1. Introduction
The accurate assessment of the surrounding environment is a crucial task for intelligent autonomous vehicles to ensure secure movement [
1]. However, the placement and perspective of onboard sensors contribute to the lack of global vision and limited remote sensing of autonomous vehicles [
2]. Intelligent roadside sensing systems can be used to address the sensory limitations of autonomous vehicles in urban traffic scenarios by sharing information about pedestrians, vehicles, and traffic signs through wireless communication devices to provide enhanced environment awareness information for autonomous vehicles, decreasing the possibility of accidents and enhancing road traffic efficiency [
3].
The current research on intelligent roadside sensing technologies can be classified as radar-based, camera-based, LiDAR-based, and multi-sensor fusion-based according to the type of sensor. Radar [
4] is capable of obtaining data about moving objects within a specific region, although its precision in perception is limited. LiDAR [
5,
6,
7] acquires point cloud data by utilizing laser scanning, which captures details regarding the target object’s position and dimensions. The method includes advantages such as high accuracy, wide sensing range, and immunity to light interference, but it is costly to deploy on the roadside. The multi-sensor fusion-based method [
8,
9,
10] combines diverse data from several sensors to enhance the precision and reliability of the system. However, it involves issues such as time and space synchronization between multiple sensors as well as high computational complexity. Compared to other sensors, the camera-based method is low-cost, can obtain rich environmental information, and has real-time performance.
The conventional image-based roadside object-detection algorithms consist of the optical flow method [
11], inter-frame difference method [
12], background subtraction method [
13], etc. These algorithms rely mainly on hand-designed characteristics and classifiers driven by expert knowledge and experience. However, artificial design features contain only low-level information, so their expressive and descriptive capabilities are always limited, resulting in poor generalization.
Due to advancements in information technology, particularly convolutional neural networks, deep learning techniques have become extensively utilized in object identification tasks, such as R-CNN [
14,
15,
16] series, FCOS [
17] and SSD [
18], YOLO [
19,
20,
21,
22] series, etc. These one-stage or two-stage methods achieve more robust and accurate object-detection tasks in various complex scenarios by training and learning features on large-scale datasets. In recent years, the YOLO series has undergone constant optimization, with significantly improved detection accuracy and speed, lower computational costs, and more excellent comprehensive performance [
23]. Zhang et al. [
24] used the Res3Unit structure and a label allocation module with a Gaussian receptive field to reconstruct YOLOv7, improving the receptive field for small targets and solving the problem of the missed detection rate. Huang et al. [
25] proposed a model based on YOLOv5s called RD-YOLO, which replaced the original pyramid network through a broad-based characteristic pyramid network and integrated coordinate attention (CA) mechanism. Although roadside cameras have a wider and longer field of view, perception algorithms based on roadside cameras also have corresponding problems in complex traffic environments, such as missed detection of targets caused by occlusion between traffic participants in dense traffic and false detection of multi-scale targets.
Multi-scale context information is essential for targets with different scales. Context information of different scales can be concatenated to gain multi-scale information to improve the performance of detection. Deng et al. [
26] proposed MS-OPN, a multi-scale object proposal network based on several intermediate feature maps, according to the certain scale ranges of different objects. Zeng et al. [
27] proposed the atrous spatial pyramid pooling balanced feature pyramid network called ABFPN, a novel enhanced multiscale feature fusion method. To fully utilize context information, atrous convolution operators with varying dilation rates are used, and skip connections are applied to achieve sufficient feature fusions. Shen et al. [
28] and Ju et al. [
29] proposed a YOLOv3-based method in which a 4 times smaller detection branch is added and a feature map cropping module is introduced. Xu et al. [
30] adopted a densely connected network to enhance the feature extraction capability of YOLOv3. Han et al. [
31] proposed a multi-scale feature extraction module called LM-fem to enhance the multi-scale feature extraction capability and a new hybrid domain attention module called S-ECA relying on multi-scale contextual information. The above methods improve the model’s ability to extract multi-scale contextual information by optimizing the structure of the feature extraction network but inevitably increase the complexity of the network.
Occluded objects are characterized by a limited number of pixels, presenting incomplete features and being obscured by noise and background clutter. After successive down-sampling and pooling operations, part of the features will be lost. Several researchers have undertaken studies on that. Tian et al. [
32] proposed a vehicle detection grammar to handle partial occlusion, including structure, deformation, and pairwise SVM grammars which captures rich information about the vehicle and occlusions. Whereas, dividing vehicles into semantic parts and then designing detection programs based on grammar models to perform vehicle detection and handle vehicle occlusion issues cannot ensure that the initial sampling network learns more suitable features for occlusion representation. Zhang et al. [
33] proposed a Faster R-CNN-based method that employed a channel-wise attention mechanism to handle various occlusion patterns. Zhang et al. [
34] proposed a detector based on Faster R-CNN integrated with a part-aware region proposal network to extract global and local visual information about vehicles. By generating partial and instance-level proposals and encoding different parts of one vehicle into a compositional proposal, the detector model reduces the impact of occlusion. Li et al. [
35] proposed a detector based on YOLOv3 called YOLO-ACN with a channel attention module, realizing the cross-channel interaction without dimensionality reduction, which can pay more attention to the occluded objects. Song et al. [
36] proposed a progressive refinement network called PRNet and PRNet++ with a dual-stream structure with occlusion loss and receptive field back-feed modules. While the aforementioned studies have made valuable contributions to occluded-object detection, they still exhibit certain limitations such as complex networks and slow inference speed. Our research aims to build upon these works and provide a lightweight and high-precision network architecture to address the challenges.
In summary, prior methodologies have demonstrated some efficacy in detecting multi-scale and occluded targets. Nonetheless, the intricacies of urban transportation environments, coupled with infrastructure limitations, necessitate a balance between accuracy, model weight, and computational efficiency in the deployment of roadside systems. Addressing these challenges, this article presents optimizations to the YOLOv7-tiny model and introduces the PDT-YOLO roadside object-detection algorithm. This article has carried out the following work:
- (1)
Revise the structure of the feature fusion layer and incorporate the AIFI module to enhance the precision of multi-scale object identification and reduce network parameters and model calculations.
- (2)
Develop a multi-scale feature extraction ETG module to replace the ELAN-T module in the head network to enhance the detection accuracy while maintaining the number of model parameters and computational complexity.
- (3)
Employ multi-attention mechanism modules to augment feature processing, mitigate intricate background interference, and amplify the expressive capacity of occluded objects.
- (4)
Utilize the WIoU to enhance the accuracy and generalization adaptability within the network.
- (5)
Implement perception algorithms on the roadside and perform real-time object detection and verification based on ROS (Robot Operating System).
2. Methodology
2.1. YOLOv7-Tiny Network
The YOLOv7 algorithm is a one-stage network released by Wang Chienyao’s team in 2022, which possesses the benefits of fast inference and high detection accuracy. YOLOv7-tiny is a lightweight YOLOv7 network suitable for edge GPUs, which mainly consists of two parts: the backbone network and the detection head network. The backbone network combines standard convolution, efficient layer aggregation network (ELAN-T), and maximum pooling convolution module (MPConv) to perform multiple feature extraction and scale transformation on the input, obtaining multi-scale feature information. The head network initially employs an enhanced spatial pyramid pooling module (SPPCSPC) to mitigate image distortion and eliminate redundant feature extraction issues. Additionally, it employs a feature pyramid framework to transfer and merge features. Ultimately, it uses standard convolution and the Detect module to obtain multiple prediction boxes and outputs predicted bounding box coordinate information, confidence, and class probability.
2.2. Feature Fusion Network Improvement
The detection of multi-scale and occluded objects poses a challenge in the field of computer vision. Due to the occluded object’s relatively weak features in the image, it may not be able to capture details and contextual information, resulting in inaccurate detection results. In the realm of roadside object-detection algorithms, there exists a dual imperative: the accurate identification of targets in complex road environments and the model size for the feasible deployment of edge devices on the roadside.
The YOLOv7-tiny model incorporates the PANet [
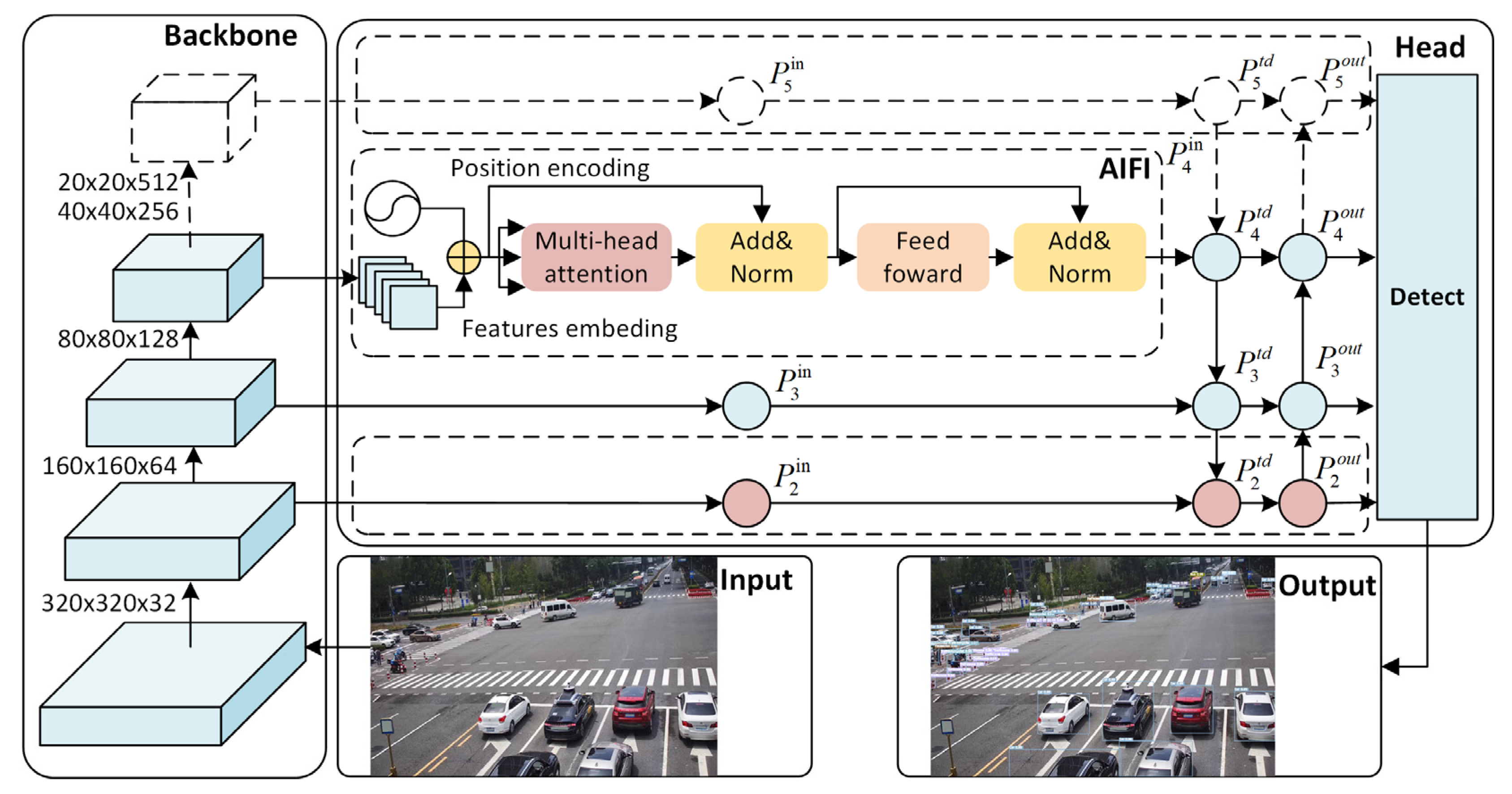
37] structure within its head component which achieves cross-level feature interaction and fusion by adding bottom-up enhancement routes and adaptive feature pooling operations. Such a design enables the effective utilization of semantic information across diverse levels, enhancing detection accuracy concerning multi-scale targets. When the input image size is set to 640 × 640, the backbone feature extraction network of the YOLOv7-tiny model generates feature maps sized 320 × 320, 160 × 160, 80 × 80, 40 × 40, and 20 × 20 through the ELAN-T module and the MP module.
Firstly, to improve the detection performance of small targets and reduce network parameters and model calculations, the processing of feature maps with a size of 160 × 160 is increased, while removing the top-level feature extraction layer of the backbone network which means feature maps with a size of 20 × 20 has been removed, as shown in
Figure 1. Deeper feature maps with larger receptive fields are more suitable for detecting large objects, while low-level feature maps with smaller receptive fields are more suitable for detecting small objects. In essence, this article focuses on processing feature maps of 160 × 160, 80 × 80, and 40 × 40 to effectively combine contextual information for smaller objects and maintain a three-layer network structure. Considering the bottom-up path aggregation network and the operation of cross-scale connections, the operation process of the third layer node is as follows:
In the above equation: is the original input feature of the third layer, and are the intermediate feature levels of the third and fourth layers in the top-down path, and are the output features of the second and third layers in the bottom-up path.
Secondly, to add richer advanced semantic features, a transformer-based module called AIFI [
38] is introduced. Transformer [
39] is a deep learning model based on a self-attention mechanism, widely used in natural language processing tasks. The encoder module in a Transformer is composed of a stack of 6 identical layers, mainly including multi-head self-attention, pointwise feedforward, and normalization. Multi-head self-attention is a key component of Transformer which allows the model to jointly focus on information from different representation subspaces at different positions. The equations of the multi-head self-attention are detailed below:
The query, key, and value matrix are the inputs of the attention mechanism. represent the weight matrix of the linear transformation related to the attention head, projecting the input into different subspaces. is the final linear transformation to obtain the final output of multi-head self-attention.
Pointwise feedforward introduces nonlinearity and allows the model to independently capture complex patterns in the data at each position. This enables the network to learn the complex relationships between different elements in the input sequence which helps in modeling and processing sequence data. The equation of the feedforward network is detailed below:
Among them, represents the input, , , and are the weight matrix and bias terms of the first and second linear transformation.
Lv et al. [
38] introduced an efficient hybrid encoder based on the Transformer which converts multi-scale features into image feature sequences through intra-scale feature interaction (AIFI) and cross-scale feature fusion module (CCFM). The AIFI module orchestrates intra-scale interaction among high-level features through a self-attention mechanism, enabling the capture of relationships between conceptual entities within the image. This mechanism proves advantageous for subsequent modules tasked with object detection and recognition. The equations of the AIFI module are detailed below:
In the above equation, the query, key, and value are the same and all come from the results of the flatten operation of the fourth layer. The flatten operation collapses the width and height dimensions of the input tensor into a single dimension while preserving the batch and channel dimensions. This paper uses the AIFI module instead of the SPPCSP structure to process the high-level feature maps of the model, reducing computational complexity and improving detection accuracy.
2.3. ETG Module
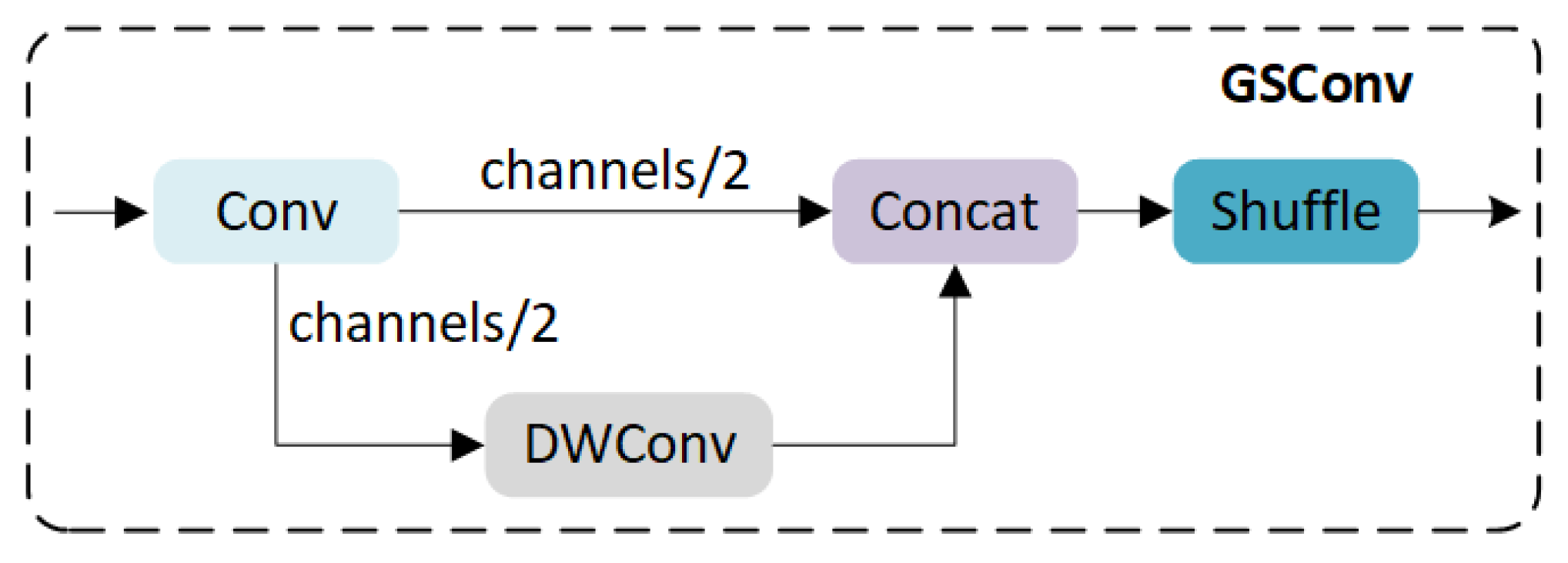
To enhance the expression ability of image features while ensuring the number of parameters and detection speed of the algorithm model, this paper introduces the GSConv module and develops an ETG structure. GSConv is a lightweight convolution technique to reduce model weight while maintaining accuracy, proposed by Li et al. [
40], which combines the advantages of a standard convolution module, a depth-wise separable convolution module, and a Shuffle. The GSConv structure is shown in
Figure 2.
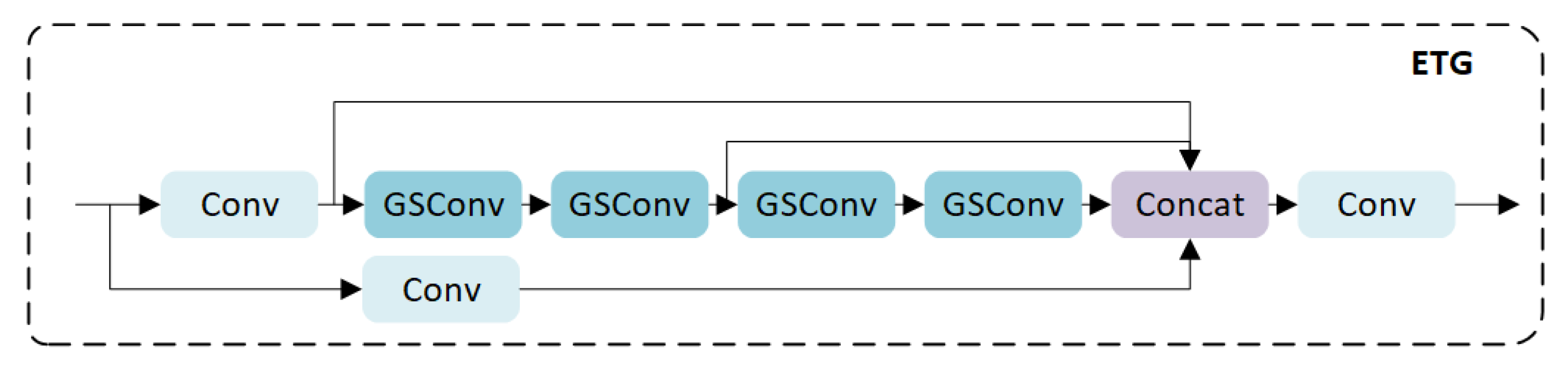
ELAN [
41] is a strategy for designing gradient paths at the network level, which optimizes the gradient path length of the entire network by introducing a stacking structure in the calculation block. The main purpose of ELAN is to address the problem of deteriorating convergence of deep models during model expansion. The ETG structure is proposed based on the idea of ELAN and consists of four parallel branches. As shown in
Figure 3, two branches use 1 × 1 convolution to preserve the texture and background features of the image, while the other two branches use two cascaded GSConv modules to improve feature fusion, accelerate network inference speed, and effectively reduce network complexity.
2.4. Multi-Attention Mechanism Module
To improve the expression ability of the detection head, a multi-attention mechanism called the DyHead [
42] module is added to the original Detect module, which is optimized to DyDetect. The network structure diagram of DyDetect is shown in
Figure 4. The DyHead module contains a scale-aware attention mechanism
, a spatial-aware attention mechanism
, and a task-aware attention mechanism
. The equations of DyHead are as follows:
The scale-aware attention mechanism conducts average pooling on the input feature maps, resizing them to a 1 × 1 size. Through a convolutional operation to reduce the dimensionality of the feature map. Subsequently, the ReLU is applied to introduce non-linearity, facilitating the model in learning complex feature relationships. The use of the hard-sigmoid function aims to strike a balance between the model’s expressive power and training efficiency.
The spatial-aware attention mechanism calculates the mask and offset based on the input feature map (level), and then uses a dynamic convolutional network (DyDCNv2) to extract features from the input level. Low-level features are extracted from the previous level by DyDCNv2. High-level features are extracted from the next level by DyDCNv2. Then all features are weighted and summed.
The task-aware attention mechanism incorporates a dynamic differentiable activation function. Initially, it performs average pooling on the input features to reduce the number of channels. Subsequently, a fully connected layer is employed to derive dynamic parameters that can be adjusted based on the mean and standard deviation of the input features. Finally, the max function implements the dynamic activation function.
Multi-attention mechanisms can be sequentially arranged and employed. Under the premise of considering computational costs, this study uses a separate set of multi-attention mechanism modules to optimize the feature expression ability of occluded targets in complex scenes and improve overall detection performance.
2.5. Loss Function
The effectiveness of object detection is partially reliant upon the design of the bounding-box loss function. Within the YOLOv7-tiny algorithm model, the CIoU Loss [
43] serves as the designated bounding-box loss function. This loss function primarily considers parameters such as the overlapping area, center distance, and aspect ratio between the predicted box and the ground truth box. The equation is as stated:
is utilized to quantify the extent of overlap between the predicted box and the true box in object-detection tasks. denotes the Euclidean distance between the center points of the predicted box and the true box. represents the diagonal distance between the smallest outer box of the wrapped predicted box and the true box. is the weighting factor employed to adjust the balance ratio, and is the parameter employed to assess the consistency of aspect ratio when the center points overlap. CIoU Loss, being a monotonically focused loss function, is often stable. However, when the aspect ratio of the predicted box and the true box is identical, vanishes, impeding model optimization and resulting in sluggish convergence of the loss function.
This study introduces the WIoU Loss presented by Tong et al. [
44] as a strategy to augment algorithmic performance and enhance detection accuracy. The loss function incorporates a dual-distance attention mechanism and a dynamic non-monotonic frequency modulation coefficient. The equations are as stated:
Among them, is the dynamic nonmonotonic frequency modulation coefficient, is used to amplify the of ordinary quality anchor boxes, and [0,1] is used to reduce the of high-quality anchor boxes. WIoU Loss with dynamic non-monotonic focusing mechanism dynamically allocates gradient gain for different quality image targets, further improving the accuracy and generalization ability of sensing.
2.6. PDT-YOLO Algorithm
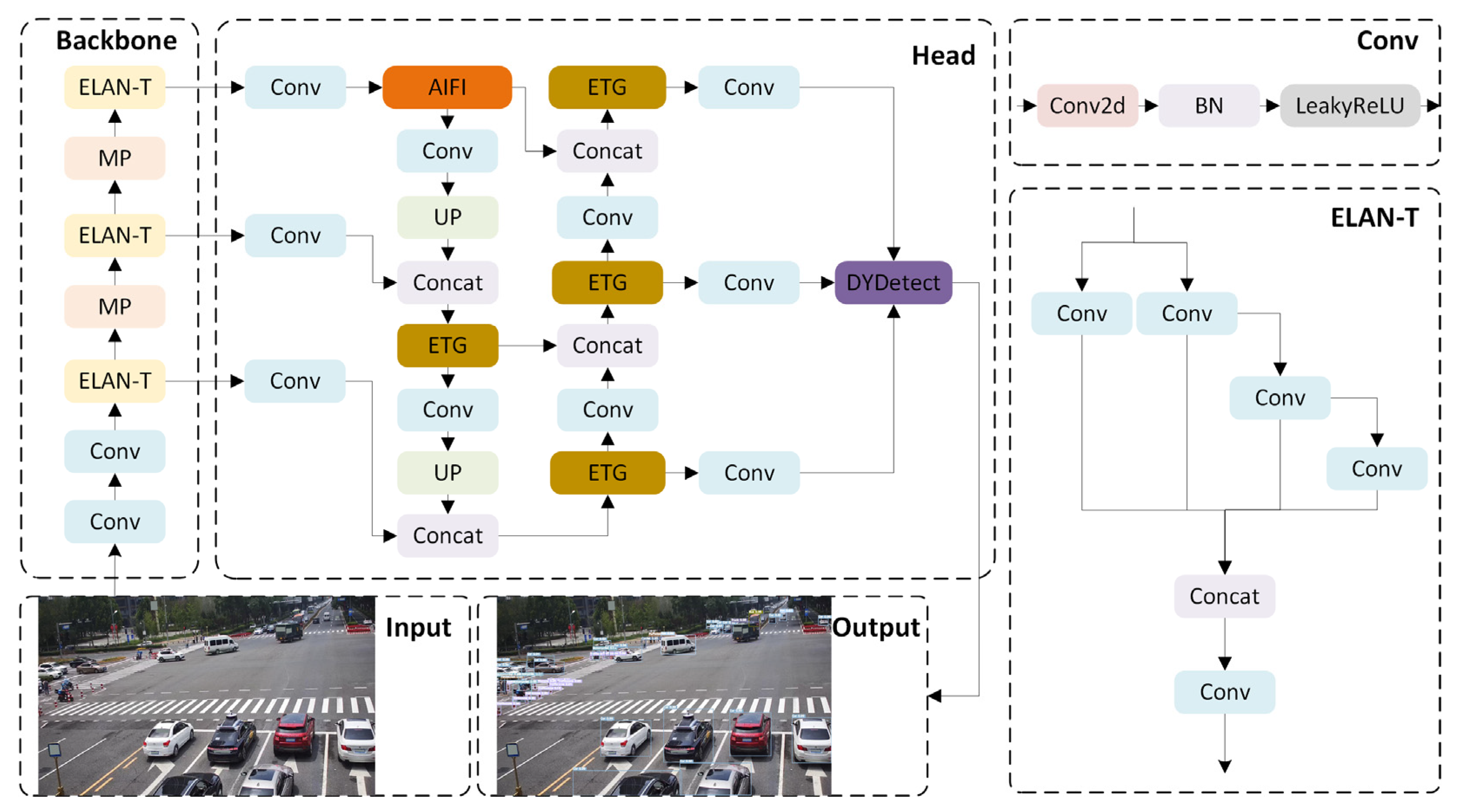
This work presents a roadside object-detection algorithm for multiscale and occluded targets, based on the above-mentioned improvement strategy.
Figure 5 displays the network architecture of the improved algorithm.
The backbone network plays a pivotal role in extracting features from input images and propagating these multi-layered feature representations to the subsequent head network. In the pursuit of lightweight deployment for roadside target detection models and the refinement of detection accuracy for small targets, we exclude 20 × 20 feature layers while augmenting the extraction process with 160 × 160 feature layers. Additionally, to enhance the extraction of more sophisticated and meaningful semantic features, a transformer-based AIFI module is introduced within the 40 × 40 feature layer. In the neck section, we substitute the original ELAN-T structure with the ETG structure to enhance the expressive capacity of image features without compromising the model’s parameter count or detection speed. The integrated multi-attention mechanism module in Detect enhances the model’s ability to process features in a more detailed manner, which allows the model to effectively concentrate on occluded target areas and reduce interference from the background. Moreover, by replacing the original CIoU Loss function with the WIoU Loss, the algorithm’s adaptability across diverse situations is enhanced, thereby amplifying the overall detection performance of the model.
4. Discussion
In recent years, intelligent roadside perception systems have always been hot spots of scientific research [
4,
5,
6,
7,
8,
9,
10]. Some scholars [
24,
25] have adopted the deep learning algorithm to address several challenges, including weak multi-scale object perception ability, the high missed detection rate of occluded targets, and difficulties in model deployment.
Target sizes vary in roadside perception scenarios. In this case, extracting target features solely through a single scale is extremely difficult. To address this, the integration of multi-scale context information becomes imperative, as it can enhance detection performance. Researchers have explored various approaches to extract contextual information across different scales. These include employing diverse convolutional kernels to extract features at multiple scales [
26], cascading hierarchical structures to propagate information [
27,
30], such as feature pyramid frameworks, increasing the number of detection heads [
28,
29], and other techniques aimed at aggregating information from input images. In our study, we reconstruct the feature pyramid structure by adding the 160 × 160 feature map while eliminating the 20 × 20 feature map. This adjustment prioritizes the processing of feature maps sized 160 × 160, 80 × 80, and 40 × 40 to effectively combine contextual information for smaller objects. Moreover, higher-level features are derived from lower-level features containing rich semantic information about objects within the image. Such high-level features, characterized by richer semantic concepts, facilitate the discernment of connections between conceptual entities within the image, aiding detection and recognition by subsequent modules. Intra-scale interactions among lower-level features are unnecessary due to their lack of semantic concepts, which may risk duplicating or confounding interactions with high-level features. The introduction of the AIFI module performs intra-scale interaction on the 40 × 40 high-level feature map to extract deeper features. Based on
Table 5, our feature fusion network enhances the extraction ability of high-level and low-level features, effectively improving the detection accuracy of the model. Meanwhile, due to the removal of the original 20 × 20 feature map, the parameters and weight of the model have also been reduced.
Due to the high density of objects and low camera angle for monitoring urban traffic, occlusion will lead to false detections of occluded objects. Some methods have been proposed to solve this problem. Attention maps that guide the learning of visible parts [
33], such as pixel-by-pixel and channel-by-channel attention maps, can learn robust feature representations to focus on relevant information. Special-designed occlusion-aware loss functions [
35,
36] can automatically increase the weight of healthy samples and reduce the weight of false positives. Post-processing techniques such as non-maximum suppression (NMS) [
34] with specially designed thresholding can refine the detection capability. We use a method of data augmentation using random noise and random grayscale to enhance the dataset and improve the model’s ability to generalize to different scenarios such as partial occlusion, object overlap, and cluttered backgrounds. We integrate a multi-attention mechanism concluding the scale-ware attention, the spatial-aware attention module, and the task-aware attention module. The multi-attention mechanism makes the importance of various feature levels adaptive to the input, applies attention to each occluded object’s spatial location, and adaptively aggregates multiple feature levels together for learning a more discriminative representation which can focus on utilizing the visible information of occluded objects while ignoring the features of occluded parts. WIoU reduces the competitiveness of common high-quality anchor boxes while also reducing the harmful gradients generated by low-quality anchor boxes such as background noise, making the algorithm more focused on ordinary quality anchor boxes such as large-scale targets, small-scale targets, and occluded targets, improving overall performance.
We introduced the GSConv module for efficient layer aggregation and constructed the ETG module. GSConv consists of a standard convolution module, a depth-wise separable convolution module, and a Shuffle. Compared to standard convolutional kernels, GSCONV may not have strong feature extraction capabilities, but it can optimize model parameters. The ETG module is based on a stacked structure design, two branches are used to preserve the texture and background features of the image using 1 × 1 convolution, while the other two branches use two cascaded GSConv modules to improve feature fusion and optimize the model parameters, effectively reducing network complexity.
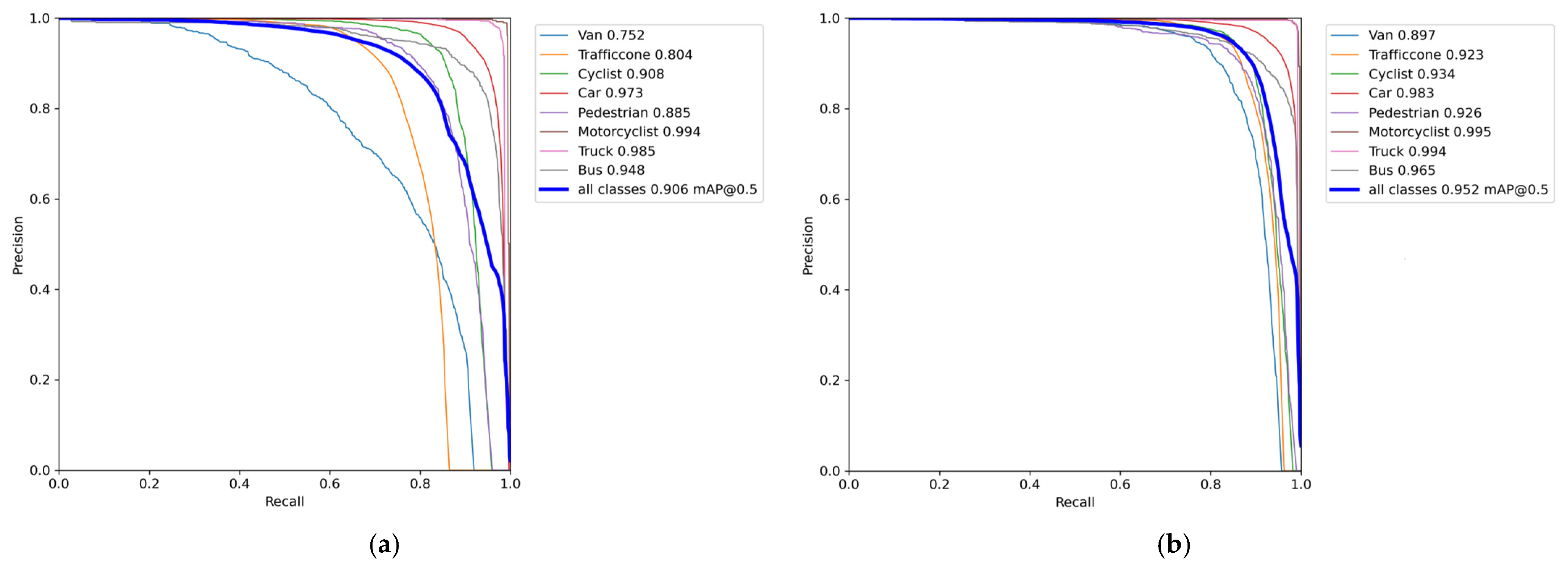
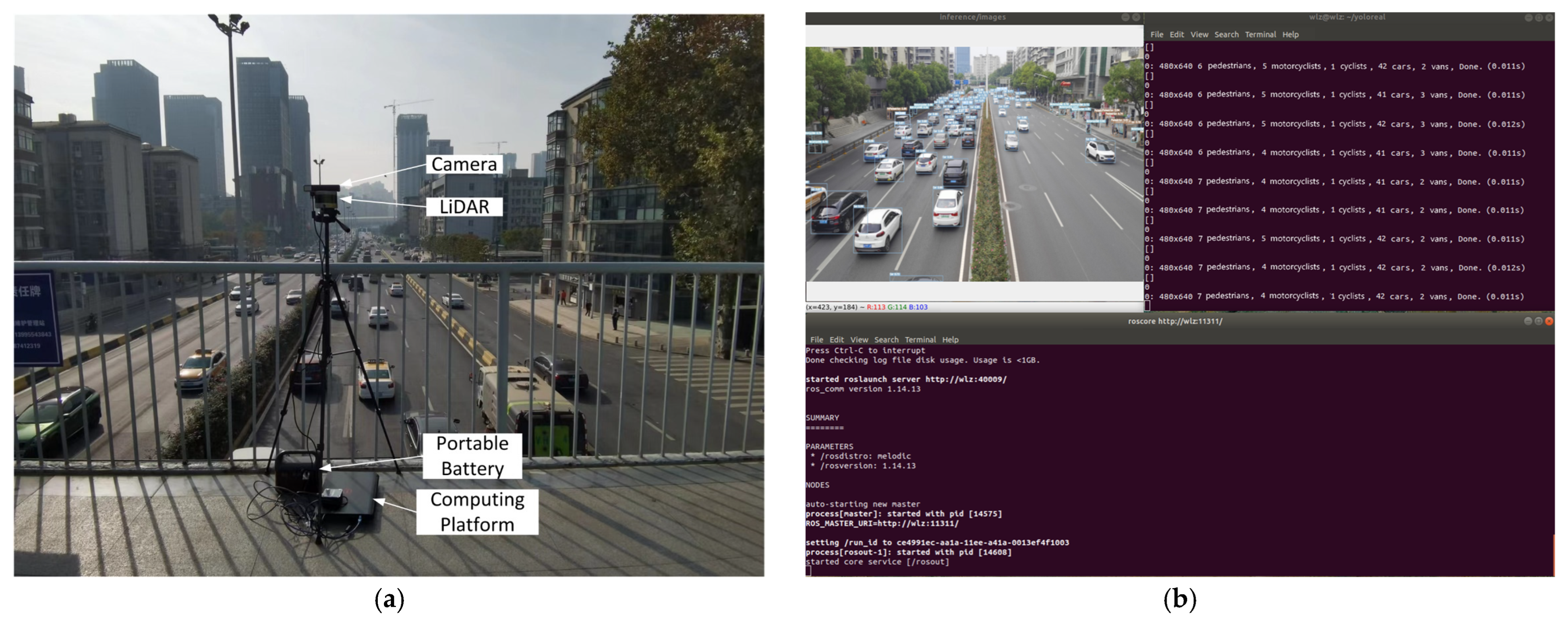
Our experimental results demonstrated that, compared to YOLOv7-tiny, PDT-YOLO improves mAP50 and mAP50:95 by 4.6% and 12.8% while maintaining comparable parameter count and weight. Additionally, PDT-YOLO outperforms several mainstream algorithms, multi-scale target detection, and occluded target detection algorithms, in terms of mAP50, mAP50:90, parameter count, and weight on the DAIR-V2X-C dataset. Moreover, the generalization and effectiveness of the algorithm were validated through testing on the IVODC dataset, showing its robust performance even in challenging environmental conditions such as cloudy and rainy weather. Real-world deployment on actual roads using ROS systems further confirmed the algorithm’s capability to detect multi-scale and occluded targets at a speed of 90, meeting the demands of edge target detection in complex traffic scenarios.
In conclusion, the PDT-YOLO algorithm presents a solution for improving the performance of intelligent roadside perception systems. Its effectiveness in addressing challenges of weak multi-scale object perception and high missed detection rate of occluded targets highlights its potential for real-world deployment for further research and development in the field of intelligent transportation systems.
5. Conclusions
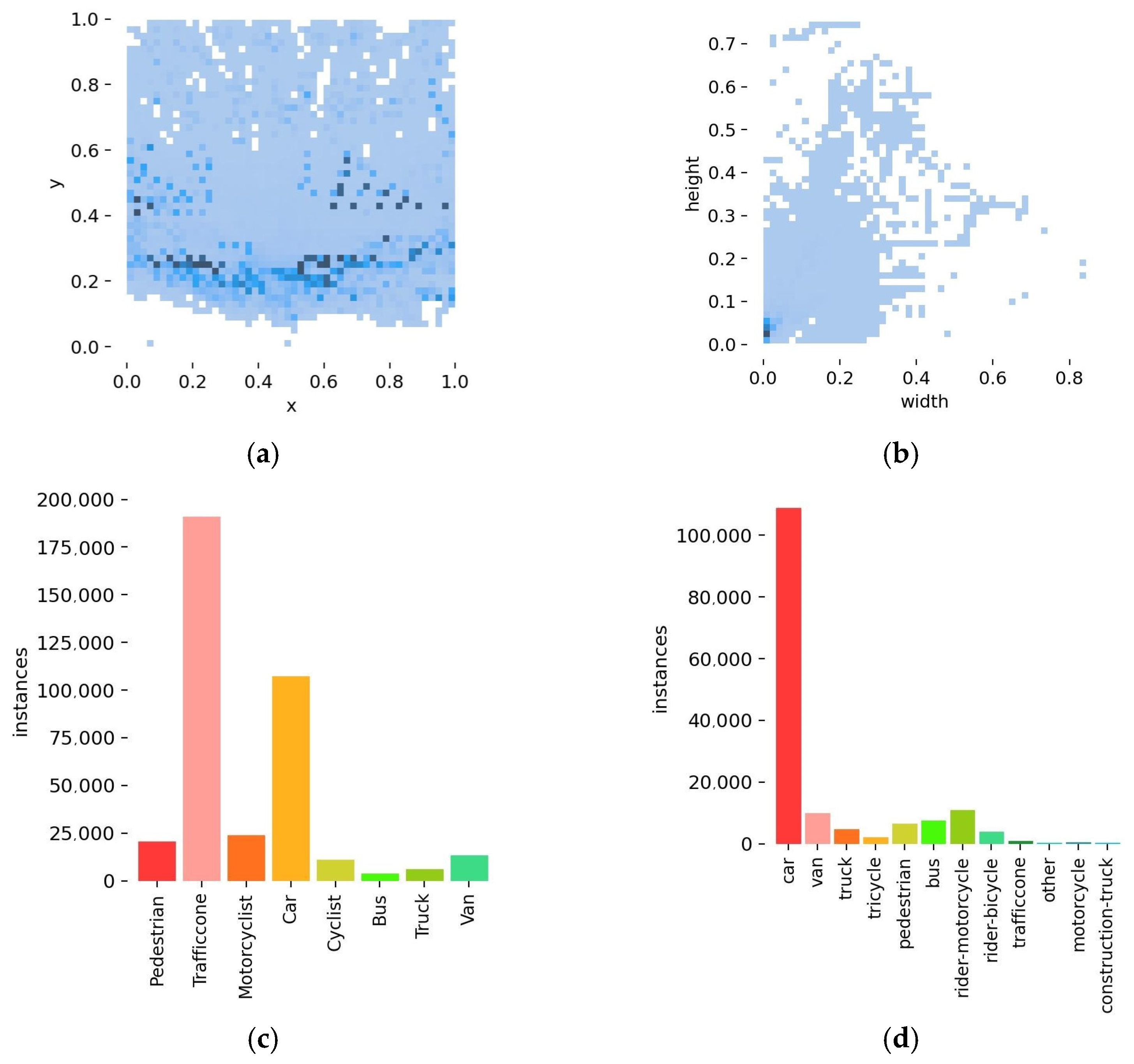
This article proposes a roadside object-detection algorithm for multiscale and occluded targets algorithm called PDT-YOLO and conducts ablation and comparison experiments on the DAIR-V2X-C dataset, generalization experiments on the IVODC dataset, and deployment verification on an actual traffic environment. Experimental results have shown that the PDT-YOLO outperformed mainstream algorithms in terms of accuracy, with small model size, minimal parameter count, and fast inference speed, meeting the demands of edge target detection in complex traffic scenarios.
However, the algorithm does not involve low visibility of cameras under extreme weather conditions such as heavy snow, so the algorithm still has certain limitations. Future work will optimize the model to enhance its robustness, accuracy, and speed, thus ensuring its applicability across a wider range of environmental conditions.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}