


Self-Interested Coalitional Crowdsensing for Multi-Agent Interactive Environment Monitoring

Abstract
:1. Introduction
- We propose an efficient framework, called SCC-MIE, which consists of multi-agent imitation learning and a secretary-based online worker selection strategy. Based on data spatiotemporal heterogeneity and confounding effects, the former estimates the importance of the data and reconstructs the sensing environment. The latter aims to select workers to proactively sense critical data in an online manner to motivate environmental reconstruction.
- Considering confounding effects in real sensing environments, we design an imitation learning framework that includes confounder-embedded policy and a discriminator to learn the policy based on their interactions effectively.
- Extensive Evaluation: we conducted an extensive evaluation of the dataset using four different methods, which verified the validity of SCC-MIE.
2. Related Work
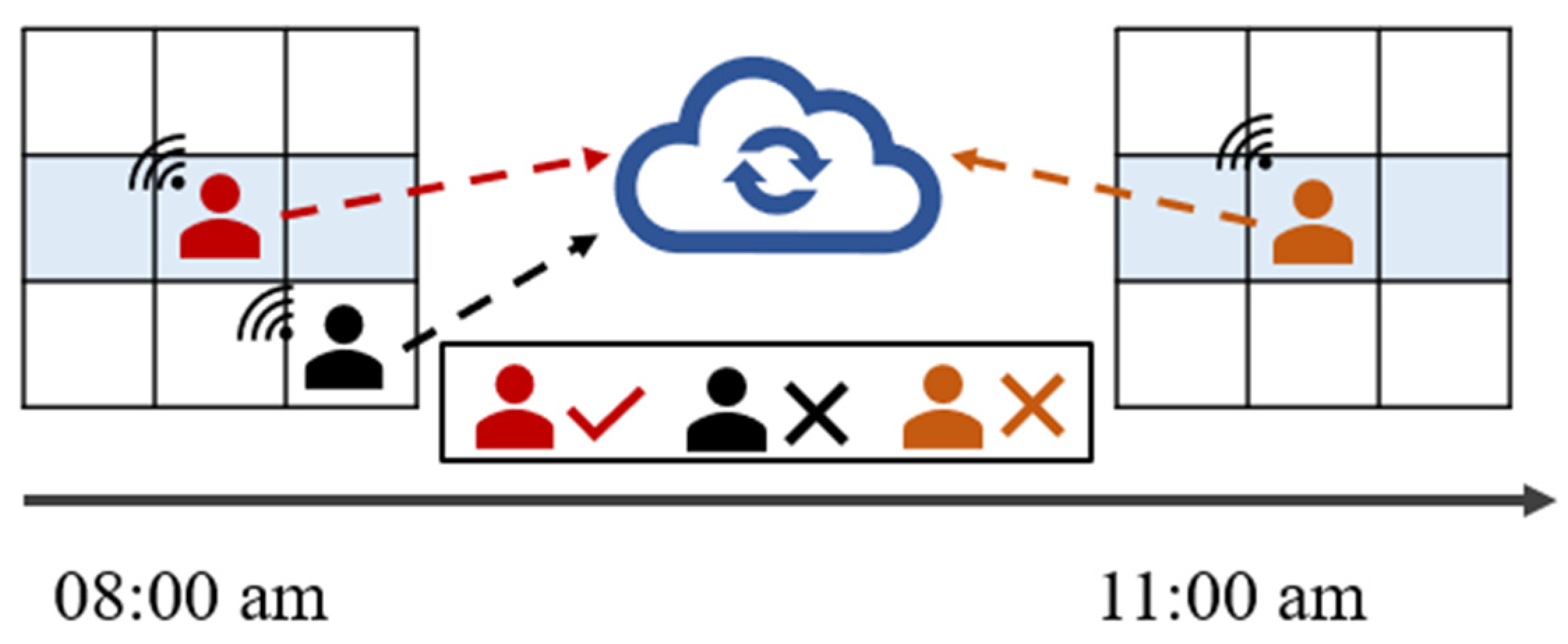
3. Problem Definition and Framework Overview
3.1. Problem Definition
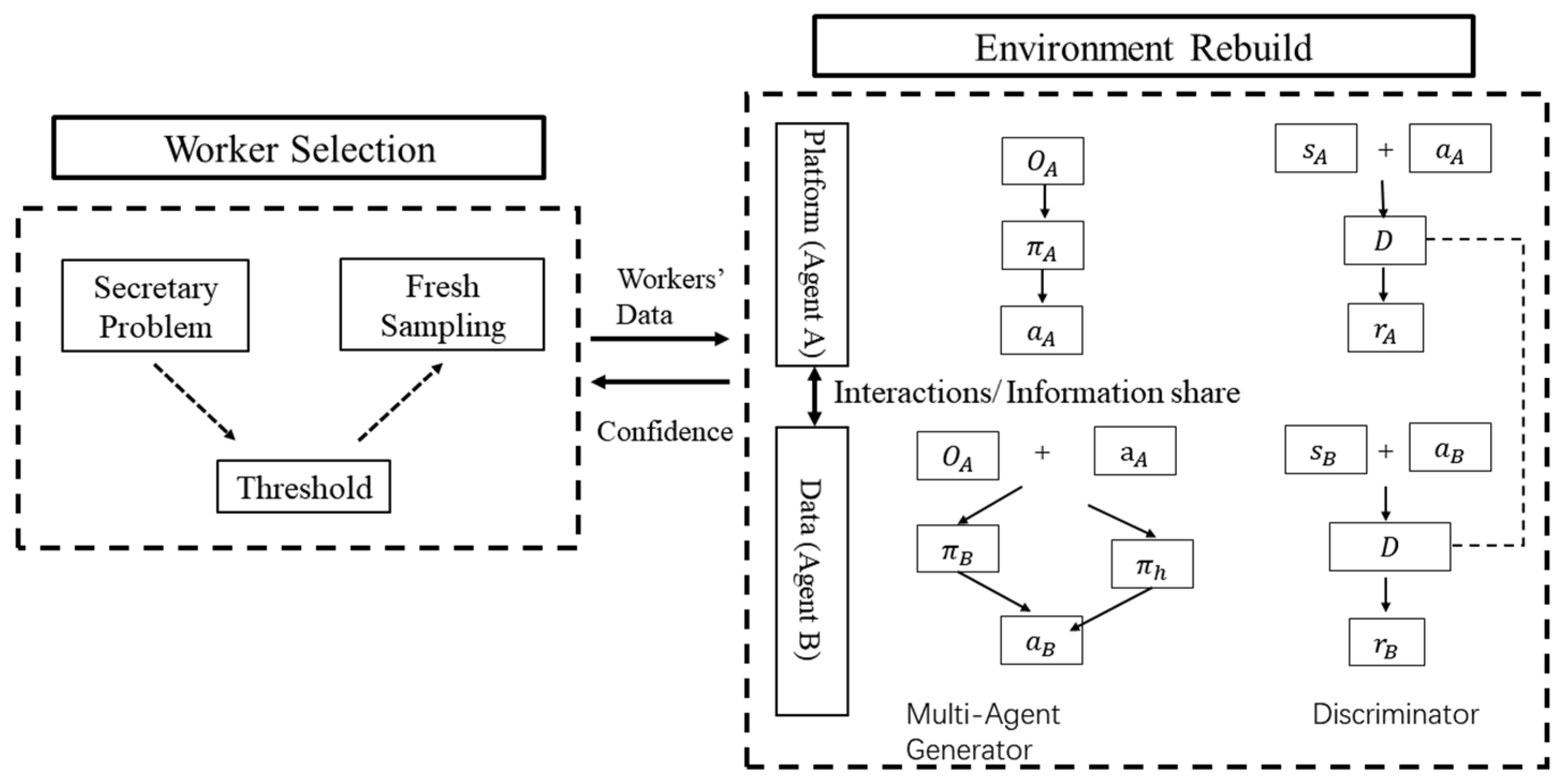
3.2. Framework Overview
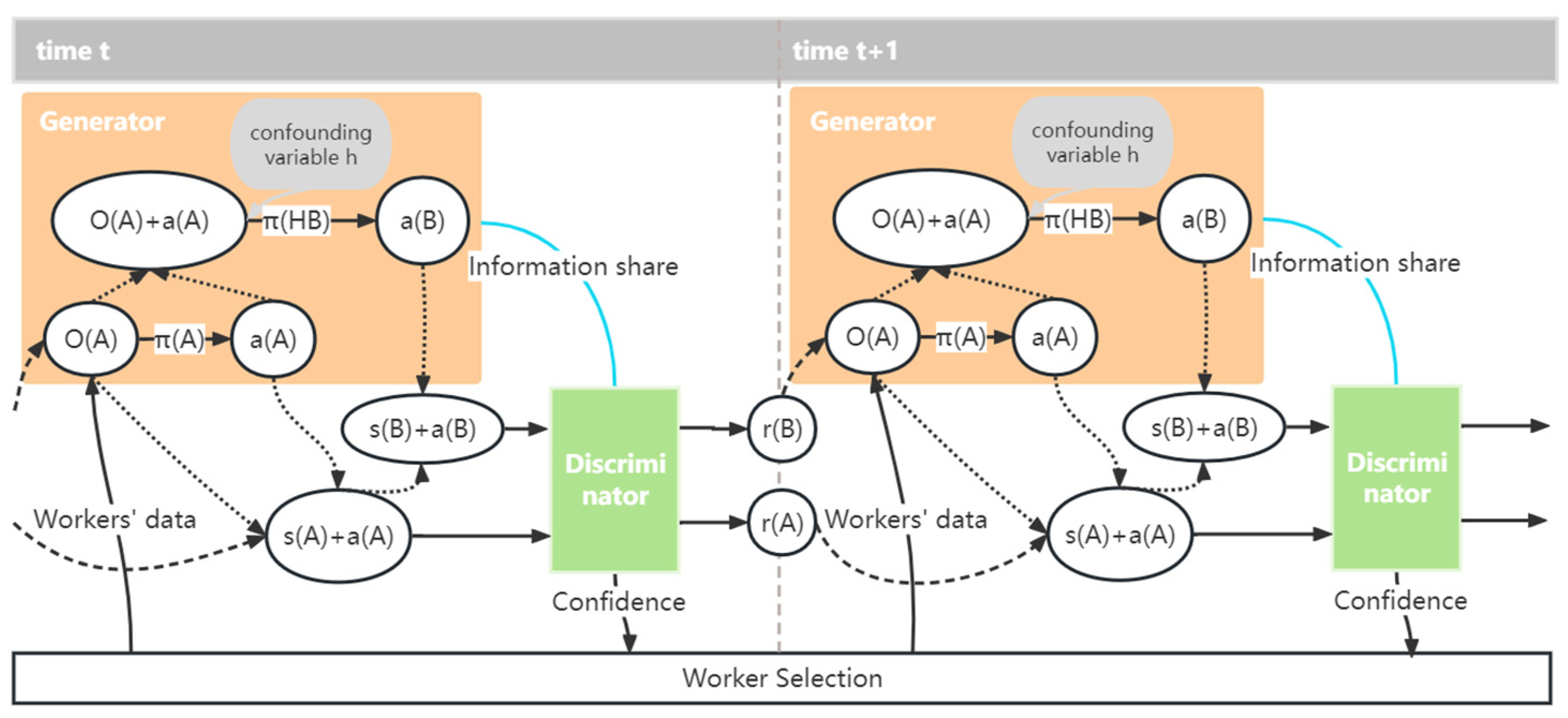
4. Online Multi-Agent Environment Reconstruction
5. Detailed Model Construction
5.1. Confounder Embedded Policy
| Algorithm 1: SCC-MIE algorithm |
| 1: Input: Trajectory data . |
| 2: Output: , , . |
| 3: Initialization policies and with parameters and , and discriminator with parameter ; |
| 4: for do |
| 5: for do |
| 6: ; |
| 7: for do |
| 8: ; |
| 9: Select a random trajectory from |
| 10: Set the first state to the initial observation ; |
| 11: for do |
| 12: Simulate the actions , by the policy and the policy , respectively |
| 13: Calculate the rewards and by Equation (15); |
| 14: Derive the next observation |
| 15: Insert into the trajectory |
| 16: end for |
| 17: Integration of the computed data |
| 18: end for |
| 19: Update parameters and according to PPO; |
| 20: end for |
| 21: Update the discriminator by minimizing the losses; |
| 22: end for |
5.2. Worker Selection
| Algorithm 2: Worker selection algorithm |
| 1: Input: selected workers , new workers , time: T; budget: B |
| 2: Conduct from history data according to and . |
| 3: while do |
| 4: if then |
| return ; |
| 5: else |
| 6: ; |
| 7: Select at random from , =; |
| 8: |
| 9: end if |
| 10: end while |
6. Performance Evaluation
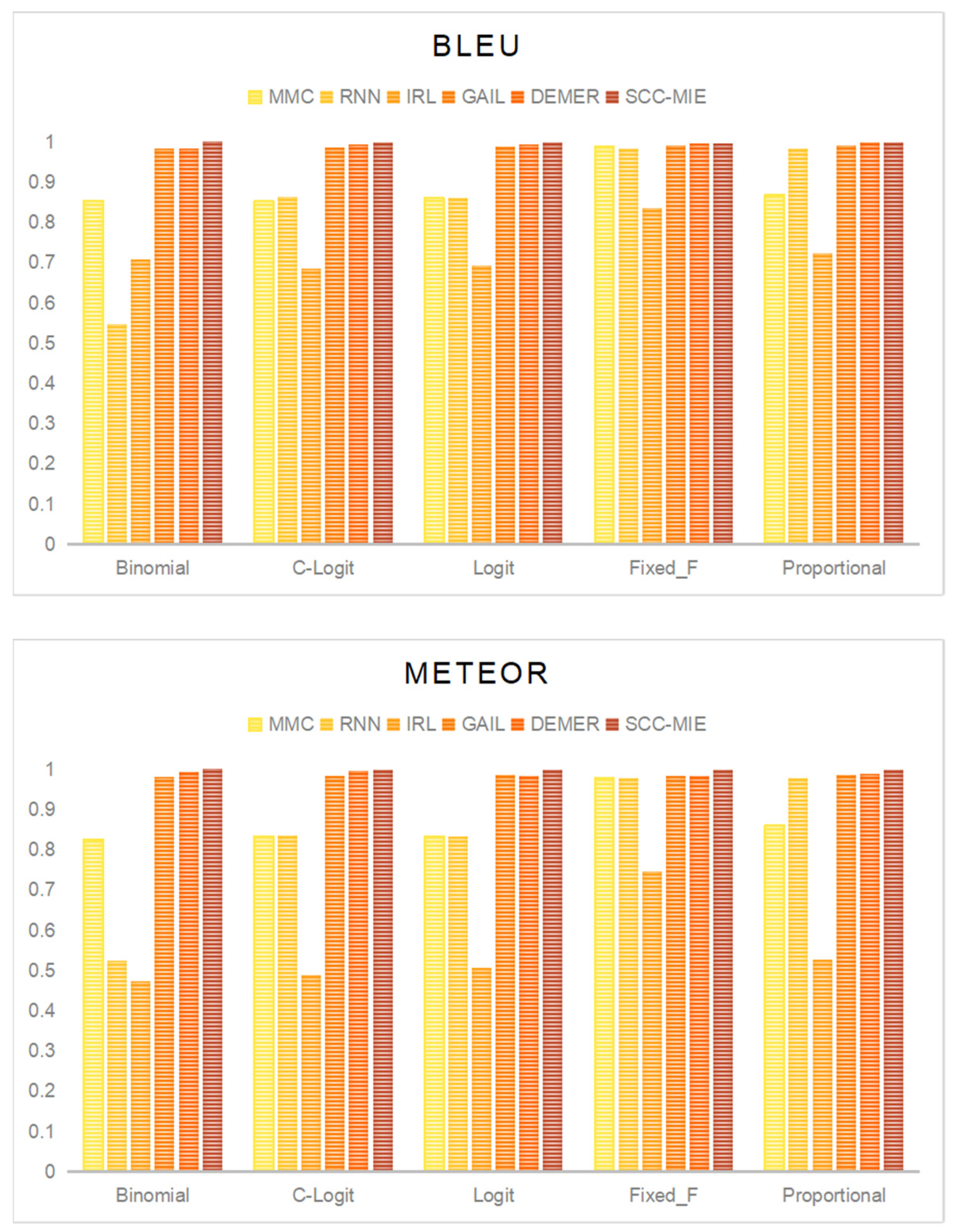
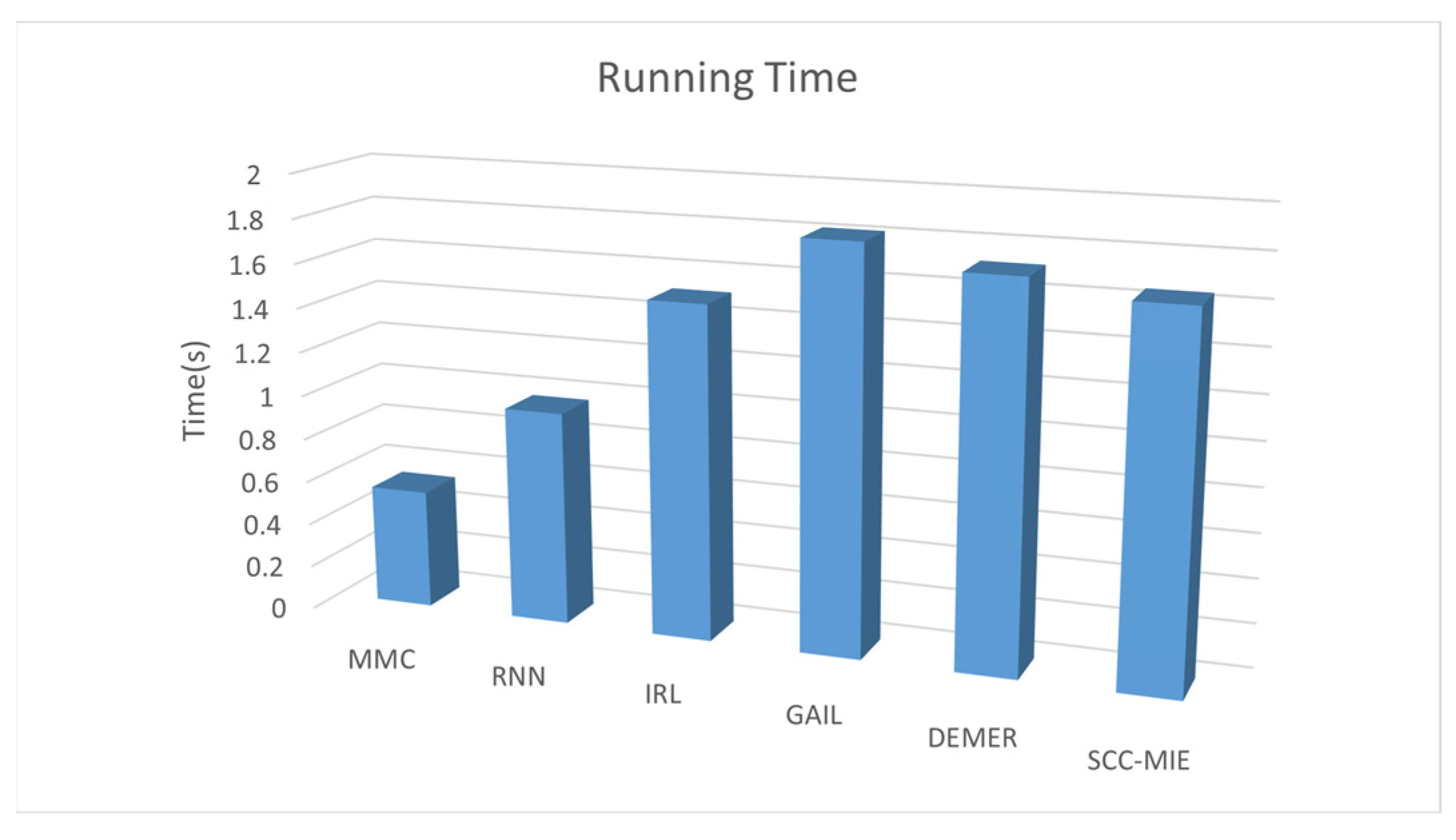
6.1. Baseline
- Mobility Markov Chain [26]: Mobile Markov chain (MMC) is a fundamental model commonly used to address location prediction problems. MMC models represent a stochastic process where transitions occur between different states in the state space. One key characteristic of MMC models is their “memoryless” nature, meaning that the probability distribution of transitioning to the next state is solely determined by the current state.
- Recurrent Neural Network [27]: Recurrent neural network (RNN) is a popular and robust algorithm for location recommendation tasks. RNN models excel at capturing the spatiotemporal characteristics in data, allowing them to make accurate predictions for the next location. In this study, we employ long short-term memory (LSTM) for modeling continuous data.
- Inverse Reinforcement Learning [28]: Inverse reinforcement learning (IRL) aims to infer unknown reward functions based on observed demonstrations or expert behaviors in order to train RL agents or guide their decision-making process in new, unknown environments. In this study, we employ maximum entropy IRL (MaxEnt) to extend the idea of matching state visits to matching state-action visits.
- Generative Adversarial Imitation Learning [6]: GAIL is an imitation learning algorithm based on generative adversarial networks (GAN), which allows a learner to learn strategies to imitate experts by confronting them.
- Deconfounded Multi-agent Environment Reconstruction [17]: DEMER uses a multi-agent generative adversarial imitation learning framework. It is proposed to introduce a confounder embedding strategy and train the strategy using a compatible discriminator.
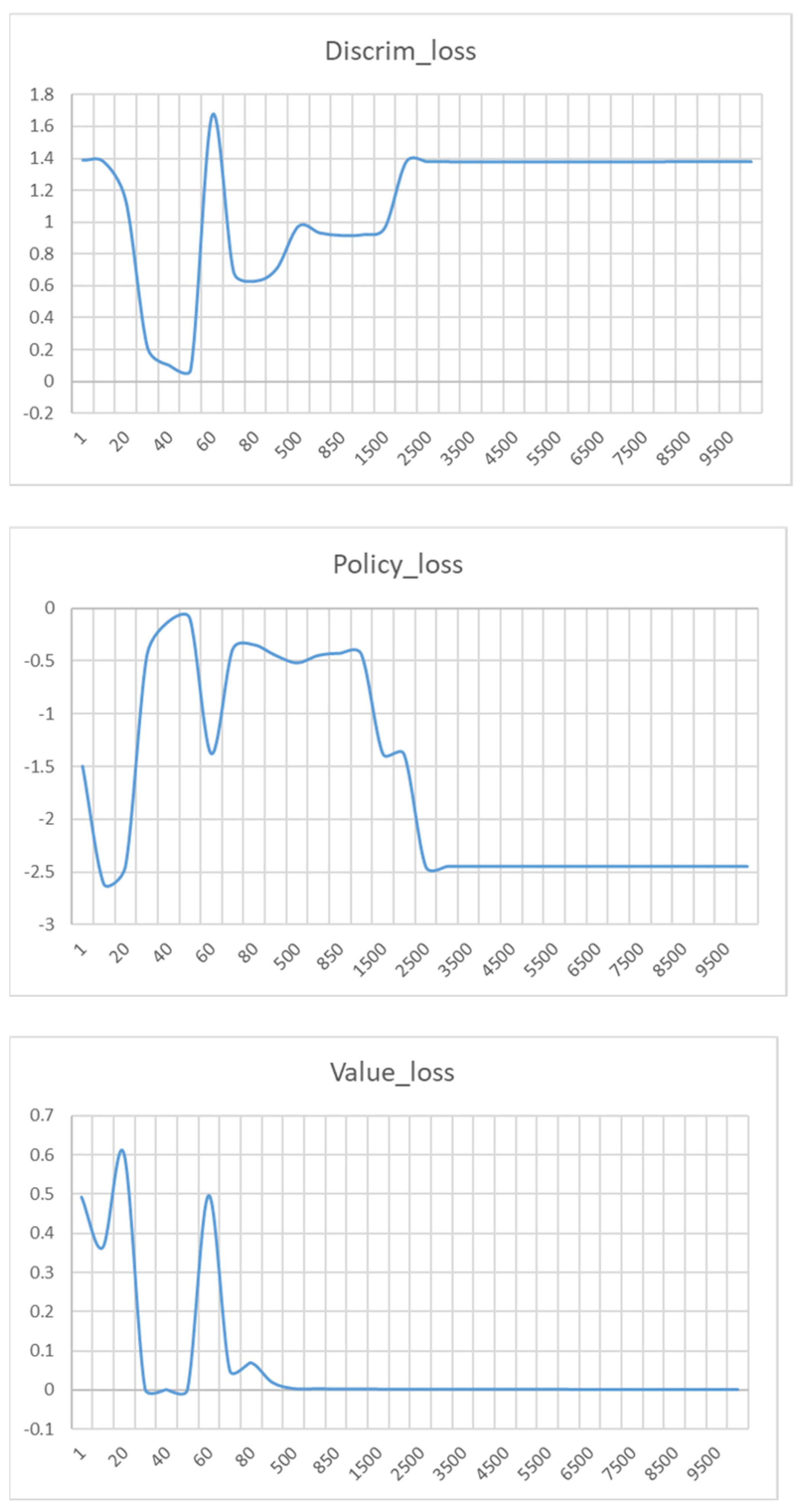
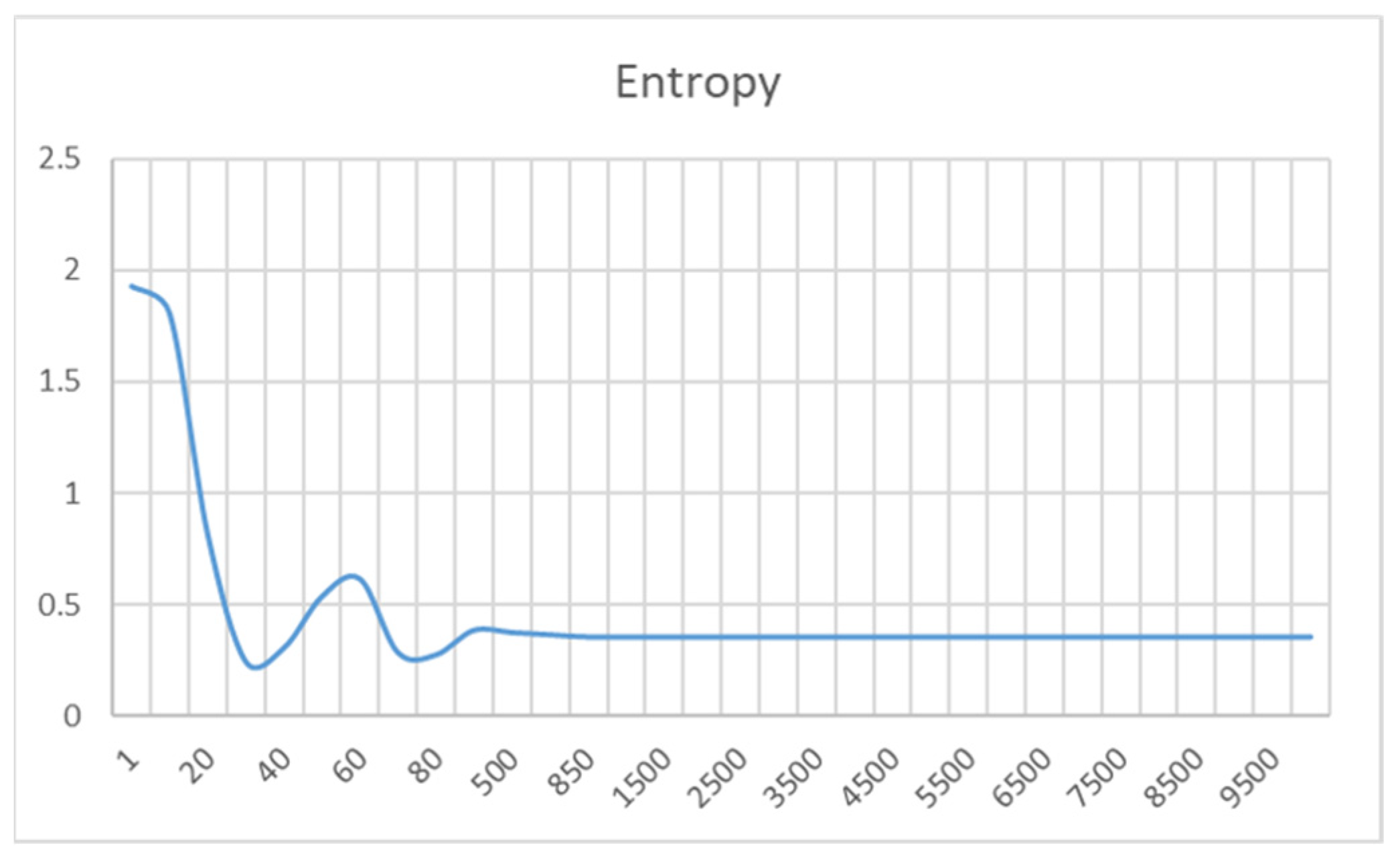
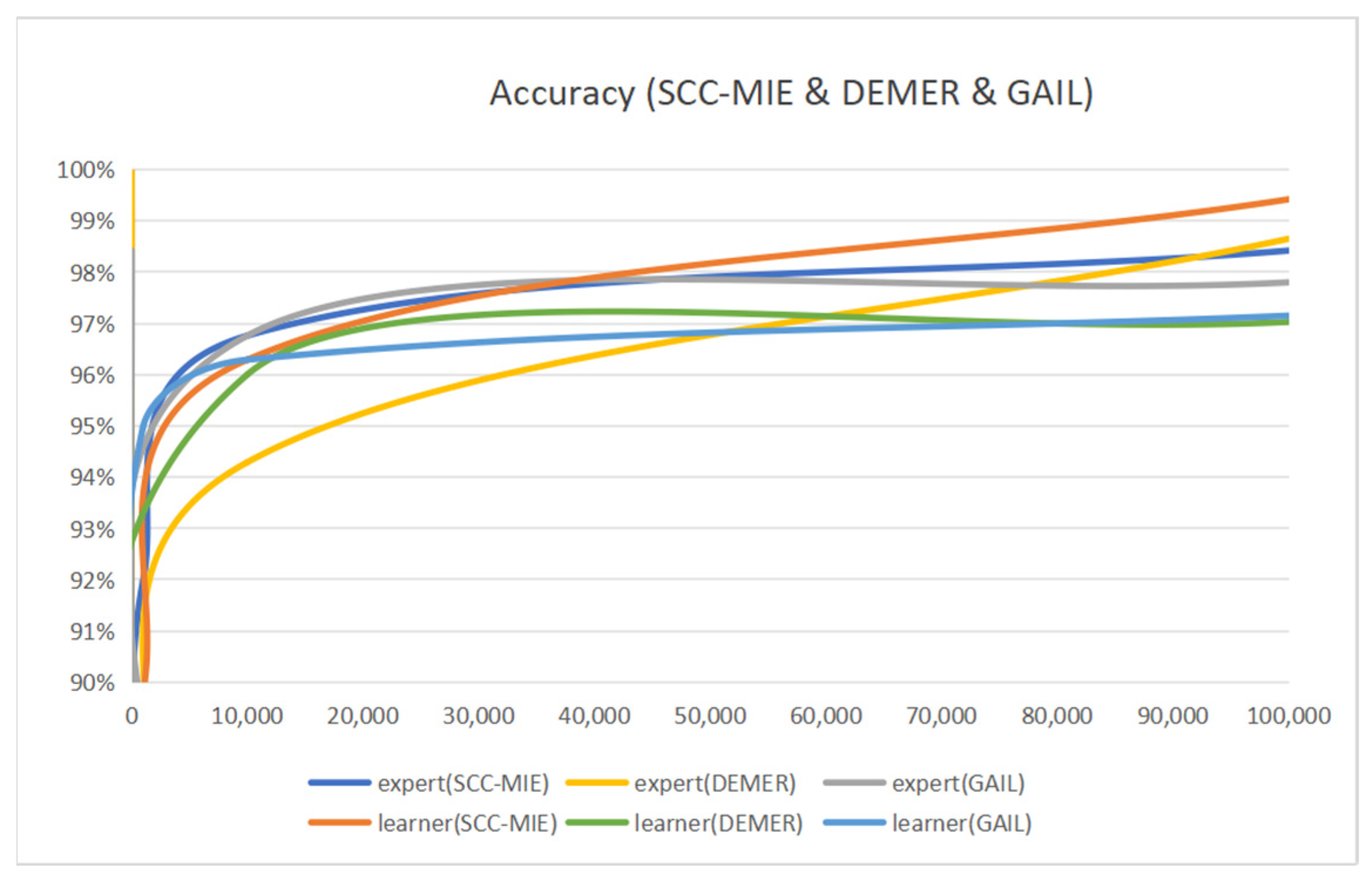
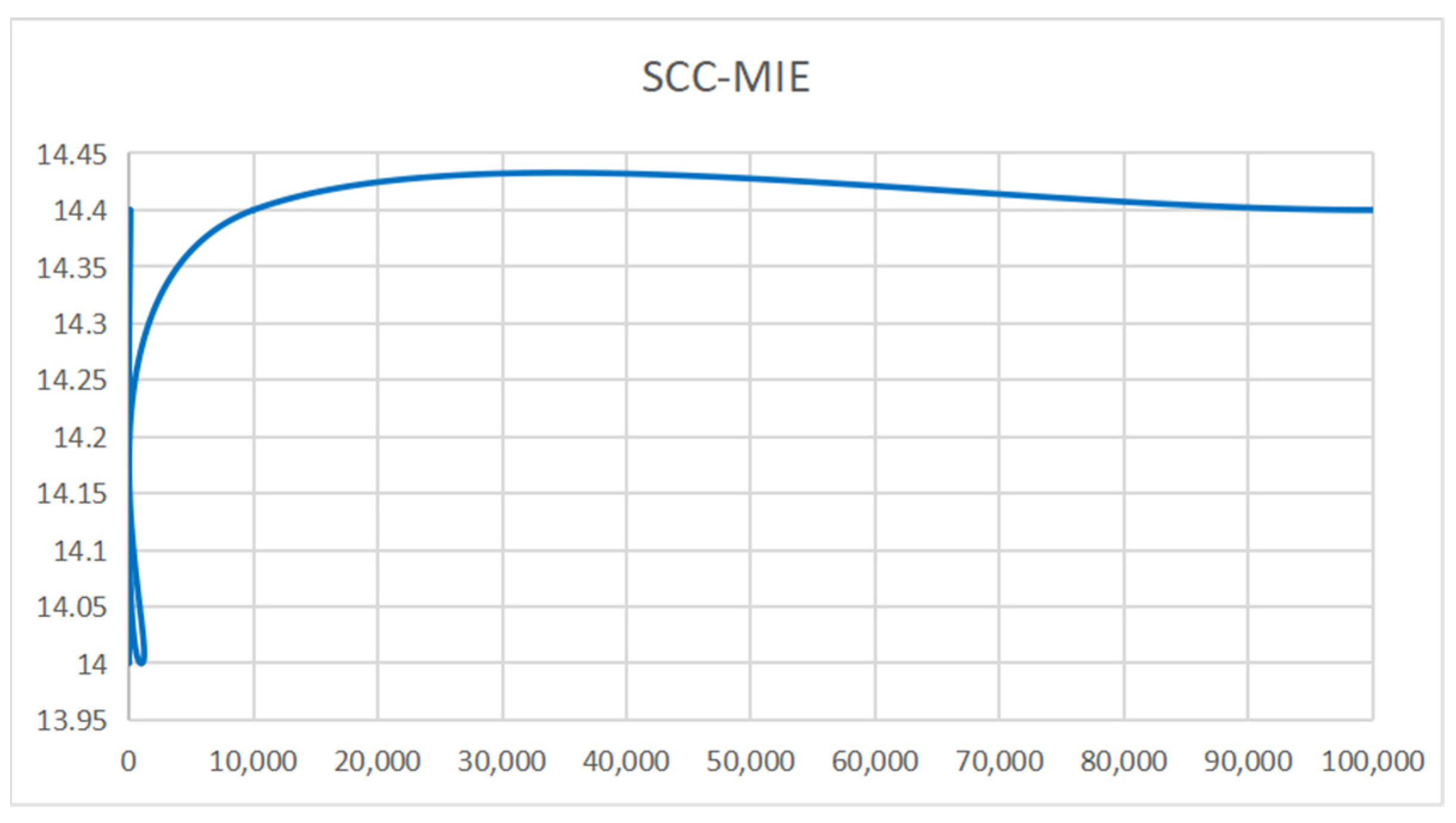
6.2. Result
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ganti, R.K.; Ye, F.; Lei, H. Mobile crowdsensing: Current state and future challenges. IEEE Commun. Mag. Artic. News Events Interest Commun. Eng. 2011, 49, 32–39. [Google Scholar] [CrossRef]
- Capponi, A.; Fiandrino, C.; Kantarci, B.; Foschini, L.; Bouvry, P. A Survey on Mobile Crowdsensing Systems: Challenges, Solutions and Opportunities. IEEE Commun. Surv. Tutor. 2019, 21, 2419–2465. [Google Scholar] [CrossRef]
- Ye, Z.; Xiao, K.; Ge, Y.; Deng, Y. Applying Simulated Annealing and Parallel Computing to the Mobile Sequential Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 31, 243–256. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, L.; Xu, C.; Ni, J.; Huang, C.; Shen, X. Location privacy-preserving task recommendation with geometric range query in mobile crowdsensing. IEEE Trans. Mob. Comput. 2021, 21, 4410–4425. [Google Scholar] [CrossRef]
- Canese, L.; Cardarilli, G.C.; Di Nunzio, L.; Fazzolari, R.; Giardino, D.; Re, M.; Spanò, S. Multi-agent reinforcement learning: A review of challenges and applications. Appl. Sci. 2021, 11, 4948. [Google Scholar] [CrossRef]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. Adv. Neural Inf. Process. Syst. 2016, 29, 4565–4573. [Google Scholar]
- Foerster, J. Deep Multi-Agent Reinforcement Learning. Ph.D. Thesis, University of Oxford, Oxford, UK, 2018. [Google Scholar]
- Li, T.; Zhu, K.; Luong, N.C.; Niyato, D.; Wu, Q.; Zhang, Y.; Chen, B. Applications of multi-agent reinforcement learning in future internet: A comprehensive survey. IEEE Commun. Surv. Tutor. 2022, 24, 1240–1279. [Google Scholar] [CrossRef]
- Schmidt, L.M.; Brosig, J.; Plinge, A.; Eskofier, B.M. An introduction to multi-agent reinforcement learning and review of its application to autonomous mobility. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 1342–1349. [Google Scholar]
- Xie, K.; Tian, J.; Xie, G.; Zhang, G.; Zhang, D. Deep learning-enabled sparse industrial crowdsensing and prediction. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Wang, E.; Zhang, M.; Cheng, X.; Yang, Y.; Liu, W.; Yu, H.; Wang, L.; Zhang, J. Low cost sparse network monitoring based on block matrix completion. In Proceedings of the IEEE Transactions on Industrial Informatics, Vancouver, BC, Canada, 10–13 May 2021; pp. 6170–6181. [Google Scholar]
- Shi, J.C.; Yu, Y.; Da, Q.; Chen, S.Y.; Zeng, A.X. Virtual-taobao: Virtualizing real-world online retail environment for reinforcement learning. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4902–4909. [Google Scholar] [CrossRef]
- Liu, C.; Wang, L.; Wen, X.; Liu, L.; Zheng, W.; Lu, Z. Efficient Data Collection Scheme based on Information Entropy for Vehicular Crowdsensing. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, Republic of Korea, 16–20 May 2022; pp. 1–6. [Google Scholar]
- Qin, H.; Zhan, X.; Li, Y.; Yang, X.; Zheng, Y. Network-wide traffic states imputation using self-interested coalitional learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery Data Mining, Virtual Event, 14–18 August 2021; pp. 1370–1378. [Google Scholar]
- Liu, W.; Wang, E.; Yang, Y.; Wu, J. Worker selection towards data completion for online sparse crowdsensing. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, Virtual Event, 2–5 May 2022; pp. 1509–1518. [Google Scholar]
- Wu, A.; Luo, W.; Yang, A.; Zhang, Y.; Zhu, J. Efficient Bilateral Privacy-Preserving Data Collection for Mobile Crowdsensing. IEEE Trans. Serv. Comput. 2023. [Google Scholar] [CrossRef]
- Shang, W.; Yu, Y.; Li, Q.; Qin, Z.; Meng, Y.; Ye, J. Environment reconstruction with hidden confounders for reinforcement learning based recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 566–576. [Google Scholar]
- Ma, J.; Guo, R.; Chen, C.; Zhang, A.; Li, J. Deconfounding with networked observational data in a dynamic environment. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual Event, 8–12 March 2021; pp. 166–174. [Google Scholar]
- Zhao, Y.; Liu, C.H. Social-aware incentive mechanism for vehicular crowdsensing by deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2314–2325. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, C.H.; Ye, Y.; Han, R.; Yuan, Y.; Wang, G.; Tang, J. Aoi-minimal uav crowdsensing by model-based graph convolutional reinforcement learning. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, Virtual Event, 2–5 May 2022; pp. 1029–1038. [Google Scholar]
- Schaal, S. Is imitation learning the route to humanoid robots? Trends Cogn. Sci. 1999, 3, 233–242. [Google Scholar] [CrossRef] [PubMed]
- Le Mero, L.; Yi, D.; Dianati, M.; Mouzakitis, A. A survey on imitation learning techniques for end-to-end autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14128–14147. [Google Scholar] [CrossRef]
- Song, J.; Ren, H.; Sadigh, D.; Ermon, S. Multi-agent generative adversarial imitation learning. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Nemhauser, G.L.; Wolsey, L.A.; Fisher, M.L. An analysis of approximations for maximizing submodular set functionsi. Math. Program. 1978, 14, 265–294. [Google Scholar] [CrossRef]
- Choi, S.; Kim, J.; Yeo, H. TrajGAIL: Generating urban vehicle trajectories using generative adversarial imitation learning. Trans-Portation Res. Part C Emerg. Technol. 2021, 128, 103091. [Google Scholar] [CrossRef]
- Gambs, S.; Killijian, M.O.; del Prado Cortez, M.N. Next place prediction using mobility markov chains. In Proceedings of the First Workshop on Measurement, Privacy, and Mobility, Bern, Switzerland, 10 April 2012; pp. 1–6. [Google Scholar]
- Altaf, B.; Yu, L.; Zhang, X. Spatio-temporal attention based recurrent neural network for next location prediction. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 937–942. [Google Scholar]
- Pieter, A.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning (ICML ‘04), Banff, AB, Canada, 4–8 July 2004; Association for Computing Machinery: New York, NY, USA, 2004. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29–30 June 2005; pp. 65–72. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation |
|---|---|
| Index of a worker, total of workers | |
| Index of time slot, total of time slot | |
| Sensory data of worker at t-time slot | |
| Reconstructed data for | |
| Observable data set and unobservable data set | |
| Sensing the trajectory of workers. | |
| Cost of collecting data. | |
| Budget of collecting data. | |
| Confidence level, the judgment of the discriminator |
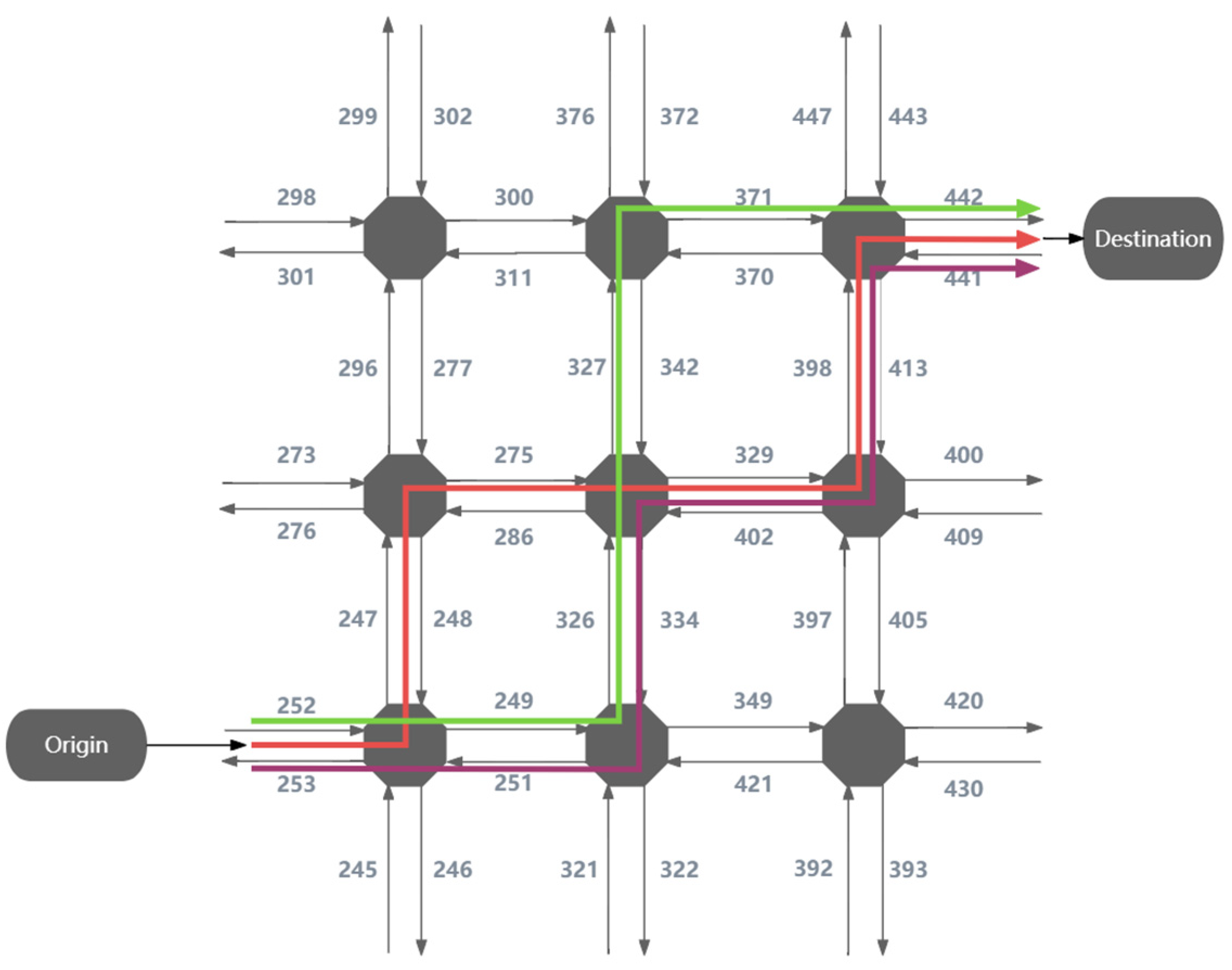
| OriginID | Number | SectionID |
|---|---|---|
| 1 | 1 | 252 |
| 1 | 2 | 247 |
| 1 | 3 | 275 |
| 1 | 4 | 329 |
| 1 | 5 | 398 |
| 1 | 6 | 442 |
| 2 | 1 | 252 |
| 2 | 2 | 249 |
| 2 | 3 | 326 |
| 2 | 4 | 329 |
| 2 | 5 | 398 |
| 2 | 6 | 442 |
| 3 | 1 | 252 |
| 3 | 2 | 249 |
| 3 | 3 | 326 |
| 3 | 4 | 327 |
| 3 | 5 | 371 |
| 3 | 6 | 442 |
| Hyperparameter | Value |
|---|---|
| Number of iterations | 10,000 |
| Number of episodes | 10,000 |
| 2048 | |
| Number of hidden neurons | 64 |
| Learning rate | 0.00003 |
| Discount rate of reward | 0.99 |
| Entropy coefficient | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Lei, X.; Li, X.; Chen, S. Self-Interested Coalitional Crowdsensing for Multi-Agent Interactive Environment Monitoring. Sensors 2024, 24, 509. https://doi.org/10.3390/s24020509
Liu X, Lei X, Li X, Chen S. Self-Interested Coalitional Crowdsensing for Multi-Agent Interactive Environment Monitoring. Sensors. 2024; 24(2):509. https://doi.org/10.3390/s24020509
Chicago/Turabian StyleLiu, Xiuwen, Xinghua Lei, Xin Li, and Sirui Chen. 2024. "Self-Interested Coalitional Crowdsensing for Multi-Agent Interactive Environment Monitoring" Sensors 24, no. 2: 509. https://doi.org/10.3390/s24020509
APA StyleLiu, X., Lei, X., Li, X., & Chen, S. (2024). Self-Interested Coalitional Crowdsensing for Multi-Agent Interactive Environment Monitoring. Sensors, 24(2), 509. https://doi.org/10.3390/s24020509