The generation of environmental and urban data in the city is used to develop the method. In addition, information on industrial areas and traffic routes, the generation of PM2.5 and noise heat maps, and the integration of environmental and traffic data are included. This information allows the evaluation of predictive models for air quality and noise levels, highlighting the performance metrics used.
2.1. Review of Similar Works
Numerous studies have addressed the topic from various perspectives in urban environmental monitoring, using multiple methodologies and technologies. Reviewing the existing literature, we found that a common approach involves using IoT sensor networks to collect data on factors such as air quality and noise in urban environments. These studies have been fundamental to understanding how pollution and other environmental factors affect city life [
21].
For example, some studies have focused on deploying sensor networks to precisely monitor levels of pollutants such as PM2.5 and NOx, providing valuable real-time air quality data. These projects have demonstrated the effectiveness of using low-cost, easily implemented technology to obtain critical environmental data [
22,
23]. Additionally, other work has explored the use of advanced data processing algorithms to interpret large environmental data sets, allowing researchers and policymakers to gain a deeper understanding of ecological patterns and trends [
23].
This work builds on these previous studies and seeks to advance the field by integrating more advanced IoT technologies and developing sophisticated algorithms for data analysis. Unlike previous studies that might have focused on specific aspects of environmental monitoring, this proposal aims to provide a holistic and systematic approach [
24]. This includes not only the collection of environmental data but also its detailed analysis to inform urban management policies and strategies better [
25,
26].
The contribution of this work to the phenomenon under study not only expands the scope of the data collected, but also improves the accuracy and usefulness of the analysis of this data. In doing so, we hope to offer new perspectives and solutions to urban environmental challenges, thereby creating healthier and more sustainable cities [
27,
28]. Additionally, our focus on optimizing and automating data collection and analysis represents a significant advance in the efficiency and effectiveness of urban environmental monitoring.
2.2. Monitoring Platform Design
Open data available on the web from recognized sources, such as the Urban Data Platform of the European Commission, France’s National Address Base, and the Open Data Barometer, are used to design the urban environmental monitoring platform. These sources offer valuable and updated information on urban variables, integrated into the platform developed to enrich the analysis and understanding of city environmental challenges.
2.2.1. Platform Architecture
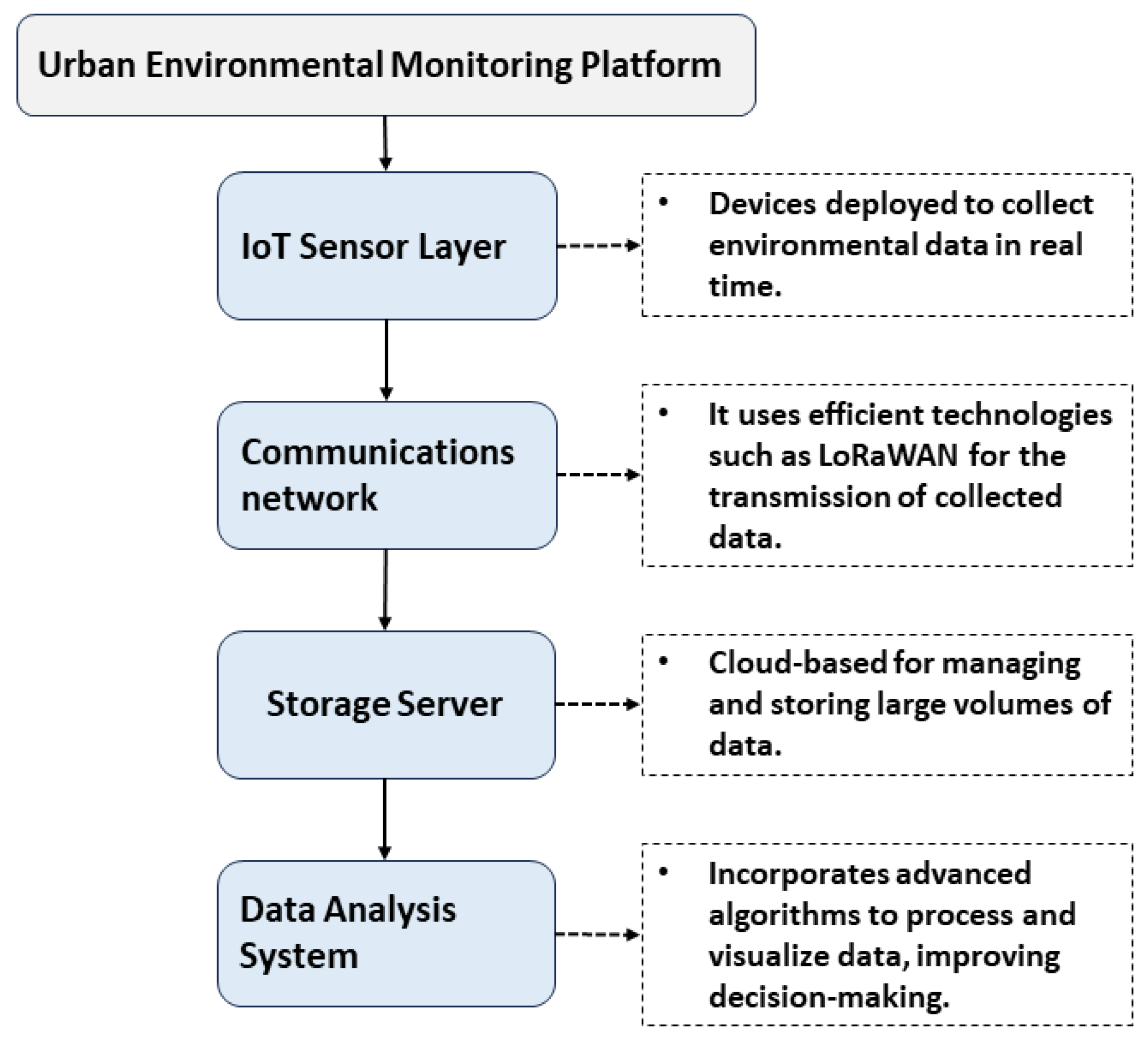
Figure 1 shows the block diagram of the urban environmental monitoring platform, detailing its structure, composed of four main layers: the IoT Sensor Layer, the Communications Network, the Storage Server, and the Data Analysis System [
29,
30]. The diagram illustrates the structure and data flow of our urban environmental monitoring platform.
The sensor layer is responsible for collecting environmental data in real-time. These data are transmitted over a network that uses efficient technologies such as LoRaWAN [
31,
32]. The cloud-based storage server manages and stores large volumes of collected data. The data analysis system processes and interprets this information using advanced algorithms, which improves decision-making related to the urban environment.
2.2.2. Selection of IoT Technologies
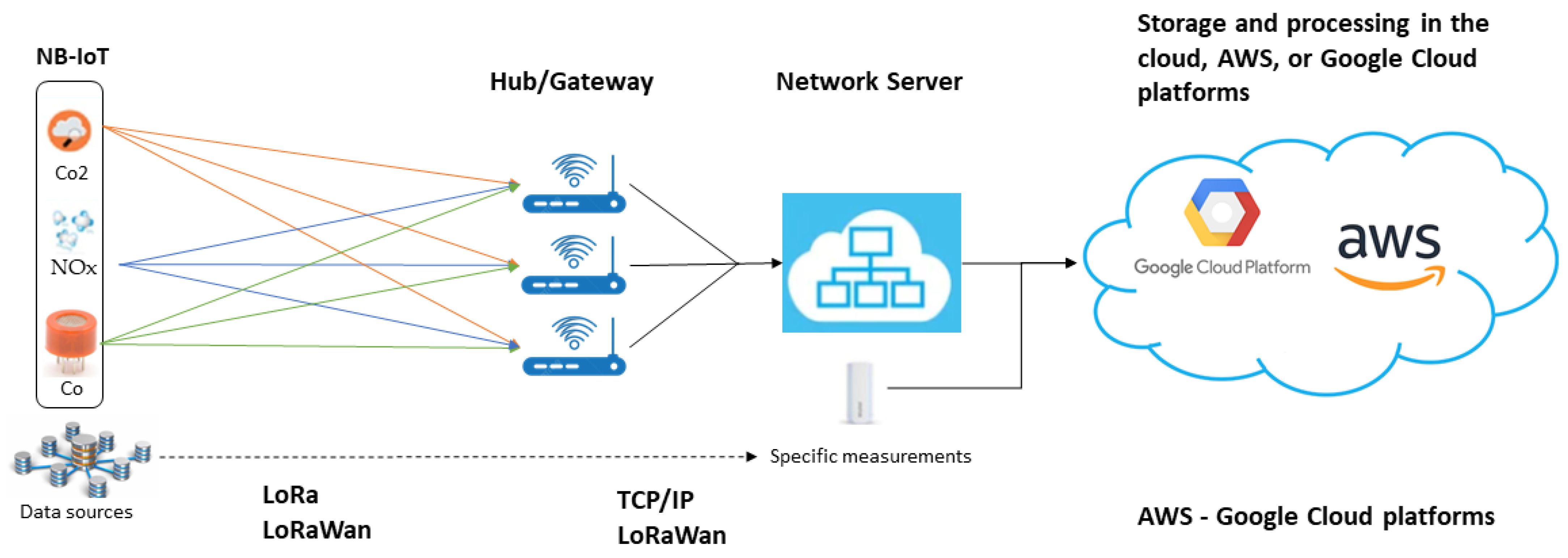
For implementing the urban environmental monitoring platform, a range of IoT technologies has been carefully selected based on their efficiency, accuracy, and reliability. The air quality sensors will be optical for PM2.5 and PM10 particles and electrochemical for gases such as NOx and SOx, providing essential data on atmospheric pollution [
33]. The infrared sensors will measure the levels of CO and CO
2, while the specific devices for ozone will give us information about this gas critical for public health and environmental quality [
34].
Regarding noise pollution, calibrated microphones will offer us precise measurements of noise levels, allowing us to address this omnipresent urban pollutant effectively [
35]. For data communication, technologies such as LoRaWAN and NB-IoT, ideal for low-power, long-range IoT data transmission, and networks for applications requiring real-time transmission and support for a high density of connected devices, were chosen [
36,
37,
38].
The cloud infrastructure, selected for its scalability and robustness, serves as the core for data storage and processing, using big data tools to manage and analyze the large volumes of information collected [
39,
40]. This is complemented by data visualization software and machine learning algorithms to interpret the data and generate predictive models that inform and improve urban environmental planning and response decisions. Each of these components ensures maximum operational consistency and energy efficiency, thus ensuring high-quality data collection and meaningful insights.
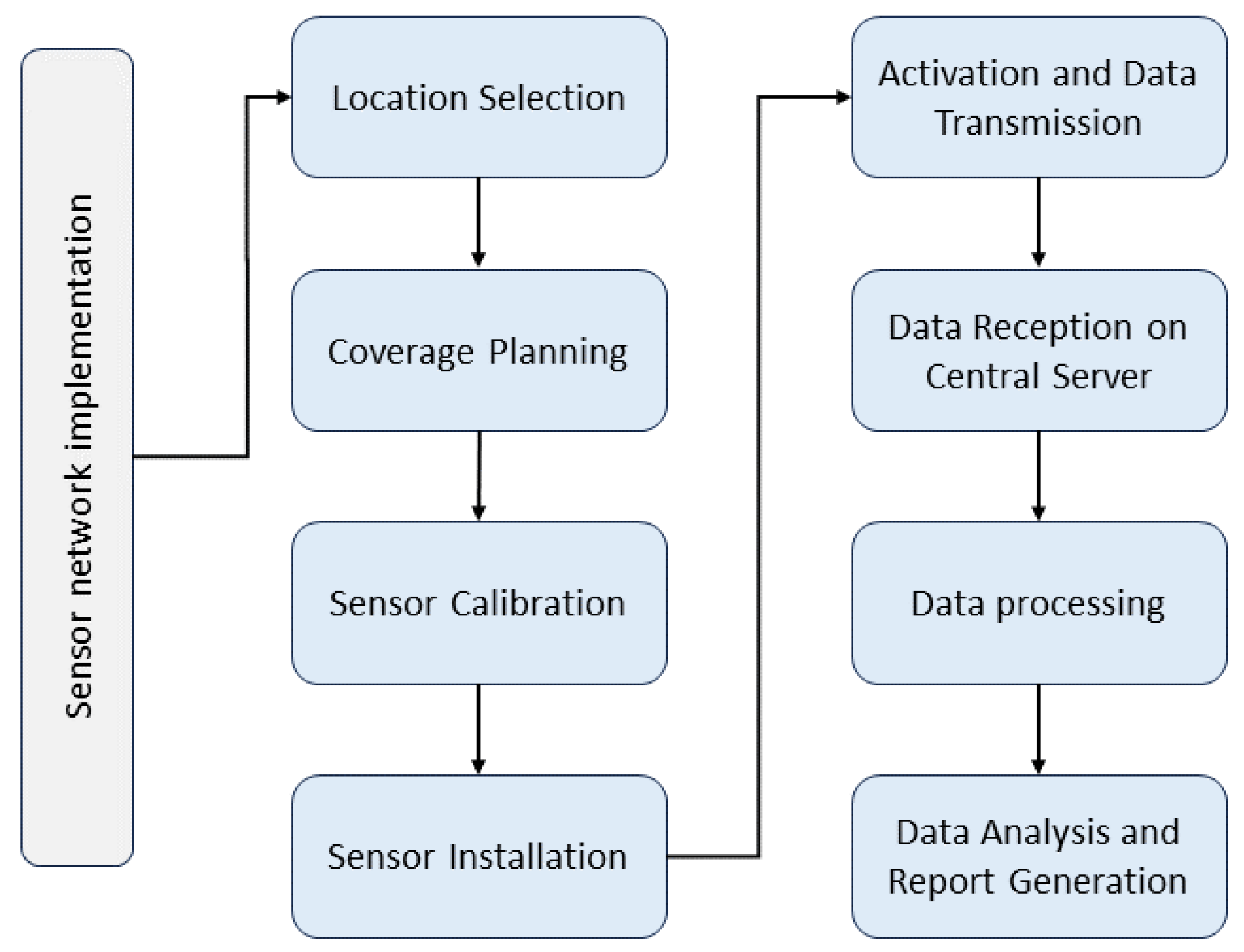
In selecting IoT technologies for our study, in addition to efficiency, accuracy, and reliability, the specific suitability of each sensor for complex urban environments was considered. Sensor calibration was performed using recognized standards in controlled environments to ensure accuracy in detecting contaminants and noise levels. This included exposing the sensors to known pollutant concentrations and decibels in a range that reflects actual urban conditions.
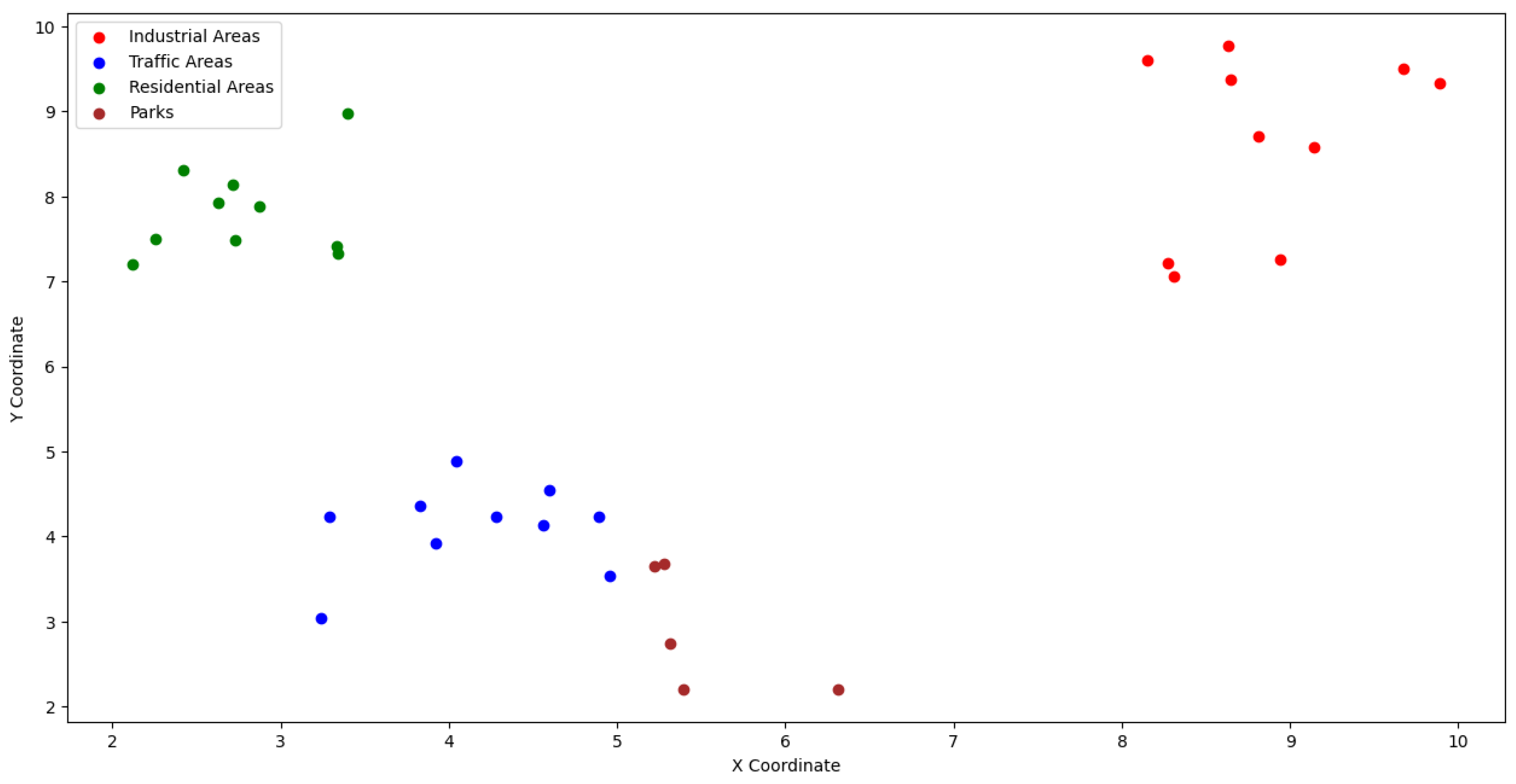
The sensor placement and deployment strategy were determined to capture a complete pollution and noise profile. The sensors were placed at strategic points, such as high-traffic intersections, residential and commercial areas, and near industrial emission sources, providing a comprehensive and detailed perspective of urban environmental conditions.
For validation, data collected by the sensors were compared to reference measurements obtained using conventional methods. This cross-validation was carried out in multiple locations and different environmental conditions, thus guaranteeing the reliability of the sensors in various urban situations.
Additionally, a regular maintenance and recalibration protocol was implemented for the sensors, considering factors such as sensor degradation over time and significant environmental changes, ensuring data consistency and accuracy over time.
Integrating these data into the urban environmental monitoring platform, combined with cloud infrastructure, big data, and machine learning algorithms, ensures high-quality data collection, and facilitates its analysis, model generation, and accurate predictions.
2.3. Data Collection and Processing
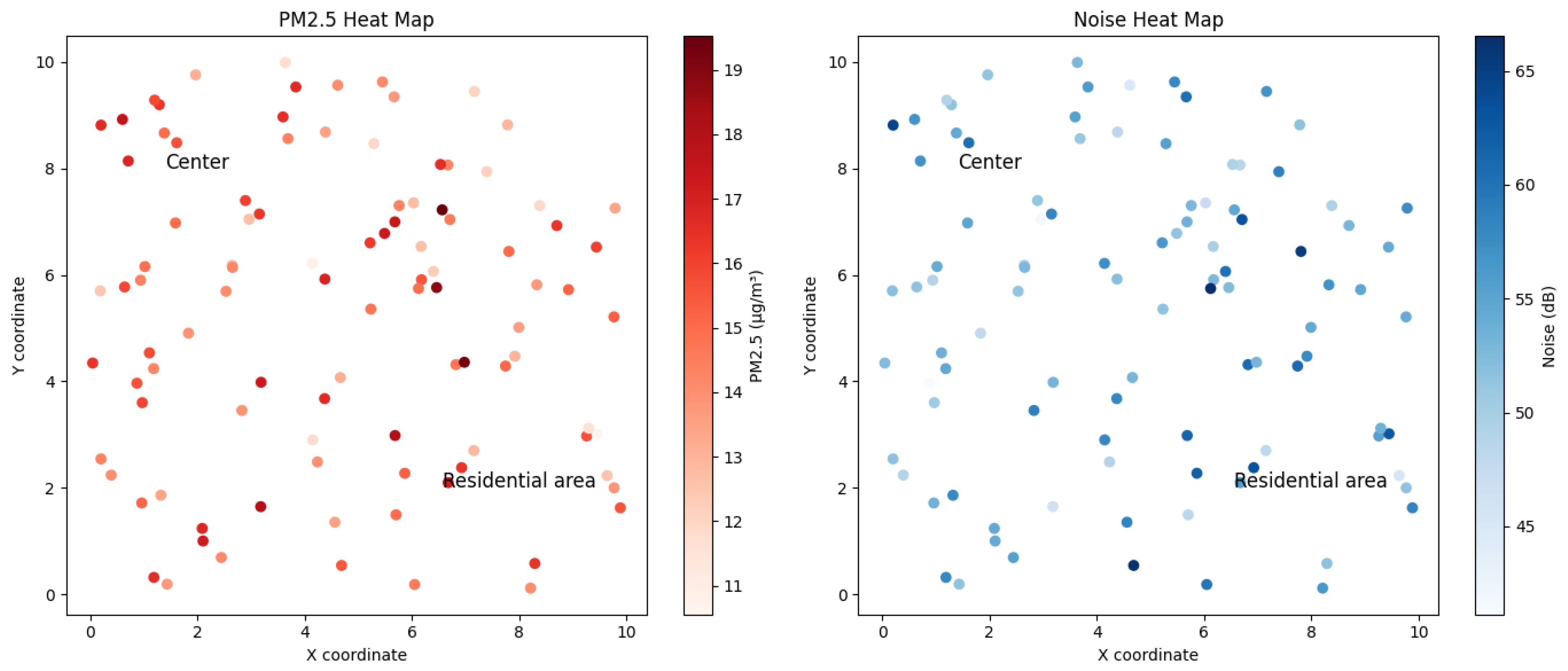
The study was conducted in a simulated city representative of a typical urban environment, with clearly defined residential, commercial, and industrial areas. To obtain a diverse and representative sample of environmental conditions, 150 IoT sensors were deployed in multiple strategic locations. Data from the sensors distributed in these areas were collected and analyzed over 6 months, providing data on air quality and noise levels. This approach allowed us to capture a detailed image of environmental patterns in a complex urban context.
Data collection and processing is based on integrating multiple open data sources and IoT instrumentation deployed throughout the urban environment. Data from the European Commission’s Urban Data Platform, the French national address database, and the Open Data Barometer enrich our analysis with contextual and comparative information.
Specifically, selected IoT sensors collect environmental data such as particle concentrations and noise levels. These data are quantitative, with volumes anticipated to be considerable, given the granularity and frequency of measurements required for detailed analysis. For example, particle sensors could generate up to 10 GB of data weekly, updating every hour, while microphones could generate around 2 GB of data with updates every half hour.
In data acquisition, a differentiated sampling frequency for each type of sensor is established and optimized to capture relevant short- and long-term environmental variations. This varied frequency allows for detailed, real-time air quality and noise analysis in different urban areas. The geographic coverage of the sensors covers a diversity of urban areas, from residential to industrial and commercial areas, thus ensuring the collection of data representative of the city. Additionally, real-time filtering and verification protocols are implemented to ensure the quality and accuracy of the data collected. This included data normalization to ensure consistency between different sensors and cross-validation with standard measurement methods, strengthening the reliability of the data set.
Processing these data begins with a cleaning phase to correct or remove outlier reads, followed by normalization to allow meaningful comparisons between data sets and locations. The processed data will be stored in a centralized repository, where big data techniques and machine learning algorithms will process the information to identify trends, patterns, and correlations.
Table 1 shows a summary of the data used.
Open data complement the data collected by sensors, providing a broader context for interpreting the data and helping to validate the prediction and analysis models developed. The processing methodology will be designed to be scalable and adaptable to adjust to emerging needs and the evolution of data collection technologies.
This work effectively integrated traffic data and other relevant urban elements with environmental data collected by sensors. Tools such as geographic information systems and extensive data analysis platforms such as Hadoop and Spark are used in data integration. These tools allow for a compelling fusion of traffic data and other urban indicators with environmental data. We use parallel processing algorithms to efficiently handle the volume and complexity of data efficiently, ensuring accurate and detailed integration. This multifaceted approach allows for developing more effective and sustainable urban planning strategies.
The representativeness of the collected data is carefully evaluated to ensure that they accurately reflect actual urban conditions. Variations in urban distribution, population density, and industrial activity are considered to ensure the generalizability of the results. However, it is essential to recognize the limitations inherent in using IoT sensors and simulation models. These include potential biases in sensor placement and constraints on representing the full complexity of the urban environment. These factors were critically analyzed to understand their impact on the study’s conclusions and formulate recommendations for future research and practical applications.
Effective management of data collected through IoT sensors is crucial to this work. With the use of Hadoop and Spark, a scalable data storage system was implemented to manage the vast amount of information collected efficiently. These platforms enabled fast and secure processing, which is essential for real-time analysis. Big data techniques were applied to analyze these data, including machine learning algorithms and statistical analysis. This approach allowed us to extract meaningful patterns and correlations from the data, which was unattainable with traditional methods due to the complexity and magnitude of the data. However, several challenges were faced, such as data integrity and processing efficiency. To overcome these issues, we established rigorous data verification and filtering protocols and processing optimizations to improve the speed and accuracy of analysis.
The use of IoT technologies for environmental monitoring involves facing various challenges. One of the main obstacles was the accurate calibration of the sensors. For example, PM2.5 sensors required periodic calibrations to counteract the drift caused by environmental factors such as humidity and temperature. We implement regular calibration protocols and compare data to reference sensors to ensure accuracy.
Data integrity was another significant challenge. Noise sensors were subject to external interference that could affect accuracy. We use data filters and statistical analysis techniques to address this to identify and correct potential errors.
Additionally, network reliability is crucial for effective data transmission. Network redundancy systems and local data storage mechanisms were established to ensure continuity in data collection and avoid data loss due to fluctuations in network connectivity.
Table 2 summarizes the key challenges faced in calibration and data collection with different types of IoT sensors and the strategies implemented to address these issues. The table provides a comprehensive view of how the accuracy and integrity of the data were ensured, highlighting both the technical obstacles and the solutions applied to overcome them in the context of urban environmental monitoring.
2.4. Data Analysis and Algorithm Development
Data analysis and algorithm development are essential for turning large volumes of raw data into actionable insights. The algorithms to be developed cover several areas of data analysis:
Preprocessing of the collected data is carried out in several stages. Initially, the data are subjected to cleaning that involves the elimination of outliers using statistical methods such as the Tukey test or the analysis of standard deviations. Missing values are treated using imputation techniques, such as mean imputation or k-nearest neighbors’ imputation, depending on the nature of the data [
41]. Normalization is applied to the data to homogenize the scale from different sources, using min–max normalization or Z-score standardization methods.
For descriptive statistical analysis, measures of central tendency and dispersion are used, and for exploratory data analysis (EDA), visual techniques such as histograms, boxplots, and scatterplots are applied. Regression algorithms, classifiers such as support vector machines, and neural networks are used to predict pollution levels in predictive modeling [
42,
43]. Clustering algorithms identify patterns in unlabeled data, such as k-means or Density-Based Spatial Clustering of Applications with Noise (DBSCAN).
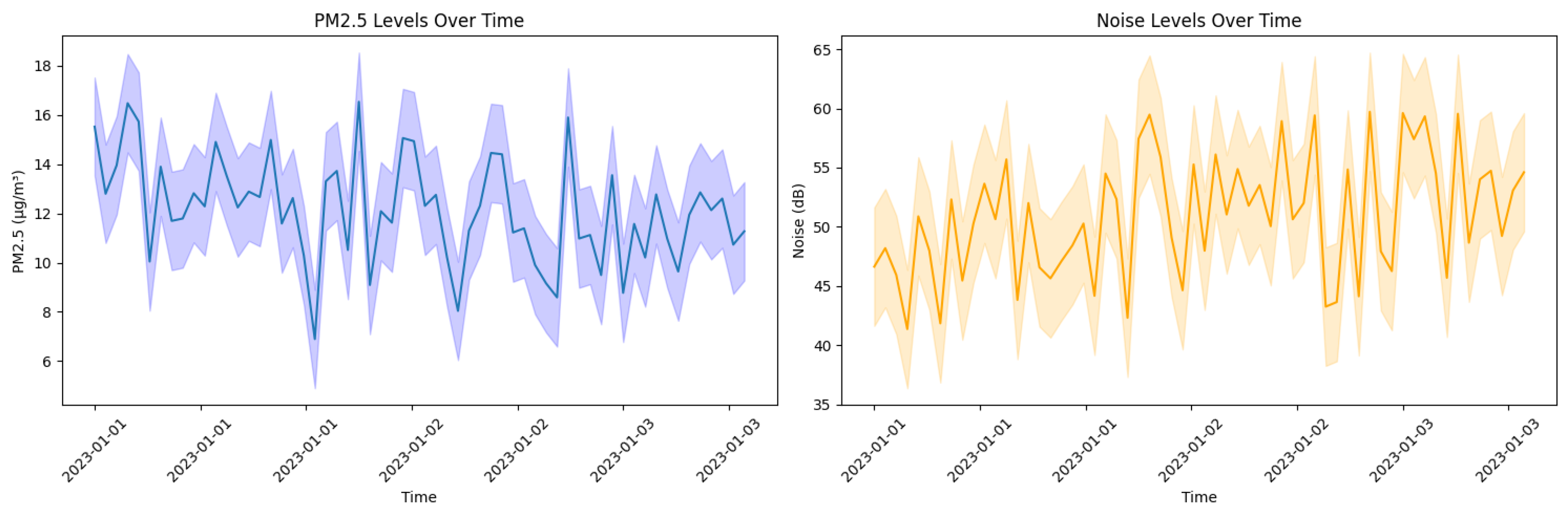
The interpretation of the data is carried out through analyzing the outputs of these models. At the same time, the visualization is facilitated through interactive dashboards that allow users to explore the data using filters and controls. Time series are visualized through line or area graphs. Each algorithm and visualization technique is selected and customized to the specific needs of the analysis, ensuring that results are both technically sound and accessible to end users, including decision-makers and the public.
Regarding the architecture of the CNNs, a model with multiple layers was used, including convolutional layers for feature extraction, pooling layers for dimensionality reduction, and finally, fully connected layers for classification. ReLU activation functions were used for the convolutional layers and Softmax for the output layer. A maximum tree depth was defined for decision trees, and entropy criteria were utilized for node splitting.
The CNN architecture consisted of three convolutional layers, each followed by a pooling layer to reduce dimensionality. The convolutional layers had 32, 64, and 128 filters, respectively, with a kernel size 3 × 3. Max pooling was used for the reduction layers. The network ended up with two fully connected layers of 64 and 32 nodes.
A maximum depth of 10 levels was set for the decision trees, and the Gini impurity criterion was used for splits. Parameter tuning was performed with a grid search, evaluating combinations of tree depth and number of leaf nodes. Five-fold cross-validation was used to avoid overfitting and ensure the model’s generalization.
Parameter tuning was performed using cross-validation and grid search techniques to find the optimal combination of hyperparameters. This approach ensured the generalization and effectiveness of the models. Validation and testing were carried out on separate data sets, using metrics such as accuracy, sensitivity, and specificity to evaluate model performance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}