




Seeking a Sufficient Data Volume for Railway Infrastructure Component Detection with Computer Vision Models


Abstract
:1. Introduction
- We conducted a benchmark to determine the sufficient data volume for railway component detection. We have shown how the YOLO and MobileNet neural network architectures perform for different sizes of datasets. We have used a completely new dataset with track images we collected and labeled. The results of the analysis will be valuable to anyone designing their own railway dataset, as we provide an estimate of the sufficient size of the data.
- We introduced a novel method of extracting background images (BIE) that can be used to enrich the datasets for the railway object detection task. We have shown that this method allows us to obtain better neural networks for really small datasets. BIE is useful to improve the performance of any models for railway track object detection.
2. Materials and Methods
2.1. Railway Track
2.2. Machine Learning Models for Object Detection
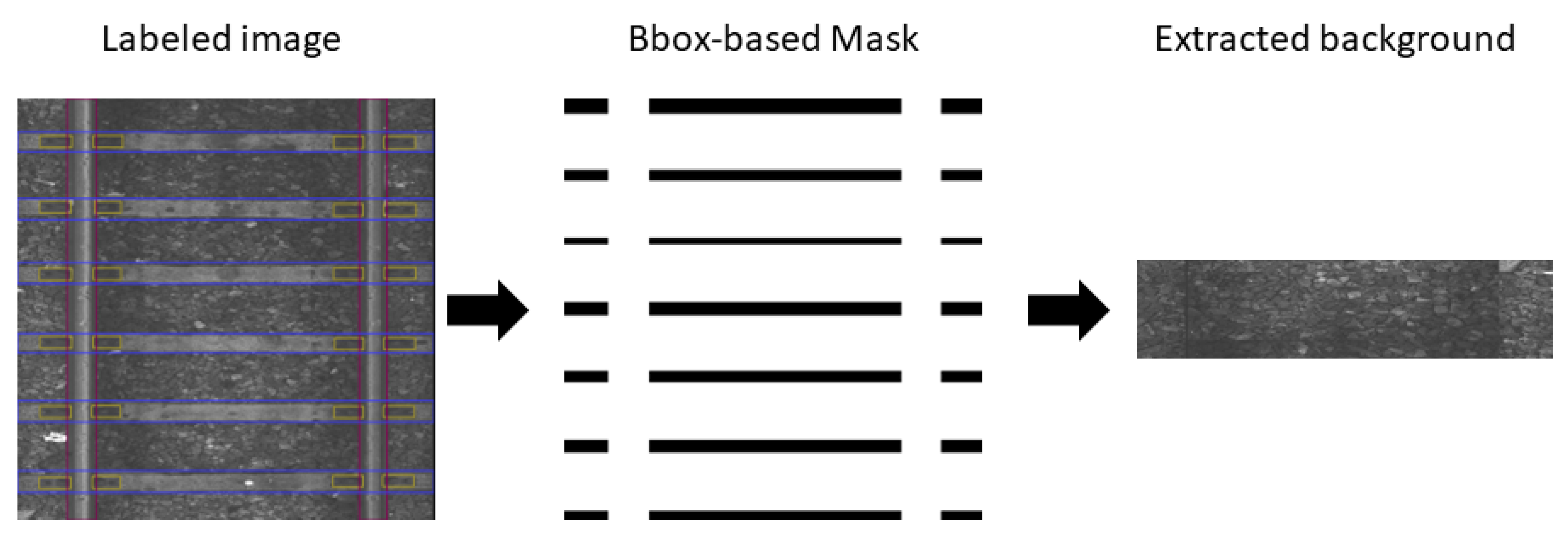
2.3. Background Image Extraction
| Algorithm 1 Mask extraction from railway image labeled with bboxes. The dot denotes a reference to the bbox property; thus, bbox.label means a class of bbox, bbox.width and bbox.height are its width and height, Additionally bbox.x_left and bbox.y_top denote the x coordinate of the left edge and y coordinate of the top edge of the bbox, respectively. |
| Require: n: image width, m: image height, x_margin: x coordinate bbox margin used for mask extraction, y_margin: y coordinate bbox margin used for mask extraction image_mask ← zeros(n, m) ▹ An array of size n × m filled with zeros. for bbox in bboxes do if bbox.label is “rail” then x_left = bbox.x_left − x_margin if x_left < 0 then x_left ← 0 end if box_width ← bbox.width + x_margin ∗ 2 y_top ← 0 ▹ Extend rail to whole image height. box_height ← bbox.height else x_left ← 0 ▹ Extend non-rail elements to whole image width. box_width ← n y_top ← bbox.y_top − y_margin if y_top < 0 then y_top ← 0 end if box_height ← bbox.height ∗ n + y_margin ∗ 2 end if ▹ Set area in mask related to the adjusted bbox to 255. image_mask[top_y: top_y + box_height, top_x: top_x + box_width] = 255 end for |
2.4. Experiment
2.4.1. Data Acquisition and Dataset
2.4.2. Experiment Settings
3. Results
4. Discussion
5. Conclusions
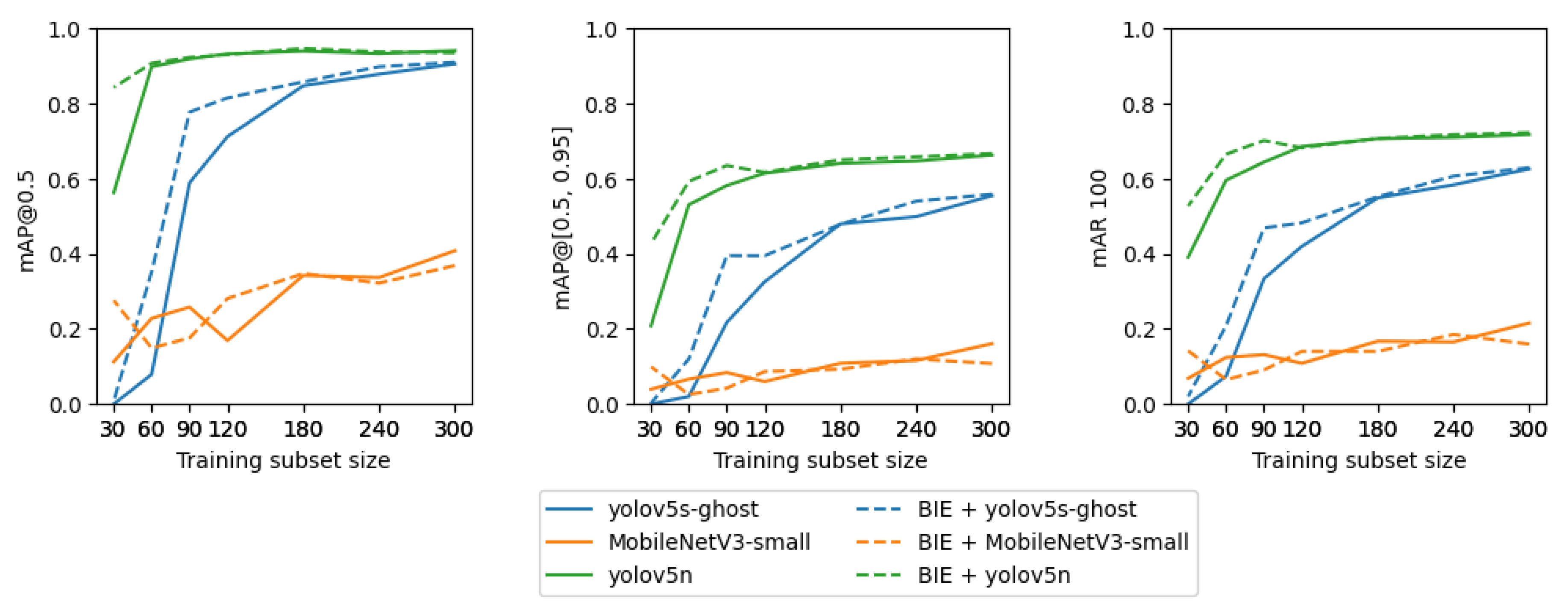
- In total, 120 training observations are enough to train an efficient YOLO model. At the same time, the authors of YOLO recommend using over 1500 images per class and over 10000 labeled objects for best training results (https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results), accessed on 3 July 2023, which is approximately 100 times more than was needed in our experiment. Taking this into account, a sufficient detector of the railway objects requires a relatively small amount of data, which is desirable since labeled railway images are not easily available;
- The number of observations required to train an efficient railway OD model can be reduced to 90 observations after applying our method BIE, which allows for background extraction from the training subset. The use of background images is common in OD tasks since backgrounds are usually simple to acquire, which is different for railway backgrounds, which cannot have any images that do not contain railway components. These should be photos composed of the ballast alone, which requires additional effort to obtain them. Thus, this paper’s result that BIE can be used to extract backgrounds from training images is an important finding;
- The best model for the railway object detection task is YOLOv5n, which is the smallest of the YOLO models, and therefore, is more robust for overfitting to small datasets.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| bbox | Bounding Box |
| BIE | Background Image Extraction |
| CNN | Convolutional Neural Network |
| IoU | Intersection Over Union |
| KNN | K-Nearest Neighbors |
| ML | Machine Learning |
| mAP | Mean Average Precision |
| mAR | Mean Average Recall |
| OD | Object Detection |
| R-CNN | Region-based Convolutional Neural Networks |
| SSD | Single-Shot Detector |
| SVM | Support Vector Machines |
| YOLO | You Only Look Once |
| YOLOv5n | YOLO version 5 nano |
| YOLOv5s-ghost | YOLO version 5 small with ghost bottleneck |
References
- Banister, D. Cities, mobility and climate change. J. Transp. Geogr. 2011, 19, 1538–1546. [Google Scholar] [CrossRef]
- Xia, T.; Zhang, Y.; Crabb, S.; Shah, P. Cobenefits of Replacing Car Trips with Alternative Transportation: A Review of Evidence and Methodological Issues. J. Environ. Public Health 2013, 2013, 1–14. [Google Scholar] [CrossRef]
- Kim, N.S.; Wee, B.V. Assessment of CO2 emissions for truck-only and rail-based intermodal freight systems in Europe. Transp. Plan. Technol. 2009, 32, 313–333. [Google Scholar] [CrossRef]
- Xia, W.; Zhang, A. High-speed rail and air transport competition and cooperation: A vertical differentiation approach. Transp. Res. Part B Methodol. 2016, 94, 456–481. [Google Scholar] [CrossRef]
- Liu, X.; Saat, M.R.; Barkan, C.P.L. Analysis of Causes of Major Train Derailment and Their Effect on Accident Rates. Transp. Res. Rec. 2012, 2289, 154–163. [Google Scholar] [CrossRef]
- Gawlak, K. Analysis and assessment of the human factor as a cause of occurrence of selected railway accidents and incidents. Open Eng. 2023, 13, 1–3. [Google Scholar] [CrossRef]
- Nakhaee, M.C.; Hiemstra, D.; Stoelinga, M.; van Noort, M. The Recent Applications of Machine Learning in Rail Track Maintenance: A Survey. In Reliability, Safety, and Security of Railway Systems. Modelling, Analysis, Verification, and Certification; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 91–105. [Google Scholar] [CrossRef]
- Li, Y.; Trinh, H.; Haas, N.; Otto, C.; Pankanti, S. Rail Component Detection, Optimization, and Assessment for Automatic Rail Track Inspection. IEEE Trans. Intell. Transp. Syst. 2014, 15, 760–770. [Google Scholar] [CrossRef]
- Manikandan, R.; Balasubramanian, M.; Palanivel, S. Machine Vision Based Missing Fastener Detection in Rail Track Images Using SVM Classifier. Int. J. Smart Sens. Intell. Syst. 2017, 10, 574–589. [Google Scholar] [CrossRef]
- Ghiasi, A.; Ng, C.T.; Sheikh, A.H. Damage detection of in-service steel railway bridges using a fine k-nearest neighbor machine learning classifier. Structures 2022, 45, 1920–1935. [Google Scholar] [CrossRef]
- Santur, Y.; Karaköse, M.; Akin, E. Random forest based diagnosis approach for rail fault inspection in railways. In Proceedings of the 2016 National Conference on Electrical, Electronics and Biomedical Engineering (ELECO), Bursa, Turkey, 1–3 December 2016; pp. 745–750. [Google Scholar]
- Hsieh, C.C.; Hsu, T.Y.; Huang, W.H. An Online Rail Track Fastener Classification System Based on YOLO Models. Sensors 2022, 22, 9970. [Google Scholar] [CrossRef]
- Gibert, X.; Patel, V.M.; Chellappa, R. Deep Multitask Learning for Railway Track Inspection. IEEE Trans. Intell. Transp. Syst. 2017, 18, 153–164. [Google Scholar] [CrossRef]
- Zhu, Y.; Sekiya, H.; Okatani, T.; Yoshida, I.; Hirano, S. Acceleration-based deep learning method for vehicle monitoring. IEEE Sensors J. 2021, 21, 17154–17161. [Google Scholar] [CrossRef]
- Lorenzen, S.R.; Riedel, H.; Rupp, M.M.; Schmeiser, L.; Berthold, H.; Firus, A.; Schneider, J. Virtual Axle Detector Based on Analysis of Bridge Acceleration Measurements by Fully Convolutional Network. Sensors 2022, 22, 8963. [Google Scholar] [CrossRef] [PubMed]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Guedes, A.; Silva, R.; Ribeiro, D.; Vale, C.; Mosleh, A.; Montenegro, P.; Meixedo, A. Detection of Wheel Polygonization Based on Wayside Monitoring and Artificial Intelligence. Sensors 2023, 23, 2188. [Google Scholar] [CrossRef]
- Ni, Y.Q.; Zhang, Q.H. A Bayesian machine learning approach for online detection of railway wheel defects using track-side monitoring. Struct. Health Monit. 2021, 20, 1536–1550. [Google Scholar] [CrossRef]
- Ta, Q.B.; Huynh, T.C.; Pham, Q.Q.; Kim, J.T. Corroded Bolt Identification Using Mask Region-Based Deep Learning Trained on Synthesized Data. Sensors 2022, 22, 3340. [Google Scholar] [CrossRef]
- Tan, L.; Tang, T.; Yuan, D. An Ensemble Learning Aided Computer Vision Method with Advanced Color Enhancement for Corroded Bolt Detection in Tunnels. Sensors 2022, 22, 9715. [Google Scholar] [CrossRef]
- Datta, D.; Hosseinzadeh, A.Z.; Cui, R.; Lanza di Scalea, F. Railroad Sleeper Condition Monitoring Using Non-Contact in Motion Ultrasonic Ranging and Machine Learning-Based Image Processing. Sensors 2023, 23, 3105. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Sresakoolchai, J.; Huang, J.; Zhu, Y.; Ngamkhanong, C.; Remennikov, A.M. Machine Learning Based Design of Railway Prestressed Concrete Sleepers. Appl. Sci. 2022, 12, 311. [Google Scholar] [CrossRef]
- Zhuang, L.; Wang, L.; Zhang, Z.; Tsui, K.L. Automated vision inspection of rail surface cracks: A double-layer data-driven framework. Transp. Res. Part C: Emerg. Technol. 2018, 92, 258–277. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Z.; Wang, H.; Núñez, A.; Han, Z. Automatic Defect Detection of Fasteners on the Catenary Support Device Using Deep Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2018, 67, 257–269. [Google Scholar] [CrossRef]
- Meixedo, A.; Ribeiro, D.; Santos, J.; Calçada, R.; Todd, M.D. Real-Time Unsupervised Detection of Early Damage in Railway Bridges Using Traffic-Induced Responses; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Suh, G.; Cha, Y.J. Deep faster R-CNN-based automated detection and localization of multiple types of damage. In Proceedings of the Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2018 (SPIE), Denver, CO, USA, 4–8 March 2018; Volume 10598, pp. 197–204. [Google Scholar]
- Giben, X.; Patel, V.M.; Chellappa, R. Material classification and semantic segmentation of railway track images with deep convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 621–625. [Google Scholar] [CrossRef]
- Wang, T.; Yang, F.; Tsui, K.L. Real-Time Detection of Railway Track Component via One-Stage Deep Learning Networks. Sensors 2020, 20, 4325. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Guo, K.; He, C.; Yang, M.; Wang, S. A pavement distresses identification method optimized for YOLOv5s. Sci. Rep. 2022, 12, 3542. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Fang, L.; Zhao, X.; Zhang, S. Small-objectness sensitive detection based on shifted single shot detector. Multimed. Tools Appl. 2019, 78, 13227–13245. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | Number of Full Railway Images | Number of Background Images Extracted with BIE | Total Number of Images |
|---|---|---|---|
| training subset 30 | 30 | 12 | 42 |
| training subset 60 | 60 | 25 | 85 |
| training subset 90 | 90 | 34 | 124 |
| training subset 120 | 120 | 49 | 169 |
| training subset 180 | 180 | 69 | 249 |
| training subset 240 | 240 | 86 | 326 |
| training subset 300 | 300 | 106 | 406 |
| validation subset | 24 | 7 | 31 |
| testing subset | 24 | - | 24 |
| Hyperparameter | YOLOv5n | YOLOv5s-Ghost | MobileNetV3-Small |
|---|---|---|---|
| Number of epochs | 100 | 100 | 100 |
| Batch size | 16 | 16 | 32 |
| Image size (in pixels) | 640 × 640 | 640 × 640 | 320 × 320 |
| Learning rate | 0.001 | 0.001 | 0.01 |
| Hyperparameter | Value |
|---|---|
| x_margin | 30 px |
| y_margin | 30 px |
| Background width or height minimal size | 100 px |
| Method | 30 obs. | 60 obs. | 90 obs. | 120 obs. | 180 obs. | 240 obs. | 300 obs. |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 0.563 | 0.899 | 0.919 | 0.933 | 0.941 | 0.934 | 0.942 |
| BIE + YOLOv5n | 0.843 | 0.908 | 0.923 | 0.931 | 0.947 | 0.938 | 0.936 |
| YOLOv5s-ghost | 0.00 | 0.079 | 0.589 | 0.712 | 0.848 | 0.879 | 0.906 |
| BIE + YOLOv5s-ghost | 0.008 | 0.352 | 0.778 | 0.816 | 0.858 | 0.899 | 0.910 |
| MobileNetV3-small | 0.113 | 0.229 | 0.258 | 0.169 | 0.343 | 0.337 | 0.408 |
| BIE + MobileNetV3-small | 0.276 | 0.149 | 0.176 | 0.281 | 0.348 | 0.322 | 0.369 |
| Method | 30 obs. | 60 obs. | 90 obs. | 120 obs. | 180 obs. | 240 obs. | 300 obs. |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 0.208 | 0.531 | 0.582 | 0.615 | 0.641 | 0.647 | 0.663 |
| BIE + YOLOv5n | 0.427 | 0.593 | 0.636 | 0.617 | 0.651 | 0.659 | 0.667 |
| YOLOv5s-ghost | 0.00 | 0.020 | 0.218 | 0.326 | 0.480 | 0.499 | 0.555 |
| BIE + YOLOv5s-ghost | 0.002 | 0.120 | 0.395 | 0.395 | 0.479 | 0.541 | 0.559 |
| MobileNetV3-small | 0.039 | 0.067 | 0.084 | 0.060 | 0.109 | 0.116 | 0.161 |
| BIE + MobileNetV3-small | 0.099 | 0.026 | 0.042 | 0.087 | 0.093 | 0.120 | 0.108 |
| Method | 30 obs. | 60 obs. | 90 obs. | 120 obs. | 180 obs. | 240 obs. | 300 obs. |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 0.391 | 0.596 | 0.645 | 0.686 | 0.707 | 0.711 | 0.718 |
| BIE + YOLOv5n | 0.528 | 0.666 | 0.702 | 0.683 | 0.707 | 0.717 | 0.723 |
| YOLOv5s-ghost | 0.00 | 0.074 | 0.334 | 0.420 | 0.549 | 0.584 | 0.626 |
| BIE + YOLOv5s-ghost | 0.020 | 0.208 | 0.469 | 0.483 | 0.552 | 0.607 | 0.630 |
| MobileNetV3-small | 0.069 | 0.124 | 0.132 | 0.109 | 0.167 | 0.165 | 0.216 |
| BIE + MobileNetV3-small | 0.142 | 0.065 | 0.091 | 0.140 | 0.140 | 0.185 | 0.160 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gosiewska, A.; Baran, Z.; Baran, M.; Rutkowski, T. Seeking a Sufficient Data Volume for Railway Infrastructure Component Detection with Computer Vision Models. Sensors 2023, 23, 7776. https://doi.org/10.3390/s23187776
Gosiewska A, Baran Z, Baran M, Rutkowski T. Seeking a Sufficient Data Volume for Railway Infrastructure Component Detection with Computer Vision Models. Sensors. 2023; 23(18):7776. https://doi.org/10.3390/s23187776
Chicago/Turabian StyleGosiewska, Alicja, Zuzanna Baran, Monika Baran, and Tomasz Rutkowski. 2023. "Seeking a Sufficient Data Volume for Railway Infrastructure Component Detection with Computer Vision Models" Sensors 23, no. 18: 7776. https://doi.org/10.3390/s23187776
APA StyleGosiewska, A., Baran, Z., Baran, M., & Rutkowski, T. (2023). Seeking a Sufficient Data Volume for Railway Infrastructure Component Detection with Computer Vision Models. Sensors, 23(18), 7776. https://doi.org/10.3390/s23187776