1. Introduction
Fire disasters are one of the most common and dangerous types of disasters, characterized by a low predictability and rapid spread. Once a fire disaster occurs, it can cause significant property damage, disrupt the ecological balance, and even endanger lives. Rapid and accurate detection and identification in the early stages of a fire disaster are crucial for fire safety and prevention. Traditional fire detection methods mainly rely on smoke detectors, heat detectors, infrared detectors, and other devices [
1]. These detectors are widely used due to their low cost and ease of use. However, smoke detectors and heat detectors are limited to small enclosed spaces, and smoke detectors are prone to false alarms in areas with a high dust concentration. Infrared detectors are mainly used in large open spaces, but they cannot determine the type of high-temperature objects and can be affected by high-temperature equipment, leading to false alarms. With the rapid development of computer vision and the widespread use of cameras in the field of security, flame detection based on image/video surveillance has emerged as a new approach to fire detection [
2,
3]. Compared to traditional detectors, image/video-based flame detection techniques offer advantages such as a fast detection speed, strong applicability, and the ability to quantify flame position and size.
Traditional flame image-processing techniques typically rely on factors such as color, texture, and gradients of the flames in the image [
4,
5] for feature design. They may also employ clustering methods [
6] to extract features from the target regions and utilize classifiers such as Support Vector Machines [
7], differential methods [
8], or XGBoost classifiers [
9] for flame classification and recognition. However, these detection methods are highly susceptible to the influence of external environmental factors, leading to a significant number of false positives and false negatives.
In recent years, object detection methods based on deep learning have rapidly advanced, showing significant improvements in detection accuracy and efficiency compared to traditional image-processing methods. Among the various object detection methods, there are two main categories: two-stage detection methods, primarily based on R-CNN series networks, and single-stage detection methods, primarily based on the YOLO series, RetinaNet, and SSD, etc. Two-stage detection methods first propose candidate bounding boxes and then classify them, offering advantages in terms of accuracy and localization precision. Single-stage detection methods directly predict the bounding boxes of objects in an image, providing simpler structures and faster speeds. CHAO et al. [
10] proposed a global information-guided flame detection method using Faster R-CNN, but it had a large number of parameters and slow detection speed. ZHAO et al. [
11] proposed the Fire-YOLO model based on YOLOv3, which achieved better results but still had room for improvement in terms of accuracy. JIANG et al. [
12] utilized the RetinaNet model for flame detection but encountered issues of sparse flame omissions. LU et al. [
13] presented the SSD_MobileNet model by modifying the VGG16 network in the classic SSD and incorporating depth-wise separable convolutions, which reduced flame omissions but still resulted in a significant number of false positives.
The lightweight single-stage object detection network is known for its flexibility, speed, and ease of use, and it is widely used in current object detection algorithms. However, directly applying it to flame detection tasks does not yield satisfactory results. This is because flame objects, unlike general rigid objects, often exhibit irregular shapes, diverse textures and edges, and imbalances in positive and negative samples and in easy and hard samples. In our previous experiments using the popular YOLOv5s network on images and videos containing flame objects, the flame recognition rate was found to be low, with many instances of missed real flames and false positives for flame-likes, making it unsuitable for practical surveillance systems.
Therefore, to address these challenges and improve the accuracy of flame detection in video surveillance scenarios, we propose a real-time flame detection method based on deformable object detection and time sequence analysis. Firstly, to better extract flame features, we introduce an improved deformable convolutional network (DCN) [
14,
15] that can handle the irregular and diverse shapes of flame objects. Secondly, to tackle the issue in flame detection of imbalances in positive and negative samples and in easy and hard samples, we improve the loss functions by employing Focal Loss [
16] as the classification loss function to alleviate the problem of sample imbalance. Additionally, we utilize EIOU Loss [
17] as the regression loss function to address the slow convergence speed of GIOU Loss [
18] and enhance the detection performance. Lastly, considering the temporal characteristics of surveillance videos, we adopt a time sequence analysis strategy to mitigate the effects of flame disturbance deformation, occlusion, and false alarms caused by suspected flame objects in a single frame, thus reducing false positives. The experimental results demonstrate that the proposed method not only improves the accuracy and recall rate of flame detection, but also achieves a real-time detection speed, which is beneficial for fire prevention.
2. Methods
In the context of video surveillance, the primary task of flame detection is to continuously monitor the video information captured by cameras in a surveillance scene and make reasonable judgments about the presence of flame objects in that scene. When a real flame object is detected, it promptly sends out an alarm notification.
The task of flame object detection differs from usual rigid object detection tasks due to challenges such as variations in flame object shapes, imbalances in positive and negative samples and in easy and hard samples, occlusion by foreign objects, and confusion with potential flame-like objects. Therefore, it is very crucial to accurately detect flame objects in individual frames of surveillance videos. Additionally, the effective use of time sequence analysis strategies to comprehensively analyze detection results across video frame sequences can help to determine the presence of real fire objects in the current surveillance scene, thereby reducing false alarm rates.
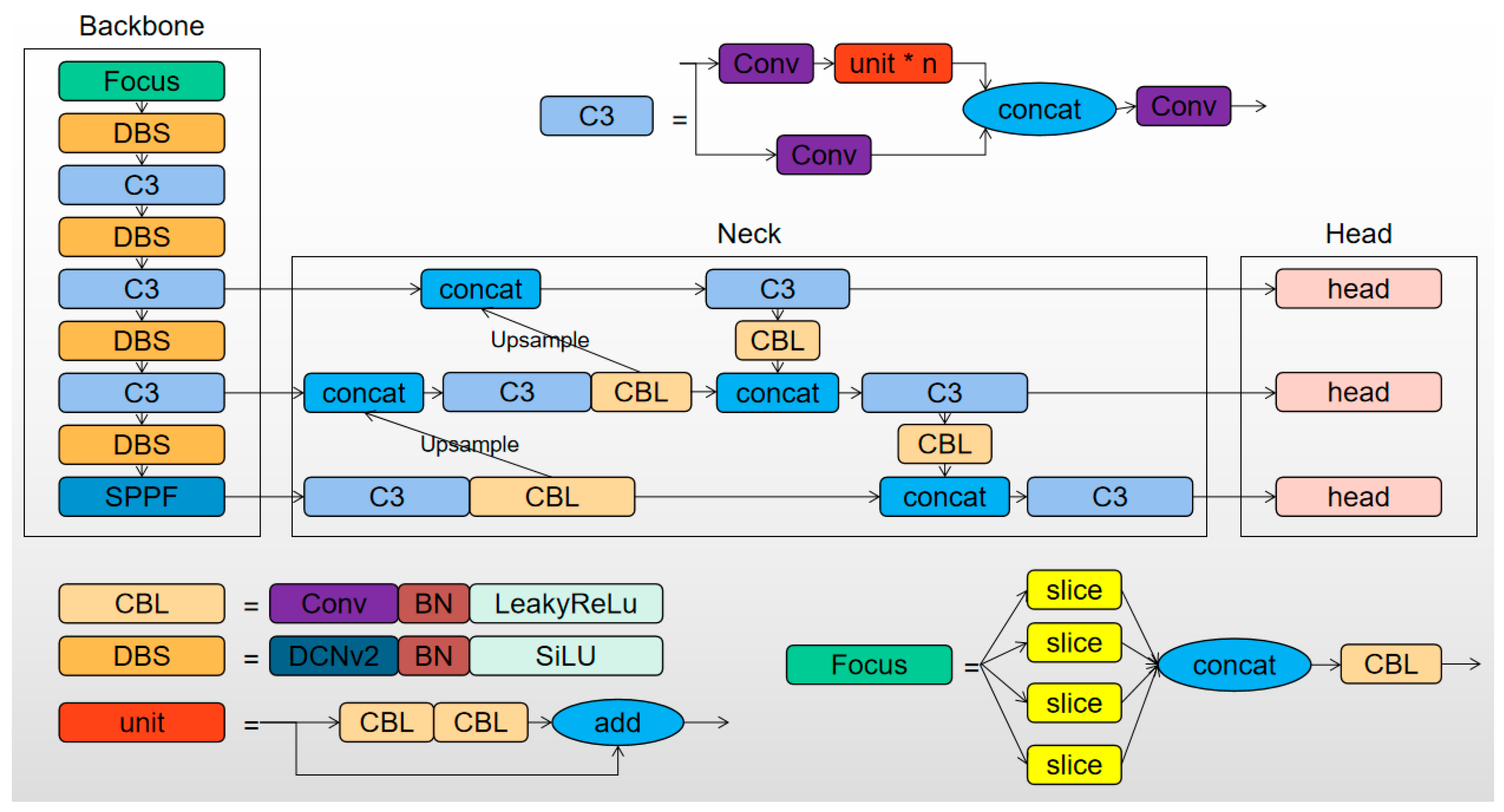
The workflow of the proposed flame detection method in this paper is illustrated in
Figure 1. An improved flame object detection network, namely Flame-YOLOv5s, processes each frame of the surveillance video to obtain a time sequence of the detection results. Then, based on our designed time sequence analysis strategy, it comprehensively analyzes the flame detection results, including that of the current frame, to determine the presence of real flame objects in the current moment of the surveillance scene. The two key aspects of this method are the improvement strategies of the flame object detection network Flame-YOLOv5s and the time sequence analysis strategy for video frames, which will be explained in detail below.
2.1. Network for Flame Object Detection
In the context of flame object detection in surveillance videos, the key step is to determine whether there is a real flame object in each frame of the video. Generally, existing object detection networks can be used for this purpose. However, considering the real-time requirements of video surveillance, we focus on improving a lightweight single-stage object detection network. In the commonly used Convolutional Neural Network (CNN) structure, the convolutional kernels typically sample the input feature maps at fixed positions and the pooling layers gradually reduce the feature map size. The ROI pooling layer generates spatially constrained regions of interest (ROI). However, these approaches cause some issues. For example, the fixed weights of the convolutional kernels result in the same receptive field size when processing the different regions of an image, which is unreasonable for deep convolutional neural networks that encode positional information. Different positions may correspond to objects with different scales or deformations, requiring methods that can automatically adjust the scale or receptive field. Another issue is that the effectiveness of object detection heavily relies on feature-based bounding boxes, which is not optimal, especially for non-grid objects.
Due to the irregularity and diversity of flame shapes, ordinary convolutions have a limited adaptability to extract flame features. To more effectively extract flame features, Deformable Convolution (DCN) [
14] is introduced in our method to improve the backbone network of the object detection network.
By introducing learnable offsets to the convolutional kernel, DCN aims to concentrate the feature points in the regions of interest, thereby enhancing the modeling capability for unknown shape transformations, which can be expressed in the following formula:
In the given formula, and are the input feature map and the output feature map, respectively, and denotes an arbitrary location on a feature map. K is the number of samples for a given convolutional kernel. The weight and pre-defined offset for the k-th position are denoted as and pk respectively, and denotes the offset that is to be learned for the k-th position.
DCNv2 [
15] further introduces an adjustment mechanism to alleviate the issues caused by either too small or too large offsets, which can result in sample points being unrelated to the object. Through this adjustment mechanism, it can adjust not only the offset of the sample points, but also the weights of the sample points. This can be expressed in the following formula:
In the given formula, denotes the learnable adjustment scalar for the k-th position, which ranges between 0 and 1.
In this paper, we aim to improve the YOLOv5s object detection network for a better suitability to flame detection tasks. The modified network is referred to as Flame-YOLOv5s. In the original YOLOv5s network, there are four CBL structures in the backbone, which stands for the structure of “CNN + BN + LeakyReLu”. In this paper, the standard convolutional layers (CNN) within these structures are replaced with improved deformable convolutions (DCNv2), and the original LeakyReLu activation function is replaced with the SiLU activation function. This results in the formation of the DBS structure, which stands for the structure of “DCNv2 + BN + SiLU”. The SiLU function has a smoother curve near zero than the LeakyReLu function, and its output ranges between 0 and 1 because it uses the sigmoid function, which makes SiLU perform better than LeakyReLu.
Therefore, the overall architecture of the Flame-YOLOv5s network is shown in
Figure 2, consisting of three components: the backbone, neck, and head. The backbone is used for extracting object features, which consists of the Focus, DBS, C3, and SPPF structures. The neck component adopts the “FPN + PAN” structure, which is primarily used for enhancing the extracted features. The head component utilizes three detection heads that perform downsampling 8, 16, and 32 times on the original image to generate feature vectors of different sizes, which is used for detecting objects of different scales.
2.2. Loss Functions
In the task of flame detection, the total loss of model training consists of two parts: classification loss and regression loss.
When using single-stage object detection algorithms like YOLOv5s to detect flame objects from input images, a large number of anchor boxes are generated to locate the flames. However, even if a real flame object (positive sample) is present in an image, its area or quantity is relatively small compared to the background (negative sample), because there are a large number of anchor boxes located in the background region. This leads to a severe imbalance between positive and negative samples.
In contrast, two-stage object detection methods such as R-CNN only generate candidate boxes in the first stage using the Region Proposal Network (RPN). These methods simply distinguish between the background and the foreground without distinguishing specific classes, thereby filtering out a significant portion of anchor boxes belonging to the background. While this approach alleviates the sample imbalance problem to some extent, it does not fully address the issue. In the second stage, heuristic sampling or OHEM (Online Hard Example Mining) is often employed to further alleviate the sample imbalance problem. On the other hand, single-stage methods sacrifice the generation of candidate boxes to improve detection speed, directly performing more challenging fine-grained classification on anchor boxes, which lacks a filtering process for the anchor boxes.
In flame detection task, the imbalance between positive and negative samples makes flame localization and classification more challenging. At the same time, some ambiguous flame-like regions may exhibit low discriminative features, making them be the hard samples. To address these issues and train the improved Flame-YOLOv5s network for flame detection, we adopt Focal Loss as the classification loss function. By focusing on the difficulty of classification, the Focal Loss assigns more importance to hard examples, thereby mitigating the imbalance between flame and background samples and improving the overall performance of the model.
Focal Loss is defined as an extension of the
BCE (Binary Cross-Entropy) loss function
that introduces a modulation factor to reduce the weight of easily classified samples and focus on training hard samples. Mathematically, the Focal Loss can be defined as follows:
Parameter is a sample weight factor used to balance positive and negative samples, parameter serves as an adjustable focusing parameter, and parameter reflects the proximity to the class. As observed, Focal Loss not only addresses the issue of imbalance between positive and negative samples, but also tackles the problem of imbalance between easy and hard samples. Therefore, Focal Loss is well-suited for flame object detection tasks, as it effectively handles both types of sample imbalance.
In addition, the original YOLOv5s network utilized the GIOU (Generalized Intersection over Union) Loss function for regression, which addresses the gradient issue arising from non-overlapping predicted and ground truth boxes. GIOU inherits all the advantages of IOU but still has drawbacks such as slow convergence and imprecise regression due to its excessive reliance on the intersection over union ratio. To enhance the convergence speed, improve the flame recognition accuracy, and achieve more precise localization in the flame detection model, we adopt the EIOU (Efficient Intersection over Union) Loss [
16] for calculating the regression loss of the bounding boxes. The EIOU Loss aims to address the limitations of the GIOU Loss, leading to faster convergence and more accurate regression in flame detection.
EIOU takes into account the overlapping region of box regression, the distance between the center points, and the aspect ratio, achieving fast convergence. The EIOU Loss can be represented as follows:
In above equation,
represent the Euclidean distance between the center points of the predicted box and the ground truth box,
represents the squared difference in width, and
represents the squared difference in height. On the other hand,
,
, and
represent the width, height, and diagonal distance of the minimum enclosing region of the predicted box and the ground truth box, respectively. The parameter information of EIOU is depicted in
Figure 3.
2.3. Time Sequence Analysis Strategy
When dealing with the flame video, we process every image frame using the proposed Flame-YOLOv5s network. Despite the improved performance obtained due to the modification of the object detection network, it is inevitable to encounter the missed detection of flame objects due to flame disturbance deformation or partial occlusion. There may also be false detections of flame objects caused by occasional high confidence in flame-like objects. However, it has been observed through experiments that such missed detections and false detections occur with a low frequency or for short durations. Therefore, leveraging the temporal characteristics of video data, a time sequence analysis strategy can be employed to eliminate the impact of these missed detections and false detections on the final determination of the presence of flame objects.
In this paper, a time sequence is designed by incorporating temporal information from the preceding and subsequent frames of a video. The queue has a window size of K and is used to store the detection results of the current frame and the preceding K-1 frames. The detection results are represented by T (indicating the presence of flame in the frame) or F (indicating the absence of flame in the frame). The time sequence is illustrated in
Figure 4.
The employed strategies for analyzing temporal information are as follows:
- (1)
Continuous Counting Strategy: If the number of consecutive frames with detected flame objects in the time sequence exceeds a specified threshold, it is considered that a real flame exists in the monitored video and an alarm signal is triggered.
- (2)
Cumulative Counting Strategy: When the time sequence is full, the number of frames with detected flame objects is counted, represented as n. If the percentage of frames with detected flame objects exceeds a specified threshold , it is considered that a real flame exists in the monitored video and an alarm signal is triggered.
- (3)
Alarm Termination Strategy: Both of the above strategies are applied simultaneously. When either of them are satisfied, an alarm is triggered. If the time sequence is full and the percentage of frames with detected flame objects is less than a specified threshold , it is considered that the alarm has ended and the system will wait for the next alarm trigger.
3. Experiments and Results
The experimental environment in this study consisted of a Windows 10 operating system and an NVIDIA GeForce RTX 3080 GPU. All the experiments were implemented using the deep learning framework PyTorch. The main parameters for the model training were set as follows: epoch = 80, batch-size = 12, optimizer = SGD, initial learning rate (lr) = 0.01, and momentum = 0.937.
3.1. Dataset
Datasets play a crucial role in testing the performance of an algorithm model. However, currently, there is a scarcity of publicly available and well-annotated flame datasets. To address this issue and construct a large-scale dataset with abundant flame samples, we collected flame images from various sources. Additionally, images with flame-like objects were also collected as negative samples to reduce the false alarm rate of the model. By incorporating a diverse range of flame and non-flame images, the aim was to enhance the generalization capability of our model.
The main sources of the dataset include the BoWFire dataset [
19], KMU Fire dataset [
20], and a custom-made dataset. The custom-made dataset consists of various types of fire videos, including firefighting experiments, natural fire incidents, fire images from the Internet, and artificially created fire videos. For the video data, images are saved every 15 frames. The final flame dataset contains a total of 9742 images, including 8149 flame images and 1593 non-flame images. The dataset covers different scenes such as indoors, outdoors, buildings, forests, highways, and factories, under different weather and lighting conditions. Because the images are collected from different sources, the original resolutions are also very different, varying from small sizes such as 110 × 185 and 200 × 150, etc., to large sizes such as 1920 × 1080 and 6000 × 4000, etc., which are all resized into 640 × 640 during training. Some samples from the dataset are shown in
Figure 5. The LabelImg annotation tool was used to annotate each image in the collected dataset.
3.2. Evaluation Methods
To evaluate the performance of the proposed method, we use the following evaluation metrics: precision (P), recall (R), F-measure (FM), average precision (AP), and frame rate (FR). Precision measures the ability of the model to correctly predict positive samples among all the predicted positive samples. Recall measures the ability of the model to correctly predict positive samples among all the actual positive samples. FM is the weighted harmonic mean of Precision and Recall. AP represents the area under the Precision–Recall curve, reflecting the model’s ability to make correct judgments. FR reflects the inference speed of the model. AP and FM are comprehensive performance indicators, and a higher value indicates better model performance. The definitions of P, R, and FM are as follows:
where TP represents true positives (the number of samples correctly predicted as positive), FP represents false positives (the number of samples incorrectly predicted as positive), and FN represents false negatives (the number of samples incorrectly predicted as negative). AP is the average precision calculated based on the model’s prediction results. FR is the frame rate, which reflects the inference speed of the model.
3.3. Ablation Experiments
To demonstrate the rationality and effectiveness of the proposed improvements, a series of ablation experiments were conducted on our dataset. The YOLOv5s network was used as the baseline model, and three different modifications were introduced: the DBS module, Focal Loss, and EIOU Loss. The results of the experiments are shown in
Table 1. For each evaluation metric, the best result is marked in bold.
According to the result data in the table, it can be observed that, by improving the network structure in the YOLOv5s model with the introduction of the DBS module, the precision (P) of flame detection obtained an increase of 2.6%. After incorporating Focal Loss and EIOU Loss, the precision (P) further had an improvement of 5.1%. Ultimately, the proposed method achieved a 6.2% increase in precision (P) for flame detection. Generally, an increase in precision (P) may result in a slight decrease in recall (R). In such cases, it is important to focus on comprehensive performance metrics such as F-measure (FM) and average precision (AP). It can be observed that, under the corresponding improvement strategies, FM achieved improvements of 0.3%, 2.2%, and 3%, and AP obtained increases of 0.4%, 1.2%, and 1.7%, respectively.
The results indicate that the proposed method, which combines the characteristics of flame objects with the improvements made to the YOLOv5s network, is effective in enhancing the flame detection performance.
3.4. Method Comparison Experiments
In order to further demonstrate the superiority of the proposed method, several representative object detection network models were selected for comparative experiments. The compared models include RetinaNet, SSD_MobileNet, Faster RCNN, YOLOv5s, YOLOv7-tiny, YOLOv8-n, and YOLOv8-s. Except for Faster RCNN, which is a two-stage object detection network, the rest are lightweight, single-stage object detection networks.
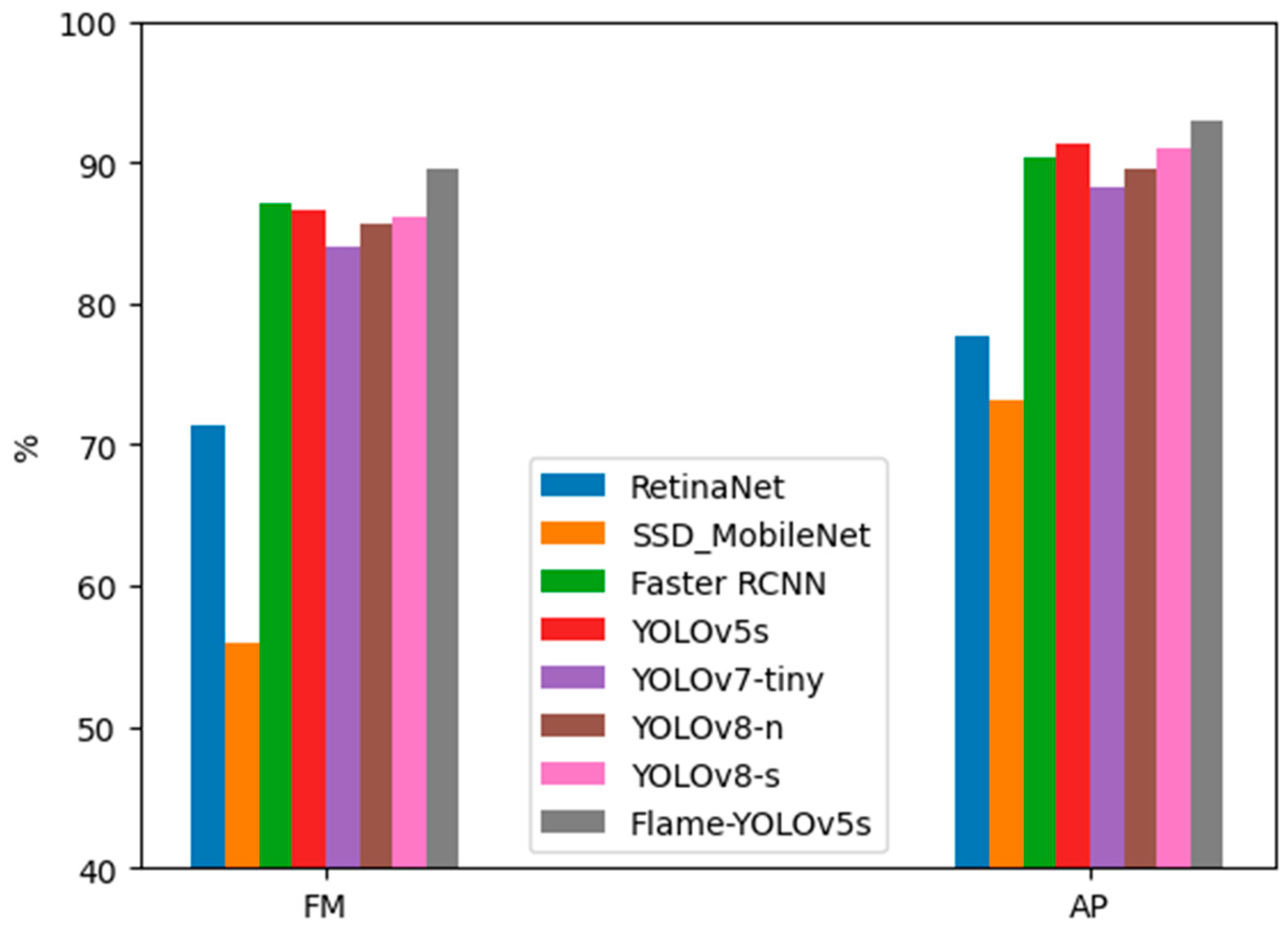
The experimental results are shown in
Table 2, where the best result is marked in bold and the listed frame rate (FR) represents the range of the inference speed on the test dataset images. The corresponding bar charts of FM and AP are also depicted in
Figure 6.
From
Table 2 and
Figure 6, it can be observed that Faster RCNN, which has the advantages of a two-stage object detection network, indeed performs better than lightweight single-stage object detection networks like RetinaNet, SSD_MobileNet, YOLOv7-tiny, YOLOv8-n, and YOLOv8-s. However, due to its non-lightweight design, it has a relatively lower detection speed of only 13–17 FPS. YOLOv5s shows a comparable performance to Faster RCNN while achieving a higher detection speed of 25–27 FPS. Flame-YOLOv5s, which is our proposed method in this paper, achieves the highest precision (P) among all the models, with a recall rate (R) slightly lower than that of the original YOLOv5s. However, it outperforms the other models in terms of the comprehensive evaluation metrics FM and AP, achieving the best overall performance. Its detection speed is also capable of reaching 24–26 FPS, meeting the requirements for real-time detection.
3.5. Example Demonstrating the Effectiveness of Flame Detection
To visualize the detection performance of the Flame-YOLOv5s network on flame objects and flame-like objects, we selected a subset of representative test images from the dataset. These images depict various real-world scenarios, including indoor and outdoor scenes, flame objects of different scales, and some flame-like objects. The detection results are shown in
Figure 7, where the detected flame objects are highlighted with rectangular bounding boxes. It is evident that Flame-YOLOv5s successfully detects flame objects of various scales in the different scenes depicted in rows 1 and 2 of
Figure 7a–f. In particular, small-sized ignited candles can be observed in
Figure 7a,d. Regarding the unignited red candle in
Figure 7d, the red scarf, the illuminated light bulb, and the sunset and clouds that resemble flame-like objects in row 3 (
Figure 7g–i), Flame-YOLOv5s does not mistakenly classify them as flames. This demonstrates that Flame-YOLOv5s exhibits a good robustness against strong distractions of this nature.
In addition,
Figure 8 shows the comparison results of the proposed method with the ground truth and other typical lightweight YOLO-based methods, including YOLOv5s, YOLOv7-tiny, and YOLOv8-s. In row 1, only YOLOv7-tiny and Flame-YOLOv5s detect the small flame object; in row 2, only Flame-YOLOv5s obtains the right result, YOLOv7-tiny has a mistaken result, and the other two methods cannot detect the flame; and in row 3, YOLOv5s and YOLOv7-tiny classify the two firefighters in red uniform as flames mistakenly, and YOLOv8-s and Flame-YOLOv5s detect the flames accurately.
Although an improved performance was obtained by Flame-YOLOv5s, it is inevitable that there are some false detection and missed detection results. Some examples are shown in
Figure 9. In
Figure 9a, the false detection of flame objects may be caused by occasional high confidence in flame-like objects such as electric lamps or clouds with a very similar shape and color to a flame. In
Figure 9b, the missed detection of flame objects may occur due to flame disturbance deformation or partial occlusion. To deal with these limitations of Flame-YOLOv5s in single-frame detection mode, we use the time sequence analysis strategy to alleviate the false alarms in the video detection mode from the practical application point of view.
3.6. The Impact of Time Sequence Analysis Strategy on Video Flame Detection
To demonstrate the effectiveness of the time sequence analysis strategy, an experimental study was conducted using 40 flame videos and 10 flame-like videos. The experimental results are presented in
Table 3. In the table, “Continuous Detection” indicates the absence of the time sequence analysis strategy, where the alarm is triggered when a frame with a flame object is detected in the video. The alarm continues as long as subsequent frames with flame objects are detected, and it ends when no flame object is detected in a frame, counting as one alarm and waiting for the next alarm. The number of alarms using the time sequence analysis strategy is determined and indicated in the table based on the method described in
Section 2.3 with the parameter setting
.
According to the data analysis from
Table 3, it can be observed that, after employing the time sequence analysis strategy, the short-term disturbances caused by flame perturbation, flowing occlusions, and interference caused by flame-like objects do not affect the continuous alarms. Throughout the experimental testing process, the frequency of alarms decreases, while the duration of each alarm increases.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}