
Deep Learning Derived Object Detection and Tracking Technology Based on Sensor Fusion of Millimeter-Wave Radar/Video and Its Application on Embedded Systems



Abstract
:1. Introduction
Motivation
2. Related Work
2.1. Types of Sensor Fusion
2.2. YOLO v3 Model
2.3. YOLO v4 Model
2.4. Clustering
3. The Proposed Method
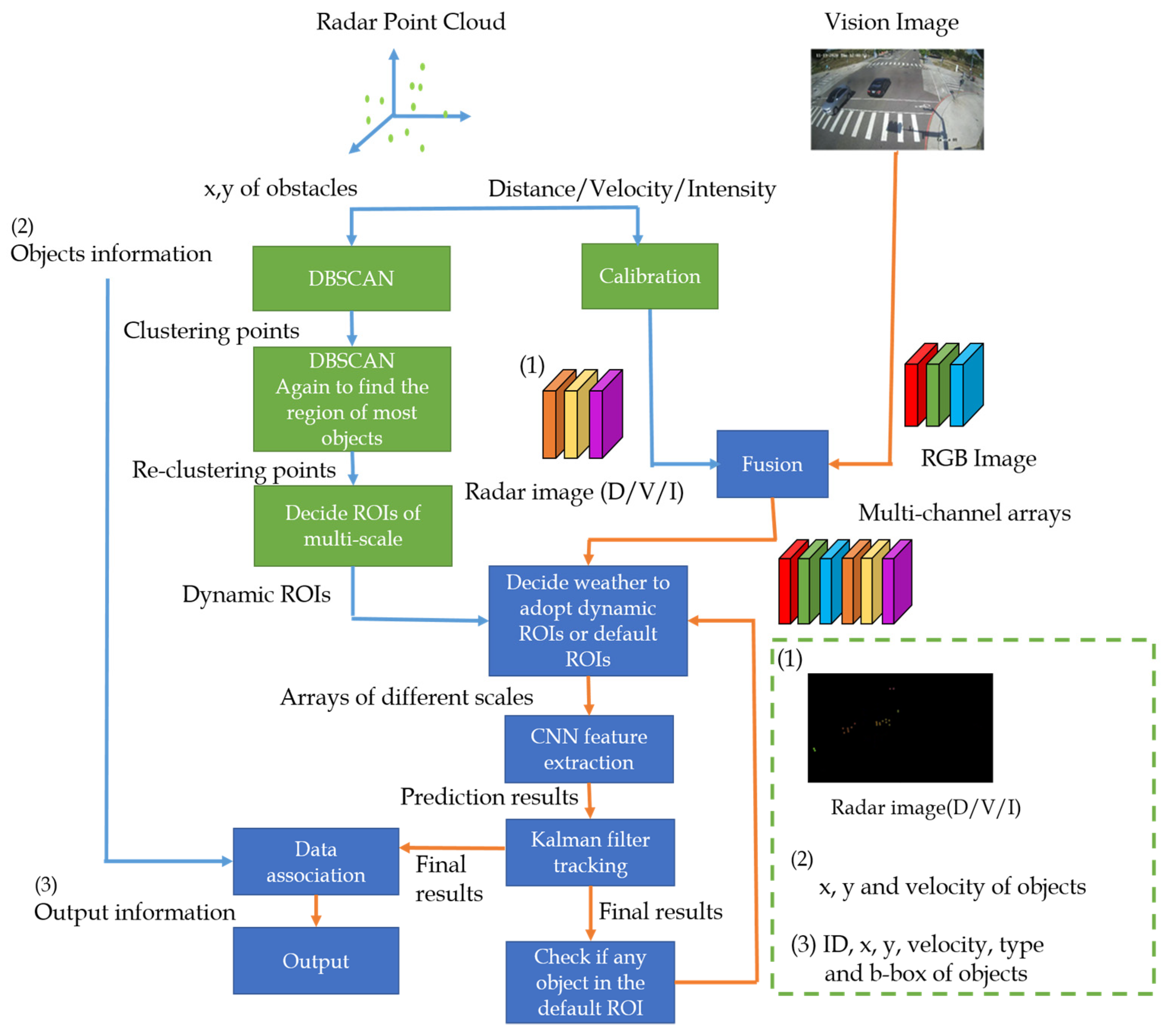
3.1. Overview
3.2. Radar Clustering
3.3. Radar and Camera Calibration
3.4. Radar and Camera Data Fusion
3.5. Dynamic ROI for Multi-Scale Object Detection
3.6. Object Detection Model
3.7. Tracking
4. Experimental Evaluation
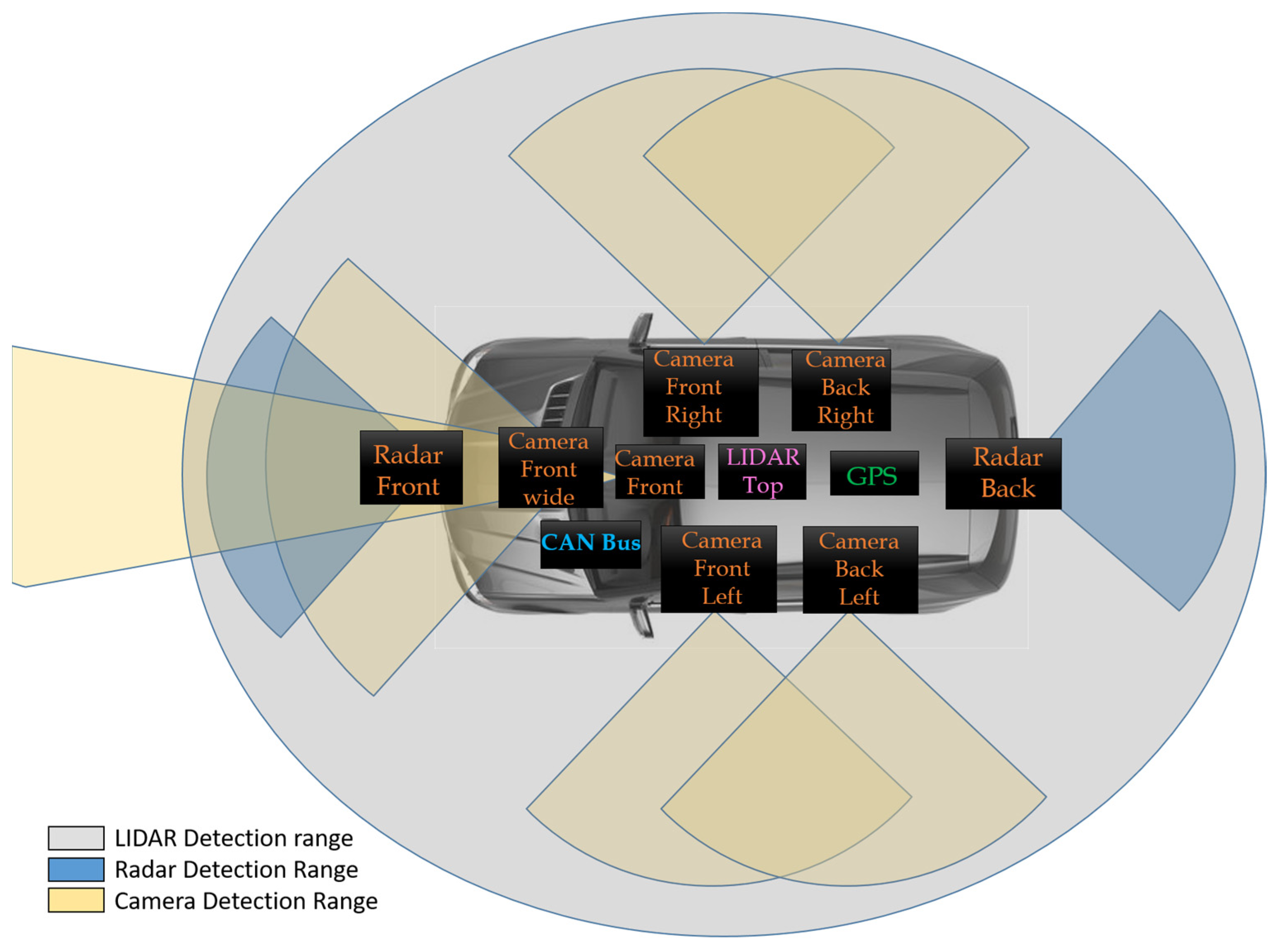
4.1. Sensor Fusion Equipment
4.2. Implementation Details
4.3. Evaluation on YOLOv3
4.4. Evaluation on YOLOv4
4.5. Comparison between YOLOv3 and YOLOv4
4.6. Proposed System Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chang, S.; Zhang, Y.; Zhang, F.; Zhao, X.; Huang, S.; Feng, Z. Spatial attention fusion for obstacle detection using mmWave radar and vision sensor. Sensors 2020, 20, 956. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, J.X.; Lin, J.C.; Vinay, M.S.; Chen, P.-Y.; Guo, J.-I. Fusion technology of radar and RGB camera sensors for object detection and tracking and its embedded system implementation. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing As-sociation Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; pp. 1234–1242. [Google Scholar]
- Obrvan, M.; Ćesić, J.; Petrović, I. Appearance based vehicle detection by radar-stereo vision integration. In Advances in Intelligent Systems and Computing; Elsevier: Amsterdam, The Netherlands, 2015; pp. 437–449. [Google Scholar]
- Wu, S.; Decker, S.; Chang, P.; Senior, T.C.; Eledath, J. Collision sensing by stereo vision and radar sensor fusion. IEEE Trans. Intell. Transp. Syst. 2009, 10, 606–614. [Google Scholar]
- Liu, T.; Du, S.; Liang, C.; Zhang, B.; Feng, R. A Novel Multi-Sensor Fusion Based Object Detection and Recognition Algorithm for Intelligent Assisted Driving. IEEE Access 2021, 9, 81564–81574. [Google Scholar] [CrossRef]
- Jha, H.; Lodhi, V.; Chakravarty, D. Object Detection and Identification Using Vision and Radar Data Fusion System for Ground-Based Navigation. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Net-works (SPIN), Noida, India, 7–8 March 2019; pp. 590–593. [Google Scholar]
- Kim, K.-E.; Lee, C.-J.; Pae, D.-S.; Lim, M.-T. Sensor fusion for vehicle tracking with camera and radar sensor. In Proceedings of the 2017 17th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 18–21 October 2017; pp. 1075–1077. [Google Scholar]
- Wang, T.; Zheng, N.; Xin, J.; Ma, Z. Integrating Millimeter Wave Radar with a Monocular Vision Sensor for On-Road Obstacle Detection Applications. Sensors 2011, 11, 8992–9008. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, X.; Du, J.; Gao, J.; Wang, W. Pedestrian detection based on fusion of millimeter wave radar and vision. In Proceedings of the 2018 International Conference on Artificial Intelligence and Pattern Recognition, Beijing, China, 18–20 August 2018; pp. 38–42. [Google Scholar]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. On-road vehicle detection and tracking using MMW radar and monovision fusion. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2075–2084. [Google Scholar] [CrossRef]
- Chadwick, S.; Maddern, W.; Newman, P. Distant vehicle detection using radar and vision. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8311–8317. [Google Scholar]
- John, V.; Mita, S. Deep sensor fusion of monocular camera and radar for image-based obstacle detection in challenging environments. In Pacific-Rim Symposium on Image and Video Technology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 351–364. [Google Scholar]
- Geisslinger, M.; Weber, M.; Betz, J.; Lienkamp, M. A deep learning-based radar and camera sensor fusion architecture for object detection. In Proceedings of the 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 15–17 October 2019; pp. 1–7. [Google Scholar]
- Yun, S.; Han, D.; Joon Oh, S.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Hao, W.; Zhili, S. Improved Mosaic: Algorithms for more Complex Images. J. Phys. Conf. Ser. 2020, 1684, 012094. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Germany, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Meta, A.; Hoogeboom, P.; Leo, P. Ligthart. Signal processing for FMCW SAR. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3519–3532. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognition Letters. Corrected Proof 2010, 31, 651–666. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xiaowei, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Luo, X.; Yao, Y.; Zhang, J. Unified calibration method for millimeter-wave radar and camera. J. Tsinghua Univ. Sci. Technol. 2014, 54, 289–293. [Google Scholar]
- Chopde, N.R.; Nichat, M.K. Landmark based shortest path detection by using A* and Haversine formula. Int. J. Innov. Res. Comput. Commun. Eng. 2013, 1, 298–302. [Google Scholar]
- Taguchi, G.; Jugulum, R. The Mahalanobis-Taguchi Strategy: A Pattern Technology System; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Xiao, B.; Fan, H.; Hu, Q.; Ling, L. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Ma, K.; Zhang, H.; Wang, R.; Zhang, Z. Target tracking system for multi-sensor data fusion. In Proceedings of the 2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017; pp. 1768–1772. [Google Scholar]
- Liu, Z.; Cai, Y.; Wang, H.; Chen, L.; Gao, H.; Jia, Y.; Li, Y. Robust Target Recognition and Tracking of Self-Driving Cars With Radar and Camera Information Fusion Under Severe Weather Conditions. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6640–6653. [Google Scholar] [CrossRef]
- Texas Instruments. IWR6843: Single-Chip 60-GHz to 64-GHz Intelligent mmWave Sensor Integrating Processing Capability. Available online: https://www.ti.com/product/IWR6843 (accessed on 23 July 2022).
- NVIDIA. NVIDIA Jetson AGX Xavier: The AI Platform for Autonomous Machines. Available online: https://developer.nvidia.com/embedded/jetson-agx-xavier-developer-kit (accessed on 24 July 2022).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Angle (Deg) | Ground Truth (m) | Radar Estimation (m) | Radar (Error) | |
|---|---|---|---|---|
| Point 1 | 0 | 5.10 | 5.20 | 1.96% |
| Point 2 | 9.58 | 9.5 | −0.84% | |
| Point 3 | 13.92 | 13.90 | −0.14% | |
| Point 4 | 25 | 5.00 | 4.90 | −2.00% |
| Point 5 | 19.26 | 18.90 | −1.87% | |
| Point 6 | 34.04 | 33.90 | −0.41% | |
| Point 7 | 45.42 | 46.00 | 1.28% |
| Class | RGB | RGB + D | RGB + V | RGB + I | RGB + DV | RGB + DI | RGB + VI | RGB + DVI | |
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | All | 68.7 | 71.2 | 69.4 | 67.4 | 77.5 | 71.1 | 65.7 | 74.4 |
| Person | 42.0 | 44.0 | 35.1 | 39.6 | 50.6 | 39.5 | 46.3 | 44.7 | |
| Bicycle | 56.3 | 65.2 | 62.5 | 62.0 | 76.7 | 65.0 | 62.9 | 64.7 | |
| Car | 95.0 | 95.2 | 95.0 | 94.7 | 96.2 | 95.2 | 94.8 | 95.2 | |
| Motorcycle | 74.5 | 78.5 | 76.3 | 78.6 | 78.6 | 72.3 | 74.0 | 79.0 | |
| F-S vehicle | 75.6 | 73.0 | 78.1 | 62.0 | 86.5 | 83.6 | 50.7 | 88.4 | |
| Recall (%) | All | 59.4 | 59.4 | 57.5 | 60.7 | 61.5 | 59.3 | 60.1 | 61.1 |
| Person | 52.0 | 50.0 | 40.0 | 50.4 | 51.0 | 49.6 | 53.9 | 47.9 | |
| Bicycle | 9.0 | 11.8 | 7.5 | 12.0 | 12.1 | 10.9 | 10.4 | 8.0 | |
| Car | 93.4 | 93.7 | 93.1 | 91.9 | 94.9 | 94.1 | 89.8 | 94.6 | |
| Motorcycle | 66.2 | 69.8 | 69.2 | 69.9 | 68.6 | 65.9 | 66.7 | 75.3 | |
| F-S vehicle | 76.5 | 71.8 | 77.7 | 79.5 | 81.2 | 75.7 | 79.5 | 79.5 | |
| mAP (%) | All | 49.8 | 51.5 | 50.2 | 51.3 | 54.3 | 50.3 | 50.4 | 52.6 |
| Person | 26.5 | 31.0 | 20.8 | 50.2 | 51.3 | 54.3 | 50.3 | 52.6 | |
| Bicycle | 7.7 | 10.0 | 6.7 | 10.6 | 11.4 | 8.9 | 8.7 | 7.3 | |
| Car | 91.4 | 91.0 | 91.7 | 89.3 | 92.8 | 92.9 | 87.3 | 92.9 | |
| Motorcycle | 51.4 | 57.3 | 59.0 | 57.7 | 56.8 | 50.8 | 51.7 | 61.9 | |
| F-S vehicle | 72.0 | 68.2 | 72.7 | 72.0 | 78.1 | 70.6 | 72.5 | 73.8 |
| Class | RGB | RGB + D | RGB + V | RGB + I | RGB + DV | RGB + DI | RGB + VI | RGB + DVI | |
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | All | 72.0 | 73.8 | 68.6 | 69.2 | 68.6 | 65.3 | 63.8 | 64.0 |
| Person | 44.3 | 37.3 | 39.6 | 36.9 | 37.1 | 41.7 | 44.1 | 36.3 | |
| Bicycle | 76.9 | 78.3 | 67.5 | 73.4 | 68.5 | 72.3 | 64.2 | 64.4 | |
| Car | 95.8 | 95.0 | 95.7 | 95.9 | 96.0 | 96.0 | 95.0 | 95.5 | |
| Motorcycle | 78.9 | 72.4 | 75.2 | 73.8 | 70.3 | 74.0 | 76.7 | 76.1 | |
| F-S vehicle | 64.1 | 86.1 | 65.0 | 66.0 | 71.3 | 42.8 | 38.8 | 47.4 | |
| Recall (%) | All | 57.4 | 56.0 | 58.8 | 57.7 | 57.2 | 58.8 | 57.3 | 56.9 |
| Person | 42.2 | 43.9 | 50.5 | 46.0 | 47.2 | 49.9 | 45.2 | 41.2 | |
| Bicycle | 8.4 | 10.3 | 8.1 | 9.1 | 8.8 | 7.5 | 8.2 | 6.8 | |
| Car | 91.0 | 94.3 | 91.9 | 91.9 | 92.2 | 85.8 | 85.2 | 87.5 | |
| Motorcycle | 63.9 | 54.7 | 60.9 | 58.6 | 54.6 | 66.4 | 65.8 | 64.2 | |
| F-S vehicle | 81.4 | 77.0 | 82.7 | 83.2 | 83.2 | 84.2 | 82.7 | 84.7 | |
| mAP (%) | All | 48.9 | 47.5 | 48.8 | 50.2 | 47.9 | 46.6 | 44.9 | 45.0 |
| Person | 24.9 | 20.8 | 25.7 | 23.6 | 22.9 | 25.1 | 24.7 | 21.3 | |
| Bicycle | 7.8 | 9.9 | 7.2 | 8.5 | 7.5 | 6.7 | 7.2 | 5.0 | |
| Car | 90.2 | 92.7 | 90.0 | 89.8 | 90.8 | 84.3 | 83.8 | 86.2 | |
| Motorcycle | 52.8 | 42.1 | 49.4 | 50.4 | 44.0 | 53.3 | 55.2 | 53.4 | |
| F-S vehicle | 69.0 | 71.9 | 71.6 | 78.5 | 74.1 | 63.8 | 53.6 | 59.4 |
| Class | RGB + VI (YOLOv3, 1ROI) | RGB + DVI (YOLOv3, 2ROI) | RGB + V (YOLOv4, 1ROI) | RGB VI (YOLOv4, 2ROI) | RGB + DVI (YOLOv3, 1ROI) | RGB + DV (YOLOv3, 2ROI) | RGB + I (YOLOv4, 1ROI) | RGB + I (YOLOv4, 2ROI) | |
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | All | 79.5 | 61.7 | 82.9 | 62.1 | 77.2 | 77.5 | 81.1 | 69.2 |
| Person | 56.2 | 36.8 | 59.8 | 36.7 | 56.5 | 50.6 | 55.0 | 36.9 | |
| Bicycle | 72.0 | 73.5 | 93.8 | 55.0 | 81.1 | 75.7 | 73.4 | 73.4 | |
| Car | 94.5 | 81.9 | 94.2 | 86.3 | 92.8 | 96.2 | 95.7 | 95.9 | |
| Motorcycle | 85.6 | 68.7 | 81.6 | 74.5 | 84.0 | 78.6 | 84.1 | 73.8 | |
| F-S vehicle | 88.9 | 47.3 | 85.1 | 57.8 | 71.6 | 86.5 | 97.1 | 66.0 | |
| Recall (%) | All | 54.4 | 57.9 | 47.8 | 53.5 | 49.8 | 61.5 | 46.6 | 57.7 |
| Person | 40.0 | 40.2 | 33.5 | 36.2 | 37.6 | 51.0 | 32.5 | 46.0 | |
| Bicycle | 4.0 | 6.6 | 2.7 | 1.3 | 4.4 | 12.1 | 5.4 | 9.1 | |
| Car | 92.9 | 90.0 | 89.8 | 87.9 | 93.0 | 94.9 | 93.4 | 91.9 | |
| Motorcycle | 63.7 | 75.1 | 49.4 | 65.2 | 67.7 | 68.6 | 51.4 | 58.6 | |
| F-S vehicle | 71.3 | 77.2 | 63.6 | 77.0 | 46.3 | 81.2 | 50.5 | 83.2 | |
| mAP (%) | All | 49.2 | 44.4 | 42.7 | 44.5 | 43.6 | 54.3 | 42.8 | 50.2 |
| Person | 26.5 | 20.4 | 21.0 | 19.2 | 22.9 | 32.4 | 20.3 | 23.6 | |
| Bicycle | 3.9 | 5.9 | 2.5 | 1.1 | 4.4 | 11.4 | 5.4 | 8.5 | |
| Car | 89.7 | 86.1 | 86.0 | 83.4 | 90.5 | 92.8 | 91.0 | 89.8 | |
| Motorcycle | 56.2 | 61.2 | 43.4 | 55.8 | 57.2 | 56.8 | 46.9 | 50.4 | |
| F-S vehicle | 70.0 | 48.4 | 60.8 | 63.2 | 43.0 | 78.1 | 50.2 | 78.5 |
| Class | RGB + DV (FP32) (YOLOv3, 2ROI) | RGB + DV (FP16) (YOLOv3, 2ROI) | RGB + DV (INT8) (YOLOv3, 2ROI) | RGB + Radar (Late Fusion) (YOLOv3, 2ROI) | |
|---|---|---|---|---|---|
| Precision (%) | All | 77.5 | 77.5 | 73.1 | 48.2 |
| Person | 50.6 | 50.7 | 44.8 | 37.5 | |
| Bicycle | 75.7 | 74.3 | 66.4 | 15.1 | |
| Car | 96.2 | 96.3 | 95.5 | 94.2 | |
| Motorcycle | 78.6 | 78.7 | 75.7 | 65.6 | |
| F-S vehicle | 86.5 | 87.2 | 83.3 | 28.5 | |
| Recall (%) | All | 61.5 | 61.5 | 62.2 | 61.8 |
| Person | 51.0 | 50.6 | 50.6 | 52.7 | |
| Bicycle | 12.1 | 11.9 | 12.7 | 6.5 | |
| Car | 94.9 | 94.8 | 95.5 | 92.9 | |
| Motorcycle | 68.6 | 68.8 | 68.7 | 71.3 | |
| F-S vehicle | 81.2 | 81.2 | 83.7 | 85.6 | |
| mAP (%) | All | 54.3 | 54.2 | 54.1 | 47.5 |
| Person | 32.4 | 32.1 | 29.6 | 28.1 | |
| Bicycle | 11.4 | 11.0 | 11.2 | 28.1 | |
| Car | 92.8 | 92.8 | 93.5 | 90.6 | |
| Motorcycle | 56.8 | 56.9 | 57.0 | 56.8 | |
| F-S vehicle | 78.1 | 78.1 | 79.1 | 57.3 |
| Class | RGB + DV (Proposed) (YOLOv3, 2ROI) | RGB + Radar (Late Fusion) (YOLOv3, 2ROI) | |
| Precision (%) | All | 86.4 | 92.5 |
| Person | 77.2 | 87.2 | |
| Bicycle | n/a | n/a | |
| Car | 98.2 | 96.7 | |
| Motorcycle | 79.3 | 91.7 | |
| F-S vehicle | 91.0 | 94.6 | |
| Recall (%) | All | 87.0 | 76.5 |
| Person | 80.0 | 51.4 | |
| Bicycle | n/a | n/a | |
| Car | 96.9 | 92.5 | |
| Motorcycle | 81.4 | 75.5 | |
| F-S vehicle | 89.6 | 86.6 | |
| mAP (%) | All | 84.2 | 73.8 |
| Person | 71.4 | 47.8 | |
| Bicycle | n/a | n/a | |
| Car | 95.7 | 91.0 | |
| Motorcycle | 79.0 | 71.9 | |
| F-S vehicle | 86.9 | 84.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, J.-J.; Guo, J.-I.; Shivanna, V.M.; Chang, S.-Y. Deep Learning Derived Object Detection and Tracking Technology Based on Sensor Fusion of Millimeter-Wave Radar/Video and Its Application on Embedded Systems. Sensors 2023, 23, 2746. https://doi.org/10.3390/s23052746
Lin J-J, Guo J-I, Shivanna VM, Chang S-Y. Deep Learning Derived Object Detection and Tracking Technology Based on Sensor Fusion of Millimeter-Wave Radar/Video and Its Application on Embedded Systems. Sensors. 2023; 23(5):2746. https://doi.org/10.3390/s23052746
Chicago/Turabian StyleLin, Jia-Jheng, Jiun-In Guo, Vinay Malligere Shivanna, and Ssu-Yuan Chang. 2023. "Deep Learning Derived Object Detection and Tracking Technology Based on Sensor Fusion of Millimeter-Wave Radar/Video and Its Application on Embedded Systems" Sensors 23, no. 5: 2746. https://doi.org/10.3390/s23052746
APA StyleLin, J.-J., Guo, J.-I., Shivanna, V. M., & Chang, S.-Y. (2023). Deep Learning Derived Object Detection and Tracking Technology Based on Sensor Fusion of Millimeter-Wave Radar/Video and Its Application on Embedded Systems. Sensors, 23(5), 2746. https://doi.org/10.3390/s23052746