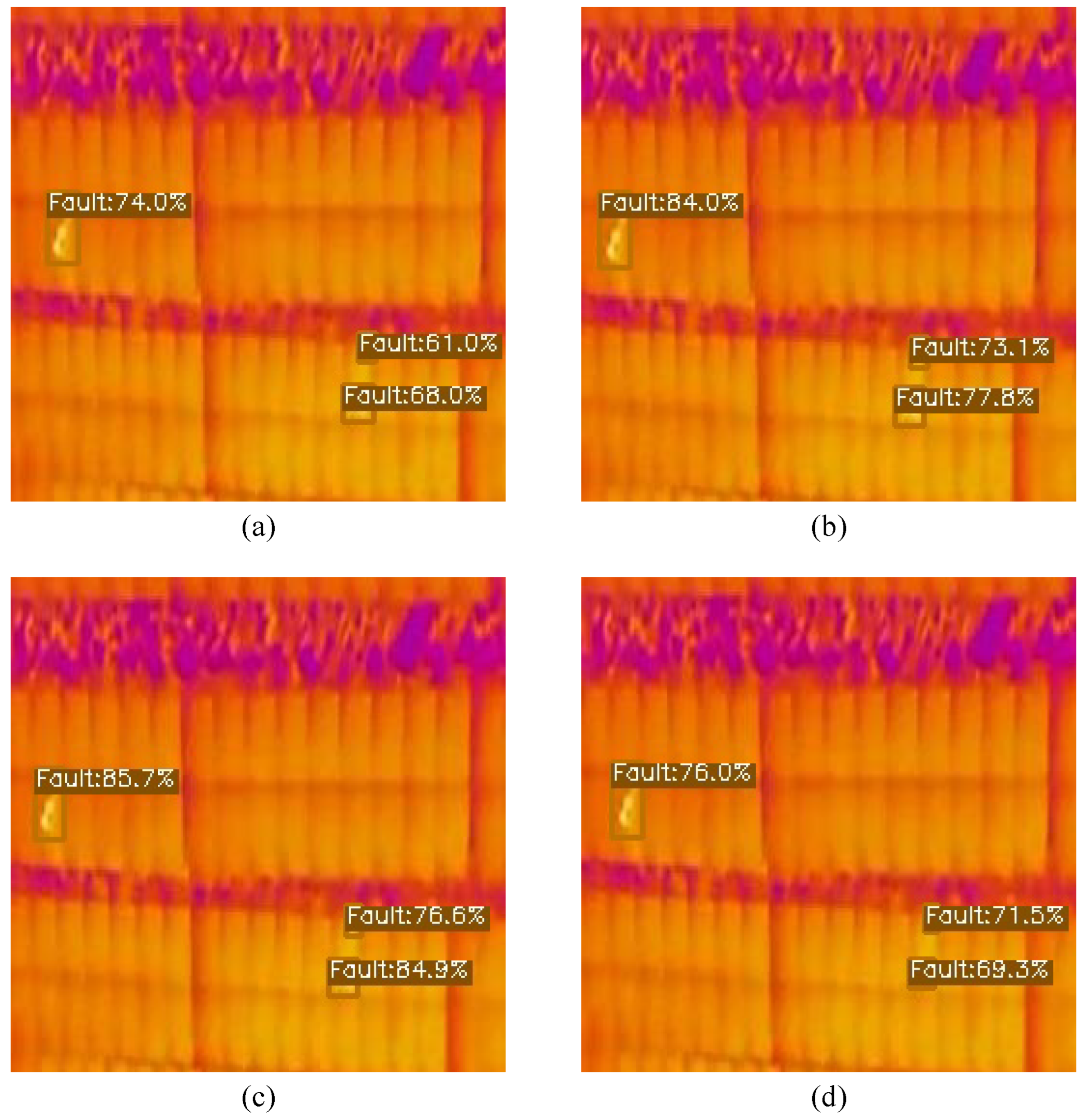
Figure 5 illustrates the instance predictions of different models for Case Study A.
Figure 5.
Image predictions for Case Study A: (a) Prediction on YOLOX-Ray-s; (b) Prediction on YOLOX-Ray-m; (c) Prediction on YOLOX-Ray-l; (d) Prediction on YOLOX-Ray-x.
Figure 5.
Image predictions for Case Study A: (a) Prediction on YOLOX-Ray-s; (b) Prediction on YOLOX-Ray-m; (c) Prediction on YOLOX-Ray-l; (d) Prediction on YOLOX-Ray-x.
By analyzing
Figure 5, it can be concluded that this image contains only small instances of the class ‘Fault’, allowing the evaluation of the YOLOX-Ray architecture’s capacity to detect small objects.
It is noticeable that the YOLOX-Ray-s model had the lowest prediction scores for all detections. In contrast, in line with the results obtained and presented in
Table 5, the medium and large models achieved the best detection scores, with YOLOX-Ray-m achieving the highest prediction scores. Interestingly, the YOLOX-Ray-x model did not perform well in this specific example, illustrating that even models designed to excel can underperform compared to lighter models in certain situations.
In summary, this example demonstrates the effectiveness of the YOLOX-Ray architecture in detecting small objects and emphasizes the significance of choosing the suitable model size based on the task requirements and dataset characteristics.
4.7. Case Study B: Experimental Results and Predictions
Table 6 demonstrates the evaluation metrics and their values for Case Study B.
Table 6 shows the YOLOX-Ray-s model surpassed all other models in all metrics, except for a slightly lower value of
when compared to the medium version (0.66 vs. 0.661). This indicates that the smaller model is adequate for achieving high performance in the crack detection task and implies that a smaller model can be a more effective solution in terms of both inference time and model complexity.
In terms of P, YOLOX-Ray-s also outperformed the other models, achieving a value of 0.984. The medium and large versions had slightly lower values of 0.972 and 0.962, respectively, while the extra-large version achieved a p value of 0.972.
All models secured high R values, ranging between 0.971 and 0.987. The small model achieved the highest value of 0.987, followed by the large version with a value of 0.979.
Regarding and , all models secured high values, spanning from 0.977 to 0.996 for and 0.625 to 0.661 for . The YOLOX-Ray-s model achieved the highest values for , while the medium version achieved the highest value for .
In terms of inference times, it is worth noting that YOLOX-Ray-s reached the lowest inference time, with a value of 9.62 ms, followed by YOLOX-Ray-m and YOLOX-Ray-l at 17.09 and 25.96 ms, respectively. As expected, the YOLOX-Ray-x model had the highest inference time, with a value of 42.53 ms.
Finally, it is important to highlight that the number of parameters remained the same across all models, since they were trained using the same configuration. The only difference was the dataset that was used for training and evaluation.
To conclude, the YOLOX-Ray-s model demonstrated the best overall performance in the crack detection task, outperforming the larger and more complex models in terms of both and inference times. These results suggest that smaller models can be a feasible solution for this industrial inspection task, particularly when efficiency is the key.
Figure 6 illustrates the instance predictions of different models for Case Study B.
Figure 6.
Image predictions for Case Study B: (a) Prediction on YOLOX-Ray-s; (b) Prediction on YOLOX-Ray-m; (c) Prediction on YOLOX-Ray-l; (d) Prediction on YOLOX-Ray-x.
Figure 6.
Image predictions for Case Study B: (a) Prediction on YOLOX-Ray-s; (b) Prediction on YOLOX-Ray-m; (c) Prediction on YOLOX-Ray-l; (d) Prediction on YOLOX-Ray-x.
By analyzing
Figure 6, it is possible to conclude that the YOLOX-Ray-s model produced a false positive detection, which is a significant observation, suggesting that smaller models might be more susceptible to false positives. The medium model (YOLOX-Ray-m) achieved the highest prediction score of 80%, followed closely by the YOLOX-Ray-x at 74.4%.
Additionally, the YOLOX-Ray-m achieved a more accurate bounding box regression aligned with the box compared to other models, implying that the YOLOX-Ray-m model is better at fitting the ‘crack’ instance.
These results show that, while all models performed almost identically in terms of evaluation metrics (as shown in
Table 6), false positives can still occur in weaker models. This emphasizes the importance of selecting a suitable model for each use case scenario, as well as the need to investigate additional methods for reducing false positives in smaller models.
4.8. Case Study C: Experimental Results and Predictions
Table 7 demonstrates the evaluation metrics and their values for Case Study C.
Table 7 displays the experimental outcomes of the YOLOX-Ray models trained and evaluated on Case Study C, which is more challenging than the other two case studies due to the presence of three classes: ‘slippage’, ‘corrosion’ and ‘crack’.
First, considering the P metric, the YOLOX-Ray-x model achieved the highest value of 0.832, indicating that it made fewer false positive predictions compared to other models. The YOLOX-Ray-m and YOLOX-Ray-l models also demonstrated high p values, at 0.829 and 0.792, respectively. However, the YOLOX-Ray-s model had the lowest p at 0.762, signifying a higher rate of false positives.
Next, examining R, which evaluates the model’s ability to accurately identify positive instances, the YOLOX-Ray-l model obtained the highest value of 0.883. The YOLOX-Ray-m and YOLOX-Ray-x models also performed well in R, with values of 0.878 and 0.876, respectively. The YOLOX-Ray-s model had the lowest R at 0.866.
Regarding , the YOLOX-Ray-x model reached the highest value of 0.877. The YOLOX-Ray-m and YOLOX-Ray-l models also posted high values, at 0.871 and 0.873, respectively. However, the YOLOX-Ray-s model had the lowest at 0.859, indicating a lower average P across all thresholds.
Lastly, for , representing the mean average P with a threshold range of 0.50 to 0.95, the YOLOX-Ray-x model achieved the highest value of 0.518. The YOLOX-Ray-l model also had a relatively high value of 0.505. The YOLOX-Ray-m and YOLOX-Ray-s models recorded values of 0.499 and 0.484, respectively.
In terms of inference times, the YOLOX-Ray-s model had the shortest time at 18.04 ms, while the YOLOX-Ray-x model had the longest time at 58.12 ms. This is expected, as larger models require more computation time.
Figure 7 illustrates the instance predictions of different models for Case Study C.
Figure 7.
Image predictions for Case Study C: (a) Prediction on YOLOX-Ray-s; (b) Prediction on YOLOX-Ray-m; (c) Prediction on YOLOX-Ray-l; (d) Prediction on YOLOX-Ray-x.
Figure 7.
Image predictions for Case Study C: (a) Prediction on YOLOX-Ray-s; (b) Prediction on YOLOX-Ray-m; (c) Prediction on YOLOX-Ray-l; (d) Prediction on YOLOX-Ray-x.
Examining
Figure 7, it is evident that this figure includes multiple instances of the ‘crack’ and ‘corrosion’ classes, which the YOLOX-Ray models were expected to accurately detect.
By analyzing image (a), it is possible to conclude that the YOLOX-Ray-s model missed three ‘crack’ instances in the image, indicating room for enhancement in its detection abilities.
The YOLOX-Ray-m model’s performance was slightly inferior to that of the YOLOX-Ray-s model, as it misidentified a ‘crack’ instance as a ‘corrosion’ instance.
The YOLOX-Ray-l model achieved better prediction scores than the YOLOX-Ray-s and YOLOX-Ray-m models but still failed to identify three ‘crack’ instances in the image.
On the other hand, the YOLOX-Ray-x model, despite having lower prediction scores, successfully detected all instances in the image, making it the only model to achieve 100% object detection for this specific image.
This example underlines the variations in detection capabilities among the YOLOX-Ray models and the trade-offs between prediction scores and detection performance. Although the YOLOX-Ray-x model achieved perfect object detection, its prediction scores were lower than those of the YOLOX-Ray-l model.
Moreover, the YOLOX-Ray-s and YOLOX-Ray-m models had lower prediction scores than the YOLOX-Ray-l model but missed certain instances, signifying the necessity for model enhancements.
Overall, this example shows the importance of striking a balance between prediction scores and detection performance in object detection models and the need for ongoing research and development to improve model capabilities.
4.9. Ablation Study
Ablation studies play a crucial role in DL experiments as they help to determine the contributions of specific techniques, features or components added to a DL base architecture to enhance its overall performance [
48].
The objective of this study is to compare the YOLOX-Ray results across all case studies when the SimAM attention mechanism is added to the YOLOX base architecture, the Alpha-IoU loss function is implemented and finally the YOLOX-Ray architecture, which is a combination of SimAM and Alpha-IoU.
Experiments were conducted using the smallest model (YOLOX-s) in all case studies, with the evaluated metrics being
P,
R,
,
, inference time in ms (
) and Frames Per Second (FPS). The ablation study results can be visualized in
Table 8,
Table 9 and
Table 10.
Incorporating the additional components into our model has not led to a change in the number of parameters. Consequently, the computational cost remains relatively unaffected by these enhancements. Therefore, since we are only using the smallest model, the number of parameters is fixed in 8.94 million.
Table 8 represents the evaluation metrics and their values for Case Study A.
By analyzing
Table 8, it is possible to observe that the YOLOX-Ray configuration, which integrates both the SimAM attention mechanism and Alpha-
IoU loss function, outperforms all other configurations in all metrics, except for
P and inference time. Moreover, it achieved a high
R value of
, the highest
value of
and the highest
value of
when compared to other configurations. Nevertheless, its
p value of
was slightly lower than the YOLOX configuration. In terms of speed, the YOLOX-Ray configuration boasted a relatively high FPS value of
and a low inference time of
.
The YOLOX configuration secured the highest p value of , but possessed a value of and an value of . It also demonstrated the highest FPS value of and the lowest inference time of ms, indicating rapid processing speed in this case study.
Regarding the other configurations with alternative attention mechanisms, YOLOX + SENet achieved a p value of , an R value of and a value of . YOLOX + CBAM reported a p value of , an R value of and a value of . Lastly, YOLOX + CA obtained a p value of , an R value of and a value of . Among these, the YOLOX + CA configuration demonstrated the best performance in terms of P and R, while the YOLOX + SimAM configuration achieved the highest value in all attention mechanisms.
For the configurations with alternative loss functions, YOLOX + CIoU achieved a p value of , an R value of and a value of . YOLOX + DIoU obtained a p value of , an R value of and a value of . Lastly, YOLOX + GIoU reported a p value of , an R value of and a value of . Among these, the YOLOX + CIoU configuration demonstrated the best performance in terms of P, R and values.
In conclusion, the ablation study results for Case Study A reveal that the YOLOX-Ray configuration delivered the best overall performance among all configurations, despite having a slightly lower p value than the YOLOX configuration. Such observations allow us to state that the combination of the SimAM attention mechanism and the Alpha-IoU loss function can effectively enhance the YOLOX-Ray architecture’s performance. However, the specific performance of each configuration depends on the task and dataset characteristics and the balance between speed and must be considered when choosing the appropriate configuration.
Table 9 represents the evaluation metrics and their values for Case Study B.
Table 9 demonstrates that the YOLOX-Ray configuration achieved the highest values across all metrics, with the exception of inference time. The configuration obtained the highest
value of
, the highest
value of
, the highest
p value of
and the highest
R value of
. However, it experienced a slightly higher inference time of
ms and a lower FPS value of
compared to the YOLOX base configuration.
Regarding the attention mechanisms, the YOLOX + SENet configuration achieved a p value of , an R value of , an value of and an value of . The YOLOX + CBAM configuration reached a p value of , an R value of , an value of and an value of . The YOLOX + CA configuration obtained a p value of , an R value of , an value of and an value of . Among these, the YOLOX + SimAM configuration demonstrated the best performance in terms of P, R and values.
For the configurations with alternative loss functions, the YOLOX + CIoU configuration achieved a p value of , an R value of , an value of and an value of . The YOLOX + DIoU configuration obtained a p value of , an R value of , an value of and an value of . The YOLOX + GIoU configuration reported a p value of , an R value of , an value of and an value of . Among these, the YOLOX + Alpha-IoU configuration demonstrated the best performance in terms of P, R and values.
In summary, the YOLOX-Ray configuration is the best choice for object detection in the crack detection case study, as it achieved the highest values in almost all metrics except inference time. The YOLOX base configuration is not recommended due to its poor performance in most metrics. While the addition of SimAM or Alpha-IoU improved certain metrics individually, the combination of both led to a better performance. It is important to note that lower inference times are preferred in real-time applications and higher FPS values signify the model’s capacity to process images more rapidly. Consequently, the YOLOX-Ray configuration demonstrated superior performance in terms of while maintaining exceptional performance in terms of speed.
Table 10 represents the evaluation metrics and their values for Case Study C.
By analyzing
Table 10, it becomes clear that the YOLOX-Ray configuration surpassed all other configurations regarding the two most challenging metrics,
and
, obtaining values of
and
, respectively. Nevertheless, it had a slightly lower
R value of
compared to the YOLOX + SimAM configuration, suggesting that it failed to detect some true positive objects. This configuration also had a relatively low inference time of
ms and a relatively high FPS value of
, making it slightly slower than the quickest configurations (YOLOX and YOLOX + SimAM).
The YOLOX base configuration exhibited the weakest performance in nearly all metrics, with a p value of 0.29, an R value of 0.821, an value of 0.768, an value of 0.389. However, it had the lowest inference time ( ms) and consequently the highest FPS value (). Curiously, despite being the simplest architecture, it achieved the same inference time as the YOLOX + SimAM configuration.
For the attention mechanisms, both the YOLOX + SimAM and YOLOX + CA configurations achieved lower values of and in comparison to the YOLOX-Ray configuration. Specifically, the YOLOX + SimAM configuration reached a slightly lower value of and a lower value of when compared to the YOLOX-Ray configuration, while the YOLOX + CA configuration secured a slightly higher value of and a lower value of when compared to the YOLOX-Ray configuration. Both configurations had high R values relative to YOLOX-Ray, with YOLOX + SimAM exhibiting the highest R value of and YOLOX + CA displaying an R value of . Concerning inference time and FPS, YOLOX + SimAM had also the lowest inference time of ms and, consequently, the highest FPS value of among all configurations, while YOLOX + CA had a slightly longer inference time of ms and a lower FPS value of .
Regarding the loss functions, the YOLOX + Alpha-IoU configuration achieved lower values of and in comparison to the YOLOX-Ray configuration, securing an even lower value of and a lower value of . The YOLOX + Alpha-IoU configuration had a high R value relative to YOLOX-Ray, displaying an R value of . Concerning inference time and FPS, YOLOX + Alpha-IoU had a slightly longer inference time of ms and a lower FPS value of .
In summary, the YOLOX-Ray configuration delivered the best performance in terms of the most crucial metrics ( and ), despite having a lower R value and slower inference times compared to some other configurations. The results also imply that, in this case study, faster inference times and higher FPS values are preferable but should not undermine model performance. The attention mechanisms and loss functions individually showed improvements over the base YOLOX configuration, but the combination of these techniques in the YOLOX-Ray configuration led to the most significant performance gains.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}