

Electrocardiogram-Based Biometric Identification Using Mixed Feature Extraction and Sparse Representation

Abstract
:1. Introduction
- This study aims to decompose signals in terms of their frequencies, and extract frequency components which exhibit significant feature differences for recognition purposes. The ECG signal features obtained through this recognition method are not specific feature components, but rather a larger and unique set of ECG components in the signals. Although this set cannot represent the entire ECG signals, it covers the most distinct portion. Subsequently, this paper utilizes the KSVD algorithm for sparse processing. This approach overcomes the limitations of the previous methods and generates matrices which have no specific meaning but have significant specificity.
- This study researches sparse matrices and develops a recognition algorithm suitable for this study. This study collected a large number of feature matrices and constructed a matrix set specifically for ECG signals. Within these matrices, we performed mathematical operations on the feature components which are in the same position, and the final result was represented as the distance. We compared the signals that need to be identified with the matrices in the set to obtain a new set that includes various distance values. By assigning different weights to different distances and performing corresponding calculations, we obtained the eigenvalues. Finally, we were able to determine the recognition results by analyzing the relationship between the threshold and feature values.
2. Related Work
2.1. Database
2.2. Wavelet Transform
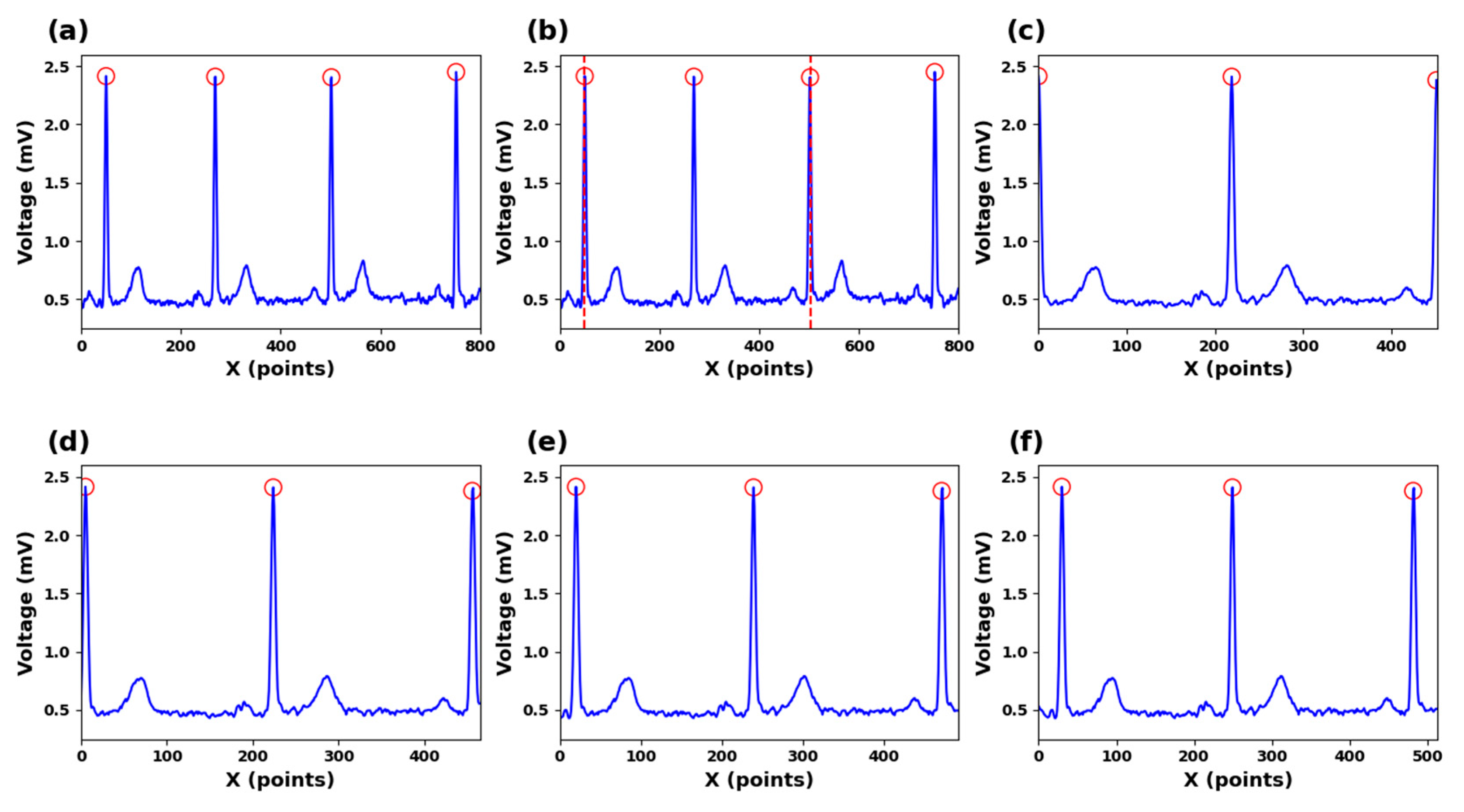
2.3. R-Peak Detection
2.4. Sparse Representation
3. Methodology of the Proposed Work Methods
3.1. Data Preprocessing
3.2. Feature Extraction
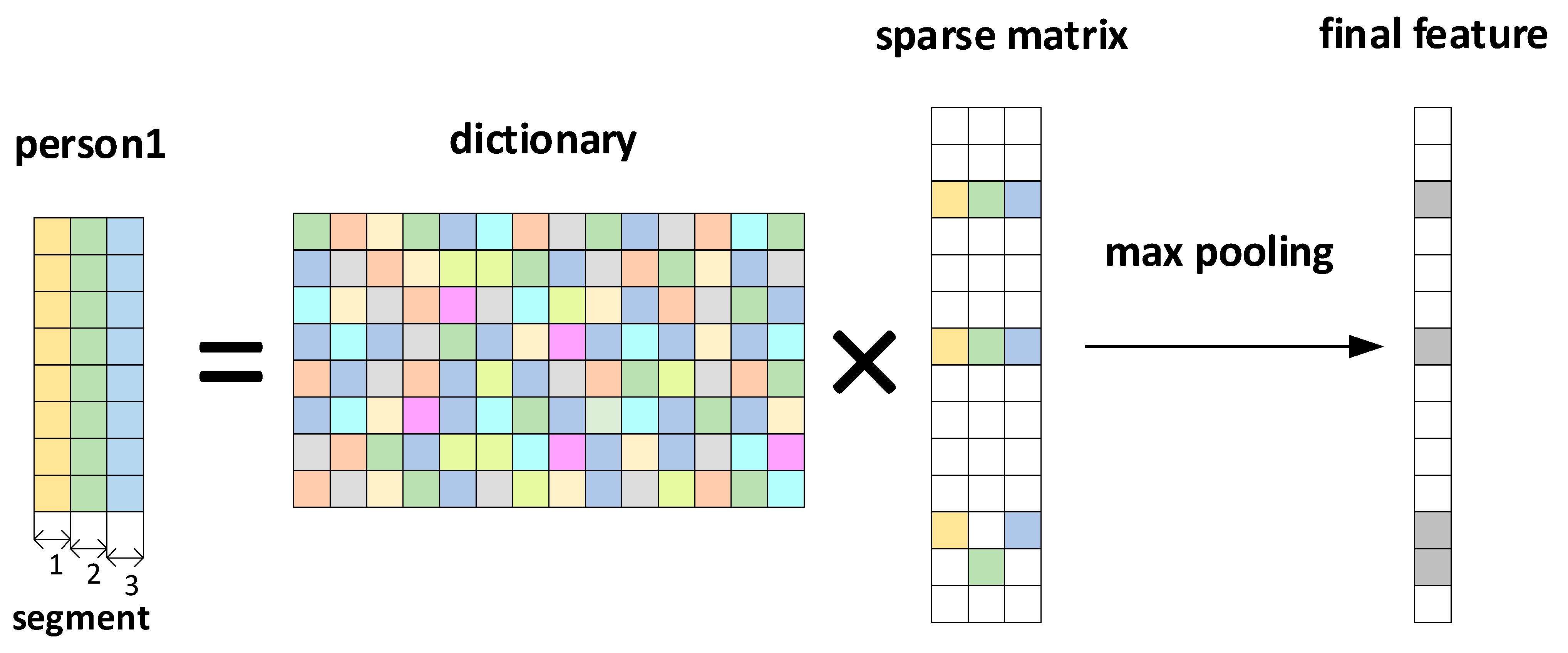
3.3. Sparse Dictionary
3.4. Classification
4. Discussion
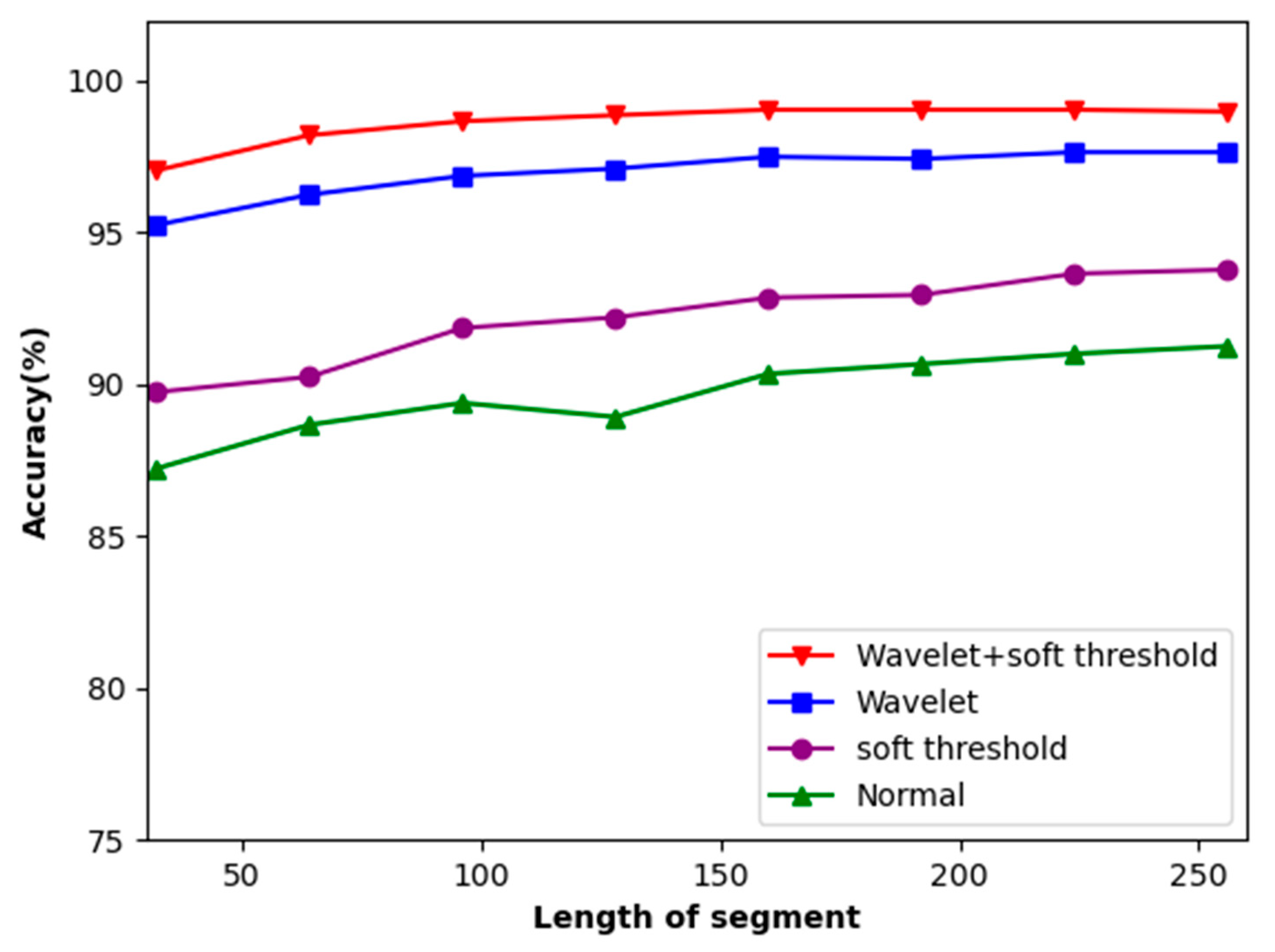
4.1. The Impact of Extraction Methods on Accuracy
4.2. The Influence of ECG Signal Length and Denoising on Accuracy
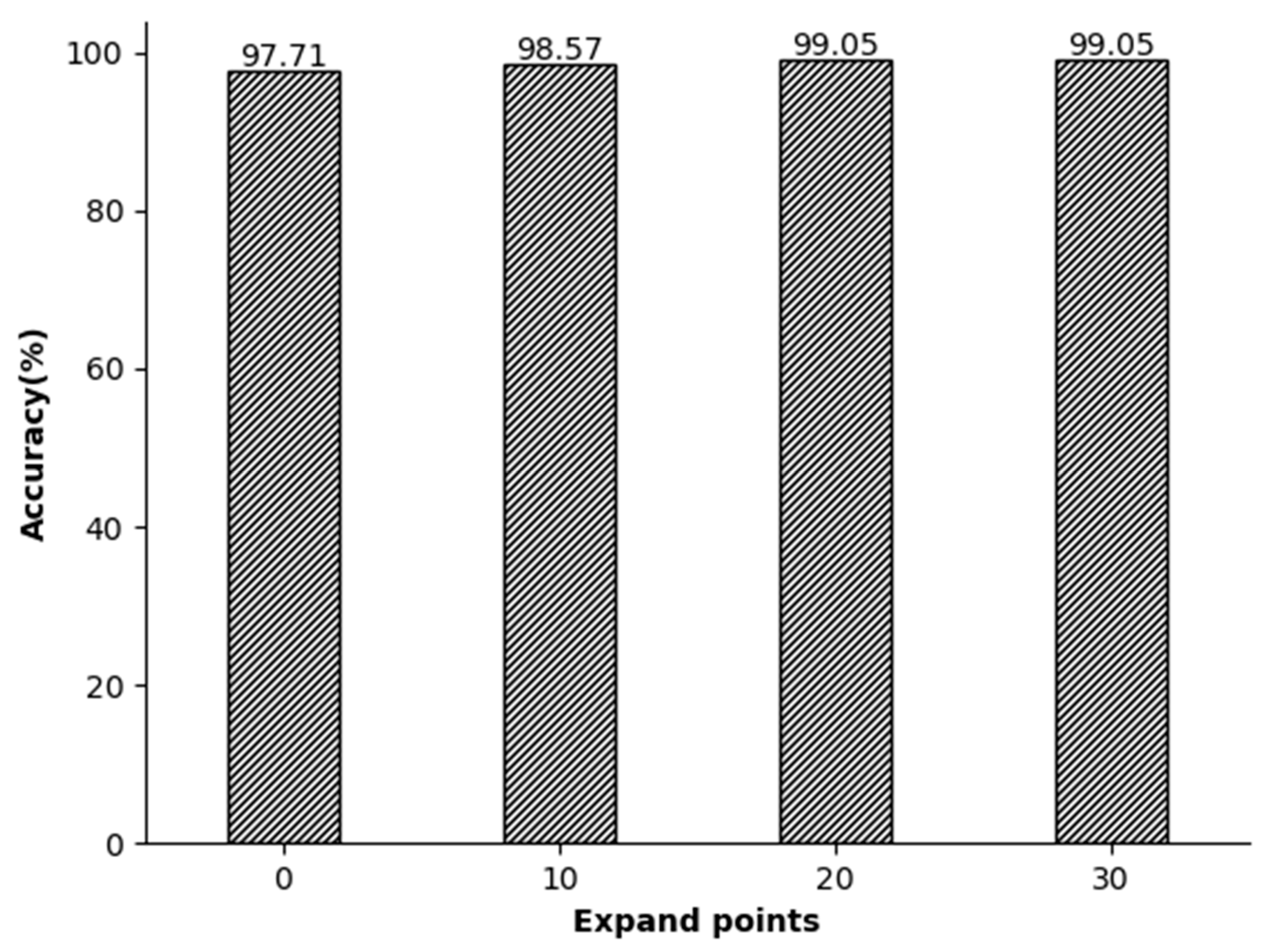
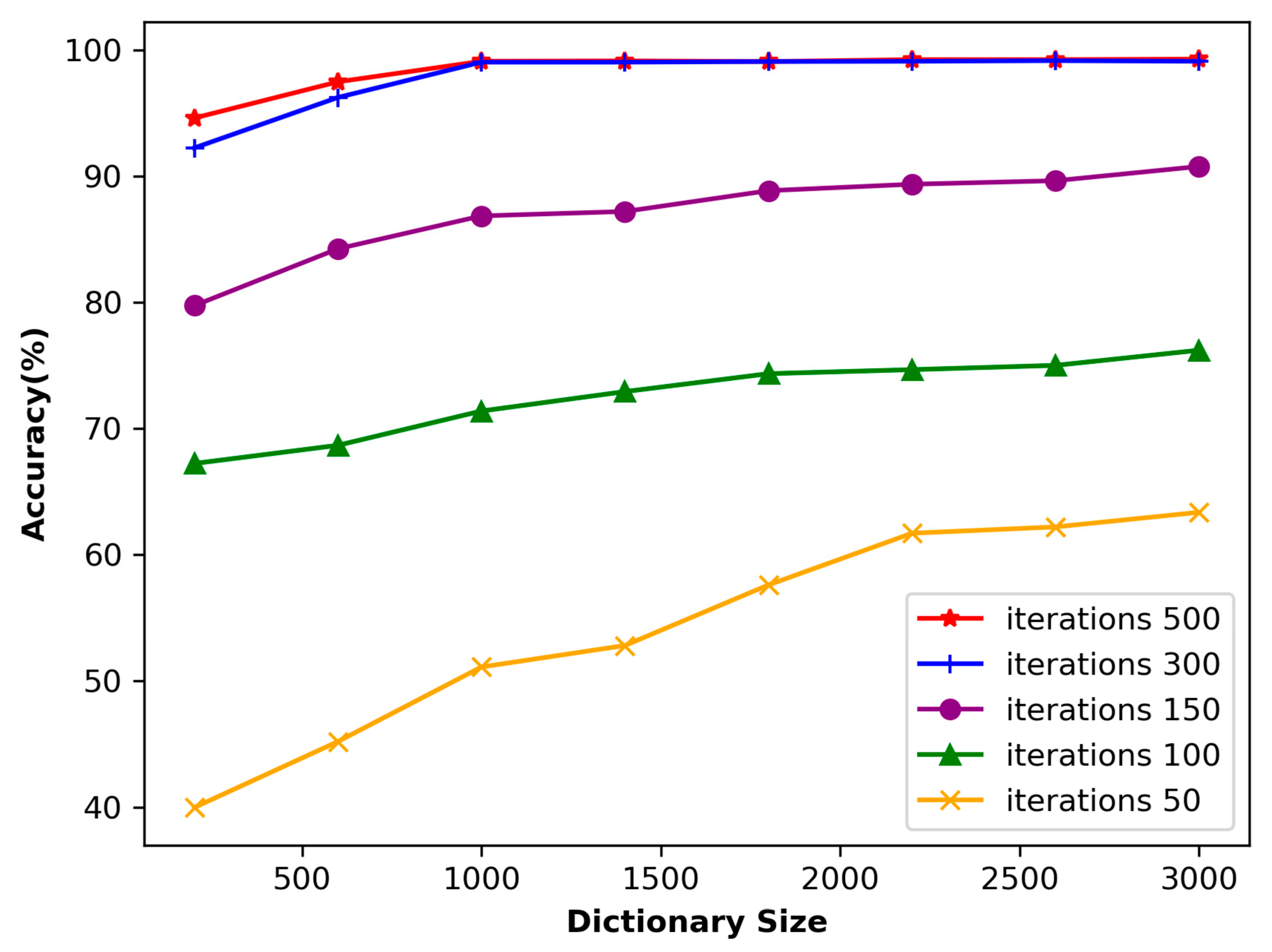
4.3. The Impact of Dictionary Length and Number of Iterations on Accuracy
4.4. Comparison with Other Articles
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benouis, M.; Mostefai, L.; Costen, N.; Regouid, M. ECG based biometric identification using one-dimensional local difference pattern. Biomed. Signal Process. Control 2021, 64, 102226. [Google Scholar] [CrossRef]
- Biel, L.; Pettersson, O.; Philipson, L.; Wide, P. ECG analysis: A new approach in human identification. IEEE Trans. Instrum. Meas. 2001, 50, 808–812. [Google Scholar] [CrossRef]
- Uwaechia, A.N.; Ramli, D.A. A Comprehensive Survey on ECG Signals as New Biometric Modality for Human Authentication: Recent Advances and Future Challenges. IEEE Access 2021, 9, 97760–97802. [Google Scholar] [CrossRef]
- Berkaya, S.K.; Uysal, A.K.; Gunal, E.S.; Ergin, S.; Gunal, S.; Gulmezoglu, M.B. A survey on ECG analysis. Biomed. Signal Process. Control 2018, 43, 216–235. [Google Scholar] [CrossRef]
- Melzi, P.; Tolosana, R.; Vera-Rodriguez, R. ECG Biometric Recognition: Review, System Proposal, and Benchmark Evaluation. IEEE Access 2023, 11, 15555–15566. [Google Scholar] [CrossRef]
- Ali, M.M.; Yannawar, P.; Gaikwad, A. Study of edge detection methods based on palmprint lines. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016. [Google Scholar]
- Phukpattaranont, P. QRS detection algorithm based on the quadratic filter. Expert Syst. Appl. 2015, 42, 4867–4877. [Google Scholar] [CrossRef]
- Silva, H.; Gamboa, H.; Fred, A. Applicability of lead v2 ECG measurements in biometrics. Med-E-Tel Proc. 2007. Available online: http://www.lx.it.pt/~afred/papers/AFred_HSilva_Med-e-Tel_07.pdf (accessed on 8 October 2007).
- Pal, A.; Singh, Y.N. ECG Biometric Recognition. In Mathematics and Computing; Springer: Singapore, 2018; pp. 61–73. [Google Scholar]
- Patro, K.K.; Kumar, P.R. AMachine Learning Classification Approaches for Biometric Recognition System using ECG Signals. J. Eng. Sci. Technol. Rev. 2017, 10, 1–8. [Google Scholar] [CrossRef]
- Gurkan, H.; Hanilci, A. ECG based biometric identification method using QRS images and convolutional neural network. Pamukkale Univ. J. Eng. Sci. 2020, 26, 318–327. [Google Scholar] [CrossRef]
- Choi, G.-H.; Bak, E.-S.; Pan, S.-B. User identification system using 2D resized spectrogram features of ECG. IEEE Access 2019, 7, 34862–34873. [Google Scholar] [CrossRef]
- Agrafioti, F.; Hatzinakos, D. ECG Based Recognition Using Second Order Statistics. In Proceedings of the 6th Annual Communication Networks and Services Research Conference (CNSR 2008), Halifax, NS, Canada, 5–8 May 2008; pp. 82–87. [Google Scholar]
- Plataniotis, K.N.; Hatzinakos, D.; Lee, J.K. ECG biometric recognition without fiducial detection. In Proceedings of the 2006 Biometrics Symposium: Special Session on Research at the Biometric Consortium Conference, Baltimore, MD, USA, 19 September–21 August 2006; pp. 1–6. [Google Scholar]
- Coutinho, D.P.; Fred, A.L.N.; Figueiredo, M.A.T. One-Lead ECG-based Personal Identification Using Ziv-Merhav Cross Parsing. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3858–3861. [Google Scholar]
- Alotaiby, T.N.; Alrshoud, S.R.; Alshebeili, S.A.; Aljafar, L.M. ECG-Based Subject Identification Using Statistical Features and Random Forest. J. Sens. 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Seena, V.; Yomas, J. A review on feature extraction and denoising of ECG signal using wavelet transform. In Proceedings of the 2014 2nd International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 6–8 March 2014. [Google Scholar]
- Mohanty, M.; Biswal, P.K.; Sabut, S.K. Feature Extraction of ECG signal for Detection of Ventricular Fibrillation. In Proceedings of the Proceedings 2015 International Conference on Man and Machine Interfacing (MAMI), Bhubaneswar, India, 17–19 December 2015. [Google Scholar]
- Kumar, A.; Tomar, H.; Mehla, V.K.; Komaragiri, R.; Kumar, M. Stationary wavelet transform based ECG signal denoising method. ISA Trans. 2021, 114, 251–262. [Google Scholar] [CrossRef] [PubMed]
- Al Alkeem, E.; Kim, S.-K.; Yeun, C.Y.; Zemerly, M.J.; Poon, K.F.; Gianini, G.; Yoo, P.D. An enhanced electrocardiogram biometric authentication system using machine learning. IEEE Access 2019, 7, 123069–123075. [Google Scholar] [CrossRef]
- Mumtaz, W.; Rasheed, S.; Irfan, A. Review of challenges associated with the EEG artifact removal methods. Biomed. Signal Process. Control 2021, 68, 102741. [Google Scholar] [CrossRef]
- Singh, B.; Singh, P.; Budhiraja, S. Various approaches to minimise noises in ECG signal: A survey. In Proceedings of the 2015 Fifth International Conference on Advanced Computing & Communication Technologies, Haryana, India, 21–22 February 2015. [Google Scholar]
- Sang, Y.-F. A review on the applications of wavelet transform in hydrology time series analysis. Atmos. Res. 2013, 122, 8–15. [Google Scholar] [CrossRef]
- Taddei, A.; Distante, G.; Emdin, M.; Pisani, P.; Moody, G.B.; Zeelenberg, C.; Marchesi, C. The European ST-T database: Standard for evaluating systems for the analysis of ST-T changes in ambulatory electrocardiography. Eur. Heart J. 1992, 13, 1164–1172. [Google Scholar] [CrossRef]
- Singh, B.N.; Tiwari, A.K. Optimal selection of wavelet basis function applied to ECG signal denoising. Digit. Signal Process. 2006, 16, 275–287. [Google Scholar] [CrossRef]
- Yadav, S.K.; Sinha, R.; Bora, P.K. Electrocardiogram signal denoising using non-local wavelet transform domain filtering. IET Signal Process. 2015, 9, 88–96. [Google Scholar] [CrossRef]
- Starck, J.L.; Fadili, J.; Murtagh, F. The undecimated wavelet decomposition and its reconstruction. IEEE Trans Image Process 2007, 16, 297–309. [Google Scholar] [CrossRef]
- Jambukia, S.H.; Dabhi, V.K.; Prajapati, H.B. Classification of ECG signals using machine learning techniques: A survey. In Proceedings of the 2015 International Conference on Advances in Computer Engineering and Applications, Ghaziabad, India, 19–20 March 2015; pp. 714–721. [Google Scholar]
- Maknickas, V.; Maknickas, A. Atrial Fibrillation Classification Using QRS Complex Features and LSTM. In Proceedings of the 2017 Computing in Cardiology Conference (CinC), Rennes, France, 24–27 September 2017. [Google Scholar]
- Zhang, Z.; Xu, Y.; Yang, J.; Li, X.; Zhang, D. A Survey of Sparse Representation: Algorithms and Applications. IEEE Access 2015, 3, 490–530. [Google Scholar] [CrossRef]
- Azimi-Sadjadi, M.R.; Kopacz, J.; Klausner, N. K-SVD dictionary learning using a fast OMP with applications. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Walsh, N.P.; Alba, B.M.; Bose, B.; Gross, C.A.; Sauer, R.T. OMP peptide signals initiate the envelope-stress response by activating DegS protease via relief of inhibition mediated by its PDZ domain. Cell 2003, 113, 61–71. [Google Scholar] [CrossRef]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993. [Google Scholar]
- Gacek, A.; Pedrycz, W. ECG Signal Processing, Classification and Interpretation: A Comprehensive Framework of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Wang, J.; She, M.; Nahavandi, S.; Kouzani, A. Human Identification from ECG Signals Via Sparse Representation of Local Segments. IEEE Signal Process. Lett. 2013, 20, 937–940. [Google Scholar] [CrossRef]
- Lee, W.; Kim, S.; Kim, D. Individual Biometric Identification Using Multi-Cycle Electrocardiographic Waveform Patterns. Sensors 2018, 18, 1005. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Si, W.; Huang, W. ECG-based identity recognition via deterministic learning. Biotechnol. Biotechnol. Equip. 2018, 32, 769–777. [Google Scholar] [CrossRef]
- Pelc, M.; Khoma, Y.; Khoma, V. ECG Signal as Robust and Reliable Biometric Marker: Datasets and Algorithms Comparison. Sensors 2019, 19, 2350. [Google Scholar] [CrossRef] [PubMed]
- Dar, M.N.; Akram, M.U.; Shaukat, A.; Khan, M.A. ECG Based Biometric Identification for Population with Normal and Cardiac Anomalies Using Hybrid HRV and DWT Features. In Proceedings of the 2015 5th International Conference on It Convergence and Security (Icitcs), Kuala Lumpur, Malaysia, 24–27 August 2015. [Google Scholar]
- Meltzer, D.; Luengo, D. Efficient Clustering-Based electrocardiographic biometric identification. Expert Syst. Appl. 2023, 219, 119609. [Google Scholar] [CrossRef]
- Kim, B.H.; Pyun, J.Y. ECG Identification for Personal Authentication Using LSTM-Based Deep Recurrent Neural Networks. Sensors 2020, 20, 3069. [Google Scholar] [CrossRef]
- Fatimah, B.; Singh, P.; Singhal, A.; Pachori, R.B. Biometric Identification from ECG Signals Using Fourier Decomposition and Machine Learning. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step 1: Data preprocessing: Processing original data using wavelet transform; Reconstructing ECG signals. |
| Step 2: Feature extraction: Positioning R peaks; Splitting data into dual-cycle ECG signals; Downsampling and normalization of signals. |
| Step 3: Sparse Dictionary: Initializing dictionary D and updating the dictionary using the OMP algorithm; Determining the sparse coefficient and iteration number to obtain the coefficient matrix of signals. |
| Step 4: Classification: Using the co-dimensional bundle search for classification. |
| Step 1: Establish a standard set 1. The matrix shown in Figure 6c as an element of a standard set. 2. Each subject takes 30 known matrices to establish a standard set. |
| Step 2: Calculate distance |
| 1. Obtain an unknown sparse matrix. |
| 2. Traverse the position of each non-zero element in the matrix and calculate the distance between each position and the same position as other elements in the dataset. Step 3: Assign tags and determine signal ownership |
| 1. Sort the distances between the same positions in the matrix and find the subject represented by the nearest label. Affix the same label to it. 2. Obtain all the labels obtained from this matrix and sort them. 3. Make it belong to the one with the most tags. |
| 4. Design a threshold R. 5. Calculate the average distance d between the matrix and all matrices in its label set. 6. If d < R, the signals belong to this subject, otherwise the subject to whom the signal belongs is not in this set. |
| Author | Preparation | Decision | Dataset | NS | Results |
|---|---|---|---|---|---|
| This paper | R-R segmentation, DWT, KSVD | Same dimension beam search (this paper) | EU-ST-T | 20 50 70 | 99.14% 99.09% 99.05% |
| Lee et al. [36] | R and T detection, R segmentation, resampling | Cosine, Euclidean, Manhattan dists., and CC | Private | 55 | 93.30% |
| Dong et. [37] | Construction of 3D VCG with 12-lead ECG | Minimum L1 norm of the bank of errors | PTB | 14 99 | 98.30% 93.30% |
| Pal et al. [38] | DWT fiducial det, P-QRS-T segmentation | Euclidean distance | PTB | 100 | 97.10% |
| Dar et al. [39] | Local-Max R det, QRS segmentation | KNN | MIT ECG-ID | 47 90 | 93.1% 83.2% |
| David et al. [40] | Pan–Tompkins, AC/DCT | A Clustering Algorithm | MIT | 549 | 98.6% |
| Kim et al. [41] | amplitude, angle, Wavelet, | LSTM+ DRNN | MIT-BIH | 47 | 99.8% |
| Binish et al. [42] | FDM + PT | RF+ ESD +SVM | BIH | 50 | 97.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, Q.; He, D.; Suo, H.; Zhao, C. Electrocardiogram-Based Biometric Identification Using Mixed Feature Extraction and Sparse Representation. Sensors 2023, 23, 9179. https://doi.org/10.3390/s23229179
Zhang X, Liu Q, He D, Suo H, Zhao C. Electrocardiogram-Based Biometric Identification Using Mixed Feature Extraction and Sparse Representation. Sensors. 2023; 23(22):9179. https://doi.org/10.3390/s23229179
Chicago/Turabian StyleZhang, Xu, Qifeng Liu, Dong He, Hui Suo, and Chun Zhao. 2023. "Electrocardiogram-Based Biometric Identification Using Mixed Feature Extraction and Sparse Representation" Sensors 23, no. 22: 9179. https://doi.org/10.3390/s23229179
APA StyleZhang, X., Liu, Q., He, D., Suo, H., & Zhao, C. (2023). Electrocardiogram-Based Biometric Identification Using Mixed Feature Extraction and Sparse Representation. Sensors, 23(22), 9179. https://doi.org/10.3390/s23229179