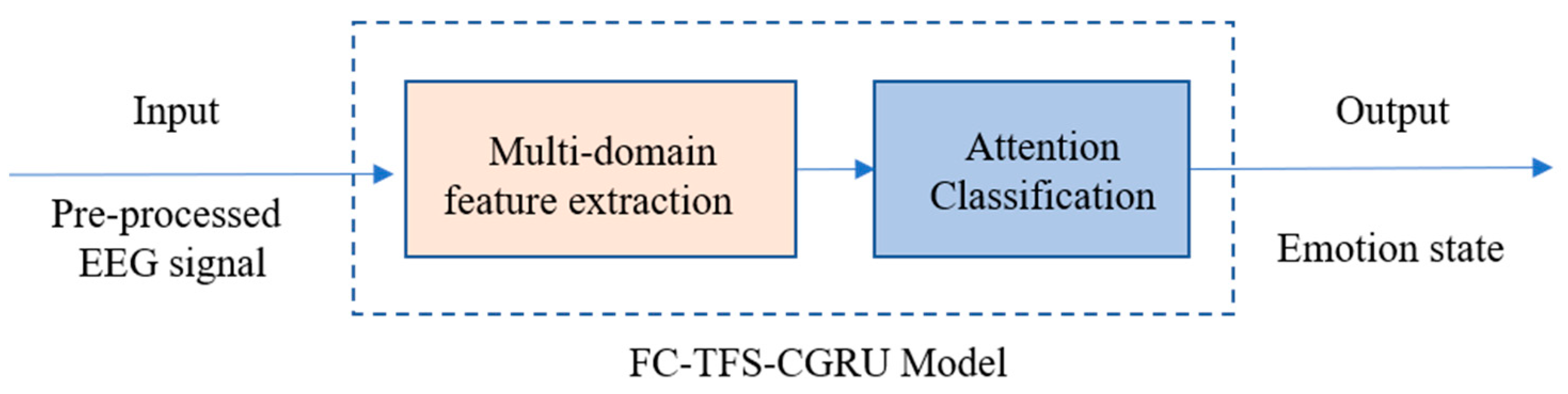
A multi-channel EEG signal is a multi-dimensional time series signal that is rich in temporal, frequency, and spatial features. These features from multiple domains, along with the hidden high-level features among them, all contribute to emotion recognition. Moreover, the extensive interaction information between the channels of multichannel EEG signals is also crucial in revealing the brain’s emotional response, which can be considered to represent emotion recognition. Therefore, to utilize the information to improve the accuracy of emotional recognition, we designed a temporal–frequency–spatial EEG emotion recognition model based on FC and a CGRU hybrid architecture (FC-TFS-CGRU) to recognize emotional states. The FC-TFS-CGRU model is depicted in
Figure 1. It significantly enhances the accuracy of emotion recognition by considering the spatial interaction information based on FC and the high-level hidden features across multiple domains.
FC-TFS-CGRU contains two important modules, i.e., a multi-domain feature extraction module and an attention classification module. The multi-domain feature extraction module includes two stages to extract the features in sequence. In stage 1, the phase-locking value (PLV) is used to calculate the spatial features of FC, and Fast Fourier transform is utilized to compose the signal into frequency bands. Then, all of them are combined to further abstract the FC-based frequency–spatial high-level feature (FC-FSH) using the CNN. In stage 2, GRUs are used to abstract the contextual information of the FC-FSH to gain the FC-based temporal–frequency–spatial hybrid feature (FC-TFS), which can reflect the temporal change in the spatial–frequency domain features. Subsequently, an attention mechanism is proposed in the classification process to utilize the different contributions of various features to emotion. The details of each module are illustrated in
Section 2.2.1 and
Section 2.2.2 2.2.1. Multi-Domain Emotional Feature Extraction
In this section, the multi-domain features of EEG signals will be extracted using the proposed model. The multi-domain emotional feature extraction module comprises two crucial stages: the first is the extraction of FC-FSH, and the second is the extraction of FC-TFS. We will introduce these stages in detail in the following parts.
In stage 1 of multi-domain feature extraction, the frequency domain features and spatial features of EEG signals are captured separately, and then, the hidden correlation features between the frequency and spatial domains are further extracted based on these two features. In the extraction of spatial features, unlike most existing studies that consider the physical connectivity between brain regions, we consider the FC of brain regions, which can better respond to the different collaborative relationships of the brain in processing emotional information. The PLV is one of the most important metrics that responds to the FC of the brain, and captures the spatial features based on the FC by calculating the phase synchronization between channels [
27]. Thus, there are
values of PLV for an EEG signal containing
channels. Given the symmetry of the EEG signal,
FC spatial features,
, can be obtained. The PLV can be calculated using Equation (1).
where
and
are the instantaneous phase of signals
and
in the same trial, respectively. The PLV is in the range [0, 1]. A larger value of PLV indicates a stronger degree of phase synchronization between the two signals.
Frequency domain analysis can accurately reflect the changes in the EEG’s frequency and phase. EEG signals include five different frequency bands, namely, delta 0.5–4 Hz, theta 4–8 Hz, alpha 8–13 Hz, beta 13–30 Hz, and gamma > 30 Hz [
28]. Thus, a maximum of
band features can be obtained for each EEG signal sample with
channels. Frequency bands are often found in different brain regions, and spectral changes among varying brain regions are associated with emotional responses. We use these frequency bands to further study the high-level EEG emotion recognition feature associated with the frequency domain. Fast Fourier transform is used to break down EEG signals
into constituent sinusoids of
as follows:
where
is the number of EEG samples and the
is the imaginary unit.
After gaining
and
, we fuse them to gain a new feature matrix and utilize two CNN layers sequentially to automatically capture their hidden relationship to further study the frequency–spatial high-level features. After every CNN layer, a pooling layer and a dropout layer are connected in series. Therefore, stage 1 contains two convolutional layers, two pooling layers, and two dropout layers. The rectified linear unit (ReLU) function is used as the activation function in the convolution operations. Thus, the input data undergo a convolution operation and an activation operation when passing through a convolution layer. After each convolutional layer, pooling and dropout layers are added to reduce the model size and overcome overfitting; the output after this sequence process can be indicated with the input signal as in Equation (3):
where
and
represent the operation in the dropout layer and pooling layer, respectively,
is the ReLU function, and
is the kernel size of the convolutional layer. Finally, after performing Equation (3) twice, the matrix of FC-FSH can be extracted.
- 2.
FC Temporal–frequency–spatial hybrid feature based on GRU network
In stage 2 of the multi-domain feature extraction, the FC-FSH data extracted in stage 1 are used as the inputs to further capture the deep intrinsic correlation features in the temporal–frequency–space domain of the EEG, i.e., FC-TFS. GRU networks have shown effective performance in extracting the long-term dependencies of signals [
29]. As shown in
Figure 2, the internal structure of the GRU contains two important basic components, the reset gate and the update gate, which control the flow of information. Therefore, GRUs are used at this stage to extract the temporal dependencies of FC-FSH.
When the input signal passes a GRU layer, the new state of the input signal at time
can be calculated as follows:
is the previous state, and
is the current candidate state. The update gate
decides how much past information to maintain and how much new information to add to the current state
. A larger value of
indicates that more information about the previous state is brought in to
.
and
can be obtained as follows:
where
is the sample vector at time
and
denotes a reset gate, which controls how much the previous state contributes to the current candidate state
. The smaller the
value, the smaller the contribution from the previous state. If
, then it will forget the previous state. The reset gate is updated as follows:
To efficiently determine the temporal relationship of the frequency–spatial domain features, two GRU layers are used in stage 2, and each GRU layer is followed by a dropout layer, which is used to randomly eliminate the connections between the GRU layer and the subsequent connected layers to prevent overfitting. The output after this sequence process can be indicated with the input signal as in Equation (8)
2.2.2. Attention Classification Module
Electrical signals generated by diverse emotional experiences in humans occur irregularly across various brain regions of the cerebral cortex [
30]. Consequently, not all features extracted from EEG signals contribute equally to the classification of emotions. Some features may carry more diagnostic value than others.
Multiple attentional mechanisms have been proposed, drawing inspiration from the brain’s attentional mechanisms. These mechanisms effectively identify the importance of distinct information. Among them, the channel attention system has demonstrated superior performance in exploring information within signal feature maps by directly assigning values to different channels. Hence, inspired by the channel attention mechanism, in this module, we introduce an attention layer following a flatten layer to assign various weights to different features for representing their contributions to emotion recognition. The output formula of the attention layer is shown in Equation (9), where
represents the weight information.
After the attention layer, the feature sequence remains in the same dimension and contains weight information. Subsequently, a dense layer and a dropout layer are added to further integrate the features; their dimension is reduced to prevent overfitting. Finally, a Softmax layer is applied to recognize emotional states.













{kind=link}
{kind=link}
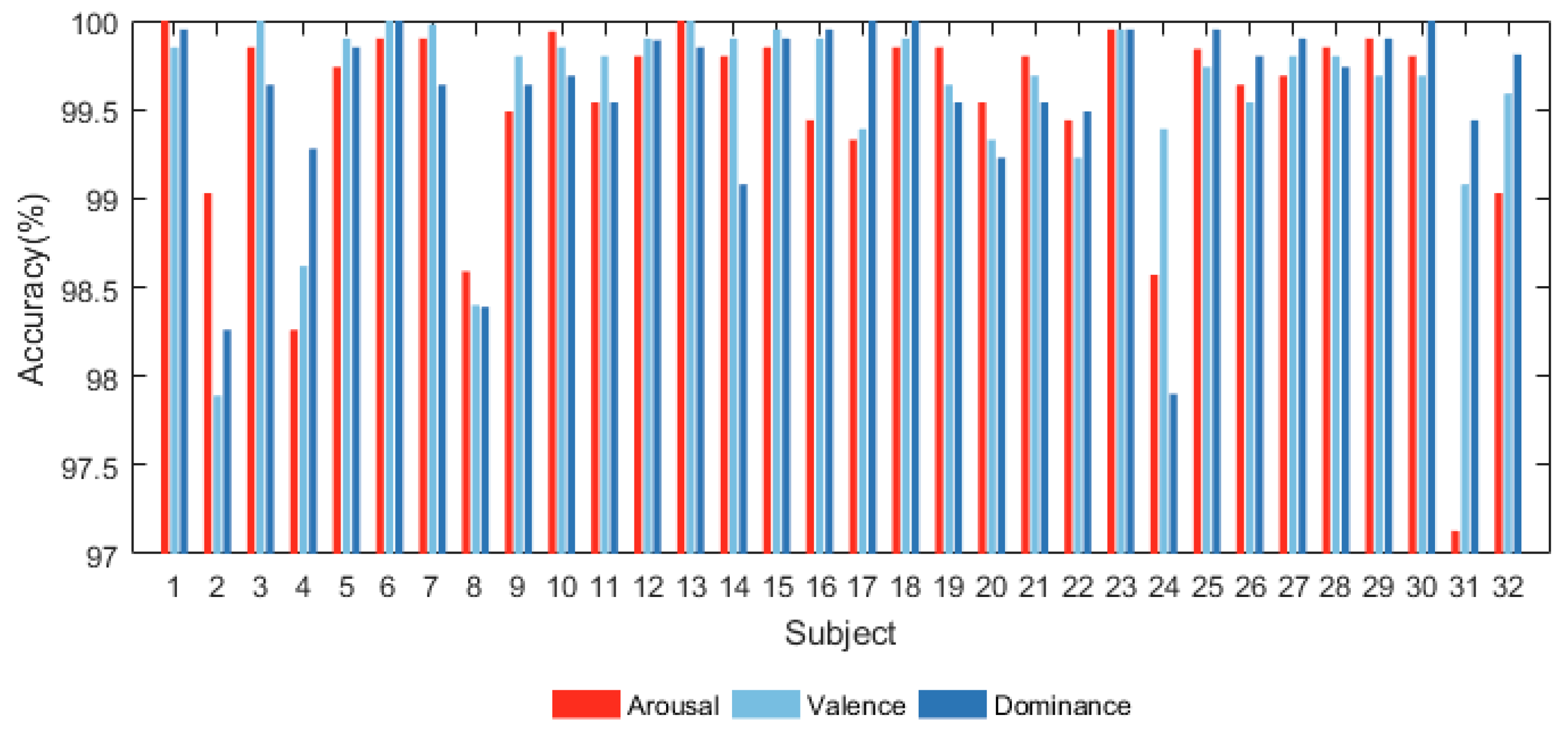
{kind=link}
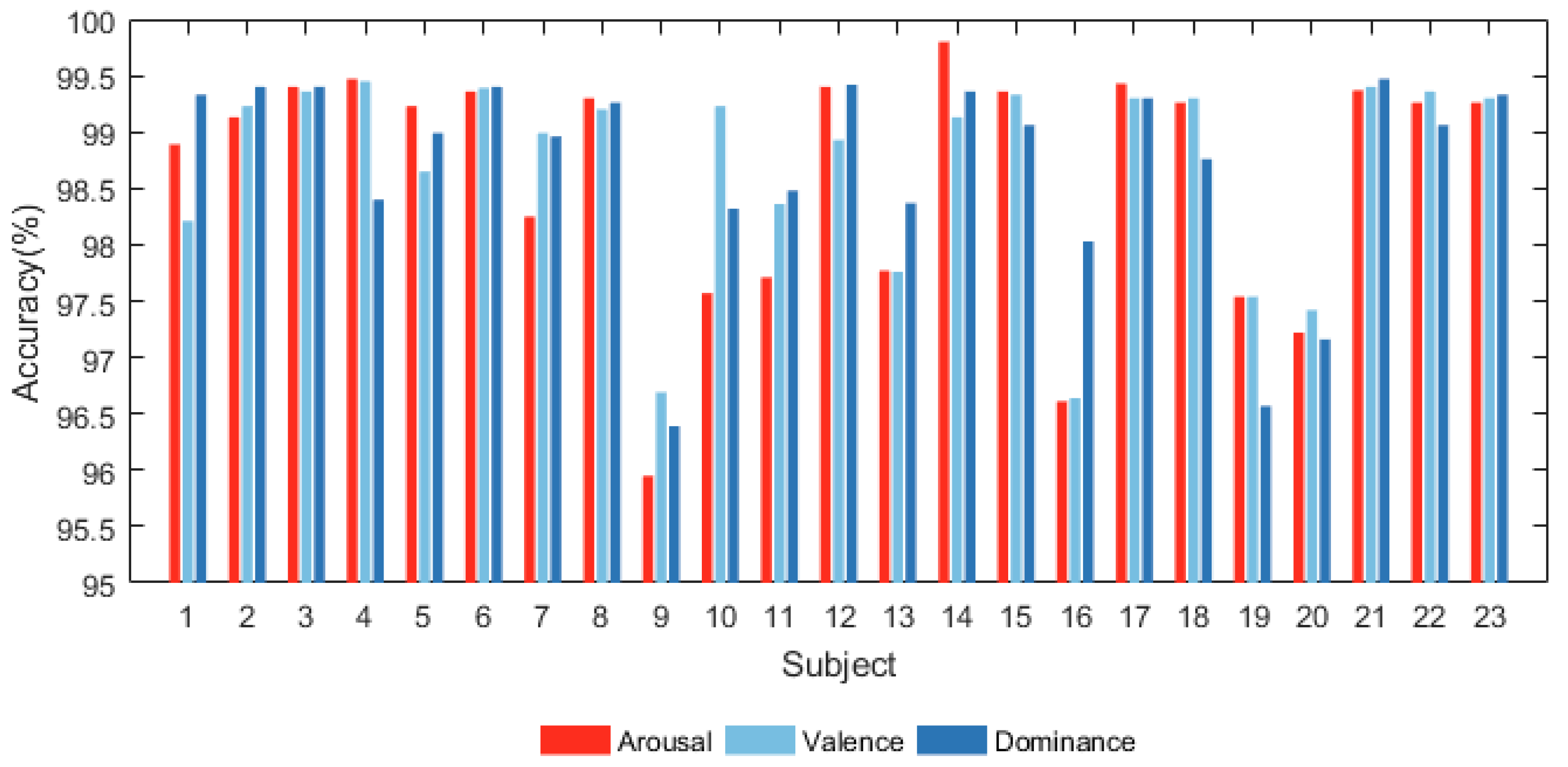
{kind=link}
{kind=link}
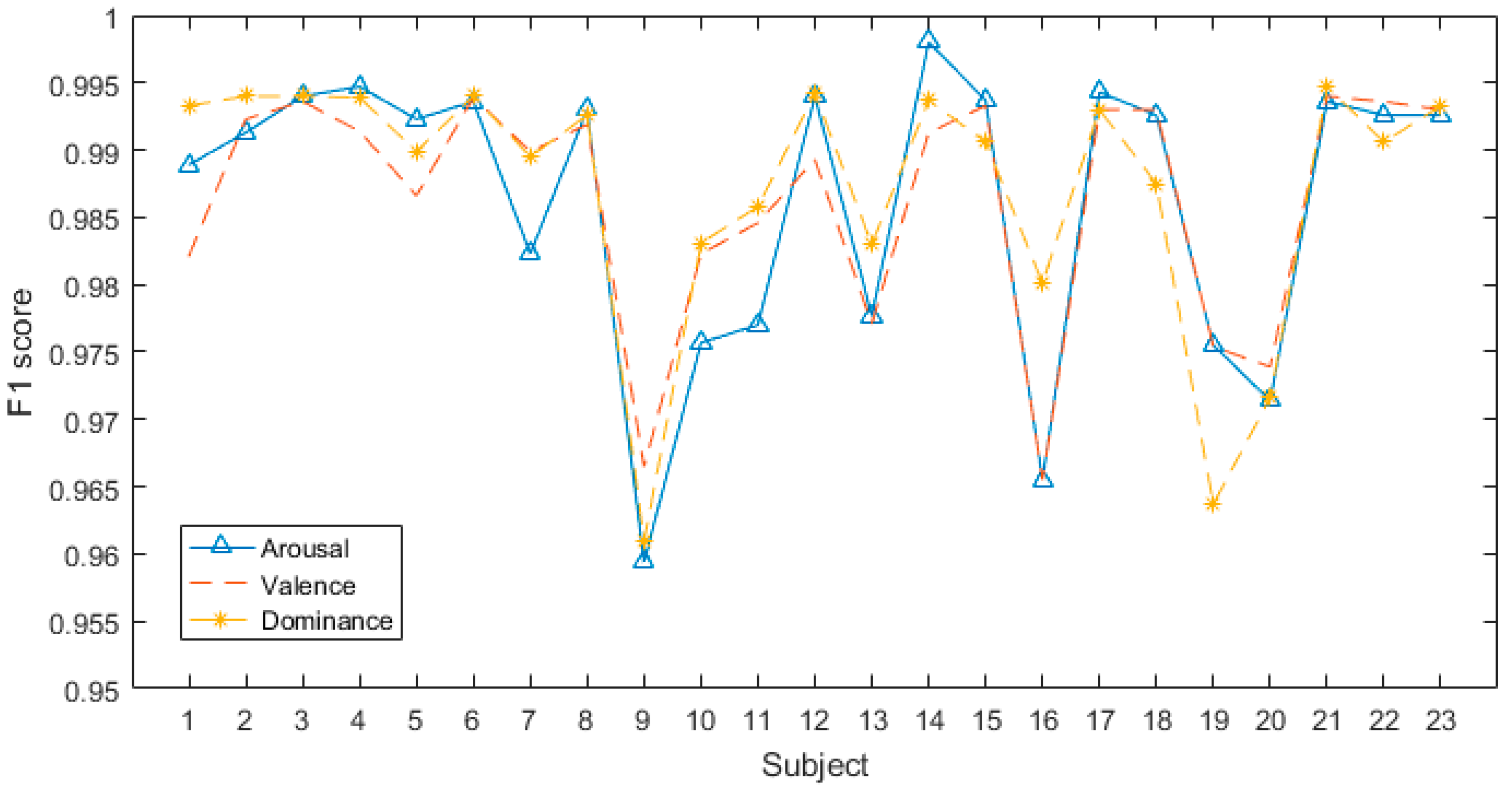
{kind=link}
{kind=link}
{kind=link}
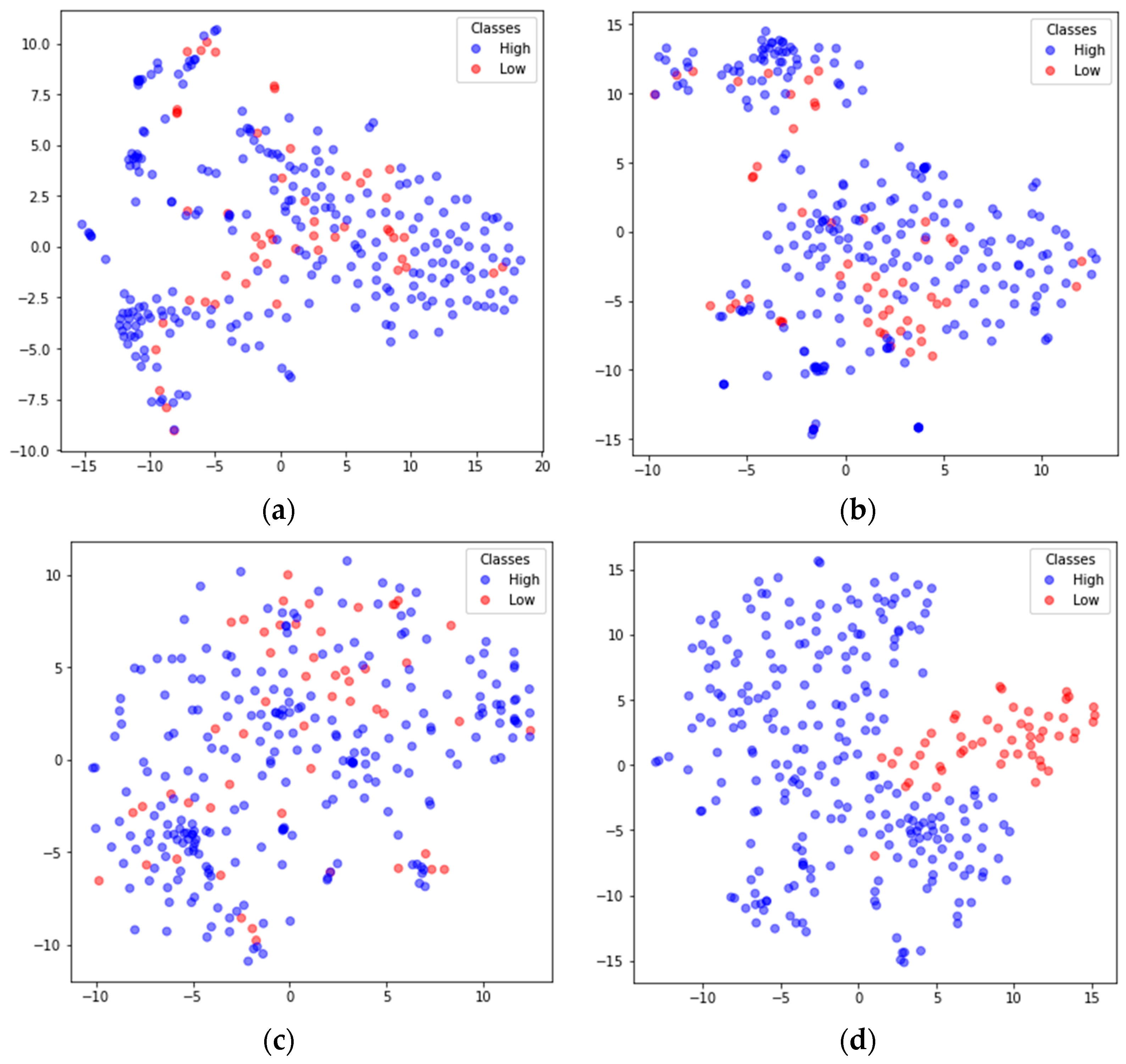{kind=link}