
PLG-ViT: Vision Transformer with Parallel Local and Global Self-Attention


Abstract
:1. Introduction
2. Related Works
3. PLG-ViT Architecture
3.1. Parallel Local-Global Self-Attention
3.2. Additional Blocks
3.3. Architecture Variants
- Tiny: C = 64, layer numbers = {3, 4, 16, 4}, d = 32
- Small: C = 96, layer numbers = {3, 3, 16, 3}, d = 24
- Base: C = 128, layer numbers = {3, 3, 16, 3}, d = 32,
4. Evaluation
4.1. Image Classification
4.2. Object Detection and Instance Segmentation
4.3. Semantic Segmentation
4.4. Ablation Study
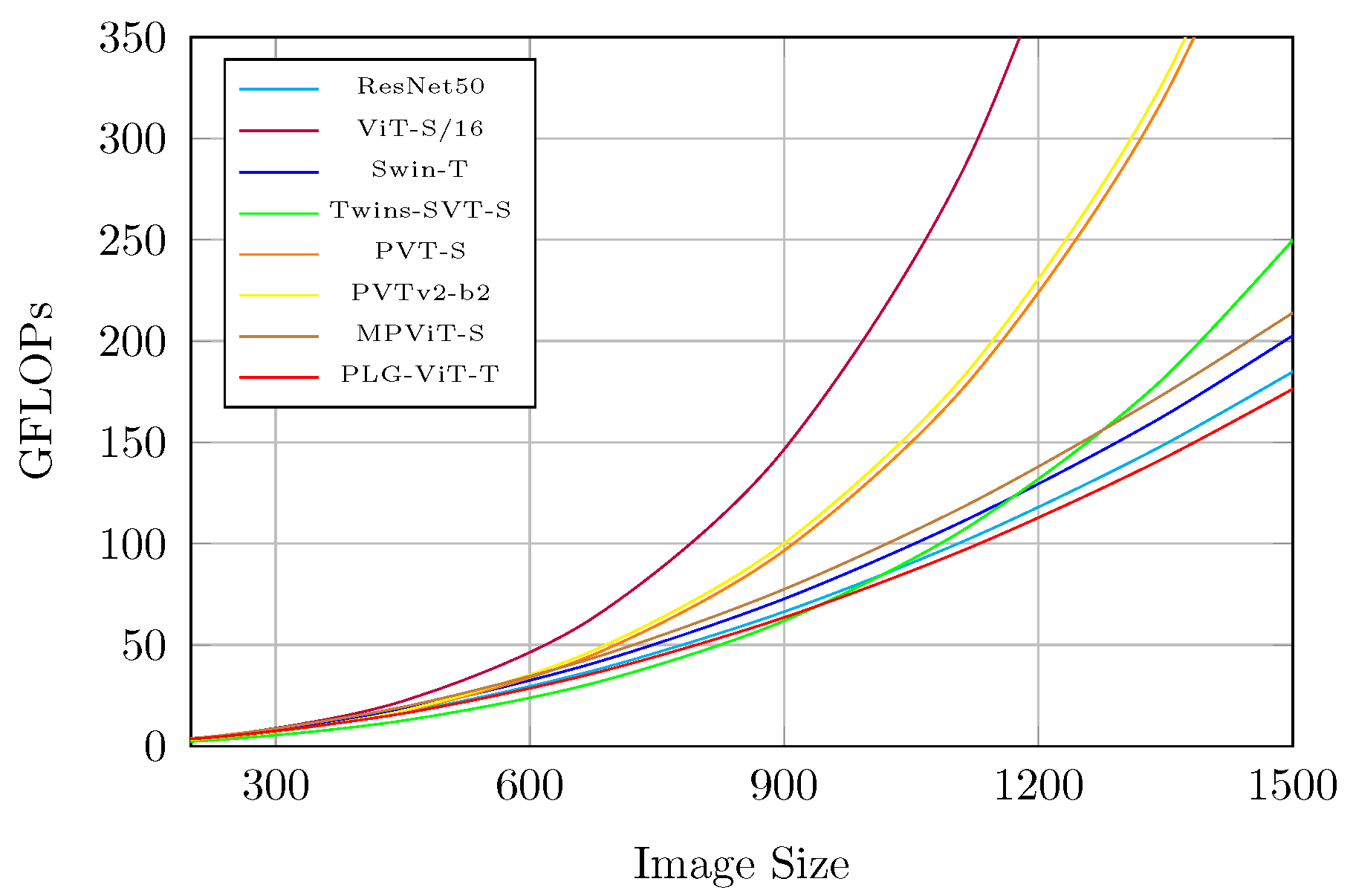
4.5. Computation Overhead Analysis
4.6. Interpretability
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Detailed Architectures

| Output Size | Layer Name | PLG-ViT Tiny | PLG-ViT Small | PLG-ViT Base | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Stage 0 | CNN-Stem | ||||||||||
| Stage 1 | PLG-Block | [ | ] | [ | ] | [ | ] | ||||
| Stage 2 | CNN-Down | ||||||||||
| PLG-Block | [ | ] | [ | ] | [ | ] | |||||
| Stage 3 | CNN-Down | ||||||||||
| PLG-Block | [ | ] | [ | ] | [ | ] | |||||
| Stage 4 | CNN-Down | ||||||||||
| PLG-Block | [ | ] | [ | ] | [ | ] | |||||
Appendix B. Detailed Experimental Settings
Appendix B.1. Image Classification on ImageNet-1K
Appendix B.2. Object Detection and Instance Segmentation
Appendix B.3. Semantic Segmentation on ADE20K
Appendix C. Visual Examples




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Pleiss, G.; Van Der Maaten, L.; Weinberger, K. Convolutional networks with dense connectivity. Trans. Pattern Anal. Mach. Intell. (TPAMI) 2019, 44, 8704–8716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. Trans. Pattern Anal. Mach. Intell. (TPAMI) 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuster, R.; Wasenmuller, O.; Unger, C.; Stricker, D. Sdc-stacked dilated convolution: A unified descriptor network for dense matching tasks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 12077–12090. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021. [Google Scholar]
- Yang, J.; Li, C.; Zhang, P.; Dai, X.; Xiao, B.; Yuan, L.; Gao, J. Focal attention for long-range interactions in vision transformers. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 30008–30022. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 9355–9366. [Google Scholar]
- Hatamizadeh, A.; Yin, H.; Kautz, J.; Molchanov, P. Global Context Vision Transformers. arXiv 2022, arXiv:2206.09959. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. MPViT: Multi-Path Vision Transformer for Dense Prediction. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. In Proceedings of the International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 15908–15919. [Google Scholar]
- Chu, X.; Tian, Z.; Zhang, B.; Wang, X.; Wei, X.; Xia, H.; Shen, C. Conditional positional encodings for vision transformers. arXiv 2021, arXiv:2102.10882. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 30392–30400. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhang, P.; Dai, X.; Yang, J.; Xiao, B.; Yuan, L.; Zhang, L.; Gao, J. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding. In Proceedings of the International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M.; et al. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ebert, N.; Mangat, P.; Wasenmuller, O. Multitask Network for Joint Object Detection, Semantic Segmentation and Human Pose Estimation in Vehicle Occupancy Monitoring. In Proceedings of the Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022. [Google Scholar]
- Fürst, M.; Gupta, S.T.; Schuster, R.; Wasenmüller, O.; Stricker, D. HPERL: 3d human pose estimation from RGB and lidar. In Proceedings of the International Conference on Pattern Recognition (ICPR), Virtual, 10–15 January 2021. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Majchrowska, S.; Pawłowski, J.; Guła, G.; Bonus, T.; Hanas, A.; Loch, A.; Pawlak, A.; Roszkowiak, J.; Golan, T.; Drulis-Kawa, Z. AGAR a microbial colony dataset for deep learning detection. arXiv 2021, arXiv:2108.01234. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Neural Inf. Process. Syst. (NeurIPS) 2021, 34, 3965–3977. [Google Scholar]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, Z.; Zhu, Y.; Zhao, C.; Hu, G.; Zeng, W.; Wang, J.; Tang, M. Dpt: Deformable patch-based transformer for visual recognition. In Proceedings of the International Conference on Multimedia (ACM MM), Virtual, China, 20–24 October 2021. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Rao, Y.; Zhao, W.; Tang, Y.; Zhou, J.; Lim, S.L.; Lu, J. HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions. Neural Inf. Process. Syst. (NeurIPS) 2022, 35, 10353–10366. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. arXiv 2022, arXiv:2202.09741. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Trans. Pattern Anal. Mach. Intell. (TPAMI) 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 8 February 2023).
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In Proceedings of the European Conference on Computer Vision (EECV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Hoffer, E.; Ben-Nun, T.; Hubara, I.; Giladi, N.; Hoefler, T.; Soudry, D. Augment your batch: Improving generalization through instance repetition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control. Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef] [Green Version]






| Method | Params (M) | GFLOPs | Top-1 (%) | |
|---|---|---|---|---|
| -50 | 25 | 4.1 | 76.1 | |
| ResNet [1] | -101 | 44 | 7.9 | 77.4 |
| -152 | 60 | 11.6 | 78.3 | |
| -50-32x4d | 25 | 4.3 | 77.6 | |
| ResNeXt [49] | -101-32x4d | 44 | 8.0 | 78.8 |
| -101-64x4d | 84 | 15.6 | 79.6 | |
| ViT [7] | -Base/16 | 86 | 17.6 | 77.9 |
| DeIT [14] | -Small/16 | 22 | 4.6 | 79.9 |
| -Base/16 | 86 | 17.6 | 81.8 | |
| CrossViT [28] | -Small | 26 | 5.6 | 81.0 |
| -Base | 104 | 21.2 | 82.2 | |
| T2T-ViT [24] | -14 | 22 | 4.8 | 81.5 |
| -19 | 39 | 8.9 | 81.9 | |
| -24 | 64 | 14.1 | 82.3 | |
| PVT [13] | -Small | 24 | 3.8 | 79.8 |
| -Medium | 44 | 6.7 | 81.2 | |
| -Large | 61 | 9.8 | 81.7 | |
| PVTv2 [19] | -B2 | 25 | 4.0 | 82.0 |
| -B3 | 45 | 6.9 | 83.2 | |
| -B4 | 62 | 10.1 | 83.6 | |
| DPT [50] | -Small | 26 | 4.0 | 81.0 |
| -Medium | 46 | 6.9 | 81.9 | |
| Twins-PCPVT [16] | -Small | 24 | 3.8 | 81.2 |
| -Base | 44 | 6.7 | 82.7 | |
| -Large | 61 | 9.8 | 83.1 | |
| Twins-SVT [16] | -Small | 24 | 2.9 | 81.7 |
| -Base | 56 | 8.6 | 83.2 | |
| -Large | 99 | 15.1 | 83.7 | |
| CoAtNet [47] | -0 | 25 | 4.2 | 81.6 |
| -1 | 42 | 8.4 | 83.3 | |
| -2 | 75 | 15.7 | 84.1 | |
| Swin [12] | -Tiny | 29 | 4.5 | 81.3 |
| -Small | 50 | 8.7 | 83.2 | |
| -Base | 88 | 15.5 | 83.5 | |
| DAT [18] | -Tiny | 29 | 4.6 | 82.0 |
| -Small | 50 | 9.0 | 83.7 | |
| -Base | 88 | 15.8 | 84.0 | |
| PoolFormer [51] | -S24 | 21 | 3.6 | 80.3 |
| ConvNeXt [9] | -Tiny | 29 | 4.5 | 82.1 |
| -Small | 50 | 8.7 | 83.1 | |
| -Base | 89 | 15.4 | 83.8 | |
| Focal [15] | -Tiny | 29 | 4.9 | 82.2 |
| -Small | 51 | 9.1 | 83.5 | |
| -Base | 90 | 16.0 | 83.8 | |
| CSwin [52] | -Tiny | 23 | 4.3 | 82.7 |
| -Small | 35 | 6.9 | 83.6 | |
| -Base | 78 | 15.0 | 84.2 | |
| MPViT [20] | -XSmall | 11 | 2.9 | 80.9 |
| -Small | 23 | 4.7 | 83.0 | |
| -Base | 75 | 16.4 | 84.3 | |
| HorNet [53] | -Tiny | 22 | 4.0 | 82.8 |
| -Small | 50 | 8.8 | 83.8 | |
| -Base | 87 | 15.6 | 84.2 | |
| VAN [54] | -B2 | 27 | 5.0 | 82.8 |
| -B3 | 45 | 9.0 | 83.9 | |
| -B4 | 60 | 12.2 | 84.2 | |
| GC ViT [17] | -Tiny | 28 | 4.7 | 83.4 |
| -Small | 51 | 8.5 | 83.9 | |
| -Base | 90 | 14.8 | 84.4 | |
| PLG-ViT (ours) | -Tiny-7 | 27 | 4.0 | 82.9 |
| -Tiny | 27 | 4.3 | 83.4 | |
| -Small | 52 | 8.6 | 84.0 | |
| -Base | 91 | 15.2 | 84.5 | |
| Backbone | Param (M) | GFLOPs | ||||||
|---|---|---|---|---|---|---|---|---|
| ResNet50 [1] | 44.2 | 260 | 41.0 | 61.7 | 44.9 | 37.1 | 58.4 | 40.1 |
| PVT-S [13] | 44.1 | 245 | 43.0 | 65.3 | 46.9 | 39.9 | 62.5 | 42.8 |
| Swin-T [12] | 47.8 | 264 | 46.0 | 68.1 | 50.3 | 41.6 | 65.1 | 44.9 |
| ConvNeXt-T [9] | 48.0 | 262 | 46.2 | 67.9 | 50.8 | 41.7 | 65.0 | 44.9 |
| DAT-T [18] | 48.0 | 272 | 47.1 | 69.2 | 51.6 | 42.4 | 66.1 | 45.5 |
| Focal-T [15] | 48.8 | 291 | 47.2 | 69.4 | 51.9 | 42.7 | 66.5 | 45.9 |
| MPViT-S [20] | 43.0 | 268 | 48.4 | 70.5 | 52.6 | 43.9 | 67.6 | 47.7 |
| GC ViT-T [17] | 48.0 | 291 | 47.9 | 70.1 | 52.8 | 43.2 | 67.0 | 46.7 |
| PLG-ViT-T | 46.3 | 250 | 48.2 | 69.5 | 53.0 | 42.9 | 66.9 | 46.1 |
| ResNet101 [1] | 63.2 | 336 | 42.8 | 63.2 | 47.1 | 38.5 | 60.1 | 41.3 |
| ResNeXt101-32x4d [49] | 62.8 | 340 | 44.0 | 64.4 | 48.0 | 39.2 | 61.4 | 41.9 |
| PVT-M [13] | 63.9 | 302 | 44.2 | 66.0 | 48.2 | 40.5 | 63.1 | 43.5 |
| Swin-S [12] | 69.1 | 354 | 48.5 | 70.2 | 53.5 | 43.3 | 67.3 | 46.6 |
| DAT-S [18] | 69.1 | 378 | 49.0 | 70.9 | 53.8 | 44.0 | 68.0 | 47.5 |
| Focal-S [15] | 71.2 | 401 | 48.8 | 70.5 | 53.6 | 43.8 | 67.7 | 47.2 |
| PLG-ViT-S | 71.2 | 335 | 49.0 | 70.2 | 53.8 | 43.5 | 67.2 | 46.5 |
| ResNeXt101-64x4d [49] | 102.0 | 493 | 44.4 | 64.9 | 48.8 | 39.7 | 61.9 | 42.6 |
| PVT-L [13] | 81.0 | 364 | 44.5 | 66.0 | 48.3 | 40.7 | 63.4 | 43.7 |
| Swin-B [12] | 107.0 | 496 | 48.5 | 69.8 | 53.2 | 43.4 | 66.8 | 46.9 |
| Focal-B [15] | 110.0 | 533 | 49.0 | 70.1 | 53.6 | 43.7 | 67.6 | 47.0 |
| MPViT-B [20] | 95.0 | 503 | 49.5 | 70.9 | 54.0 | 44.5 | 68.3 | 48.3 |
| PLG-ViT-B | 110.5 | 461 | 49.5 | 70.6 | 54.0 | 43.8 | 67.7 | 47.3 |
| Faster RCNN [55] | RetinaNet [33] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Resnet50 [1] | ConvNeXt-T [9] | Swin-T [12] | PVTv2-b2 [19] | PLG-ViT-T | Resnet50 [1] | ConvNeXt-T [9] | Swin-T [12] | PVTv2-b2 [19] | PLG-ViT-T | ||
| Param (M) | 41.5 | 45.5 | 45.2 | 42.4 | 43.6 | 37.4 | 38.8 | 38.5 | 35.1 | 36.7 | |
| GFLOPs | 207 | 209 | 211 | 184 | 197 | 239 | 243 | 245 | 218 | 231 | |
| COCO [22] | AP | 37.4 | 43.5 | 42.0 | 44.9 | 45.1 | 36.5 | 43.4 | 41.9 | 44.6 | 44.8 |
| AP50 | 58.1 | 65.8 | 64.8 | 67.2 | 67.2 | 55.4 | 64.1 | 62.8 | 65.6 | 65.7 | |
| AP75 | 40.4 | 47.7 | 45.9 | 49.0 | 49.2 | 39.1 | 46.8 | 44.7 | 47.6 | 48.3 | |
| APS | 21.2 | 26.8 | 26.1 | 29.2 | 27.8 | 20.4 | 26.9 | 25.4 | 27.4 | 28.0 | |
| APM | 41.0 | 47.2 | 45.5 | 48.6 | 48.7 | 40.3 | 47.8 | 45.5 | 48.8 | 49.0 | |
| APL | 48.1 | 56.6 | 55.5 | 58.8 | 59.4 | 48.1 | 56.6 | 55.1 | 58.6 | 58.6 | |
| BDD100K [46] | AP | 31.0 | 33.3 | 32.1 | 32.9 | 33.7 | 28.6 | 33.0 | 31.8 | 32.4 | 33.0 |
| AP50 | 55.9 | 59.5 | 58.8 | 59.0 | 60.3 | 52.1 | 59.0 | 57.4 | 58.4 | 58.9 | |
| AP75 | 29.4 | 31.5 | 29.8 | 31.4 | 32.6 | 26.6 | 31.1 | 29.8 | 30.8 | 31.4 | |
| APS | 14.7 | 16.1 | 15.2 | 16.1 | 16.4 | 10.6 | 13.9 | 13.1 | 13.9 | 14.2 | |
| APM | 36.0 | 37.5 | 37.0 | 37.2 | 38.7 | 34.6 | 38.5 | 37.3 | 37.9 | 38.6 | |
| APL | 50.9 | 55.2 | 53.7 | 54.3 | 54.6 | 49.6 | 55.9 | 55.1 | 55.1 | 55.5 | |
| AGAR [45] | AP | 55.4 | 54.3 | 56.7 | 54.0 | 58.4 | 49.3 | 52.9 | 55.6 | 55.3 | 56.5 |
| AP50 | 79.1 | 79.3 | 79.3 | 79.9 | 80.3 | 76.6 | 80.6 | 80.7 | 81.4 | 80.8 | |
| AP75 | 65.2 | 61.5 | 67.5 | 61.3 | 69.6 | 55.9 | 58.5 | 65.1 | 62.6 | 66.7 | |
| APS | 2.4 | 3.4 | 2.8 | 3.7 | 4.6 | 8.2 | 11.5 | 12.2 | 13.8 | 13.9 | |
| APM | 40.2 | 39.5 | 42.1 | 39.6 | 44.0 | 29.6 | 33.3 | 37.7 | 36.9 | 38.2 | |
| APL | 62.3 | 60.7 | 63.1 | 60.5 | 64.4 | 57.8 | 60.6 | 62.7 | 61.6 | 63.9 | |
| Backbone | Params (M) | GFLOPs | mIoU | mIoUms |
|---|---|---|---|---|
| Swin-T [12] | 60 | 945 | 44.5 | 45.8 |
| DAT-T [18] | 60 | 957 | 45.5 | 46.4 |
| ConvNeXt-T [9] | 60 | 939 | 46.1 | 46.7 |
| Twins-SVT-S [16] | 54 | 896 | 46.2 | 47.1 |
| Focal-T [15] | 62 | 998 | 45.8 | 47.0 |
| MPViT-S [20] | 52 | 943 | 48.3 | N/A |
| GC ViT-T [17] | 58 | 947 | 47.0 | N/A |
| PLG-ViT-T | 56 | 925 | 46.4 | 47.2 |
| Swin-S [12] | 81 | 1038 | 47.6 | 49.5 |
| DAT-S [18] | 81 | 1079 | 48.3 | 49.8 |
| ConvNeXt-S [9] | 82 | 1027 | 48.6 | 49.6 |
| Twins-SVT-B [16] | 88 | 1005 | 47.7 | 48.9 |
| Focal-S [15] | 85 | 1130 | 48.0 | 50.0 |
| GC ViT-S [17] | 84 | 1163 | 48.3 | N/A |
| PLG-ViT-S | 83 | 1014 | 48.0 | 48.6 |
| Swin-B [12] | 121 | 1188 | 48.1 | 49.7 |
| DAT-B [18] | 121 | 1212 | 49.4 | 50.6 |
| ConvNeXt-B [9] | 122 | 1170 | 48.7 | 49.9 |
| Twins-SVT-L [16] | 133 | 1134 | 48.8 | 50.2 |
| Focal-B [15] | 126 | 1354 | 49.0 | 50.0 |
| MPViT-S [20] | 105 | 1186 | 50.3 | N/A |
| GC ViT-B [17] | 125 | 1348 | 49.0 | N/A |
| PLG-ViT-B | 125 | 1147 | 49.9 | 50.7 |
| Modules | Param (M) | GFLOPs | ImageNet-1K | COCO | ||
|---|---|---|---|---|---|---|
| Top-1 | Top-5 | APbox | APmask | |||
| w/o PLG-SA | 28.8 | 4.9 | 83.2 | 96.5 | 46.0 | 41.2 |
| w/o CCF-FFN | 26.3 | 4.2 | 82.6 | 96.2 | 43.7 | 40.1 |
| w/o Conv-PE | 25.6 | 4.2 | 83.3 | 96.5 | 45.7 | 40.8 |
| Swin Config | 30.0 | 4.7 | 82.9 | 96.3 | 44.6 | 40.7 |
| w/o rel. pos. | 26.5 | 4.3 | 83.3 | 96.4 | 45.6 | 40.8 |
| w/o ch. split | 35.7 | 6.7 | 83.7 | 96.7 | 46.3 | 41.5 |
| PLG-ViT | 26.6 | 4.3 | 83.4 | 96.4 | 46.2 | 41.3 |
| Global Window Size Experiments | ||||
|---|---|---|---|---|
| Win-Size | Param (M) | GFLOPs | Top-1 (%) | Top-5 (%) |
| 7 | 26.6 | 4.0 | 82.9 | 96.3 |
| 10 | 26.6 | 4.1 | 83.1 | 96.3 |
| 14 | 26.6 | 4.3 | 83.4 | 96.4 |
| 18 | 26.7 | 4.8 | 83.2 | 96.4 |
| PPM | 26.3 | 4.1 | 83.1 | 96.4 |
| Patch Sampling Experiments | ||||
| Pooling | Params (M) | GFLOPs | Top-1 (%) | Top-5 (%) |
| Max | 26.6 | 4.3 | 83.2 | 96.4 |
| Avg | 26.6 | 4.3 | 83.1 | 96.3 |
| Max + Avg | 26.6 | 4.3 | 83.4 | 96.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebert, N.; Stricker, D.; Wasenmüller, O. PLG-ViT: Vision Transformer with Parallel Local and Global Self-Attention. Sensors 2023, 23, 3447. https://doi.org/10.3390/s23073447
Ebert N, Stricker D, Wasenmüller O. PLG-ViT: Vision Transformer with Parallel Local and Global Self-Attention. Sensors. 2023; 23(7):3447. https://doi.org/10.3390/s23073447
Chicago/Turabian StyleEbert, Nikolas, Didier Stricker, and Oliver Wasenmüller. 2023. "PLG-ViT: Vision Transformer with Parallel Local and Global Self-Attention" Sensors 23, no. 7: 3447. https://doi.org/10.3390/s23073447
APA StyleEbert, N., Stricker, D., & Wasenmüller, O. (2023). PLG-ViT: Vision Transformer with Parallel Local and Global Self-Attention. Sensors, 23(7), 3447. https://doi.org/10.3390/s23073447