
GPU Rasterization-Based 3D LiDAR Simulation for Deep Learning
 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
- The proposed simulator exploits the highly optimised rasterization pipeline of the GPU, increasing data generation speeds one hundredfold compared to the state-of-the-art. This is particularly useful for data-driven applications demanding vast amounts of data, such as deep-learning.
- The presented algorithms are generic and allow simulation of any ToF sensor, including those with unique sampling patterns, which has not been considered in any prior work to the best of our knowledge.
- We introduce a novel loss function leveraging synthetic and partially annotated real data to alleviate the mismatch between simulation and reality. It furthermore allows the model to learn classes for which no labels are provided in the real-world training set.
- Our techniques greatly alleviate, and in some cases completely eliminate, the tedious annotation process of real data, even for difficult tasks such as segmentation, unlike any prior work focusing on LiDAR. That is, we present a working pipeline for training reliable models for specific ToF devices with unique hardware specifications when no or limited annotated data are available.
- Two neural networks operating on real data for denoising and semantic segmentation are trained using synthetic point clouds generated by a digital twin of a real-world prototype LiDAR.
2. Related Work
3. GPU-Accelerated LiDAR Simulation
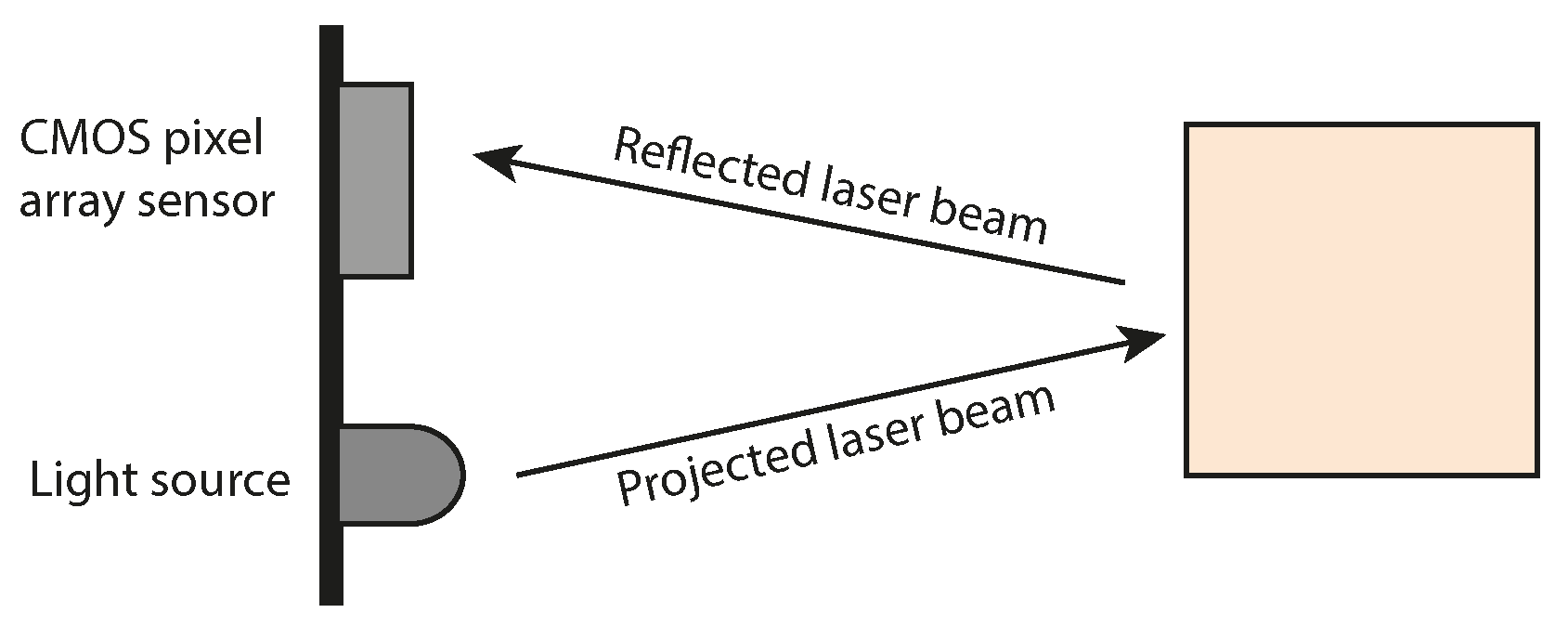
3.1. Basic Principles ToF Sensors
3.2. Rasterization-Based ToF Sensor Simulation
3.3. Matching Hardware Specifications
3.4. Noise Model
3.5. GPU Implementation Details
4. Experimental Evaluation
4.1. Data Generation Speed
4.2. Point Cloud Denoising
4.2.1. Dataset Generation
4.2.2. Performance Evaluation
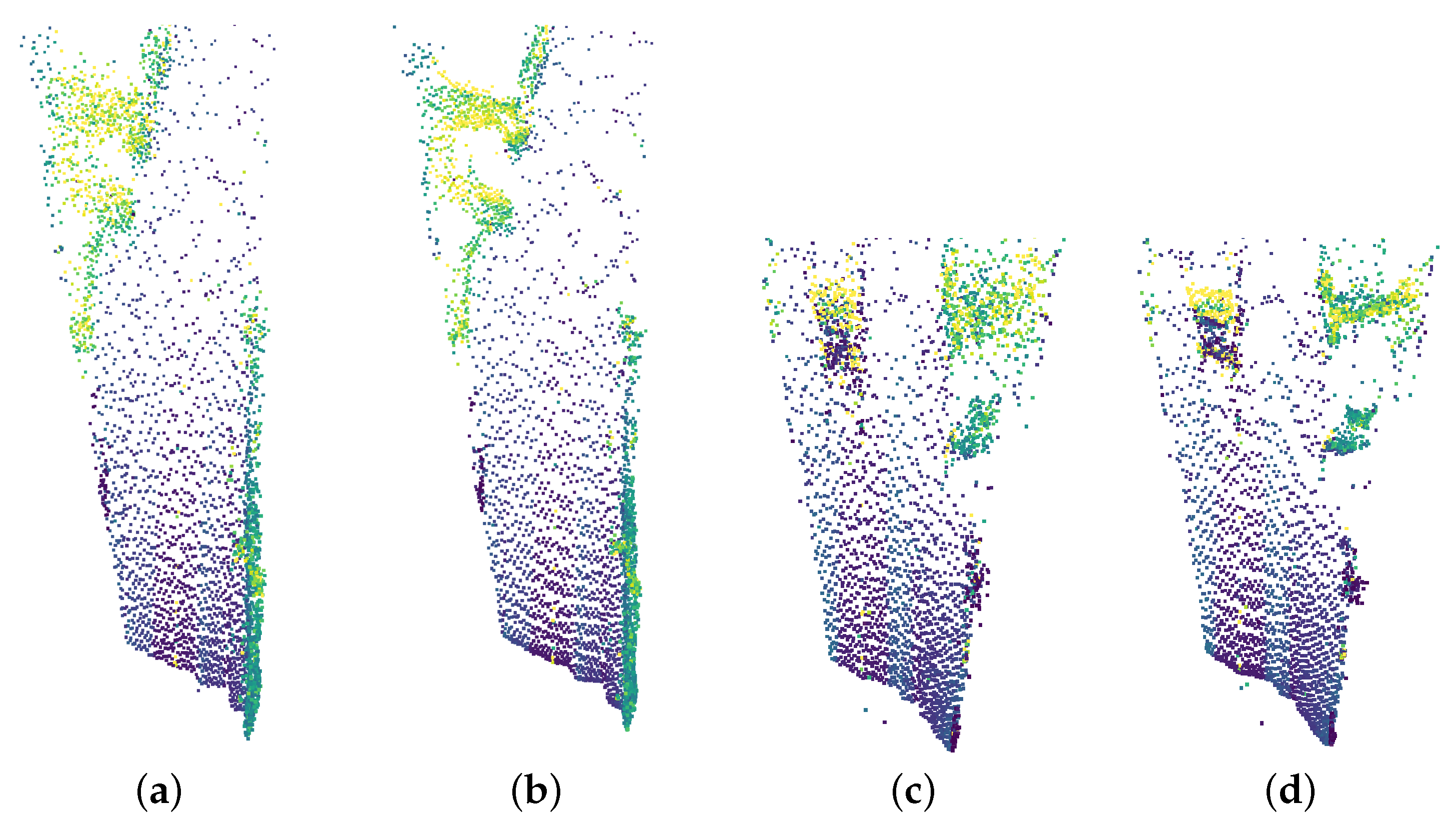
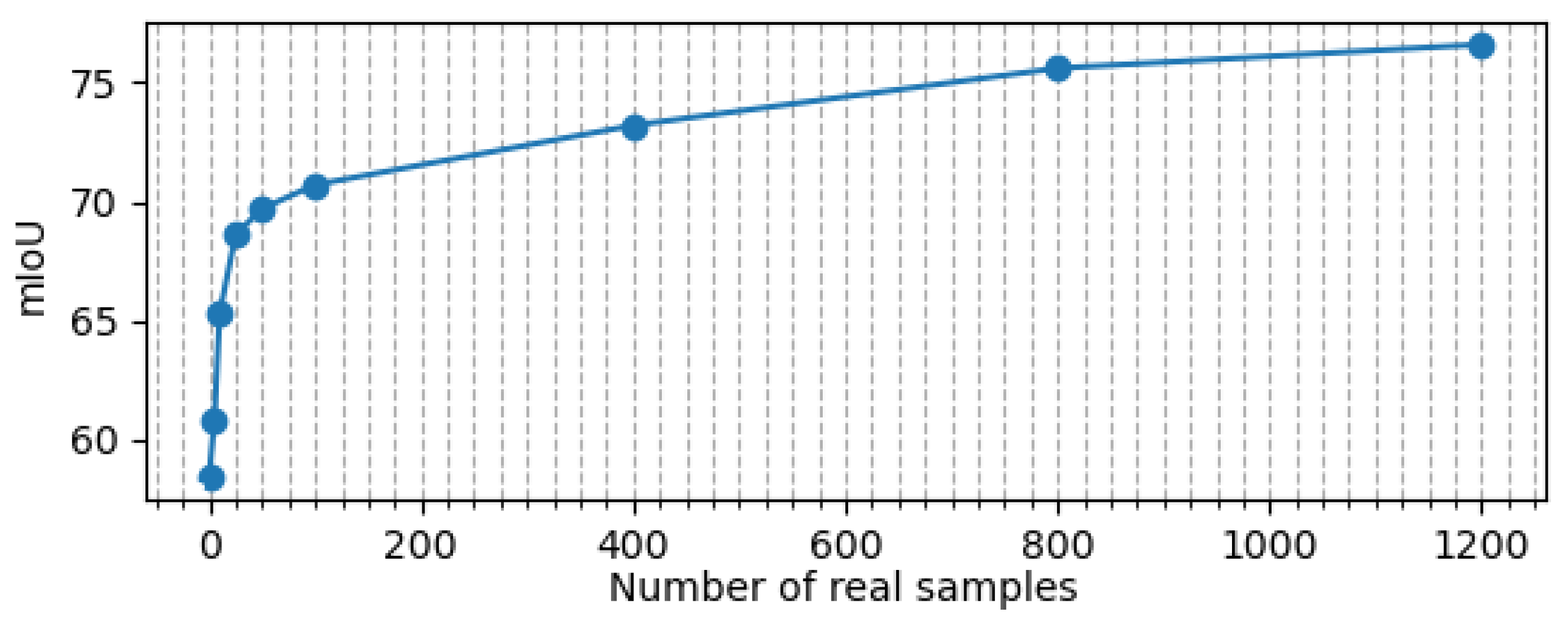
4.3. Semantic Segmentation
4.3.1. Dataset Generation
4.3.2. Custom Loss
4.3.3. Performance Evaluation
5. Limitations and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Dayton, OH, USA, 15–19 July 2012; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Sydney, Australia, 2012; Volume 25. [Google Scholar]
- Liu, X.; Liu, T.; Zhou, J.; Liu, H. High-resolution facial expression image restoration via adaptive total variation regularization for classroom learning environment. Infrared Phys. Technol. 2023, 128, 104482. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, C.; Deng, Y.; Xie, B.; Liu, T.; Zhang, Z.; Li, Y.F. TransIFC: Invariant Cues-aware Feature Concentration Learning for Efficient Fine-grained Bird Image Classification. IEEE Trans. Multimed. 2023, 1, 8548. [Google Scholar] [CrossRef]
- Ivanovs, M.; Ozols, K.; Dobrajs, A.; Kadikis, R. Improving Semantic Segmentation of Urban Scenes for Self-Driving Cars with Synthetic Images. Sensors 2022, 22, 2252. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Yan, Y.; Wang, W. CF-YOLOX: An Autonomous Driving Detection Model for Multi-Scale Object Detection. Sensors 2023, 23, 3794. [Google Scholar] [CrossRef]
- Yuan, Z.; Wang, Z.; Li, X.; Li, L.; Zhang, L. Hierarchical Trajectory Planning for Narrow-Space Automated Parking with Deep Reinforcement Learning: A Federated Learning Scheme. Sensors 2023, 23, 4087. [Google Scholar] [CrossRef]
- Shi, J.; Li, K.; Piao, C.; Gao, J.; Chen, L. Model-Based Predictive Control and Reinforcement Learning for Planning Vehicle-Parking Trajectories for Vertical Parking Spaces. Sensors 2023, 23, 7124. [Google Scholar] [CrossRef]
- Gu, Z.; Liu, Z.; Wang, Q.; Mao, Q.; Shuai, Z.; Ma, Z. Reinforcement Learning-Based Approach for Minimizing Energy Loss of Driving Platoon Decisions. Sensors 2023, 23, 4176. [Google Scholar] [CrossRef]
- Yang, L.; Babayi Semiromi, M.; Xing, Y.; Lv, C.; Brighton, J.; Zhao, Y. The Identification of Non-Driving Activities with Associated Implication on the Take-Over Process. Sensors 2022, 22, 42. [Google Scholar] [CrossRef]
- Boulch, A.; Sautier, C.; Michele, B.; Puy, G.; Marlet, R. ALSO: Automotive Lidar Self-Supervision by Occupancy Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13455–13465. [Google Scholar]
- Ryu, K.; Hwang, S.; Park, J. Instant Domain Augmentation for LiDAR Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 9350–9360. [Google Scholar]
- Wang, P.; Huang, X.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 29, 6463. [Google Scholar] [CrossRef]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The ApolloScape Dataset for Autonomous Driving. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1067–10676. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–16 June 2020. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, Canada, 16–21 June 2012. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–16 June 2020; pp. 11621–11631. [Google Scholar]
- Reitmann, S.; Neumann, L.; Jung, B. BLAINDER—A Blender AI Add-On for Generation of Semantically Labeled Depth-Sensing Data. Sensors 2021, 21, 2144. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Los Angeles, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Razani, R.; Cheng, R.; Taghavi, E.; Bingbing, L. Lite-HDSeg: LiDAR Semantic Segmentation Using Lite Harmonic Dense Convolutions. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an China, 12–15 June 2021; pp. 9550–9556. [Google Scholar] [CrossRef]
- Cheng, R.; Razani, R.; Ren, Y.; Bingbing, L. S3Net: 3D LiDAR Sparse Semantic Segmentation Network. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 12–15 June 2021; pp. 14040–14046. [Google Scholar] [CrossRef]
- Zhou, D.; Fang, J.; Song, X.; Liu, L.; Yin, J.; Dai, Y.; Li, H.; Yang, R. Joint 3D Instance Segmentation and Object Detection for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-time 3D Object Detection from Point Clouds. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Zhou, Z.; Zhang, Y.; Foroosh, H. Panoptic-PolarNet: Proposal-Free LiDAR Point Cloud Panoptic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 12–15 June 2021; pp. 13194–13203. [Google Scholar]
- Hu, J.S.K.; Kuai, T.; Waslander, S.L. Point Density-Aware Voxels for LiDAR 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8469–8478. [Google Scholar]
- Lai, X.; Chen, Y.; Lu, F.; Liu, J.; Jia, J. Spherical Transformer for LiDAR-Based 3D Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 12–15 June 2023; pp. 17545–17555. [Google Scholar]
- Li, J.; Luo, C.; Yang, X. PillarNeXt: Rethinking Network Designs for 3D Object Detection in LiDAR Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 12–15 June 2023; pp. 17567–17576. [Google Scholar]
- Erabati, G.K.; Araujo, H. Li3DeTr: A LiDAR Based 3D Detection Transformer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), London, UK, 5–7 January 2023; pp. 4250–4259. [Google Scholar]
- Whitted, T. An Improved Illumination Model for Shaded Display. Commun. ACM 1980, 23, 343–349. [Google Scholar] [CrossRef]
- Morsdorf, F.; Frey, O.; Koetz, B.; Meier, E. Ray tracing for modeling of small footprint airborne laser scanning returns. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2007, 36, 249–299. [Google Scholar] [CrossRef]
- Kukko, A.; Hyyppä, J. Small-footprint Laser Scanning Simulator for System Validation, Error Assessment, and Algorithm Development. Photogramm. Eng. Remote Sens. 2009, 75, 1177. [Google Scholar] [CrossRef]
- Kim, S.; Min, S.; Kim, G.; Lee, I.; Jun, C. Data simulation of an airborne lidar system. Proc. SPIE 2009, 12, 8545. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, D.; Yan, G.; Zhang, W.; Mu, X. Analysis on the inversion accuracy of LAI based on simulated point clouds of terrestrial LiDAR of tree by ray tracing algorithm. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium, IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 532–535. [Google Scholar] [CrossRef]
- Gastellu-Etchegorry, J.P.; Yin, T.; Lauret, N.; Cajgfinger, T.; Gregoire, T.; Grau, E.; Féret, J.B.; Lopes, M.; Guilleux, J.; Dedieu, G.; et al. Discrete Anisotropic Radiative Transfer (DART 5) for Modeling Airborne and Satellite Spectroradiometer and LIDAR Acquisitions of Natural and Urban Landscapes. Remote Sens. 2015, 7, 1667–1701. [Google Scholar] [CrossRef]
- Yun, T.; Cao, L.; An, F.; Chen, B.; Xue, L.; Li, W.; Pincebourde, S.; Smith, M.J.; Eichhorn, M.P. Simulation of multi-platform LiDAR for assessing total leaf area in tree crowns. Agric. For. Meteorol. 2019, 276–277, 107610. [Google Scholar] [CrossRef]
- Gusmão, G.; Barbosa, C.; Raposo, A. Development and Validation of LiDAR Sensor Simulators Based on Parallel Raycasting. Sensors 2020, 20, 7186. [Google Scholar] [CrossRef]
- Hanke, T.; Schaermann, A.; Geiger, M.; Weiler, K.; Hirsenkorn, N.; Rauch, A.; Schneider, S.A.; Biebl, E. Generation and validation of virtual point cloud data for automated driving systems. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Yue, X.; Wu, B.; Seshia, S.A.; Keutzer, K.; Sangiovanni-Vincentelli, A.L. A LiDAR Point Cloud Generator: From a Virtual World to Autonomous Driving. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, ICMR ’18, New York, NY, USA, 17–21 April 2018; pp. 458–464. [Google Scholar] [CrossRef]
- Unreal Technologies. Unreal Engine. Available online: https://www.unrealengine.com (accessed on 10 August 2023).
- Wang, F.; Zhuang, Y.; Gu, H.; Hu, H. Automatic Generation of Synthetic LiDAR Point Clouds for 3-D Data Analysis. IEEE Trans. Instrum. Meas. 2019, 68, 2671–2673. [Google Scholar] [CrossRef]
- Manivasagam, S.; Wang, S.; Wong, K.; Zeng, W.; Sazanovich, M.; Tan, S.; Yang, B.; Ma, W.; Urtasun, R. LiDARsim: Realistic LiDAR Simulation by Leveraging the Real World. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11164–11173. [Google Scholar] [CrossRef]
- Bechtold, S.; Höfle, B. Helios: A multi-purpose lidar simulation framework for research, planning and training of laser scanning operations with airborne, ground-based mobile and stationary platforms. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2016, III-3, 161–168. [Google Scholar] [CrossRef]
- Winiwarter, L.; Pena, A.M.E.; Weiser, H.; Anders, K.; Sanchez, J.M.; Searle, M.; Höfle, B. Virtual laser scanning with HELIOS++: A novel take on ray tracing-based simulation of topographic 3D laser scanning. arXiv 2021, arXiv:2101.09154. [Google Scholar] [CrossRef]
- Community, B.O. Blender—A 3D Modelling and Rendering Package; Blender Foundation, Stichting Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Li, W.; Pan, C.W.; Zhang, R.; Ren, J.P.; Ma, Y.X.; Fang, J.; Yan, F.L.; Geng, Q.C.; Huang, X.Y.; Gong, H.J.; et al. AADS: Augmented autonomous driving simulation using data-driven algorithms. Sci. Robot. 2019, 4, eaaw0863. [Google Scholar] [CrossRef] [PubMed]
- Fang, J.; Zhou, D.; Yan, F.; Tongtong, Z.; Zhang, F.; Ma, Y.; Wang, L.; Yang, R. Augmented LiDAR Simulator for Autonomous Driving. IEEE Robot. Autom. Lett. 2020, 29PP, 9927. [Google Scholar] [CrossRef]
- Hossny, M.; Saleh, K.; Attia, M.H.; Abobakr, A.; Iskander, J. Fast Synthetic LiDAR Rendering via Spherical UV Unwrapping of Equirectangular Z-Buffer Images. arXiv 2020, arXiv:2006.04345. [Google Scholar]
- Fang, J.; Zuo, X.; Zhou, D.; Jin, S.; Wang, S.; Zhang, L. LiDAR-Aug: A General Rendering-Based Augmentation Framework for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4710–4720. [Google Scholar]
- Yang, Z.; Chen, Y.; Wang, J.; Manivasagam, S.; Ma, W.C.; Yang, A.J.; Urtasun, R. UniSim: A Neural Closed-Loop Sensor Simulator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 1389–1399. [Google Scholar]
- Yang, Z.; Manivasagam, S.; Chen, Y.; Wang, J.; Hu, R.; Urtasun, R. Reconstructing Objects in-the-wild for Realistic Sensor Simulation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 11661–11668. [Google Scholar] [CrossRef]
- Guillard, B.; Vemprala, S.; Gupta, J.K.; Miksik, O.; Vineet, V.; Fua, P.; Kapoor, A. Learning to Simulate Realistic LiDARs. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 8173–8180. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.; Cao, D.; Li, J. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 30, 5992. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schutz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2020, 29, 2974. [Google Scholar] [CrossRef]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE/CVF International Conf. on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the Field and Service Robotics, Cham, Swizerland, 2–9 August 2018; Hutter, M., Siegwart, R., Eds.; pp. 621–635. [Google Scholar]
- Mueller, M.; Casser, V.; Lahoud, J.; Smith, N.; Ghanem, B. Sim4CV: A Photo-Realistic Simulator for Computer Vision Applications. Int. J. Comput. Vis. 2018, 126, 902–919. [Google Scholar] [CrossRef]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In Proceedings of the Computer Vision—ECCV, Cham, Swizerland, 14–19 June 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; pp. 102–118. [Google Scholar]
- NVIDIA. Self-Driving Cars Technology & Solutions from NVIDIA Automotive. Available online: https://www.nvidia.com/en-us/self-driving-cars/ (accessed on 10 August 2023).
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the Matrix: Can virtual worlds replace human-generated annotations for real world tasks? In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 746–753. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar] [CrossRef]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the ICRA, Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Zhao, S.; Wang, Y.; Li, B.; Wu, B.; Gao, Y.; Xu, P.; Darrell, T.; Keutzer, K. ePointDA: An End-to-End Simulation-to-Real Domain Adaptation Framework for LiDAR Point Cloud Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 7–14 February 2021. [Google Scholar]
- Alhaija, H.; Mustikovela, S.; Mescheder, L.; Geiger, A.; Rother, C. Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes. Int. J. Comput. Vis. 2018, 126, 11263. [Google Scholar] [CrossRef]
- Schmitt, A.; Leister, W.; Müller, H. Ray Tracing Algorithms—Theory and Practice; Springer: Berlin/Heidelberg, Germany, 1988; pp. 997–1030. [Google Scholar] [CrossRef]
- Mei, L.; Zhang, L.; Kong, Z.; Li, H. Noise modeling, evaluation and reduction for the atmospheric lidar technique employing an image sensor. Opt. Commun. 2018, 426, 463–470. [Google Scholar] [CrossRef]
- Falie, D.; Buzuloiu, V. Noise Characteristics of 3D Time-of-Flight Cameras. In Proceedings of the 2007 International Symposium on Signals, Circuits and Systems, Iasi, Romania, 13–14 July 2007; Volume 1, pp. 1–4. [Google Scholar] [CrossRef]
- Khronos Group. OpenGL 4.5 Reference Pages. Available online: https://www.khronos.org/registry/OpenGL-Refpages/gl4/ (accessed on 10 August 2023).
- Nvidia OptiXTM. Available online: https://developer.nvidia.com/optix (accessed on 10 August 2023).
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Unity Technologies. Unity Real-Time Development Platform 3D, 2D VR & AR Engine. Available online: https://unity.com/ (accessed on 10 August 2023).
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Patil, S.S.; Patil, Y.M.; Patil, S.B. Detection and Estimation of Tree Canopy using Deep Learning and Sensor Fusion. In Proceedings of the 2023 International Conference for Advancement in Technology (ICONAT), Goa, India, 24–26 January 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Reji, J.; Nidamanuri, R.R. Deep Learning based Fusion of LiDAR Point Cloud and Multispectral Imagery for Crop Classification Sensitive to Nitrogen Level. In Proceedings of the 2023 International Conference on Machine Intelligence for GeoAnalytics and Remote Sensing (MIGARS), Hyderabad, India, 27–29 January 2023; Volume 1, pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, X. Spatiotemporal wind field prediction based on physics-informed deep learning and LIDAR measurements. Appl. Energy 2021, 288, 116641. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulated Laser Pulses | |||||
|---|---|---|---|---|---|
| Simulator | 1K | 10K | 100K | 1M | 10M |
| Blainder [18] | 45.20 | 79.76 | 566.73 | 5381.91 | 53,750.80 |
| Carla [19] | 4.24 | 5.78 | 109.75 | 1386.94 | 11,653.42 |
| NVIDIA OptiX [69] | 18.35 | 19.02 | 26.72 | 74.76 | 559.74 |
| Proposed | 0.61 | 0.81 | 2.27 | 10.87 | 113.41 |
| Target | Before Denoising | After Denoising | Noise Reduction |
|---|---|---|---|
| Dark | 6.54 | 5.24 | 19.88% |
| Gray | 4.71 | 3.61 | 23.35% |
| Light | 2.46 | 1.96 | 20.33% |
| Training Data | Results | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Synth | Real | Car | Street | Flora | Average | |||||
| Acc | IoU | Acc | IoU | Acc | IoU | oAcc | mAcc | mIoU | ||
| 10,000 | 0 | 77.38 | 32.72 | 72.48 | 67.83 | 89.74 | 74.71 | 79.90 | 78.86 | 58.35 |
| 0 | 800 | 74.02 | 50.81 | - | - | - | - | - | - | - |
| 10,000 | 800 | 79.72 | 62.88 | 90.73 | 83.29 | 89.18 | 80.55 | 89.36 | 86.51 | 75.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Denis, L.; Royen, R.; Bolsée, Q.; Vercheval, N.; Pižurica, A.; Munteanu, A. GPU Rasterization-Based 3D LiDAR Simulation for Deep Learning. Sensors 2023, 23, 8130. https://doi.org/10.3390/s23198130
Denis L, Royen R, Bolsée Q, Vercheval N, Pižurica A, Munteanu A. GPU Rasterization-Based 3D LiDAR Simulation for Deep Learning. Sensors. 2023; 23(19):8130. https://doi.org/10.3390/s23198130
Chicago/Turabian StyleDenis, Leon, Remco Royen, Quentin Bolsée, Nicolas Vercheval, Aleksandra Pižurica, and Adrian Munteanu. 2023. "GPU Rasterization-Based 3D LiDAR Simulation for Deep Learning" Sensors 23, no. 19: 8130. https://doi.org/10.3390/s23198130
APA StyleDenis, L., Royen, R., Bolsée, Q., Vercheval, N., Pižurica, A., & Munteanu, A. (2023). GPU Rasterization-Based 3D LiDAR Simulation for Deep Learning. Sensors, 23(19), 8130. https://doi.org/10.3390/s23198130