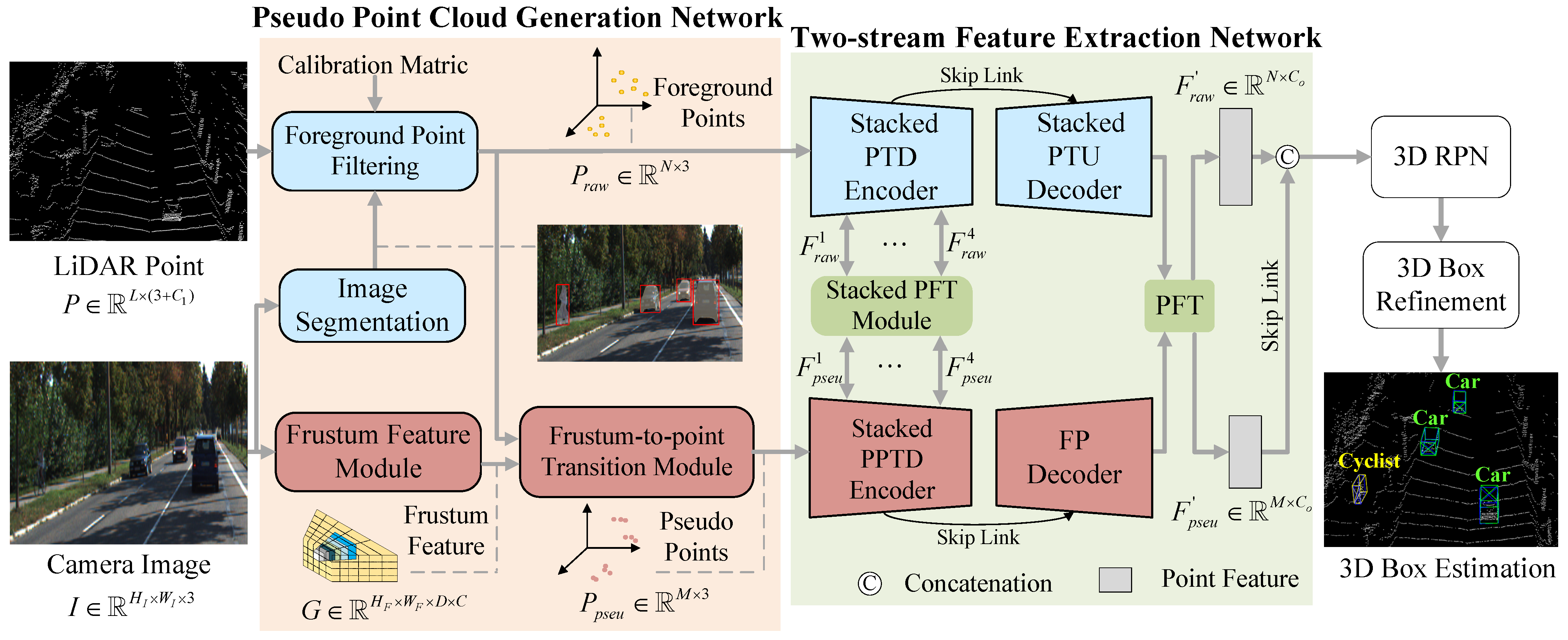
3.1. Pseudo Point Cloud Generation Network
In this network, image was transformed into PPCs which were further utilized to represent image features. During processing, the image depth was predicted in a semi-supervision manner, and LiDAR points were projected onto the image to obtain sparse depth labels, which were used to supervise depth prediction. With the help of the foreground mask from Mask-RCNN [
37] and the predicted depth image, the foreground pixels can be converted into pseudo points. At the same time, adhering to CaDDN [
27], the Frustum Feature Module was used to construct the frustum feature. Then, the PPC features were obtained by interpolating the frustum feature in the Frustum-to-point Transition module.
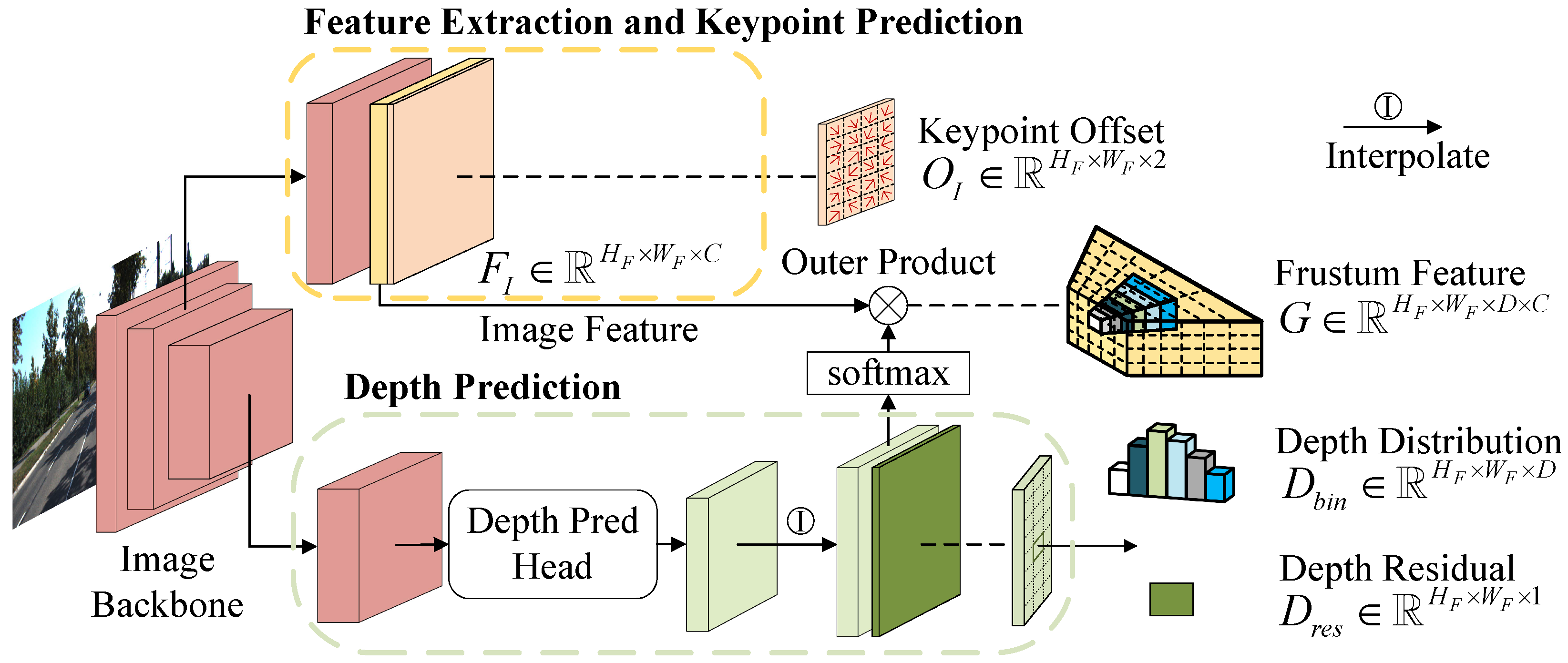
Frustum Feature Module. In order to make full use of the image information, a Frustum Feature module was constructed to generate frustum feature. In
Figure 3, extracting image features and predicting image depth were two fundamental steps. Similar to CaDDN [
27], ResNet-101 [
38] was utilized as the backbone to process images and the output of its Block1 was used to collect image features
, where
,
were the height and width of the image feature, and
C was the number of feature channels.
On the other hand, a depth prediction head was applied to the output of the image backbone to predict image depth. The depth prediction was viewed as a bin-based classification problem and the depth range was discretized into D bins by the discretization strategy LID [
39]. Then the depth distribution
and depth residual
can be obtained.
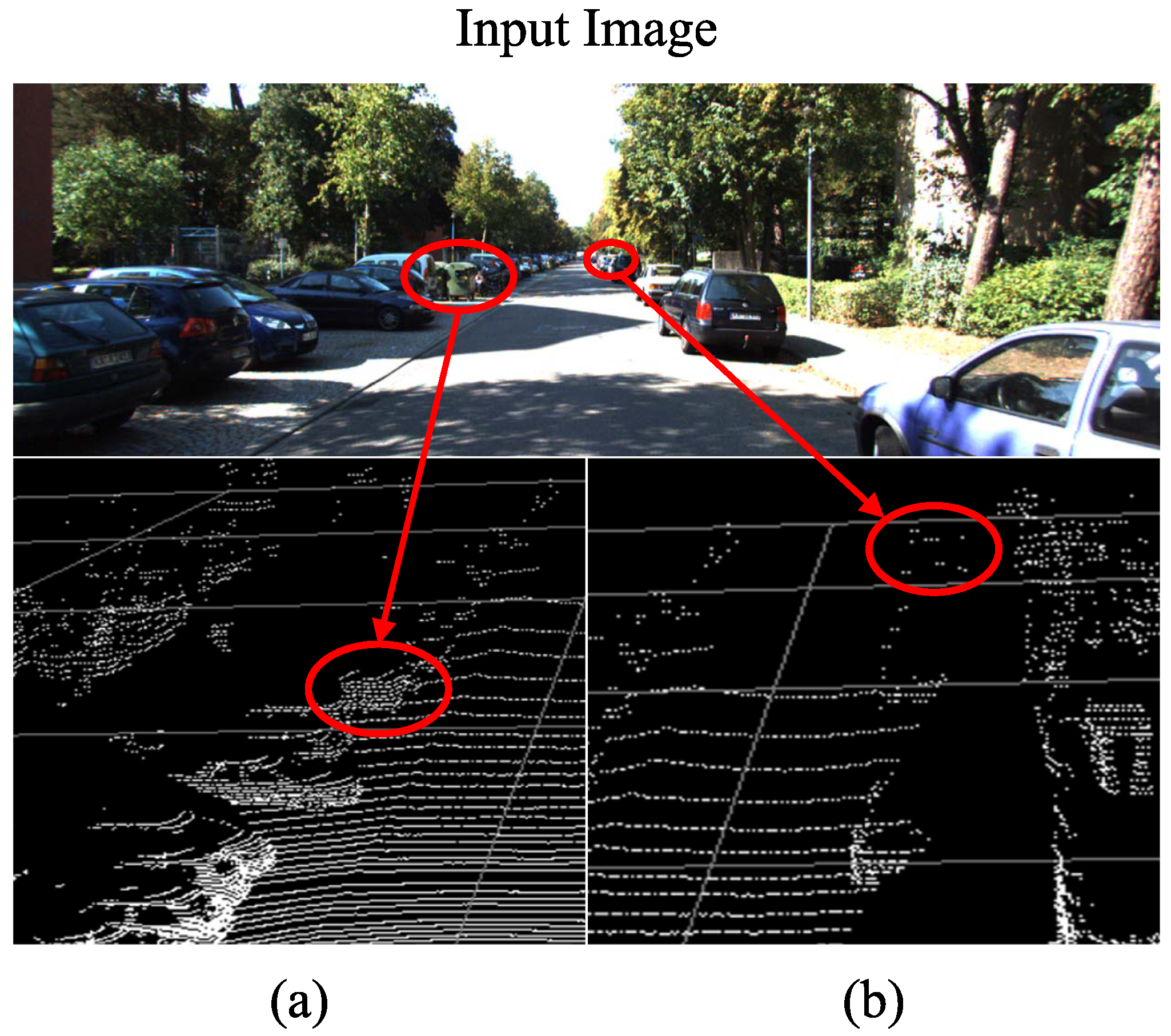
Early depth estimators [
27,
39,
40] computed the loss over the entire image including a large number of background pixels. These methods placed over-emphasis on background regions in depth prediction. According to Qian et al. [
31], background pixels can occupy about 90% of all pixels in the KITTI dataset. Therefore, instead of calculating the loss of all image pixels, the off-the-shelf image segmentation network Mask-RCNN [
37] was employed to select N foreground points from LiDAR points by distinguishing their 2D projection positions. The N points were re-projected onto the image to acquire sparse depth label for calculating the depth loss of foreground pixels. In addition, the foreground loss will be given more weight to balance the contributions of foreground and background pixels.
With the image feature and image depth, the frustum feature
can be constructed as follows
where ⊗ was the outer product and
represented the
function. Equation (
1) stated that at each image pixel, the image features were weighted by the depth distribution values along the depth axis. CNN was known to extract image features in convolutional kernels, where object pixels may be surrounded by the pixels of the background or other objects. In contrast, the frustum feature network lifted image features onto depth bins along the depth axis, which enabled the model to discriminate misaligned features in 3D space.
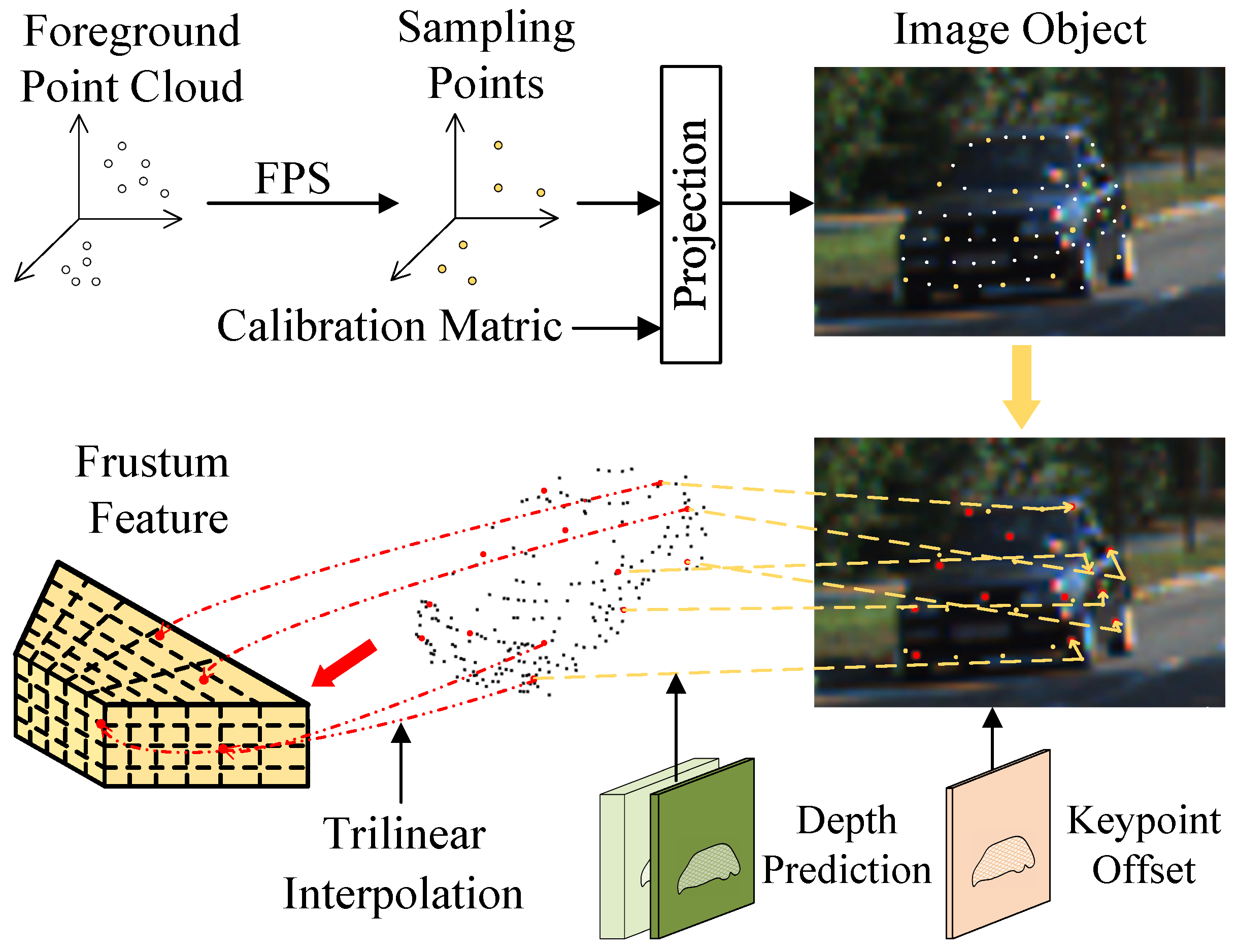
Frustum-to-point Transition Module. The submodule aims to extract the PPC features from frustum feature. There are two issues to be addressed regarding the choice of PPC. First, due to the presence of depth errors, the PPCs converted from image may not be consistent with the distribution of the object in space. Second, the number of PPC is proportional to the image resolution, and the number is generally large. Nevertheless, only in the area where the point cloud is relatively sparse can PPC play an important role by compensating for the missing object information.
For the first issue, we applied the farthest point sampling (FPS) algorithm to select M of the previous N foreground points as the initial PPCs in
Figure 4. Foreground points are used because they have more accurate depth values near the projected positions in the image. Accordingly, the projected coordinates
of M foreground points can be obtained via calibration matrix.
As for the second issue, the object keypoints that focus on more representative object parts are introduced as the final PPCs. Keypoints are defined as locations that reflect the local geometry of an object, such as points on mirrors and wheels. To determine the locations of keypoints in 3D space, inspired by Deformable Convolutional Networks [
41], a 2D keypoint offset was predicted which represented the offset of each pixel on the image to its nearest keypoint. For the M projected coordinates, M keypoint offsets were acquired as follows
where
q enumerated the nearby integral locations of
on the image and
was the bilinear interpolation kernel. Keypoint offset
was predicted when generating image features illustrated in
Figure 3.
Then, the locations of the 2D keypoints can be obtained as
by moving the M pixels according to the corresponding keypoint offsets. With the depth value
of the updated positions, the final PPCs can be determined in camera space. As shown in
Figure 4, the features of the PPCs
can be extracted from the frustum feature
using the trilinear interpolation. Subsequently, in order to process the PPCs features and LiDAR points features simultaneously, the PPC
was re-projected to LiDAR space from the camera space by the transformation function
in KITTI
where
was the final coordinate of the
ith PPC,
was the transformation matrix from the coordinate of color camera to the reference camera, and
was the transformation matrix from the reference camera to LiDAR. To verify the effectiveness of Frustum-to-point Transition module, an alternative directly using M initial foreground points as PPCs and extracting their features in the same way was provided. In
Section 4, the comparison between two strategies on the KITTI dataset will be presented.
Overall, the multi-modal detection task is transformed into single-modal detection by using PPC instead of image to convey object information. The unified point-based representation helps to make subsequent interactions across multi-modal features easier.
3.2. Two-Stream Feature Extraction Network
Multiple multi-modal methods [
10,
13,
15] used a two-stream structure to process image and point cloud separately. Limited by the local receptive field of traditional building blocks, e.g., CNN and sparse convolution, these methods struggled to capture all useful feature relationships. In addition, feature alignment and fusion between image and point cloud were still tricky problems.
Based on the unified point-based representation described above, a two-stream feature extraction network was developed to learn the features of point cloud and image at the point level. The two-stream network was mainly built on a transformer for better feature learning and fusion. It had the inputs of the coordinates of point clouds and the coordinates of PPCs , and the corresponding features were and . Here, the feature of raw point was represented as , where was a one-hot class vector indicating the confidence score of specific class, was the normalized RGB pixel-values of projected location of , and was the reflectance. The feature channel of pseudo point was the same as the image feature channel C.
Point Transition Down. In the two-stream network, a stacked PTD encoder was responsible for iteratively extracting multilevel point-based representations. Based on recent attempts [
24,
25] at object classification, PTD integrated the feature sampling and grouping, self-attention feature extraction and forward-feedback network into a independent module. In
Figure 5, PTD first subsampled M points from the input point
(here
or
can act as
) and use
k-NN algorithm to construct a neighbor embedding for each point. Then, an LBR (Linear layer, BatchNorm layer and ReLU function) operator and a max-pooling operator (MP) were used to encode local features as follows
where
was the feature of point
q which belonged to the neighbor of point
p,
was k-nearest neighbors of point
p in
.
Next, we sent the local feature
into self-attention feature extraction network to learn long-range dependencies of the features. The relationship between the
query (
Q),
key (
K),
value (
V) matrices and self-attention was as follows
where
was the learnable weights of the linear layer and
represented repeat and grouping operation.
were the outputs after repeat and grouping operation related to the input
Q,
K, and
V. Furthermore, a position encoding defined as
was added to the attention, where
,
were the coordinates of points
i and
j.
and
both consisted of two linear layers and a ReLU function. Thereafter, the output of PTD could be derived as
where
represented the element-wise product, + denoted channel-wise summation along the neighborhood axis, and
was an LBR operator.
In the point cloud branch, the stacked PTD encoder (including four PTD modules) was used to learn point cloud features. In the PPC branch, the PPTD encoder adopted the same structure to extract image features.
Point Transition Up. In the point cloud branch, the stacked PTU decoder aimed to restore the point cloud to its initial number and obtained the multi-scale features for proposal generation. PTU can be easily constructed by replacing the feature sampling and grouping in PTD with the inverse distance-weighted average operation while keeping the other structures intact. The inverse distance-weighted average operation was proposed as the skip connection in PointNet++ [
19]
where
,
was the coordinate of the interpolated point,
was the coordinate of the neighboring point of
,
denoted the Euclidean distance between two points, and
denoted the interpolated features of
. Let
,
be the same settings in PointNet++ [
19], then, the interpolated features were added by the skip connection features as
where
was the
n-th output of the PTD and
was the interpolated feature of the
n-th PTU.
was used as the input of the remaining structure of the
n-th PTU. On the contrary, in the PPC branch, a stacked FP decoder with four FP layers was used to recover the initial PPCs. Since the position of the PPC was defined on the object keypoint, the distribution of the PPC was more focused on the object surface than the point cloud directly sampled from the LiDAR. Meanwhile, considering the large memory and time overhead of PTU itself, the FP layer was selected to handle the PPC that did not require a large receptive field.
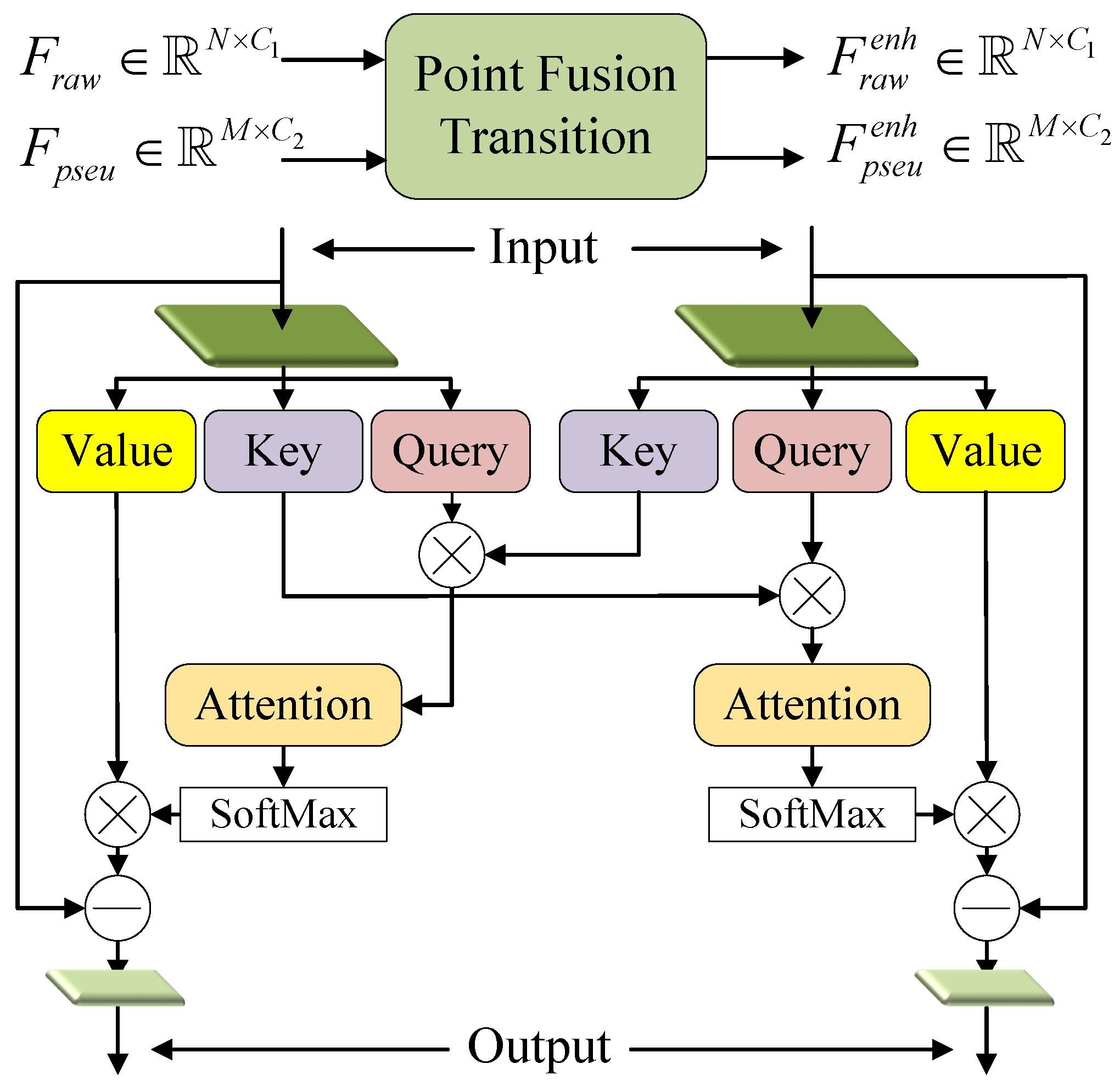
Point Fusion Transition. According to the above introduction, the stacked PTD encoders of the two branches simultaneously extracted point-based features layer-by-layer. However, the features from the point cloud branch lacked the semantic and textural information about the object, and the features from the PPC branch lacked the geometry information for locating the object. Moreover, both the point cloud provided by LiDAR and the image-generated PPC were inevitably contaminated by noise. To address these problems, a dual input and dual output PFT module was designed for feature fusion in
Figure 6. PFT fused two input features based on cross-attention and produced two enhanced features as the inputs to the next level. Finally, an additional PFT was used to fuse the outputs of the two branches (see
Figure 2) to obtain the final point representations.
PFT module was also based on transformer and the
Q,
K, and
V matrices were generated separately for the two inputs
where
and
were both learnable weights. Then, the cross-attention for each data is defined as
where
and
both comprised two linear layers and a ReLU function. Here, we multiplied the
K matrix of one modality by the
Q matrix of the other modality to generate cross-attention. It differed from the way computed in PTD. This practice was inspired by HVPR [
42] which took voxel-based features as queries and computed matching probabilities between the voxel-based features and the memory items through dot product. In
Section 4, we conducted ablation experiments to compare the effects of different attention calculation ways. Finally, the enhanced features as the outputs of PFT can be expressed as
It was worth mentioning that Zhang et al. [
34] proposed a similar structure to PFT. However, they had the limitations that the information can only flow from the image domain to the point domain. In contrast, PFT conducted bidirectional information exchange which provided semantic information for point cloud and geometry information for PPC.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}