



Reinforcement and Curriculum Learning for Off-Road Navigation of an UGV with a 3D LiDAR

Abstract
:1. Introduction
- Generation of virtual 2D traversability ranges from a 3D laser scan, using a Random Forest (RF) classifier trained with synthetic data.
- Implementation of an Actor–Critic RL scheme, which has been trained in simulated scenarios of increasing difficulty with CL.
- Testing autonomous navigation on natural environments with the Actor NN in both simulated and real experiments.
2. Related Work
2.1. Non-Trained Methods
2.2. Data Trained Methods
2.2.1. Reinforcement Learning (RL)
2.2.2. Curriculum Learning (CL)
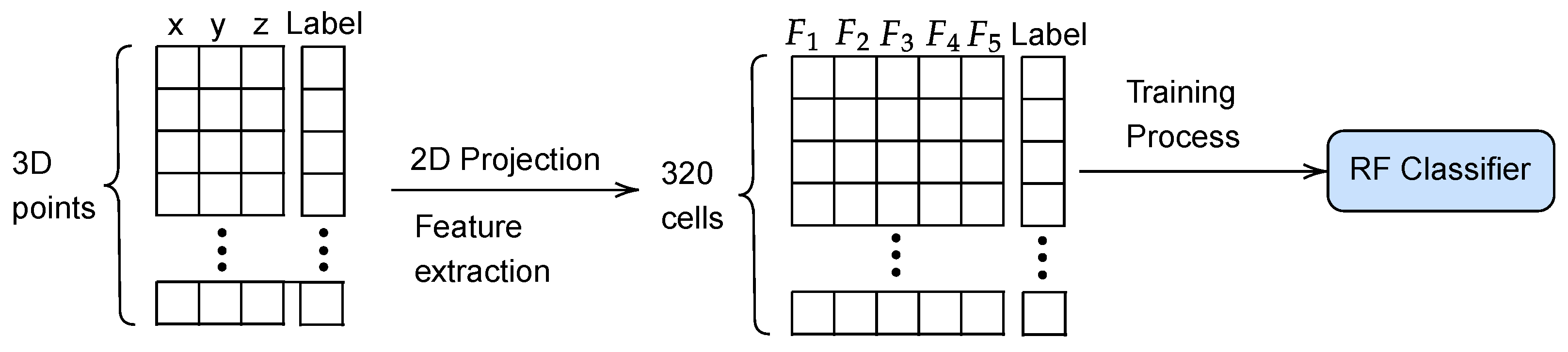
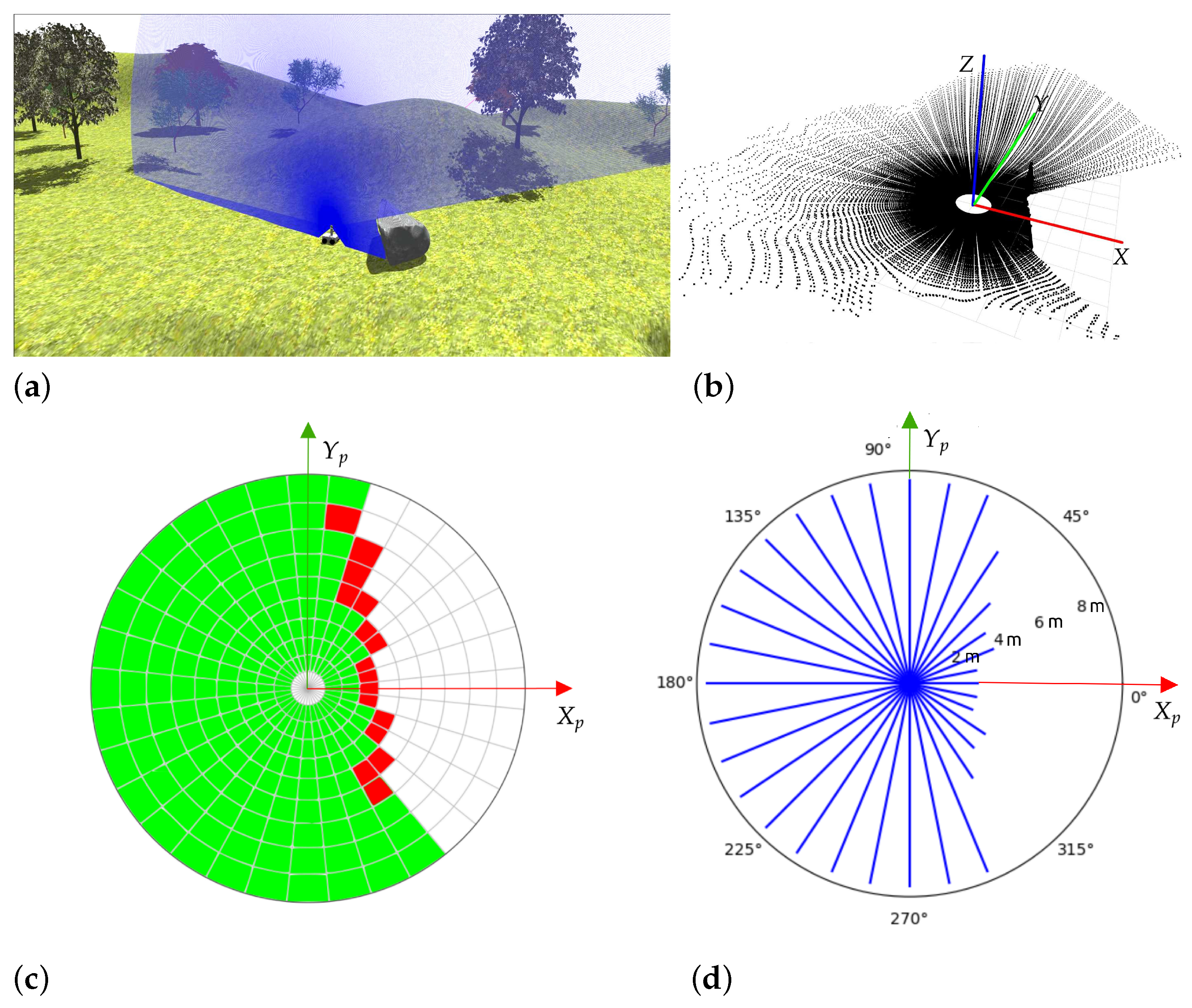
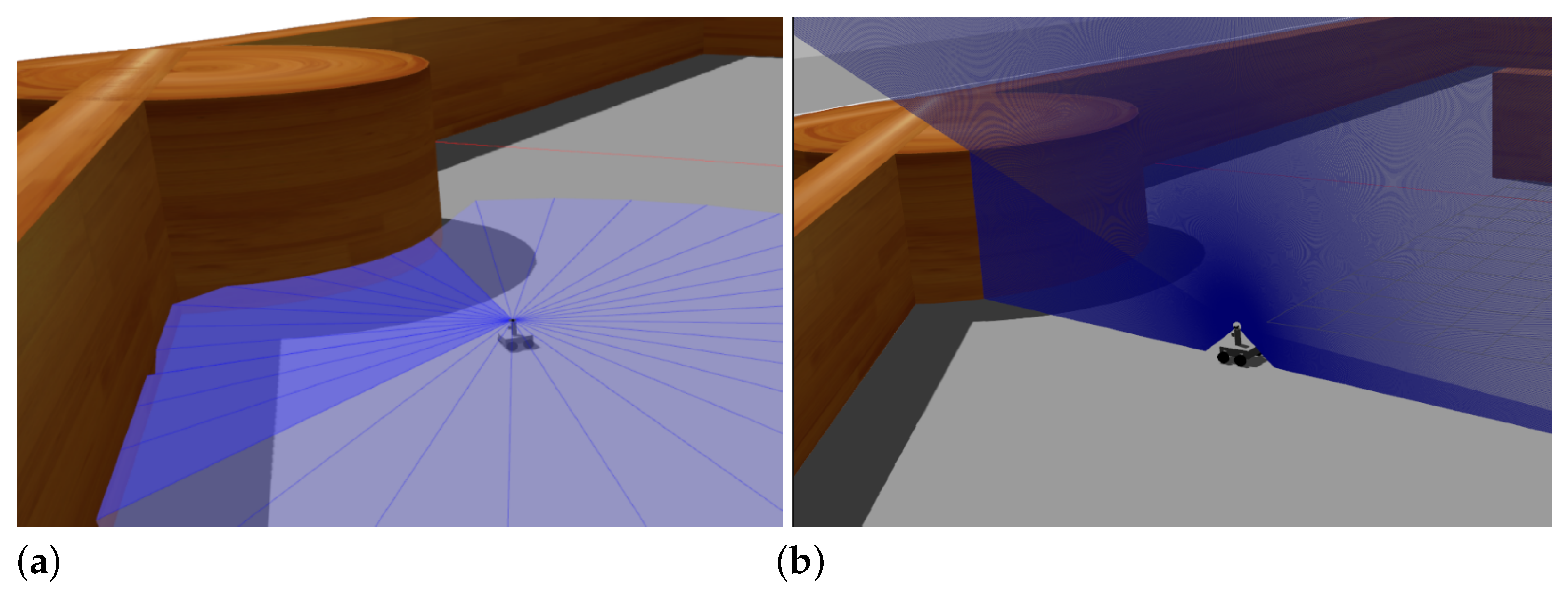
3. Virtual 2D Traversability Scanner
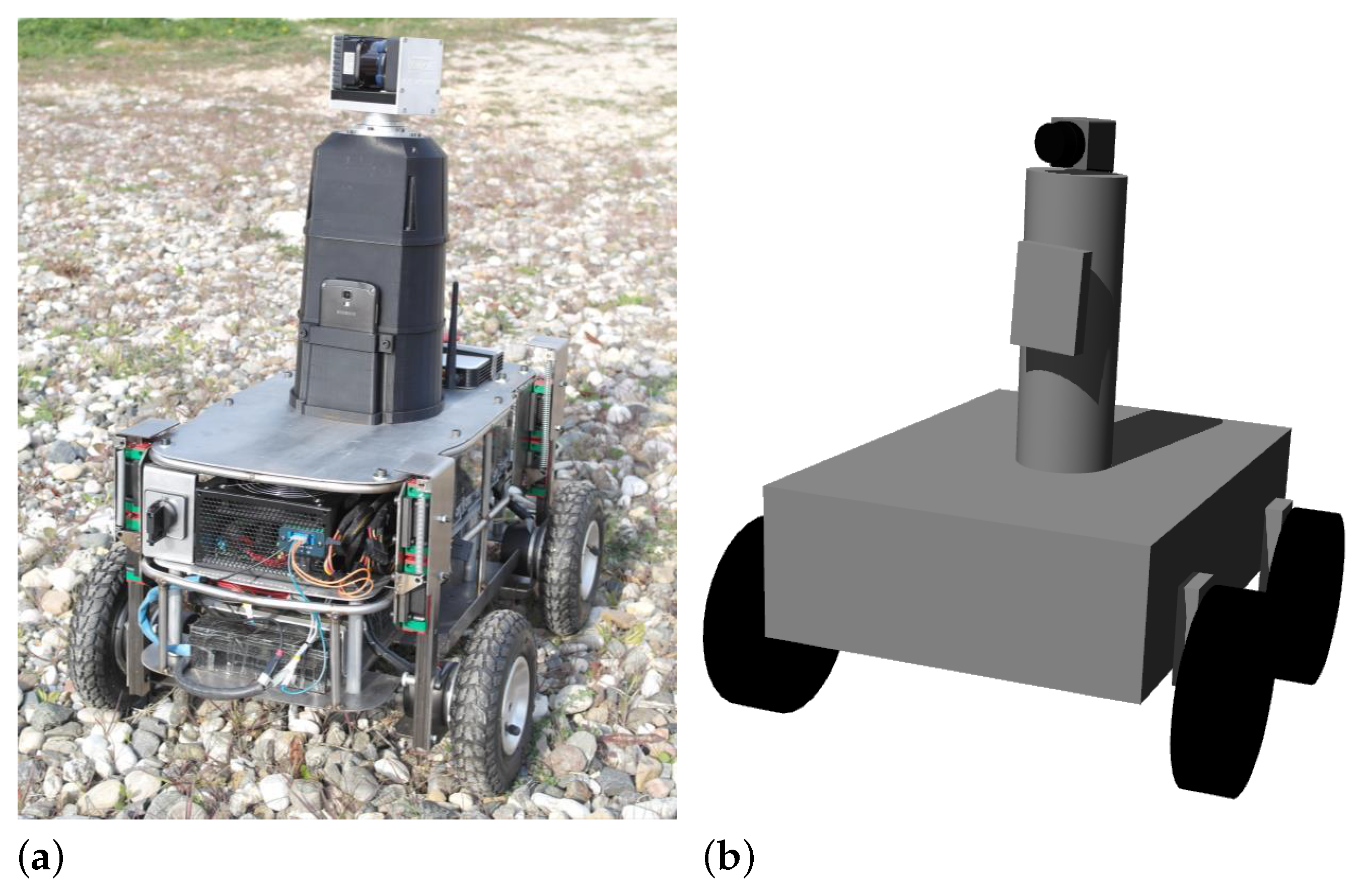
3.1. Case Study
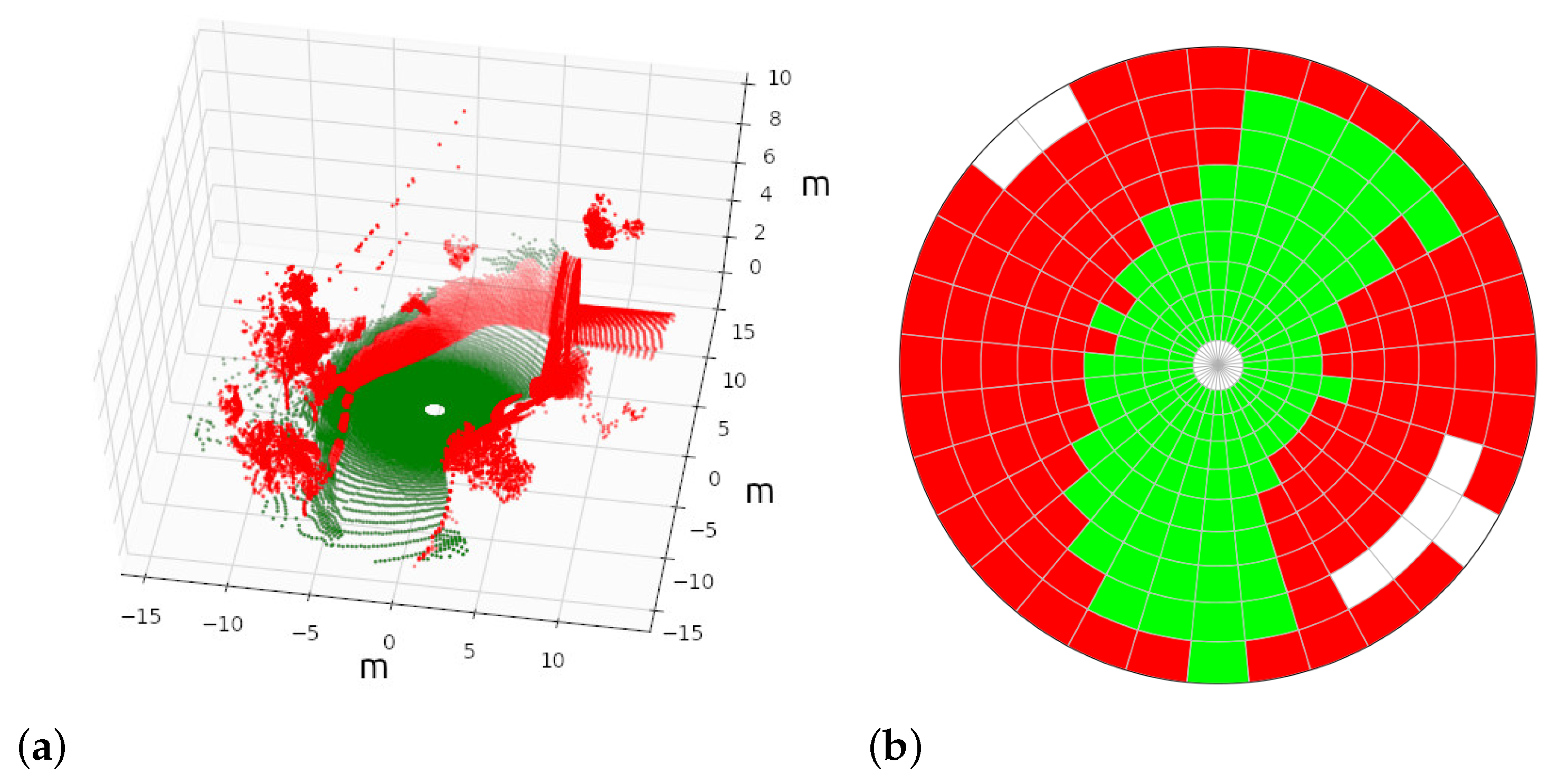
3.2. Traversability Assesment
- If the cell does not contain enough points to compute geometric features (i.e., five), it is labeled as empty in white.
- If at least 15% of points are non-traversable, the cell is classified as non-traversable in red.
- In another case, i.e., with more than 85% of traversable points, the cell is classified as traversable in green.
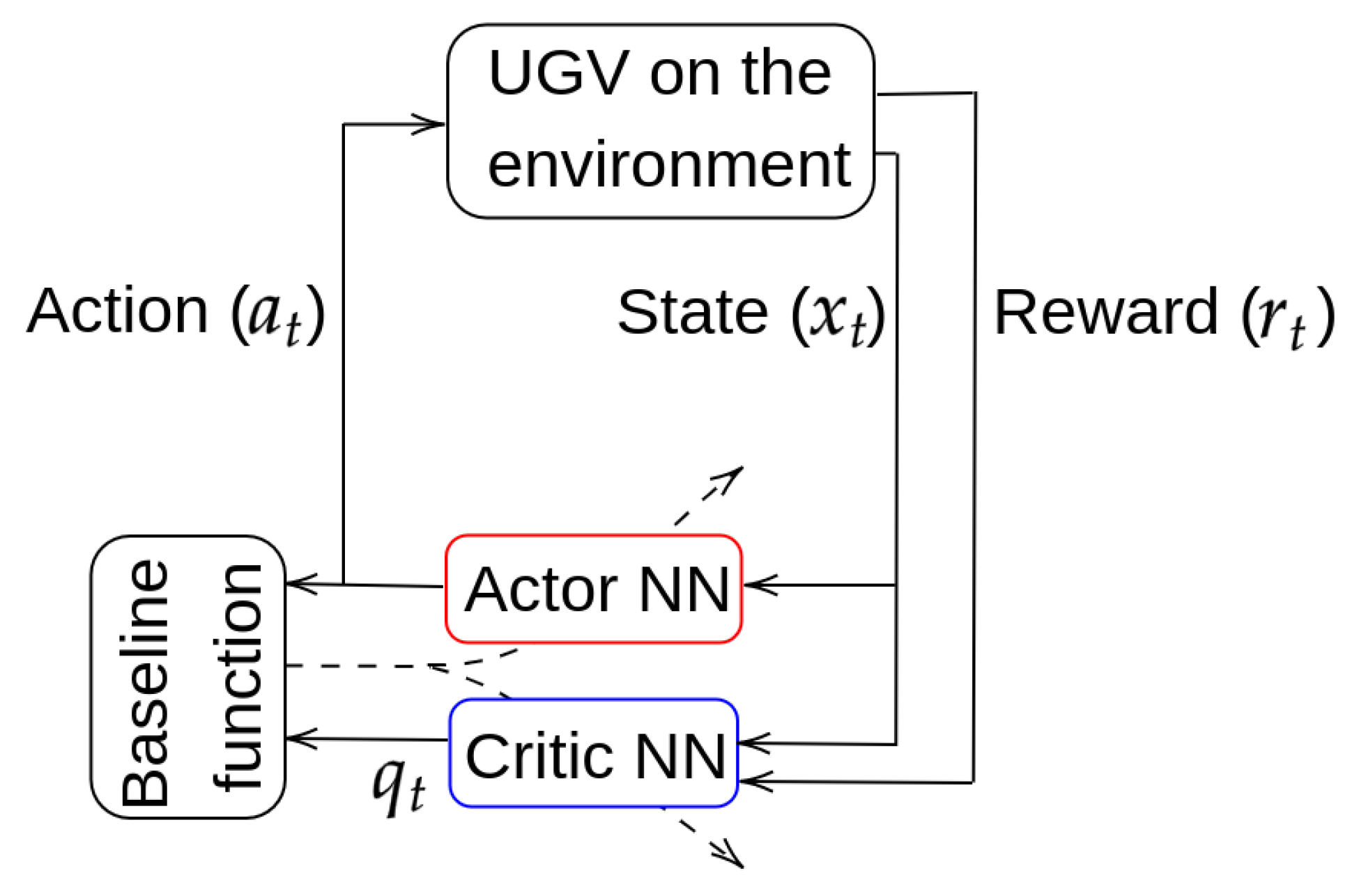
4. Deep Reinforcement Learning
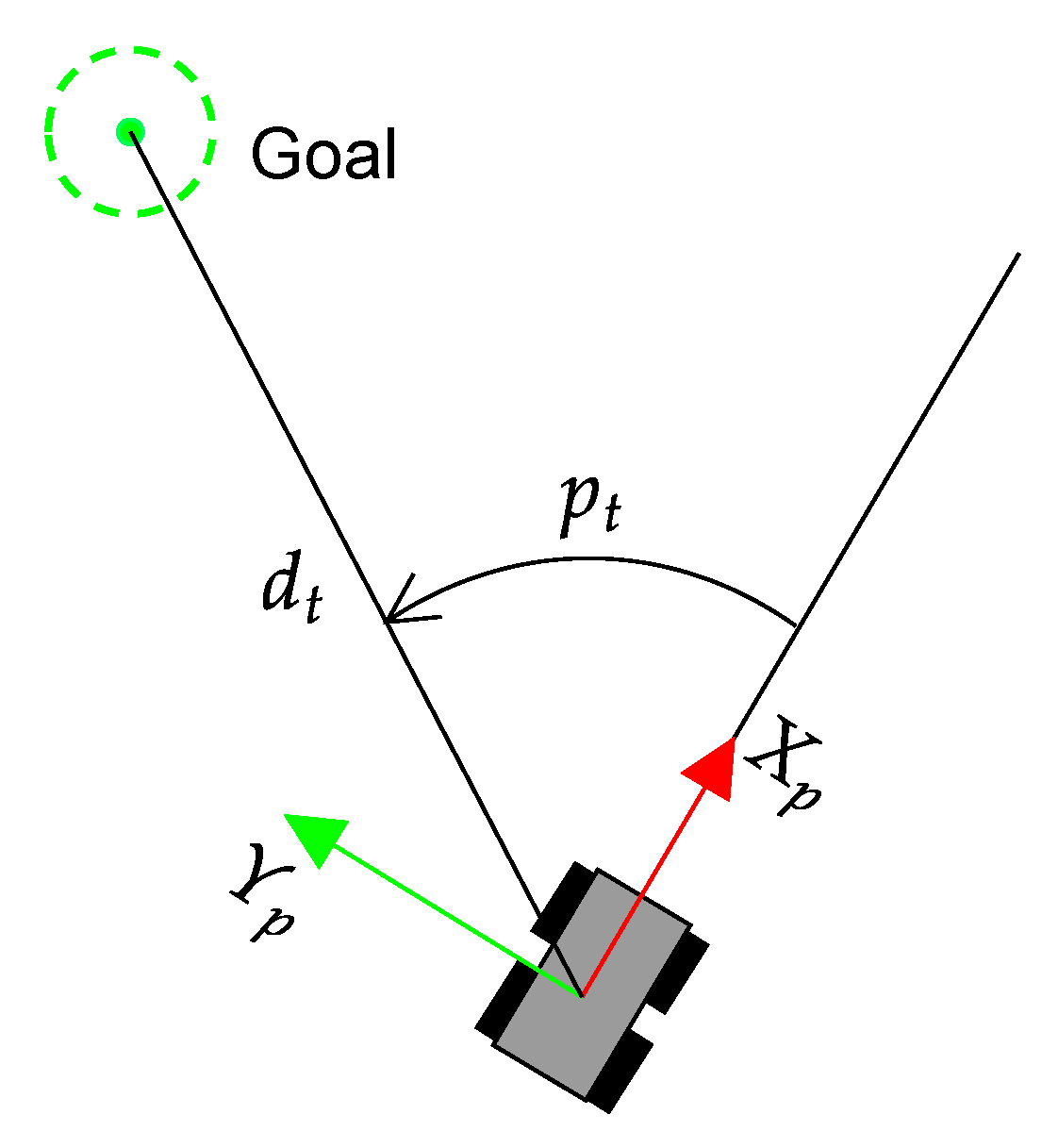
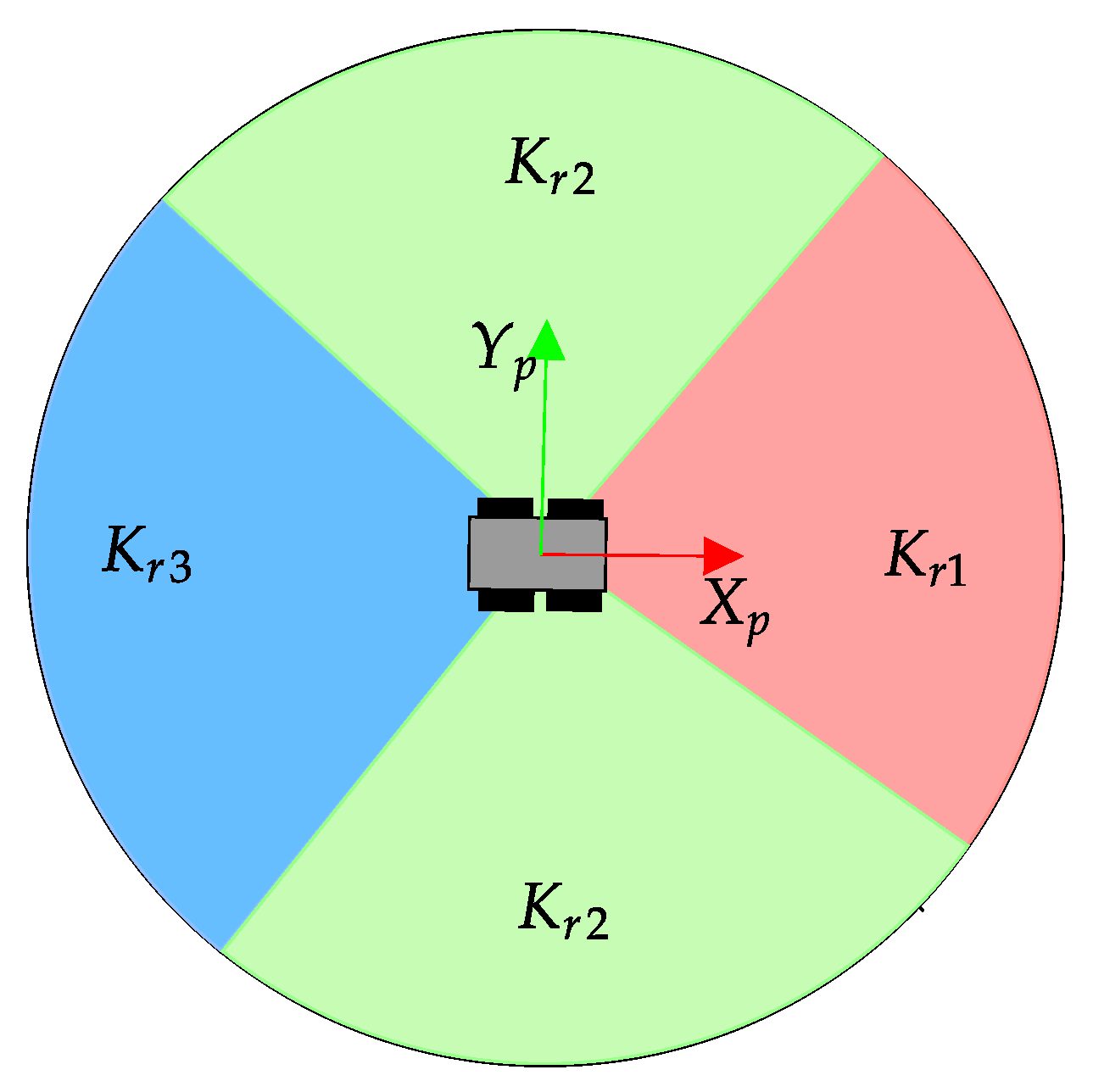
4.1. Reward Function
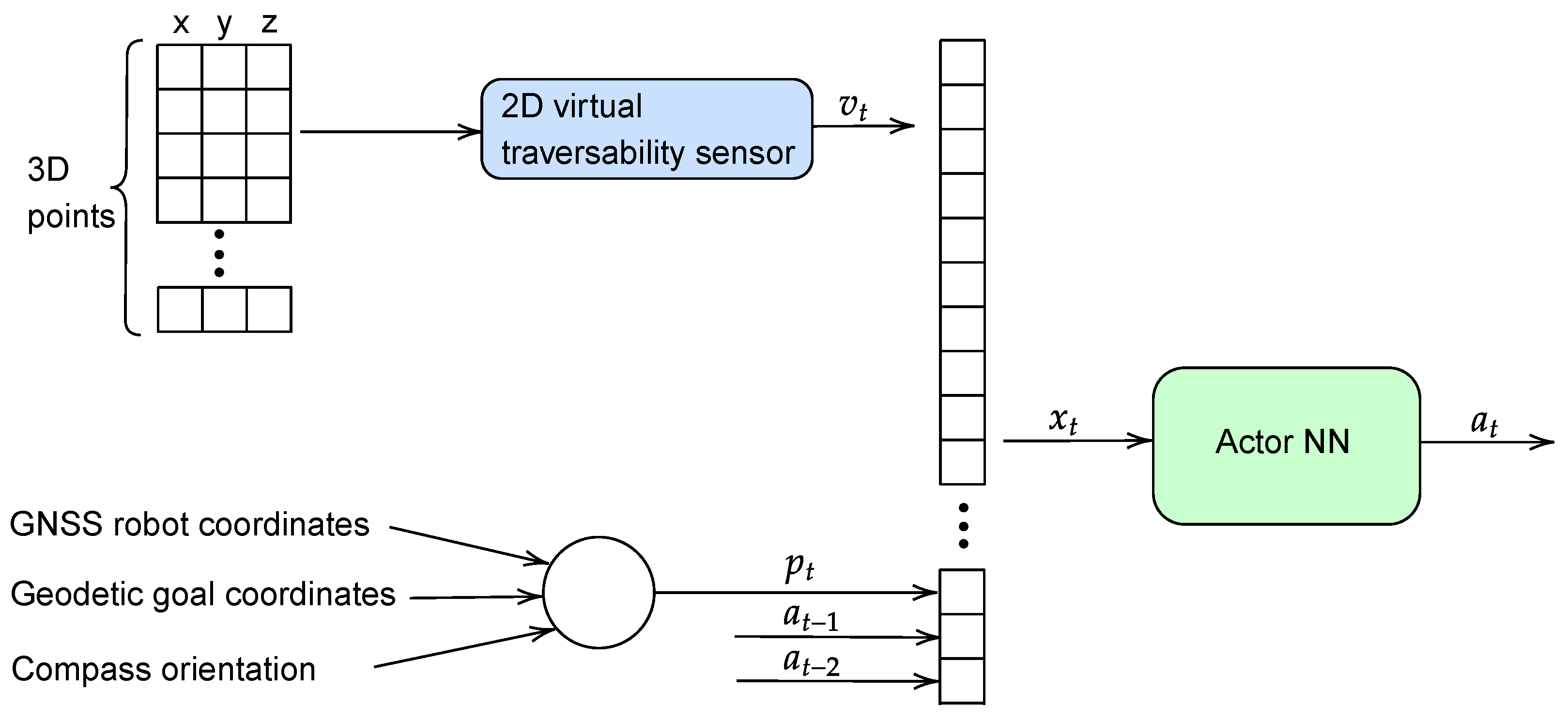
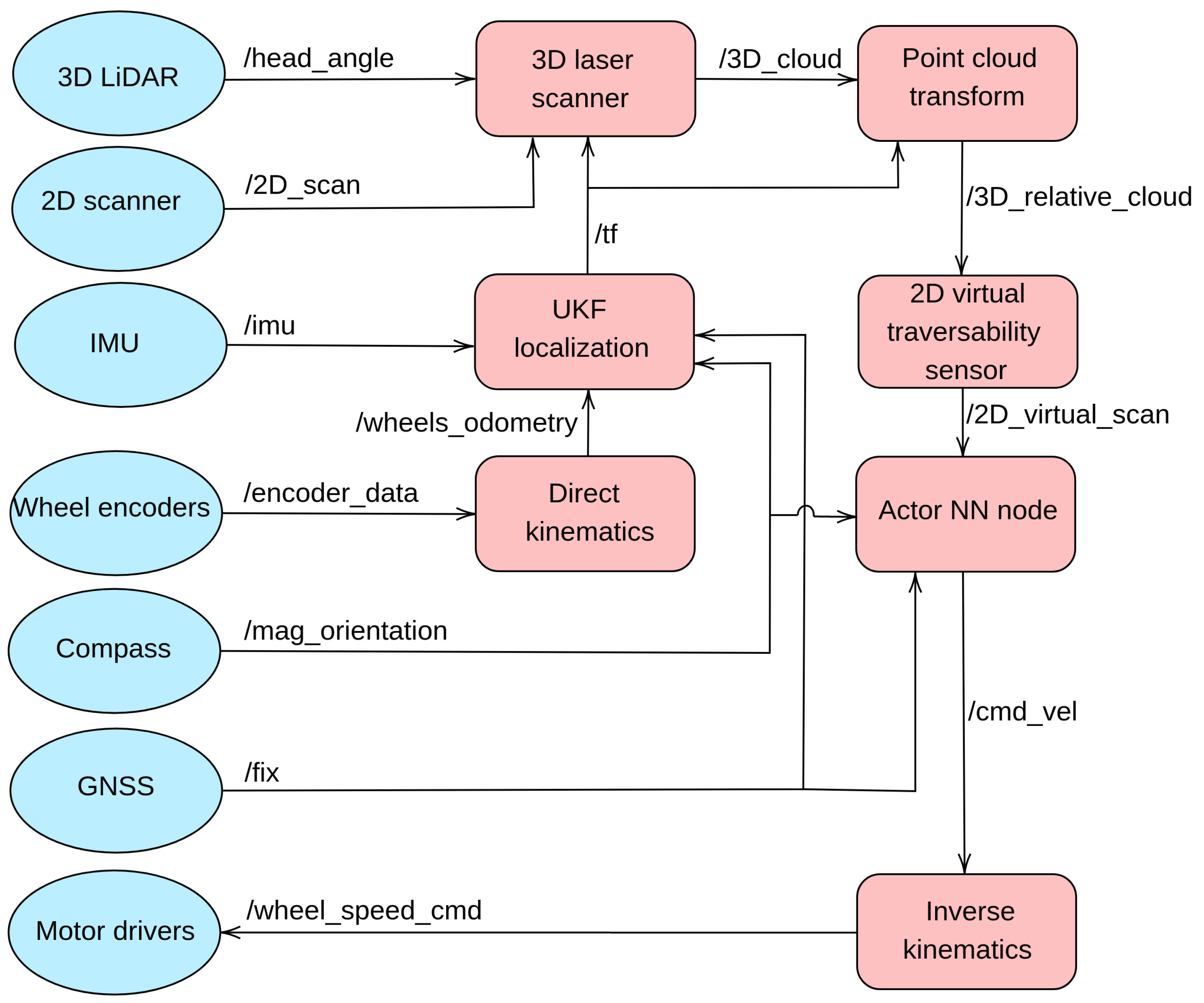
4.2. ROS Implementation
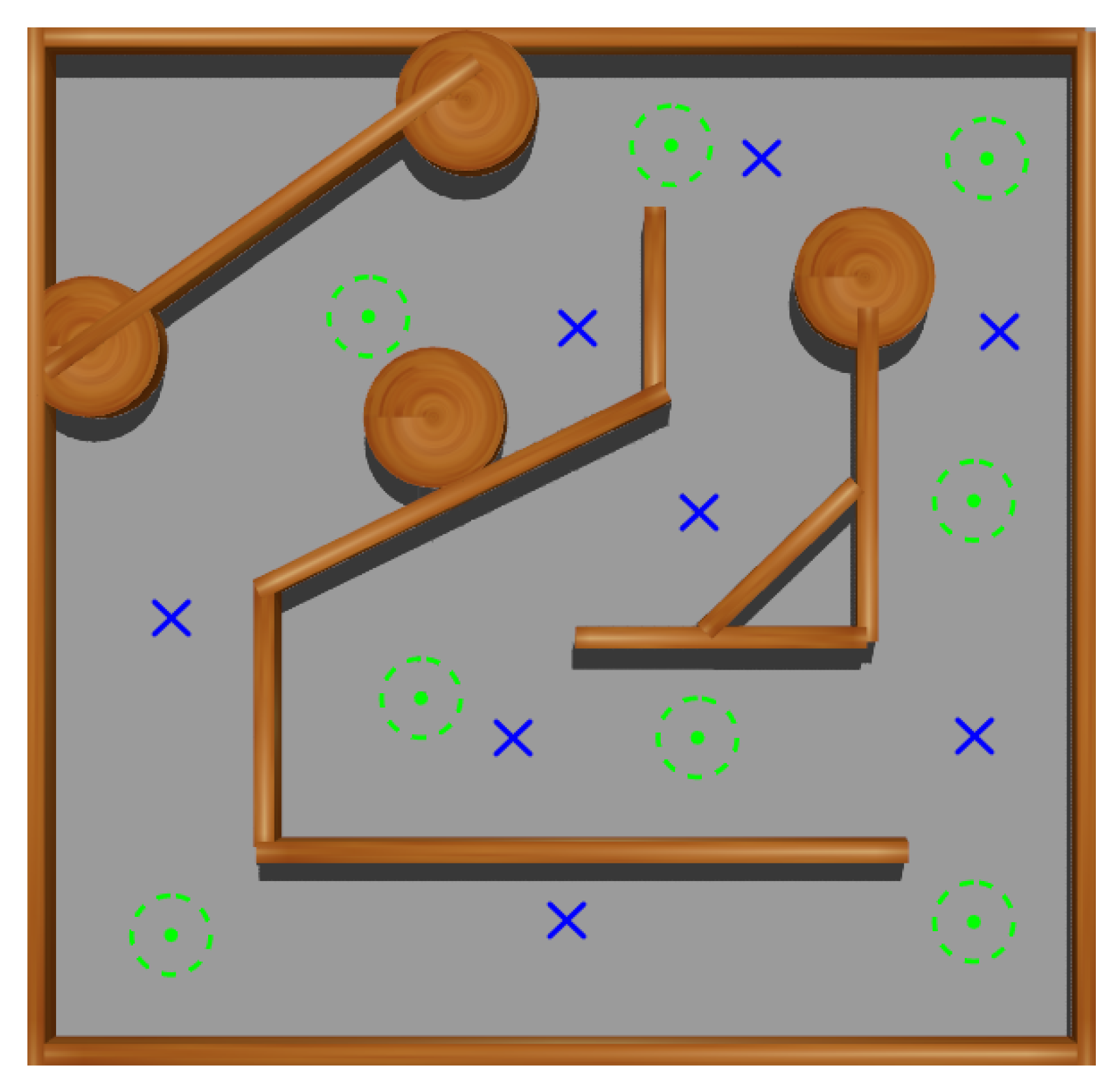
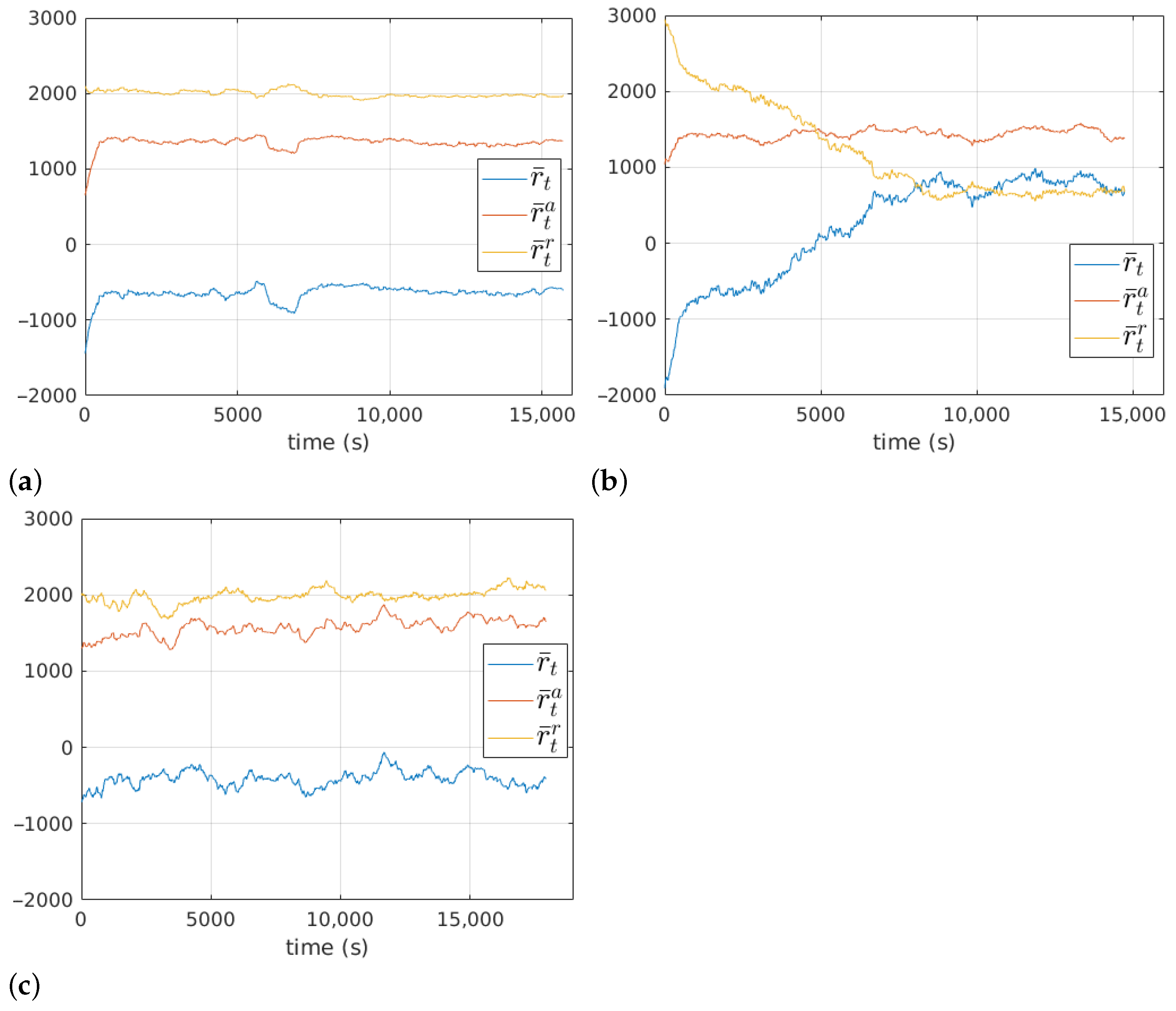
5. Training with Curriculum Learning
5.1. First Stage
5.2. Second Stage
5.3. Third Stage
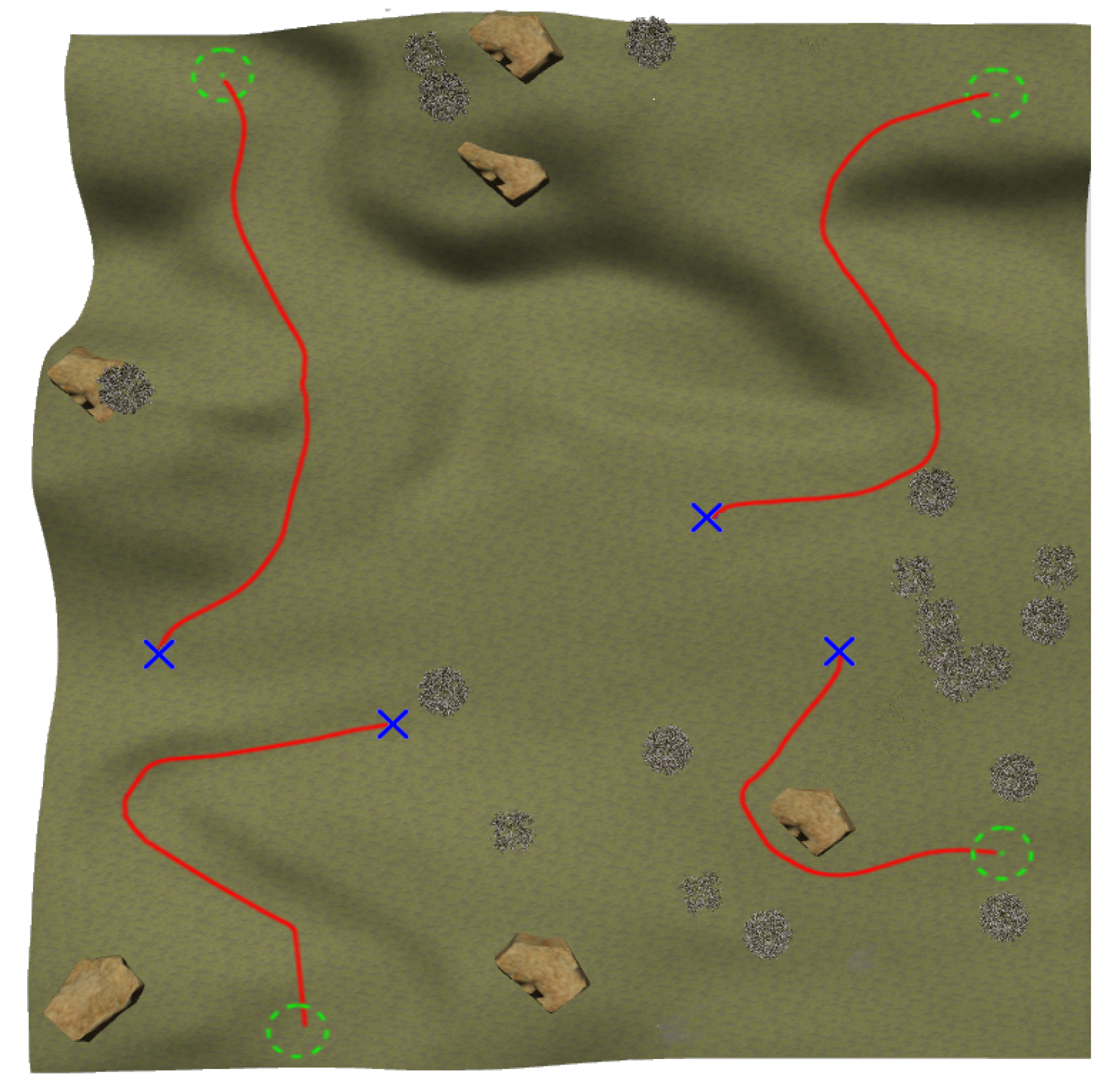
6. Experimental Results
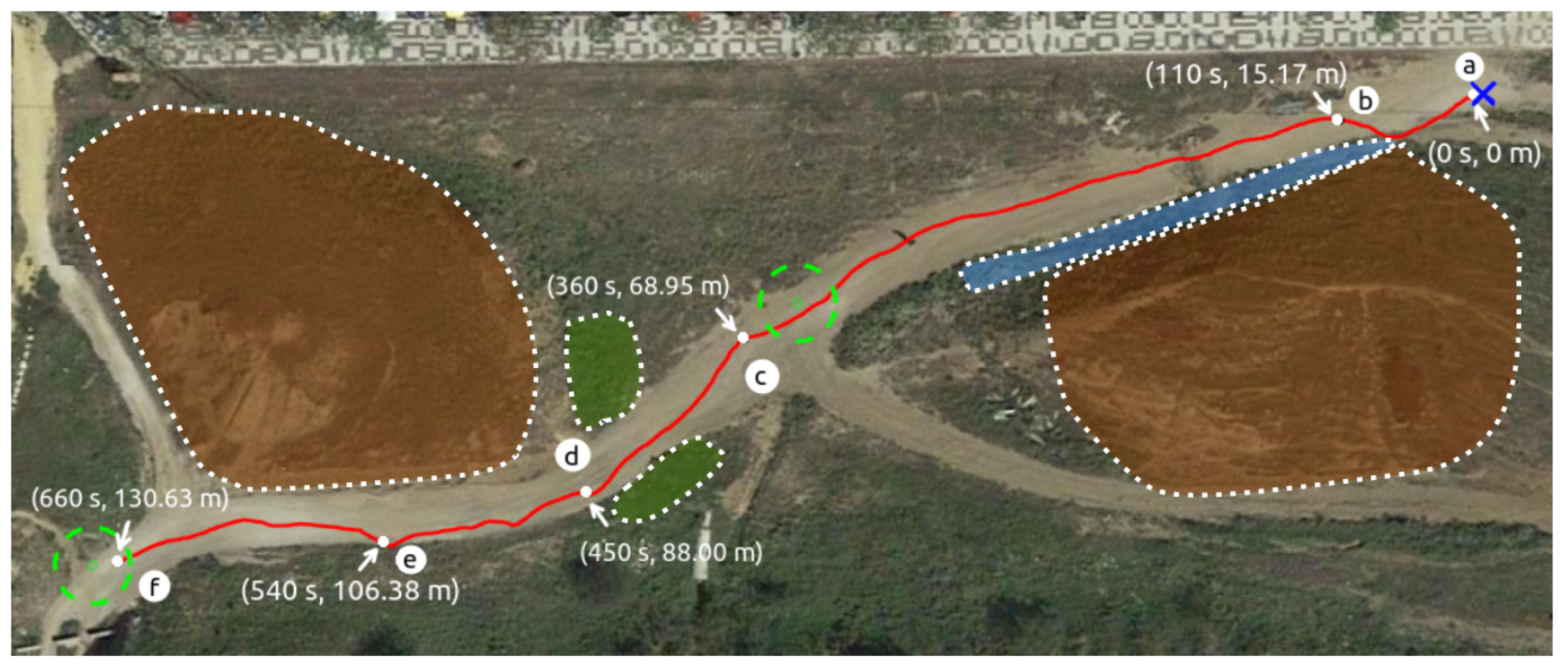
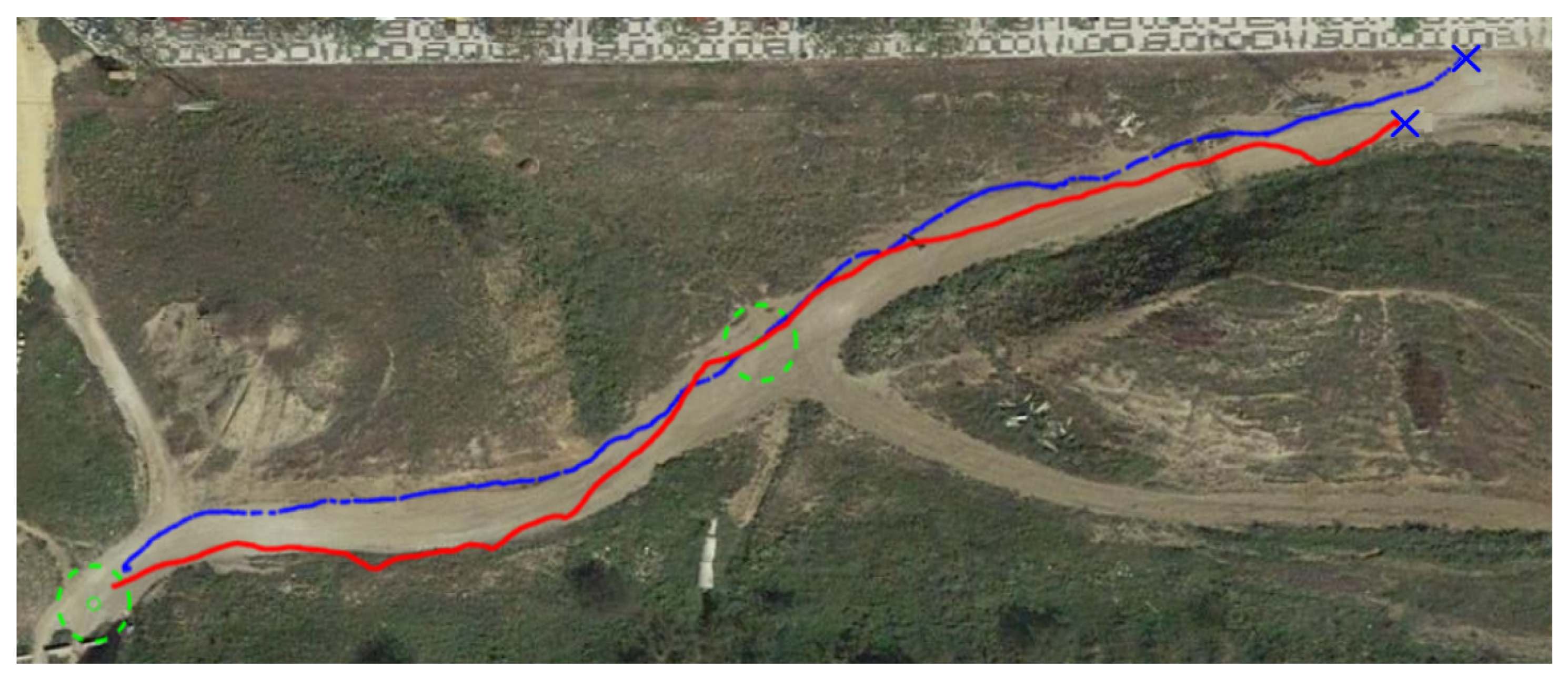
6.1. Real Test
6.2. Simulated Test
6.3. Comparison between Reactive and RL Approaches
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2D | Two-Dimensional |
| 3D | Three-Dimensional |
| CL | Curriculum Learning |
| FN | False Negative |
| FP | False Positive |
| GNSS | Global Navigation Satellite System |
| IMU | Inertial Measurement Unit |
| LiDAR | Light Detection Furthermore, Ranging |
| ML | Machine Learning |
| NN | Neural Network |
| PCA | Principal Components Analysis |
| RE | REcall |
| RL | Reinforcement Learning |
| RF | Random Forest |
| ROS | Robot Operating System |
| SP | SPecifity |
| TN | True Negative |
| TP | True Positive |
| UGV | Unmanned Ground Vehicle |
| UKF | Unscented Kalman Filter |
References
- Islam, F.; Nabi, M.M.; Ball, J.E. Off-Road Detection Analysis for Autonomous Ground Vehicles: A Review. Sensors 2022, 22, 8463. [Google Scholar] [CrossRef] [PubMed]
- Shimoda, S.; Kuroda, Y.; Iagnemma, K. High-speed navigation of unmanned ground vehicles on uneven terrain using potential fields. Robotica 2007, 25, 409–424. [Google Scholar] [CrossRef] [Green Version]
- Bagnell, J.A.; Bradley, D.; Silver, D.; Sofman, B.; Stentz, A. Learning for autonomous navigation. IEEE Robot. Autom. Mag. 2010, 17, 74–84. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep reinforcement learning in computer vision: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 2733–2819. [Google Scholar] [CrossRef]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement Learning in Robotics: A Survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Gao, H.; Zhou, C.; Yang, C.; Li, Z. Reinforcement Learning Control of a Flexible Two-Link Manipulator: An Experimental Investigation. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 7326–7336. [Google Scholar] [CrossRef]
- Bakale, V.A.; Kumar V S, Y.; Roodagi, V.C.; Kulkarni, Y.N.; Patil, M.S.; Chickerur, S. Indoor Navigation with Deep Reinforcement Learning. In Proceedings of the International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 660–665. [Google Scholar] [CrossRef]
- Kulhánek, J.; Derner, E.; Babuška, R. Visual Navigation in Real-World Indoor Environments Using End-to-End Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 6, 4345–4352. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; López, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Liu, M.; Zhao, F.; Yin, J.; Niu, J.; Liu, Y. Reinforcement-Tracking: An Effective Trajectory Tracking and Navigation Method for Autonomous Urban Driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6991–7007. [Google Scholar] [CrossRef]
- Nikolenko, S. Synthetic Simulated Environments. In Synthetic Data for Deep Learning; Springer Optimization and Its Applications: Berlin/Heidelberg, Germany, 2021; Volume 174, Chapter 7; pp. 195–215. [Google Scholar] [CrossRef]
- Soviany, P.; Ionescu, R.T.; Rota, P.; Sebe, N. Curriculum Learning: A Survey. Int. J. Comput. Vis. 2022, 130, 1526–1565. [Google Scholar] [CrossRef]
- Koenig, K.; Howard, A. Design and Use Paradigms for Gazebo, an Open-Source Multi-Robot Simulator. In Proceedings of the IEEE-RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, 28 September–2 October 2004; pp. 2149–2154. [Google Scholar] [CrossRef] [Green Version]
- Konda, V.; Tsitsiklis, J. Actor–Critic Algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Sevastopoulos, C.; Konstantopoulos, S. A Survey of Traversability Estimation for Mobile Robots. IEEE Access 2022, 10, 96331–96347. [Google Scholar] [CrossRef]
- Colas, F.; Mahesh, S.; Pomerleau, F.; Liu, M.; Siegwart, R. 3D Path Planning and Execution for Search and Rescue Ground Robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 722–727. [Google Scholar] [CrossRef] [Green Version]
- Krüsi, P.; Furgale, P.; Bosse, M.; Siegwart, R. Driving on Point Clouds: Motion Planning, Trajectory Optimization, and Terrain Assessment in Generic Nonplanar Environments. J. Field Robot. 2017, 34, 940–984. [Google Scholar] [CrossRef]
- Martínez, J.L.; Morán, M.; Morales, J.; Reina, A.J.; Zafra, M. Field Navigation Using Fuzzy Elevation Maps Built with Local 3D Laser Scans. Appl. Sci. 2018, 8, 397. [Google Scholar] [CrossRef] [Green Version]
- Guastella, D.C.; Muscato, G. Learning-Based Methods of Perception and Navigation for Ground Vehicles in Unstructured Environments: A Review. Sensors 2021, 21, 73. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Bagnell, J.A.; Stentz, A. Learning from Demonstration for Autonomous Navigation in Complex Unstructured Terrain. Int. J. Robot. Res. 2010, 29, 1565–1592. [Google Scholar] [CrossRef]
- Chavez-Garcia, R.O.; Guzzi, J.; Gambardella, L.M.; Giusti, A. Learning ground traversability from simulations. IEEE Robot. Autom. Lett. 2018, 3, 1695–1702. [Google Scholar] [CrossRef] [Green Version]
- Schilling, F.; Chen, X.; Folkesson, J.; Jensfelt, P. Geometric and visual terrain classification for autonomous mobile navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2678–2684. [Google Scholar] [CrossRef]
- Martínez, J.L.; Morán, M.; Morales, J.; Robles, A.; Sánchez, M. Supervised Learning of Natural-Terrain Traversability with Synthetic 3D Laser Scans. Appl. Sci. 2020, 10, 1140. [Google Scholar] [CrossRef] [Green Version]
- Martínez, J.L.; Morales, J.; Sánchez, M.; Morán, M.; Reina, A.J.; Fernández-Lozano, J.J. Reactive Navigation on Natural Environments by Continuous Classification of Ground Traversability. Sensors 2020, 20, 6423. [Google Scholar] [CrossRef]
- Sánchez, M.; Morales, J.; Martínez, J.L.; Fernández-Lozano, J.J.; García-Cerezo, A. Automatically Annotated Dataset of a Ground Mobile Robot in Natural Environments via Gazebo Simulations. Sensors 2022, 22, 5599. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, S.; Cheng, S.; Xia, Q.; Zhang, J. Path-Following and Obstacle Avoidance Control of Nonholonomic Wheeled Mobile Robot Based on Deep Reinforcement Learning. Appl. Sci. 2022, 12, 6874. [Google Scholar] [CrossRef]
- Doukhi, O.; Lee, D.J. Deep Reinforcement Learning for End-to-End Local Motion Planning of Autonomous Aerial Robots in Unknown Outdoor Environments: Real-Time Flight Experiments. Sensors 2021, 21, 2534. [Google Scholar] [CrossRef]
- Zeng, J.; Ju, R.; Qin, L.; Hu, Y.; Yin, Q.; Hu, C. Navigation in Unknown Dynamic Environments Based on Deep Reinforcement Learning. Sensors 2019, 19, 3837. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, J.; Ye, W.; Guo, J.; Li, Z. Deep Reinforcement Learning for Indoor Mobile Robot Path Planning. Sensors 2020, 20, 5493. [Google Scholar] [CrossRef] [PubMed]
- de Jesus, J.C.; Kich, V.A.; Kolling, A.H.; Grando, R.B.; Cuadros, M.A.d.S.L.; Gamarra, D.F.T. Soft Actor–Critic for Navigation of Mobile Robots. J. Intell. Robot. Syst. 2021, 102, 31. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, G.; Pan, L.; Ma, J.; Zhang, Y.; Zhang, Y.; Ji, J. DRQN-based 3D Obstacle Avoidance with a Limited Field of View. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 8137–8143. [Google Scholar] [CrossRef]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar] [CrossRef] [Green Version]
- Yokoyama, K.; Morioka, K. Autonomous Mobile Robot with Simple Navigation System Based on Deep Reinforcement Learning and a Monocular Camera. In Proceedings of the IEEE/SICE International Symposium on System Integration (SII), Honolulu, HI, USA, 12–15 January 2020; pp. 525–530. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, K.; Tan, A.H.; Ruan, M.; Agia, C.; Nejat, G. A Sim-to-Real Pipeline for Deep Reinforcement Learning for Autonomous Robot Navigation in Cluttered Rough Terrain. IEEE Robot. Autom. Lett. 2021, 6, 6569–6576. [Google Scholar] [CrossRef]
- Luo, S.; Kasaei, H.; Schomaker, L. Accelerating Reinforcement Learning for Reaching Using Continuous Curriculum Learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Xue, H.; Hein, B.; Bakr, M.; Schildbach, G.; Abel, B.; Rueckert, E. Using Deep Reinforcement Learning with Automatic Curriculum Learning for Mapless Navigation in Intralogistics. Appl. Sci. 2022, 12, 3153. [Google Scholar] [CrossRef]
- Anzalone, L.; Barra, S.; Nappi, M. Reinforced Curriculum Learning For Autonomous Driving in Carla. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3318–3322. [Google Scholar] [CrossRef]
- Martínez, J.L.; Morales, J.; Reina, A.; Mandow, A.; Pequeño Boter, A.; Garcia-Cerezo, A. Construction and calibration of a low-cost 3D laser scanner with 360° field of view for mobile robots. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 149–154. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Value |
|---|---|
| True Positive (TP) | 340 |
| True Negative (TN) | 780 |
| False Positive (FP) | 82 |
| False Negative (FN) | 210 |
| Metric | Formula | Result |
|---|---|---|
| Precision | 0.798 | |
| Recall (RE) | 0.618 | |
| Specificity (SP) | 0.906 | |
| Balanced Accuracy | 0.762 |
| ROS Topic | Message Type | Rate (Hz) |
|---|---|---|
| /2D_scan | sensor_msgs/LaserScan | 40 |
| /head_angle | andabata_msgs/LaserEvent | 40 |
| /encoder_data | andabata_msgs/Wheels_speed | 100 |
| /imu | sensor_msgs/Imu | 100 |
| /3D_cloud | sensor_msgs/PointCloud2 | 0.3 |
| /3D_relative_cloud | sensor_msgs/PointCloud2 | 20 |
| /tf | tf/tfMessage | 1000 |
| /mag_orientation | sensor_msgs/MagneticField | 100 |
| /fix | sensor_msgs/NavSatFix | 1 |
| /2D_virtual_scan | sensor_msgs/LaserScan | 10 |
| /cmd _vel | geometry_msgs/Twist | 10 |
| /wheel _speed _cmd | andabata_msgs/Wheels_cmd | 10 |
| Controller | Goal 1 | Goal 2 | Goal 3 |
|---|---|---|---|
| Actor NN | 98.0% | 90.0% | 70.0% |
| Reactive | 80.0% | 73.3% | 53.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez, M.; Morales, J.; Martínez, J.L. Reinforcement and Curriculum Learning for Off-Road Navigation of an UGV with a 3D LiDAR. Sensors 2023, 23, 3239. https://doi.org/10.3390/s23063239
Sánchez M, Morales J, Martínez JL. Reinforcement and Curriculum Learning for Off-Road Navigation of an UGV with a 3D LiDAR. Sensors. 2023; 23(6):3239. https://doi.org/10.3390/s23063239
Chicago/Turabian StyleSánchez, Manuel, Jesús Morales, and Jorge L. Martínez. 2023. "Reinforcement and Curriculum Learning for Off-Road Navigation of an UGV with a 3D LiDAR" Sensors 23, no. 6: 3239. https://doi.org/10.3390/s23063239
APA StyleSánchez, M., Morales, J., & Martínez, J. L. (2023). Reinforcement and Curriculum Learning for Off-Road Navigation of an UGV with a 3D LiDAR. Sensors, 23(6), 3239. https://doi.org/10.3390/s23063239