1. Introduction
It is of utmost importance to conserve endangered whale populations which are declining due to various reasons, such as striking by ships/vessels, entangling with fishing gear, and global warming. Automated acoustic monitoring has been used for monitoring marine species such as whales. Recorded acoustic samples let us listen and analyze sounds from soniferous whales for their identification. As sound travels quicker than light underwater, it is good to do acoustic monitoring than video surveillance for identifying endangered whales. However, accurate acoustic identification of endangered whale calls (vocalizations) is still difficult, especially when a whale population is getting dangerously small and the size of the available data samples is also too small.
Blue whales (
Balaenoptera musculus) are the largest of the baleen whales and are endangered worldwide [
1]. Blue whale calls are low-frequency (20–100 Hz) and repetitive [
2]. Blue whales are known to produce downswept FM (frequency-modulated) calls that are often referred as D-calls. Both male and female blue whales have been found to produce such calls [
3]. On the contrary, it is observed that only males produce song, and with that, these calls are associated with the breeding season. Thus, blue whale song apparently carries information about the population. Similarly, fin whales (
Balaenoptera physalus) are listed as endangered species, which also produce low-frequency vocalizations (i.e., <100 Hz) [
4,
5]. Single vocalizations, in particular, are generated by male fin whales, whereas songs in the form of pulse trains can occur at high sound pressure that can be detected over a long distance (e.g., >50 km) [
6]. In locations of high fin whale density, the songs and single vocalizations of numerous fin whales do overlap in time and frequency, producing the so-called fin whale chorus [
6].
The development of robust deep learning methods to identify whales or finding when and where each whale population occurs is getting much attention. Recent abundance estimates using acoustic whale calls can aid assessment of the current status of each identified whale population, especially for blue whales and fin whales whose population sizes are critically decaying. This status assessment thus provides us the basis to a proper management plan for the conservation of endangered whale populations.
Deep learning motivation is greatly deduced by artificial intelligence (AI), which simulates the ability of the human brain in terms of analyzing, making decisions, and learning. The AI-enabled technique, such as deep learning, is quickly becoming a mainstream technology that can analyze large volumes of data and potentially unlock insights, especially in ocean monitoring applications. Deep learning can be defined as a technique of machine learning to learn useful features directly from given sounds, images, and texts. The core of deep learning is hieratically computing features and representing information, such as defining the features starting from a low level to high level. Different hidden layers are involved in making decisions by using the feedback from one layer to the previous one, or the resulting layer will have been fed into the first layer. Therefore, many layers are exploited by deep learning for nonlinear data processing of supervised or unsupervised feature extraction for classification and pattern recognition. It is difficult for a computer to understand complex data, such as an image or a sequence of data of a complex nature, so deep learning algorithms are used instead of usual learning methods. The conventional methods have been overtaken by deep learning methods which can detect and classify objects in complex scenarios. Deep learning can thus help us to create better ocean acoustic detection and classification models.
Recently, a few studies have been reported about the deep learning methods developed for blue whale and fin whale monitoring. In the Ref. [
2], Siamese neural networks (SNN) were utilized to detect/classify blue whale calls from the acoustic recordings. The method classified calls from four populations of blue whales providing the highest accuracy of 94.30% for Antarctic blue whale calls, while the lowest accuracy of 90.80% was provided for the central Indian Ocean (CIO) blue calls. Studies in the Ref. [
3] showed that the DenseNet-automated blue whale D-Call detector, which is based on conventional Convolutional Neural Networks (CNN) provided better results in terms of detection probability than that of human observers’ analyses, particularly at low and medium signal-to-noise ratios (SNRs). Higher detection probabilities (0.905 and 0.910 for low and medium SNRs) were obtained compared to the detection probabilities obtained by human observers’ analyses (0.699 and 0.697 for low and medium SNRs). In the Ref. [
3], a long-term recording dataset, particularly the Australian Antarctic Division’s “Casey2019” dataset was used for the results. In the Ref. [
7], a two-stage deep-learning approach was developed based on a region-based convolutional neural network (rCNN) and following CNN to automatically detect/classify both blue whale D-calls and fin whale 40-Hz calls. In stage 1, the detection of regions of interests (ROIs) containing potential calls was performed using rCNN. In stage 2, a CNN was employed to classify the target whale calls from the detected ROIs. The work in the Ref. [
8] presents an application of deep learning for automatic identification of fin whale 20 Hz calls, which are sometimes contaminated with other sources, such as shipping and earthquakes. All of these recently proposed advanced deep-learning-based methods have one common feature—they all require a large dataset for learning.
In this paper, taking advantage of deep nonlinear features of wavelet scattering transform (WST) [
9], we adopted the LSTM [
10] deep learning classifier to automatically detect/classify the endangered whale calls. The proposed method was evaluated for real recorded ocean acoustic data from the northeast (NE) Pacific, giving high performances in terms of classification results with a small dataset.
The main contributions of this work are the following: (1) Study of the applicability of the WST to detect/classify endangered whale vocalizations with a small dataset. (2) Incorporation of the temporal contextual information provided by the LSTM network for identification of endangered whale calls. (3) Proposal of an efficient deep-learning-based endangered whale monitoring method from small data samples. (4) To the best of our knowledge, the WST and LSTM techniques together have not been explored for identification of endangered whale calls.
The organization of the paper is as follows.
Section 2 presents the materials and methods related to this study. In
Section 3, the experimental results are described. The discussion is provided in
Section 4.
4. Discussion
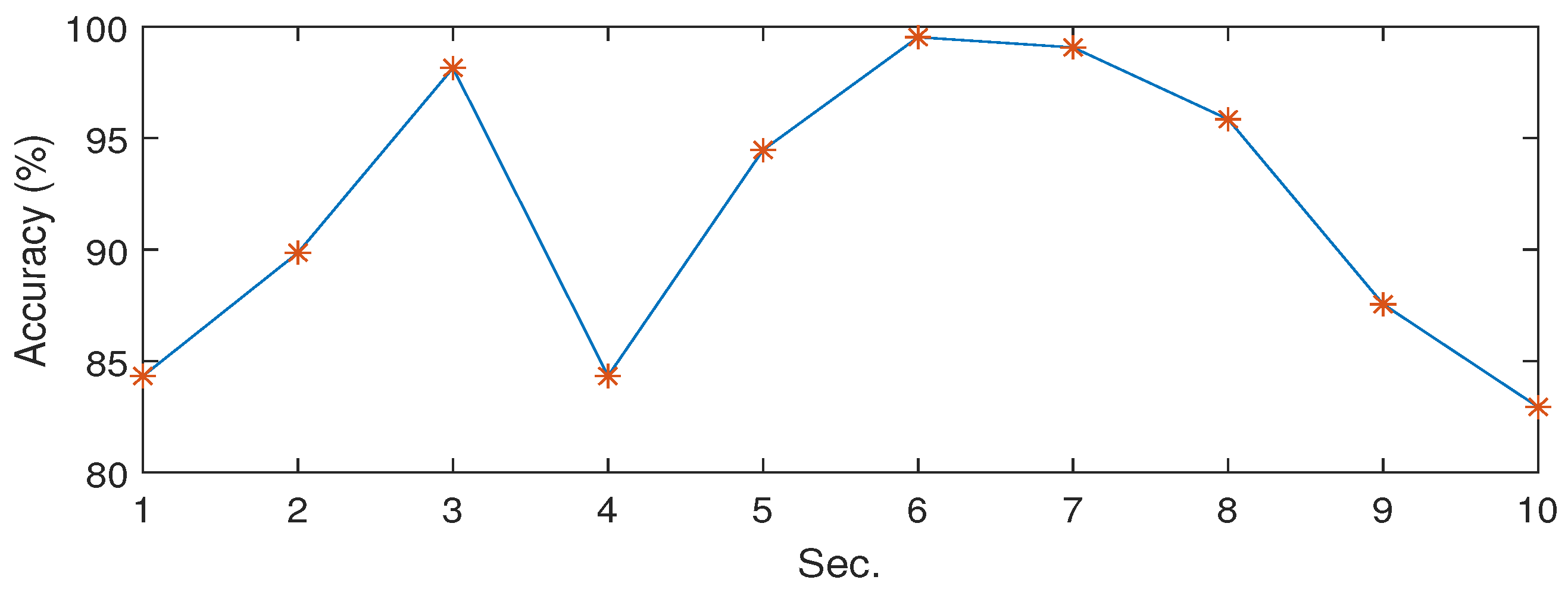
Through the LSTM, the temporal context inside the feature set are fully considered and the nonlinear mapping relationship between the past and future information of the signal are learned. The new approach demonstrates significant improvements in the endangered whale calls identification with high classification results as above 90% with small data samples. The method is also computationally efficient, since only a single epoch for the deep learning process is able to produce high classification accuracies (%), as shown in
Table 2,
Table 3 and
Table 4.
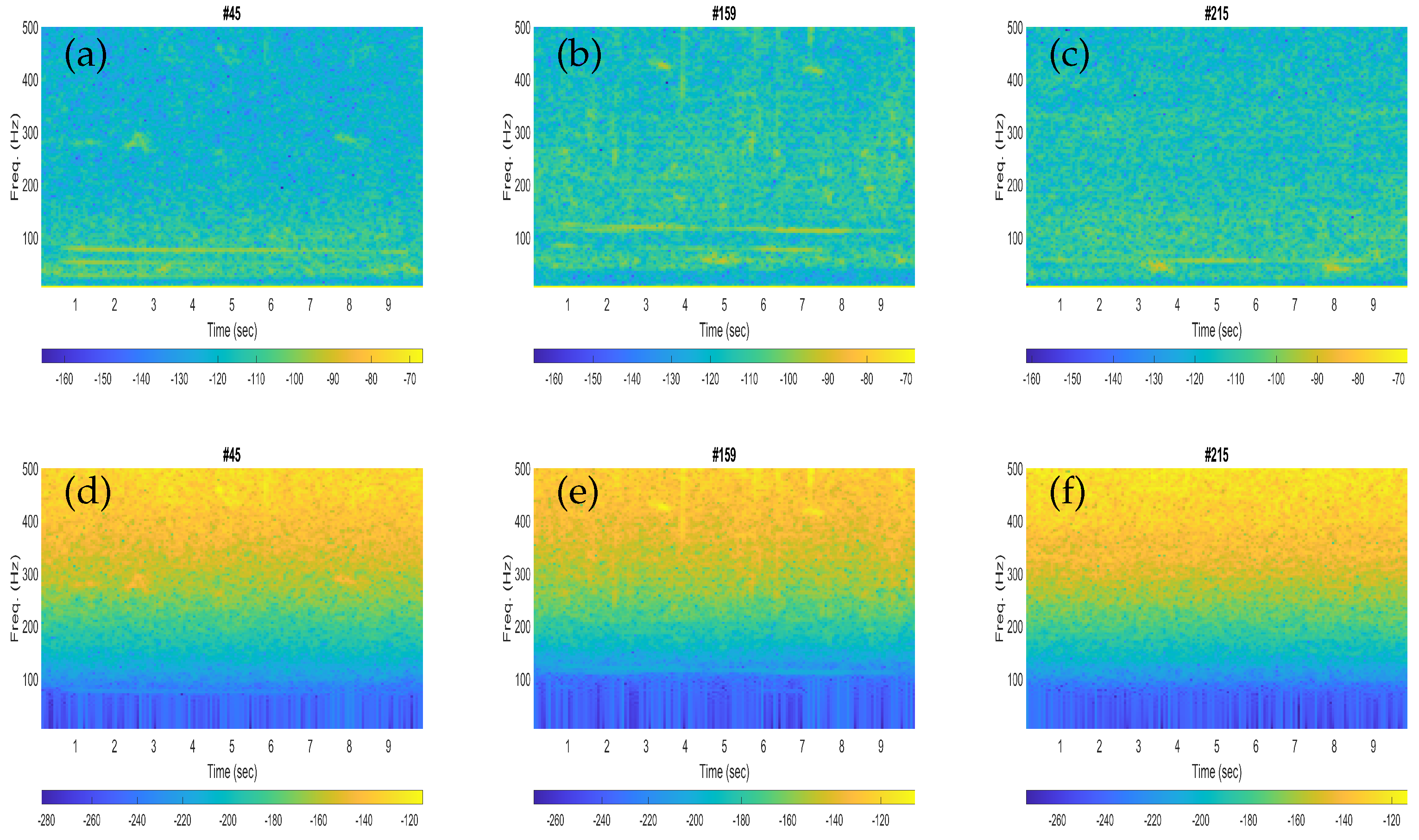
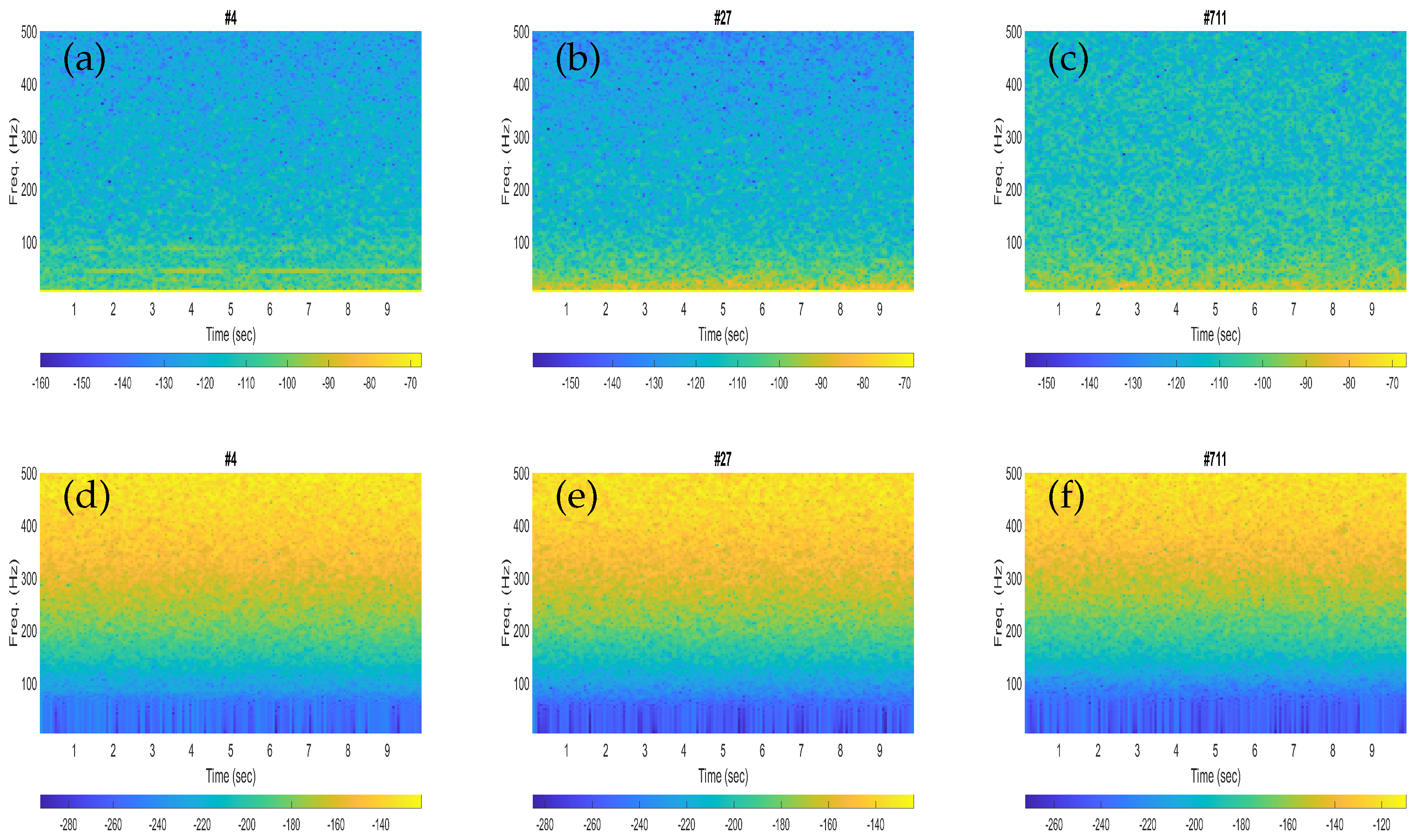
The performances obtained with the fin whales were found to be slightly better than that of the blue whales in terms of higher classification scores. This could be clarified from the spectrogram plots of the illustrative blue whale and fin whale calls. For instance, the fin whale 20 Hz pulses are quite prominent in the spectrograms (see
Figure 3b,c), while the blue whale B-calls (40–50 Hz) are less visible in the corresponding spectrogram plots (see
Figure 2a,b). In
Table 2 and
Table 3, the sensitivity represents the correctly classified of the respective whale calls, and the specificity represents the correctly classified of the noise. Then the false positive rates (FPRs) obtained from the specificity (%) were found to be as low as 4.39% and 0%, respectively.
In our proposed framework, the variability is linearized by the WST providing invariants to translations through such average pooling. Most importantly, WST comprising the LSTM network can produce good identification results with small sets of training data. In fact, WST can assist us to extract significant features for LSTM in those situations when it is not possible to learn efficient features with the available training data in case of data scarcity. This makes our proposed scheme for use, such as few-shot learning [
29] for identification of endangered whale calls unlike the existing recent deep-learning-based methods [
2,
3,
7,
8] that require large datasets for learning.
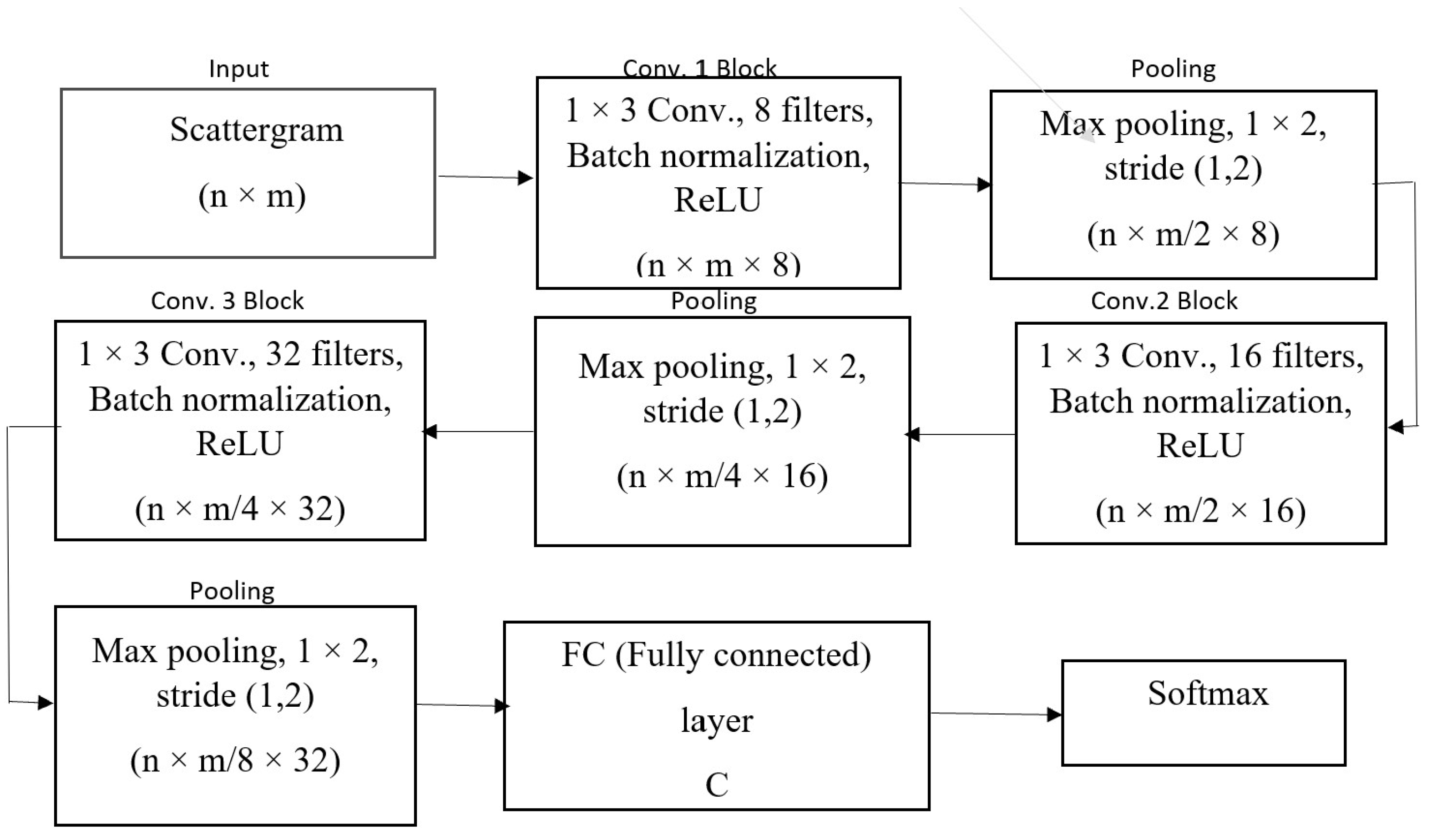
Both LSTM and CNN are deep neural networks, although the design mechanism of LSTM is different than a CNN. Usually, the LSTM is designed to process and perform prediction/classification from sequences of data by exploiting temporal correlation, whereas the CNN is designed to process image data (for example, a 2D scattergram image shown in
Figure 5) for classification by exploiting spatial correlation. The LSTM architecture solved the zero-gradient and exploded gradient, as well as short-term memory problems in RNN. On the other hand, CNN automatically generates complex features at different layers. Basically, WST can be realized as a CNN with fixed filters. In this way, we have a new mechanism here for the classification of endangered whale calls by combining CNN and LSTM. This proposed combined scheme can be efficient, both in terms of classification accuracy and computation.
The proposed method outperforms the relevant state-of-the-art methods based on STFT and LSTM. The presented method provides much-improved classification results even with 1 epoch instead of 10 epochs as used by the comparison method in the learning process. Then the performances of the proposed method is better than the comparison method in terms of classification accuracy as well as computational burden. We have further compared our method with another relevant method based on scattergram and deep CNN, while our method yields better performance. Moreover, the proposed scheme demonstrates high noise resiliency when we compare the results of the proposed scheme and the SVM classifier-based scheme summarized in
Table 5.
To the best of our knowledge, the framework consisting of the WST and LSTM networks has not been investigated for detection/classification of whale calls. The preliminary results are presented in this paper. For future work, we would like to obtain data from noisier environments to make the proposed method more robust by proposing a learned wavelet scattering transform together with optimizing the model parameters of the LSTM network. Moreover, we plan to investigate the method for other critically endangered species, such as the North Atlantic right whale and Sei whale.
Finally, we want to emphasize that the MATLAB source codes will be available upon request to the corresponding author.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}