


Research on Apple Recognition Algorithm in Complex Orchard Environment Based on Deep Learning

Abstract
:1. Introduction
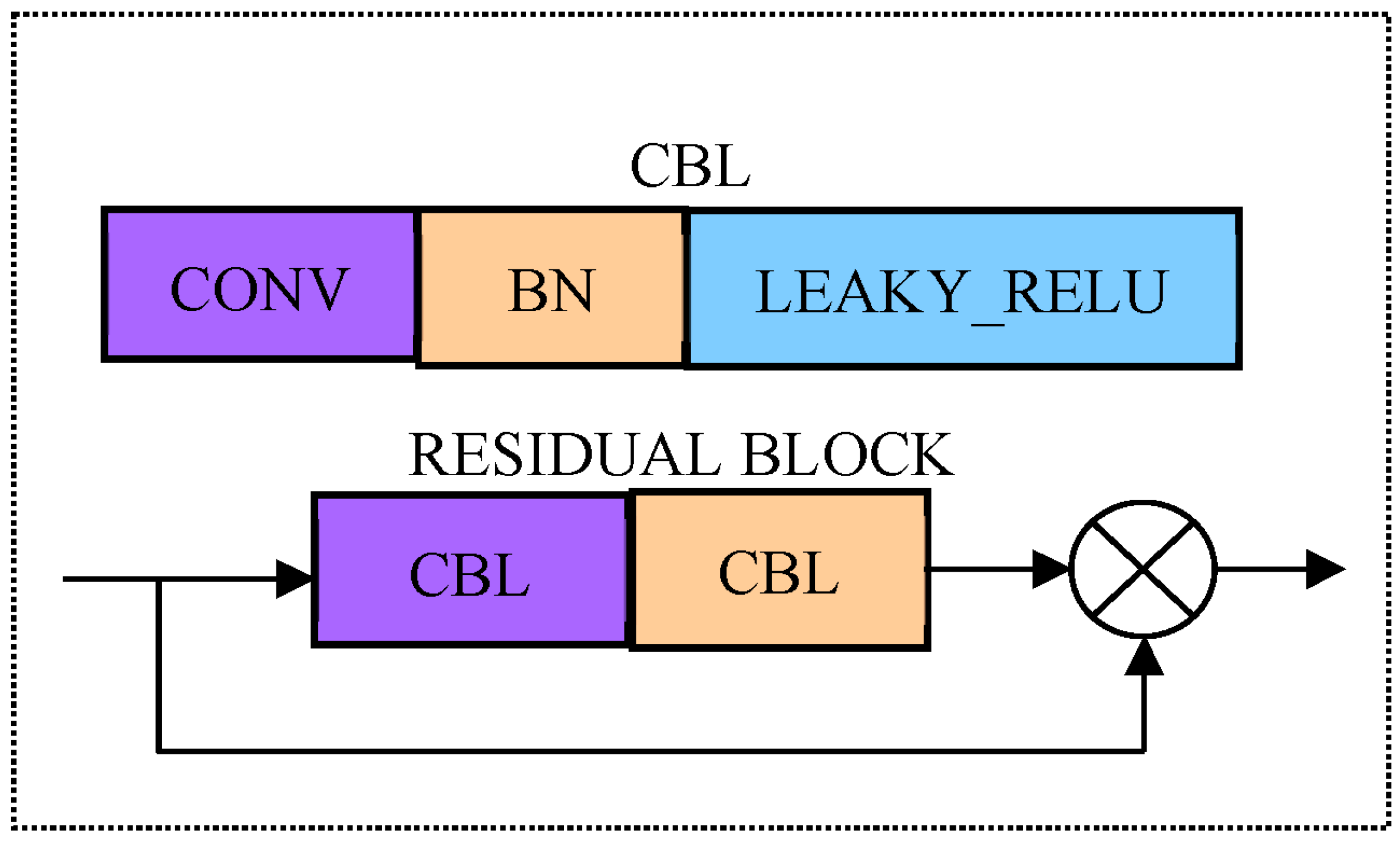
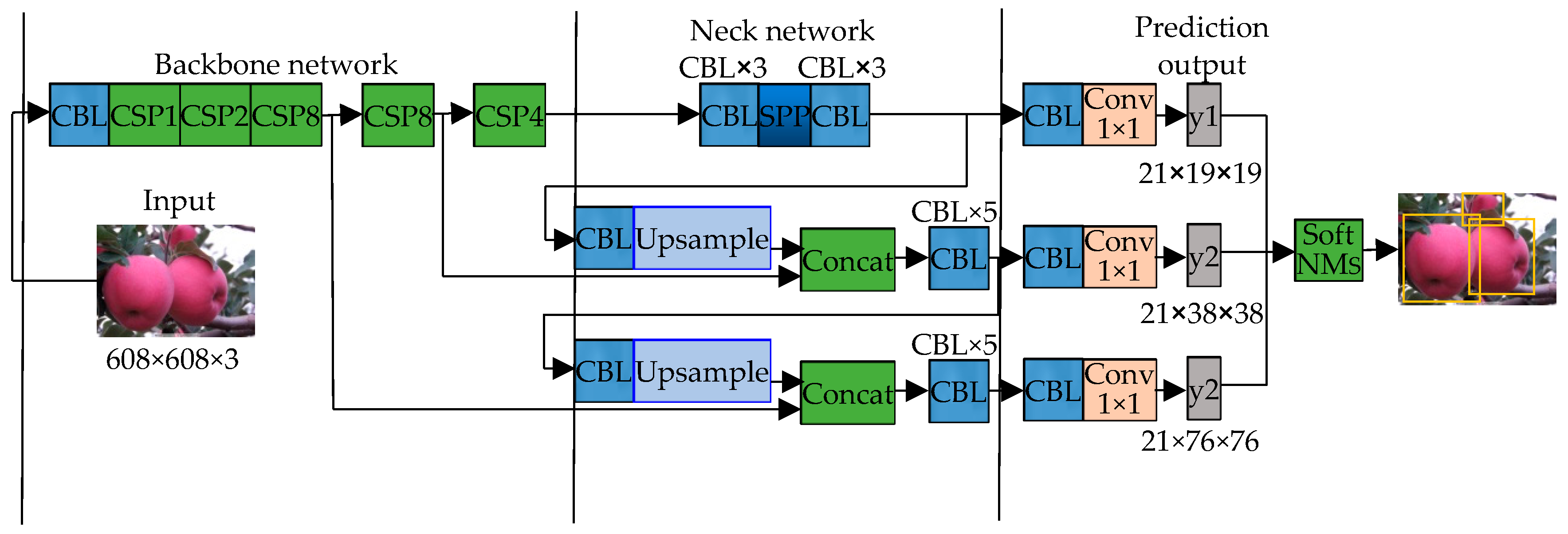
2. YOLOV5s Network
3. Data Processing
3.1. Data Collection Process and Image Sources
3.2. Production of Dataset
3.3. Enhanced Processing of Data
4. Improved Apple Recognition Algorithm
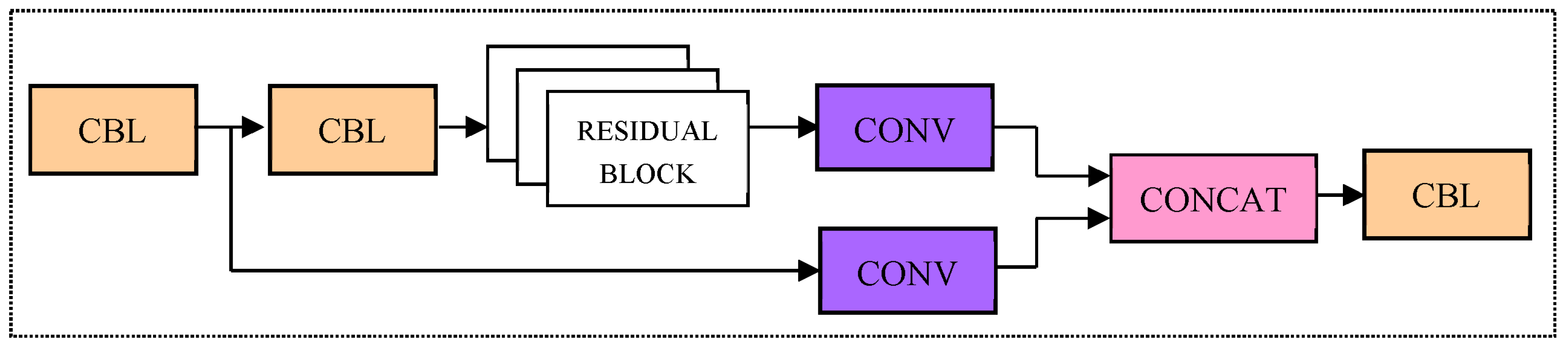
4.1. CSP_X Module [27]
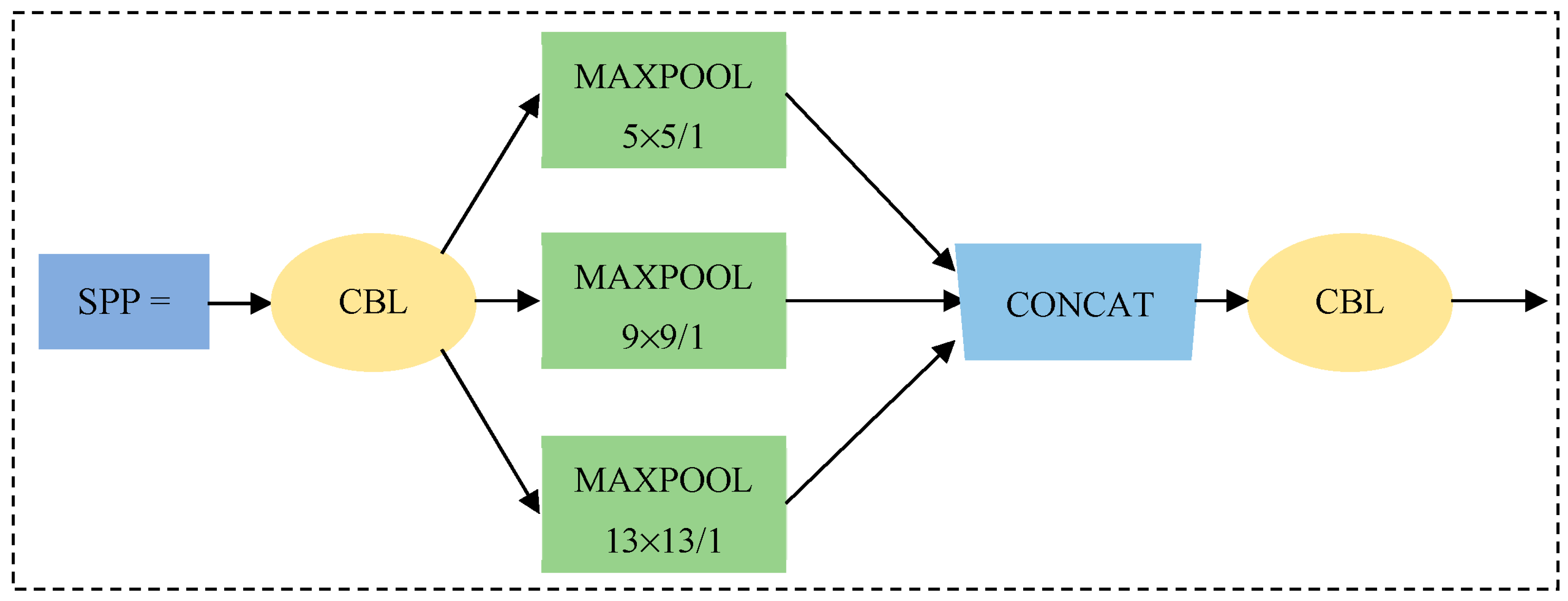
4.2. Spatial Pyramid Pool SPP Module [28]
4.3. Soft NMS (Non-Maximum Suppression) Algorithm [31]
4.4. Improvement of Network Model
4.5. Optimization of Loss Function
4.5.1. Focal Loss [33]
4.5.2. CIoU Loss (Complete Cross-Over Loss)
5. Model Training
5.1. Experimental Conditions
5.2. Evaluation Index System
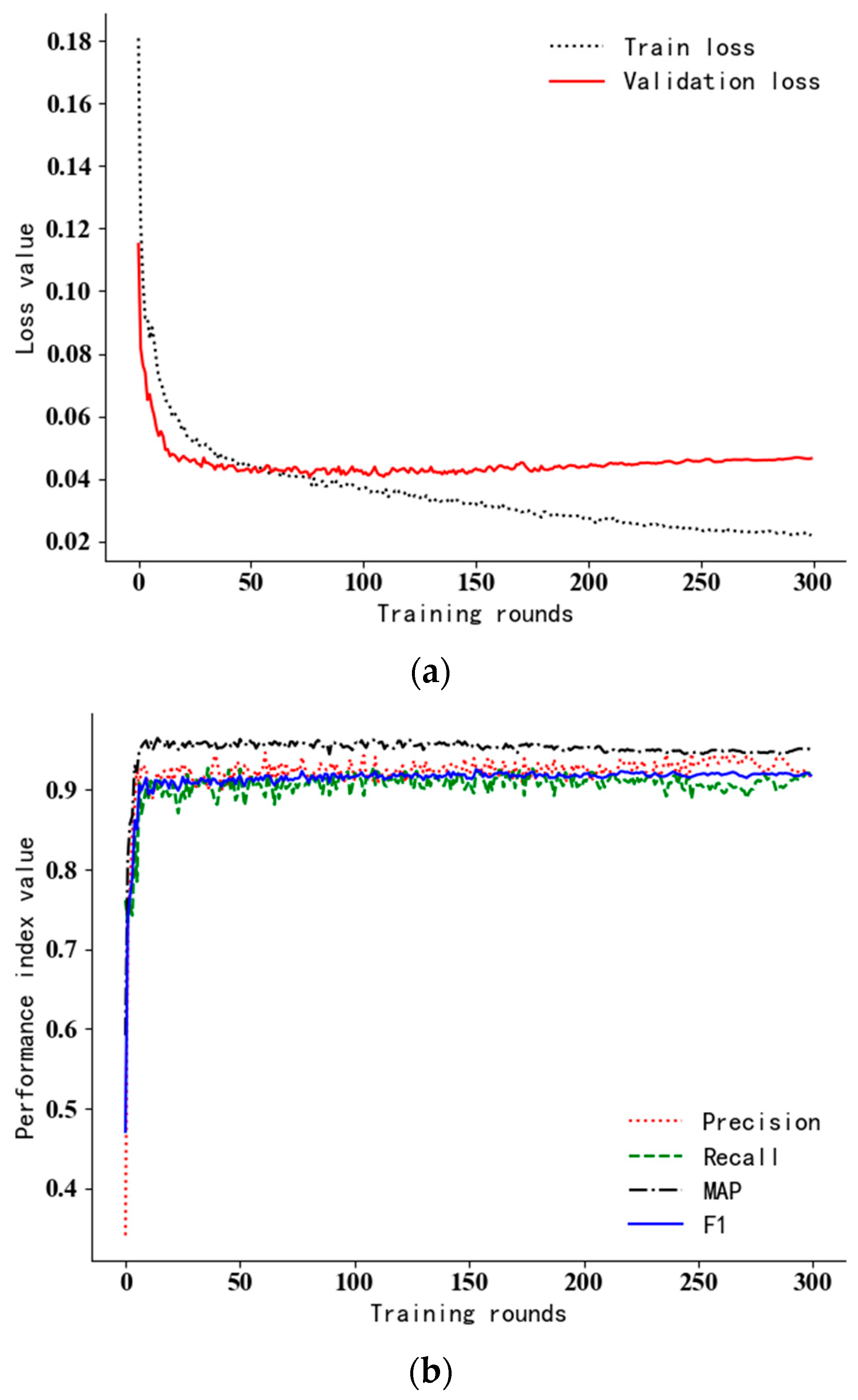
5.3. Training Process
5.4. Analysis of Training Data
6. Test Results
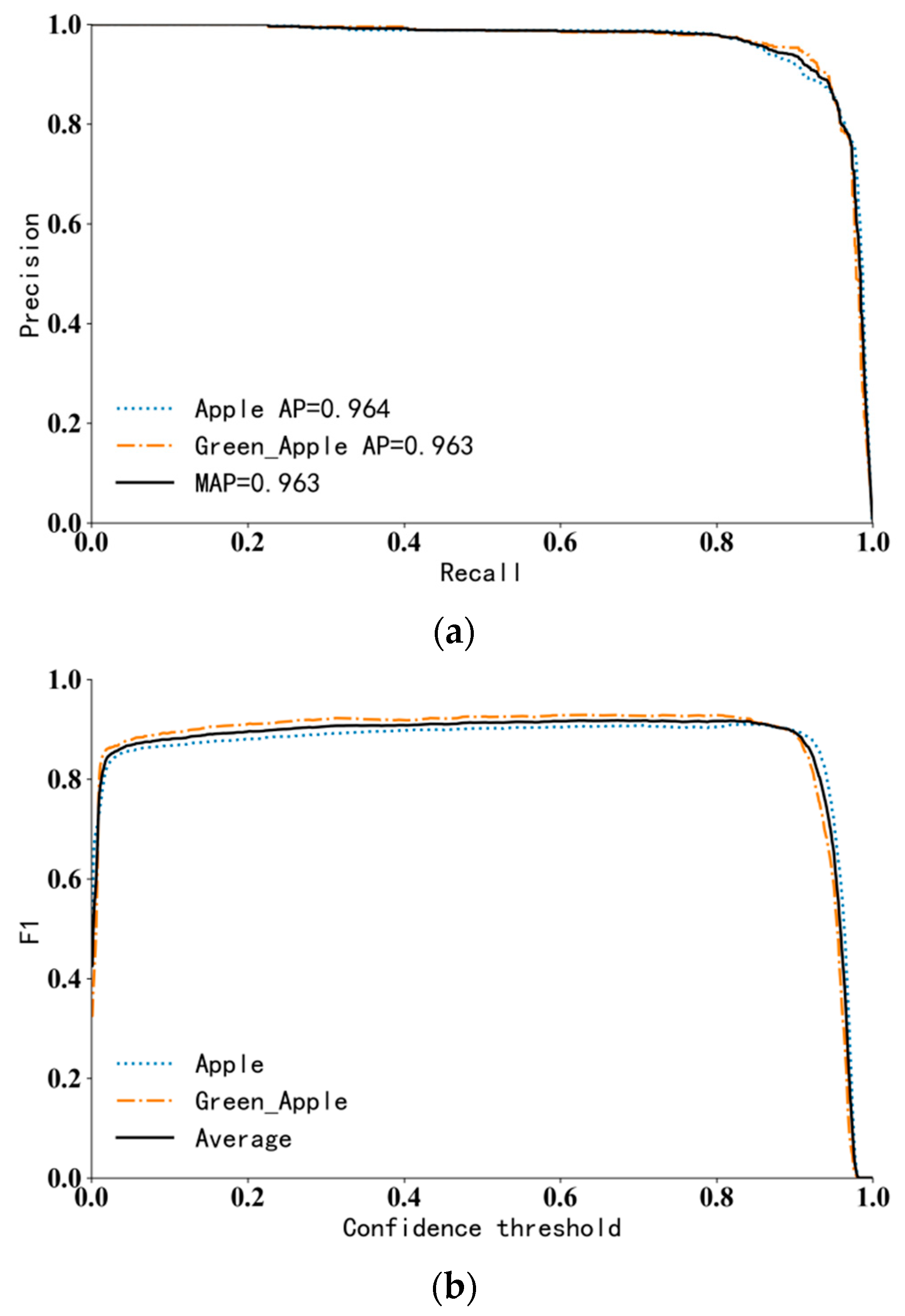
6.1. Evaluation of Test Results
6.2. Recognition Results of Different Algorithms
6.3. Comparative Experiment under Different Fruit Number
6.4. Comparison Test under Different Light Conditions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, W.K.; Tian, Y.Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Fu, L.S.; Feng, Y.L.; Wu, J.Z.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2020, 22, 754–766. [Google Scholar] [CrossRef]
- Jia, W.K.; Zhang, Y.; Lian, J.; Zheng, Y.; Zhao, D.; Li, C. Apple harvesting robot under information technology: A review. Int. J. Adv. Robot. Syst. 2020, 17, 1–16. [Google Scholar] [CrossRef]
- Kang, H.W.; Chen, C. Fruit detection and segmentation for apple harvesting using visual sensor in orchards. Sensors 2019, 19, 4599. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, G.C.; Tang, Y.C.; Zou, X.J.; Li, J.; Xiong, J. In-field citrus detection and localisation based on RGB-D image analysis. Biosyst. Eng. 2019, 186, 34–44. [Google Scholar] [CrossRef]
- Jia, W.; Wang, Z.; Zhang, Z.; Yang, X.; Hou, S.; Zheng, Y. A fast and efficient green apple object detection model based on Foveabox. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 5156–5169. [Google Scholar] [CrossRef]
- Liu, G.X.; Nouaze, J.C.; Touko, P.L.; Kim, J.H. YOLO-Tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 202145. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Jiang, M.; He, D.; Long, Y.; Song, H. Recognition of green apples in an orchard environment by combining the GrabCut model and Ncut algorithm. Biosyst. Eng. 2019, 187, 201–213. [Google Scholar] [CrossRef]
- Wan, S.H.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Liang, C.X.; Xiong, J.T.; Zheng, Z.H.; Zhong, Z.; Li, Z.; Chen, S.; Yang, Z. A visual detection method for nighttime litchi fruits and fruiting stems. Comput. Electron. Agric. 2020, 169, 105192. [Google Scholar] [CrossRef]
- Ma, L.; Zheng, Y.; Zhang, Z.; Yao, Y.; Fan, X.; Ye, Q. Motion stimulation for compositional action recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2061–2074. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, D.; Ye, Q. Recurrent thrifty attention network for remote sensing scene recognition. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8257–8268. [Google Scholar] [CrossRef]
- Pan, W.; Zhao, Z.; Huang, W.; Zhang, Z.; Fu, L.; Pan, Z.; Yu, J.; Wu, F. Video Moment Retrieval with Noisy Labels. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Jin, L.; Wang, S.; Xu, H. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Sun, J.; He, X.F.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of key organs in tomato based on deep migration learning in a complex background. Agriculture 2018, 8, 8196. [Google Scholar] [CrossRef] [Green Version]
- Shang, Y.; Xu, X.; Jiao, Y.; Wang, Z.; Hua, Z.; Song, H. Using lightweight deep learning algorithm for real-time detection of apple flowers in natural environments. Comput. Electron. Agric. 2023, 207, 107765. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Y.N.; Yang, G.D.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLOv3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Zhao, D.; Wu, R.; Liu, X.; Zhao, Y. Apple positioning based on YOLO deep convolutional neural network for picking robot in complex background. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2019, 35, 164–173. [Google Scholar]
- Huang, M.; Wang, B.; Wan, J.; Zhou, C. Improved Blood Cell Detection Method Based on YOLOv5 Algorithm. In Proceedings of the 2023 IEEE 6th Information Technology, Networking, Electronic and Automation Control Conference, Chongqing, China, 24–26 February 2023. [Google Scholar] [CrossRef]
- Alexey, B.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Chena, S.; Cheng, Z.; Zhang, L.; Zheng, Y. SnipeDet: Attention-guided pyramidal prediction kernels for generic object detection. Pattern Recognit. Lett. 2021, 152, 302–310. [Google Scholar] [CrossRef]
- Fan, S.; Li, J.; Zhang, Y.; Tian, X.; Wang, Q.; He, X.; Zhang, C.; Huang, W. On line detection of defective apples using computer vision system combined with deep learning methods. J. Food Eng. 2020, 286, 110102. [Google Scholar] [CrossRef]
- Tu, S.Q.; Pang, J.; Liu, H.F.; Zhuang, N.; Chen, Y.; Zheng, C.; Wan, H.; Xue, Y. Passion fruit detection and counting based on multiple scale faster R-CNN using RGB-D images. Precis. Agric. 2020, 21, 1072–1091. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Shuping, C.; Zhongming, S.; Hui, L. Real-time detection methodology for obstacles in orchards using improved YOLOv4. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 36–43. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Zhang, K.L.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Algorithm | P/% | R/% | F1/% | AP1/ % | AP2/ % | Detection Speed F·s−1 |
|---|---|---|---|---|---|---|
| Faster RCNN | 91.5 | 73.1 | 81.0 | 92.5 | 85.2 | 16.5 |
| RetinaNet | 89.8 | 81.8 | 85.5 | 92.7 | 88.6 | 26.3 |
| CenterNet | 90.4 | 70.3 | 79.0 | 90.7 | 83.6 | 32.3 |
| YOLOv5 | 91.7 | 92.0 | 91.8 | 95.1 | 95.0 | 25.6 |
| Improved YOLOv5 | 91.0 | 92.6 | 91.8 | 96.4 | 96.3 | 27.8 |
| Apples Number | Algorithm | P/ % | R/ % | F1/ % | AP1/ % | AP2/ % |
|---|---|---|---|---|---|---|
| Single | YOLOv5 | 92.4 | 98.9 | 95.5 | 98.8 | 99.6 |
| Improved YOLOv5 | 98.1 | 95.7 | 96.9 | 98.5 | 98.8 | |
| Multiple | YOLOv5 | 89.6 | 91.2 | 90.5 | 95.3 | 93.4 |
| Improved YOLOv5 | 91.9 | 93.1 | 92.5 | 96.8 | 96.9 | |
| Intensive | YOLOv5 | 89.9 | 85.2 | 87.5 | 94.2 | 91.0 |
| Improved YOLOv5 | 89.6 | 92.8 | 91.2 | 96.0 | 95.0 | |
| Wide field | YOLOv5 | 84.4 | 82.5 | 83.0 | 90.4 | 85.6 |
| Improved YOLOv5 | 85.4 | 86.6 | 88.7 | 93.2 | 92.3 |
| Light Condition | Detection Algorithm | P/ % | R/ % | F1/ % | AP1/ % | AP2/ % |
|---|---|---|---|---|---|---|
| Natural light | YOLOv5 | 91.3 | 95.4 | 93.3 | 97.3 | 96.8 |
| Improved YOLOv5 | 95.2 | 94.7 | 94.9 | 97.7 | 97.7 | |
| Side light | YOLOv5 | 91.6 | 95.6 | 93.6 | 97.4 | 97.0 |
| Improved YOLOv5 | 95.6 | 94.8 | 95.2 | 98.0 | 97.9 | |
| Back light | YOLOv5 | 90.7 | 94.5 | 92.6 | 96.9 | 96.0 |
| Improved YOLOv5 | 94.6 | 94.0 | 94.3 | 97.3 | 97.2 | |
| Night | YOLOv5 | 90.8 | 95.0 | 92.9 | 97.0 | 96.5 |
| Improved YOLOv5 | 95.0 | 94.2 | 94.6 | 97.4 | 97.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Wang, J.; Zhao, H. Research on Apple Recognition Algorithm in Complex Orchard Environment Based on Deep Learning. Sensors 2023, 23, 5425. https://doi.org/10.3390/s23125425
Zhao Z, Wang J, Zhao H. Research on Apple Recognition Algorithm in Complex Orchard Environment Based on Deep Learning. Sensors. 2023; 23(12):5425. https://doi.org/10.3390/s23125425
Chicago/Turabian StyleZhao, Zhuoqun, Jiang Wang, and Hui Zhao. 2023. "Research on Apple Recognition Algorithm in Complex Orchard Environment Based on Deep Learning" Sensors 23, no. 12: 5425. https://doi.org/10.3390/s23125425
APA StyleZhao, Z., Wang, J., & Zhao, H. (2023). Research on Apple Recognition Algorithm in Complex Orchard Environment Based on Deep Learning. Sensors, 23(12), 5425. https://doi.org/10.3390/s23125425