



A Novel CNN Model for Classification of Chinese Historical Calligraphy Styles in Regular Script Font





Abstract
:1. Introduction
2. Related Works
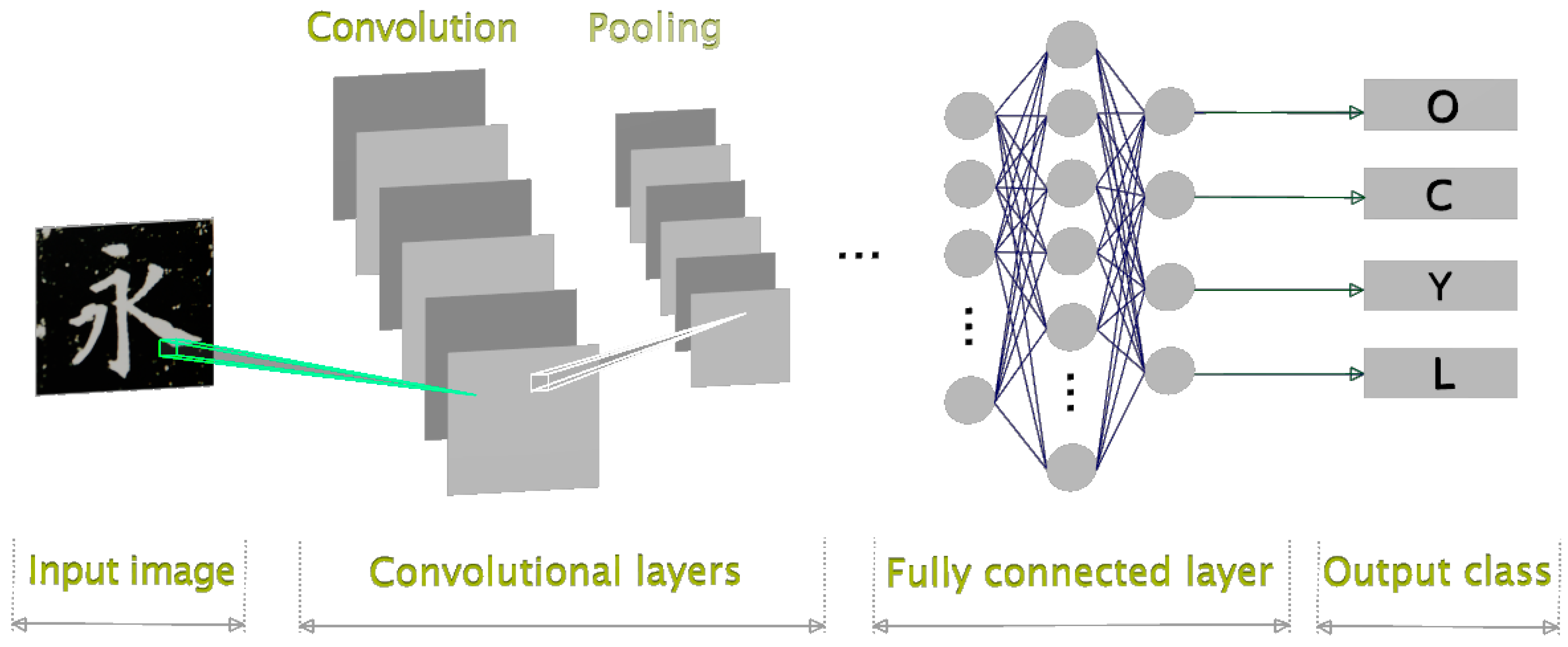
3. A CNN Model for the Classification of Chinese Calligraphy Images
4. Experiments and Analysis
4.1. Dataset Construction
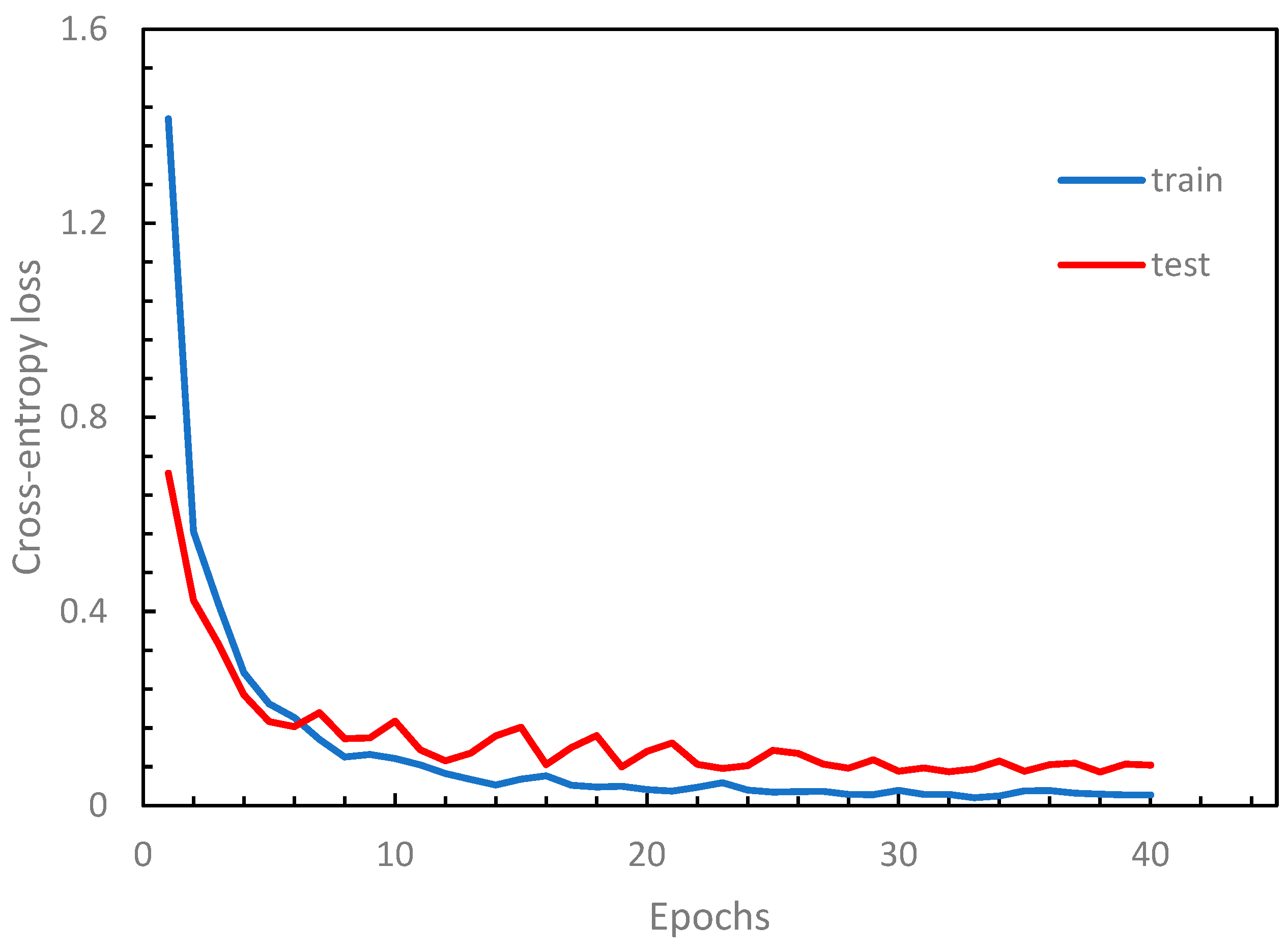
4.2. Numerical Experiments, Results, and Discussion
5. Conclusions and Future Works
- Development of a comprehensive image dataset for Chinese calligraphy (regular script) classification, comprising over 8000 images, serving as a valuable resource for future scholarly endeavors.
- Pioneering the application of CNN in the classification of personal styles in Chinese calligraphy.
- Achieving elevated performance metrics with the CNN model, as evidenced by test accuracy rates ranging from 89.5% to 96.2%.
- Effective fine tuning of both architectural and algorithmic parameters within the classical CNN framework, resulting in the identification of optimal parameters associated with outstanding performance accuracy.
- Preliminary investigation into the challenge of an imbalanced distribution within the training data, laying the groundwork for addressing this issue in subsequent studies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Q.; Balsys, R.J. Applying Fractal and Chaos Theory to Animation in the Chinese Literati Tradition. In Proceedings of the Sixth International Conference on Computer Graphics, Imaging and Visualization, Tianjin, China, 11–14 August 2009. [Google Scholar] [CrossRef]
- Fitzgerald, C.P. The Horizon History of China; American Heritage Publishing Co., Inc.: Rockville, MD, USA, 1969. [Google Scholar]
- Wong, E. The Shambhala Guide to Taoism; Shambhala Publications, Inc.: Boulde, CO, USA, 1997. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Liu, S. (Ed.) Full Colour Art History of Chinese Calligraphy, 1st ed.; Ningxia People’s Publishing House: Yinchuan, China, 2003; pp. 114–115. [Google Scholar]
- Li, W. Research on Key Technologies of Chinese Calligraphy Synthesis and Recognition for Chinese Character of Video. Ph.D. Thesis, School of Information Science and Engineering, Xiamen University, Xiamen, China, 2013. [Google Scholar]
- Lin, Y. Research and Application of Chinese Calligraphic Character Recognition. Ph.D. Thesis, College of Computer Science, Zhejiang University, Hangzhou, China, 2014. [Google Scholar]
- Mao, T.J. Calligraphy Writing Style Recognition. Ph.D. Thesis, College of Computer Science, Zhejiang University,, Hangzhou, China, 2014. [Google Scholar]
- Wang, X.; Zhang, X.F.; Han, D.Z. Calligraphy style identification based on visual features. Mod. Comput. 2016, 21, 39–46. [Google Scholar]
- Yan, Y.F. Calligraphy Style Recognition Based on CNN. Ph.D. Thesis, College of Information and Computer, Taiyuan University of Technology, Taiyuan, China, 2018. [Google Scholar]
- Cui, W.; Inoue, K. Chinese calligraphy recognition system based on convolutional neural network. ICIC Express Lett. 2021, 15, 1187–1195. [Google Scholar] [CrossRef]
- Chen, L. Research and Application of Chinese Calligraphy Character Recognition Algorithm Based on Image Analysis. In Proceedings of the 2021 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 27–28 August 2021; pp. 405–410. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Y.; Wang, P.; Xu, R.; Ma, W.; Zhu, Y.; Zhang, B. Fake Calligraphy Recognition Based on Deep Learning. In International Conference on Artificial Intelligence and Security, ICAIS 2021: Artificial Intelligence and Security; Lecture Notes in Computer Science book series; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12736, pp. 585–596. [Google Scholar]
- Zhai, C.; Chen, Z.; Li, J.; Xu, B. Chinese image text recognition with BLSTM-CTC: A segmentation-free method. In Proceedings of the 7th Chinese Conference on Pattern Recognition—(CCPR), Chengdu, China, 5–7 November 2016; pp. 525–536. [Google Scholar]
- Li, B. Convolution Neural Network for Traditional Chinese Calligraphy Recognition. CS231N Final Project. 2016. Available online: http://cs231n.stanford.edu/reports/2016/pdfs/257Report.pdf (accessed on 18 May 2021).
- Wen, Y.; Sigüenza, J. Chinese calligraphy: Character style recognition based on full-page document. In Proceedings of the 2019 8th International Conference on Computing and Pattern Recognition, Prague, Czech Republic, 19–21 February 2019; pp. 390–394. [Google Scholar] [CrossRef]
- Wang, M.; Fu, Q.; Wang, X.; Wu, Z.; Zhou, M. Evaluation of Chinese calligraphy by using DBSC vectorization and ICP algorithm. Math. Probl. Eng. 2016, 2016, 4845092. [Google Scholar] [CrossRef]
- Gao, P.; Gu, G.; Wu, J.; Wei, B. Chinese calligraphic style representation for recognition. Int. J. Doc. Anal. Recognit. (IJDAR) 2017, 20, 59–68. [Google Scholar]
- Zou, J.; Zhang, J.; Wang, L. Handwritten Chinese character recognition by convolutional neural network and similarity ranking. arXiv 2019, arXiv:1908.11550. [Google Scholar]
- Zhang, J.; Yu, W.; Wang, Z.; Li, J.; Pan, Z. Attention-Enhanced CNN for Chinese Calligraphy Styles Classification. In Proceedings of the 2021 IEEE 7th International Conference on Virtual Reality, Foshan, China, 20–22 May 2021. [Google Scholar]
- Liu, H.; Liu, T.; Chen, Y.; Zhang, Z.; Li, Y.-F. EHPE: Skeleton Cues-based Gaussian Coordinate Encoding for Efficient Human Pose Estimation. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-Aware Representation Learning for Head Pose Estimation in Industrial Human–Computer Interaction. IEEE Trans. Ind. Inform. 2022, 18, 7107–7117. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y.-F. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2022, 433, 310–322. [Google Scholar] [CrossRef]
- Xu, Y.; Qian, W.; Li, N.; Li, H. Typical advances of artificial intelligence in civil engineering. Adv. Struct. Eng. 2022, 25, 3405–3424. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, Y.; Zhang, Y.; Li, H. Attribute-based structural damage identification by few-shot meta learning with inter-class knowledge transfer. Struct. Health Monit. 2021, 20, 1494–1517. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef] [PubMed]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courvile, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Conference 2012, Lake Tahoe, NV, USA, 3–5 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 12–15 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, G.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Wang, X.; Zhang, M.; Zhu, J.; Zhen, R.; Wu, Q. MPCE: A maximum probability based cross-entropy loss function for neural network classification. IEEE Access 2015, 7, 146331–146341. [Google Scholar] [CrossRef]
- Sinha, T.; Haidar, A.; Verma, B. Particle swarm optimization based approach for finding optimal values of convolutional neural network parameters. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar]
- Available online: https://www.tensorflow.org/tutorials/images/classification (accessed on 15 October 2022).
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Szeghalmy, S.; Fazekas, A. A Comparative Study of the Use of Stratified Cross-Validation and Distribution-balanced Stratified Cross-Validation Imbalanced Learning. Sensors 2023, 23, 2333. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seal (zhuan): |  |
| Clerical (li): |  |
| Cursive (cao): |  |
| Semi-cursive (xing): |  |
| Regular (kai): |  |
| Parameters | Values |
|---|---|
| Input image size | 64 × 64 × 1 |
| Filter size (F × F) | 3 × 3, 5 × 5, 7 × 7 |
| Number of filters (K) | 16, 24, 32, 48 |
| Pooling size (Max Pooling) | 2 × 2 stride = 2 |
| Configuration type (Cn) | C1, C2, C3, C4, C5 |
| Neuron numbers of FC Layer (N) | 512, 256, 128 |
| (1) Filter size 3 × 3 (K = 32) | |||
| Block | Layer | Layer Type | Description (Feature Map Size) |
| Block 1 | L1 | Conv + ReLU | 32@62 × 62 |
| L2 | Max Pooling | 32@31 × 31 | |
| Block 2 | L3 | Conv + ReLU | 64@29 × 29 |
| L4 | Max Pooling | 64@14 × 14 | |
| Block 3 | L5 | Conv + ReLU | 128@12 × 12 |
| L6 | Max Pooling | 128@6 × 6 | |
| Block 4 | L7 | Conv + ReLU | 256@4 × 4 |
| L8 | Max Pooling | 256@2 × 2 | |
| Block 5 (FC layers) | L9 | FC1 | 512 neurons |
| L10 | FC2 | 256 neurons | |
| L11 | FC3 (softmax) | 4 neurons | |
| (2) Filter size 5 × 5 (K = 32) | |||
| Block | Layer | Layer Type | Description (Feature Map Size) |
| Block 1 | L1 | Conv + ReLU | 32@60 × 60 |
| L2 | Max Pooling | 32@30 × 30 | |
| Block 2 | L3 | Conv + ReLU | 64@26 × 26 |
| L4 | Max Pooling | 64@13 × 13 | |
| Block 3 | L5 | Conv + ReLU | 128@9 × 9 |
| L6 | Max Pooling | 128@4 × 4 | |
| Block 4 (FC layers) | L7 | FC1 | 512 neurons |
| L8 | FC2 | 256 neurons | |
| L9 | FC3 (softmax) | 4 neurons | |
| (3) Filter sizes, 5 × 5, 3 × 3 (K = 32) | |||
| Block | Layer | Layer Type | Description (Feature Map Size) |
| Block 1 | L1 | Conv + ReLU | 32@60 × 60 |
| L2 | Max Pooling | 32@30 × 30 | |
| Block 2 | L3 | Conv + ReLU | 64@28 × 28 |
| L4 | Max Pooling | 64@14 × 14 | |
| Block 3 | L5 | Conv + ReLU | 128@12 × 12 |
| L6 | Max Pooling | 128@6 × 6 | |
| Block 4 | L7 | Conv + ReLU | 256@4 × 4 |
| L8 | Max Pooling | 256@2 × 2 | |
| Block 5 (FC layers) | L9 | FC1 | 512 neurons |
| L10 | FC2 | 256 neurons | |
| L11 | FC3 (softmax) | 4 neurons | |
| (4) Filter size 7 × 7 (K = 32) | |||
| Block | Layer | Layer Type | Description (Feature Map Size) |
| Block 1 | L1 | Conv + ReLU | 32@58 × 58 |
| L2 | Max Pooling | 32@29 × 29 | |
| Block 2 | L3 | Conv + ReLU | 64@23 × 23 |
| L4 | Max Pooling | 64@11 × 11 | |
| Block 3 | L5 | Conv + ReLU | 128@5 × 5 |
| L6 | Max Pooling | 128@2 × 2 | |
| Block 5 (FC layers) | L7 | FC1 | 512 neurons |
| L8 | FC2 | 256 neurons | |
| L9 | FC3 (softmax) | 4 neurons | |
| (5) VGG-like style (filter size 3 × 3, K = 32) | |||
| Block | Layer | Layer Type | Description (Feature Map Size) |
| Block 1 | L1 | Conv + ReLU | 32@62 × 62 |
| L2 | Conv + ReLU | 32@60 × 60 | |
| L3 | Max Pooling | 32@30 × 30 | |
| Block 2 | L4 | Conv + ReLU | 64@28 × 28 |
| L5 | Conv + ReLU | 64@26 × 26 | |
| L6 | Conv + ReLU | 64@24 × 24 | |
| L7 | Max Pooling | 64@12 × 12 | |
| Block 3 | L8 | Conv + ReLU | 128@10 × 10 |
| L9 | Conv + ReLU | 128@8 × 8 | |
| L10 | Conv + ReLU | 128@6 × 6 | |
| L11 | Max Pooling | 128@3 × 3 | |
| Block 4 | L12 | Conv + ReLU | 256@1 × 1 |
| Block 5 (FC layers) | L13 | FC1 | 256 neurons |
| L14 | FC2 | 128 neurons | |
| L15 | FC3 (softmax) | 4 neurons | |
| Optimizer | Adam |
|---|---|
| Learning rate | 1.0 × 10−4 |
| Batch size | 32, 64 |
| Dropout rate | 0.25, 0.5 |
| Architecture | Accuracy | ||
|---|---|---|---|
| K | Configuration | Training | Testing |
| 16 | C1 | 98.6% | 94.3% |
| C2 | 96.3% | 92.2% | |
| C3 | 98.7% | 95.5% | |
| C4 | 93.7% | 89.5% | |
| C5 | 96.6% | 93.7% | |
| 24 | C1 | 99.2% | 95.2% |
| C2 | 98.9% | 94.0% | |
| C3 | 99.0% | 95.7% | |
| C4 | 95.7% | 90.4% | |
| C5 | 98.1% | 93.8% | |
| 32 | C1 | 99.5% | 96.2% |
| C2 | 98.2% | 94.1% | |
| C3 | 98.9% | 94.9% | |
| C4 | 95.2% | 92.2% | |
| C5 | 98.7% | 95.1% | |
| 48 | C1 | 99.1% | 95.8% |
| C2 | 97.7% | 93.5% | |
| C3 | 98.3% | 94.5% | |
| C4 | 96.8% | 91.5% | |
| C5 | 98.2% | 93.9% | |
| Class | Type 1 (C1) | Type 2 (C2) |
|---|---|---|
| O | 93.8% | 92.1% |
| C | 98.3% | 96.2% |
| L | 97.0% | 95.2% |
| Y | 95.7% | 93.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Li, M.; Agustin, D.; Li, L.; Jha, M. A Novel CNN Model for Classification of Chinese Historical Calligraphy Styles in Regular Script Font. Sensors 2024, 24, 197. https://doi.org/10.3390/s24010197
Huang Q, Li M, Agustin D, Li L, Jha M. A Novel CNN Model for Classification of Chinese Historical Calligraphy Styles in Regular Script Font. Sensors. 2024; 24(1):197. https://doi.org/10.3390/s24010197
Chicago/Turabian StyleHuang, Qing, Michael Li, Dan Agustin, Lily Li, and Meena Jha. 2024. "A Novel CNN Model for Classification of Chinese Historical Calligraphy Styles in Regular Script Font" Sensors 24, no. 1: 197. https://doi.org/10.3390/s24010197
APA StyleHuang, Q., Li, M., Agustin, D., Li, L., & Jha, M. (2024). A Novel CNN Model for Classification of Chinese Historical Calligraphy Styles in Regular Script Font. Sensors, 24(1), 197. https://doi.org/10.3390/s24010197