
Robust Offloading for Edge Computing-Assisted Sensing and Communication Systems: A Deep Reinforcement Learning Approach


Abstract
:1. Introduction
- The computation uncertainty of a UE’s task within the framework of ISCC is investigated in this paper. To tackle the uncertainty of computation, a robust optimization problem aimed at minimizing system energy consumption is formulated. This is achieved by simultaneously optimizing communication and computation resources, beamforming, and offloading ratio.
- To address the outlined optimization challenges, this paper introduces a method that incorporates the proximal policy optimization (PPO) algorithm into deep reinforcement learning (DRL). This approach is designed to meet multiple constraints, including radar estimation information rate, computational offloading delay, and resource allocation. Utilizing a DRL training framework, this method allows for the efficient exploration and resolution of this intricate optimization problem. The system not only addresses practical constraints but also elevates decision making through the integration of intelligent learning algorithms.
- Through a series of simulation experiments, we assess the performance of this method, confirming the effectiveness of the computational robustness design and the PPO method in enhancing system efficiency and reducing energy expenditure. The robustness design demonstrates the improved performance in scenarios with uncertain task complexities. The simulations further reveal that the system’s weighted energy consumption could be significantly lowered when using the PPO algorithm with robustness.
2. Related Works
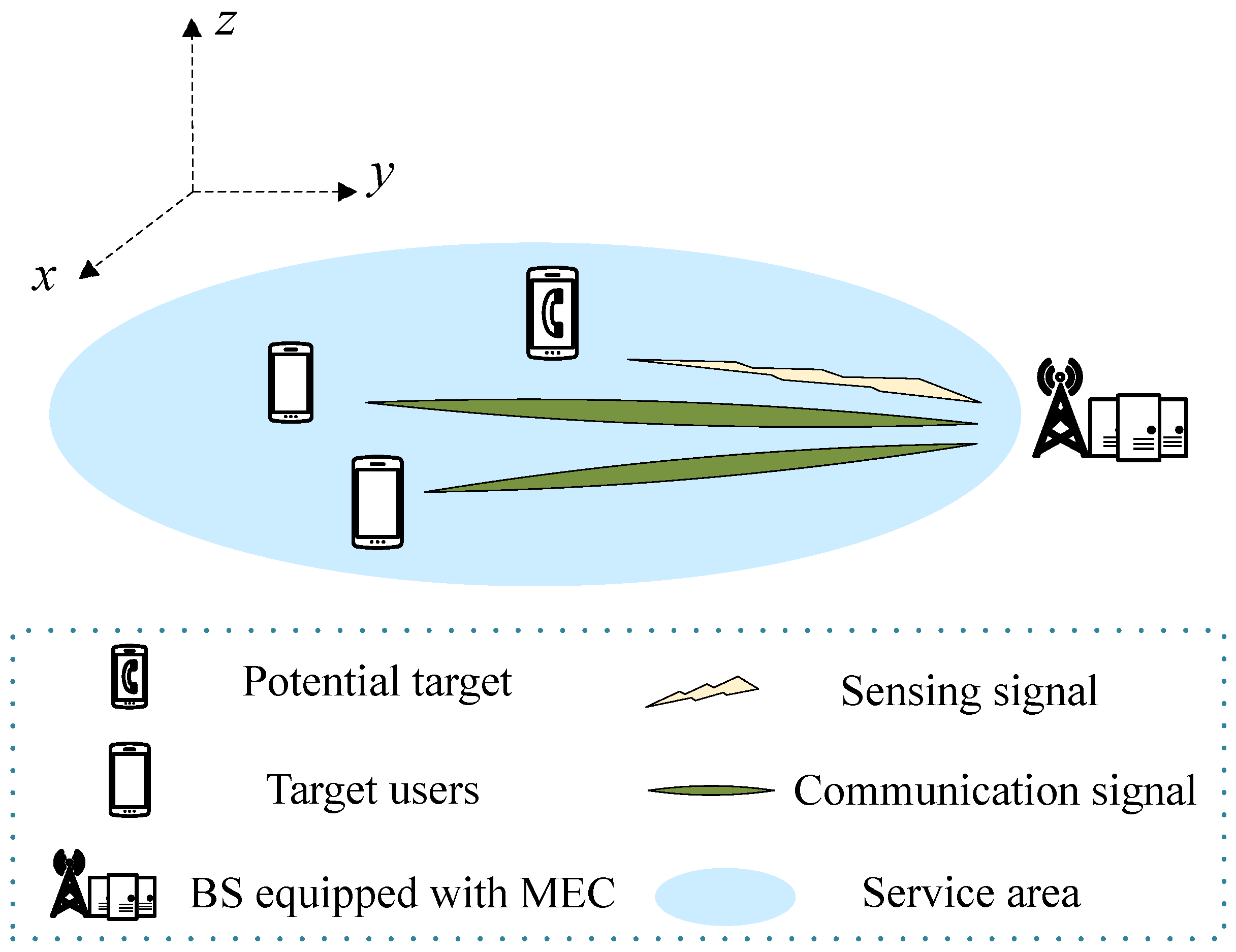
3. System Model and Problem Formulation
3.1. System Model
3.2. Signal Model
3.3. Sensing Model
3.4. Computation Model
3.5. Problem Formulation
4. Proposed Algorithm
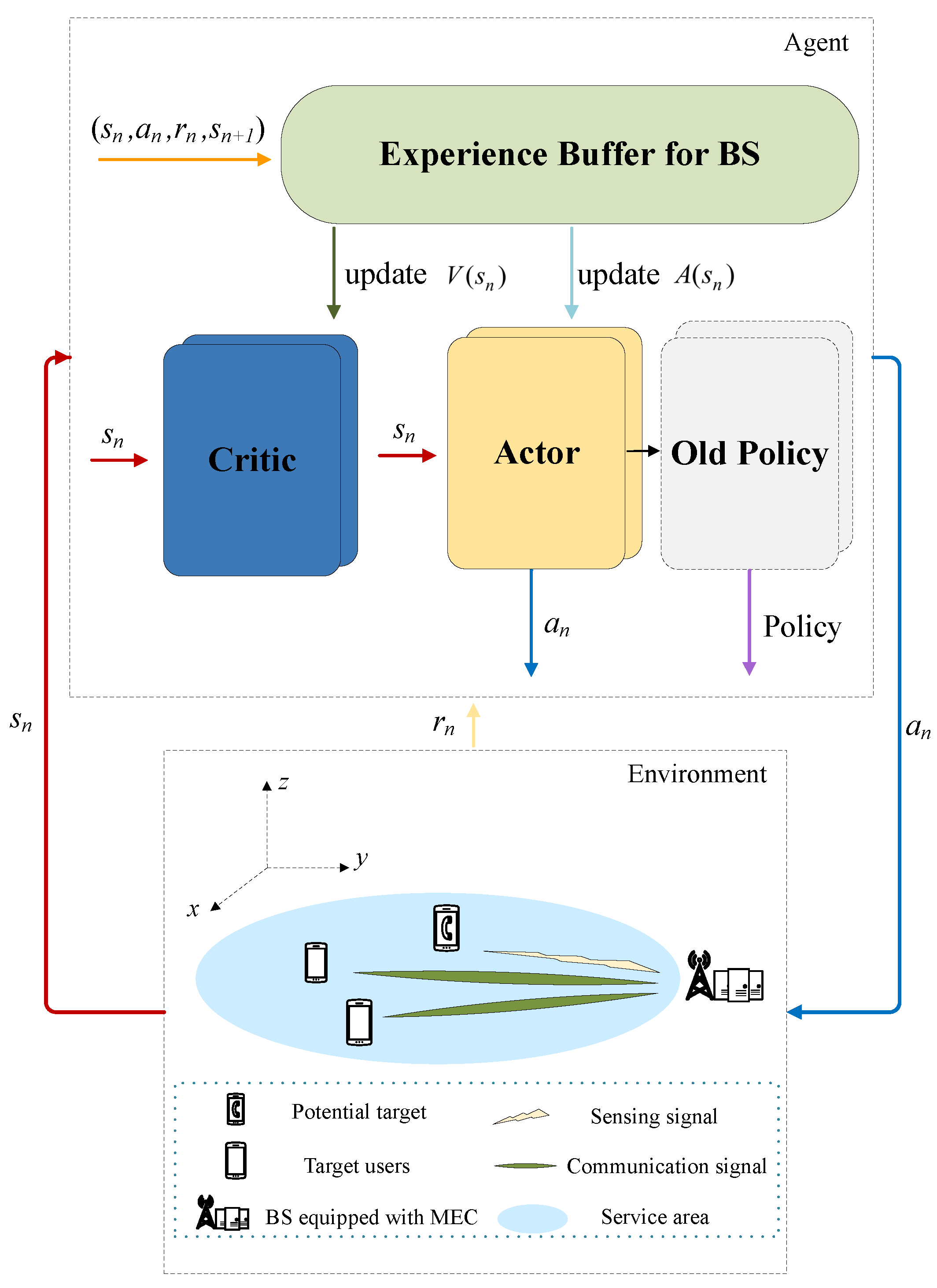
4.1. Modeling of Single-Agent MDP
4.2. PPO-Based DRL Training Framework
| Algorithm 1 Proposed PPO training framework |
|
4.3. Complexity Analysis
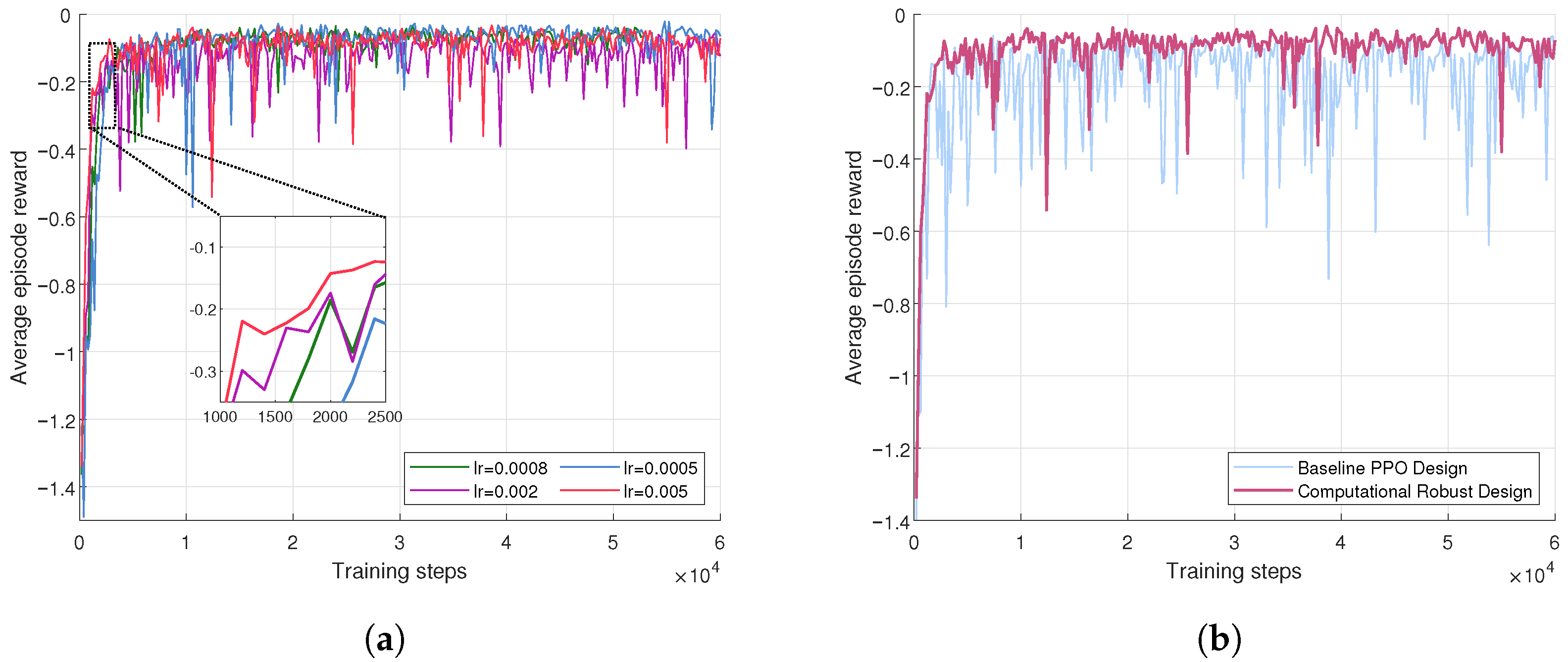
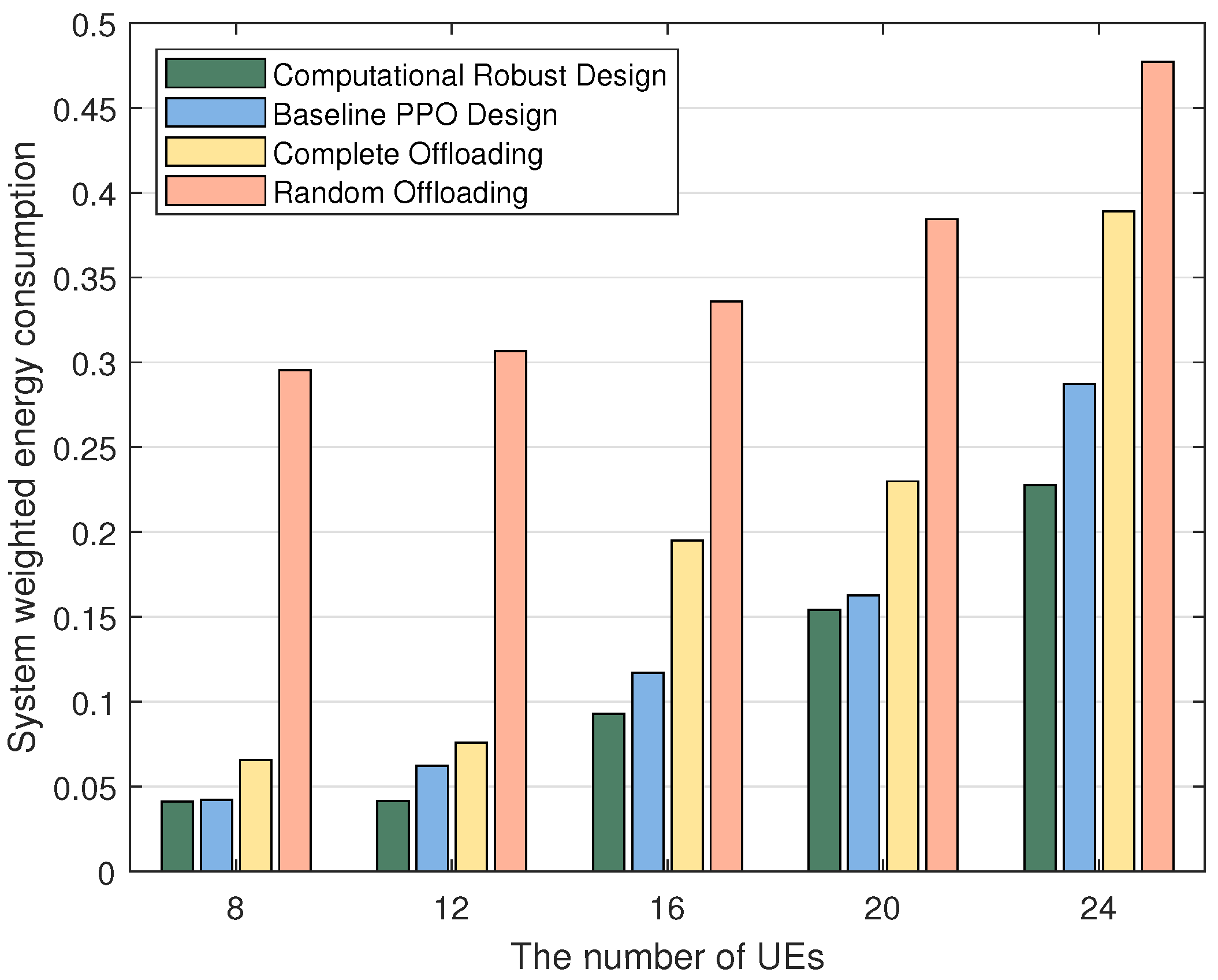
5. Simulation Results
5.1. Parameter Settings
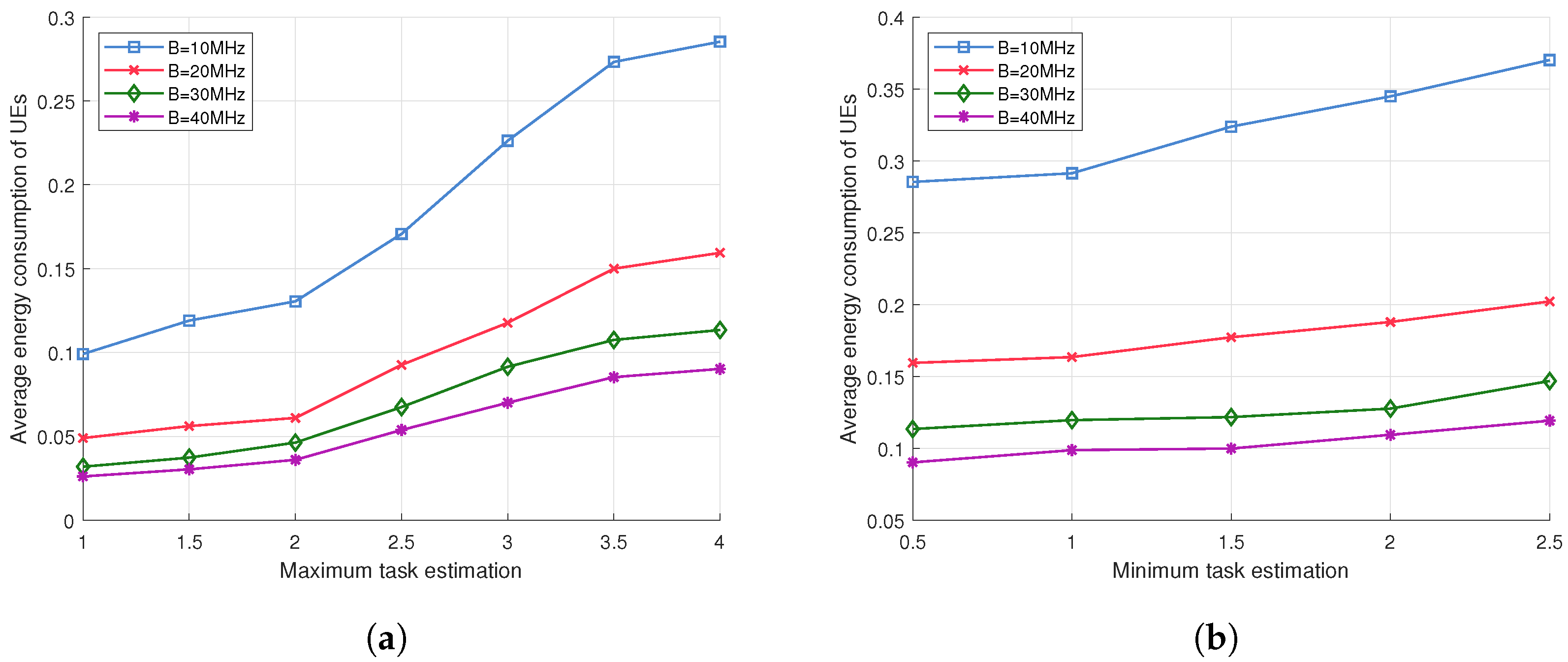
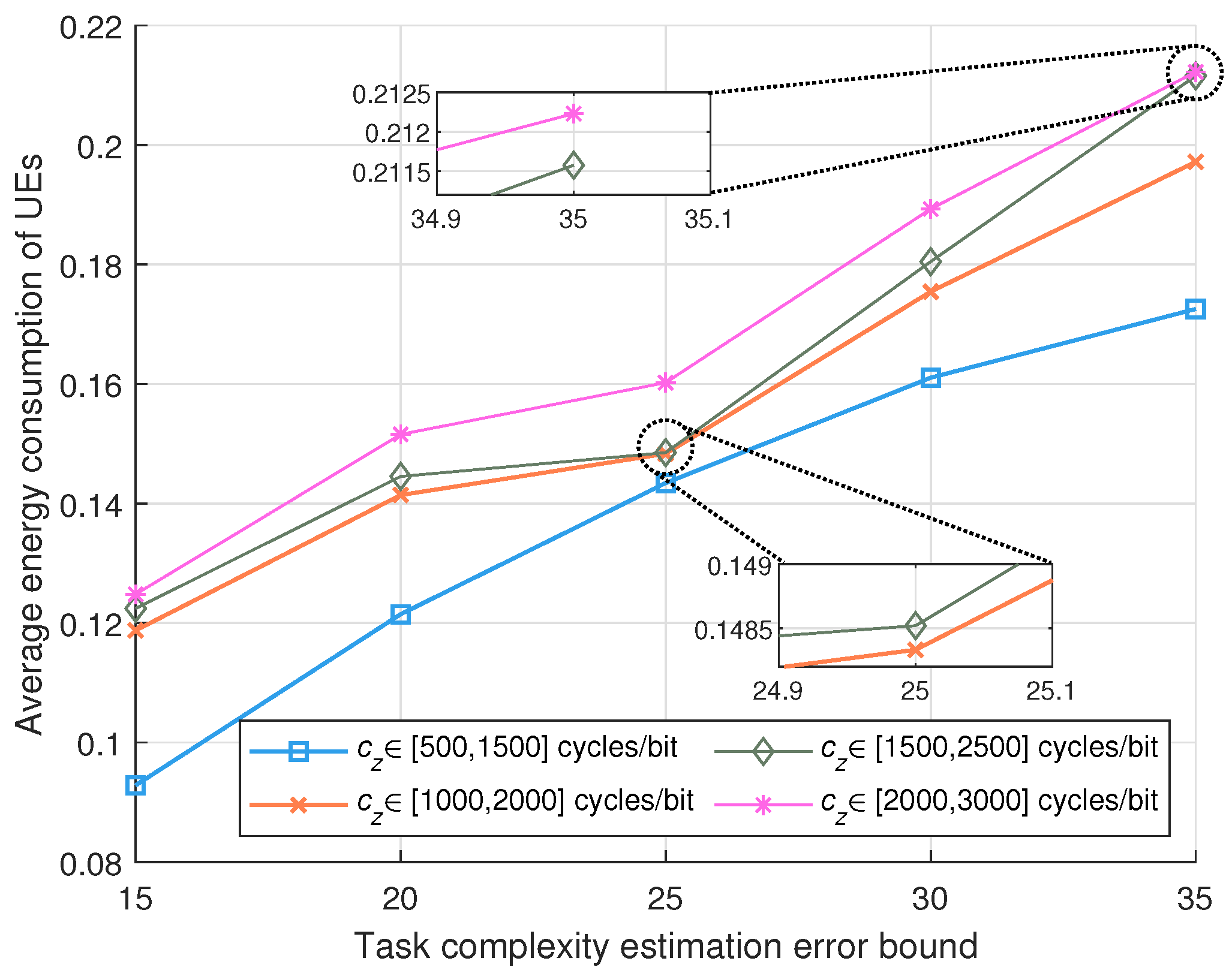
5.2. Simulation Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xing, H.; Zhu, G.; Liu, D.; Wen, H.; Huang, K.; Wu, K. Task-Oriented Integrated Sensing, Computation and Communication for Wireless Edge AI. IEEE Netw. 2023, 37, 135–144. [Google Scholar] [CrossRef]
- Ding, C.; Wang, J.B.; Zhang, H.; Lin, M.; Li, G.Y. Joint MIMO Precoding and Computation Resource Allocation for Dual-Function Radar and Communication Systems with Mobile Edge Computing. IEEE J. Sel. Areas Commun. 2022, 40, 2085–2102. [Google Scholar] [CrossRef]
- Spinelli, F.; Mancuso, V. Toward Enabled Industrial Verticals in 5G: A Survey on MEC-Based Approaches to Provisioning and Flexibility. IEEE Commun. Surv. Tutor. 2021, 23, 596–630. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Kamruzzaman, J. Quantum Particle Swarm Optimization for Task Offloading in Mobile Edge Computing. IEEE Trans. Ind. Inform. 2023, 19, 9113–9122. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and Resource Allocation with General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Feng, Z.; Wei, Z.; Chen, X.; Yang, H.; Zhang, Q.; Zhang, P. Joint Communication, Sensing, and Computation Enabled 6G Intelligent Machine System. IEEE Netw. 2021, 35, 34–42. [Google Scholar] [CrossRef]
- Liu, F.; Cui, Y.; Masouros, C.; Xu, J.; Han, T.X.; Eldar, Y.C.; Buzzi, S. Integrated Sensing and Communications: Toward Dual-Functional Wireless Networks for 6G and Beyond. IEEE J. Sel. Areas Commun. 2022, 40, 1728–1767. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Mob. Comput. 2022, 21, 1985–1997. [Google Scholar] [CrossRef]
- Li, B.; Yang, R.; Liu, L.; Wang, J.; Zhang, N.; Dong, M. Robust Computation Offloading and Trajectory Optimization for Multi-UAV-Assisted MEC: A Multiagent DRL Approach. IEEE Internet Things J. 2024, 11, 4775–4786. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, L.; Liu, J.; Kato, N. Smart Resource Allocation for Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1529–1541. [Google Scholar] [CrossRef]
- Chen, Y.; Chang, Z.; Min, G.; Mao, S.; Hämäläinen, T. Joint Optimization of Sensing and Computation for Status Upyear in Mobile Edge Computing Systems. IEEE Trans. Wirel. Commun. 2023, 22, 8230–8243. [Google Scholar] [CrossRef]
- Liu, P.; Zhu, G.; Wang, S.; Jiang, W.; Luo, W.; Poor, H.V.; Cui, S. Toward Ambient Intelligence: Federated Edge Learning with Task-Oriented Sensing, Computation, and Communication Integration. IEEE J. Sel. Top. Signal Process. 2023, 17, 158–172. [Google Scholar] [CrossRef]
- Fan, R.; Liang, B.; Zuo, S.; Hu, H.; Jiang, H.; Zhang, N. Robust Task Offloading and Resource Allocation in Mobile Edge Computing with Uncertain Distribution of Computation Burden. IEEE Trans. Commun. 2023, 71, 4283–4299. [Google Scholar] [CrossRef]
- Zhao, L.; Wu, D.; Zhou, L.; Qian, Y. Radio Resource Allocation for Integrated Sensing, Communication, and Computation Networks. IEEE Trans. Wirel. Commun. 2022, 21, 8675–8687. [Google Scholar] [CrossRef]
- Li, B.; Liu, W.; Xie, W.; Zhang, N.; Zhang, Y. Adaptive Digital Twin for UAV-Assisted Integrated Sensing, Communication, and Computation Networks. IEEE Trans. Green Commun. Netw. 2023, 7, 1996–2009. [Google Scholar] [CrossRef]
- Li, X.; Gong, Y.; Huang, K.; Niu, Z. Over-the-Air Integrated Sensing, Communication, and Computation in IoT Networks. IEEE Wirel. Commun. 2023, 30, 32–38. [Google Scholar] [CrossRef]
- Qi, Q.; Chen, X.; Khalili, A.; Zhong, C.; Zhang, Z.; Ng, D.W.K. Integrating Sensing, Computing, and Communication in 6G Wireless Networks: Design and Optimization. IEEE Trans. Commun. 2022, 70, 6212–6227. [Google Scholar] [CrossRef]
- Huang, N.; Wang, T.; Wu, Y.; Wu, Q.; Quek, T.Q.S. Integrated Sensing and Communication Assisted Mobile Edge Computing: An Energy-Efficient Design via Intelligent Reflecting Surface. IEEE Wirel. Commun. Lett. 2022, 11, 2085–2089. [Google Scholar] [CrossRef]
- Huang, N.; Dou, C.; Wu, Y.; Qian, L.; Lu, R. Energy-Efficient Integrated Sensing and Communication: A Multi-Access Edge Computing Design. IEEE Wirel. Commun. Lett. 2023, 12, 2053–2057. [Google Scholar] [CrossRef]
- Yamansavascilar, B.; Baktir, A.C.; Sonmez, C.; Ozgovde, A.; Ersoy, C. DeepEdge: A Deep Reinforcement Learning Based Task Orchestrator for Edge Computing. IEEE Trans. Netw. Sci. Eng. 2023, 10, 538–552. [Google Scholar] [CrossRef]
- Wang, Z.; Mu, X.; Liu, Y.; Xu, X.; Zhang, P. NOMA-Aided Joint Communication, Sensing, and Multi-Tier Computing Systems. IEEE J. Sel. Areas Commun. 2023, 41, 574–588. [Google Scholar] [CrossRef]
- Liu, C.; Yuan, W.; Li, S.; Liu, X.; Li, H.; Ng, D.W.K.; Li, Y. Learning-Based Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks. IEEE J. Sel. Areas Commun. 2022, 40, 2317–2334. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Computational Complexity |
|---|---|
| WMMMSE algorithm [21] | |
| LSTM algorithm [22] | |
| Proposed algorithm |
| Parameters | Values |
|---|---|
| Time slot | 1.0 s |
| Constant | |
| Radar duty cycle factor | 0.01 |
| Radar pulse duration | s |
| Predefined threshold | 15 |
| MEC maximum frequency | 8 GHz |
| UE maximum frequency | 1.5 GHz |
| UE maximum transmitting power | 0.4 W |
| Minimum radar estimation information rate | dB |
| Effective capacitance coefficients |
| Parameters | Values |
|---|---|
| Learning rate | |
| Maximum training set | |
| Length of each training set | |
| Discount factor | |
| GAE parameters |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, L.; Li, B.; Zhu, X. Robust Offloading for Edge Computing-Assisted Sensing and Communication Systems: A Deep Reinforcement Learning Approach. Sensors 2024, 24, 2489. https://doi.org/10.3390/s24082489
Shen L, Li B, Zhu X. Robust Offloading for Edge Computing-Assisted Sensing and Communication Systems: A Deep Reinforcement Learning Approach. Sensors. 2024; 24(8):2489. https://doi.org/10.3390/s24082489
Chicago/Turabian StyleShen, Li, Bin Li, and Xiaojie Zhu. 2024. "Robust Offloading for Edge Computing-Assisted Sensing and Communication Systems: A Deep Reinforcement Learning Approach" Sensors 24, no. 8: 2489. https://doi.org/10.3390/s24082489
APA StyleShen, L., Li, B., & Zhu, X. (2024). Robust Offloading for Edge Computing-Assisted Sensing and Communication Systems: A Deep Reinforcement Learning Approach. Sensors, 24(8), 2489. https://doi.org/10.3390/s24082489