
Person Recognition Based on Deep Gait: A Survey


Abstract
:1. Introduction
1.1. Gait for Person Recognition
1.2. Data Extraction
1.3. Background and Motivation
1.4. Contributions
- i.
- The paper presents a taxonomy of deep learning methods to describe and organize the research landscape in this field. This taxonomy can help researchers and practitioners understand the various approaches and their limitations.
- ii.
- The paper provides a comprehensive overview of the advancements made in the field of gait recognition using deep learning methods.
- iii.
- The paper acknowledges the challenges associated with recognizing gait accurately due to the complexity and variability of environments and human body representations. It also identifies the limitations of deep learning methods in the context of gait recognition.
- iv.
- The paper concludes by focusing on the present challenges and suggesting a number of research directions to improve the performance of gait recognition in the future.
1.5. Organization
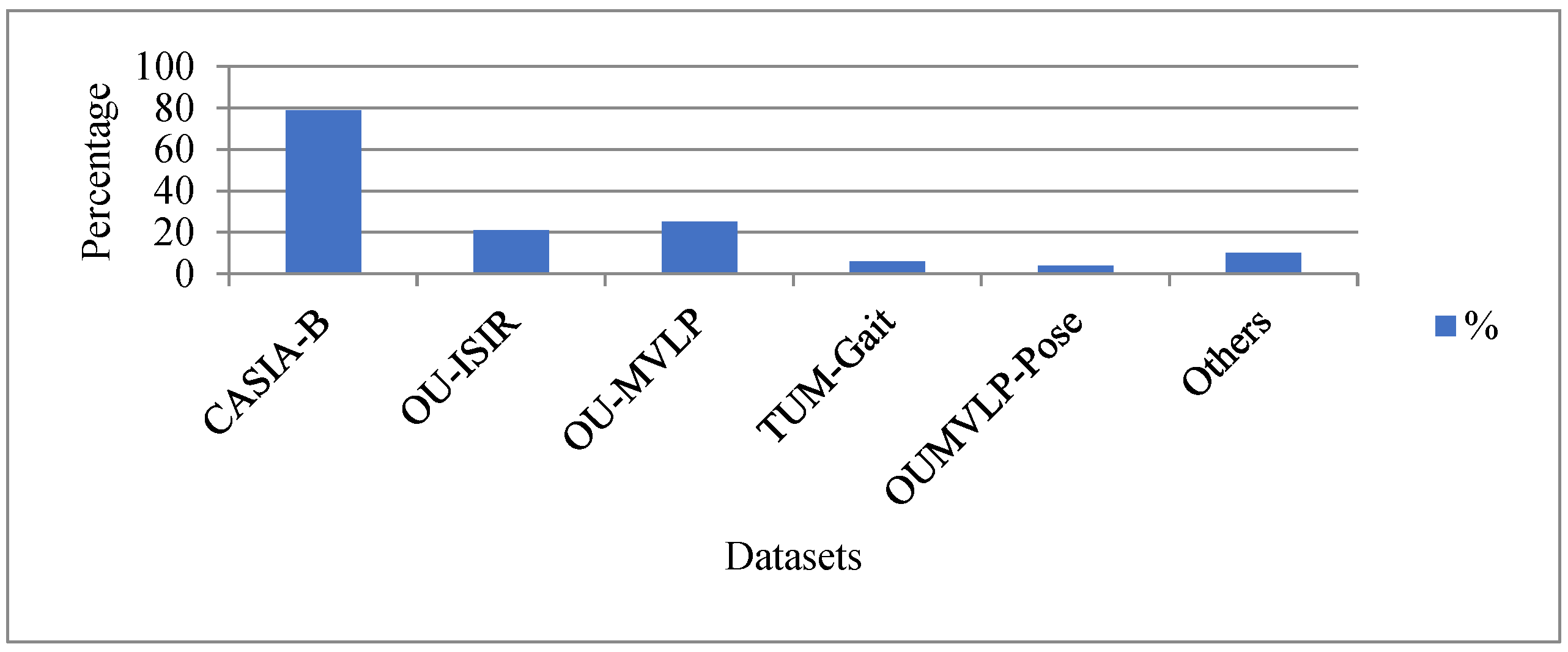
2. Datasets
2.1. CASIA-A
2.2. CASIA-B
2.3. CASIA-C
2.4. CASIA-E
2.5. OU-ISIR
2.6. OU-ISIR LP Bag
2.7. OU-ISIR MV
2.8. OU-ISIR Speed
2.9. OU-ISIR Clothing
2.10. OU-MVLP
2.11. OUMVLP-Pose
2.12. TUM GAID
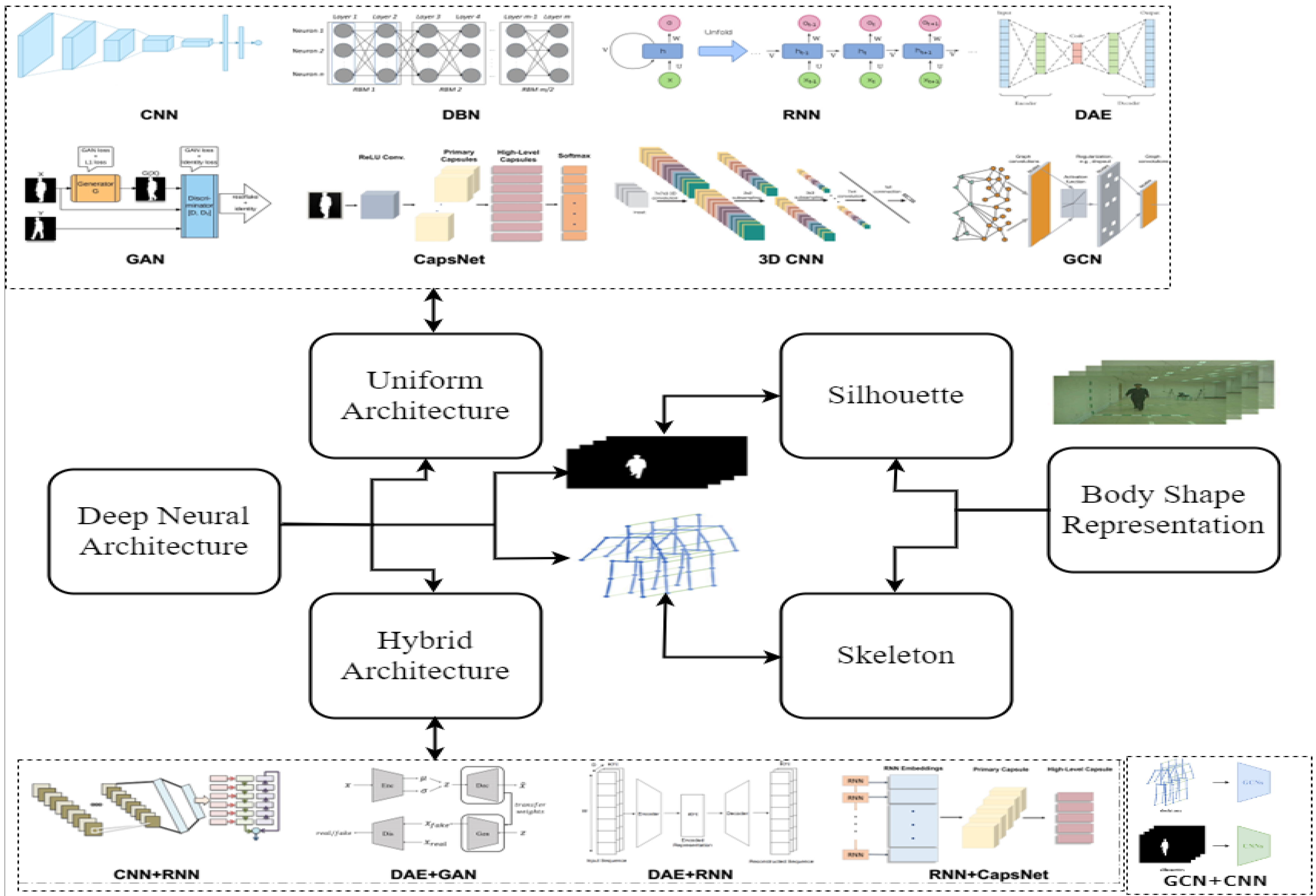
3. Taxonomy
3.1. Uniform Deep Architecture
3.1.1. Convolutional Neural Network (CNN)
3.1.2. Generative Adversarial Networks (GAN)
3.1.3. Deep Belief Networks (DBN)
3.1.4. Capsule Networks (CapsNets)
3.1.5. Recurrent Neural Networks (RNNs)
3.1.6. Three-Dimensional Convolutional Neural Networks (3DCNN)
3.1.7. Deep Auto Encoders
3.1.8. Graph Convolutional Networks
3.2. Hybrid Deep Architecture
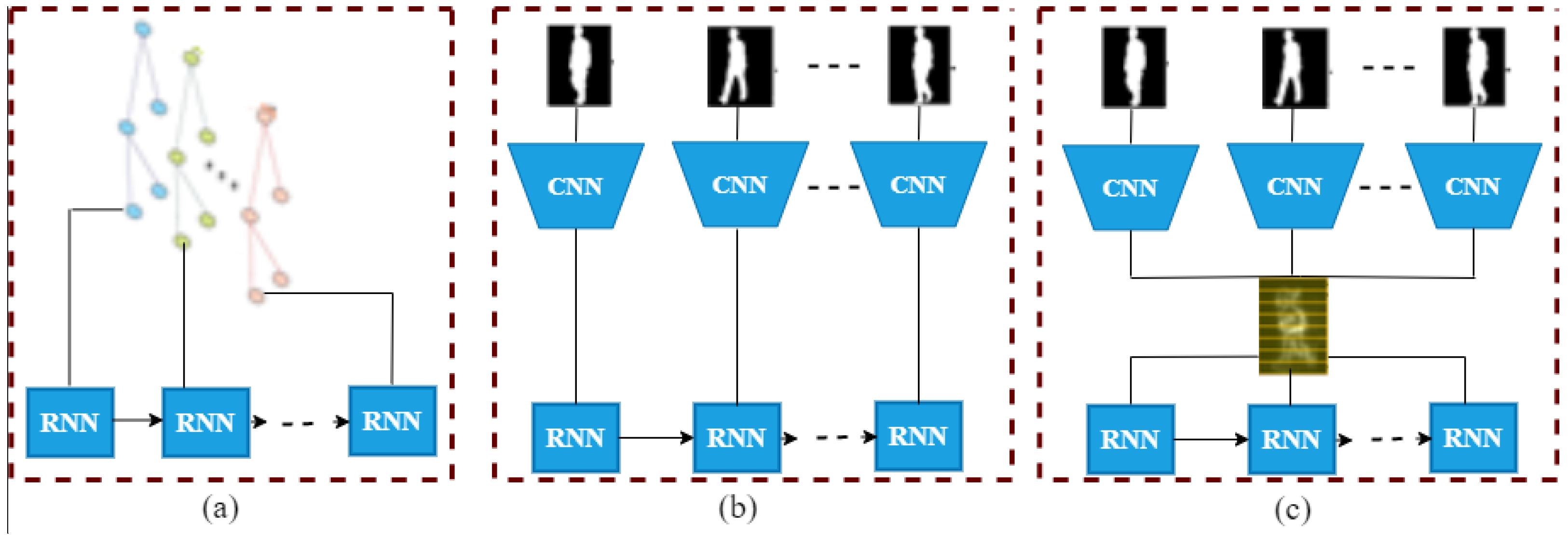
3.2.1. CNN + RNN:CNN + LSTM and CNN + GRU
3.2.2. DAE + GAN
3.2.3. DAE + RNN: DAE + LSTM
3.2.4. RNN + CapsNet:CNN + GRU + CapsNet and LSTM + CapsNet
3.2.5. CNN + GNN
4. Trends and Performance Analysis
4.1. Body Shape
Datasets
4.2. Performance of Deep Methods on Datasets
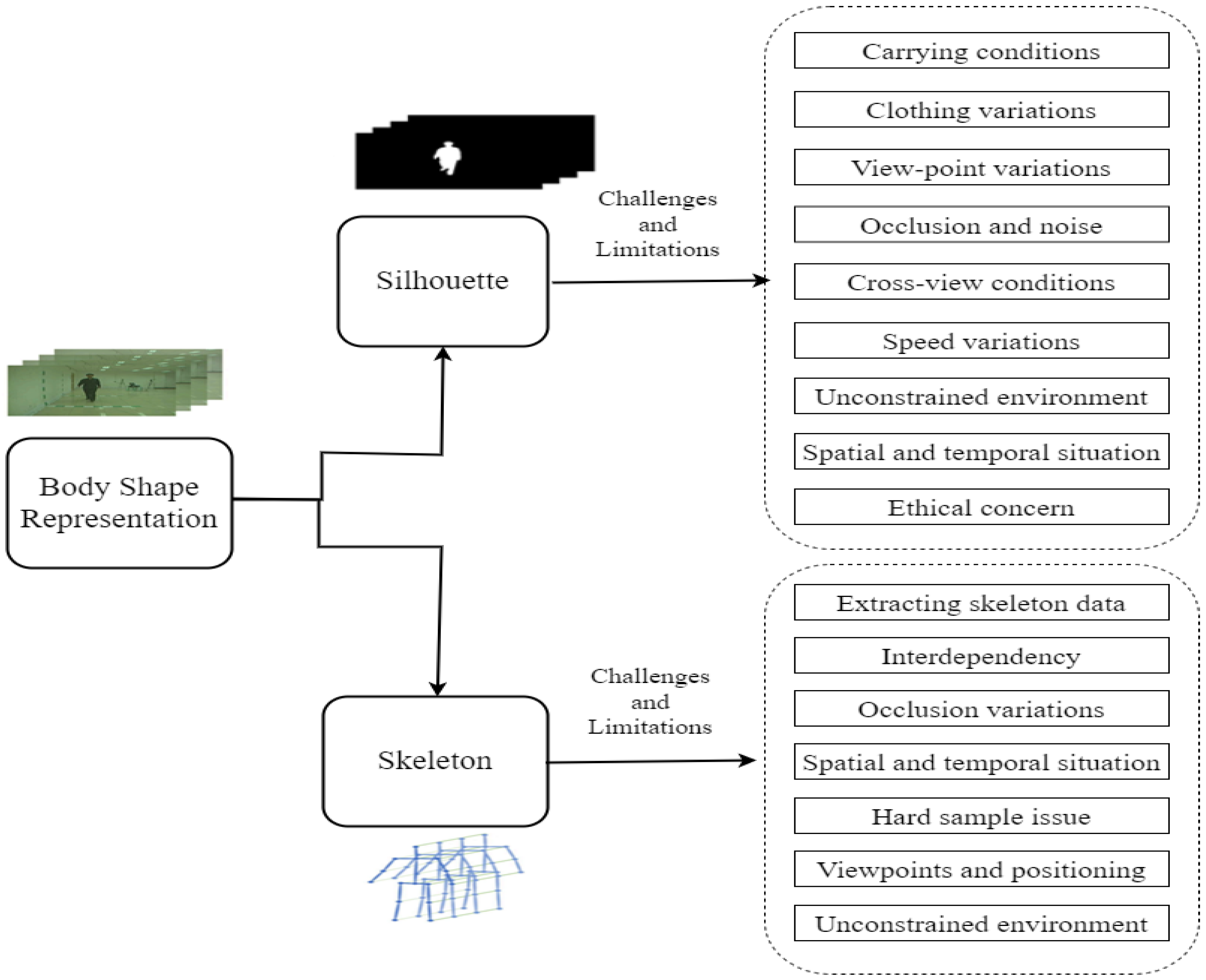
5. Limitations and Challenges
5.1. Model-Free-Based Limitations and Challenges
5.1.1. Carrying Conditions
5.1.2. Clothing Variations
5.1.3. Viewpoint Variations
5.1.4. Occlusion and Noise
5.1.5. Cross-View Conditions
5.1.6. Speed Variations
5.1.7. Unconstrained Environment
5.1.8. Spatial and Temporal Situations
5.1.9. Ethical Concerns
5.2. Model-Based Limitations and Challenges
5.2.1. Extracting Skeleton Data
5.2.2. Interdependency
5.2.3. Spatial and Temporal Situations
5.2.4. Hard Sample Issue
5.2.5. Viewpoints and Positioning
5.2.6. Unconstrained Environment
6. Problem Identification and Discussion
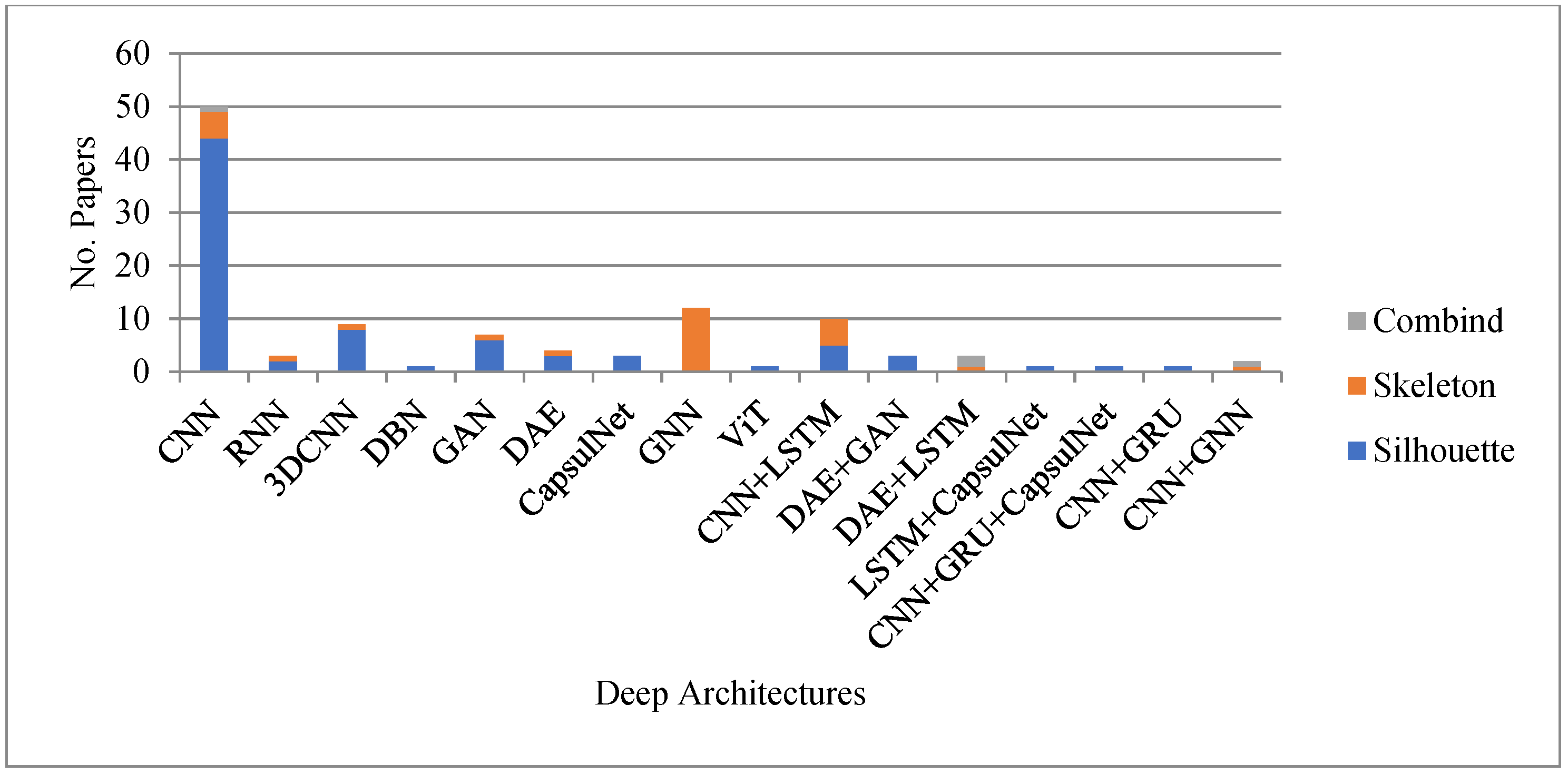
6.1. Problems with Silhouette Images Overcome by Skeleton Structure
6.2. Problems of Deep Neural Architecture for Processing Skeleton Data
- Deep structures (CNNs) treat the skeleton as grid-shaped structural data, whereas the skeleton is graph-shaped structural data, thus resulting in limited representation and difficulties with generalization.
- Gait patterns are extracted from specific body parts. However, the deep structure lacks the attention mechanisms to emphasize the significant body regions.
- Deep structures (CNNs) are rotationally invariant. For viewpoint changes, we need to be rotationally equivariant.
- Deep structures may struggle to handle gait data captured from different angles and perspectives, which can impact gait accuracy. However, CapsNet can handle this problem.
- As the gait skeleton is composed of a number of non-Euclidean graphs, it is unable to reveal the latent spatial connections in the joints of the skeleton.
7. Conclusions
8. Future Directions
- Multi-modal gait recognition: In this method, gait recognition can be combined with other types of data, such as facial recognition, voice recognition, or biometric data from wearable sensors. This can help make gait recognition systems more accurate and reliable, especially in tough situations where gait recognition alone might not be enough.
- Deep learning techniques: Deep learning models can learn complex features and patterns from large amounts of data, which can potentially improve the accuracy of gait recognition systems. This approach can also help reduce the need for manual feature engineering, which can be time-consuming and challenging.
- Robustness to environmental factors: In real-world scenarios, gait recognition systems may encounter various environmental factors such as changes in lighting, weather conditions, and terrain. Developing methods that can handle these variations can improve the accuracy and reliability of gait recognition systems in practical applications.
- Privacy-preserving gait recognition: Privacy concerns have been raised regarding the use of full-body images in gait recognition systems. Developing methods that can recognize gait while preserving individual privacy can address these concerns and increase the acceptance and adoption of gait recognition technology.
- Long-term tracking: Gait recognition systems that can track individuals over longer periods, such as days or weeks, can provide valuable information for security and surveillance applications. Developing methods that can handle variations in gait due to changes in clothing or footwear can improve the accuracy and reliability of long-term tracking systems.
- Cross-domain gait recognition: Gait recognition models trained on one dataset may not generalize well to other datasets with different conditions and populations. Developing methods that can adapt to different datasets can improve the performance and applicability of gait recognition systems across different domains.
- Real-time gait recognition: In many real-world scenarios, gait recognition systems need to operate in real time with low computational requirements and fast processing times. Developing real-time gait recognition methods can address these requirements and increase the applicability and adoption of gait recognition technology.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marín-Jiménez, M.J.; Castro, F.M.; Guil, N.; De la Torre, F.; Medina-Carnicer, R. Deep Multi-Task Learning for Gait-Based Biometrics. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 106–110. [Google Scholar]
- Sepas-Moghaddam, A.; Pereira, F.M.; Correia, P.L. Face Recognition: A Novel Multi-Level Taxonomy Based Survey. IET Biom. 2020, 9, 58–67. [Google Scholar] [CrossRef]
- Helbostad, J.L.; Leirfall, S.; Moe-Nilssen, R.; Sletvold, O. Physical Fatigue Affects Gait Characteristics in Older Persons. J. Gerontol. Ser. A Biol. Sci. Med. Sci. 2007, 62, 1010–1015. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, K.; Fookes, C.; Jillela, R.; Sridharan, S.; Ross, A. Long Range Iris Recognition: A Survey. Pattern Recognit. 2017, 72, 123–143. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Acien, A.; Morales, A.; Monaco, J.V.; Vera-Rodriguez, R.; Fierrez, J. TypeNet: Deep learning keystroke biometrics. IEEE Trans. Biom. Behav. Identity Sci. 2021, 4, 57–70. [Google Scholar] [CrossRef]
- Makihara, Y.; Nixon, M.S.; Yagi, Y. Gait Recognition: Databases, Representations, and Applications. In Computer Vision: A Reference Guide; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–13. [Google Scholar]
- Rani, V.; Kumar, M. Human Gait Recognition: A Systematic Review. Multimed. Tools Appl. 2023, 1–35. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Etemad, A. Deep Gait Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 264–284. [Google Scholar] [CrossRef]
- Liang, J.; Fan, C.; Hou, S.; Shen, C.; Huang, Y.; Yu, S. Gaitedge: Beyond Plain End-to-End Gait Recognition for Better Practicality. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Part V. Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 375–390. [Google Scholar]
- Kumar, P.; Singh, S.; Garg, A.; Prabhat, N. Hand written signature recognition & verification using neural network. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 44–49. [Google Scholar]
- Ghalleb, A.E.K.; Slamia, R.B.; Amara, N.E.B. Contribution to the Fusion of Soft Facial and Body Biometrics for Remote People Identification. In Proceedings of the 2016 2nd International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Monastir, Tunisia, 21–23 March 2016; IEEE: Piscataway, NJ, USA; pp. 252–257. [Google Scholar]
- Turner, A.; Hayes, S. The classification of minor gait alterations using wearable sensors and deep learning. IEEE Trans. Biomed. Eng. 2019, 66, 3136–3145. [Google Scholar] [CrossRef]
- Muro-De-La-Herran, A.; Garcia-Zapirain, B.; Mendez-Zorrilla, A. Gait analysis methods: An overview of wearable and non-wearable systems, highlighting clinical applications. Sensors 2014, 14, 3362–3394. [Google Scholar] [CrossRef]
- Feng, Y.; Li, Y.; Luo, J. Learning Effective Gait Features Using LSTM. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 325–330. [Google Scholar]
- Lee, T.K.; Belkhatir, M.; Sanei, S. A comprehensive review of past and present vision-based techniques for gait recognition. Multimed. Tools Appl. 2014, 72, 2833–2869. [Google Scholar] [CrossRef]
- Sakata, A.; Takemura, N.; Yagi, Y. Gait-Based Age Estimation Using Multi-Stage Convolutional Neural Network. IPSJ Trans. Comput. Vis. Appl. 2019, 11, 4. [Google Scholar] [CrossRef]
- Lu, J.; Tan, Y.P. Gait-Based Human Age Estimation. IEEE Trans. Inf. Forensics Secur. 2010, 5, 761–770. [Google Scholar] [CrossRef]
- Makihara, Y.; Okumura, M.; Iwama, H.; Yagi, Y. Gait-Based Age Estimation Using a Whole-Generation Gait Database. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Oliveira, E.L.; Lima, C.A.; Peres, S.M. Fusion of Face and Gait for Biometric Recognition: Systematic Literature Review. In Proceedings of the XII Brazilian Symposium on Information Systems on Brazilian Symposium on Information Systems: Information Systems in the Cloud Computing Era, Porto Alegre, Brazil, 17–20 May 2016; Volume 1, pp. 108–115. [Google Scholar]
- Klöpfer-Krämer, I.; Brand, A.; Wackerle, H.; Müßig, J.; Kröger, I.; Augat, P. Gait Analysis–Available Platforms for Outcome Assessment. Injury 2020, 51, S90–S96. [Google Scholar] [CrossRef]
- Stevenage, S.V.; Nixon, M.S.; Vince, K. Visual Analysis of Gait as a Cue to Identity. Appl. Cogn. Psychol. Off. J. Soc. Appl. Res. Mem. Cogn. 1999, 13, 513–526. [Google Scholar] [CrossRef]
- Deligianni, F.; Guo, Y.; Yang, G.Z. From Emotions to Mood Disorders: A Survey on Gait Analysis Methodology. IEEE J. Biomed. Health Inform. 2019, 23, 2302–2316. [Google Scholar] [CrossRef] [PubMed]
- Sigal, L.; Fleet, D.J.; Troje, N.F.; Livne, M. Human Attributes from 3D Pose Tracking. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Part III. Springer: Berlin/Heidelberg, Germany; Volume 11, pp. 243–257. [Google Scholar]
- Koide, K.; Miura, J. Identification of a Specific Person Using Color, Height, and Gait Features for a Person Following Robot. Robot. Auton. Syst. 2016, 84, 76–87. [Google Scholar] [CrossRef]
- Liu, C.; Gong, S.; Loy, C.C.; Lin, X. Person Re-Identification: What Features Are Important? In Proceedings of the Computer Vision–ECCV 2012. Workshops and Demonstrations, Florence, Italy, 7–13 October 2012; Part I. Springer: Berlin/Heidelberg, Germany; pp. 391–401. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep Learning for Sensor-Based Activity Recognition: A Survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Karg, M.; Kühnlenz, K.; Buss, M. Recognition of Affect Based on Gait Patterns. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 1050–1061. [Google Scholar] [CrossRef]
- Gul, S.; Malik, M.I.; Khan, G.M.; Shafait, F. Multi-View Gait Recognition System Using Spatio-Temporal Features and Deep Learning. Expert Syst. Appl. 2021, 179, 115057. [Google Scholar] [CrossRef]
- Bijalwan, V.; Semwal, V.B.; Mandal, T.K. Fusion of Multi-Sensor-Based Biomechanical Gait Analysis Using Vision and Wearable Sensor. IEEE Sensors J. 2021, 21, 14213–14220. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, B.; Coenen, F. Multi-Attributes Gait Identification by Convolutional Neural Networks. In Proceedings of the 2015 8th International Congress on Image and Signal Processing (CISP), Shenyang, China, 14–16 October 2015; IEEE: Piscataway, NJ, USA; pp. 642–647. [Google Scholar]
- Shiraga, K.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Geinet: View-Invariant Gait Recognition Using a Convolutional Neural Network. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A Framework for Evaluating the Effect of View Angle, Clothing, and Carrying Condition on Gait Recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Washington, DC, USA, 20–24 August 2006; IEEE: Piscataway, NJ, USA; Volume 4, pp. 441–444. [Google Scholar]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 209–226. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Kusakunniran, W.; Wu, Q.; Zhang, J.; Tang, Z. Robust CNN-Based Gait Verification and Identification Using Skeleton Gait Energy Image. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; IEEE: Piscataway, NJ, USA; pp. 1–7. [Google Scholar]
- Zhang, Z.; Tran, L.; Yin, X.; Atoum, Y.; Liu, X.; Wan, J.; Wang, N. Gait Recognition via Disentangled Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 4710–4719. [Google Scholar]
- Chao, H.; He, Y.; Zhang, J.; Feng, J. GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA; Volume 33, pp. 8126–8133. [Google Scholar]
- Sokolova, A.; Konushin, A. Pose-Based Deep Gait Recognition. IET Biom. 2019, 8, 134–143. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Etemad, A. View-Invariant Gait Recognition with Attentive Recurrent Learning of Partial Representations. IEEE Trans. Biom. Behav. Identity Sci. 2020, 3, 124–137. [Google Scholar] [CrossRef]
- Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; He, Z. GaitPart: Temporal Part-Based Model for Gait Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14225–14233. [Google Scholar]
- Lin, B.; Zhang, S.; Bao, F. Gait Recognition with Multiple-Temporal-Scale 3D Convolutional Neural Network. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; ACM: New York, NY, USA; pp. 3054–3062. [Google Scholar]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Yu, S.; Ren, M. End-to-End Model-Based Gait Recognition. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Springer: Berlin/Heidelberg, Germany. [Google Scholar]
- Hou, S.; Cao, C.; Liu, X.; Huang, Y. Gait Lateral Network: Learning Discriminative and Compact Representations for Gait Recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part IX. Springer: Berlin/Heidelberg, Germany; pp. 382–398. [Google Scholar]
- Shopon, M.; Bari, A.H.; Gavrilova, M.L. Residual Connection-Based Graph Convolutional Neural Networks for Gait Recognition. Vis. Comput. 2021, 37, 2713–2724. [Google Scholar] [CrossRef]
- Sheng, W.; Li, X. Multi-Task Learning for Gait-Based Identity Recognition and Emotion Recognition Using Attention Enhanced Temporal Graph Convolutional Network. Pattern Recognit. 2021, 114, 107868. [Google Scholar] [CrossRef]
- Huang, Z.; Xue, D.; Shen, X.; Tian, X.; Li, H.; Huang, J.; Hua, X.S. 3D Local Convolutional Neural Networks for Gait Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA; pp. 14920–14929. [Google Scholar]
- Marín-Jiménez, M.J.; Castro, F.M.; Delgado-Escaño, R.; Kalogeiton, V.; Guil, N. UGaitNet: Multimodal Gait Recognition with Missing Input Modalities. IEEE Trans. Inf. Forensics Secur. 2021, 16, 5452–5462. [Google Scholar] [CrossRef]
- Wang, L.; Han, R.; Feng, W. Combining the Silhouette and Skeleton Data for Gait Recognition. Proceedings 2023, 1, 1–5. [Google Scholar]
- Shopon, M.; Hsu, G.S.J.; Gavrilova, M.L. Multiview Gait Recognition on Unconstrained Path Using Graph Convolutional Neural Network. IEEE Access 2022, 10, 54572–54588. [Google Scholar] [CrossRef]
- Mogan, J.N.; Lee, C.P.; Lim, K.M.; Muthu, K.S. Gait-ViT: Gait Recognition with Vision Transformer. Sensors 2022, 22, 7362. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional Multi-Person Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA; pp. 2334–2343. [Google Scholar]
- Wan, C.; Wang, L.; Phoha, V.V. (Eds.) A Survey on Gait Recognition. ACM Comput. Surv. 2018, 51, 1–35. [Google Scholar]
- Rida, I.; Almaadeed, N.; Almaadeed, S. Robust Gait Recognition: A Comprehensive Survey. IET Biom. 2019, 8, 14–28. [Google Scholar] [CrossRef]
- Nambiar, A.; Bernardino, A.; Nascimento, J.C. Gait-Based Person Re-identification: A Survey. ACM Comput. Surv. 2019, 52, 1–34. [Google Scholar] [CrossRef]
- Marsico, M.D.; Mecca, A. A Survey on Gait Recognition via Wearable Sensors. ACM Comput. Surv. 2019, 52, 1–39. [Google Scholar] [CrossRef]
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. Vision-Based Gait Recognition: A Survey. IEEE Access 2018, 6, 70497–70527. [Google Scholar] [CrossRef]
- Connor, P.; Ross, A. Biometric Recognition by Gait: A Survey of Modalities and Features. Comput. Vis. Image Underst. 2018, 167, 1–27. [Google Scholar] [CrossRef]
- Nordin, M.J.; Saadoon, A. A Survey of Gait Recognition Based on Skeleton Model for Human Identification. Res. J. Appl. Sci. Eng. Technol. 2016, 12, 756–763. [Google Scholar] [CrossRef]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Multi-View Large Population Gait Dataset and Its Performance Evaluation for Cross-View Gait Recognition. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 4. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Wang, W.; Wang, L. CASIA-E: A Large Comprehensive Dataset for Gait Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2801–2815. [Google Scholar] [CrossRef]
- Makihara, Y.; Mannami, H.; Yagi, Y. Gait Analysis of Gender and Age Using a Large-Scale Multi-View Gait Database. In Proceedings of the Computer Vision—ACCV 2010: 10th Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Revised Selected Papers, Part II. Springer: Berlin/Heidelberg, Germany, 2011; Volume 10, pp. 440–451. [Google Scholar]
- Makihara, Y.; Mannami, H.; Tsuji, A.; Hossain, M.A.; Sugiura, K.; Mori, A.; Yagi, Y. The OU-ISIR Gait Database Comprising the Treadmill Dataset. IPSJ Trans. Comput. Vis. Appl. 2012, 4, 53–62. [Google Scholar] [CrossRef]
- Iwama, H.; Okumura, M.; Makihara, Y.; Yagi, Y. The OU-ISIR Gait Database Comprising the Large Population Dataset and Performance Evaluation of Gait Recognition. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1511–1521. [Google Scholar] [CrossRef]
- Uddin, M.; Ngo, T.T.; Makihara, Y.; Takemura, N.; Li, X.; Muramatsu, D.; Yagi, Y. The OU-ISIR Large Population Gait Database with Real-Life Carried Object and Its Performance Evaluation. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 5. [Google Scholar] [CrossRef]
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette Analysis-Based Gait Recognition for Human Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Tan, D.; Huang, K.; Yu, S.; Tan, T. Efficient Night Gait Recognition Based on Template Matching. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Washington, DC, USA, 20–24 August 2006; IEEE: Piscataway, NJ, USA; Volume 3, pp. 1000–1003. [Google Scholar]
- Zhang, Y.; Huang, Y.; Wang, L.; Yu, S. A Comprehensive Study on Gait Biometrics Using a Joint CNN-Based Method. Pattern Recognit. 2019, 93, 228–236. [Google Scholar] [CrossRef]
- Tsuji, A.; Makihara, Y.; Yagi, Y. Silhouette Transformation Based on Walking Speed for Gait Identification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA; pp. 717–722. [Google Scholar]
- Hossain, M.A.; Makihara, Y.; Wang, J.; Yagi, Y. Clothing-Invariant Gait Identification Using Part-Based Clothing Categorization and Adaptive Weight Control. Pattern Recognit. 2010, 43, 2281–2291. [Google Scholar] [CrossRef]
- An, W.; Yu, S.; Makihara, Y.; Wu, X.; Xu, C.; Yu, Y.; Liao, R.; Yagi, Y. Performance Evaluation of Model-Based Gait on Multi-View Very Large Population Database with Pose Sequences. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 421–430. [Google Scholar] [CrossRef]
- Hofmann, M.; Bachmann, S.; Rigoll, G. 2.5D Gait Biometrics Using the Depth Gradient Histogram Energy Image. In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; IEEE: Piscataway, NJ, USA; pp. 399–403. [Google Scholar]
- Qin, H.; Chen, Z.; Guo, Q.; Wu, Q.J.; Lu, M. RPNet: Gait Recognition with Relationships between Each Body-Parts. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2990–3000. [Google Scholar] [CrossRef]
- Yu, S.; Chen, H.; Garcia Reyes, E.B.; Poh, N. GaitGAN: Invariant Gait Feature Extraction Using Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA; pp. 30–37. [Google Scholar]
- Sharif, M.I.; Khan, M.A.; Alqahtani, A.; Nazir, M.; Alsubai, S.; Binbusayyis, A.; Damaševičius, R. Deep Learning and Kurtosis-Controlled, Entropy-Based Framework for Human Gait Recognition Using Video Sequences. Electronics 2022, 11, 334. [Google Scholar] [CrossRef]
- Wolf, T.; Babaee, M.; Rigoll, G. Multi-View Gait Recognition Using 3D Convolutional Neural Networks. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA; pp. 4165–4169. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Hinton, G.E.; Sejnowski, T.J. Learning and Relearning in Boltzmann Machines. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 282–317. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Yu, S.; Chen, H.; Wang, Q.; Shen, L.; Huang, Y. Invariant Feature Extraction for Gait Recognition Using Only One Uniform Model. Neurocomputing 2017, 239, 81–93. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Advances in Neural Information Processing Systems; ACM Digital Library: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodola, E.; Svoboda, J.; Bronstein, M.M. Geometric Deep Learning on Graphs and Manifolds Using Mixture Model CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5115–5124. [Google Scholar]
- Batchuluun, G.; Yoon, H.S.; Kang, J.K.; Park, K.R. Gait-Based Human Identification by Combining Shallow Convolutional Neural Network-Stacked Long Short-Term Memory and Deep Convolutional Neural Network. IEEE Access 2018, 6, 63164–63186. [Google Scholar] [CrossRef]
- Yu, S.; Liao, R.; An, W.; Chen, H.; Garcıa, E.B.; Huang, Y.; Poh, N. GaitGANv2: Invariant Gait Feature Extraction Using Generative Adversarial Networks. Pattern Recognition 2019, 87, 179–189. [Google Scholar] [CrossRef]
- Jun, K.; Lee, D.W.; Lee, K.; Lee, S.; Kim, M.S. Feature Extraction Using an RNN Autoencoder for Skeleton-Based Abnormal Gait Recognition. IEEE Access 2020, 8, 19196–19207. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, X.; Shen, Y.; Du, B.; Zhao, G.; Cui, L.; Wen, H. Event-Stream Representation for Human Gaits Identification Using Deep Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3436–3449. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Li, J.; Jain, A.K.; Shan, S.; Chen, X. Tattoo Image Search at Scale: Joint Detection and Compact Representation Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2333–2348. [Google Scholar] [CrossRef]
- Hou, S.; Liu, X.; Cao, C.; Huang, Y. Set Residual Network for Silhouette-Based Gait Recognition. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 384–393. [Google Scholar] [CrossRef]
- Han, F.; Li, X.; Zhao, J.; Shen, F. A Unified Perspective of Classification-Based Loss and Distance-Based Loss for Cross-View Gait Recognition. Pattern Recognit. 2022, 125, 108519. [Google Scholar] [CrossRef]
- Hou, S.; Liu, X.; Cao, C.; Huang, Y. Gait Quality Aware Network: Toward the Interpretability of Silhouette-Based Gait Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Dou, H.; Zhang, P.; Zhao, Y.; Dong, L.; Qin, Z.; Li, X. GaitMPL: Gait Recognition with Memory-Augmented Progressive Learning. IEEE Trans. Image Process. 2022. [CrossRef] [PubMed]
- Li, H.; Qiu, Y.; Zhao, H.; Zhan, J.; Chen, R.; Wei, T.; Huang, Z. GaitSlice: A Gait Recognition Model Based on Spatio-Temporal Slice Features. Pattern Recognit. 2022, 124, 108453. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Agarap, A.F. Deep Learning Using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Karlik, B.; Olgac, A.V. Performance Analysis of Various Activation Functions in Generalized MLP Architectures of Neural Networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Xu, J.; Li, H.; Hou, S. Attention-Based Gait Recognition Network with Novel Partial Representation PGOFI Based on Prior Motion Information. Digit. Signal Process. 2023, 13, 103845. [Google Scholar] [CrossRef]
- Saleh, A.M.; Hamoud, T. Analysis and Best Parameters Selection for Person Recognition Based on Gait Model Using CNN Algorithm and Image Augmentation. J. Big Data 2021, 8, 1. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A. Gait Recognition for Person Re-Identification. J. Supercomput. 2021, 77, 3653–3672. [Google Scholar] [CrossRef]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y. End-to-End Model-Based Gait Recognition Using Synchronized Multi-View Pose Constraint. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA; pp. 4106–4115. [Google Scholar]
- Chao, H.; Wang, K.; He, Y.; Zhang, J.; Feng, J. GaitSet: Cross-View Gait Recognition through Utilizing Gait as a Deep Set. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3467–3478. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Huang, Y.; Jia, N.; Wang, L. GaitNet: An End-to-End Network for Gait-Based Human Identification. Pattern Recognit. 2019, 96, 106988. [Google Scholar] [CrossRef]
- He, Y.; Zhang, J.; Shan, H.; Wang, L. Multi-Task GANs for View-Specific Feature Learning in Gait Recognition. IEEE Trans. Inf. Forensics Secur. 2018, 14, 102–113. [Google Scholar] [CrossRef]
- Zhang, K.; Luo, W.; Ma, L.; Liu, W.; Li, H. Learning Joint Gait Representation via Quintuplet Loss Minimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA; pp. 4700–4709. [Google Scholar]
- Li, N.; Zhao, X.; Ma, C. JointsGait: A Model-Based Gait Recognition Method Based on Gait Graph Convolutional Networks and Joints Relationship Pyramid Mapping. arXiv 2020, arXiv:2005.08625. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Wang, Y.; Song, C.; Huang, Y.; Wang, Z.; Wang, L. Learning View Invariant Gait Features with Two-Stream GAN. Neurocomputing 2019, 339, 245–254. [Google Scholar] [CrossRef]
- Zhang, P.; Wu, Q.; Xu, J. VT-GAN: View Transformation GAN for Gait Recognition Across Views. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Zhang, P.; Wu, Q.; Xu, J. VN-GAN: Identity-Preserved Variation Normalizing GAN for Gait Recognition. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Ren, M. Gait Recognition Invariant to Carried Objects Using Alpha Blending Generative Adversarial Networks. Pattern Recognit. 2020, 105, 107376. [Google Scholar] [CrossRef]
- Benouis, M.; Senouci, M.; Tlemsani, R.; Mostefai, L. Gait Recognition Based on Model-Based Methods and Deep Belief Networks. Int. J. Biom. 2016, 8, 237–253. [Google Scholar] [CrossRef]
- Nair, B.M.; Kendricks, K.D. Deep Network for Analyzing Gait Patterns in Low Resolution Video Towards Threat Identification. Electron. Imaging 2016, 2016, art00015. [Google Scholar] [CrossRef]
- Xu, Z.; Lu, W.; Zhang, Q.; Yeung, Y.; Chen, X. Gait Recognition Based on Capsule Network. J. Vis. Commun. Image Represent. 2019, 59, 159–167. [Google Scholar] [CrossRef]
- Wang, Y.; Bilinski, P.; Bremond, F.; Dantcheva, A. Imaginator: Conditional Spatio-Temporal GAN for Video Generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; IEEE: Piscataway, NJ, USA; pp. 1160–1169. [Google Scholar]
- Wu, Y.; Hou, J.; Su, Y.; Wu, C.; Huang, M.; Zhu, Z. Gait Recognition Based on Feedback Weight Capsule Network. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; IEEE: Piscataway, NJ, USA; Volume 1, pp. 155–160. [Google Scholar]
- Sepas-Moghaddam, A.; Ghorbani, S.; Troje, N.F.; Etemad, A. Gait Recognition Using Multi-Scale Partial Representation Transformation with Capsules. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA; pp. 8045–8052. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Liu, W.; Zhang, C.; Ma, H.; Li, S. Learning Efficient Spatial-Temporal Gait Features with Deep Learning for Human Identification. Neuroinformatics 2018, 16, 457–471. [Google Scholar] [CrossRef]
- Battistone, F.; Petrosino, A. TGLSTM: A Time Based Graph Deep Learning Approach to Gait Recognition. Pattern Recognit. Lett. 2019, 126, 132–138. [Google Scholar] [CrossRef]
- Yu, S.; Tan, T.; Huang, K.; Jia, K.; Wu, X. A Study on Gait-Based Gender Classification. IEEE Trans. Image Process. 2009, 18, 1905–1910. [Google Scholar] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Li, X.; Maybank, S.J.; Yan, S.; Tao, D.; Xu, D. Gait Components and Their Application to Gender Recognition. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 145–155. [Google Scholar]
- Xing, W.; Li, Y.; Zhang, S. View-Invariant Gait Recognition Method by Three-Dimensional Convolutional Neural Network. J. Electron. Imaging 2018, 27, 013010. [Google Scholar] [CrossRef]
- Thapar, D.; Nigam, A.; Aggarwal, D.; Agarwal, P. VGR-Net: A View Invariant Gait Recognition Network. In Proceedings of the 2018 IEEE 4th International Conference on Identity, Security, and Behavior Analysis (ISBA), Singapore, 11–12 January 2018; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- Lin, B.; Zhang, S.; Yu, X. Gait Recognition via Effective Global-Local Feature Representation and Local Temporal Aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14648–14656. [Google Scholar]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Ren, M. Joint Intensity Transformer Network for Gait Recognition Robust Against Clothing and Carrying Status. IEEE Trans. Inf. Forensics Secur. 2019, 14, 3102–3115. [Google Scholar] [CrossRef]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Ren, M. Gait Recognition via Semi-Supervised Disentangled Representation Learning to Identity and Covariate Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13309–13319. [Google Scholar]
- Teepe, T.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Towards a Deeper Understanding of Skeleton-Based Gait Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–24 June 2022; pp. 1569–1577. [Google Scholar]
- Song, X.; Huang, Y.; Shan, C.; Wang, J.; Chen, Y. Distilled Light GaitSet: Towards Scalable Gait Recognition. Pattern Recognit. Lett. 2022, 157, 27–34. [Google Scholar] [CrossRef]
- Teepe, T.; Khan, A.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Gaitgraph: Graph Convolutional Network for Skeleton-Based Gait Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA; pp. 2314–2318. [Google Scholar]
- Zhang, Y.; Huang, Y.; Yu, S.; Wang, L. Cross-View Gait Recognition by Discriminative Feature Learning. IEEE Trans. Image Process. 2020, 29, 1001–1015. [Google Scholar] [CrossRef]
- Liu, D.; Ye, M.; Li, X.; Zhang, F.; Lin, L. Memory-Based Gait Recognition. In Proceedings of the BMVC, York, UK, 19–22 September 2016; pp. 1–12. [Google Scholar]
- Li, S.; Liu, W.; Ma, H.; Zhu, S. Beyond View Transformation: Cycle-Consistent Global and Partial Perception GAN for View-Invariant Gait Recognition. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Zhang, Z.; Tran, L.; Liu, F.; Liu, X. On Learning Disentangled Representations for Gait Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 345–360. [Google Scholar] [CrossRef]
- Zhao, A.; Li, J.; Ahmed, M. SpiderNet: A Spiderweb Graph Neural Network for Multi-View Gait Recognition. Knowl.-Based Syst. 2020, 206, 106273. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, Y.; Wang, L. Learning Representative Deep Features for Image Set Analysis. IEEE Trans. Multimed. 2015, 17, 1960–1968. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, W.; Ma, H.; Fu, H. Siamese Neural Network Based Gait Recognition for Human Identification. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; IEEE: Piscataway, NJ, USA; pp. 2832–2836. [Google Scholar]
- Alotaibi, M.; Mahmood, A. Improved Gait Recognition Based on Specialized Deep Convolutional Neural Network. Comput. Vis. Image Underst. 2017, 164, 103–110. [Google Scholar] [CrossRef]
- Li, C.; Min, X.; Sun, S.; Lin, W.; Tang, Z. DeepGait: A Learning Deep Convolutional Representation for View-Invariant Gait Recognition Using Joint Bayesian. Appl. Sci. 2017, 7, 210. [Google Scholar] [CrossRef]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. On Input/Output Architectures for Convolutional Neural Network-Based Cross-View Gait Recognition. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 2708–2719. [Google Scholar] [CrossRef]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; López-Tapia, S.; de la Blanca, N.P. Evaluation of CNN Architectures for Gait Recognition Based on Optical Flow Maps. In Proceedings of the 2017 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 20–22 September 2017; IEEE: Piscataway, NJ, USA; pp. 1–5. [Google Scholar]
- Tong, S.; Ling, H.; Fu, Y.; Wang, D. Cross-View Gait Identification with Embedded Learning. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, New York, NY, USA, 23–27 October 2017; ACM: New York, NY, USA; pp. 385–392. [Google Scholar]
- Liao, R.; Cao, C.; Garcia, E.B.; Yu, S.; Huang, Y. Pose-based temporal-spatial network (PTSN) for gait recognition with carrying and clothing variations. In Proceedings of the Chinese Conference on Biometric Recognition, Beijing, China, 16–18 October 2017. [Google Scholar]
- Tong, S.; Fu, Y.; Yue, X.; Ling, H. Multi-View Gait Recognition Based on a Spatial-Temporal Deep Neural Network. IEEE Access 2018, 6, 57583–57596. [Google Scholar] [CrossRef]
- Wu, H.; Weng, J.; Chen, X.; Lu, W. Feedback Weight Convolutional Neural Network for Gait Recognition. J. Vis. Commun. Image Represent. 2018, 55, 424–432. [Google Scholar] [CrossRef]
- An, W.; Liao, R.; Yu, S.; Huang, Y.; Yuen, P.C. Improving Gait Recognition with 3D Pose Estimation. In Proceedings of the Biometric Recognition: 13th Chinese Conference, CCBR 2018, Urumqi, China, 11–12 August 2018; Springer International Publishing: Cham, Switzerland; pp. 137–147. [Google Scholar]
- Tong, S.; Fu, Y.; Ling, H. Gait Recognition with Cross-Domain Transfer Networks. J. Syst. Archit. 2019, 93, 40–47. [Google Scholar] [CrossRef]
- Tong, S.B.; Fu, Y.Z.; Ling, H.F. Cross-View Gait Recognition Based on a Restrictive Triplet Network. Pattern Recognit. Lett. 2019, 125, 212–219. [Google Scholar] [CrossRef]
- Sokolova, A.; Konushin, A. View Resistant Gait Recognition. In Proceedings of the 3rd International Conference on Video and Image Processing, Shanghai, China, 20–23 December 2019; pp. 7–12. [Google Scholar]
- Li, S.; Liu, W.; Ma, H. Attentive Spatial-Temporal Summary Networks for Feature Learning in Irregular Gait Recognition. IEEE Trans. Multimed. 2019, 21, 2361–2375. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Yan, W.Q. Gait Recognition Using Multichannel Convolutional Neural Networks. Neural Comput. Appl. 2020, 32, 14275–14285. [Google Scholar] [CrossRef]
- Wang, X.; Yan, W.Q. Cross-View Gait Recognition through Ensemble Learning. Neural Comput. Appl. 2020, 32, 7275–7287. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A Model-Based Gait Recognition Method with Body Pose and Human Prior Knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J. Gait Feature Extraction and Gait Classification Using Two-Branch CNN. Multimed. Tools Appl. 2020, 79, 2917–2930. [Google Scholar] [CrossRef]
- Wang, X.; Yan, W.Q. Human Gait Recognition Based on Frame-by-Frame Gait Energy Images and Convolutional Long Short-Term Memory. Int. J. Neural Syst. 2020, 30, 1950027. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Makihara, Y.; Li, X.; Yagi, Y.; Lu, J. Cross-View Gait Recognition Using Pairwise Spatial Transformer Networks. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 260–274. [Google Scholar] [CrossRef]
- Wang, X.; Yan, W.Q. Non-Local Gait Feature Extraction and Human Identification. Multimed. Tools Appl. 2021, 80, 6065–6078. [Google Scholar] [CrossRef]
- Wang, X.; Yan, K. Gait Classification through CNN-Based Ensemble Learning. Multimed. Tools Appl. 2021, 80, 1565–1581. [Google Scholar] [CrossRef]
- Wen, J. Gait Recognition Based on GF-CNN and Metric Learning. J. Inf. Process. Syst. 2020, 16, 1105–1112. [Google Scholar]
- Mehmood, A.; Khan, M.A.; Sharif, M.; Khan, S.A.; Shaheen, M.; Saba, T.; Riaz, N.; Ashraf, I. Prosperous Human Gait Recognition: An End-to-End System Based on Pre-Trained CNN Features Selection. Multimed. Tools Appl. 2020, 1–21. [Google Scholar] [CrossRef]
- Yousef, R.N.; Khalil, A.T.; Samra, A.S.; Ata, M.M. Model-Based and Model-Free Deep Features Fusion for High-Performance Human Gait Recognition. J. Supercomput. 2023, 1–38. [Google Scholar] [CrossRef]
- Pan, J.; Sun, H.; Wu, Y.; Yin, S.; Wang, S. Optimization of GaitSet for Gait Recognition. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Springer: Berlin/Heidelberg, Germany. [Google Scholar]
- Zhang, P.; Song, Z.; Xing, X. Multi-Grid Spatial and Temporal Feature Fusion for Human Identification at a Distance. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020; pp. 1–5. [Google Scholar]
- Huang, G.; Lu, Z.; Pun, C.M.; Cheng, L. Flexible Gait Recognition Based on Flow Regulation of Local Features between Key Frames. IEEE Access 2020, 8, 75381–75392. [Google Scholar] [CrossRef]
- Su, J.; Zhao, Y.; Li, X. Deep Metric Learning Based on Center-Ranked Loss for Gait Recognition. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA; pp. 4077–4081. [Google Scholar]
- Liao, R.; An, W.; Yu, S.; Li, Z.; Huang, Y. Dense-View GEIs Set: View Space Covering for Gait Recognition Based on Dense-View GAN. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; IEEE: Piscataway, NJ, USA; pp. 1–9. [Google Scholar]
- Huynh-The, T.; Hua, C.H.; Tu, N.A.; Kim, D.S. Learning 3D Spatiotemporal Gait Feature by Convolutional Network for Person Identification. Neurocomputing 2020, 397, 192–202. [Google Scholar] [CrossRef]
- Supraja, P.; Tom, R.J.; Tiwari, R.S.; Vijayakumar, V.; Liu, Y. 3D Convolution Neural Network-Based Person Identification Using Gait Cycles. Evol. Syst. 2021, 12, 1045–1056. [Google Scholar] [CrossRef]
- Wu, X.; An, W.; Yu, S.; Guo, W.; García, E.B. Spatial-Temporal Graph Attention Network for Video-Based Gait Recognition. In Proceedings of the Pattern Recognition: 5th Asian Conference (ACPR 2019), Auckland, New Zealand, 26–29 November 2019; Revised Selected Papers, Part II. Springer International Publishing: Cham, Switzerland, 2020; pp. 274–286. [Google Scholar]
- Khan, M.A.; Kadry, S.; Parwekar, P.; Damaševičius, R.; Mehmood, A.; Khan, J.A.; Naqvi, S.R. Human Gait Analysis for Osteoarthritis Prediction: A Framework of Deep Learning and Kernel Extreme Learning Machine. Complex Intell. Syst. 2021, 1–19. [Google Scholar] [CrossRef]
- Wang, Z.; Tang, C.; Su, H.; Li, X. Model-Based Gait Recognition Using Graph Network with Pose Sequences. In Proceedings of the Pattern Recognition and Computer Vision: 4th Chinese Conference (PRCV 2021), Beijing, China, 29 October–1 November 2021; Part III. Springer International Publishing: Cham, Switzerland; pp. 491–501. [Google Scholar]
- Zhang, S.; Wang, Y.; Li, A. Cross-View Gait Recognition with Deep Universal Linear Embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA; pp. 9095–9104. [Google Scholar]
- Ding, X.; Wang, K.; Wang, C.; Lan, T.; Liu, L. Sequential Convolutional Network for Behavioral Pattern Extraction in Gait Recognition. Neurocomputing 2021, 463, 411–421. [Google Scholar] [CrossRef]
- Chai, T.; Mei, X.; Li, A.; Wang, Y. Silhouette-Based View-Embeddings for Gait Recognition Under Multiple Views. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA; pp. 2319–2323. [Google Scholar]
- Zhu, H.; Zheng, Z.; Nevatia, R. Gait Recognition Using 3-D Human Body Shape Inference. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 909–918. [Google Scholar]
- Arshad, H.; Khan, M.A.; Sharif, M.I.; Yasmin, M.; Tavares, J.M.R.; Zhang, Y.D.; Satapathy, S.C. A Multilevel Paradigm for Deep Convolutional Neural Network Features Selection with an Application to Human Gait Recognition. Expert Syst. 2022, 39, e12541. [Google Scholar] [CrossRef]
- Wang, L.; Chen, J.; Chen, Z.; Liu, Y.; Yang, H. Multi-Stream Part-Fused Graph Convolutional Networks for Skeleton-Based Gait Recognition. Connect. Sci. 2022, 34, 652–669. [Google Scholar] [CrossRef]
- BenAbdelkader, C.; Cutler, R.; Davis, L. View-Invariant Estimation of Height and Stride for Gait Recognition. In Proceedings of the Biometric Authentication: International ECCV 2002 Workshop, Copenhagen, Denmark, 1 June 2002; Springer: Berlin/Heidelberg, Germany; pp. 155–167. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
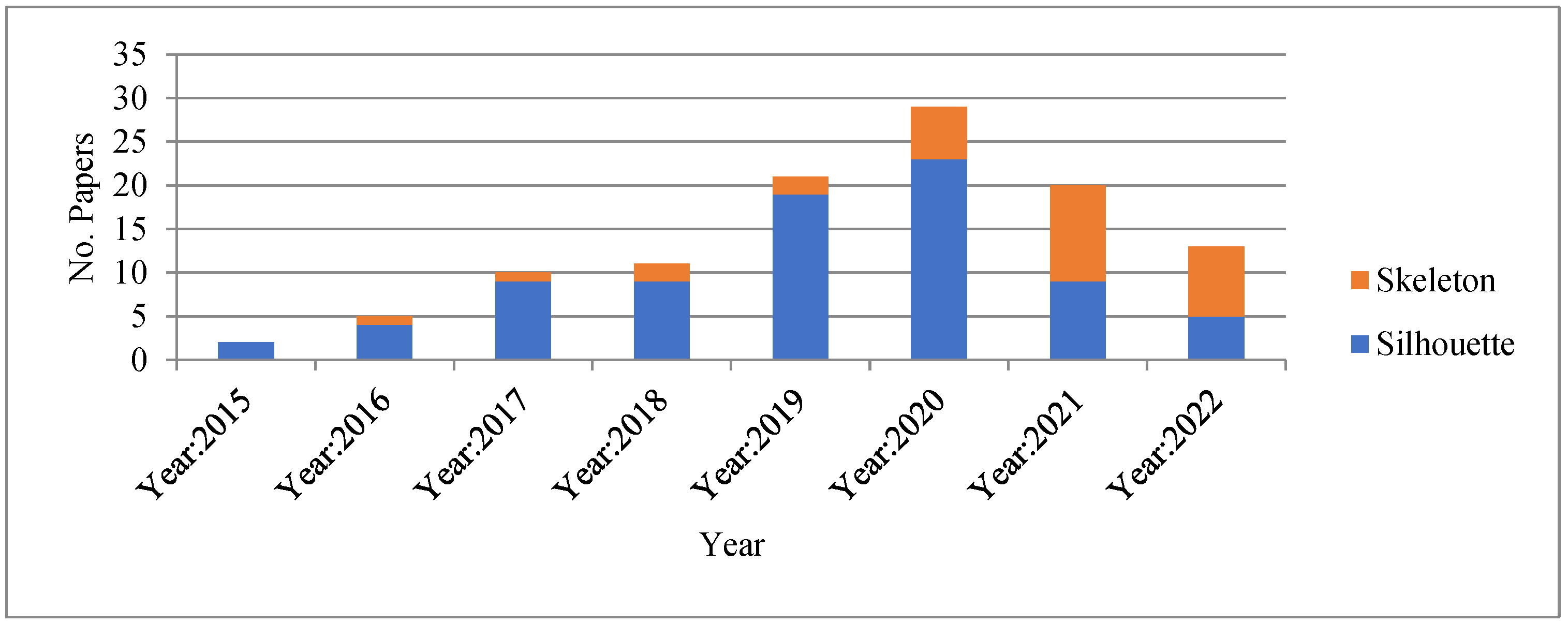{kind=link}
{kind=link}
{kind=link}
| Name of Dataset | Presentation: Subject/Sequences: Environment: Views | Covariates |
|---|---|---|
| CASIA-A [66] | RGB: 20/240: Outdoor: 3 | Walking in normal |
| CASIA-B [33] | RGB; Silhouette: 124/13,680: Indoor: 11 | Walking: Normal; Carrying—a Bag; Wearing—a Coat |
| CASIA-C [67] | Infrared; Silhouette: 153/1530: Outdoor: 1 | Three Walking Speed; Carrying—a Bag |
| CASIA-E [61,68] | Silhouette: 1014/Undisclosed: Indoor and Outdoor: 15 | Three Scenes; Walk-Normal; Carrying—a Bag; Wearing—a Coat |
| OU-ISIR [64] | Silhouette: 4007/31,368: Outdoor: 4 | Walk-Normal |
| OU-ISIR LP Bag [65] | Silhouette: 62,528/187,584: Indoor: 1 | Carried Objects—7 variations |
| OU-ISIRMV [62] | Silhouette: 168/4200: Indoor: 25 | View—24azimuthviewsandTopview—1 |
| OU-ISIR Speed [69] | Silhouette: 34/306: Indoor: 4 | walking speeds—Nine |
| OU-ISIR Clothing [70] | Silhouette: 68/2746: Indoor: 4 | Clothing—up to 32 combinations |
| OU-MVLP [60] | Silhouette; Skeleton: 10,307/259,013: Indoor: 14 | Walk-Normal |
| OU-MVLP Pose [71] | Skeleton: 10,307/259,013: Indoor: 14 | Walk-Normal |
| TUM GAID [72] | RGB; Depth; Audio: 305/3737: Indoor: 1 | Walk-Normal; Backpack; Wearing coat with shoes |
| Models | Input Dimension | Total Layer | Conv. Layer | Pooling Layer | Fully Connected Layer |
|---|---|---|---|---|---|
| PF-Gait [96] | 64 × 64 | 7 | 3 | 2 | 2 |
| Gait-Part [97] | 64 × 64 | 9 | 6 | 2 | 1 |
| GEI-Gait [98] | 120 × 120 | 11 | 5 | 4 | 2 |
| Pose-Gait [99] | 64 × 64 | 6 | 3 | 2 | 1 |
| GaitSET [100] | 64 × 64 | 5 | 3 | 2 | 1 |
| MA-GAIT [31] | 124 × 124 | 8 | 3 | 3 | 2 |
| GEINet [32] | 88 × 128 | 6 | 2 | 2 | 2 |
| Ensem.-CNNs [34] | 128 × 128 | 7 | 3 | 2 | 2 |
| Gait-joint [101] | 64 × 64 | 16 | 12 | 2 | 2 |
| MGANs [102] | 64 × 64 | 8 | 4 | 1 | 3 |
| EV-Gait [103] | 128 × 128 | 9 | 6 | 0 | 2 |
| Gait-Set [37] | 64 × 64 | 9 | 6 | 2 | 1 |
| Caps-Gait [104] | 64 × 64 | 9 | 6 | 2 | 1 |
| SMPL [40] | 64 × 64 | 5 | 3 | 1 | 1 |
| Gait-RNNPart [39] | 64 × 64 | 9 | 6 | 2 | 1 |
| Reference | Published Year | Publisher | Venue | Body Shape | Deep Methods | Datasets |
|---|---|---|---|---|---|---|
| [135] | 2015 | IEEE | IEEE-T-MM | Silhouette | CNN | CASIA-B |
| [31] | 2015 | IEEE | IEEE-CISP | Silhouette | CNN | CASIA-B |
| [15] | 2016 | IEEE | IEEE-ICPR | Skeleton | LSTM | CASIA-B |
| [32] | 2016 | IEEE | IEEE-ICB | Silhouette | CNN | OU-ISIR |
| [76] | 2016 | IEEE | IEEE-ICIP | Silhouette | 3DCNN | CMU Mobo; USF HumanlD |
| [136] | 2016 | IEEE | IEEE-ICASSP | Silhouette | CNN | OU-ISIR |
| [131] | 2016 | Journal | BMVC | Skeleton | CNN + LSTM | CASIA-B; CASIA-A |
| [110] | 2017 | Inderscience | IndS-Int. J. Biom. | Silhouette | DBN | CASIA-B |
| [137] | 2017 | ScienceDir | SD-CVIU | Silhouette | CNN | CASIA-B |
| [34] | 2017 | IEEE | IEEE-T-PAMI | Silhouette | CNN | CASIA-B; OU-ISIR |
| [138] | 2017 | MDPI | Applied Sci. | Silhouette | CNN | OU-ISIR |
| [139] | 2017 | IEEE | IEEE-T-CSVT | Silhouette | CNN | OU-ISIR |
| [140] | 2017 | IEEE | IEEE-BIOSIG | Silhouette | CNN | TUM-GAID |
| [141] | 2017 | Journal | MM | Silhouette | CNN | OU-ISIR |
| [142] | 2017 | IET | IET-CCBR | Skeleton | CNN + LSTM | CASIA-B |
| [74] | 2017 | IEEE | IEEE-CVPRW | Silhouette | GAN | CASIA-B |
| [80] | 2017 | ScienceDir | SD-NC | Silhouette | DAE | CASIA-B; SZU RGB-D |
| [122] | 2018 | Journal | Elect. Imaging | Silhouette | 3DCNN | CASIA-B |
| [83] | 2018 | IEEE | IEEE-Access | Silhouette | CNN + LSTM | CASIA-C |
| [117] | 2018 | SpringerLink | SL-Neuroinform | Silhouette | 3DCNN | OU-ISIR |
| [35] | 2018 | IEEE | IEEE-DIC | Skeleton | CNN | CASIA-B |
| [143] | 2018 | IEEE | IEEE-Access | Silhouette | CNN + LSTM | CASIA-B; OU-ISIR |
| [123] | 2018 | IEEE | IEEE-ISBA | Silhouette | 3DCNN | CASIA-B |
| [132] | 2018 | IEEE | IEEE-ICME | Silhouette | DAE + GAN | CASIA-B |
| [144] | 2018 | ScienceDir | SD-JVCIR | Silhouette | CNN | CASIA-B; OU-ISIR |
| [145] | 2018 | SpringerLink | SL-CCBR | Skeleton | CNN + LSTM | CASIA-B |
| [118] | 2019 | ScienceDir | SD-PRL | Skel.; Silh. | LSTM | CASIA-B; TUM-GAID |
| [38] | 2019 | IET | IET-Biom. | Silhouette | CNN | CASIA-B; TUM; OU-ISIR |
| [36] | 2019 | IEEE | IEEE-CVPR | Skel.; Silh. | DAE + LSTM | CASIA-B; FVG |
| [146] | 2019 | ScienceDir | SD-J. Sys. Arch. | Silhouette | DAE + GAN | CASIA-B; OU-ISIR |
| [101] | 2019 | ScienceDir | SD-PR | Silhouette | CNN | CASIA-B; SZU |
| [102] | 2019 | IEEE | IEEE-T-IFS | Silhouette | GAN | CASIA-B; OU-ISIR |
| [147] | 2019 | ScienceDir | SD-PRL | Silhouette | CNN | CASIA-B; OU-ISIR |
| [103] | 2019 | IEEE | IEEE-CVPR | Silhouette | CNN | CASIA-B; OU-ISIR LP Bag |
| [106] | 2019 | ScienceDir | SD-NC | Silhouette | GAN | CASIA-B; OU-ISIR |
| [107] | 2019 | IEEE | IEEE-IJCNN | Silhouette | GAN | CASIA-B |
| [125] | 2019 | IEEE | IEEE-T-IFS | Skeleton | DAE | OU-ISIR LP Bag; TUM-GAID |
| [148] | 2019 | Conf. | ICVIP | Silhouette | CNN | CASIA-B |
| [149] | 2019 | IEEE | IEEE-T-MM | Silhouette | CNN + LSTM | CASIA-B; OU-ISIR |
| [108] | 2019 | IEEE | IEEE-IJCNN | Silhouette | GAN | CASIA-B |
| [150] | 2019 | SpringerLink | SL-NCAA | Silhouette | CNN | CASIA-B; CASIA-A; OU-ISIR |
| [68] | 2019 | ScienceDir | SD-PR | Silhouette | CNN | CASIA-B |
| [151] | 2019 | SpringerLink | SL-NCAA | Silhouette | CNN | CASIA-B; OU-ISIR |
| [112] | 2019 | ScienceDir | SD-JVCIR | Silhouette | CapsNet | CASIA-B |
| [37] | 2019 | SpringerLink | SL-AAA | Silhouette | CNN | CASIA-B; OU-MVLP |
| [113] | 2019 | ScienceDir | SD-JVCIR | Silhouette | CapsNet | CASIA-B; OU-ISIR |
| [85] | 2020 | IEEE | IEEE-Access | Skeleton | DAE + LSTM | Walking Gait |
| [152] | 2020 | ScienceDir | SD-PR | Skeleton | CNN | CASIA-B; CASIA-E |
| [133] | 2020 | IEEE | IEEE-T-PAMI | Silh; Skel | DAE + LSTM | CASIA-B; FVG |
| [130] | 2020 | IEEE | IEEE-T-IP | Silhouette | CNN + LSTM | CASIA-B; OU-MVLP; OU-LP |
| [109] | 2020 | ScienceDir | SD-PR | Silhouette | GAN | OULP-BAG; OU-ISIR LP Bag |
| [153] | 2020 | SpringerLink | SL-MTAP | Silhouette | CNN | CASIA-B |
| [134] | 2020 | ScienceDir | SD-KBS | Silhouette | LSTM + Capsule | CASIA-B; OU-MVLP |
| [154] | 2020 | Journal | JINS | Silhouette | CNN + LSTM | CASIA-B; OU-ISIR |
| [155] | 2020 | IEEE | IEEE-T-CSVT | Silhouette | CNN | CASIA-B; OU-MVLP; OU-ISIR |
| [124] | 2020 | arXiv | arXiv | Silhouette | 3DCNN | CASIA-B; OU-MVLP |
| [156] | 2020 | SpringerLink | SL-MTAP | Silhouette | CNN | CASIA-B; OU-ISIR |
| [104] | 2020 | arXiv | arXiv | Skeleton | GCN | CASIA-B |
| [157] | 2020 | SpringerLink | SP-MTAP | Silhouette | CNN | CASIA-B; OU-ISIR |
| [158] | 2020 | Journal | J-JIPS | Silhouette | CNN | CASIA-B; OU-ISIR |
| [159] | 2020 | SpringerLink | SL-MTAP | Silhouette | CNN | CASIA-B |
| [160] | 2020 | SpringerLink | SL-SC | Silhouette | CNN | CASIA-B; OU-ISIR; OU-MVLP |
| [114] | 2020 | IEEE | IEEE-ITNEC | Silhouette | CapsNet | CASIA-B; OU-ISIR |
| [40] | 2020 | IEEE | IEEE-CVPR | Silhouette | CNN | CASIA-B; OU-MVLP |
| [126] | 2020 | IEEE | IEEE-CVPR | Silhouette | DAE | CASIA-B; OU-ISIR LP Bag |
| [71] | 2020 | IEEE | IEEE-T-Biom | Skeleton | CNN + LSTM | OUMVLP-Pose |
| [161] | 2020 | Conf. | C-ACCVW | Silhouette | CNN | CASIA-E |
| [162] | 2020 | Conf. | C-ACCVW | Silhouette | CNN | CASIA-E |
| [115] | 2020 | IEEE | IEEE-ICPR | Silhouette | CNN + GRU + CapsNet | CASIA-B; OU-MVLP |
| [39] | 2020 | IEEE | IEEE-T-Biom. | Silhouette | CNN + GRU | CASIA-B; OU-MVLP |
| [163] | 2020 | IEEE | IEEE-Access | Silhouette | CNN | CASIA-B |
| [164] | 2020 | IEEE | IEEE-ICASSP | Silhouette | CNN | CASIA-B; OU-MVLP |
| [165] | 2020 | IEEE | IEEE-IJCB | Silhouette | DAE + GAN | CASIA-B; OU-ISIR |
| [42] | 2020 | CVF | ACCV | Silh; Skel | CNN + LSTM | CASIA-B; OU-MVLP |
| [41] | 2020 | ACM | ACM-MM | Silhouette | 3DCNN | CASIA-B; OU-ISIR |
| [43] | 2020 | SpringerLink | SL-ECCV | Silhouette | CNN | CASIA-B; OU-MVLP |
| [166] | 2020 | ScienceDir | SD-NC | Sleleton | CNN | UPCV; KS20; SDU |
| [167] | 2021 | SpringerLink | SL-ES | Skeleton | 3DCNN | CASIA- B |
| [44] | 2021 | SpringerLink | SL-VC | Skeleton | GCNN | CASIA- B |
| [168] | 2021 | SpringerLink | SL-ACPR | Skeleton | GAN | CASIA-B; OU-ISIR |
| [45] | 2021 | ScienceDir | SD-PR | Skeleton | GCN | TUM Gait |
| [97] | 2021 | SpringerLink | SL-JBD | Silhouette | CNN | Market dataset |
| [169] | 2021 | SpringerLink | SL-CIS | Image | CNN | CASIA- B |
| [98] | 2021 | SpringerLink | SL-SC | Silhouette | CNN | CASIA- B, OU-ISIR, OU-MVLP |
| [129] | 2021 | IEEE | IEEE-ICIP | Skeleton | GCNN | CASIA- B |
| [86] | 2021 | IEEE | IEEE-T-PAMI | Skeleton | GCN + CNN | CASIA- B |
| [170] | 2021 | IEEE | IEEE-PRCV | Skeleton | GCN | OUMVLP-Pose |
| [46] | 2021 | IEEE | IEEE-ICCV | Silhouette | 3DCNN | CASIA- B; OU-MVLP |
| [171] | 2021 | CVF | CVF-CVPR | Silhouette | CNN | OUMVLP |
| [99] | 2021 | IEEE | IEEE-ICCV | Skeleton | CNN | CASIA- B; OU-MVLP |
| [100] | 2021 | IEEE | IEEE-T-PAMI | Silhouette | CNN | CASIA- B; OU-MVLP |
| [29] | 2021 | ScienceDir | SD-ESWA | Silhouette | 3DCNN | CASIA- B; OULP |
| [73] | 2021 | IEEE | IEEE-T-CSVT | Silhouette | CNN | CASIA- B; OULPOU-MVLP |
| [172] | 2021 | ScienceDir | SD-NC | Silhouette | CNN | CASIA- B; OU-MVLP |
| [88] | 2021 | IEEE | IEEE-T-BBIS | Silhouette | CNN | CASIA- B; OU-MVLP |
| [173] | 2021 | IEEE | IEEE-ICPC | Silhouette | CNN | CASIA- B; OU-MVLP |
| [47] | 2021 | IEEE | IEEE-T-IFS | Silhouette | ANN | CASIA-BTUM-GAIT |
| [96] | 2022 | ScienceDir | SD-DSP | Silhouette | CNN | CASIA-B, OUMVLP |
| [174] | 2022 | CVF | CVF | Silh; Skel | CNN | CASIA-B; OUMVLP |
| [49] | 2022 | IEEE | IEEE-Access | Skeleton | GCNN | CASIA-B |
| [48] | 2022 | ScienceDir | SD-CVIU | Silh; Skel | GCN + CNN | CASIA-B |
| [175] | 2022 | Wiley | Wiley-Expert system | Skeleton | DCNN | CASIA-A; B, C |
| [89] | 2022 | ScienceDir | SD-PR | Silhouette | CNN | CASIA-B |
| [127] | 2022 | IEEE | IEEE-CVPR | Skeleton | GCN | CASIA-B; OUMVLP-Pose |
| [128] | 2022 | ScienceDir | SD-PRL | Skeleton | GCN | CASIA-B; OUMVLP-Pose |
| [90] | 2022 | IEEE | IEEE-T-NNLS | Silhouette | CNN | CASIA-B; OUMVLP |
| [75] | 2022 | MDPI | Electronics | Skeleton | CNN | CASIA-B |
| [176] | 2022 | Taylor | Taylor-CS | Skeleton | GCN | CASIA-B |
| [50] | 2022 | MDPI | Sensor | Silhouette | ViT | CASIA-B; OU-ISIR OU-LP |
| [91] | 2022 | IEEE | IEEE-T-IP | Silhouette | CNN | CASIA-B; OUMVLP |
| [92] | 2022 | ScienceDir | SD-PR | Silhouette | CNN | CASIA-B; OUMVLP |
| Information | Performances | ||||||
|---|---|---|---|---|---|---|---|
| Reference | Year | Publisher | Venue | NM | BG | CL | Avg. |
| [135] | 2015 | IEEE | IEEE-T-MM | 78.90 | - | - | - |
| [110] | 2017 | Inderscience | IndS-Int. J. Biom. | 90.80 | 45.90 | 45.30 | 60.70 |
| [34] | 2017 | IEEE | IEEE-T-PAMI | 94.10 | 72.40 | 54.00 | 73.50 |
| [35] | 2018 | IEEE | IEEE-DIC | 83.30 | - | 62.50 | - |
| [68] | 2019 | ScienceDir | SD-PR | 75.00 | - | - | - |
| [102] | 2019 | IEEE | IEEE-T-IFS | 79.80 | - | - | - |
| [101] | 2019 | ScienceDir | SD-PR | 89.90 | - | - | - |
| [36] | 2019 | IEEE | IEEE-CVPR | 93.90 | 82.60 | 63.20 | 79.90 |
| [103] | 2019 | IEEE | IEEE-CVPR | 89.90 | - | - | - |
| [38] | 2019 | IET | IET-Biom. | 94.50 | 78.60 | 51.60 | 74.90 |
| [118] | 2019 | ScienceDir | SD-PRL | 86.10 | - | - | - |
| [37] | 2019 | SpringerLink | SL-AAA | 95.00 | 87.20 | 70.40 | 84.20 |
| [133] | 2020 | IEEE | IEEE-T-PAMI | 92.30 | 88.90 | 62.30 | 81.20 |
| [130] | 2020 | IEEE | IEEE-T-IP | 96.00 | - | - | - |
| [155] | 2020 | IEEE | IEEE-T-CSVT | 92.70 | - | - | - |
| [163] | 2020 | IEEE | IEEE-Access | 95.10 | 87.90 | 74.00 | 85.70 |
| [115] | 2020 | IEEE | IEEE-ICPR | 95.70 | 90.70 | 72.40 | 86.30 |
| [39] | 2020 | IEEE | IEEE-T-Biom. | 95.20 | 89.70 | 74.70 | 86.50 |
| [40] | 2020 | IEEE | IEEE-CVPR | 96.20 | 91.50 | 78.70 | 88.80 |
| [126] | 2020 | IEEE | IEEE-CVPR | 94.50 | - | - | - |
| [43] | 2020 | SpringerLink | SL-ECCV | 96.80 | 94.00 | 77.50 | 89.40 |
| [42] | 2020 | CVF | ACCV | 97.90 | 93.10 | 77.60 | 89.50 |
| [41] | 2020 | ACM | ACM-MM | 96.70 | 93.00 | 81.50 | 90.40 |
| [44] | 2021 | SpringerLink | SL-VC | 97.03 | 90.77 | 89.90 | 92.57 |
| [46] | 2021 | IEEE | IEEE-ICCV | 98.30 | 95.50 | 84.50 | 92.77 |
| [47] | 2021 | IEEE | IEEE-T-IFS | 97.70 | 94.80 | 95.30 | 95.93 |
| [100] | 2021 | IEEE | IEEE-T-PAMI | 96.10 | 90.80 | 70.30 | 96.10 |
| [173] | 2021 | IEEE | IEEE-ICPC | 96.20 | 92.90 | 87.20 | 92.10 |
| [29] | 2021 | ScienceDir | SD-ESWA | - | - | - | 98.34 |
| [45] | 2021 | ScienceDir | SD-PR | 99.40 | 95.40 | 99.40 | 98.07 |
| [49] | 2022 | IEEE | IEEE-Access | - | - | - | 98.86 |
| [48] | 2022 | ScienceDir | SD-CVIU | 97.70 | 93.80 | 92.70 | 94.73 |
| [75] | 2022 | MDPI | Electronics | 94.00 | 95.00 | 97.00 | 95.33 |
| [50] | 2022 | MDPI | Sensor | - | - | - | 99.93 |
| [91] | 2022 | IEEE | IEEE-T-IP | 97.50 | 94.50 | 88.00 | 93.33 |
| [92] | 2022 | ScienceDir | SD-PR | 96.70 | 92.40 | 81.60 | 90.23 |
| Information | ||||
|---|---|---|---|---|
| Reference | Published Year | Publisher | Venue | Performances |
| [37] | 2019 | SpringerLink | SL-AAA | 83.40 |
| [164] | 2019 | IEEE | IEEE-ICASSP | 57.80 |
| [155] | 2020 | IEEE | IEEE-T-CSVT | 63.10 |
| [130] | 2020 | IEEE | IEEE-T-IP | 84.60 |
| [115] | 2020 | IEEE | IEEE-ICPR | 84.50 |
| [39] | 2020 | IEEE | IEEE-T-Biom. | 84.30 |
| [40] | 2020 | IEEE | IEEE-CVPR | 88.70 |
| [43] | 2020 | SpringerLink | SL-ECCV | 89.18 |
| [46] | 2021 | IEEE | IEEE-ICCV | 90.90 |
| [100] | 2021 | IEEE | IEEE-T-PAMI | 87.90 |
| [73] | 2021 | IEEE | IEEE-T-CSVT | 94.92 |
| [88] | 2021 | IEEE | IEEE-T-BBIS | 96.40 |
| [173] | 2021 | IEEE | IEEE-ICPC | 89.90 |
| [98] | 2021 | SpringerLink | SL-SC | 98.00 |
| [90] | 2022 | IEEE | IEEE-T-NNLS | 96.15 |
| [91] | 2022 | IEEE | IEEE-T-IP | 90.50 |
| [92] | 2022 | ScienceDir | SD-PR | 89.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khaliluzzaman, M.; Uddin, A.; Deb, K.; Hasan, M.J. Person Recognition Based on Deep Gait: A Survey. Sensors 2023, 23, 4875. https://doi.org/10.3390/s23104875
Khaliluzzaman M, Uddin A, Deb K, Hasan MJ. Person Recognition Based on Deep Gait: A Survey. Sensors. 2023; 23(10):4875. https://doi.org/10.3390/s23104875
Chicago/Turabian StyleKhaliluzzaman, Md., Ashraf Uddin, Kaushik Deb, and Md Junayed Hasan. 2023. "Person Recognition Based on Deep Gait: A Survey" Sensors 23, no. 10: 4875. https://doi.org/10.3390/s23104875
APA StyleKhaliluzzaman, M., Uddin, A., Deb, K., & Hasan, M. J. (2023). Person Recognition Based on Deep Gait: A Survey. Sensors, 23(10), 4875. https://doi.org/10.3390/s23104875