

RAIM and Failure Mode Slope: Effects of Increased Number of Measurements and Number of Faults


Abstract
:1. Introduction
2. Problem Formulation
3. Notation
4. Analysis of the Estimation Error and Residual
4.1. Effects of Noise and Faults on the Estimate
4.2. Effects of Noise and Faults on the Measurement Residual
4.3. Fault Decisions
5. Integrity Risk Evaluation
5.1. Hypothesis Probabilities
5.2. Evaluating
6. Failure Mode Slope
7. Best and Worst-Case Faults
- Best Case:
- For any fault that has and , the fault direction . In this case, the numerator is zero and the failure mode slope Physically, this means that the fault has absolutely no impact on the state estimate.
- Worst Case:
- For any fault that has and , the fault direction . In this case, the denominator is zero and the failure mode slope Physically this means that the fault has no impact on the residual. Therefore, the residual test cannot detect it.
8. Single, Double, Multi-Measurement Faults
8.1. Single-Measurement Faults
8.2. Double-Measurement Faults
8.3. Multi-Measurement Faults
8.4. Undetectable Faults
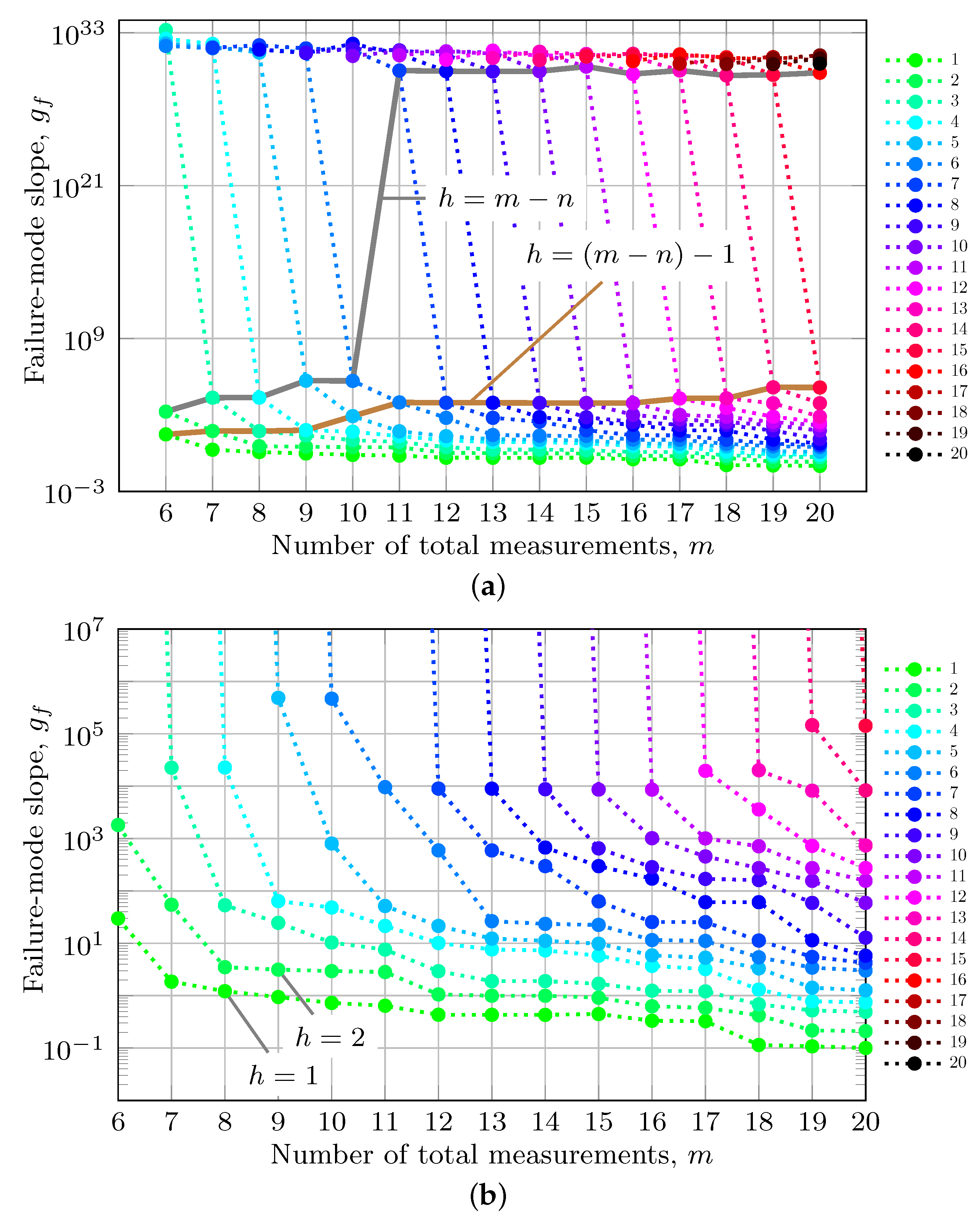
8.5. Effect of Number of Faults on Failure Mode Slope
- (a)
- (b)
- As h increases toward , the numerator in Equation (40) is bounded above by the squared reciprocal of the smallest singular value (i.e., ), while the (worst-case) denominator can decrease toward zero, which causes the failure mode slope to increase toward infinity.
- (c)
- When , is singular. Therefore, there is at least one fault direction, as defined in Equation (57), that will make . As a result, .
- (d)
- For , and . This has eigenvalues values that are one and n eigenvalues that are zero. The eigenvectors corresponding to the zero eigenvalues are in , which is the null space of . As stated in Section 6, any fault in is not detectable from the residual and has . In particular, the worst-case fault direction is , which is undetectable and affects the state estimation error the most. This is the same solution as that in Equation (57).
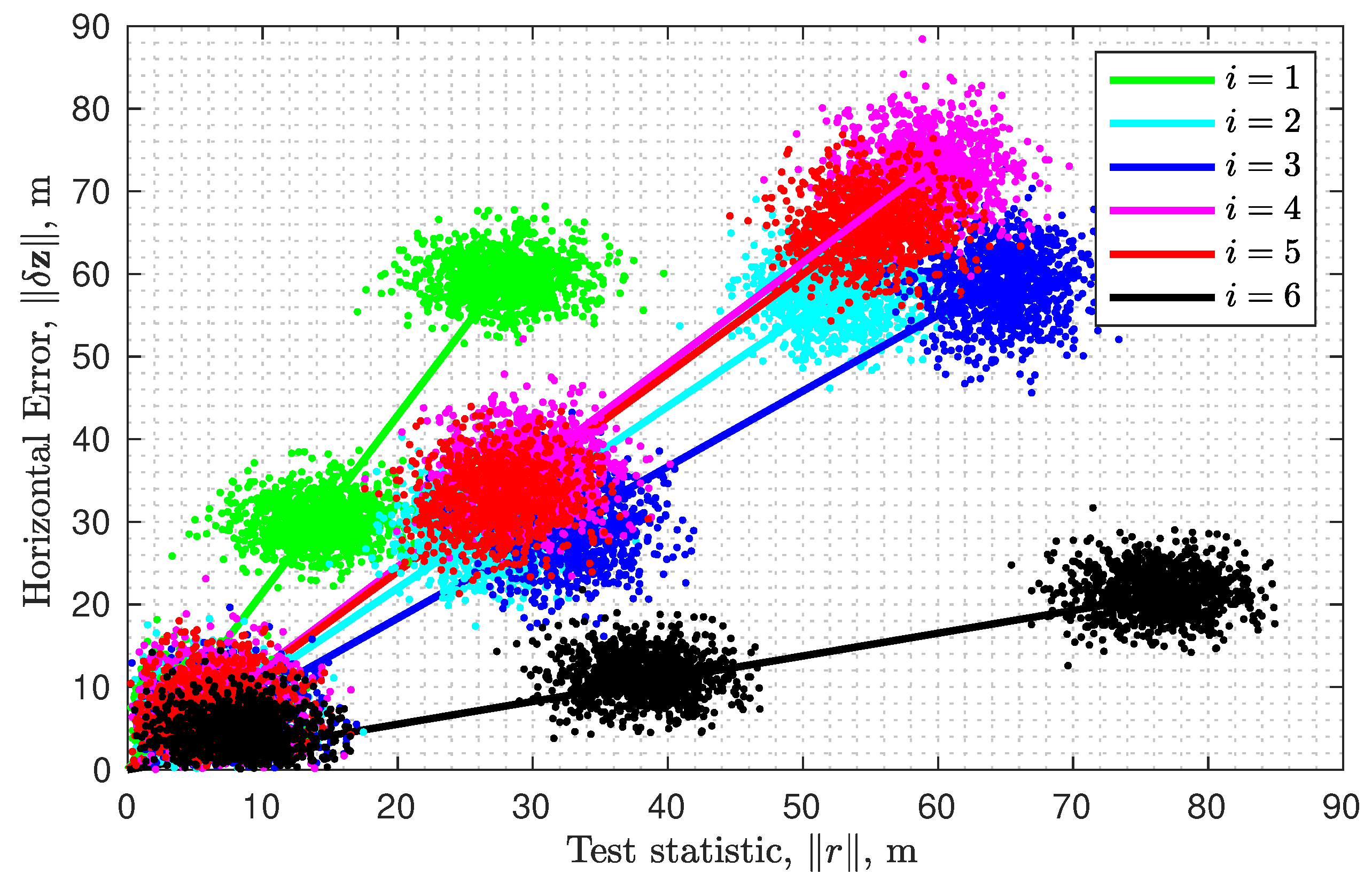
9. Effect of Fault on Horizontal Position
10. Example Discussion
10.1. Fixed Number of Measurements
10.2. Multi-Measurement Faults: Increasing m
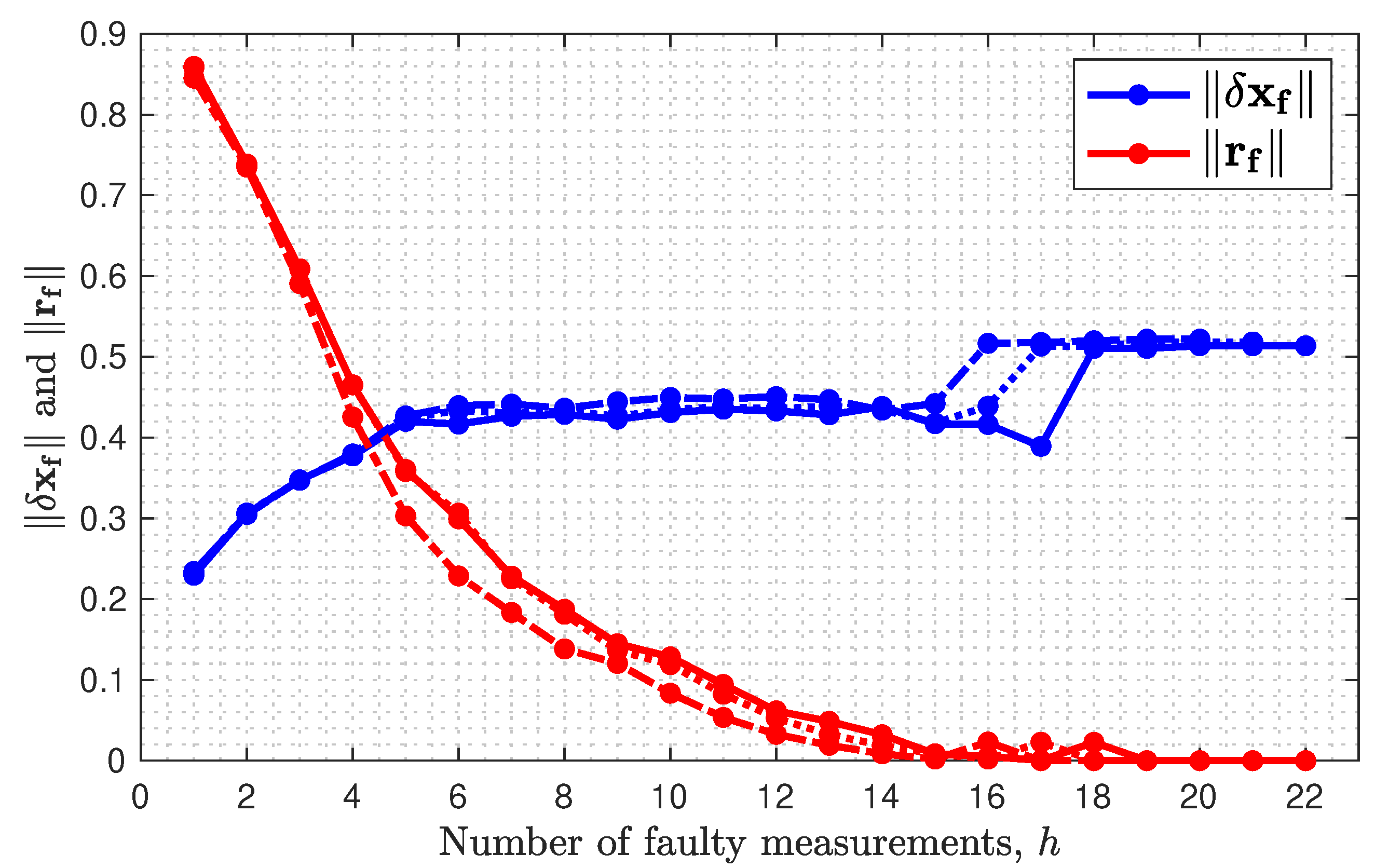
10.3. Multi-Measurement Faults: Increasing h
10.4. How Does Become Infinite for ?
11. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Montenbruck, O.; Steigenberger, P.; Hauschild, A. Comparing the ‘Big 4’—A User’s View on GNSS Performance. In Proceedings of the IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020; pp. 407–418. [Google Scholar]
- Aggrey, J.; Bisnath, S.; Naciri, N.; Shinghal, G.; Yang, S. Multi-GNSS precise point positioning with next-generation smartphone measurements. J. Spat. Sci. 2020, 65, 79–98. [Google Scholar] [CrossRef]
- Esper, M.; Chao, E.L.; Wolf, C.F. 2019 Federal Radionavigation Plan; Technical Report; U.S. Department of Defense: Washington, DC, USA, 2020.
- Sturza, M.A. Navigation System Integrity Monitoring Using Redundant Measurements. NAVIGATION J. Inst. Navig. 1988, 35, 483–501. [Google Scholar] [CrossRef]
- Lee, Y.C. Analysis of range and position comparison methods as a means to provide GPS integrity in the user receiver. In Proceedings of the 42nd Annual Meeting of the Institute of Navigation, Seattle, WA, USA, 24–26 June 1986; pp. 1–4. [Google Scholar]
- Parkinson, B.W.; Axelrad, P. Autonomous GPS integrity monitoring using the pseudorange residual. NAVIGATION J. Inst. Navig. 1988, 35, 255–274. [Google Scholar] [CrossRef]
- Joerger, M.; Chan, F.C.; Pervan, B. Solution separation versus residual-based RAIM. NAVIGATION J. Inst. Navig. 2014, 61, 273–291. [Google Scholar] [CrossRef]
- Pullen, S.; Joerger, M. GNSS Integrity and Receiver Autonomous Integrity Monitoring (RAIM). In Position, Navigation, and Timing Technologies in the 21st Century: Integrated Satellite Navigation, Sensor Systems, and Civil Applications; Morton, Y.J., van Diggelen, F., Spilker, J.J., Jr., Parkinson, B.W., Lo, S., Gao, G., Eds.; Wiley Online Library: Hoboken, NJ, USA, 2021; Chapter 23; pp. 591–617. [Google Scholar]
- Van Dyke, K.L. RAIM availability for supplemental GPS navigation. NAVIGATION J. Inst. Navig. 1992, 39, 429–444. [Google Scholar] [CrossRef]
- Pervan, B.S. Navigation Integrity for Aircraft Precision Landing Using the Global Positioning System. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 1996. [Google Scholar]
- Pervan, B.S.; Lawrence, D.G.; Parkinson, B.W. Autonomous fault detection and removal using GPS carrier phase. IEEE Trans. Aerosp. Electron. Syst. 1998, 34, 897–906. [Google Scholar] [CrossRef]
- Lee, Y.C. RAIM Availability for GPS Augmented with Barometric Altimeter Aiding and Clock Coasting. NAVIGATION J. Inst. Navig. 1993, 40, 179–198. [Google Scholar] [CrossRef]
- Walter, T.; Enge, P. Weighted RAIM for precision approach. In Proceedings of the 8th International Meeting of the Satellite Division of The Institute of Navigation, Palm Springs, CA, USA, 12–15 September 1995; Volume 8, pp. 1995–2004. [Google Scholar]
- Kraemer, J.H.; Chin, G.Y.; Nim, G.C.; Van Dyke, K.L. RAIM for WAAS Category I precision approach. In Proceedings of the 11th International Technical Meeting of the Satellite Division of The Institute of Navigation, Nashville, TN, USA, 15–18 September 1998; pp. 1375–1384. [Google Scholar]
- Camacho-Lara, S. Current and future GNSS and their augmentation systems. In Handbook of Satellite Applications; Springer: New York, NY, USA, 2017. [Google Scholar]
- Verhagen, S.; Odijk, D.; Teunissen, P.J.; Huisman, L. Performance improvement with low-cost multi-GNSS receivers. In Proceedings of the 2010 5th ESA Workshop on Satellite Navigation Technologies and European Workshop on GNSS Signals and Signal Processing, Noordwijk, The Netherlands, 8–10 December 2010; pp. 1–8. [Google Scholar]
- Zangenehnejad, F.; Jiang, Y.; Gao, Y. GNSS Observation Generation from Smartphone Android LocationAPI: Performance of Existing Apps, Issues and Improvement. Sensors 2023, 23, 777. [Google Scholar] [CrossRef]
- Vana, S.; Bisnath, S. Low-Cost, Triple-Frequency, Multi-GNSS PPP and MEMS IMU Integration for Continuous Navigation in Simulated Urban Environments. NAVIGATION J. Inst. Navig. 2023, 70, navi.578. [Google Scholar] [CrossRef]
- Hsu, L.T.; Gu, Y.; Kamijo, S. NLOS correction/exclusion for GNSS measurement using RAIM and city building models. Sensors 2015, 15, 17329–17349. [Google Scholar] [CrossRef]
- Peyraud, S.; Bétaille, D.; Renault, S.; Ortiz, M.; Mougel, F.; Meizel, D.; Peyret, F. About non-line-of-sight satellite detection and exclusion in a 3D map-aided localization algorithm. Sensors 2013, 13, 829–847. [Google Scholar] [CrossRef] [PubMed]
- Khanafseh, S.; Kujur, B.; Joerger, M.; Walter, T.; Pullen, S.; Blanch, J.; Doherty, K.; Norman, L.; de Groot, L.; Pervan, B. GNSS multipath error modeling for automotive applications. In Proceedings of the 31st International Technical Meeting of the Satellite Division of The Institute of Navigation, Miami, FL, USA, 24–28 September 2018; pp. 1573–1589. [Google Scholar]
- Zair, S.; Le Hégarat-Mascle, S.; Seignez, E. Outlier detection in GNSS pseudo-range/Doppler measurements for robust localization. Sensors 2016, 16, 580. [Google Scholar] [CrossRef] [PubMed]
- Pi, X.; Iijima, B.A.; Lu, W. Effects of ionospheric scintillation on GNSS-based positioning. NAVIGATION J. Inst. Navig. 2017, 64, 3–22. [Google Scholar] [CrossRef]
- Vilà-Valls, J.; Linty, N.; Closas, P.; Dovis, F.; Curran, J.T. Survey on signal processing for GNSS under ionospheric scintillation: Detection, monitoring, and mitigation. NAVIGATION J. Inst. Navig. 2020, 67, 511–536. [Google Scholar] [CrossRef]
- Liu, W.; Jin, X.; Wu, M.; Hu, J.; Wu, Y. A new real-time cycle slip detection and repair method under high ionospheric activity for a triple-frequency GPS/BDS receiver. Sensors 2018, 18, 427. [Google Scholar] [CrossRef] [PubMed]
- Adjrad, M.; Groves, P.D. Intelligent urban positioning using shadow matching and GNSS ranging aided by 3D mapping. In Proceedings of the 29th International Technical Meeting of the Satellite Division of The Institute of Navigation, Portland, OR, USA, 12–16 September 2016; pp. 534–553. [Google Scholar]
- Skone, S.; Knudsen, K.; De Jong, M. Limitations in GPS receiver tracking performance under ionospheric scintillation conditions. Phys. Chem. Earth Part A Solid Earth Geod. 2001, 26, 613–621. [Google Scholar] [CrossRef]
- Benton, C.J.; Mitchell, C.N. Further observations of GPS satellite oscillator anomalies mimicking ionospheric phase scintillation. GPS Solut. 2014, 18, 387–391. [Google Scholar] [CrossRef]
- Benton, C.J.; Mitchell, C.N. GPS satellite oscillator faults mimicking ionospheric phase scintillation. GPS Solut. 2012, 16, 477–482. [Google Scholar] [CrossRef]
- Cameron, A. Russia Practices Widespread Spoofing. GPS World 2019, 30, 14. [Google Scholar]
- Psiaki, M.L.; Humphreys, T.E. GNSS spoofing and detection. Proc. IEEE 2016, 104, 1258–1270. [Google Scholar] [CrossRef]
- Kuusniemi, H.; Blanch, J.; Chen, Y.H.; Lo, S.; Innac, A.; Ferrara, G.; Honkala, S.; Bhuiyan, M.Z.H.; Thombre, S.; Söderholm, S.; et al. Feasibility of fault exclusion related to advanced RAIM for GNSS spoofing detection. In Proceedings of the 30th International Technical Meeting of the Satellite Division of The Institute of Navigation, Portland, OR, USA, 25–29 September 2017; pp. 2359–2370. [Google Scholar]
- Clements, Z.; Yoder, J.E.; Humphreys, T.E. Carrier-phase and IMU based GNSS Spoofing Detection for Ground Vehicles. In Proceedings of the 2022 International Technical Meeting of The Institute of Navigation, Long Beach, CA, USA, 25–27 January 2022; pp. 83–95. [Google Scholar]
- Brown, R.G. Solution of the Two-Failure GPS RAIM Problem Under Worst Case Bias Conditions: Parity Space Approach. NAVIGATION J. Inst. Navig. 1997, 44, 425–431. [Google Scholar] [CrossRef]
- Angus, J.E. RAIM with multiple faults. NAVIGATION J. Inst. Navig. 2006, 53, 249–257. [Google Scholar] [CrossRef]
- Liu, B.; Gao, Y.; Gao, Y.; Wang, S. HPL calculation improvement for Chi-squared residual-based ARAIM. GPS Solut. 2022, 26, 45. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; El-Mowafy, A.; Rizos, C. Integrity monitoring scheme for undifferenced and uncombined multi-frequency multi-constellation PPP-RTK. GPS Solut. 2023, 27, 68. [Google Scholar] [CrossRef]
- Farrell, J.A. Aided Navigation: GPS with High Rate Sensors; McGraw Hill: New York, NY, USA, 2008. [Google Scholar]
- Gander, W.; Golub, G.H.; Von Matt, U. A constrained eigenvalue problem. Linear Algebra Its Appl. 1989, 114, 815–839. [Google Scholar] [CrossRef]
- Kay, S.M. Fundamentals of Statistical Signal Processing, Estimation Theory; Prentice Hall PTR: Hoboken, NJ, USA, 2013. [Google Scholar]
- Uwineza, J.B.; Farrell, J.A. Supplementary Materials: RAIM and Failure Mode Slope: Effects of Increased Number of Measurements and Number of Faults. Available online: https://escholarship.org/uc/item/7gk1c3kg (accessed on 17 May 2023).
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: Cambridge, UK, 1985. [Google Scholar]
- Brown, R.G.; Chin, G.Y. GPS RAIM: B. In Global Positioning System, Papers Published in Navigation; The Institute of Navigation: Alexandria, VA, USA, 1997; pp. 155–178. [Google Scholar]
- Joerger, M.; Pervan, B. Fault detection and exclusion using solution separation and chi-squared ARAIM. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 726–742. [Google Scholar] [CrossRef]
- Blanch, J.; Walter, T.; Enge, P.; Lee, Y.; Pervan, B.; Rippl, M.; Spletter, A. Advanced RAIM user algorithm description: Integrity support message processing, fault detection, exclusion, and protection level calculation. In Proceedings of the 25th International Technical Meeting of the Satellite Division of The Institute of Navigation, Nashville, TN, USA, 17–21 September 2012; pp. 2828–2849. [Google Scholar]
- Walter, T.; Blanch, J.; Enge, P. Reduced subset analysis for multi-constellation ARAIM. In Proceedings of the International Technical Meeting of The Institute of Navigation, San Diego, CA, USA, 27–29 January 2014; pp. 89–98. [Google Scholar]
- Brown, R.G.; Chin, G.Y.; Kraemer, J.H. Update on GPS Integrity Requirements of the RTCA MOPS. In Proceedings of the 4th International Technical Meeting of the Satellite Division of The Institute of Navigation, Albuquerque, NM, USA, 11–13 September 1991; pp. 761–772. [Google Scholar]
- Brown, R.G. A baseline GPS RAIM scheme and a note on the equivalence of three RAIM methods. NAVIGATION J. Inst. Navig. 1992, 39, 301–316. [Google Scholar] [CrossRef]
- Liu, J.; Lu, M.; Feng, Z.; Wang, J. GPS RAIM: Statistics based improvement on the calculation of threshold and horizontal protection radius. In Proceedings of the International Symposium on GPS/GNSS, Hong Kong, China, 8–10 December 2005. [Google Scholar]
- Parkinson, B.W.; Axelrad, P. A Basis for the Development of Operational Algorithms for Simplified GPS Integrity Checking. In Proceedings of the Satellite Division’s First Technical Meeting (ION GPS), Colorado Spring, CO, USA, 21–25 September 1987; pp. 269–276. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| i | |||
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 |
| h | Faulty Measurements | |||
|---|---|---|---|---|
| 0 | 0 | |||
| 3 * | 0 | ∞ | ||
| 4 * | 0 | ∞ | ||
| 5 * | 0 | ∞ | ||
| 6 * | 0 | ∞ |
| m | ||||||
|---|---|---|---|---|---|---|
| 6 | 29.78 | 1813.29 | ∞ | ∞ | ∞ | ∞ |
| 7 | 1.85 | 54.32 | 22,545.14 | ∞ | ∞ | ∞ |
| 8 | 1.22 | 3.5 | 53.41 | 22,729.26 | ∞ | ∞ |
| 9 | 0.94 | 3.14 | 24.59 | 63.98 | 4.86 × 10 | ∞ |
| 10 | 0.73 | 2.95 | 10.34 | 48.22 | 803.44 | 4.69 × 10 |
| 11 | 0.64 | 2.83 | 7.59 | 21.47 | 51.57 | 9597.89 |
| 12 | 0.43 | 1.06 | 2.94 | 10.11 | 21.46 | 594.47 |
| 13 | 0.43 | 1 | 1.89 | 7.63 | 12.29 | 26.46 |
| 14 | 0.43 | 1 | 1.9 | 7.32 | 11.17 | 23.49 |
| 15 | 0.45 | 0.91 | 1.69 | 5.8 | 9.82 | 22.46 |
| 16 | 0.33 | 0.63 | 1.24 | 3.71 | 5.89 | 11.52 |
| 17 | 0.33 | 0.59 | 1.21 | 3.21 | 5.31 | 11.12 |
| 18 | 0.11 | 0.42 | 0.68 | 1.31 | 3.32 | 5.4 |
| 19 | 0.11 | 0.22 | 0.52 | 0.78 | 1.42 | 3.43 |
| 20 | 0.1 | 0.21 | 0.49 | 0.75 | 1.27 | 3.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uwineza, J.-B.; Farrell, J.A. RAIM and Failure Mode Slope: Effects of Increased Number of Measurements and Number of Faults. Sensors 2023, 23, 4947. https://doi.org/10.3390/s23104947
Uwineza J-B, Farrell JA. RAIM and Failure Mode Slope: Effects of Increased Number of Measurements and Number of Faults. Sensors. 2023; 23(10):4947. https://doi.org/10.3390/s23104947
Chicago/Turabian StyleUwineza, Jean-Bernard, and Jay A. Farrell. 2023. "RAIM and Failure Mode Slope: Effects of Increased Number of Measurements and Number of Faults" Sensors 23, no. 10: 4947. https://doi.org/10.3390/s23104947
APA StyleUwineza, J. -B., & Farrell, J. A. (2023). RAIM and Failure Mode Slope: Effects of Increased Number of Measurements and Number of Faults. Sensors, 23(10), 4947. https://doi.org/10.3390/s23104947