
PSBF: p-adic Integer Scalable Bloom Filter

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The proposal of a bloom filter automatic expansion technique founded on p-adic integers. This technique enables the bloom filter to dynamically adapt its size in accordance with the actual number of stored elements, thereby resolving the problems associated with inefficient storage utilization and elevated false positive rates encountered in bloom filters employing fixed-size binary vectors;
- Algorithms for the insertion and querying of a bloom filter, utilizing p-adic integers, have been developed, and their effectiveness in terms of storage and query efficiency has been validated through experimental analysis;
- The algorithms address the limitation of conventional bloom filters in terms of expandability when the number of stored elements is uncertain, thereby enhancing the practicality and adaptability of bloom filters.
2. Related Works
3. Methods
- 1.
- The p-adic integer algebraic representation is defined as follows: Let α be an element in the number domain Qp. It can be expressed as Equation (1).
- 2.
- Coefficient extraction operation. Taking the example of 3-adic, the p-adic integer representation is obtained. Let an integer e = 11 be given, and the 3-adic expanded form of the number e is calculated using Equation (2), where n = 0. The process involves three steps:
- 3.
- Calculation of the probability of false positives. The PSBF involves determining the depth d and prime number p of the p-adic expansion. The number of slices from layer 1 to layer d is represented by p, p2, p3, …, pd. The probability of a false positive for a single number Pf is calculated using Equation (4).
- 4.
- PSBF operation. During the initialization stage, the algorithm “InitBloom” is executed to generate a bt bloom filter. As depicted in Algorithm 1, a “tree” array is initialized. Each data element comprises two attributes, namely “Id” and “Index”, where “Id” represents the index and “Index” denotes the array of its own structure.
| Algorithm 1 InitBloom |
| Input: none |
| Output: bt |
| 1.function InitBloom |
| 2. btcreate an empty array tree; |
| 3. return bt |
| 4.end function |
| Algorithm 2 BKDRHash |
| Input: str |
| Output: hashCode |
| 1.function BKDRHash (str) |
| 2. seed131; |
| 3. hash0; |
| 4. for i0 to len(str) - 1 do |
| 5. hash(hashseed) + unit64(str[i]); |
| 6. end for |
| 7. return hashCode&0x7FFFFFFF |
| 8.end function |
| Algorithm 3 DecimalToAny |
| Input: num, p |
| Output: new_num_str |
| 1.function DecimalToAny(num,p) |
| 2. initialize variables new_num_str, remainder, remainder_string; |
| 3. while num0 do |
| 4. remainder num mod p; |
| 5. if remainder > 9 and remainder < 76 then |
| 6. remainder_stringtenToAny[remainder]; |
| 7. else |
| 8. remainder_stringstr(remainder); |
| 9. end if |
| 10. new_num_str tetany + remainder_string; |
| 11. numnum/p; |
| 12. end while |
| 13. return new_num_str |
| 14. end function |
| Algorithm 4 InsertElement |
| Input: e, bt |
| Output: newBt |
| 1.function InsterElement(e, bt) |
| 2. initialize variables path, flag, num, newBt; |
| 3. for i⇐0 to len(e)—1 do |
| 4. for h⇐0 to len(bt))—1 do |
| 5. if string(e[i]) == bt[h].Id then |
| 6. flag⇐true; |
| 7. if i =- 0 then |
| 8. path⇐strconv.Itoa(h) + “.Index” |
| 9. else |
| 10. path⇐path + “.”+ strconv.Itoa(h) + “.Index”; |
| 11. end if |
| 12. bt⇐bt[h].Index; |
| 13. break |
| 14. else |
| 15. flag⇐false; |
| 16. end if |
| 17. end for |
| 18. if !flag then |
| 19. if i == 0 then |
| 20. create a new node a of the tree, add a to the end of newBt, record path, and bt⇐newBt [len(newBt)-1].Index; |
| 21. else |
| 22. create a new node a of the tree, add a to the end of bt, update newBt, and bt⇐bt [len(bt)-1].Index; |
| 23. if num == 0 then |
| 24. path⇐path + “.”+ strconv.Itoa(v) + “.Index”; |
| 25. num++; |
| 26. else |
| 27. path⇐ path + “.0.Index”; |
| 28. end if |
| 29. end if |
| 30. end if |
| 31. end for |
| 32. return s |
| 33.end function |
| Algorithm 5 SearchElement |
| Input: e, bt |
| Output: true or false |
| 1.function SearchElement(e, bt) |
| 0 to len(e)—1 do |
| 3. if len(bt) < 1 then |
| 4. return false |
| 5. end if |
| 6. found⇐ false; |
| 7. for h⇐0 to len(bt)—1 do |
| 8. if string(e[i]) = bt[h].Id then |
| 9. found⇐true; |
| 10. bt⇐ bt[h].Index; |
| 11. break |
| 12. end if |
| 13. end for |
| 14. if !found then |
| 15. return false |
| 16. end if |
| 17. end for |
| 18. return true |
| 19.end function |
4. Results
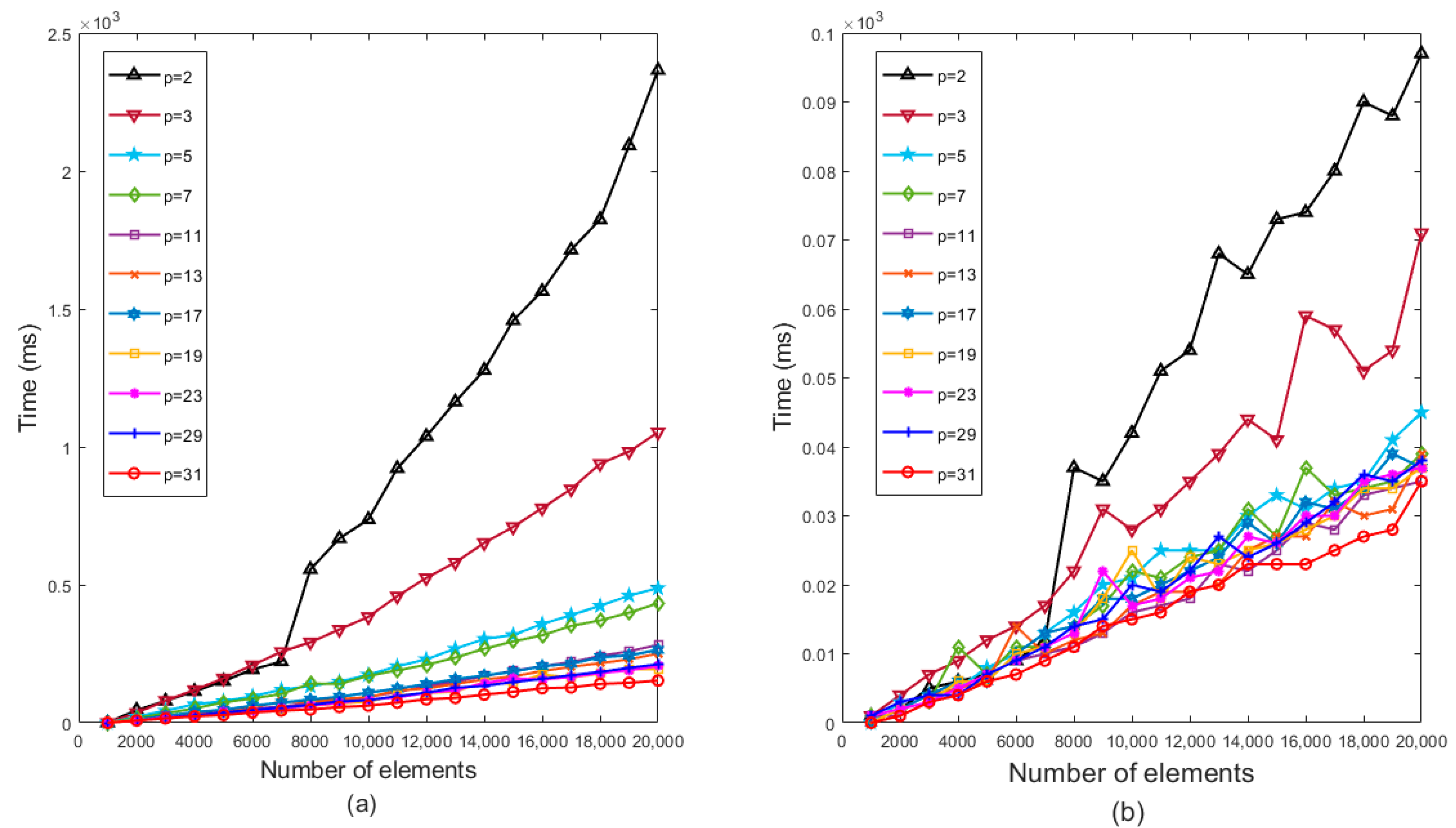
4.1. Selection of the Optimal Prime Number p
4.2. Selection of a Suitable Hash Function
5. Discussion
5.1. Analysis of Insertion and Query Performance
5.2. Analysis of Space Utilization and Misjudgment Number
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, A.; Garg, S.; Kaur, K.; Batra, S.; Kumar, N.; Choo, K.-K.R. Fuzzy-folded bloom filter-as-a-service for big data storage in the cloud. IEEE Trans. Ind. Inform. 2018, 15, 2338–2348. [Google Scholar] [CrossRef]
- Singh, A.; Garg, S.; Batra, S.; Kumar, N.; Rodrigues, J.J. Bloom filter based optimization scheme for massive data handling in IoT environment. Future Gener. Comput. Syst. 2018, 82, 440–449. [Google Scholar] [CrossRef]
- Yang, C.; Tao, X.; Zhao, F.; Wang, Y. Secure data transfer and deletion from counting bloom filter in cloud computing. Chin. J. Electron. 2020, 29, 273–280. [Google Scholar] [CrossRef]
- Luo, L.; Guo, D.; Ma, R.T.; Rottenstreich, O.; Luo, X. Optimizing bloom filter: Challenges, solutions, and comparisons. IEEE Commun. Surv. Tutor. 2018, 21, 1912–1949. [Google Scholar] [CrossRef]
- Hou, R.; Zhang, L.; Wu, T.; Mao, T.; Luo, J. Bloom-filter-based request node collaboration caching for named data networking. Clust. Comput. 2019, 22, 6681–6692. [Google Scholar] [CrossRef]
- Ni, J.; Zhang, K.; Vasilakos, A.V. Security and privacy for mobile edge caching: Challenges and solutions. IEEE Wirel. Commun. 2020, 28, 77–83. [Google Scholar] [CrossRef]
- He, P.; Xue, K.; Yang, J.; Xia, Q.; Liu, J.; Wei, D.S. FASE: Fine-grained accountable and space-efficient access control for multimedia content with in-network caching. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4462–4475. [Google Scholar] [CrossRef]
- Cohen, I.; Einziger, G.; Scalosub, G. False negative awareness in indicator-based caching systems. IEEE/ACM Trans. Netw. 2022, 30, 2674–2687. [Google Scholar] [CrossRef]
- Zhang, L.; Bai, Z.; Cui, B.; Wu, Z. Search mechanism for data contents based on bloom filter and tree hybrid structure in system wide information management. IET Commun. 2023, 17, 1262–1273. [Google Scholar] [CrossRef]
- Zeng, Z.; Xiao, R.; Lin, X.; Luo, T.; Lin, J. Double locality sensitive hashing Bloom filter for high-dimensional streaming anomaly detection. Inf. Process. Manag. 2023, 60, 103306. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, L.Y.; Li, J. Fast detection of maximal exact matches via fixed sampling of query K-mers and Bloom filtering of index K-mers. Bioinformatics 2019, 35, 4560–4567. [Google Scholar] [CrossRef]
- Patgiri, R.; Nayak, S.; Borgohain, S.K. Passdb: A password database with strict privacy protocol using 3d bloom filter. Inf. Sci. 2020, 539, 157–176. [Google Scholar] [CrossRef]
- Byun, H.; Lim, H. Learned FBF: Learning-Based Functional Bloom Filter for Key–Value Storage. IEEE Trans. Comput. 2021, 71, 1928–1938. [Google Scholar] [CrossRef]
- Lemane, T.; Medvedev, P.; Chikhi, R.; Peterlongo, P. Kmtricks: Efficient and flexible construction of bloom filters for large sequencing data collections. Bioinform. Adv. 2022, 2, vbac029. [Google Scholar] [CrossRef]
- Liang, Y.; Ma, J.; Miao, Y.; Kuang, D.; Meng, X.; Deng, R.H. Privacy-Preserving Bloom Filter-Based Keyword Search over Large Encrypted Cloud Data. IEEE Trans. Comput. 2023. [Google Scholar] [CrossRef]
- Yi, W.; Gerasimov, I.; Kuzmin, S.; He, H. A stream processing approach to distance measurement of integers in p-adic metric space. In Proceedings of the 2017 XX IEEE International Conference on Soft Computing and Measurements (SCM), Saint Petersburg, Russia, 24–26 May 2017; pp. 617–620. [Google Scholar]
- Almeida, P.S.; Baquero, C.; Preguiça, N.; Hutchison, D. Scalable bloom filters. Inf. Process. Lett. 2007, 101, 255–261. [Google Scholar] [CrossRef]
- Guo, D.; Wu, J.; Chen, H.; Yuan, Y.; Luo, X. The dynamic bloom filters. IEEE Trans. Knowl. Data Eng. 2009, 22, 120–133. [Google Scholar] [CrossRef]
- Patgiri, R.; Borgohain, S.K.; Bhattacharjee, A. rFilter: A scalable and space-efficient membership filter. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 478–485. [Google Scholar]
- Kleyko, D.; Rahimi, A.; Gayler, R.W.; Osipov, E. Autoscaling bloom filter: Controlling trade-off between true and false positives. Neural Comput. Appl. 2020, 32, 3675–3684. [Google Scholar] [CrossRef]
- Kim, M.-K.; Kim, S.-R. Modifications using Circular Shift for a Better Bloom Filter. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, Gwangju, Korea, 13–16 October 2020; pp. 149–154. [Google Scholar]
- Rottenstreich, O.; Reviriego, P.; Porat, E.; Muthukrishnan, S. Constructions and applications for accurate counting of the bloom filter false positive free zone. In Proceedings of the Symposium on SDN Research, San Jose, CA, USA, 3 March 2020; pp. 135–145. [Google Scholar]
- Nayak, S.; Patgiri, R. robustBF: A high accuracy and memory efficient 2d bloom filter. arXiv 2021, arXiv:2106.04365. [Google Scholar]
- Patgiri, R.; Nayak, S.; Borgohain, S.K. rDBF: A r-dimensional bloom filter for massive scale membership query. J. Netw. Comput. Appl. 2019, 136, 100–113. [Google Scholar] [CrossRef]
- Dayan, N.; Bercea, I.; Reviriego, P.; Pagh, R. InfiniFilter: Expanding Filters to Infinity and Beyond. Proc. ACM Manag. Data 2023, 1, 1–27. [Google Scholar] [CrossRef]
- Bender, M.A.; Farach-Colton, M.; Johnson, R.; Kuszmaul, B.C.; Medjedovic, D.; Montes, P.; Shetty, P.; Spillane, R.P.; Zadok, E. Don’t thrash: How to cache your hash on flash. In Proceedings of the 3rd Workshop on Hot Topics in Storage and File Systems (HotStorage 11), Portland, OR, USA, 14 June 2011. [Google Scholar]
- Cohen, S.; Matias, Y. Spectral Bloom Filters. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, 10–12 June 2003; pp. 241–252. [Google Scholar]
- Kiss, S.Z.; Hosszu, É.; Tapolcai, J.; Rónyai, L.; Rottenstreich, O. Bloom filter with a false positive free zone. IEEE Trans. Netw. Serv. Manag. 2021, 2, 2334–2349. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, Q.; Cheng, T.; Liu, L.; Zhou, W.; He, J. DLB: Deep Learning Based Load Balancing. In Proceedings of the 2021 IEEE 14th International Conference on Cloud Computing (CLOUD), Chicago, IL, USA, 5–10 September 2021; pp. 648–653. [Google Scholar]
- Kim, K.; Jeong, Y.; Lee, Y.; Lee, S. Analysis of counting bloom filters used for count thresholding. Electronics 2019, 8, 779. [Google Scholar] [CrossRef]
- Saxena, M.; Saurabh, P.; Verma, B. A new hashing scheme to overcome the problem of overloading of articles in Usenet. In Proceedings of the Advances in Computer Science, Engineering & Applications: Proceedings of the Second International Conference on Computer Science, Engineering and Applications (ICCSEA 2012), New Delhi, India, 25–27 May 2012; Volume 1, pp. 967–975. [Google Scholar]
- Bernstein, D.J. DJB Hash. Available online: http://www.partow.net/programming/hashfunctions/#DJBHashFunction (accessed on 7 August 2023).
- Wu, W.-Q.; Xue, M.-T.; Xing, Q.-J.; Yu, F. High-Parallelism Hash-Merge Architecture for Accelerating Join Operation on FPGA. IEEE Trans. Circuits Syst. II: Express Briefs 2021, 68, 2650–2654. [Google Scholar] [CrossRef]
- Shi, Y.; Huang, S.; Lou, J. A characteristic standardization method for circuit input vectors based on Hash algorithm. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1505–1513. [Google Scholar] [CrossRef]
- Jain, S.; Pandey, M. Hash table based word searching algorithm. Int. J. Comput. Sci. Inf. Technol. 2012, 3, 4385–4388. [Google Scholar]
- Lin, Y.; Huang, Z.; Li, Y. Learning hash index based on a shallow autoencoder. Appl. Intell. 2023, 53, 14999–15010. [Google Scholar] [CrossRef]
- Trimoska, M.; Ionica, S.; Dequen, G. Time-memory analysis of parallel collision search algorithms. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 254–274. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, W.; Wang, C.; Xie, Q.; Zhao, Y.; Jia, J. PSBF: p-adic Integer Scalable Bloom Filter. Sensors 2023, 23, 7775. https://doi.org/10.3390/s23187775
Yi W, Wang C, Xie Q, Zhao Y, Jia J. PSBF: p-adic Integer Scalable Bloom Filter. Sensors. 2023; 23(18):7775. https://doi.org/10.3390/s23187775
Chicago/Turabian StyleYi, Wenlong, Chuang Wang, Qiliang Xie, Yingding Zhao, and Jing Jia. 2023. "PSBF: p-adic Integer Scalable Bloom Filter" Sensors 23, no. 18: 7775. https://doi.org/10.3390/s23187775
APA StyleYi, W., Wang, C., Xie, Q., Zhao, Y., & Jia, J. (2023). PSBF: p-adic Integer Scalable Bloom Filter. Sensors, 23(18), 7775. https://doi.org/10.3390/s23187775