3.1. Overall Idea
In order to utilize digital watermarking technology to achieve leak tracing of PDF documents after printing and distribution, it is necessary to design specialized watermarking algorithms. The previous algorithms that utilize PDF file structural elements will no longer be applicable, as these structural attributes cannot be obtained through scanning after printing, making it difficult to extract watermarks. Therefore, efforts must be made in the form of text representation, studying how to embed watermarks by changing the features of the text, and ensuring that the changes in these features after printing can be reflected through the scanned PDF.
Based on the above considerations, this paper proposes a scheme to modify the edge pixels of text strokes.
Figure 1 provides an example of modifying the stroke edge pixels of the text in
Figure 1a to obtain
Figure 1b, which can be observed when zoomed in. After printing and scanning,
Figure 1c can still be observed even when zoomed in. Therefore, modifying the edge pixels of text strokes is a feasible solution.
The issues that need to be considered in designing our algorithm framework include the following aspects:
- (1)
How to accurately cut the text in document images?
- (2)
Which strokes are selected for modification?
- (3)
How to compare and extract watermark information during extraction?
In response to problem (1), we found that after the binarization of PDF document images, a single text can be roughly cut using row and column projection methods. The gaps between individual text will not change after embedding the watermark and before embedding the watermark. Then, we utilized this feature to divide each row into two sub-blocks, with the segmentation point being the location with the largest text spacing. Compared with segmenting a single character, splitting a text line into two sub-blocks is more robust because it avoids the accumulation of extraction errors due to single character segmentation errors. Our approach to problem 2 is to select the longest stroke to modify the surrounding edge pixels, which can improve the invisibility and robustness of the watermark. Considering that in the application system for distributing official documents, the original PDF electronic document before printing can be obtained, our extraction scheme is designed as non-blind extraction, which not only reduces the difficulty of embedding the algorithm design but also improves the success rate of detection. However, the noise generated in the print–scan process will make the position of the watermarked sub-block relative to the original sub-block higher or lower. To deal with this problem, we propose an adaptive alignment model to automatically adjust the position of the watermarked image. Then, we compare the specific pixels selected at the embedding stage and then extract information according to the comparison, which will be described in detail in the following.
3.2. Embedding Algorithm
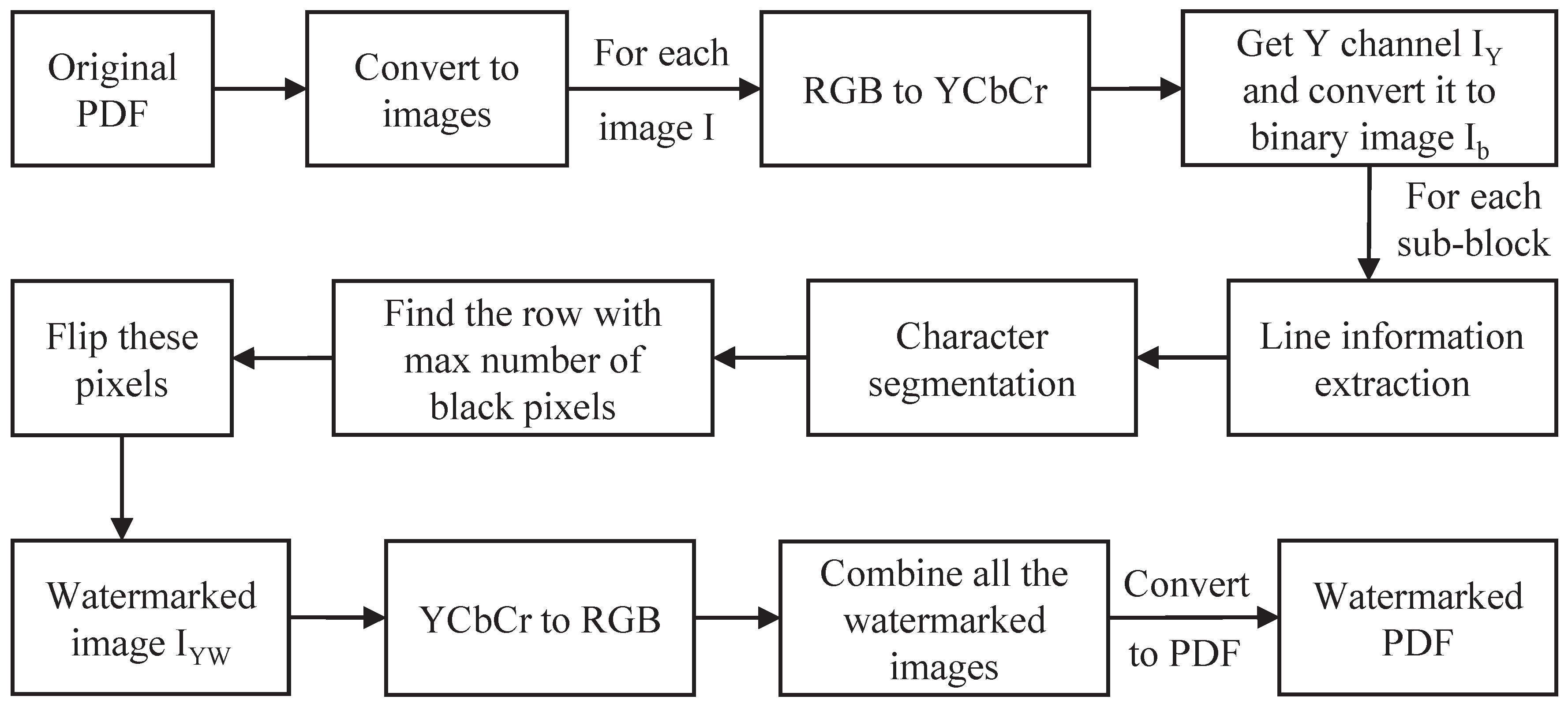
Based on above overall idea, the embedding process of the proposed PDF watermarking algorithm is shown in
Figure 2 and the corresponding embedding algorithm is shown in Algorithm 1. The detailed process can be illustrated as follows:
(1) Step 1: Convert the original PDF file into a series of images, and perform subsequent operations on each image.
(2) Step 2: Map the original image from the RGB color space to the YCbCr color space, decompose the component, mark it as , and convert it into a binary text image ;
(3) Step 3: Perform character segmentation on the binary text image , and the segmentation process is as follows:
(1) Step 3.1: Firstly, perform line information extraction. The basic idea of line information extraction is to divide character blocks based on the characteristics of the connected domain of characters. For , the white background is 1, and the black text is 0. Then, the sum of pixels is calculated by line, and the area with a cumulative sum of 0 is classified as the text area. Considering text connectivity, the number of lines P and the upper and lower boundaries of each line can be obtained based on the divided area.
(2) Step 3.2: Then, for each text line, sum the column pixels separately, and further confirm the left and right boundaries of each text line based on character connectivity. Next, calculate the spacing between each two characters and select the maximum spacing to divide the current line into two sub-blocks, that is, each line is divided into two sub blocks, so there are a total of sub-blocks.
(3) Step 3.3: Repeat operations 3.1 to 3.2 to obtain the set of sub-blocks to embed the watermark. contains rows and columns of pixels (note: the and of each may not be the same).
(4) Step 4: Assuming that the watermark bit sequence to be embedded is , if , an error exit will be prompted. Otherwise, modify to based on being 0 or 1, and the modification process is as follows:
(1) Step 4.1: Calculate the number of black pixels in each row of and find the row with the highest number of black pixels, denoted as ;
(2) Step 4.2: Extract the columns with black pixels from and mark them as , ;
(3) Step 4.3: For each column in L, extract all pixels of that column, find the white pixel closest to , and mark it as . When the watermark bit to be embedded is ‘1’, first determine the position of p. If p is above , flip the pixel in with position to a white pixel; When p is located below , flip the pixel in with position to a white pixel. When the watermark bit to be embedded is ‘0’, flip the pixel at position in to black pixels. Thus, we obtain the watermarked image .
(4) Step 4.4: Replace the Y channel in the YCbCr color space with , map it back to RGB space, and save the watermarked image .
(5) Step 5: After embedding all images, combine all watermarked images in the original order to generate a PDF file with watermarks.
| Algorithm 1 Embedding algorithm |
| Input: Original PDF file, watermark bit sequence |
| Output: Watermarked PDF file |
- 1:
Convert the original PDF file into a series of images - 2:
for each image I do - 3:
Map from the RGB color space to the YCbCr color space, decompose the component, mark it as , and convert it into a binary text image . - 4:
Perform character segmentation and text line information extraction. - 5:
for each text line do - 6:
Confirm the left and right boundaries of each text line. - 7:
Calculate the spacing between each two characters and select the maximum spacing to divide the current line into two sub-blocks. - 8:
end for - 9:
Obtain the set of sub-blocks , P is the number of text lines. - 10:
for each sub-block do - 11:
Calculate the number of black pixels in each row of and find the row with the highest number of black pixels, denoted as . - 12:
Extract the columns with black pixels from and mark them as , . - 13:
for each column in L do - 14:
Extract all pixels of that column, find the white pixel closest to , and mark it as . - 15:
if is “1” then - 16:
When p is above , flip the pixel in with position to a white pixel; When p is located below , flip the pixel in with position to a white pixel. - 17:
end if - 18:
if is “0” then - 19:
Flip the pixel at position in to black pixels. - 20:
end if - 21:
end for - 22:
end for - 23:
Get the watermarked image . - 24:
Replace the Y channel in the YCbCr color space with , map it back to RGB space. - 25:
Save the watermarked image . - 26:
end for - 27:
Combine all watermarked images in the original order and convert to a PDF file with watermarks.
|
3.3. Extraction Algorithm
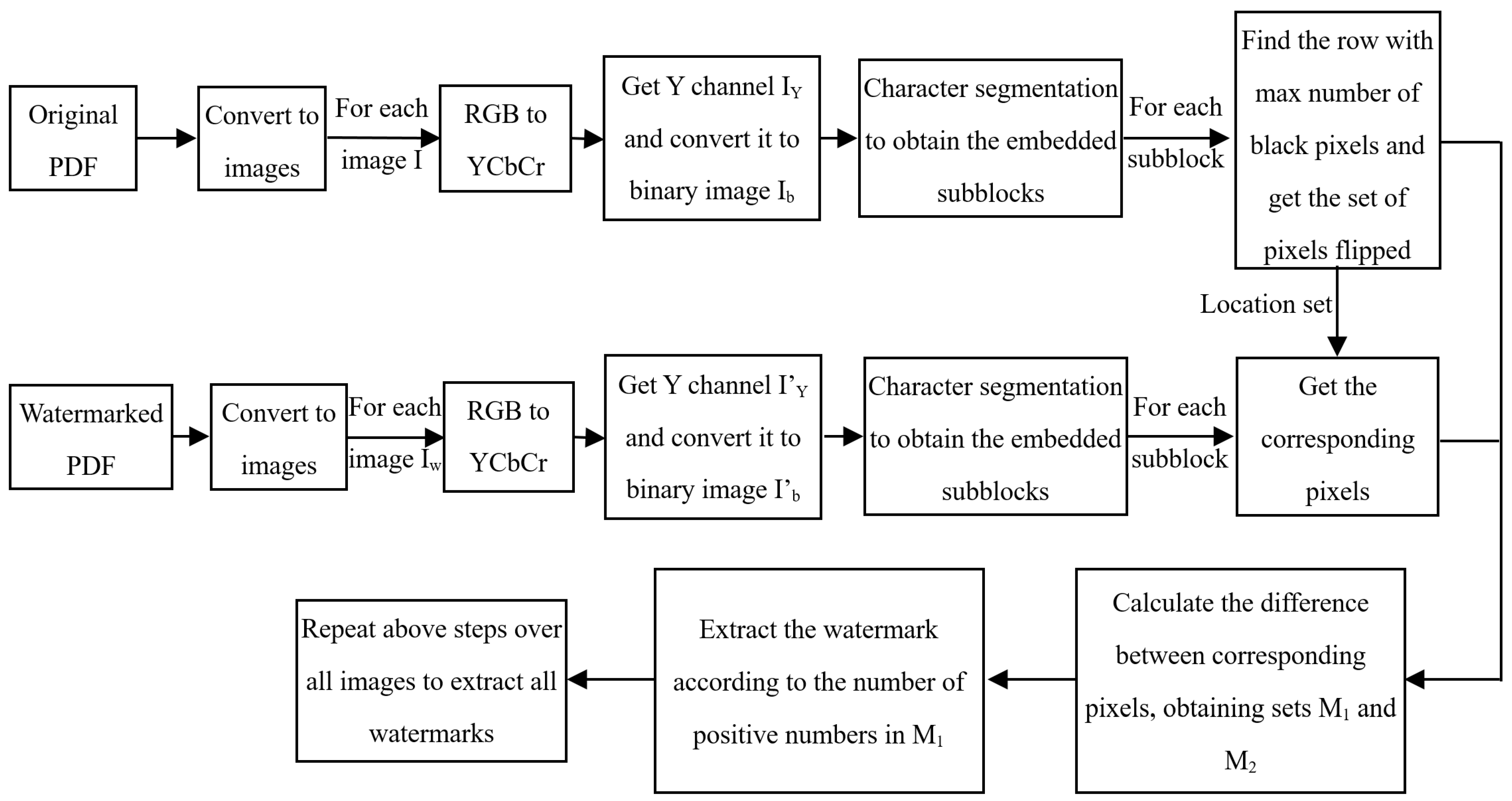
The extraction algorithm requires the participation of the original PDF file and is a non-blind detection algorithm. The extraction process of the proposed PDF watermarking algorithm is shown in
Figure 3 and the corresponding extraction algorithm is shown in Algorithm 2. The detailed process is as follows.
(1) Step 1: Convert the original PDF file and the test PDF file into a series of images, and perform subsequent operations on each original image and the test image ;
(2) Step 2: Correct the geometric distortions and remove the isolated noise for . Map the image and to be detected from RGB space to YCbCr space, decompose the components, mark it as and , and convert them into binary text images and .
(3) Step 3: Perform character segmentation on the binary text image using the same method as when embedding the watermark. After segmentation, obtain the set of sub blocks for the watermark to be extracted, where P is the number of rows.
(4) Step 4: Similarly, perform the above operation on the original binary image to obtain the set .
(5) Step 5: For each , adaptively adjust its corresponding to ensure that the pixels of and correspond one by one to prevent watermark extraction failure due to pixel offset. The adaptive adjustment process is as follows:
First, calculate the similarity between
and
using the following formula.
Afterwards, remove the leftmost column pixels of and add one row of pixels to the rightmost column, with pixel values of 255. Use Formula (1) to calculate the similarity between and at this time.
Similarly, remove the rightmost column pixels of and add one row of pixels to the leftmost column, with pixel values of 255. Use Formula (1) to calculate the similarity between and Bi at this time.
Similarly, remove the first row of pixels from and add one row of pixels below the ri row of , with pixel values of 255. Use Formula (1) to calculate the similarity between and Bi at this point.
Similarly, remove the pixels in the th row of and add a row of pixels above the first row of , with pixel values of 255. Use Formula (1) to calculate the similarity between and at this time.
Compare the values of and select the corresponding to the minimum for the following operation.
(6) Step 6: Calculate the number of black pixels in each row of , find the row with the highest number of black pixels, and mark it as .
(7) Step 7: Extract the columns with black pixels from and mark them as .
(8) Step 8: For each column in L, extract all the pixels in that column, find the white pixel closest to , and mark it as . Extract pixel from the watermarked image , and calculate the difference between and .
(9) Step 9: Repeat steps 6–8 to obtain sets . Calculate the number of positive and negative numbers in . If the number of positive numbers and 0s in is greater than the number of negative numbers, denote as , and otherwise denote as .
(10) Step 10: If , the extracted watermark bit is ‘1’, and if , the extracted watermark bit is ‘0’.
(11) Step 11: Repeat steps 5–10 to extract all watermark bits and obtain the watermark string (length N) extracted from the current image.
(12) Step 12: Overlay and average all extracted watermark strings to obtain the final extracted watermarks .













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}