
Efficient Lp Distance Computation Using Function-Hiding Inner Product Encryption for Privacy-Preserving Anomaly Detection



Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
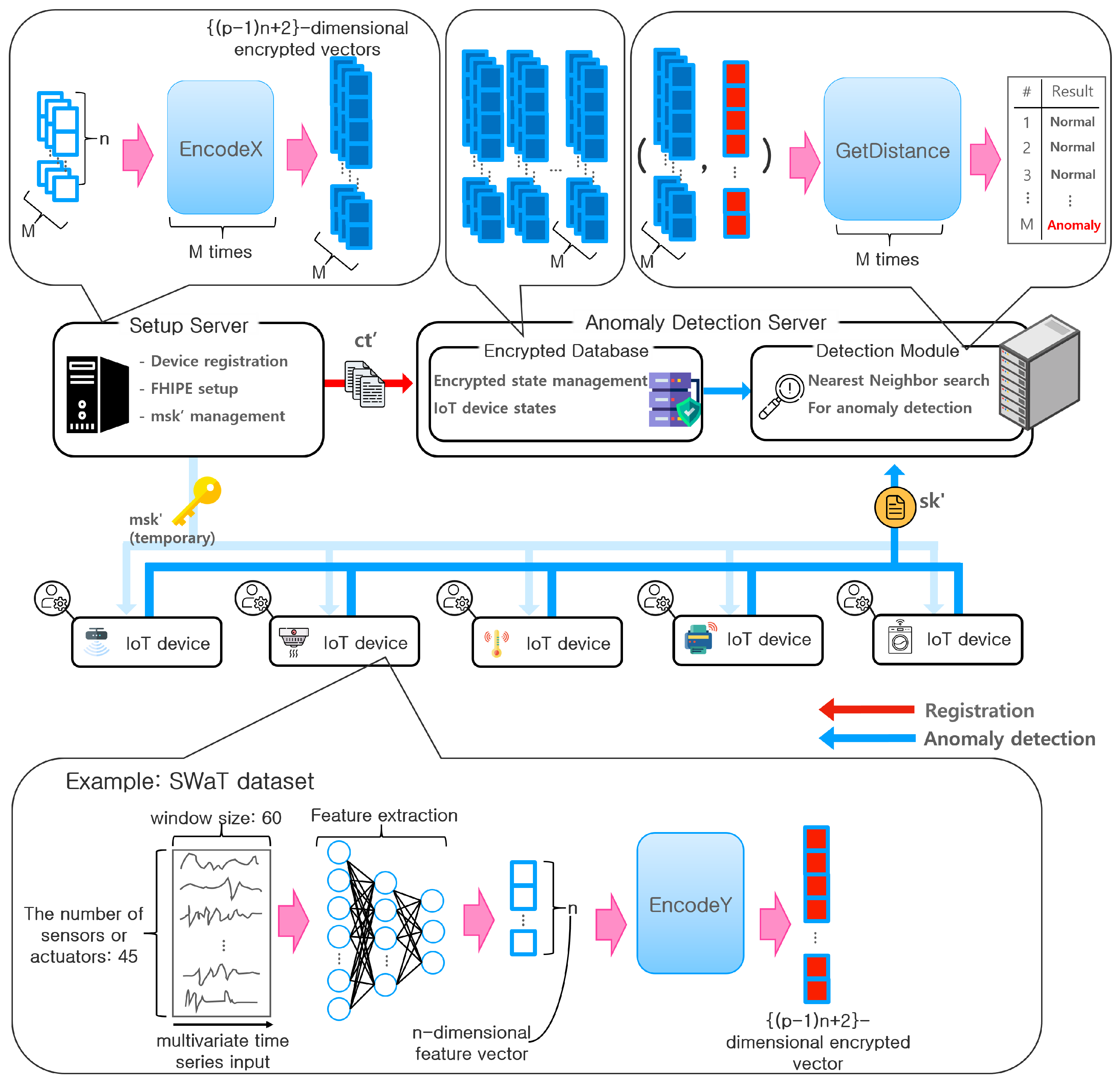
- We propose a method to compute the distance for an even number over FHIPE. We use this distance to compute the mean p-powered error for anomaly detection.
- To demonstrate the feasibility for IoT ecosystems, we implement the proposed method in C++ and conduct experiments on a prototype system composed of a desktop computer (as a server) and the Raspberry Pi (as an IoT device) system. The experimental result shows that the proposed method is sufficiently efficient to be applied to IoT ecosystems in terms of execution times and memory usage.
- We present two possible applications of the proposed distance computation method for privacy-preserving anomaly detection, i.e., smart building management and remote device diagnosis. Accordingly, we suggest a protocol involving multiple IoT devices and two servers.
2. Preliminaries
2.1. Barreto–Naehrig Curve (BN Curve)
2.2. Cryptographic Pairing
- The map e and group operations in , , and are efficiently computable.
- The map e is bilinear for all , and a, b∈. That is,
- The map e is nondegenerate for , . That is,
2.3. FHIPE
- 1.
- Select a bilinear environment according to the security parameter .
- 2.
- Choose a matrix , where refers to a group of square matrices whose elements belong to the finite field and an inverse matrix exists.
- 3.
- Compute .
- 4.
- Output the public parameter and master secret key .
- 1.
- Choose a uniformly random element .
- 2.
- Using the master key and vector , output the secret key such that .
- 2.
- Choose a uniformly random element .
- 2.
- Using the master key and vector , output the ciphertext such that .
- 1.
- Using the public parameter , secret , and ciphertext , compute and .
- 2.
- Find a solution for . If z exists, it is the inner product of and , denoted as . Output z if it exists; otherwise, output ⊥, which indicates that no solution exists.
2.4. and Distances over FHIPE
- 1.
- Construct an -dimensional vector from .
- 2.
- Output .
- 1.
- Construct an -dimensional vector from .
- 2.
- Output .
- 1.
- Calculate .
- 2.
- Output z. z satisfies
3. Proposed Method
- 1.
- Select a bilinear environment according to the security parameter .
- 2.
- Choose a matrix for , where is a group of square matrices whose elements belong to the finite field and an inverse matrix exists.
- 3.
- Compute .
- 4.
- Output the public parameter and master secret key .
- 1.
- Construct a vector as described previously (8).
- 2.
- Output .
- 1.
- Construct a vector as described previously (9).
- 2.
- Output .
- 1.
- Calculate .
- 2.
- Output z. z satisfies .
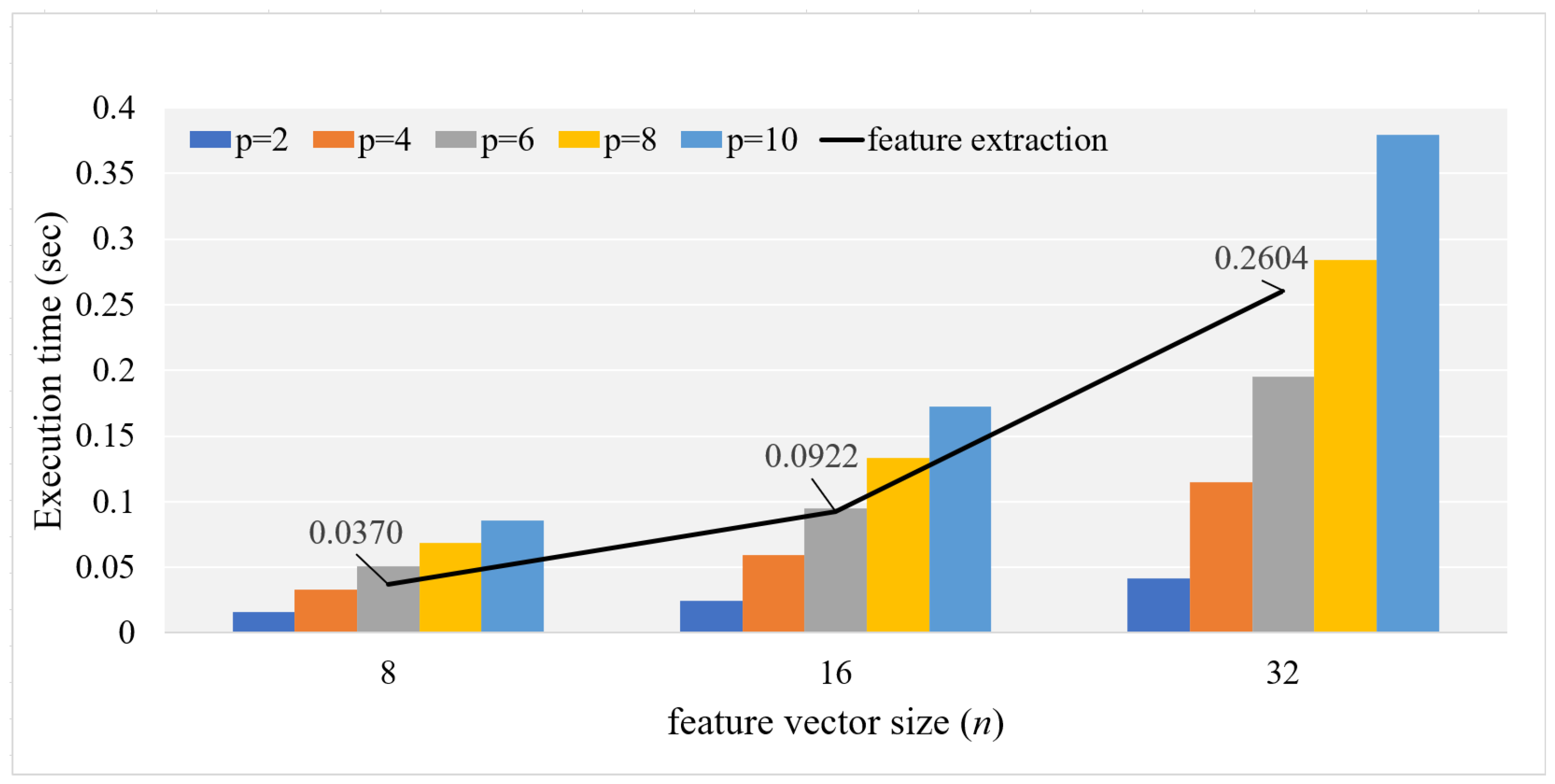
4. Performance Analysis
5. Applications
5.1. Smart Building Management
5.2. Remote Device Diagnosis
5.3. Possible Attacks and Mitigation on Our Systems
- Attack to devices: an attacker may attempt to extract either the state vector or by observing the memory of a device while encryption is performed with . However, this type of physical threat can be mitigated using a a trusted execution environment.
- Network attack: attackers may attempt to sniff the communication between a device and servers or steal the normal-state vectors stored in the database. As the vectors are encrypted by and , attackers learn no information about the vectors, even when they obtain the encrypted vectors. Attackers may attempt to perform replay attacks and man-in-the-middle attacks on the communication between a device and servers to manipulate data. These attacks can be prevented by marking with a timestamp and authenticating with a message authentication code or digital signature of the server on every request and response.
- Attack to servers: if is compromised, s for all devices may be leaked. Therefore, we assume that is protected with a proper mechanism. We also assume that is trustworthy. In other words, it does not attempt to recover the device information with . Under this assumption, the only concern involves , which may want to recover any useful information from its database of encrypted feature vectors. (This also includes the case where is compromised from outside attackers.) However, this is prevented by the security property of FHIPE. For this, however, and must be strictly separated to ensure that they do not share with each other.
6. Limitation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FE | Functional encryption |
| IPE | Inner product encryption |
| FHIPE | Function-hiding inner product encryption |
| DL | Discrete logarithm |
| NN | Nearest neighbor |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| 8 | 0.2829 | 1.3004 | 4.0788 | 9.1245 | 17.5512 |
| 16 | 0.7050 | 6.2276 | 23.2380 | 57.6781 | 116.7271 |
| 32 | 2.7922 | 38.1033 | 157.1521 | 409.0067 | 847.1027 |
| 64 | 13.4316 | 262.8206 | 1154.1302 | 3169.3995 | 6654.9266 |
| 128 | 84.3335 | 1996.4130 | 9102.0401 | 24,568.7575 | 51,736.9127 |
| n | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| 8 | 0.5360 | 1.0178 | 1.4379 | 1.9993 | 2.3923 |
| 16 | 0.6928 | 1.5539 | 2.4909 | 3.3429 | 4.2303 |
| 32 | 1.0629 | 2.7375 | 4.5277 | 6.6077 | 9.3979 |
| 64 | 1.9716 | 5.4832 | 10.7796 | 17.2424 | 24.8129 |
| 128 | 3.6427 | 13.8724 | 28.8228 | 57.3657 | 100.5351 |
| n | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| 8 | 0.4172 | 0.6683 | 0.9487 | 1.3669 | 1.6381 |
| 16 | 0.4990 | 1.0367 | 1.7212 | 2.2604 | 3.1142 |
| 32 | 0.7689 | 2.1281 | 3.5350 | 5.6405 | 8.2282 |
| 64 | 1.3513 | 4.3957 | 9.2588 | 15.2354 | 21.8299 |
| 128 | 2.7581 | 12.0748 | 25.7857 | 51.5276 | 84.5382 |
| n | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| 8 | 3.9364 | 25.9514 | 209.0308 | 1943.1150 | 21,997.1054 |
| 16 | 5.5135 | 33.2946 | 273.7545 | 3005.3176 | 28,656.2952 |
| 32 | 7.1317 | 51.0461 | 422.1917 | 3934.5410 | 44,462.6137 |
| 64 | 11.1817 | 67.7086 | 555.1111 | 6066.4581 | 57,326.4031 |
| 128 | 15.8210 | 105.7101 | 856.1863 | 7930.5029 | 89,076.5944 |
| n | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| 8 | 0.0334 | 0.0681 | 0.1046 | 0.1382 | 0.1752 |
| 16 | 0.0515 | 0.1202 | 0.1906 | 0.2638 | 0.3386 |
| 32 | 0.0855 | 0.2281 | 0.3780 | 0.5351 | 0.6965 |
| 64 | 0.1560 | 0.4553 | 0.7879 | 1.1443 | 1.5455 |
| 128 | 0.3026 | 0.9714 | 1.7483 | 2.6981 | 3.8167 |
| n | 2 | 4 | 6 | 8 | 10 |
|---|---|---|---|---|---|
| 8 | 0.0162 | 0.0332 | 0.0512 | 0.0687 | 0.0866 |
| 16 | 0.0249 | 0.0596 | 0.0951 | 0.1337 | 0.1732 |
| 32 | 0.0419 | 0.1143 | 0.1944 | 0.2809 | 0.3765 |
| 64 | 0.0770 | 0.2376 | 0.4298 | 0.6494 | 0.9114 |
| 128 | 0.1534 | 0.5407 | 1.0486 | 1.7215 | 2.5846 |
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Denning, D. An Intrusion-Detection Model. IEEE Trans. Softw. Eng. 1987, SE-13, 222–232. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. CorrAUC: A malicious bot-IoT traffic detection method in IoT network using machine-learning techniques. IEEE Internet Things J. 2020, 8, 3242–3254. [Google Scholar] [CrossRef]
- Shalyga, D.; Filonov, P.; Lavrentyev, A. Anomaly Detection for Water Treatment System based on Neural Network with Automatic Architecture Optimization. arXiv 2018, arXiv:1807.07282. [Google Scholar]
- iTrust lab of Singapore University of Technology and Design (SUTD). Available online: https://itrust.sutd.edu.sg/itrust-labs-home/itrust-labs_swat (accessed on 16 January 2023).
- Meteriz, Ü.; Y𝜄ld𝜄ran, N.F.; Kim, J.; Mohaisen, D. Understanding the Potential Risks of Sharing Elevation Information on Fitness Applications. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 464–473. [Google Scholar]
- Tabassum, M.; Kosiński, T.; Frik, A.; Malkin, N.; Wijesekera, P.; Egelman, S.; Lipford, H.R. Investigating Users’ Preferences and Expectations for Always-Listening Voice Assistants. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 3, 1–23. [Google Scholar] [CrossRef]
- Ma, T.; Kim, S.D.; Wang, J.; Zhao, Y. Privacy Preserving in Ubiquitous Computing: Challenges & Issues. In Proceedings of the 2008 IEEE International Conference on e-Business Engineering, Xi’an, China, 22–24 October 2008; pp. 297–301. [Google Scholar]
- Hall, D.; Llinas, J. An introduction to multisensor data fusion. Proc. IEEE 1997, 85, 6–23. [Google Scholar] [CrossRef]
- Nesa, N.; Banerjee, I. IoT-Based Sensor Data Fusion for Occupancy Sensing Using Dempster–Shafer Evidence Theory for Smart Buildings. IEEE Internet Things J. 2017, 4, 1563–1570. [Google Scholar] [CrossRef]
- Guo, E.; Ryan-Mosley, T. Inside the Bitter Campus Privacy Battle over Smart Building Sensors, MIT Technology Review, 3 April 2023. Available online: https://www.technologyreview.com/2023/04/03/1070665/cmu-university-privacy-battle-smart-building-sensors-mites/?truid=&utm_source=the_download&utm_medium=email&utm_campaign=the_download.unpaid.engagement&utm_term=&utm_content=04-03-2023&mc_cid=bcaff9641c&mc_eid=fa860b1d8f (accessed on 19 April 2023).
- Kim, S.; Lewi, K.; Mandal, A.; Montgomery, H.; Roy, A.; Wu, D.J. Function-Hiding Inner Product Encryption Is Practical. In Proceedings of the Security and Cryptography for Networks, Amalfi, Italy, 5–7 September 2018; Catalano, D., De Prisco, R., Eds.; Springer: Cham, Switzerland, 2018; pp. 544–562. [Google Scholar]
- Jeon, S.Y.; Lee, M.K. Acceleration of Inner-Pairing Product Operation for Secure Biometric Verification. Sensors 2021, 21, 2859. [Google Scholar] [CrossRef]
- Zhou, K.; Ren, J. PassBio: Privacy-Preserving User-Centric Biometric Authentication. IEEE Trans. Inf. Forensics Secur. 2018, 13, 3050–3063. [Google Scholar] [CrossRef]
- Lee, J.; Kim, D.; Kim, D.; Song, Y.; Shin, J.; Cheon, J.H. Instant Privacy-Preserving Biometric Authentication for Hamming Distance; Cryptology ePrint Archive, Report 2018/1214; IACR. 2018. Available online: https://eprint.iacr.org/2018/1214 (accessed on 21 April 2023).
- Im, J.H.; Jeon, S.Y.; Lee, M.K. Practical Privacy-Preserving Face Authentication for Smartphones Secure Against Malicious Clients. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2386–2401. [Google Scholar] [CrossRef]
- Wang, X.; Xue, H.; Liu, X.; Pei, Q. A Privacy-Preserving Edge Computation-Based Face Verification System for User Authentication. IEEE Access 2019, 7, 14186–14197. [Google Scholar] [CrossRef]
- Li, X.Y.; Jung, T. Search me if you can: Privacy-preserving location query service. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2760–2768. [Google Scholar]
- Wei, F.; Vijayakumar, P.; Kumar, N.; Zhang, R.; Cheng, Q. Privacy-Preserving Implicit Authentication Protocol Using Cosine Similarity for Internet of Things. IEEE Internet Things J. 2021, 8, 5599–5606. [Google Scholar] [CrossRef]
- Murugesan, M.; Jiang, W.; Clifton, C.; Si, L.; Vaidya, J. Efficient privacy-preserving similar document detection. VLDB J. 2010, 19, 457–475. [Google Scholar] [CrossRef]
- Gheid, Z.; Challal, Y. An efficient and privacy-preserving similarity evaluation for big data analytics. In Proceedings of the 2015 IEEE/ACM 8th International Conference on Utility and Cloud Computing (UCC), Limassol, Cyprus, 7–10 December 2015; pp. 281–289. [Google Scholar]
- Li, D.; Chen, C.; Lv, Q.; Shang, L.; Zhao, Y.; Lu, T.; Gu, N. An algorithm for efficient privacy-preserving item-based collaborative filtering. Future Gener. Comput. Syst. 2016, 55, 311–320. [Google Scholar] [CrossRef]
- Alabdulatif, A.; Kumarage, H.; Khalil, I.; Yi, X. Privacy-preserving anomaly detection in cloud with lightweight homomorphic encryption. J. Comput. Syst. Sci. 2017, 90, 28–45. [Google Scholar] [CrossRef]
- Alabdulatif, A.; Khalil, I.; Kumarage, H.; Zomaya, A.Y.; Yi, X. Privacy-preserving anomaly detection in the cloud for quality assured decision-making in smart cities. J. Parallel Distrib. Comput. 2019, 127, 209–223. [Google Scholar] [CrossRef]
- Mehnaz, S.; Bertino, E. Privacy-preserving Real-time Anomaly Detection Using Edge Computing. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 469–480. [Google Scholar]
- Lyu, L.; Law, Y.W.; Erfani, S.M.; Leckie, C.; Palaniswami, M. An improved scheme for privacy-preserving collaborative anomaly detection. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, NSW, Australia, 14–18 March 2016; pp. 1–6. [Google Scholar]
- Mukherjee, S.; Chen, Z.; Gangopadhyay, A. A privacy-preserving technique for Euclidean distance-based mining algorithms using Fourier-related transforms. VLDB J. 2006, 15, 293–315. [Google Scholar] [CrossRef]
- Kikuchi, H.; Nagai, K.; Ogata, W.; Nishigaki, M. Privacy-preserving similarity evaluation and application to remote biometrics authentication. Soft Comput. 2010, 14, 529–536. [Google Scholar] [CrossRef]
- Bringer, J.; Chabanne, H.; Favre, M.; Patey, A.; Schneider, T.; Zohner, M. GSHADE: Faster privacy-preserving distance computation and biometric identification. In Proceedings of the 2nd ACM Workshop on Information Hiding and Multimedia Security, Santa Barbara, CA, USA, 27–28 June 2014; pp. 187–198. [Google Scholar]
- Kang, H.E.D.; Kim, D.; Kim, S.; Kim, D.D.; Cheon, J.H.; Anthony, B.W. Homomorphic Encryption as a secure PHM outsourcing solution for small and medium manufacturing enterprise. J. Manuf. Syst. 2021, 61, 856–865. [Google Scholar] [CrossRef]
- Kwon, H.Y.; Lee, M.K. Comments on “PassBio: Privacy-Preserving User-Centric Biometric Authentication”. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2816–2817. [Google Scholar] [CrossRef]
- Jia, Q.; Guo, L.; Jin, Z.; Fang, Y. Privacy-Preserving Data Classification and Similarity Evaluation for Distributed Systems. In Proceedings of the 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS), Nara, Japan, 27–30 June 2016; pp. 690–699. [Google Scholar]
- Barreto, P.S.L.M.; Naehrig, M. Pairing-Friendly Elliptic Curves of Prime Order. In Proceedings of the 12th International Conference on Selected Areas in Cryptography, Kingston, ON, Canada, 11–12 August 2005; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- El Mrabet, N.; Joye, M. Guide to Pairing-Based Cryptography; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Fallat, S.M.; Johnson, C.R. Hadamard powers and totally positive matrices. Linear Algebra Appl. 2007, 423, 420–427. [Google Scholar] [CrossRef]
- A Library for Doing Numbery Theory (NTL). Available online: https://www.shoup.net/ntl (accessed on 16 January 2023).
- A Portable and Fast Pairing-Based Cryptography Library. Available online: https://github.com/herumi/mcl (accessed on 16 January 2023).
- The GNU MP Bignum Library. Available online: https://gmplib.org/ (accessed on 16 January 2023).
- Wang, C.; Wang, B.; Liu, H.; Qu, H. Anomaly detection for industrial control system based on autoencoder neural network. Wirel. Commun. Mob. Comput. 2020, 2020, 8897926. [Google Scholar] [CrossRef]




| Desktop Computer | Raspberry Pi | |
|---|---|---|
| CPU | AMD Ryzen5 3600 6-Core @ 3.60 GHz | ARM Cortex-A7 4-Core @ 900 MHz |
| Memory | 16 GB | 1 GB |
| OS | Ubuntu 20.04 (using Windows 11 Pro WSL2) | Raspbian |
| language | C++11 | |
| SW library | FHIPE library [13], NTL 11.3.2 [36], MCL 1.51 [37], GMP 6.1.2 [38] | |
| Method | Cryptographic Primitive | Protection | Metric | p |
|---|---|---|---|---|
| [23] | HE | Client data | Euclidean distance | 2 |
| [24] | HE | Client data | Euclidean distance | 2 |
| [25] | HE (Additive only) | Client data | Q-function * (customized metric) | – |
| [26] | Differential Privacy | Train data | Mean absolute error * | 1 |
| Proposed | FE | Client data | distance | any even p |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, D.-H.; Jeon, S.-Y.; Hong, J.; Lee, M.-K. Efficient Lp Distance Computation Using Function-Hiding Inner Product Encryption for Privacy-Preserving Anomaly Detection. Sensors 2023, 23, 4169. https://doi.org/10.3390/s23084169
Ryu D-H, Jeon S-Y, Hong J, Lee M-K. Efficient Lp Distance Computation Using Function-Hiding Inner Product Encryption for Privacy-Preserving Anomaly Detection. Sensors. 2023; 23(8):4169. https://doi.org/10.3390/s23084169
Chicago/Turabian StyleRyu, Dong-Hyeon, Seong-Yun Jeon, Junho Hong, and Mun-Kyu Lee. 2023. "Efficient Lp Distance Computation Using Function-Hiding Inner Product Encryption for Privacy-Preserving Anomaly Detection" Sensors 23, no. 8: 4169. https://doi.org/10.3390/s23084169
APA StyleRyu, D. -H., Jeon, S. -Y., Hong, J., & Lee, M. -K. (2023). Efficient Lp Distance Computation Using Function-Hiding Inner Product Encryption for Privacy-Preserving Anomaly Detection. Sensors, 23(8), 4169. https://doi.org/10.3390/s23084169