1. Introduction
With the advancement of smart grid technology and the ongoing expansion of power system infrastructure, the power industry, as a fundamental sector facilitating national economic growth, has increasingly emphasized the need to enhance the economic efficiency and ensure the stable operation of power companies [
1]. The categorization of electricity losses can be divided into two main types: technical losses (TLs) and non-technical losses (NTLs) [
2]. Technical losses are a result of disparities in infrastructure and energy dissipation, whereas non-technical losses emerge from the disparity between the total power transferred over distribution lines and the power consumed by customers. Electricity theft is the predominant type of non-technical loss, encompassing a range of techniques including private cables, physical manipulation of meter counting components, and destructive modification of meter facilities resulting in inconsistent meter readings [
3]. Electricity theft not only carries significant economic consequences for the nation but also poses a threat to public safety, since it heightens the risk of mishaps such as fires and electric shocks. According to the source cited as [
4], the aggregate financial impact of power theft on a global scale is estimated to be around CAD 100 million per year. This substantial amount of money, if not lost to theft, might instead be utilized to supply electricity to around 77,000 households for a duration of 1 year.
Numerous potential resolutions to the issue of power theft have been put out in the existing body of scholarly work [
5,
6,
7]. The existing body of literature classifies these solutions into two primary categories: hardware-based solutions and data-driven solutions. Hardware-based solutions primarily center around the development of intelligent devices and sensors with the capability to identify and detect irregularities. Nevertheless, it should be noted that the aforementioned solutions incur significant maintenance expenses, exhibit lower levels of efficiency, and require a substantial amount of time [
8]. Furthermore, they demonstrate an elevated false-positive rate (FPR). On the other hand, there exists a plethora of data-driven methodologies aimed at detecting instances of electricity theft [
9]. These solutions utilize methodologies rooted in artificial intelligence (AI) [
10], game theory (GT) [
11], and machine learning (ML), which are extensively applied in various fields such as healthcare, education, and transportation. According to cited source [
12], solutions that are driven by data have enhanced resilience, efficiency, and comprehensibility. Furthermore, the scholarly literature [
13] presents a methodology centered on grid analysis as a means to examine the identification of abnormal power consumption patterns. This methodology involves scrutinizing several parameters of the grid, such as current, voltage, and others, in order to find any atypical usage behavior. Anomaly detection encompasses the utilization of diverse data types, encompassing network-related data such as the operational state of switches and circuit breakers, alongside sensor data like voltage and current magnitudes captured by remote terminal units.
During the early phases of classification research, conventional machine learning techniques [
14,
15] were employed for the purposes of feature extraction and classification. The approaches employed in this study encompassed support vector machines (SVMs) [
16,
17], decision trees (DTs) [
18,
19], and nearest neighbors [
20,
21]. With the advancement of machine learning algorithms, there has been an increasing adoption of integrated learning algorithms that consist of several individual learners for the purpose of power theft detection. Several studies have presented several strategies for detecting instances of electricity theft, utilizing integrated learning algorithms such as random forest (RF), Adaboost, and XGBoost [
22,
23,
24,
25]. The experimental findings provided evidence that the integrated learning algorithms exhibit superior performance compared to conventional approaches. In a specific research investigation [
26], deep learning models [
27] were utilized as binary classifiers, with the purpose of detecting instances of energy theft. The researchers examined various deep learning architectures, such as CNN, Multi-Layer Perceptron (MLP), Long–Short-Term Memory (LSTM), and Gated Recurrent Unit (GRU) networks. Pereira et al. [
28] employed a CNN for the purpose of detecting instances of power theft. Additionally, they conducted a comparative analysis of different oversampling approaches to investigate the potential effects of dataset imbalance. Zheng et al. [
29] utilized a CNN to extract periodic features from load data that were transformed into a two-dimensional format. These extracted features were subsequently combined with global characteristics acquired from one-dimensional load data, which were captured using a fully connected network. The purpose of this approach was to detect instances of power theft. In a separate investigation, the authors of study [
30] employed a fusion of clustering algorithms and Long–Short-Term Memory networks in order to identify instances of electricity theft. The methodology employed entailed forecasting the subsequent electricity usage of a client at each given time and afterwards evaluating the disparity between the projected values and the actual data. Deep learning techniques provide the advantage of automated sequence feature extraction in comparison to conventional machine learning algorithms.
The issue of detecting electricity theft has been extensively explored in academic research, leading to the development and widespread adoption of several hybrid neural network models that incorporate deep learning techniques. The study conducted by [
2] introduced a hybrid neural network that integrates Long–Short-Term Memory (LSTM) and Multilayer Perceptron (MLP) models. This hybrid network demonstrates the ability to extract characteristics from diverse data sources. The authors Ismail et al. [
31] proposed a hybrid neural network model that combines CNN and GRU to tackle the issue of electricity theft in distributed generation systems. The researchers in [
32] devised a novel hybrid neural network architecture that integrates the GRU, CNN, and Particle Swarm Optimization (PSO) algorithms. This model was trained and evaluated using real-time data on electricity use. The utilization of the CNN facilitates the reduction of dimensionality and redundancy within time series data. The classification of consumption patterns into normal and fraudulent categories is achieved by the utilization of the GRU network and particle swarm algorithm. The integration of the long- and short-term memory strategies into CNN technology was found to boost e-fraud detection, as demonstrated in a study conducted by [
33]. The optimal values of the hyperparameters for the CNN–LSTM were computed using meta-heuristic techniques, namely Black-Widow Optimization (BWO) and Blue-Monkey Optimization (BMO). The aforementioned works [
30,
31,
32,
33] have introduced detectors that function as hybrid deep-learning models, specifically designed for the purpose of feature extraction.
The aforementioned models have demonstrated favorable outcomes in the domain of electricity theft detection, yet certain concerns persist. The initial approach in many electrical theft detection models relies on CNNs. However, CNNs have limitations in properly capturing the global characteristics of time series data and calculating the relative correlations among the retrieved features. The excessive dependence on the initial input data presents a notable limitation. Furthermore, it is possible for the model to experience overfitting as a result of the disparity between the amount of data available in the training set and the intricacy of the model. As a result, the model’s capacity to generalize to real-world scenarios is constrained. Therefore, it is imperative to consider the importance of mitigating model overfitting and improving feature extraction capabilities. Ding et al. [
34] introduced a multivariate-branching block (DBB) as a means to extract feature information. The DBB accomplishes this by integrating several branches with diverse widths and complexities. The Gaussian-weighted feature-tokenization transformer module (FTT) was introduced by Sun et al. [
35]. The FTT module aims to investigate the transformer’s ability to capture local spatial semantic information and effectively represents the links between adjacent sequences. Moreover, Shi et al. [
36] introduced a novel methodology for detecting power theft through an end-to-end approach by utilizing the transformer neural network. This study presents a novel hybrid model named the DSDB CNN and the Gaussian-weighted transformer network (DSDBGWT), which integrates a CNN with a DSDB structure and a GWT network. In contrast to a CNN, the DSDBGWT model demonstrates enhanced proficiency in extracting global features and determining the relative relationships among various characteristics. As a result, it diminishes its dependence on the initial input data when performing classification tasks. In order to augment the model’s ability to extract features, a GWT module is utilized, which is particularly well-suited for processing sequences of extended duration. The present module effectively captures the characteristics of extended temporal sequences through the computation of attention coefficients, which are determined by the positional information of the input sequences. As a result, the model demonstrates enhanced efficacy in the detection of electricity theft. In order to address the issue of overfitting in the model, the initial step involves incorporating suitable normalization layers (LN) into both the regular block and transformer block. Furthermore, the dropout regularization technique is utilized to stochastically deactivate a certain proportion of neurons throughout the training process.
The main contributions of this article are summarized as follows:
(1) We propose a simple and efficient DSDB convolutional module in our network to extract inter- and intra-periodic features from sequences. This module replaces the traditional CNN structure, resulting in a lightweight model while improving model accuracy;
(2) We employ a transformer network with Gaussian weighting. The attention weights in this network can be attenuated based on the distance between related symbols. This allows for a more rational allocation of the attention mechanism, leading to more efficient extraction of sequence features and improved model accuracy;
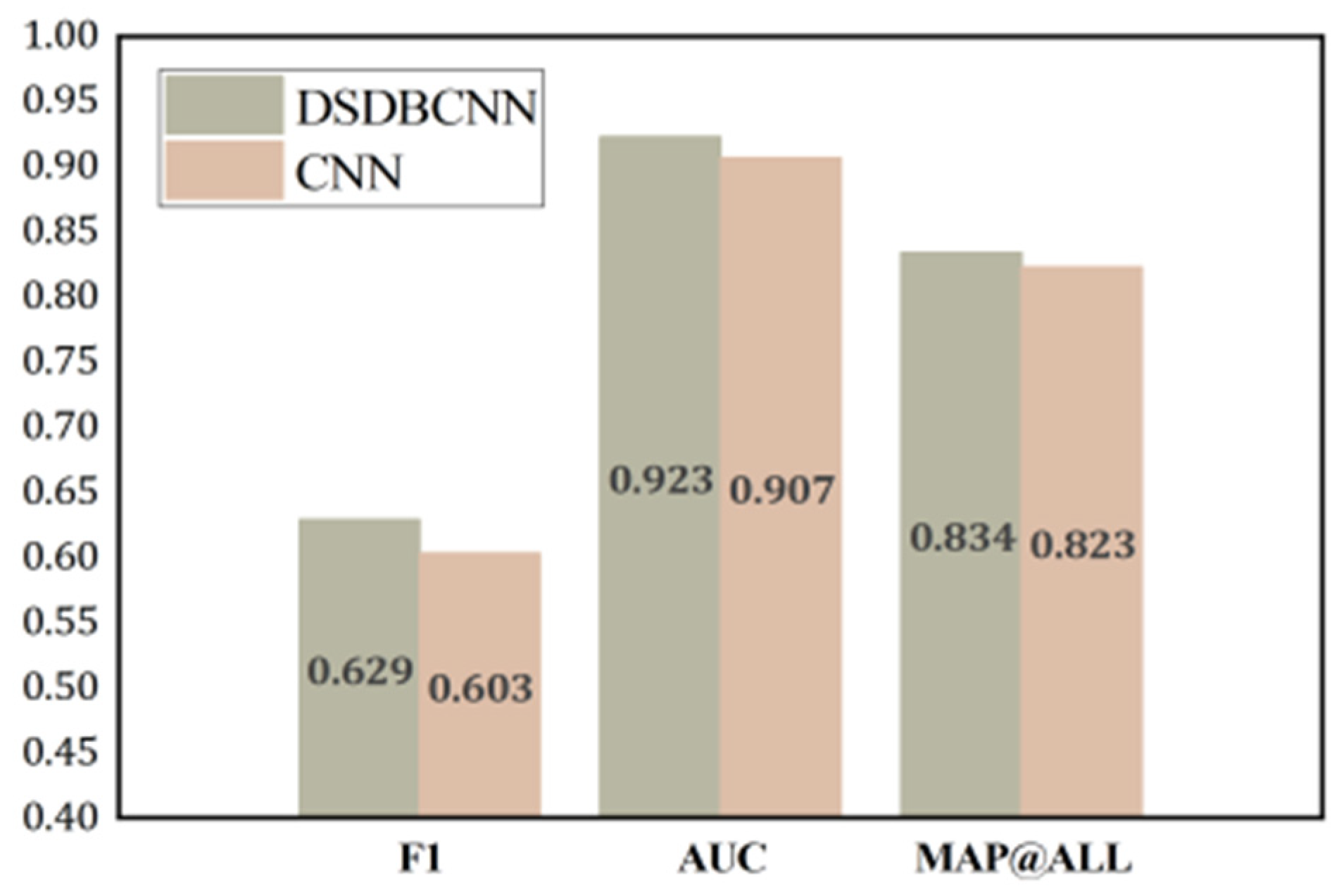
(3) The systematic combination of CNN network and GWT network can fully extract the electricity consumption information in the sequences and accurately and efficiently recognize the semantic features, thus significantly improving the classification accuracy. Extensive experiments on the China National Grid dataset show that our DSDBGWT model outperforms other existing methods.
The remainder of this paper is structured as follows.
Section 2 presents the framework of the proposed model and provides specific details on the implementation of its constituent modules. In
Section 3, we elaborate on the dataset processing, conduct comparative experiments to assess the effectiveness of our framework, and discuss the experimental results. Finally,
Section 4 concludes the paper.
2. Materials and Methods
The overall architecture of the hybrid model for electricity theft detection (DSDBGWT) based on a CNN with DSDB and a GWT network is shown in
Figure 1. The framework has three distinct modules: a CNN that incorporates a DSDB structure to facilitate shallow feature extraction, a GWT network designed specifically for long-distance feature extraction, and a classification module. Initially, the original sequence is segmented on a weekly basis using patch [
37] to effectively capture the overall characteristics and minimize computing workload, while still retaining the information from the original sequence. Following the implementation of the patch, two DSDB structures are employed, possessing identical structures. This approach enables the extraction of inter- and intra-week features of electricity consumption information with enhanced accuracy and efficiency. Additionally, this significantly reduces the computational burden associated with the convolutional operation. Subsequently, the output data generated by the CNN are once again divided into discrete four-week intervals, employing patches as the input for the transformer model. The GWT network is capable of extracting a sequence’s global features, which can produce varying weighting weights based on the input data’s distance. Thus, enhancement in feature extraction accuracy is achieved. It is important to highlight that this approach differs from the standard transformer in that it does not incorporate a class token and position embedding into the transformer’s tokens. Consequently, it does not engage in MLP processing within the tokens, but instead prioritizes the extraction of deep features from the tokens. Ultimately, the outcomes of the encoding process for each token are fed into the classification module.
The DSDBGWT network model proposed in this paper can be denoted as , with parameters . Here, is a convolutional neural network, used for shallow feature extraction, and its output is ; is a transformer network, used for long-distance feature extraction, and its output is ; and is a classifier, used for result categorization, which maps instances from the representations to the corresponding logics, which can be transformed into similar classes by . We optimize the end-to-end parameters by minimizing the cross-entropy loss on the set of markers denoted as . We define to represent the input data, to represent the derived probability value, and to represent the sum of the loss functions.
2.1. Data Preprocessing
The suggested approach is used for the smart meter data of consumers’ daily electricity consumption, which is sourced from the State Grid Corporation of China (SGCC) [
38]. The dataset provided includes authentic power consumers as well as those engaged in electricity theft, with more information about the dataset available in
Table 1.
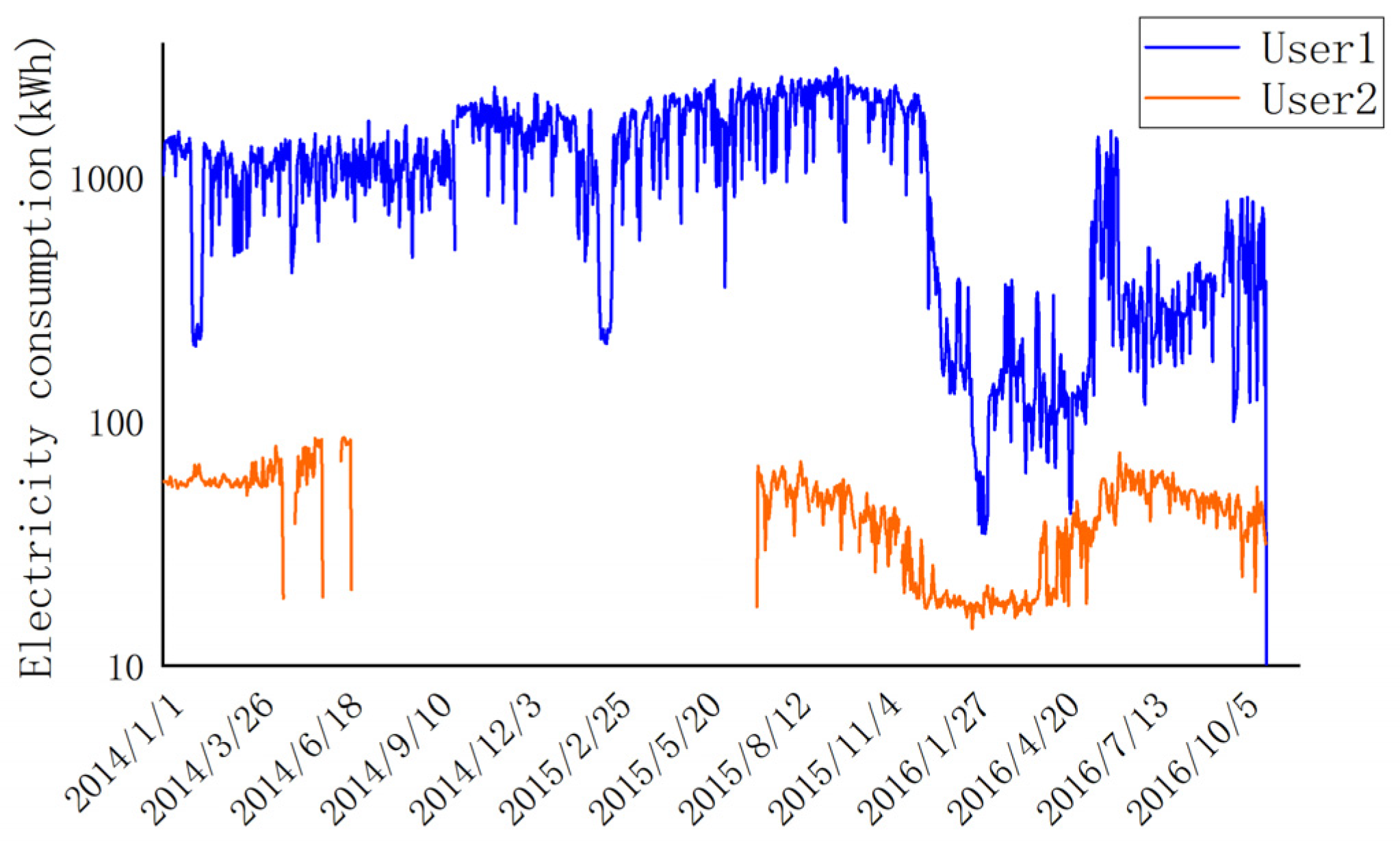
Figure 2 illustrates the electricity consumption patterns of two users within the dataset. User 1 exhibits the highest electricity usage, with a daily consumption reaching close to 2000. In contrast, User 2 represents the majority of electricity users, ranging from a few kWh to a dozen kWh per day. This discrepancy highlights the significant variation in electricity consumption among users. To address this, it is necessary to normalize the data. Normalization not only stabilizes the dataset but also enhances the convergence speed and overall efficiency of the model. Furthermore, it is evident that the data from User 2 exhibits discontinuity in certain instances. This can be attributed to various intricate factors encountered during the meter collection process, such as unreliable transmission of data due to smart meter faults, irregular system maintenance, occurrence of special events, and other multifaceted elements. Consequently, these factors contribute to the absence of electricity consumption data. In order to mitigate the impact of data variations on the neural network model, it is imperative to employ appropriate data preprocessing techniques. This study undertakes the normalization of raw data and addresses the issue of missing values through appropriate processing techniques.
(1) The process of normalization.
The act of normalizing the dataset has the effect of increasing the numerical conditions of the dataset, which in turn enhances the stability of the optimization method. Consequently, this phenomenon enhances the speed of model training and augments the efficiency of the algorithm. In addition, the process of normalization serves to standardize the distribution of data and reduce the influence of outliers on the model, improving its resilience. We choose the scaling method of
to normalize the data according to the following equation. In the normalization process, we leave the missing values untouched first:
Here, represents the user’s electricity consumption on a specific day, while and represent the minimum and maximum values, respectively, across the entire dataset.
(2) Missing value processing.
Missing values are predominantly observed when there is a lack of data at a particular point in time, typically resulting from mistakes in the measuring instrument. The inclusion of these omitted values serves to improve the overall quality of the data, enhancing its trustworthiness and suitability for analytical and modeling purposes. The zero-replacement approach is employed to address the presence of missing data that meet the specified requirements:
where
indicates the user’s electricity consumption at a given time and
indicates that
is a null value.
The network encountered difficulty distinguishing between the original value being zero and the missing value being imputed as zero, due to the preexistence of zero values in the samples. In order to tackle this matter, we implemented an additional input channel by using a binary mask [
39]. Within the mask matrix, the original data’s missing value is designated as 0, whereas the normal value of 0 is designated as 1. By employing this approach, the neural network is capable of differentiating between these two situations, thereby improving the resilience of the model.
The initial dataset, denoted as , comprises the electricity consumption data for a specific electricity user (referred to as ) over a time period of days in the past. Therefore, we can represent the original dataset as . The dataset undergoes preprocessing, which involves normalizing the raw data, processing missing values, and adding binary masks. These processes transform the dataset from a two-dimensional structure to a three-dimensional structure for variable .
2.2. Patch
Due to the considerable length of the sample sequence, it is necessary to employ the patch technique to partition the data into several subsequences at specific intervals. This strategy not only maintains the intrinsic properties of sequence but also enables more effective management and processing of the data for a range of activities, such as model training, feature extraction, and predictive analytics. The length of the patch is represented by the variable
. The sampling step is marked as
. The total number of patches is indicated by the variable
. The electricity usage per user over a period of
days is symbolized by the variable
. The calculation formula can be expressed as follows:
Electricity consumption data for normal users are usually more cyclical than for abnormal users [
29,
40,
41] (detailed analysis in
Section 3.3). To effectively process such periodic data using CNN, we employ the Patch architecture. Taking a specific sample as an example, the preprocessed data has a spatial size of
. Utilizing the Patch architecture and considering the weekly periodicity of the data, we set the parameters
= 7 and
= 7, thus transforming the data into a three-dimensional space represented as
after Patch processing, as illustrated in
Figure 3. Similarly, as shown in
Figure 4, the inputs to the transformer network undergo processing using Patch. The decision to employ Patch processing on a four-week cycle is motivated by the transformer network’s exceptional feature extraction capabilities and its proficiency in capturing distant features. The parameters Patch_size = 28 and Stride_size = 28 were set to partition the data based on monthly time intervals. This Patch architecture transforms the dimensionality of the output data from
to
, then to
. Moreover, the Patch operation reduces the number of input channels from
to approximately
, resulting in a reduction in computational complexity by a factor of
. Additionally, the Patch operation enables the model to have a stronger ability to refer back to earlier data, enhancing the network’s learning capability and leading to significant improvements in prediction performance.
2.3. Shallow Feature Extraction for DSDB Structures
After performing data preprocessing, the sequence features of the samples are extracted using 2D convolution.
Figure 5 depicts the implementation of a DSDB structure during this phase. Each branch within the structure incorporates a convolution kernel of different scales, enabling the extraction of more complete feature information compared to a single convolutional network. Taking inspiration from work with ACNet [
42], we propose the incorporation of asymmetric convolution into our approach. Specifically, we construct the convolution kernels for each branch to have dimensions of 1 × s and s × 1, respectively. The convolution kernel with dimensions s × 1 is utilized for feature extraction within a singular cycle, whereas the 1 × s convolution kernel is employed for extracting features across different cycles. The process involves the linear combination of two convolutions that are applied to the same locations but on different channels. This results in the emphasis of the squared convolution kernel in both horizontal and vertical directions, thereby highlighting distinct locally prominent features from various orientations. After the integration of the outputs from both branches into a single DSDB output, a 1 × 1 convolutional kernel is employed to maintain the inherent structure of the original sequence. In order to accelerate the rate at which the model converges during training and improve the overall generalization ability of the network [
43], a normalization layer is implemented following the convolutional layer in each branch. The normalization layer is responsible for ensuring the normalization of the feature mapping in each branch. This process results in the output features becoming nonlinear and effectively reduces data dispersion. Additionally, it serves as a preventive measure against problems such as gradient explosion or gradient vanishing. Following the normalizing procedure, the PReLu activation function is employed to counteract linearity inside the network, so enabling the network to acquire knowledge about nonlinear mappings in a hierarchical fashion. Ultimately, the utilization of Dropout serves as a means to change data in order to mitigate the occurrence of overfitting.
The model employs two distinct DSDB structures, and the subsequent description pertains to both of these DSDBs. The input data of the DSDB CNN are denoted as
, where
represents the spatial size and
represents the number of input channels. The mathematical expression for the DSDB convolution at point
of its
th channel can be represented by the following formula:
Here, represents the s × 1 convolution kernel, represents the 1 × s convolution kernel, represents the sum of channels, represents the corresponding position ranging from 1 to s in the s × 1 convolution kernel, and, similarly, represents the corresponding position ranging from 1 to s in the 1 × s convolution kernel. To maximize data utilization, it is essential to employ the padding operation by adding zeros around the space . The padding size is determined by ; at this point, .
Following the DSDB structure, a 1 × 1 convolution kernel is utilized to perform the convolution operation. Consequently, the value at the
position of the
th channel can be obtained as follows:
where
represents the sum of
channels. At this point,
.
Finally, we perform linear normalization processing and use PReLu activation function to obtain .
2.4. Gaussian-Weighted Transformer Encoder Module
Regarding the detection of electricity theft, past research has predominantly concentrated on shallow feature extraction using convolutional neural networks, resulting in favorable outcomes. However, when addressing the issue of electricity theft, it is crucial to consider the correlation of data over an extended period. The data samples in this case consist of long time series. CNN has limitations in representing features for such long-time series data. The shallow feature extraction of CNN restricts their ability to capture long-term dependencies, as the extensive use of convolutional operations can only encompass a limited range of features. Moreover, the sample data contain a small number of anomalous samples, accounting for only 8.5% of the total. Relying solely on CNNs not only fails to extract more positive outcomes, but also runs the risk of gradient vanishing. To address the challenge at hand, this study introduces a transformer network into the framework. By incorporating the transformer network, the model is able to effectively capture global dependencies, enabling the extraction of long-distance characteristics. Additionally, the transformer network offers parallel computing capabilities, enhancing the overall efficiency of the network. This paper aims to enhance the precision of the model by enhancing the transformer network’s Gaussian-weighted attention mechanism. The proposed improvement involves incorporating a Gaussian-weighted self-attention mechanism into the original network. This mechanism combines features extracted from , , and using a Gaussian-weighted matrix, thereby eliminating the reliance on attention weights for feature utilization. The weights undergo attenuation based on the proximity of tokens, with the degree of attenuation being defined by the Gaussian variance. This variance is acquired through the training process. The proposed method has the capability to comprehensively and precisely capture the temporal dependencies on a worldwide scale inside electricity consumption data. Consequently, this approach has the potential to enhance the effectiveness of power theft detection to a greater extent.
The module comprises two blocks of multi-head self-attention mechanism (MSA), as depicted in
Figure 1. The residual operation is iterated by using the input channels as the heads of the first MSA, and mapping the output of the first MSA to the second MSA as the input heads of the second MSA, with the same dimensions for
and
. The matrix dimensions of the input and output features are shown in
Figure 6. To encompass the global relationship, the multi-head attention mechanism incorporates three learnable weight matrices, namely,
,
, and
. The
th self-attention (SA) is chosen using the three learnable weight matrices mentioned above. It is then linearly normalized to obtain Scaled Dot-Product Attention, as depicted in
Figure 7. This section introduces the concept of Gaussian-weighted self-attention, which allows for the utilization of varying weights based on the proximity of tokens. This feature enhances the accuracy of the findings obtained.
The formula for the SA mechanism is as follows:
where
is the dimension of
.
The diagram illustrating the internal architecture of Gaussian-weighted self-attention is depicted in
Figure 8. In this context,
represents the size of the batch,
T defines the length of the sequence,
marks the dimension of the input, and
relates to the number of units in the self-attention mechanism. The matrices for the query, key, and value are defined in the following manner:
where
is the input to the
th hidden layer (
= 0, 1, 2).
,
, and
are network parameters. The score matrix in our proposed method is scaled by utilizing a Gaussian weighting matrix. This matrix is computed through the multiplication of key and query matrices, as described below:
is the Gaussian weight matrix.
Within the MSA block, a series of weight matrices in variables
,
, and
are subjected to the same operating technique. This results in the calculation of multiple head-attention values. Afterwards, the outcomes of each individual head attention are combined. The mathematical representation of this process can be expressed by the following equation:
where
represents the number of heads.
Ultimately, the characteristics acquired within the transformer are afterward inputted into the classifier for the purpose of categorization. This classifier comprises two fully linked layers, with the Sigmoid activation function being employed for the output of the final layer. The function maps the output values within the range of 0 and 1. Individuals with a value equal to or beyond a threshold of 0.5 are classified as engaging in electro-pilfering, whilst individuals falling below this threshold are categorized as regular users.
2.5. Overall Algorithm Steps
The overall process of the proposed DSDBGWT is shown in Algorithm 1.
| Algorithm 1 DSDBGWT Model |
| Input: Input a dataset ; patch size s1 = 7; patch size s2 = 28; training sample rate = 80%. |
| Output: Normal and abnormal prediction of test sets |
| 1: Set batch size to 100, optimizer Adam (learning rate: 10−4), epochs number e to 80. |
| 2: Perform patch1 in the , available to and divide them into training dataset and test dataset. |
| 3: Generate training loader and test loader. |
| 4: for = 1 to e do |
| 5: Perform DSDB convolution layer. |
| 6: Perform patch 2 to change . |
| 7: Perform a transformer network using Gaussian weighting. |
| 8: Spread the transformer output to pass into the classifier. |
| 9: Use the sigmoid function to identify the labels. |
| 10: end for |
| 11: Use test dataset with the trained model to get predicted labels. |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}