
Deep Reinforcement Learning for Joint Trajectory Planning, Transmission Scheduling, and Access Control in UAV-Assisted Wireless Sensor Networks

Abstract
:1. Introduction
2. Related Works
2.1. Multi-UAV-Assisted Wireless Networks
2.2. Multi-Agent DRL for UAV-Assisted Wireless Networks
2.3. UAV-Assisted Sensing Scheduling and Access Control
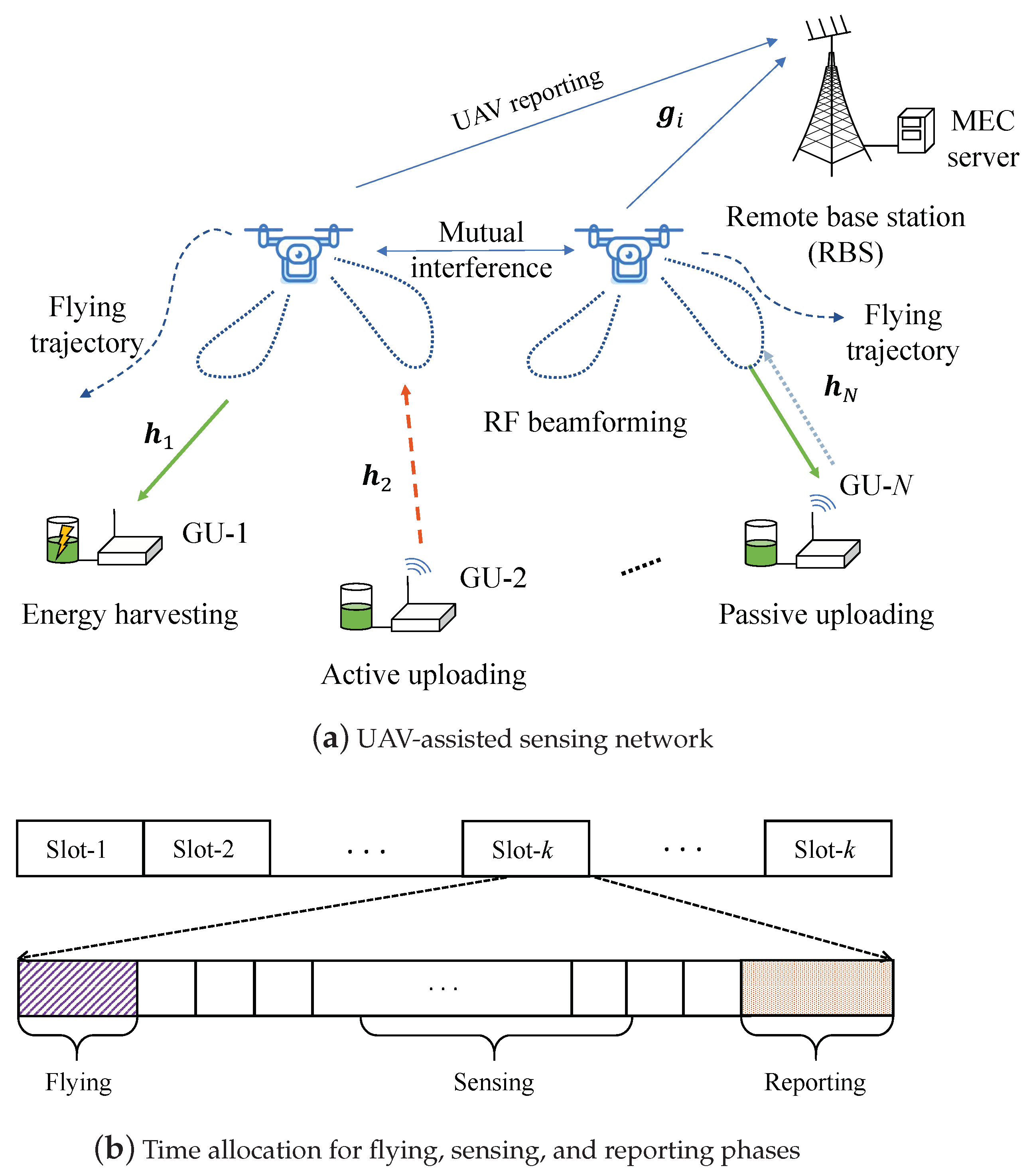
3. System Model
3.1. UAV Trajectory Planning
3.2. GU Access Control and Mode Selection
3.3. UAV Transmission Scheduling and Buffer Dynamics
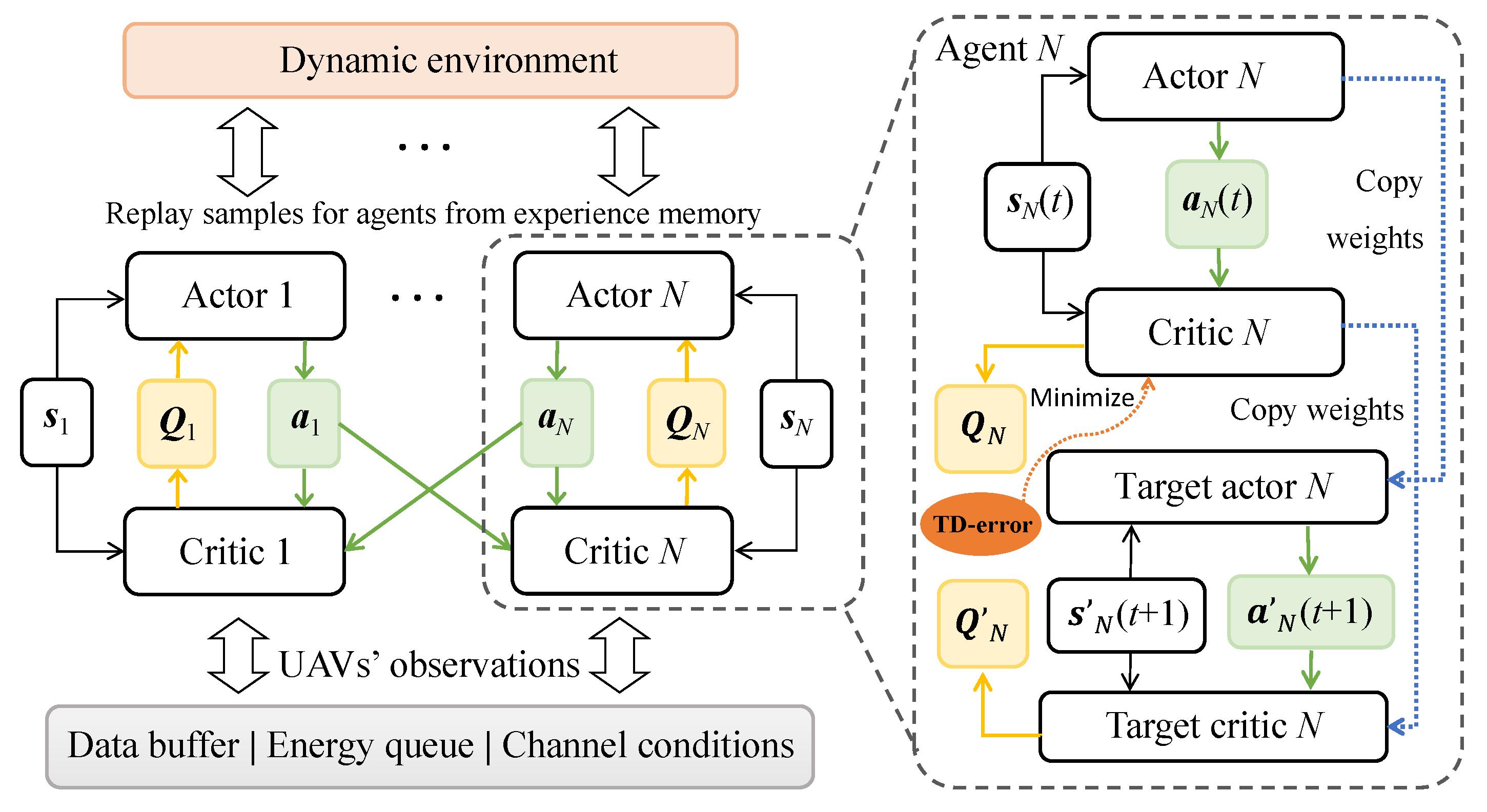
4. Learning for Energy-Efficiency Maximization
| Algorithm 1 MADDPG for multi-UAV trajectory planning, transmission scheduling, access control, and mode selection |
|
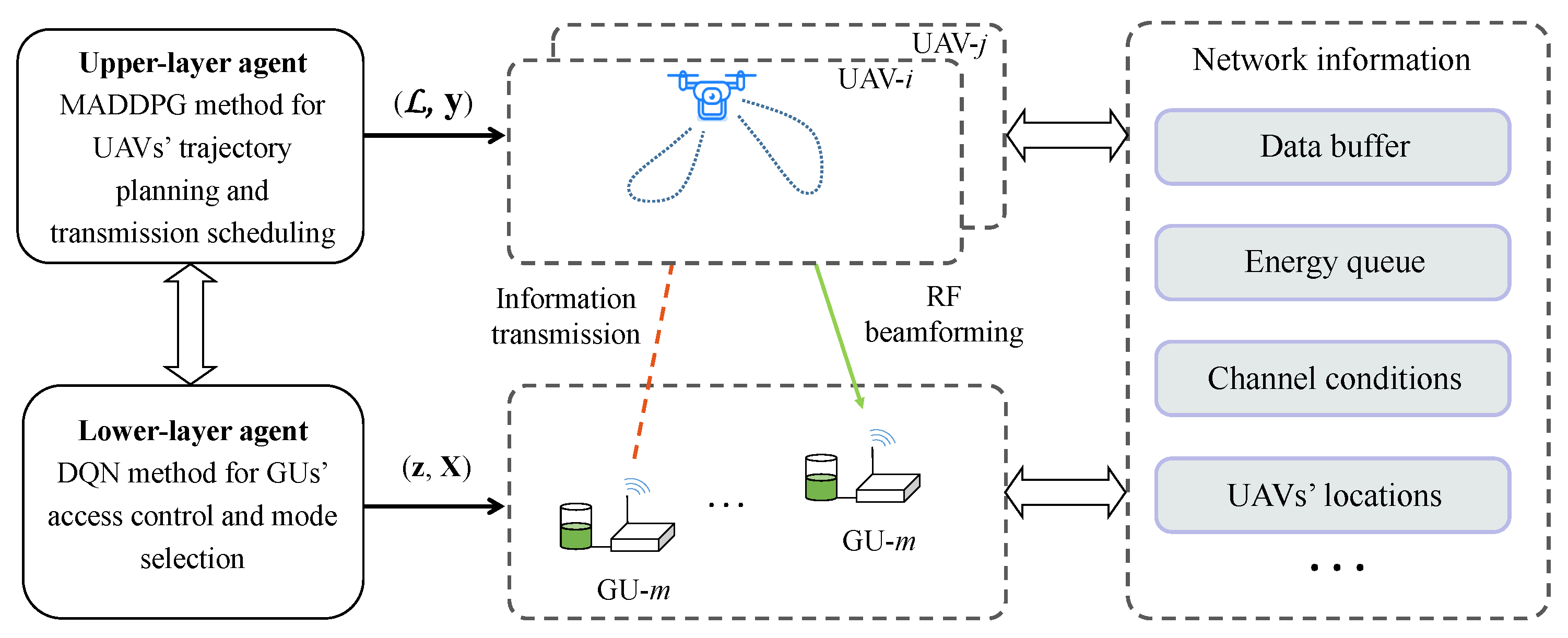
5. A Hierarchical Learning Approach
5.1. Hierarchical Multi-Agent Learning Framework
5.2. Upper-Layer MADDPG for Trajectory Planning and Scheduling
5.3. Lower-Layer DQN for GU Access Control and Mode Selection
| Algorithm 2 Hierarchical learning for multi-UAV trajectory planning, transmission scheduling, and access control |
|
6. Numerical Results
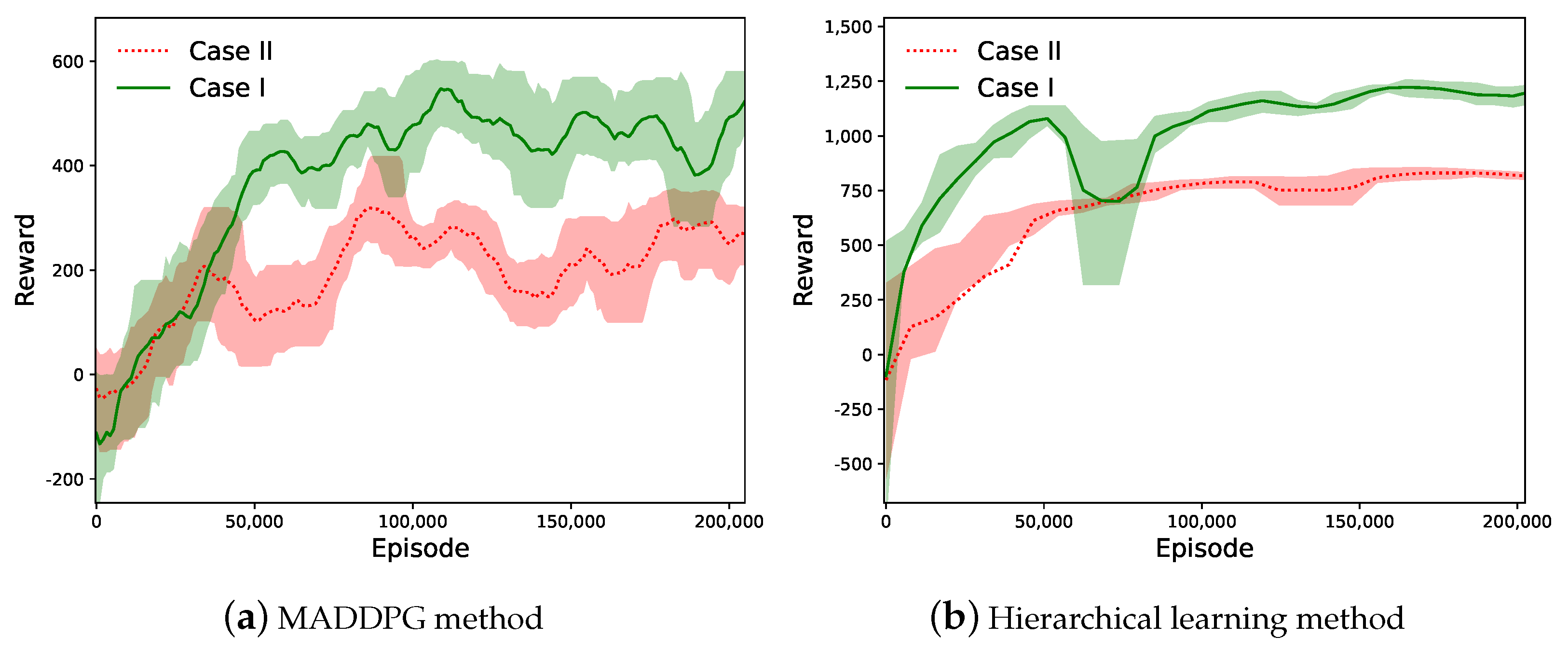
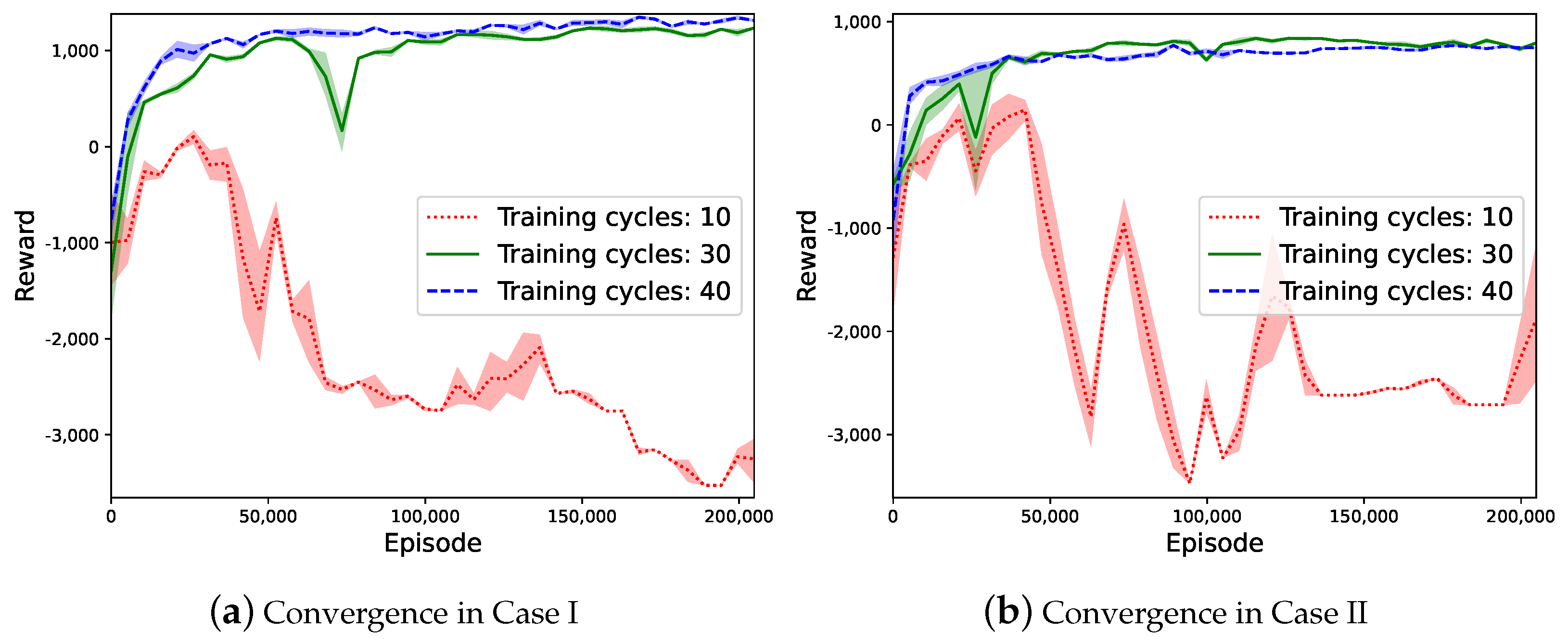
6.1. Convergence and Reward Performance
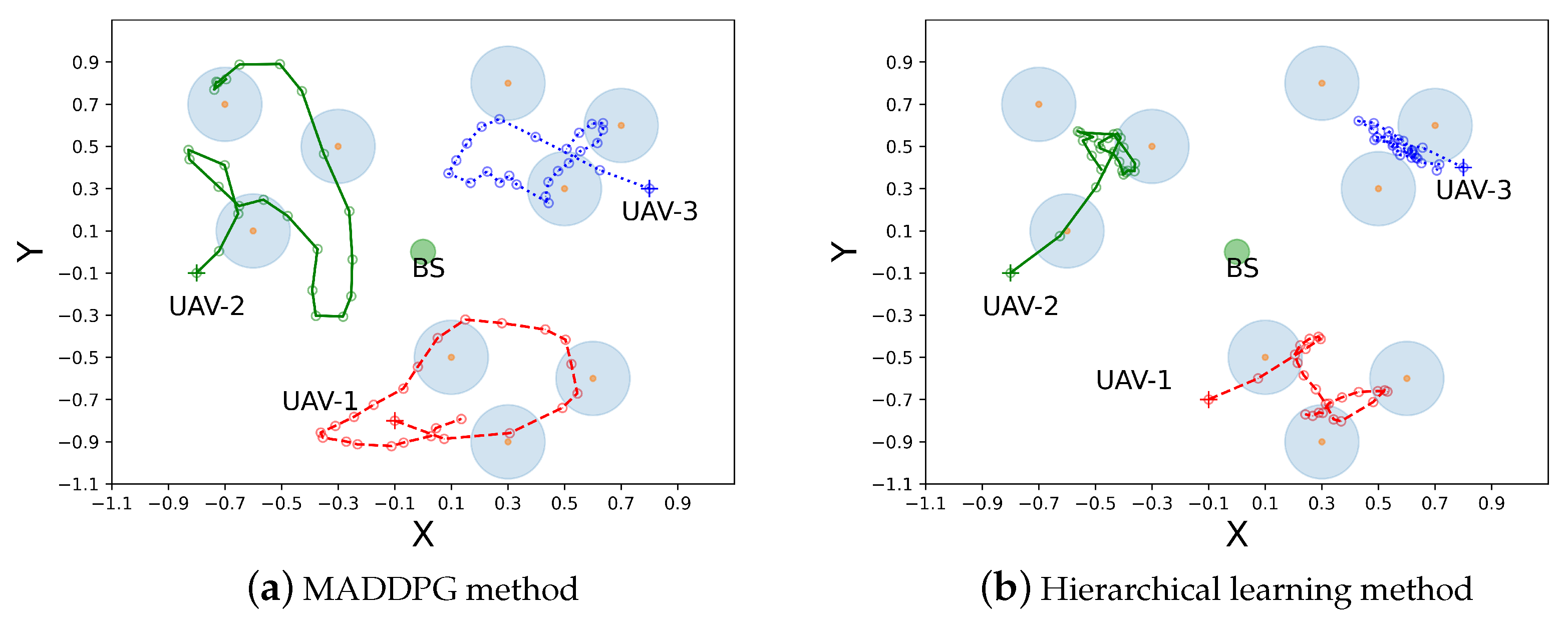
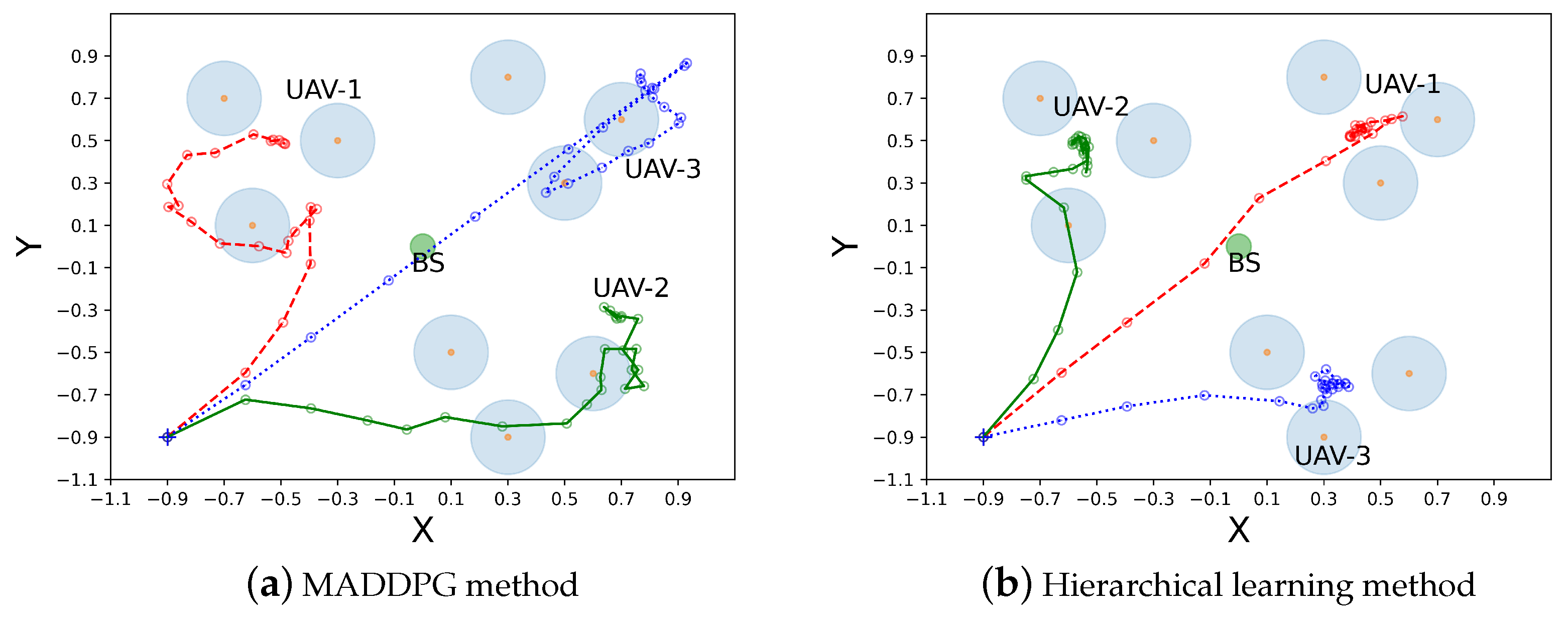
6.2. Trajectory Planning in Two Cases
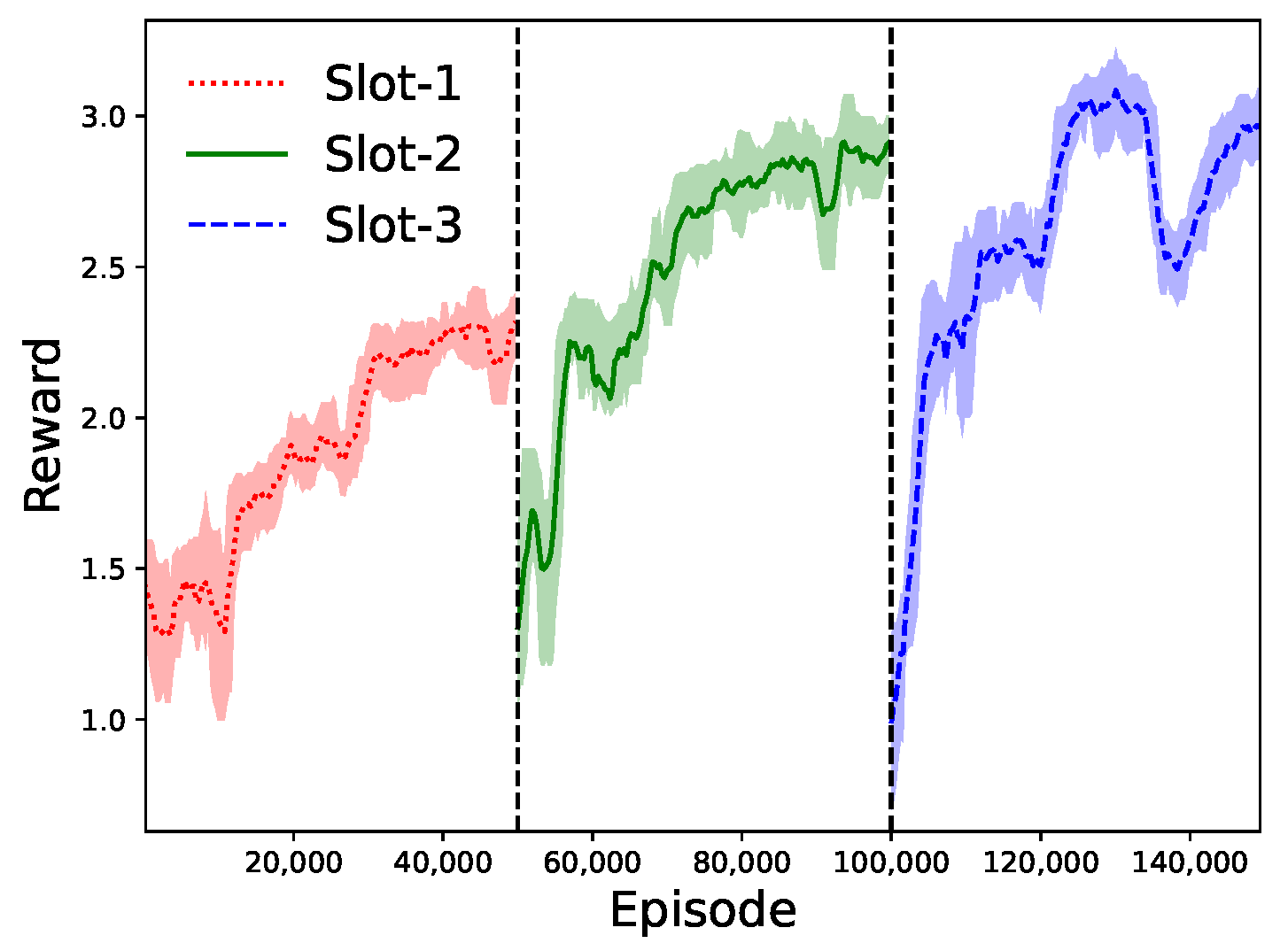
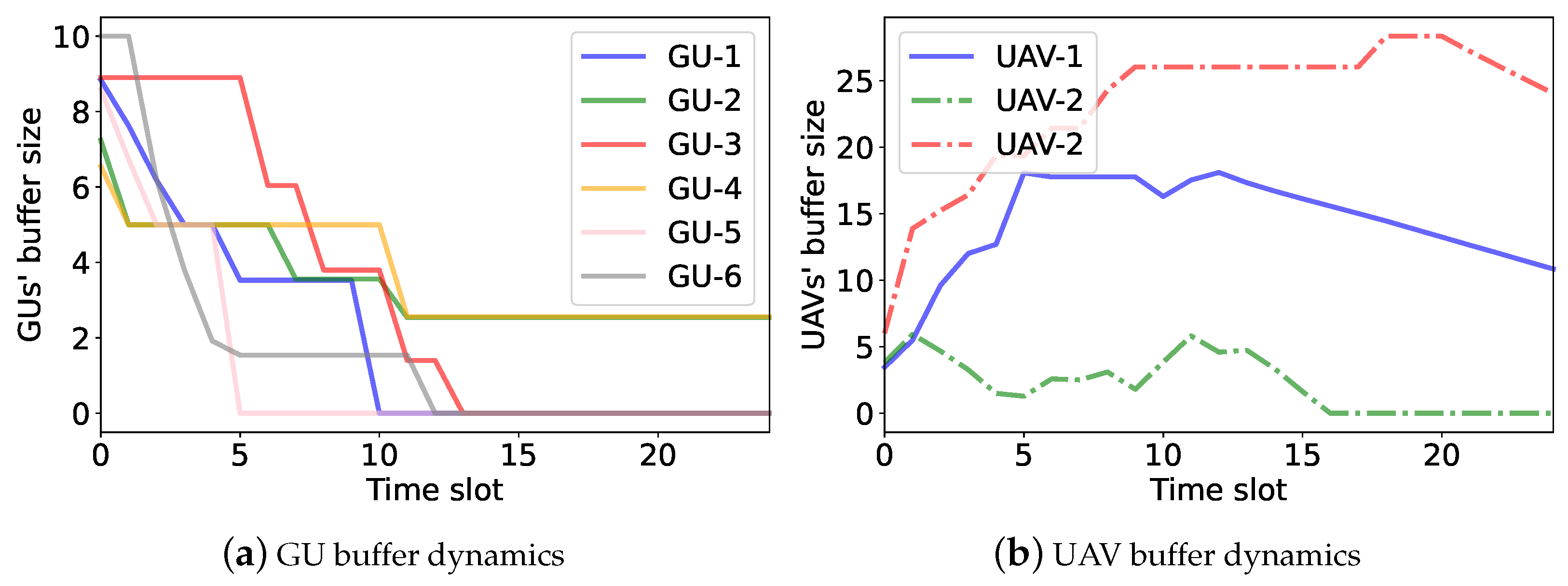
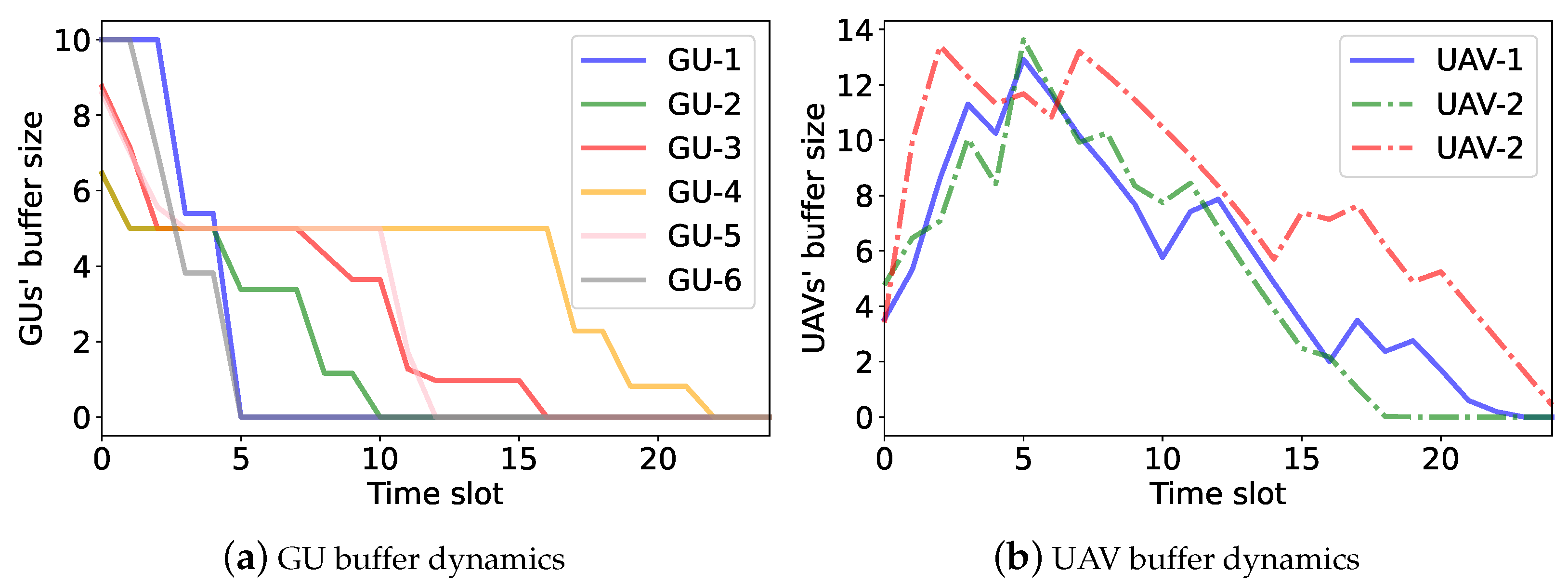
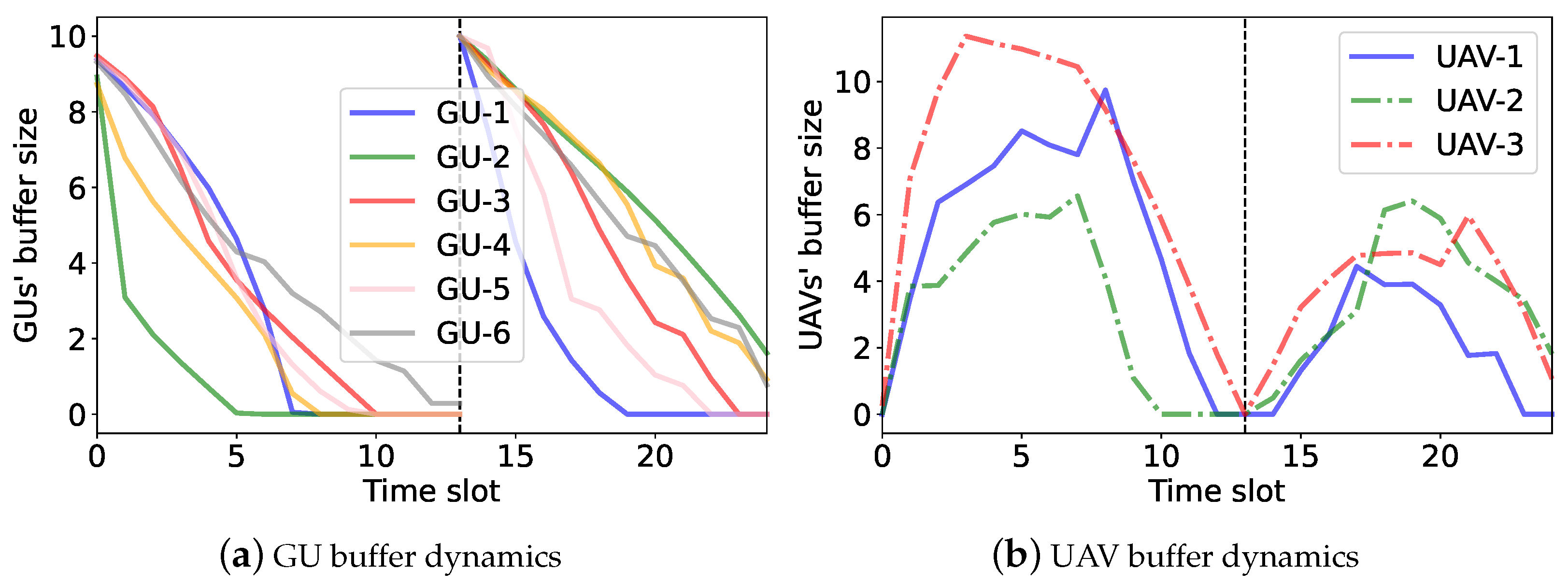
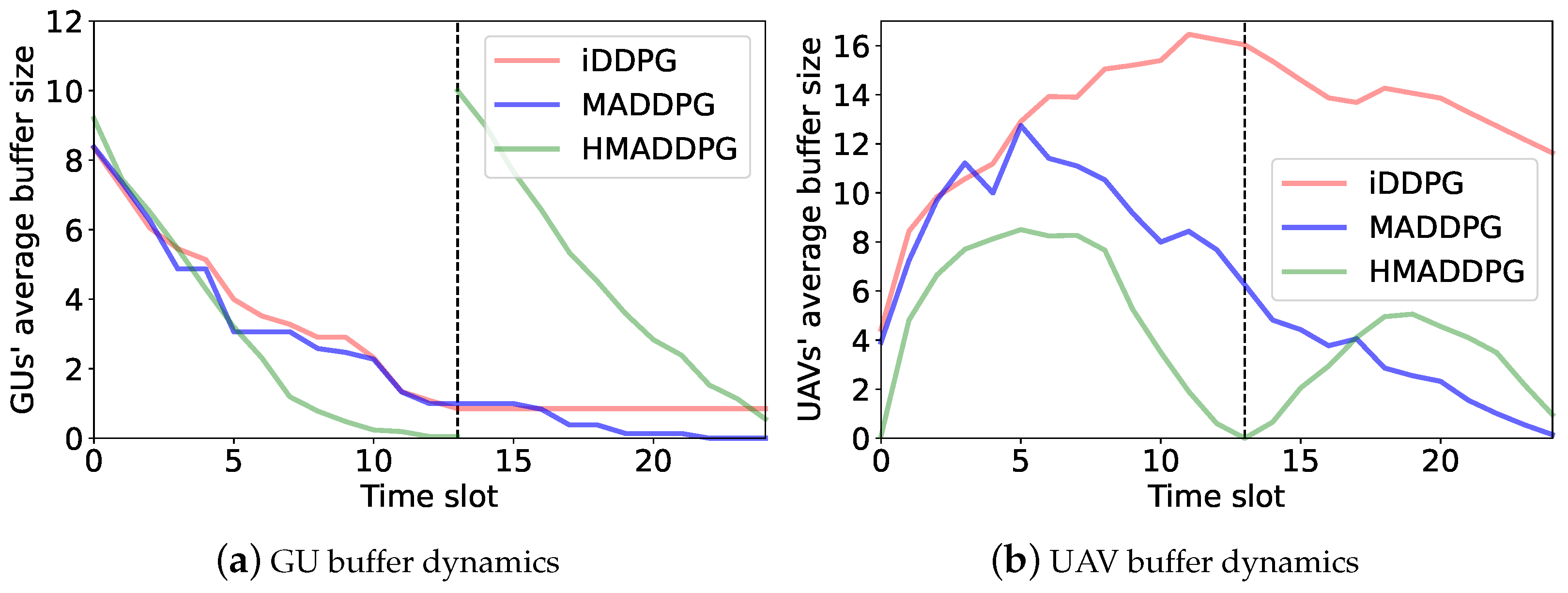
6.3. Access Control and Buffer Dynamics
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Unmanned Aerial Vehicle | UAV |
| Internet of Things | IoT |
| Ground User | GU |
| Remote Base Station | RBS |
| Block Coordinate Descent | BCD |
| Multi-agent Proximal Policy Optimization | MAPPO |
| Multi-agent Deep Deterministic Policy Gradient | MADDPG |
| Federated MADDPG | F-MADDPG |
| Federated Averaging | FA |
| Hierarchical Multi-Agent DRL | H-MADRL |
| Quality-of-Service | QoS |
| Mixed-Integer Nonlinear Programming | MINLP |
| Line-of-Sight | LOS |
| Markov Decision Process | MDP |
| Deep Neural Network | DNN |
| Independent DDPG | IDDPG |
| Non-Orthogonal Multiple Access | NOMA |
| Rate-Splitting Multiple Access | RSMA |
References
- Lagkas, T.; Argyriou, V.; Bibi, S.; Sarigiannidis, P. UAV IoT framework views and challenges: Towards protecting drones as “Things”. Sensors 2018, 18, 4015. [Google Scholar] [CrossRef] [PubMed]
- Gupta, L.; Jain, R.; Vaszkun, G. Survey of important issues in UAV communication networks. IEEE Commun. Surv. Tutor. 2015, 18, 1123–1152. [Google Scholar] [CrossRef]
- Han, R.; Bai, L.; Wen, Y.; Liu, J.; Choi, J.; Zhang, W. UAV-aided backscatter communications: Performance analysis and trajectory optimization. IEEE J. Sel. Areas Commun. 2021, 39, 3129–3143. [Google Scholar] [CrossRef]
- Yang, G.; Dai, R.; Liang, Y.C. Energy-efficient UAV backscatter communication with joint trajectory design and resource optimization. IEEE Trans. Wirel. Commun. 2020, 20, 926–941. [Google Scholar] [CrossRef]
- Zhao, N.; Lu, W.; Sheng, M.; Chen, Y.; Tang, J.; Yu, F.R.; Wong, K.K. UAV-assisted emergency networks in disasters. IEEE Trans. Wirel. Commun. 2019, 26, 45–51. [Google Scholar] [CrossRef]
- Boccardo, P.; Chiabrando, F.; Dutto, F.; Giulio Tonolo, F.; Lingua, A. UAV deployment exercise for mapping purposes: Evaluation of emergency response applications. Sensors 2015, 15, 15717–15737. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Localization and clustering based on swarm intelligence in UAV networks for emergency communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Hayat, S.; Yanmaz, E.; Muzaffar, R. Survey on unmanned aerial vehicle networks for civil applications: A communications viewpoint. IEEE Commun. Surv. Tutor. 2016, 18, 2624–2661. [Google Scholar] [CrossRef]
- Ding, G.; Wu, Q.; Zhang, L.; Lin, Y.; Tsiftsis, T.A.; Yao, Y.D. An amateur drone surveillance system based on the cognitive Internet of Things. IEEE Commun. Mag. 2018, 56, 29–35. [Google Scholar] [CrossRef]
- Zhao, C.; Liu, J.; Sheng, M.; Teng, W.; Zheng, Y.; Li, J. Multi-UAV trajectory planning for energy-efficient content coverage: A decentralized learning-based approach. IEEE J. Sel. Areas Commun. 2021, 39, 3193–3207. [Google Scholar] [CrossRef]
- Tran, D.H.; Nguyen, V.D.; Chatzinotas, S.; Vu, T.X.; Ottersten, B. UAV relay-assisted emergency communications in IoT networks: Resource allocation and trajectory optimization. IEEE Trans. Wirel. Commun. 2021, 21, 1621–1637. [Google Scholar] [CrossRef]
- You, C.; Zhang, R. 3D trajectory optimization in Rician fading for UAV-enabled data harvesting. IEEE Trans. Wirel. Commun. 2019, 18, 3192–3207. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, H.; Du, W.; Long, K.; Nallanathan, A. IRS empowered UAV wireless communication with resource allocation, reflecting design and trajectory optimization. IEEE Trans. Wirel. Commun. 2022, 21, 7867–7880. [Google Scholar] [CrossRef]
- Lakew, D.S.; Tran, A.T.; Dao, N.N.; Cho, S. Intelligent offloading and resource allocation in heterogeneous aerial access IoT networks. IEEE Internet Things J. 2022, 10, 5704–5718. [Google Scholar] [CrossRef]
- Kang, H.; Chang, X.; Mišić, J.; Mišić, V.B.; Fan, J.; Liu, Y. Cooperative UAV Resource Allocation and Task Offloading in Hierarchical Aerial Computing Systems: A MAPPO Based Approach. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, Z.; Zhang, J.; Cao, X.; Zheng, D.; Gao, Y.; Ng, D.W.K.; Di Renzo, M. Trajectory Design for UAV-Based Internet of Things Data Collection: A Deep Reinforcement Learning Approach. IEEE Internet Things J. 2021, 9, 3899–3912. [Google Scholar] [CrossRef]
- Wang, M.; Long, Y.; Gong, S.; Xu, J. Adaptive Network Formation and Trajectory Optimization for Multi-UAV-Assisted Wireless Data Offloading. In Proceedings of the 2021 IEEE 23rd International Conference on High Performance Computing & Communications, Haikou, China, 20–22 December 2021; pp. 961–967. [Google Scholar] [CrossRef]
- Wu, S.; Xu, W.; Wang, F.; Li, G.; Pan, M. Distributed federated deep reinforcement learning based trajectory optimization for air-ground cooperative emergency networks. IEEE Trans. Veh. Technol. 2022, 71, 9107–9112. [Google Scholar] [CrossRef]
- Qian, L.P.; Zhang, H.; Wang, Q.; Wu, Y.; Lin, B. Joint Multi-Domain Resource Allocation and Trajectory Optimization in UAV-Assisted Maritime IoT Networks. IEEE Internet Things J. 2022, 10, 539–552. [Google Scholar] [CrossRef]
- Zhou, H.; Long, Y.; Gong, S.; Zhu, K.; Hoang, D.T.; Niyato, D. Hierarchical Multi-Agent Deep Reinforcement Learning for Energy-Efficient Hybrid Computation Offloading. IEEE Trans. Veh. Technol. 2022, 72, 986–1001. [Google Scholar] [CrossRef]
- Gong, S.; Cui, L.; Gu, B.; Lyu, B.; Hoang, D.T.; Niyato, D. Hierarchical Deep Reinforcement Learning for Age-of-Information Minimization in IRS-aided and Wireless-powered Wireless Networks. IEEE Trans. Wirel. Commun. 2023. [Google Scholar] [CrossRef]
- Gong, S.; Wang, M.; Gu, B.; Zhang, W.; Hoang, D.T.; Niyato, D. Bayesian Optimization Enhanced Deep Reinforcement Learning for Trajectory Planning and Network Formation in Multi-UAV Networks. IEEE Trans. Veh. Technol. 2023. [Google Scholar] [CrossRef]
- Zheng, J.; Chen, R.; Yang, T.; Liu, X.; Liu, H.; Su, T.; Wan, L. An efficient strategy for accurate detection and localization of UAV swarms. IEEE Internet Things J. 2021, 8, 15372–15381. [Google Scholar] [CrossRef]
- Mou, Z.; Zhang, Y.; Gao, F.; Wang, H.; Zhang, T.; Han, Z. Deep reinforcement learning based three-dimensional area coverage with UAV swarm. IEEE J. Sel. Areas Commun. 2021, 39, 3160–3176. [Google Scholar] [CrossRef]
- Ye, Z.; Wang, K.; Chen, Y.; Jiang, X.; Song, G. Multi-UAV Navigation for Partially Observable Communication Coverage by Graph Reinforcement Learning. IEEE Trans. Mobil. Comput. 2022, 8, 15372–15381. [Google Scholar] [CrossRef]
- Jung, S.; Yun, W.J.; Shin, M.; Kim, J.; Kim, J.H. Orchestrated scheduling and multi-agent deep reinforcement learning for cloud-assisted multi-UAV charging systems. IEEE Trans. Veh. Technol. 2021, 70, 5362–5377. [Google Scholar] [CrossRef]
- Abd-Elmagid, M.A.; Dhillon, H.S. Average peak age-of-information minimization in UAV-assisted IoT networks. IEEE Trans. Veh. Technol. 2018, 68, 2003–2008. [Google Scholar] [CrossRef]
- Du, Y.; Wang, K.; Yang, K.; Zhang, G. Energy-efficient resource allocation in UAV based MEC system for IoT devices. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Luong, P.; Gagnon, F.; Tran, L.N.; Labeau, F. Deep reinforcement learning-based resource allocation in cooperative UAV-assisted wireless networks. IEEE Trans. Wirel. Commun. 2021, 20, 7610–7625. [Google Scholar] [CrossRef]
- Singh, S.K.; Agrawal, K.; Singh, K.; Chen, Y.M.; Li, C.P. Ergodic Capacity and Placement Optimization for RSMA-Enabled UAV-Assisted Communication. IEEE Syst. J. 2022. [Google Scholar] [CrossRef]
- Singh, S.K.; Agrawal, K.; Singh, K.; Chen, Y.M.; Li, C.P. Performance Analysis and Optimization of RSMA Enabled UAV-Aided IBL and FBL Communication with Imperfect SIC and CSI. IEEE Trans. Wirel. Commun. 2022. [Google Scholar] [CrossRef]
- Sohail, M.F.; Leow, C.Y.; Won, S. Non-orthogonal multiple access for unmanned aerial vehicle assisted communication. IEEE Access 2018, 6, 22716–22727. [Google Scholar] [CrossRef]
- Hosseini, M.; Ghazizadeh, R. Stackelberg game-based deployment design and radio resource allocation in coordinated UAVs-assisted vehicular communication networks. IEEE Trans. Veh. Technol. 2022, 72, 1196–1210. [Google Scholar] [CrossRef]
- Liang, Y.C.; Zhang, Q.; Wang, J.; Long, R.; Zhou, H.; Yang, G. Backscatter communication assisted by reconfigurable intelligent surfaces. IEEE Trans. Knowl. Data Eng. 2022, 28, 2296–2319. [Google Scholar] [CrossRef]
- Gong, S.; Gao, L.; Xu, J.; Guo, Y.; Hoang, D.T.; Niyato, D. Exploiting backscatter-aided relay communications with hybrid access model in device-to-device networks. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 835–848. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter, A.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Setting |
|---|---|
| Training cycles per episode | 30 |
| Path-loss coefficient | 2 |
| Range of GU’s data size | Mbits |
| Maximum UAV speed | 25 m/s |
| Noise power | dBm |
| -greedy parameter | 0.05 |
| Actor’s learning rate | |
| Critic’s learning rate | |
| Batch size | 32 |
| Reward discount | 0.95 |
| Memory capacity | 2000 |
| Target replace iter | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Chen, C.; Zeng, C.; Li, C.; Xu, J.; Gong, S. Deep Reinforcement Learning for Joint Trajectory Planning, Transmission Scheduling, and Access Control in UAV-Assisted Wireless Sensor Networks. Sensors 2023, 23, 4691. https://doi.org/10.3390/s23104691
Luo X, Chen C, Zeng C, Li C, Xu J, Gong S. Deep Reinforcement Learning for Joint Trajectory Planning, Transmission Scheduling, and Access Control in UAV-Assisted Wireless Sensor Networks. Sensors. 2023; 23(10):4691. https://doi.org/10.3390/s23104691
Chicago/Turabian StyleLuo, Xiaoling, Che Chen, Chunnian Zeng, Chengtao Li, Jing Xu, and Shimin Gong. 2023. "Deep Reinforcement Learning for Joint Trajectory Planning, Transmission Scheduling, and Access Control in UAV-Assisted Wireless Sensor Networks" Sensors 23, no. 10: 4691. https://doi.org/10.3390/s23104691
APA StyleLuo, X., Chen, C., Zeng, C., Li, C., Xu, J., & Gong, S. (2023). Deep Reinforcement Learning for Joint Trajectory Planning, Transmission Scheduling, and Access Control in UAV-Assisted Wireless Sensor Networks. Sensors, 23(10), 4691. https://doi.org/10.3390/s23104691