1. Introduction
Autonomous driving is certainly one of the most popular research directions in the robotics and intelligent transportation communities. The core capabilities of an autonomous driving agent are grounded on the navigation stack, which is composed of the following components: i.e., localization, mapping, path planning and collision avoidance. Among these, the localization module is probably the most crucial one, being the prerequisite for the proper functioning of all the others. Therefore, its performance is of utmost importance for the success of the overall navigation pipeline.
Localization aims to estimate and describe the agent pose, and i.e., its position and orientation in 3D space. This information is extracted from the input data provided by the available sensors of the agent, such as LIDAR, lasers, monocular or stereo cameras, and IMUs. Cameras are particularly attractive, due to their low cost, weight, and energy consumption, and the significant amount of information about the surrounding environment contained in the images collected. Stereo vision is probably the most common configuration, and several works and commercial products have proven its effectiveness. Nonetheless, its accuracy is tightly linked to the correctness of the stereo calibration, the estimated parameters of which might drift over time, due to physical modification of the rig (e.g., thermal expansion and cool contraction). The monocular setup considered in this paper does not suffer from this limitation. This advantage comes at the cost of more challenging image processing algorithms (He et al. [
1]), due to the well-known scale drift and the single-point-of-failure (SPOF) problems (Aqel et al. [
2], Yang et al. [
3]).
From a methodological point of view, localization is achieved by relying on Visual Odometry (VO) or Simultaneous Localization And Mapping (SLAM), as presented in numerous literature works e.g., Yousif et al. [
4], Agostinho et al. [
5] and Chen et al. [
6]. Most of these approaches leverage image features (i.e., keypoints) tracking across multiple frames to estimate the camera ego-motion.
For decades, feature detection and description methods were hand-engineered to guarantee invariance to geometrical or photometric changes and robustness concerning matching procedures. Many of the state-of-the-art feature extraction algorithms have shown impressive results in many applications (Chen et al. [
7], Macario et al. [
8]). Starting from the pioneering work by Moravec [
9], we have witnessed a rapid improvement of feature extractors, from the Harris detector by Harris et al. [
10] and blob detector by Matas et al. [
11], to the famous SIFT by Lowe et al. [
12], FAST by Rosten et al. [
13] and SURF by Bay et al. [
14].
More recently, the ORB extractor by Rublee et al. [
15] has become quite popular as the pillar of the famous ORB–SLAM framework by Mur-Artal et al. [
16], which has been further improved in its subsequent versions, i.e., ORBSLAM2 (Mur et al. [
17]) and ORBSLAM3 (Campos et al. [
18]).
Choosing the feature extractor that best suits the application at hand is, in general, not trivial. Each method might be appropriate for a specific condition (e.g., illumination or blur degree) or scenarios (e.g., automotive, indoor, aerial). In addition, these approaches rely on many hyper-parameters having optimal values which are hardly a priori known and could change significantly from one context to another.
Viable alternatives to hand-engineered feature extractors have recently been proposed through the exploitation of data-driven representation learning approaches (Jing et al. [
19]). Deep learning is widely utilized for this objective, and new techniques based on both supervised and self-supervised approaches are continuously being developed. Models based on Convolutional Neural Networks (CNNs), in particular, are capable of computing features that exhibit robust invariance to geometric and photometric changes, including illumination, background, viewpoint, and scale (Wang et al. [
20]).
A pioneering contribution to the field of learned features and descriptors was made by Verdie et al. [
21], which lay the foundations for learning-based keypoints and descriptors detection by proposing a simple method to identify potentially stable points in training images, and a regression model that detects keypoints invariant to weather and illumination changes. Lenc et al. [
22], instead, proposed DetNetm, which learns to compute local covariant features. This approach was improved by Zhang et al. [
23] with TCDET, which ensures the detection of discriminative image features and guarantees repetitiveness. Finally, Barroso-Laguna et al. [
24] fused hand-engineered and learned filters to obtain a lightweight and efficient detector with real-time performance.
The aforementioned methods treat feature detection and description as separate problems. In the last few years, strategies that jointly detect features and compute the associated descriptors are spreading. LIFT by Yi et al. [
25] was among the first attempts in this direction and was followed by other successful models, including Superpoint by Detone et al. [
26], LF-Net by Ono et al. [
27] and D2-Net by Dusmanu et al. [
28].
While the previous works propose general purpose algorithms, recent researchers have steered attention toward the integration of learning-based feature extractors into VO and SLAM systems. DXSLAM by Li et al. [
29] exploits CNN-based features to obtain scene representations that are robust to environmental changes and combines them into the SLAM pipeline. To meet the high demand for neural network models for graph data, GCN (Graph Convolutional Neural Networks) was introduced by Derr et al. [
30]. GCN approaches bring significant improvement in a variety of network analysis tasks, one of which is learning node representations. In particular, they were successfully used by Tang et al. in [
31] and in its improved version, GCNv2 (Tang et al. [
32]), for the task of keypoint and descriptor extraction.
DROID–SLAM by Teed et al. [
33], relies, instead, on the end-to-end paradigm and is characterized by a neural architecture that can be easily adapted to different setups (monocular, stereo and RGB-D).
Inspired by the discussions above, this work intended to provide a benchmark study for researchers and practitioners that highlights the differences between learning-based descriptors and hand-engineered ones in visual SLAM algorithms. For this purpose, we selected one of the most popular visual SLAM algorithms, i.e., ORBSLAM3 by Campos et al. [
18], and studied how the localization performance changed when its standard feature extraction pipeline was replaced with learning-based feature extractors. Namely, we employed Superpoint as the CNN-based keypoint detector and descriptor extractor. The two versions of ORBSLAM3 were compared on three different reference datasets widely employed in the robotics community. Different metrics were considered to provide an extensive quantitative analysis.
An attempt to combine Superpoint with ORBSLAM2 was also made by Deng et al. [
34]. However, their analysis was limited to a single dataset, without studying the impact that the different hyper-parameters of ORBSLAM2 had on the overall performance. Instead, we propose an in-depth benchmark that includes and discusses localization performance and memory\computational resources consumption and compares the two ORBSLAM3 versions, (the first with Superpoint and the second with standard hand-engineered ORB features), under several hyper-parameter configurations.
Contribution
As highlighted by the literature review, in recent years learned features have emerged as a promising alternative to traditional handcrafted features. Despite their demonstrated robustness to image non-idealities and generalization capabilities, to the best of our knowledge, there has been limited research directly comparing standard and handcrafted features in visual odometry applications. Thus, we believed it was crucial to conduct a thorough benchmark between learned and handcrafted features to assess their relative strengths and limitations in the context of visual odometry and SLAM.
This study could be beneficial to inform future development efforts, guiding the design and implementation of more effective and efficient algorithms. Moreover, comparing the performance of learned and handcrafted features on a diverse range of datasets provides a better understanding of the generalization capabilities of the approaches and the applicability of the algorithms to real-world scenarios.
To summarize, our contributions are as follows:
A study on the integration of learned features into the ORBSLAM3 pipeline.
A thorough evaluation of both learned and hand-crafted features across three diverse datasets, and considering different application domains.
A performance comparison between learned and handcrafted features in terms of computational efficiency and execution timing.
The present study is structured as follows.
Section 2 provides a comprehensive overview of the algorithms employed in the work and summarizes the main contribution of our work. The methodology and implementation process are explained in detail in
Section 3. The results of the experiments carried out in this study are presented in
Section 4, and their implications are discussed and analyzed in
Section 5.
Finally,
Section 6 concludes the study by offering insights that are valuable for future research and development.
2. Background
The high-level pipeline of a SLAM system can be divided into two main blocks: front-end and back-end. The front-end block is responsible for feature extraction, tracking, and 3D triangulation. The back-end, on the other hand, integrates the information provided by the front-end and fuses the IMU measurements (in the case of VIO approaches) to update the current and past pose estimates.
The aim of this work was to evaluate the performance of the overall SLAM pipeline when the hand-engineered feature extractors of the front-end were replaced with learning-based ones. More specifically, as mentioned in the previous section, we integrated Superpoint in the front-end of the ORBSLAM3 framework and compared this configuration against the standard one. Therefore, in the following, we briefly summarize the main characteristics of the two methods, while in
Section 3 we describe the changes made to the ORBSLAM3 pipeline in order to perform the integration with Superpoint.
2.1. ORBSLAM3
ORBSLAM3 (Campos et al. [
18]) has become one of the most popular modern keyframe-based SLAM systems, thanks to the impressive results shown in different scenarios. It can work with monocular, stereo, and RGB-D camera setups and can be used in visual, visual–inertial, and multi-map SLAM settings.
When ORBSLAM3 is used in the monocular setup-based configuration, we can identify three main threads that run in parallel:
The Tracking thread receives, as input, the current camera frame and outputs an estimated pose. If the incoming frame is selected as a new keyframe, this information is forwarded to the back-end for global optimization purposes. In this stage, the algorithm extracts keypoints and descriptors from the input images using the ORB feature detector and the BRIEF feature descriptor. Moreover, the algorithm matches the keypoints and descriptors from the current image to those from previous images. This stage uses the global descriptor index, a data structure that allows the efficient matching of features across multiple images. A prior motion estimation is also performed in this thread.
The Local Mapping thread handles the insertion and removal of map points and performs map optimization. The local mapping thread is responsible for incorporating new keyframes and points, pruning any unnecessary information, and improving the accuracy of the map through the visual (or visual–inertial) bundle adjustment (BA) optimization process. This is accomplished by focusing on a small group of keyframes near the current frame.
The Loop & Map Matching thread identifies loop closings. If a loop is detected, a global optimization procedure is triggered to update the map points and poses to achieve global consistency.
ORBSLAM3 employs ORB (Rublee et al. [
15]) as a feature extractor, which relies on FAST (Rosten et al. [
13]) for keypoint detection and BRIEF by Calendor et al. [
35] to compute a rotation invariant 256-bit descriptor vector. ORB is a fast detector that extracts features that exhibit different invariances, such as viewpoint and illumination, and has high repeatability. This makes it well-suited for challenging environments, where the camera motion is fast and erratic. On the other hand, ORB features are not completely scale-invariant and are sensitive to orientation changes.
To overcome these limitations, in the ORBSLAM3 implementation, the ORB feature extraction process leverages an image pyramid strategy: multiple scaled versions of the same frame are used to compute features at different image resolutions. While this improves the robustness with respect to scale variations, it entails a higher computational cost.
In this work, we replaced the ORB feature extractor with the Superpoint one in the ORBSLAM3 pipeline to assess the benefits and the limitations of sparse learning-based features for pose estimation applications. Therefore, in the following, we describe the characteristics of Superpoint before providing details on its integration with ORBSLAM3.
2.2. Superpoint
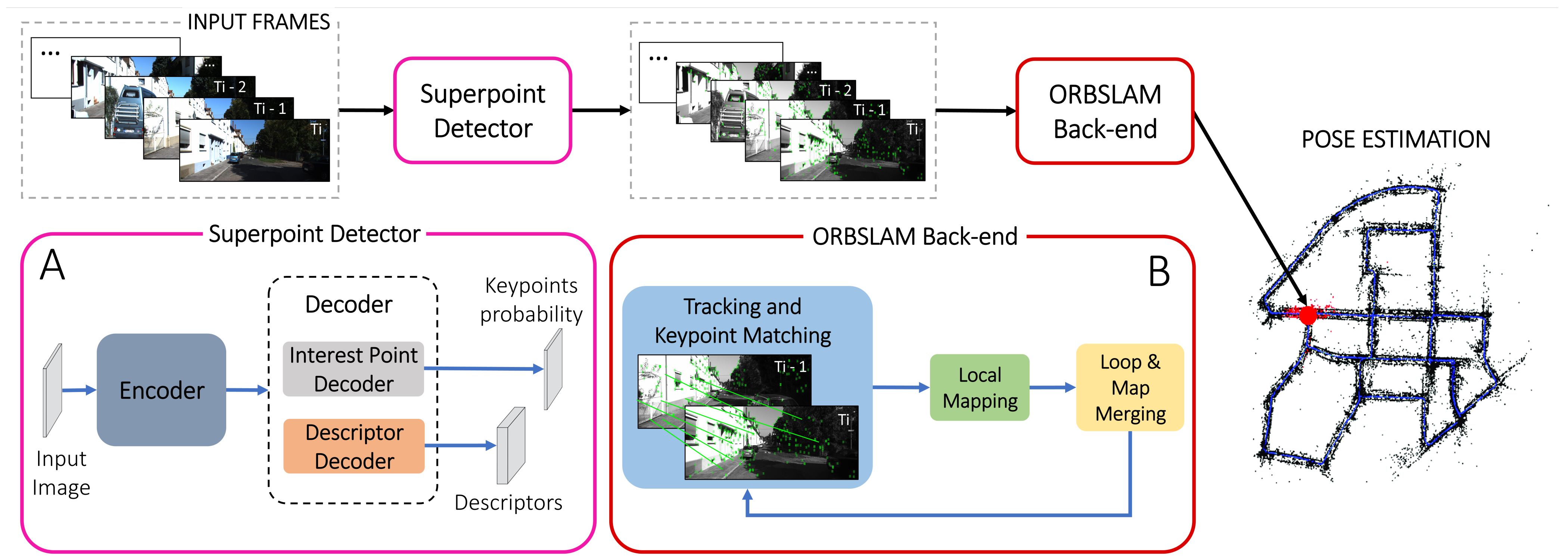
The Superpoint learning model is based on a self-supervised strategy able to jointly extract keypoints and relative descriptors. It exploits a convolutional encoder–decoder architecture to extract features and descriptors from two different learning pipelines. Specifically, the Superpoint pipeline (
Figure 1) receives a colored 3-channels image, which is then converted into a 1-channel grayscale image with dimensions
(where
H and
W are the height and the width of the image in pixels, respectively) and outputs a dense
map, having pixels values which express the probability of being a Superpoint. The descriptor decoder pipeline, instead, computes a unique 256 element descriptor for each detected keypoint.
Superpoint takes advantage of a homographic adaptation strategy during the learning phase to achieve robustness to scale and geometric scene structure changes without the need to have ground truth keypoints and descriptors. In addition, by exploiting GPU parallelism, the evaluation phase of the algorithm is fast and compatible with the real-time constraints of most applications.
3. Superpoint Integration with ORBSLAM3
This section details the integration of the Superpoint feature extraction pipeline with the front-end of the ORBSLAM3 framework. Specifically, we replace the ORB extraction module of ORBSLAM3 with the keypoints and descriptors computed by feeding input frames in the Superpoint network.
In
Figure 1 the implemented pipeline is represented; specifically, the learned encoder sub-block of the Superpoint convolutional encoder–decoder architecture (sub-block A in the
Figure 1) is used to extract robust visual cues from the image, and consists of convolutional layers, spatial downsampling via pooling and non-linear activation functions. The encoder input, represented by the
-sized image, is then converted to a
feature map after the network convolutional layers.
Features and descriptors are then extracted through two different non-learned decoder pipelines, namely the interest point decoder and the descriptor decoder, respectively. Both decoders receive as input images. The interest point decoder outputs a matrix of “Superpointness” probability. On the other hand, the descriptor decoder outputs the associated (with ) matrix of keypoint descriptors.
Both decoders operate on a shared, and spatially reduced, representation of the input and use non-learned up-sampling to bring the representation back to .
The integration of Superpoint into the ORBSLAM3 back-end is not a direct process. This is due to the fact that the FAST detector in ORBSLAM3 was specifically designed to operate across multiple pyramid levels and various image sub-blocks, to ensure an evenly distributed keypoint arrangement. Superpoint, instead, processes the full-resolution image and outputs a dense map of keypoint probabilities and associated descriptors. Therefore, we modified the ORBSLAM3 sub-blocks extraction methods to meet this specification.
To allow Superpoint to process the image at multiple pyramid levels similarly to ORB, we scaled the input frame according to the number of levels required and forwarded each scaled image through the neural network independently. Concerning the image sub-block division, we noticed that Superpoint could intrinsically extract features over the entire image. Therefore, differing from ORBSLAM3, feature sparsity could be achieved without additional image processing strategies, such as sub-cell division. Instead, since Superpoint computes a dense keypoint probability map, we thresholded it to select the K features with the highest probability. This procedure enabled the control of the number of keypoints extracted and imposed constraints on both the Superpoint and ORB extractors by ensuring a consistent number of features.
Differing from the ORB descriptors, which are characterized by a 256-bit vector, Superpoint provides vectors of float values that cannot be matched with the Hamming-based bit-a-bit distance of ORBSLAM3. Instead, for Superpoint features, we adopted the L2-norm between descriptors vectors and tuned the matching thresholds accordingly.
Finally, we also adapted the loop & map matching thread of ORBSLAM3 to use Superpoint features. In ORBSLAM3, the BoW representation is used to match local features between images, allowing the system to identify common locations across different frames. This approach is efficient and effective for place recognition in ORBSLAM3, as it allows for quick matching between images, and robust recognition of similar environments, despite changes in lighting, viewpoint, and other factors. By utilizing the BoW representation, ORBSLAM3 can maintain an accurate and consistent mapping of environments, even in challenging conditions. For this purpose, we used the Bag-of-Words (BoW) vocabulary made available by Deng et al. [
34]. The Bag-of-words vocabulary is trained with the DBoW3 library (
https://github.com/rmsalinas/DBow3, [
36] accessed on 15 October 2022) on Bovisa_2008-09-01 (Bonarini et al. [
37], Ceriani et al. [
38]) with both outdoor and mixed sequences.
The full pipeline from input frames to output pose estimation can be summarized as follows:
- 1.
Image pre-processing: the image is resized and, if needed, rectified to remove lens distortion. The resulting frame is then converted into a single-channel grayscale format.
- 2.
Feature detection and description: the pipeline detects and describes salient features in the image using the Superpoint feature detector and descriptor. The feature extraction operation is performed by taking into account several scale levels of the input image to enhance scale invariance and increase the number of detected features.
- 3.
Keyframe selection: the system selects keyframes from the input images, which are frames deemed to be representative of the environment.
- 4.
Map initialization and update: the system uses the information from the keyframes to initialize a map of the environment and continually updates this map as new frames are processed.
- 5.
Motion estimation: the pipeline uses monocular visual odometry motion estimation algorithms to estimate the relative motion between the current and the previous frame.
- 6.
Pose estimation: the system integrates the motion estimates to compute the absolute pose of the camera in the environment.
- 7.
Loop closure detection: the pipeline regularly checks for loop closures, which occur when the camera revisits a previously visited location. If a loop closure is detected, the pipeline updates the map and refines the pose estimates.
In the following, to distinguish the standard ORBSLAM3 pipeline from the one that integrates Superpoint, we refer to the latter as SUPERSLAM3.
4. Experiments
In this section, we describe the experimental setup and discuss the results. Performance and resource utilization comparisons were designed to investigate the different effects of the Superpoint and standard ORB feature extraction pipelines on the ORBSLAM3 back-end.
We performed two different types of analysis: a performance analysis suited to comparing the localization accuracy achieved with ORB and Superpoint feature extractors, and a computational analysis that examined the memory and resource usage of the GPU and CPU. Finally, we provide and discuss the impact that the standard ORB extractor and the Superpoint network had on the execution times of the ORBSLAM3 feature extraction and feature matching blocks.
This work mainly focused on the comparison of deep feature extractor against ORB. Therefore, we used the monocular configuration of ORBSLAM3, although the considerations we drew could be extended to the stereo, visual–inertial, and RGB-D cases.
To provide an extensive and in-depth analysis, multiple datasets from different domains (aerial, automotive, and hand-held) and scenarios (outdoor, indoor) were selected. To compare ORBSLAM3 and SUPERSLAM3 in hand-held camera scenarios, we considered the TUM-VI by Schubert et al. [
39] dataset. It offered numerous challenges, including blur due to camera shaking, six degrees of freedom (6-DoF) motions, and rapid camera movements. To evaluate the algorithms in automotive and aerial scenarios, we chose the KITTI by Geiger et al. [
40] and the EuRoC by Burri et al. [
41] datasets, which, in general, were characterized by sudden appearances and photometric changes, and were subject to various motion constraints. Specifically, we ran tests on all the six
Vicon Room and five
Machine Hall sequences of EuRoC (for a total of 27,049 frames), and on ten sequences (from
00 to
10) of the KITTI dataset (for a total of 23,201 frames). On the other hand, for the TUM-VI we selected only six
Room sequences (from
Room_1 to
Room_6) (for a total of 16,235 frames), where ground truth poses estimated by the motion capture system were available for the entire trajectory.
4.1. Parameter Exploration
The original ORBSLAM3 implementation relies on different parameters that control tracking, loop closure, and matching behaviors. Among all of these, we focused on the two with the highest impact on the system performance, i.e., nFeatures and nLevels. Specifically, we considered several combinations of the latter parameters to assess how they affected the performance of the ORBSLAM3 and SUPERSLAM3 pipelines.
For both the algorithms analyzed, nFeatures defines the number N of features extracted from an image. In SUPERSLAM3, this aspect is controlled by extracting the N features with the highest Superpoint probability value. Instead, in ORBSLAM3, N represents the maximum number of features that are extracted for each level of the image pyramid scale. nLevels describes, for both the approaches, the numbers of pyramid scale levels processed in the feature extraction pipeline, andi.e., the number of times a frame is scaled before computing features and descriptors.
Other parameters introduced in the original ORBSLAM3 implementation are mostly dataset-dependant and, therefore, for both SUPERSLAM3 and ORBSLAM3 we experimentally found the best possible values and kept them unchanged during all tests. We also decided not to change the scaleFactor parameter.
Similar considerations were made for the (init/min)ThFAST FAST threshold parameters, with the exception that they were meaningless in SUPERSLAM3 and, therefore, considered only in the ORBSLAM3 evaluations.
4.2. Experimental Setup
The comparisons were performed by running ORBSLAM3 and SUPERSLAM3 on the sequences previously listed. For each sequence, multiple parameter configurations were analyzed by changing the number of pyramid scales used for image scaling (i.e., nLevels) within the range of [1, 4, 8] and the number of keypoints extracted (i.e., nFeatures) within the range of [500, 750, 900, 1000].
The intervals for the parameters nLevels and nFeatures were established with the consideration that both ORBSLAM3 and SUPERSLAM3 often encounter initialization problems in most sequences when the number of features is below 500. On the other hand, increasing the number of features beyond 1000 does not result in improved performance for the algorithms and instead leads to a decrease in computational efficiency.
Additionally, we conducted experiments on a subset of sequences, the images of which were deliberately blurred to evaluate the performance of the algorithms on non-ideal inputs.
In particular, we selected the
MH_02 sequence from the EuRoC dataset, the
room_6 sequence from the TUM-VI dataset, and the
07 sequence from the KITTI dataset and applied a Gaussian blur filter to their images with a patch size of 12 pixels and a standard deviation of 2.15 pixels in both directions (as depicted in
Figure 2). The parameters for this set of experiments were based on the analysis performed on the standard sequences.
For MH_02, we set nFeatures to 700 and nLevels to 8. For room_6 and 07, nFeatures is set to 900 and nLevels to 4.
4.3. Evaluation Metrics
4.3.1. Pose Estimation Metrics
To quantitatively assess the accuracy of both approaches, we utilized various commonly used metrics.
In particular, we considered the absolute pose error (APE), which is composed of rotational (expressed in degree) and positional (expressed in meters) parts. The absolute pose error
is a metric for investigating the global consistency of a trajectory. Given the ground-truth poses
and the aligned estimation
, we can define as
and
, respectively, the
pose point of the ground truth and the estimated trajectories. The APE error can then be evaluated as the absolute relative pose between the estimated pose (
1) and the real one (
2) at timestamp
i.
where
N and
M are respectively the numbers of poses in the ground truth and the estimated trajectories. The APE statistic can be easily calculated from the relation (
3).
It can be decomposed into its translational (
4) and rotational components (
5).
where
belongs to the special Euclidean group of 3D rotations and translations,
is a function that extracts the translation component of a pose,
extracts the rotational matrix from the
pose matrix, and
is a function that extracts the rotation angle from a rotation matrix. The exact form of the
function may vary, depending on the convention used for the rotational part representation.
Specifically, the logarithm of gives the axis and angle of the relative rotation, which can then be converted into a scalar angle using the function.
and are the absolute value and the Euclidean norm operators, respectively.
To measure the overall quality of the trajectory, we used the Root Mean Square Error (RMSE) of the Absolute Pose Error (APE), which was further divided into the Absolute Trajectory Error (ATE, as described in Equation (
6)) and the Absolute Rotational Error (ARE, as described in Equation (
7)). For simplicity, we refer to the RMSE values of ATE and ARE as ATE and ARE, respectively.
ATE and ARE are compact metrics to evaluate the position and rotation estimations and provided an immediate and quantitative measure to compare the tracking algorithms.
To generate the evaluation metrics, we used EVO (Grupp et al. [
42]). However, EVO only considers the correspondence between the estimated trajectory and ground truth based on the timestamps, which may result in inaccurate outcomes and incorrect conclusions. This is because both SUPERSLAM3 and ORBSLAM3 may lose tracking and produce fewer poses than those provided by the ground truth.
Therefore, in our analysis, we chose to also include the Trajectory Ratio metric (TR, as defined in Equation (
8)), along with ATE and ARE, to evaluate the proportion of estimated poses relative to the total number of ground truth poses:
4.3.2. Memory Resource and Computational Metrics
We analyzed the computational statistics of both ORBSLAM3 and SUPERSLAM3, based on two main aspects:
Resource analysis, including the average allocated memory for CPU and GPU (both expressed in MB) and the utilization of computational resources (expressed as a percentage of the total available resources).
Time analysis (in milliseconds ms) for the main functional blocks of SUPERSLAM3, including the feature extraction module and the descriptor matching module.
We evaluated the average CPU and GPU memory allocation and computational resource utilization for all combinations of parameters. In addition, we conducted the time analysis by considering the average extraction and matching times for a 512 × 512 image as a reference. We evaluated the matching time, based on an average of 200 matched features. On the other hand, the extraction time depended on the values selected for nFeatures and nLevels. Hence, we provided time statistics for nFeatures = 1000 and nLevels = 1 both for SUPERSLAM3 and ORBSLAM3.
4.4. Implementation and Training Details
For the SUPERSLAM3 tests, we used a set of pre-trained network weights, i.e., the original COCO-based training weight file provided by the Magic Leap research team (Detone et al. [
43]). As the author states in the original paper (Detone et al. [
26]), the SuperPoint model is first trained using the Synthetic Shapes Dataset and then refined using the 240 × 320 grayscale COCO generic image dataset (Lin et al. [
44]) by exploiting the homographic adaptation process.
We ran all our tests using a Nvidia GeForce RTX 2080 Ti with 12.0 GB of dedicated RAM and an Intel(R) Core(TM) i7-9800X CPU @ 3.80 GHz 3.79 GHz with 64.0 GB of RAM.
5. Results and Discussion
For the purpose of clarity in presenting the results, we adopted the following compact notation to represent the dataset and its corresponding set of parameter configurations: dataset-name_sequence-name_nFeatures-value-nLevels-value.
Based on the performance results, presented in
Table 1,
Table 2 and
Table 3, we observed varying trends in the performance of ORBSLAM3 and SUPERSLAM3. While some sequences showed good tracking performance, in terms of ATE, ARE, and TR for both algorithms, there were others in which SUPERSLAM3 failed to initialize (indicated by
fail in
Table 1,
Table 2 and
Table 3). Conversely, there were also sequences where ORBSLAM3 was outperformed by SUPERSLAM3.
More specifically, in EuRoC (see
Table 1) the results of both algorithms were comparable for all of the medium and low complexity sequences (MH_01, MH_02, MH_03, V1_01). However, in complex scenes, the performance of SUPERSLAM3 dropped, while ORBSLAM3 maintained a reasonable estimation accuracy. In our opinion, to explain this different behavior, it is important to note that EuRoC included sequences recorded with flying drones into indoor environments, which resulted in images affected by non-idealities specifically related to fast motions and poor illumination. While in some instances, SUPERSLAM3 performed slightly better than ORBSLAM3 (e.g., for EuRoC_MH_05_700_8), upon visual inspection we noticed that Superpoint failed to detect keypoints in scenes with high levels of blur (e.g., due to rapid motion or rapid panning).
The KITTI dataset (
Table 2) included outdoor automotive scenarios and had the highest number of sequences in which the algorithms tended to experience initialization failures. This was the case, for example, for SUPERSLAM3 when configured with
nFeatures = 500 and
nLevels = 1. We believe that most of the difficulties were related to the low amount of texture and distinctive cues in the sequences, e.g., due to the high portion of the images characterized by sky or asphalt, which reduced the number of informative features that could be detected. In general, from our understanding, this caused the results on KITTI to be worse than those obtained with the other two datasets, both for ORBSLAM3 and for SUPERSLAM3.
The TUM-VI dataset (see
Table 3) included handheld scenes from an indoor environment and was the only dataset where both the algorithms provided reasonable performance across all sequences and parameter configurations. From a quantitative point of view, performance was generally comparable, with ORBSLAM3 achieving slightly higher metrics.
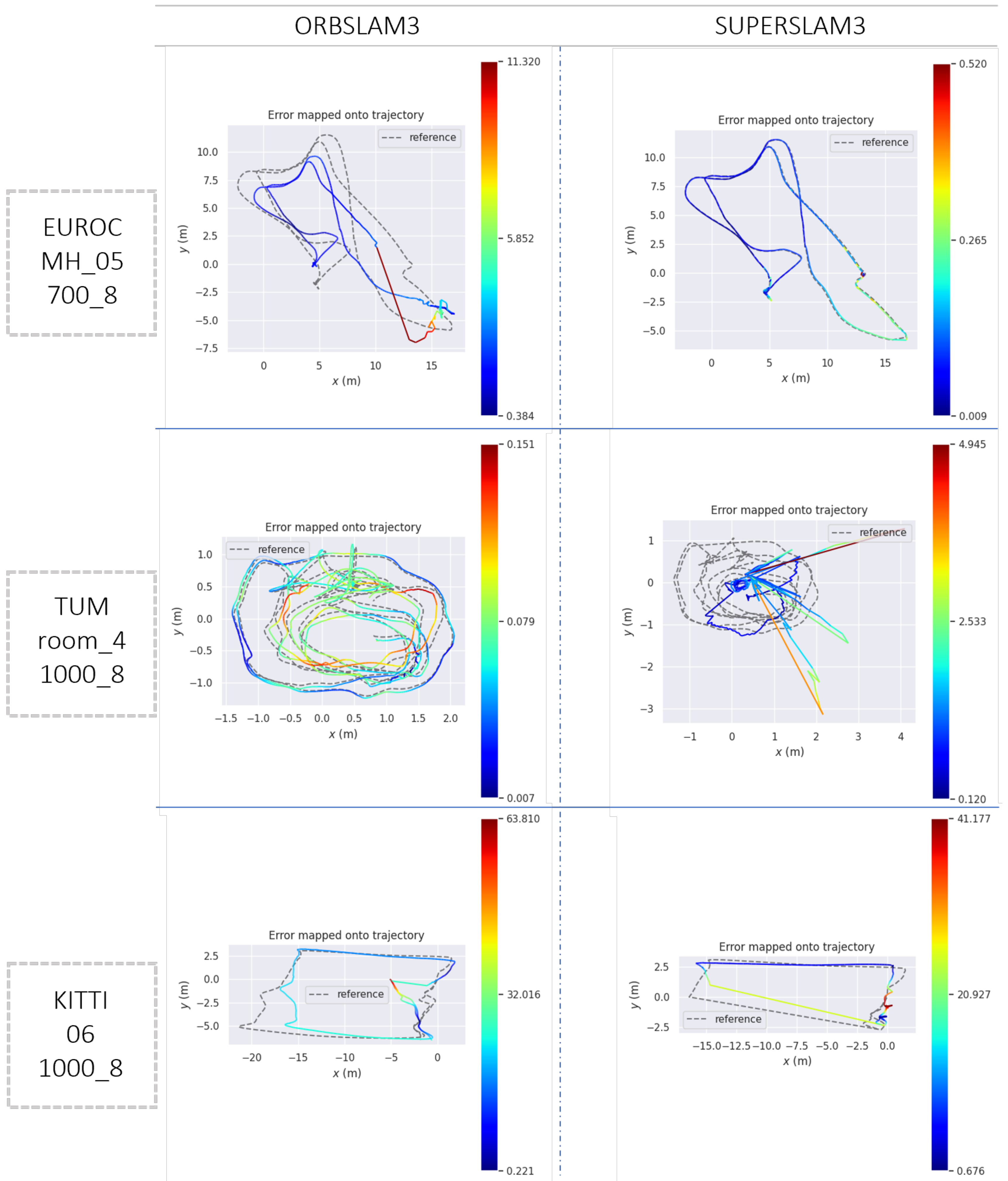
In
Figure 3, we present three qualitative plots depicting the estimated trajectories of three sample sequences. By comparing these plots with the quantitative results in
Table 1,
Table 2 and
Table 3, we observe that, on EuRoC_MH_05_700_8, SUPERSLAM3 outperformed ORBSLAM3 in terms of ATE and ARE. The trajectory ratio was comparable, indicating that both algorithms never lost the position tracking. On the other hand, in TUM_room_4_1000_8, SUPERSLAM3 performance was significantly worse than ORBSLAM3, with ATE and ARE values of 1.01 and 26.70 for SUPERSLAM3, and 0.08 and 2.48 for ORBSLAM3, respectively. The third trajectory from the KITTI dataset showed poor performance for both algorithms, particularly with regard to the ATE metric.
As expected, the results suggested that, as the number of features and pyramid levels increased, the values of TR increased, and ATE and ARE values decreased. In general, a larger number of features and pyramid levels could potentially improve the accuracy of the estimated trajectories, although the computational cost increased. It is worth noting that none of the trajectories estimated by SUPERSLAM3 had notably higher accuracy than those provided by ORBSLAM3. However, to better understand these results it is important to note that the set of Superpoint weights used in SUPERSLAM3 was trained on the COCO dataset. Hence, the detected keypoints were not specifically designed for automotive, handheld, or aerial applications. Therefore, the fact that SUPERSLAM3 could achieve performance comparable to ORBSLAM3 in most of the sequences was remarkable and showed its robustness and generalization capabilities.
On the blurred sequences, SUPERSLAM3 often lost feature tracking. This was particularly evident in the KITTI dataset, where turnings and curves were, in most cases, poorly estimated due to directional blur effects. This can also be observed in
Table 4 which shows how ORBSLAM3 achieved low errors, even on blurred sequences, while SUPERSLAM3’s performance dropped significantly. We believe that this phenomenon was related to the absence of blurred images in the homographic adaptation technique used in the training process of the Superpoint network.
Computational analysis results are presented in
Table 5 and
Table 6 for resource and time analysis, respectively. It can be observed that the average CPU memory utilization was higher for SUPERSLAM3 compared to ORBSLAM3. This could be ascribed to the larger number of detected features stored during the tracking process. In particular, both Superpoints and ORB features were represented by 256-element vectors. However, while each element of the ORB vector was represented by a binary value, the Superpoint descriptor contained 64-bit floats, which led to higher memory usage. The average GPU utilization of SUPERSLAM3 was mainly dependent on the number of pyramid stages that needed to be forwarded through the network and remained almost constant when changing the values of both the
nFactor and
nLevel parameters. Indeed, Superpoint computed keypoints and descriptors for the entire image in a single forward pass, repeated for each level of the pyramid ladder. On the other hand, the average GPU memory was mainly used to store network weights.
According to a time statistics analysis, the computation of the Superpoint feature and descriptor was faster than that of the ORB keypoint and descriptor. Specifically,
Table 6 shows that the average extraction time for ORBSLAM3 was approximately double that of the Superpoint descriptor. In contrast, the feature matching time for Superpoint features was higher than that of ORBSLAM3. This was expected since the feature matching process in SUPERSLAM3, which utilized the L2 norm, was slower than ORBSLAM3’s bit-wise descriptor matching method.
6. Conclusions
State estimation and tracking are fundamental in robotics and automotive applications, as they enable high-precision real-time SLAM systems for navigation tasks. These tasks require the selection of high-quality keyframes across images for accurate tracking, which can be achieved through the use of single-camera applications.
In addition to traditional methods, there has been a surge in the use of learning-based methods, which can automatically learn robust feature representations from large datasets and simultaneously estimate feature keypoints and descriptors with low computational costs and strong generalization capabilities.
In this study, we integrated Superpoint features within the ORBSLAM3 pipeline. We then presented a quantitative evaluation of the tracking and computational performance of the integration of Superpoint learned features into the ORBSLAM3 pipeline (i.e., SUPERSLAM3). We tested both SUPERSLAM3 and ORBSLAM3 on three datasets from different domains, including aerial, automotive, and handheld.
Our findings indicated that learned features could achieve good pose estimation results. However, by analyzing the results obtained, we hypothesized that including blurry image patterns and rotations in the training phase could enhance the system’s robustness and reliability. Training on a larger dataset could also enhance the extraction of robust Superpoint features, while increasing the generalization capabilities of the overall algorithm.
In our computational analysis, we observed that SUPERSLAM3 had faster performance for keypoints and descriptors extraction compared to ORBSLAM3. However, it was slower in the features matching phase.
Future work could consider the use of learned features trained on a large dataset to improve generalization capabilities and overall performance in terms of tracking estimation. The Superpoint matching phase could be enhanced through the integration of a GPU-based matching process, such as SuperGLUE (Sarlin et al. [
45]). Finally, based on our experimental results, we concluded that incorporating artificially blurred and non-ideal images into the training process of the network could enhance the robustness and consistency of the detector.




 ,
, 




{kind=link}
{kind=link}
{kind=link}