

Invertible Privacy-Preserving Adversarial Reconstruction for Image Compressed Sensing


Abstract
:1. Introduction
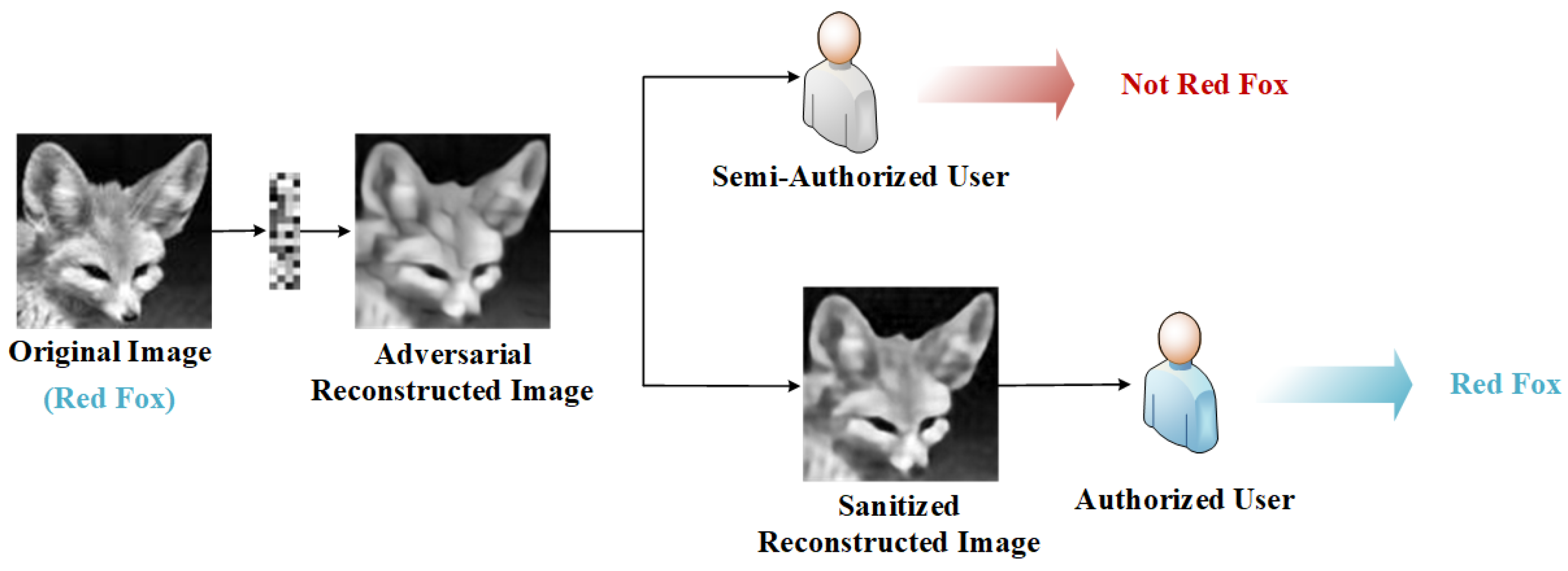
- We consider both the visual quality of reconstructed images and their ability to confuse DNN models during the reconstruction process of CS so that the reconstructed images have the ability to fool the DNN models at the time of generation.
- We propose a privacy-preserving reconstruction method for image CS based on adversarial examples for users with two levels. While guaranteeing the visual quality of the reconstructed images, we take the machine recognition metric as the starting point and focus on the privacy needs of different users. We not only follow the original adversarial samples but also consider the invertibility of task availability of reconstructed images. Specifically, semi-authorized users can only obtain adversarial reconstructed images, which protects user privacy by reducing the accuracy rate of the recognition models. In contrast, authorized users can restore sanitized reconstructed images from the adversarial reconstructed images for more efficient model training or more accurate data analysis, enabling invertibility for machine task availability.
- The good performance of the IPPARNet is demonstrated with extensive experiments. Keeping good visual quality, the recognizability of adversarial reconstructed images is low enough to avoid being used illegally by malicious users, while the sanitized reconstructed images can reach an approximate or even slightly higher recognition rate compared with that of the original CS reconstructed images.
2. Related Works
2.1. Compressed Sensing
2.1.1. Traditional Compressed Sensing
2.1.2. Compressed Sensing Based on Deep Learning
2.2. Adversarial Examples
3. Proposed Method
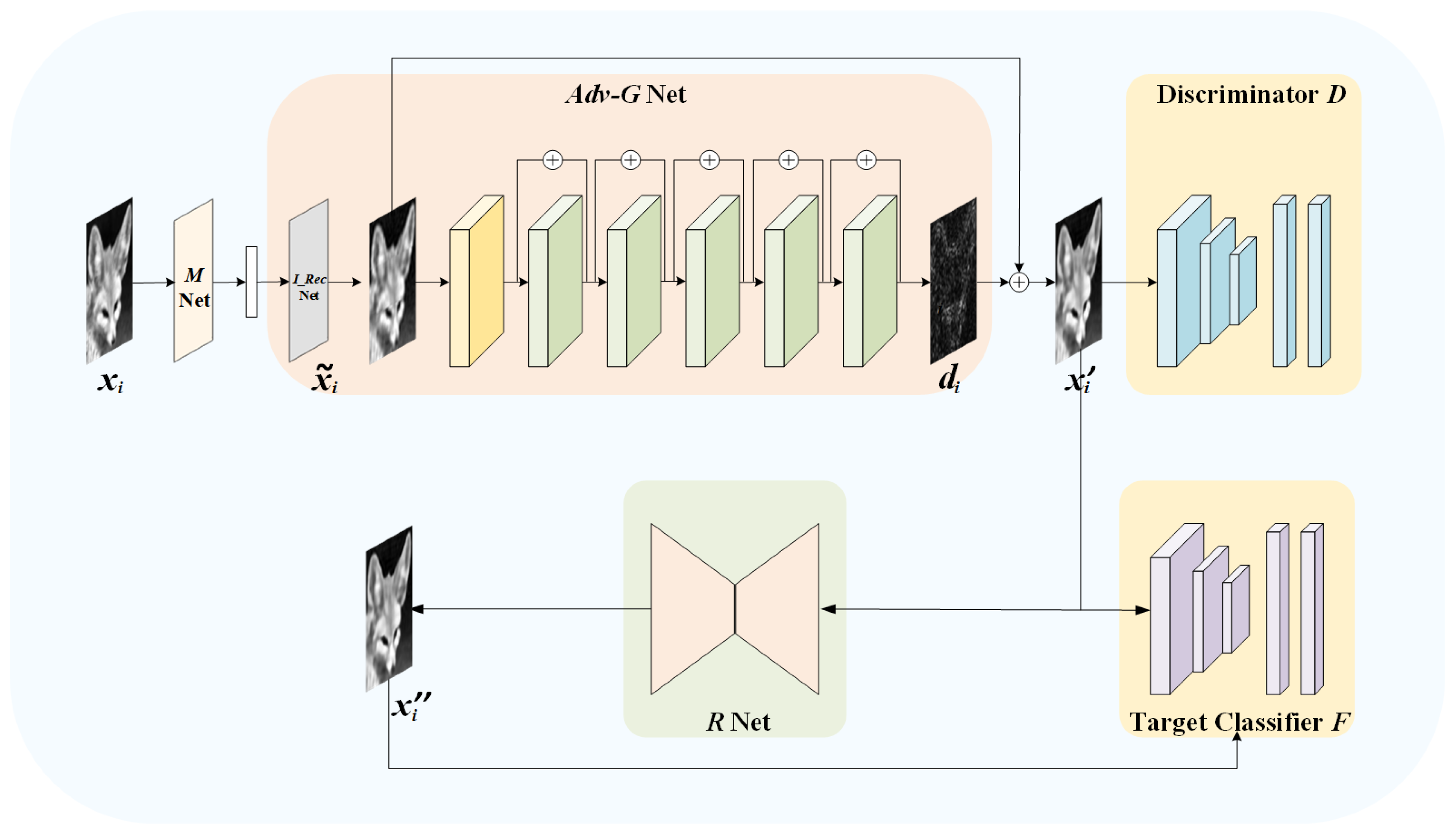
3.1. Overview
3.2. Network Architecture
3.2.1. Measurement Network:
3.2.2. Adversarial Reconstruction Network: -
3.2.3. Restoration Network: R
3.2.4. Discriminator:
3.2.5. Ensemble Target Networks:
3.3. Loss Functions
3.4. Training and Inference
4. Experiment and Results
4.1. Experimental Setting
4.2. Results and Analysis
4.2.1. Benchmark
4.2.2. Performance Evaluation
- Analysis of Recognition Accuracy
- 2.
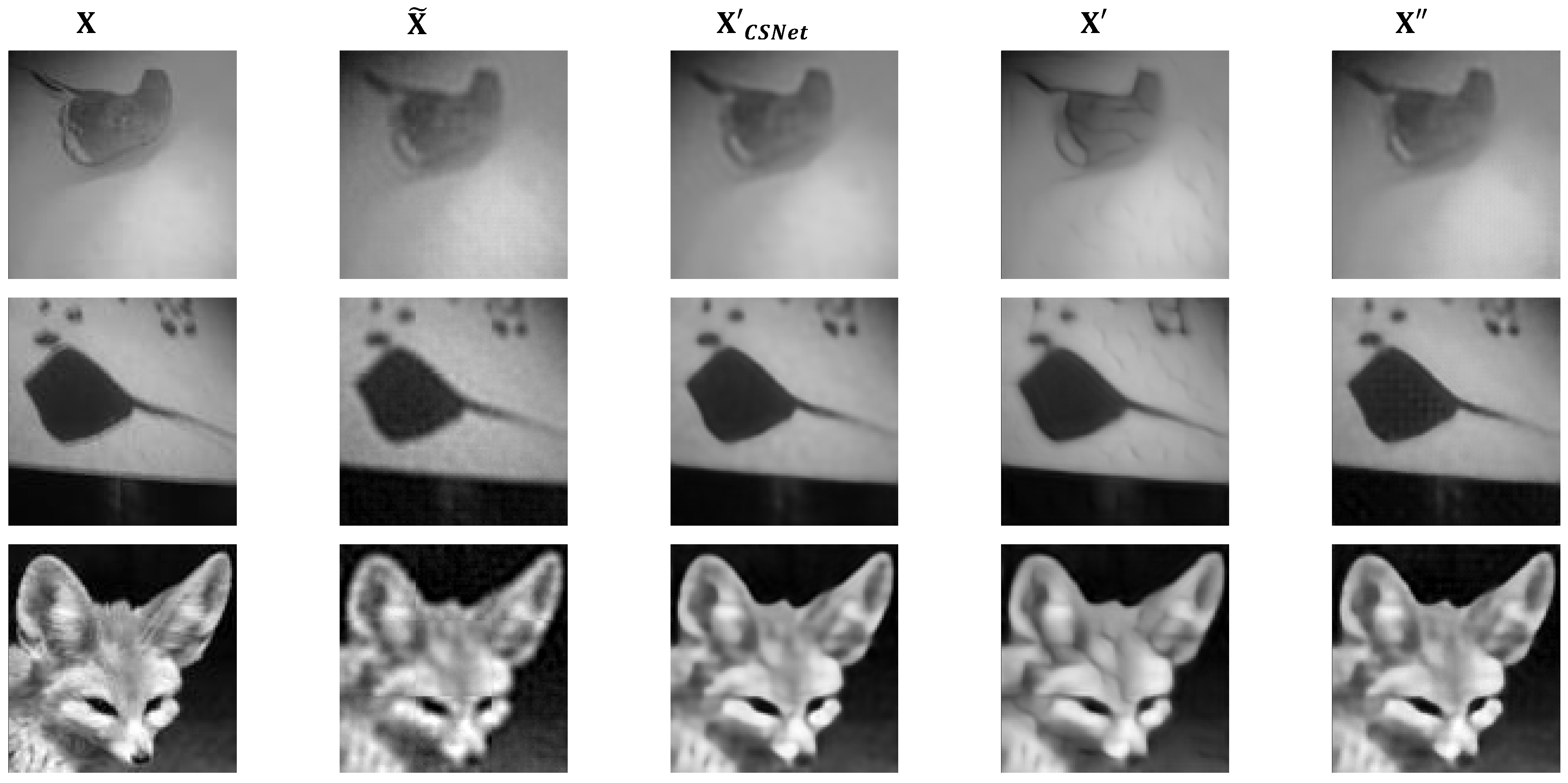
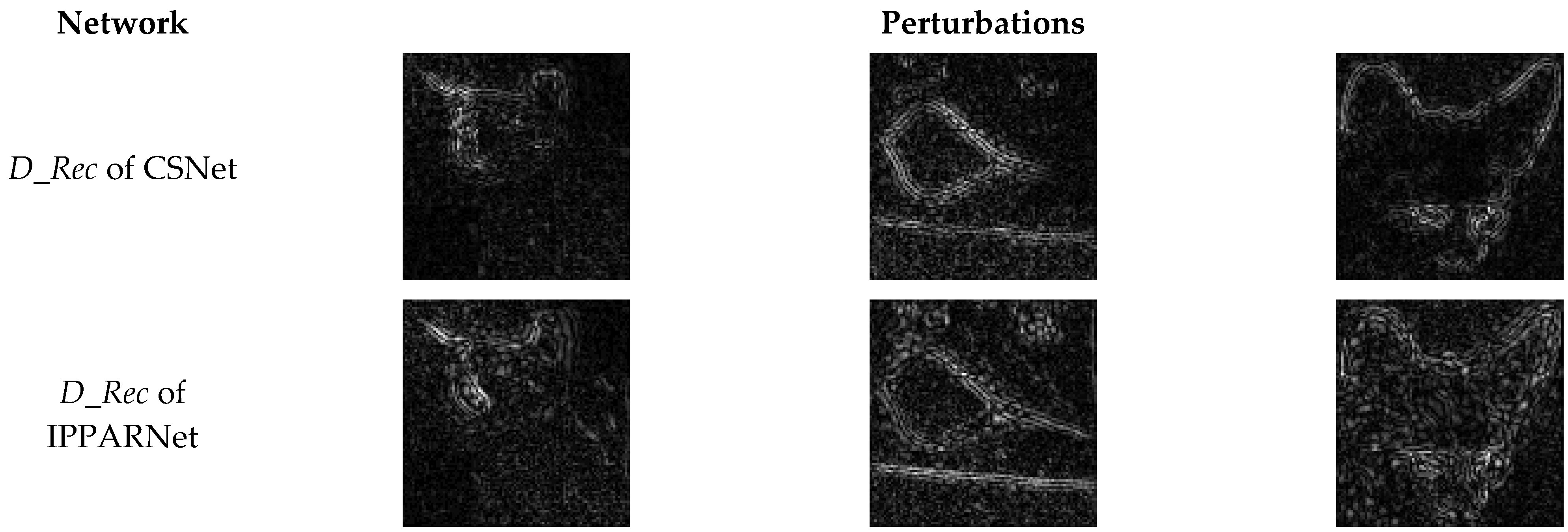
- Analysis of Image Visual Quality
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CS | Compressed sensing |
| OMP | Orthogonal matching pursuit |
| GPSR | Gradient projection for sparse reconstruction |
| DNN | Deep neural network |
| BP | Basis pursuit |
| MP | Matching pursuit |
| SDA | Stacked denoising autoencoder |
| CNN | Convolutional neural network |
| BCS | Block compressed sensing |
| FGSM | Fast gradient sign method |
| BIM | Basic iterative method |
| PGD | Projected gradient descent |
| GAN | Generative adversarial networks |
| ReLU | Rectified linear unit |
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inform. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery from Random Measurements Via Orthogonal Matching Pursuit. IEEE Trans. Inform. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient Projection for Sparse Reconstruction: Application to Compressed Sensing and Other Inverse Problems. IEEE J. Sel. Top. Sign. Process. 2007, 1, 586–597. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Zhou, S.; He, Y.; Liu, Y.; Li, C.; Zhang, J. Multi-Channel Deep Networks for Block-Based Image Compressive Sensing. IEEE Trans. Multimed. 2021, 23, 2627–2640. [Google Scholar] [CrossRef]
- Lohit, S.; Kulkarni, K.; Kerviche, R.; Turaga, P.; Ashok, A. Convolutional Neural Networks for Noniterative Reconstruction of Compressively Sensed Images. IEEE Trans. Comput. Imaging 2018, 4, 326–340. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable Optimization-Inspired Deep Network for Image Compressive Sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 1828–1837. [Google Scholar]
- Hill, K. The secretive company that might end privacy as we know it. The New York Times, 18 January 2020. [Google Scholar]
- Shan, S.; Wenger, E.; Zhang, J.; Li, H.; Zheng, H.; Zhao, B.Y. Fawkes: Protecting Privacy against Unauthorized Deep Learning Models. In Proceedings of the 29th USENIX Conference on Security Symposium, Boston, MA, USA, 12–14 August 2020; pp. 1589–1604. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Chen, K.; Zeng, X.; Ying, Q.; Li, S.; Qian, Z.; Zhang, X. Invertible Image Dataset Protection. In Proceedings of the IEEE International Conference on Multimedia and Expo, Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- You, Z.; Li, S.; Qian, Z.; Zhang, X. Reversible Privacy-Preserving Recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhou, S.; Deng, X.; Li, C.; Liu, Y.; Jiang, H. Recognition-Oriented Image Compressive Sensing with Deep Learning. IEEE Trans. Multimed. 2022, in press. [Google Scholar] [CrossRef]
- Mousavi, A.; Patel, A.B.; Baraniuk, R.G. A deep learning approach to structured signal recovery. In Proceedings of the IEEE Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 29 September–2 October 2015; pp. 1336–1343. [Google Scholar]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. ReconNet: Non-Iterative Reconstruction of Images from Compressively Sensed Measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 449–458. [Google Scholar]
- Gan, L. Block Compressed Sensing of Natural Images. In Proceedings of the IEEE International Conference on Digital Signal Processing, Cardiff, UK, 1–4 July 2007; pp. 403–406. [Google Scholar]
- Yao, H.; Dai, F.; Zhang, D.; Ma, Y.; Zhang, S.; Zhang, Y. DR2-Net: Deep Residual Reconstruction Network for Image Compressive Sensing. Neurocomputing 2017, 359, 483–493. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Wang, Y.; Shi, G.; Wang, C.; Du, J.; Han, X. Adaptive Measurement Network for CS Image Reconstruction. In Proceedings of the Chinese Conference on Computer Vision, Tianjin, China, 11–14 October 2017; pp. 407–417. [Google Scholar]
- Shi, W.; Jiang, F.; Zhang, S.; Zhao, D. Deep networks for compressed image sensing. In Proceedings of the IEEE International Conference on Multimedia and Expo, Hong Kong, China, 10–14 July 2017; pp. 877–882. [Google Scholar]
- Shi, W.; Jiang, F.; Liu, S.; Zhao, D. Image Compressed Sensing Using Convolutional Neural Network. IEEE Trans. Image Process. 2020, 29, 375–388. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.060832. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QB, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3905–3911. [Google Scholar]
- Jandial, S.; Mangla, P.; Varshney, S.; Balasubramanian, V. AdvGAN++: Harnessing Latent Layers for Adversary Generation. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Seoul, Republic of Korea, 27–28 October 2019; pp. 2045–2048. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, NL, USA, 8–16 October 2016; pp. 694–711. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Testing Set | Tiny-ImageNet | |
|---|---|---|
| Recognizer | ||
| VGG16 | 81.4 | |
| ResNet50 | 80.2 | |
| DenseNet121 | 77.2 | |
| Average | 79.5 | |
| Sampling Rate | PSNR |
|---|---|
| 0.1 | 26.33 |
| 0.2 | 29.19 |
| 0.3 | 30.30 |
| 0.5 | 33.27 |
| Sampling Rate | 0.1 | 0.2 | 0.3 | 0.5 | |
|---|---|---|---|---|---|
| Recognizer | |||||
| VGG16 | 40.8 | 69.8 | 70.8 | 79.6 | |
| ResNet50 | 61.0 | 73.4 | 74.4 | 79.4 | |
| DenseNet121 | 55.2 | 71.2 | 76.8 | 77.0 | |
| Average | 52.3 | 71.5 | 74.0 | 78.6 | |
| Sampling Rate | 0.1 | 0.2 | 0.3 | 0.5 | |
|---|---|---|---|---|---|
| Images | |||||
| Average | 52.3 | 71.5 | 74.0 | 78.6 | |
| VGG16 | 6.0 | 7.2 | 11.6 | 10.4 | |
| ResNet50 | 10.0 | 12.8 | 15.2 | 19.0 | |
| DenseNet121 | 7.6 | 6.4 | 11.6 | 11.2 | |
| Average | 7.8 | 8.8 | 12.8 | 13.5 | |
| VGG16 | 49.2 | 68.8 | 69.8 | 74.8 | |
| ResNet50 | 62.0 | 72.0 | 72.8 | 76.8 | |
| DenseNet121 | 55.6 | 68.0 | 68.4 | 72.4 | |
| Average | 55.6 | 69.6 | 70.3 | 74.7 |
| Sampling Rate | 0.1 | 0.2 | 0.3 | 0.5 | |
|---|---|---|---|---|---|
| Images | |||||
| 26.33 | 29.19 | 30.30 | 33.27 | ||
| 25.94 | 27.52 | 27.78 | 27.82 | ||
| 26.27 | 28.91 | 29.09 | 31.25 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, D.; Li, Y.; Li, M. Invertible Privacy-Preserving Adversarial Reconstruction for Image Compressed Sensing. Sensors 2023, 23, 3575. https://doi.org/10.3390/s23073575
Xiao D, Li Y, Li M. Invertible Privacy-Preserving Adversarial Reconstruction for Image Compressed Sensing. Sensors. 2023; 23(7):3575. https://doi.org/10.3390/s23073575
Chicago/Turabian StyleXiao, Di, Yue Li, and Min Li. 2023. "Invertible Privacy-Preserving Adversarial Reconstruction for Image Compressed Sensing" Sensors 23, no. 7: 3575. https://doi.org/10.3390/s23073575
APA StyleXiao, D., Li, Y., & Li, M. (2023). Invertible Privacy-Preserving Adversarial Reconstruction for Image Compressed Sensing. Sensors, 23(7), 3575. https://doi.org/10.3390/s23073575