
Non-Intrusive Load Identification Based on Retrainable Siamese Network



Abstract
:1. Introduction
- (1)
- (2)
- (3)
- In the model retraining process, only the BP network parameters need to be finetuned and the CNN remains unchanged. Therefore, it can be deployed on the embedded Linux system without PC and Server support.
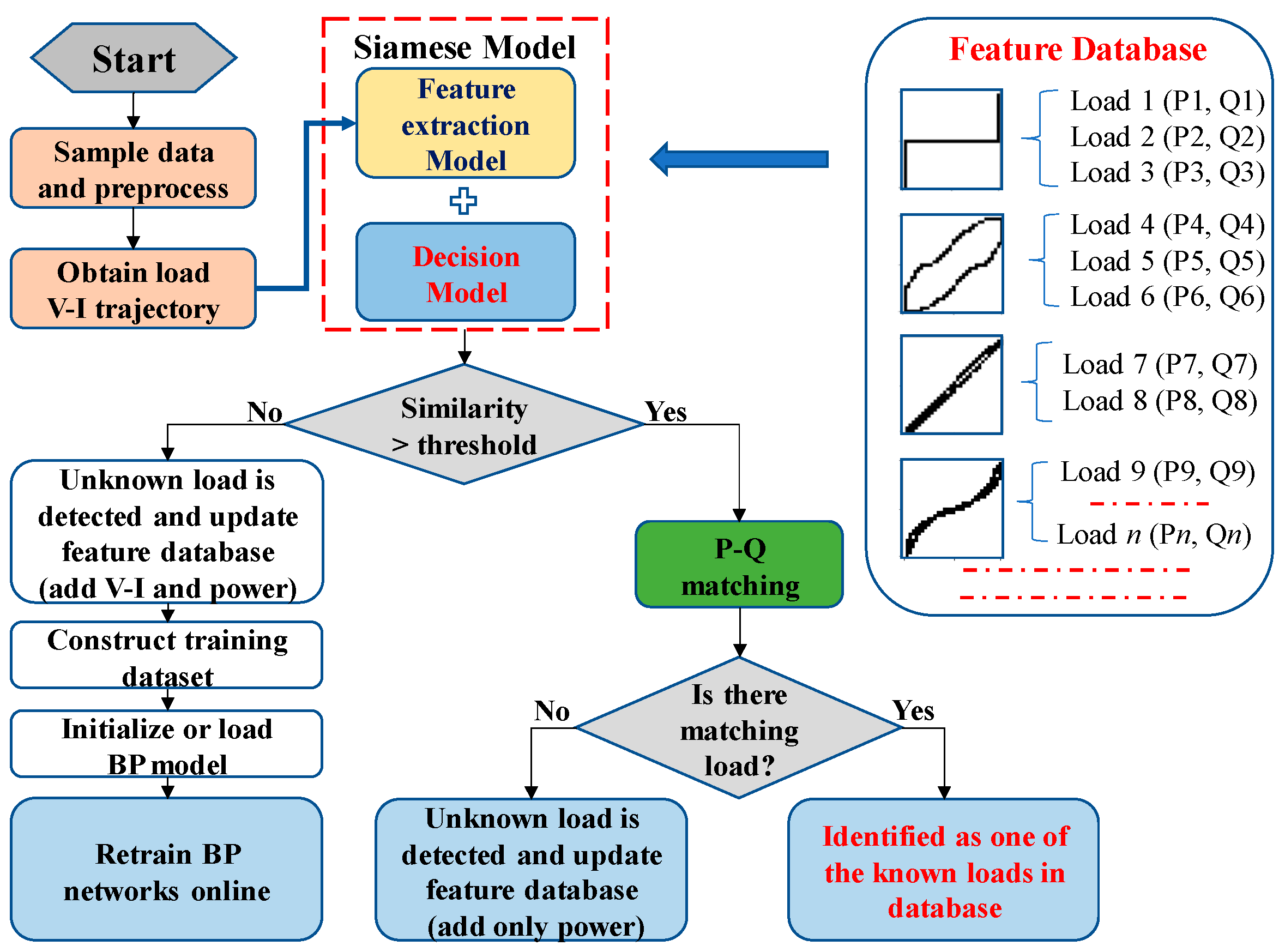
2. Principle of Load Identification Based on a Retrainable Siamese Network
2.1. Load Identification Process
- (1)
- Collect the steady-state voltage and current of the load using a high sampling rate with the minimum number of one cycle of data points;
- (2)
- Normalize the voltage and current and obtain the V-I trajectory image of the load;
- (3)
- Input the V-I trajectory image into the Siamese network to calculate the similarity with the known V-I trajectory in the feature database;
- (4)
- Compare the similarity with the preset threshold for preliminary identification.
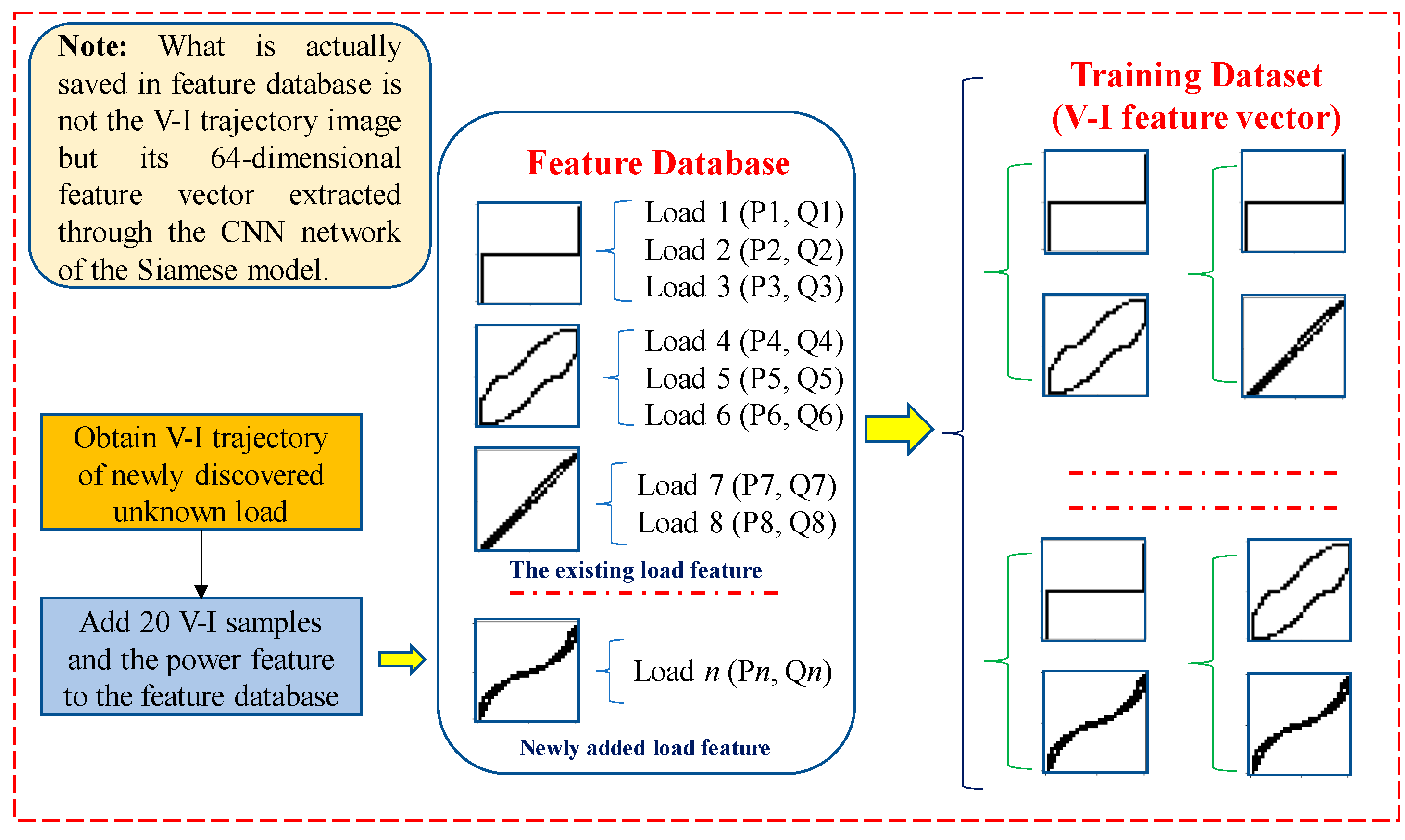
- When the similarity is less than the threshold, it will be recognized as an unknown load. The feature database is updated by adding both the V-I trajectory feature vector and the corresponding power feature. The training set is constructed of pairs of V-I trajectory feature vectors. Then, the two BP networks in the Siamese model are retrained in real-time.
- When the similarity exceeds the threshold, the power features are further analyzed through the length ratio and cosine distance between the power features. When similar power features exist, the load is identified as one of the known loads. Otherwise, when there are significant differences with the known power features, the load will be marked as new and the feature database is updated by adding only the power feature.
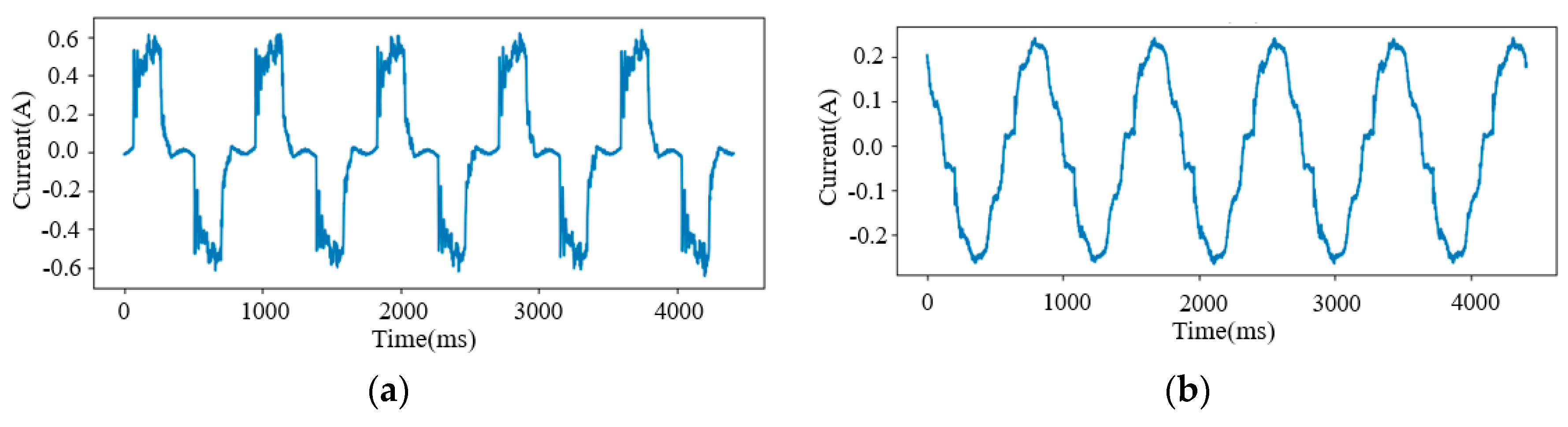
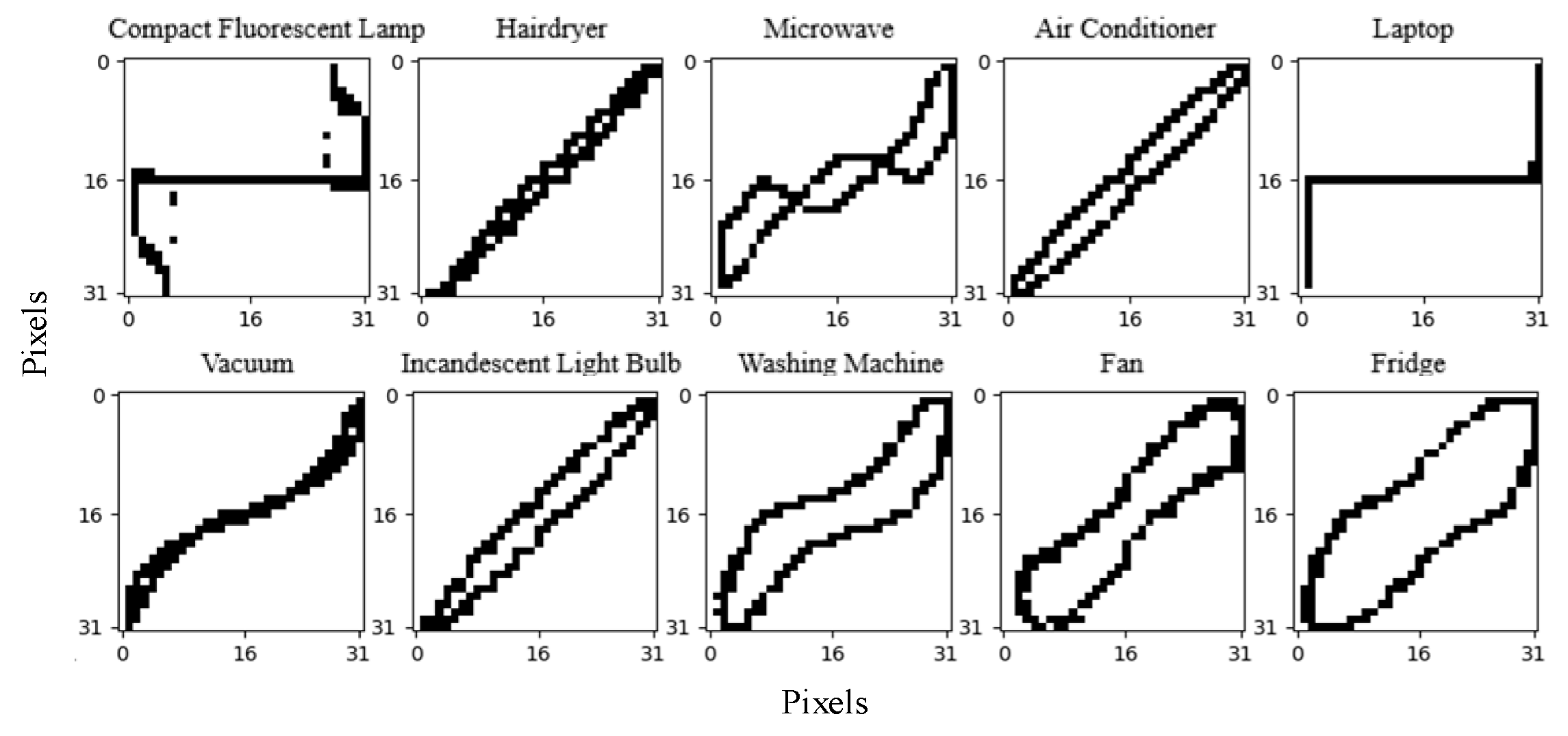
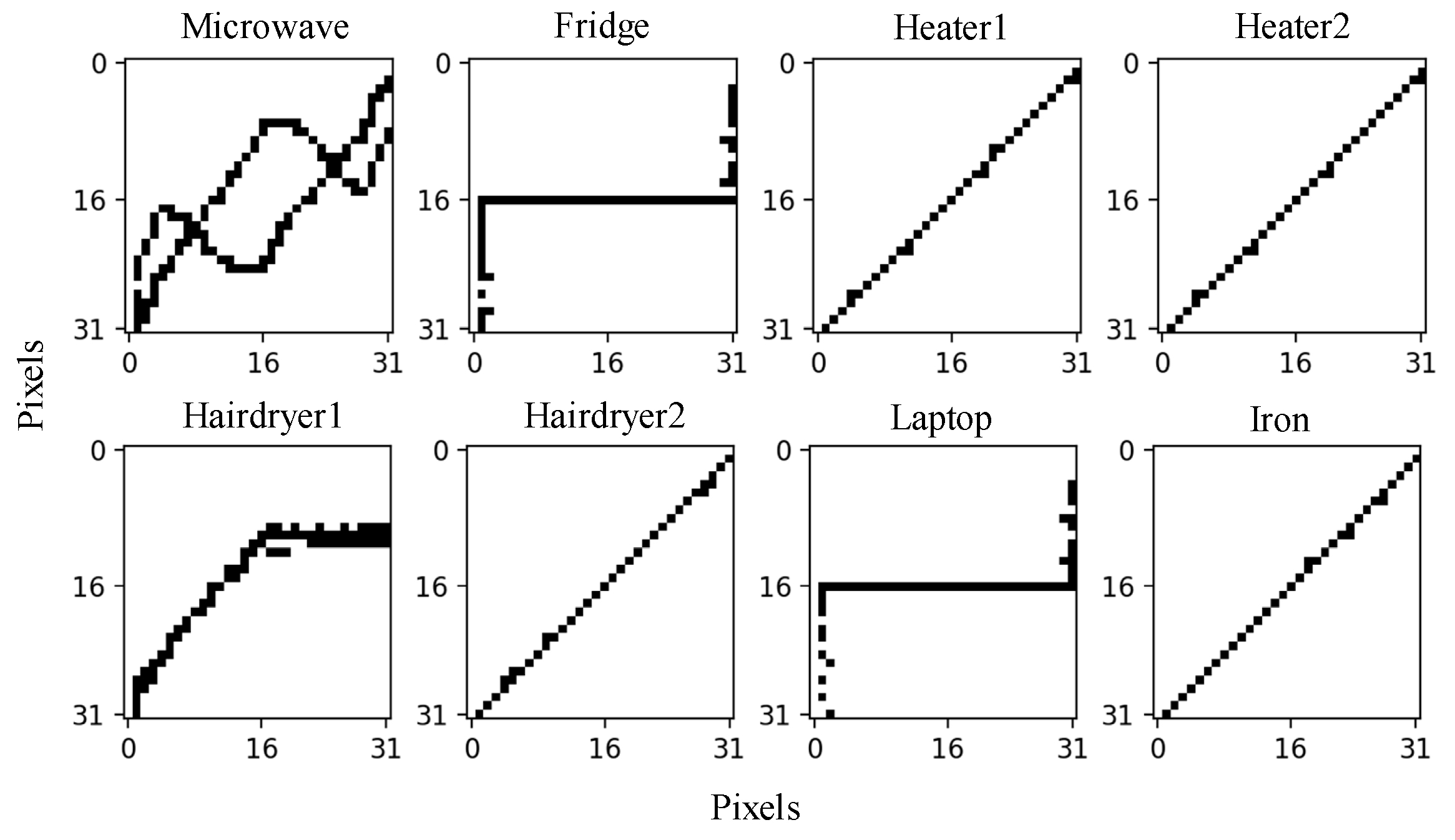
2.2. V-I Trajectory Image
2.3. Power Feature Matching
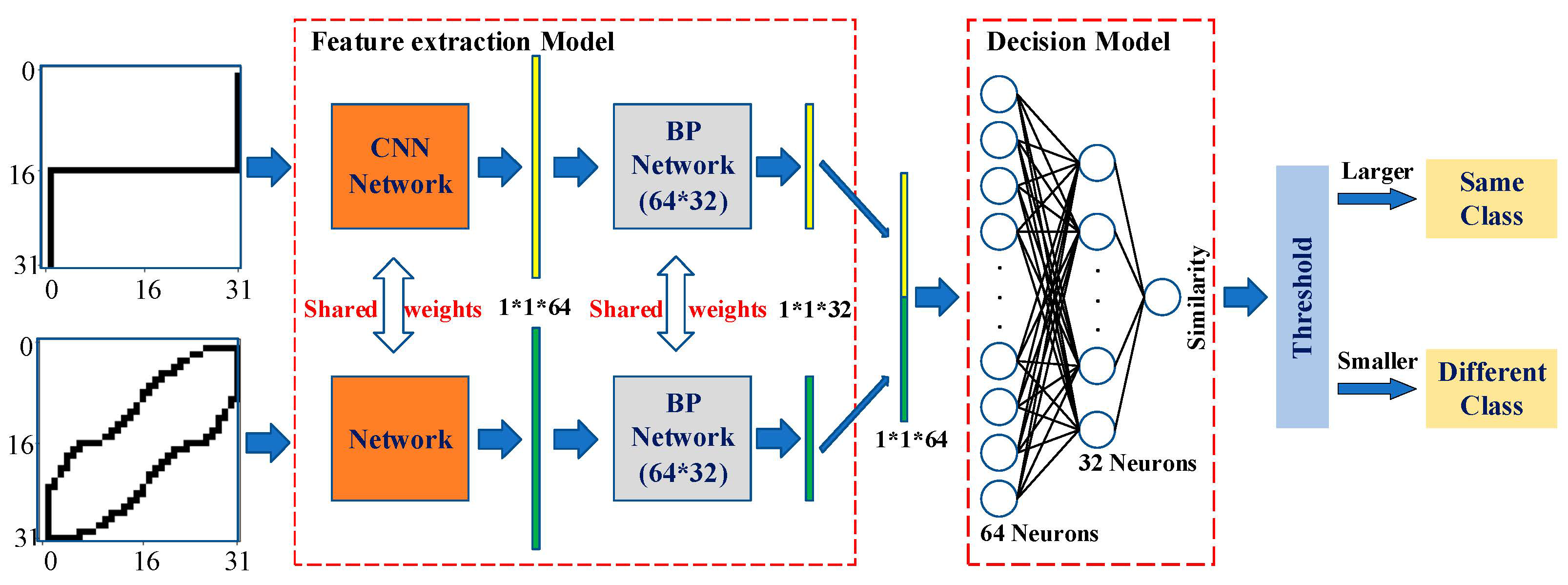
3. Retrainable Siamese Network
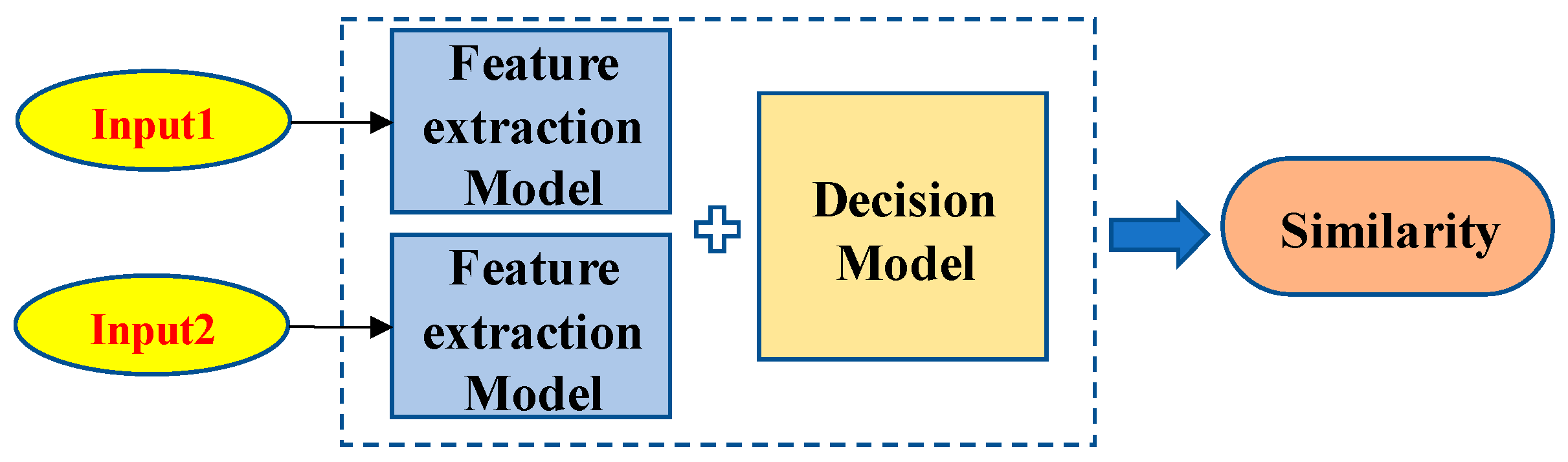
3.1. Introduction of the Siamese Network
3.2. Self-Adaption of the Siamese Network
4. Results
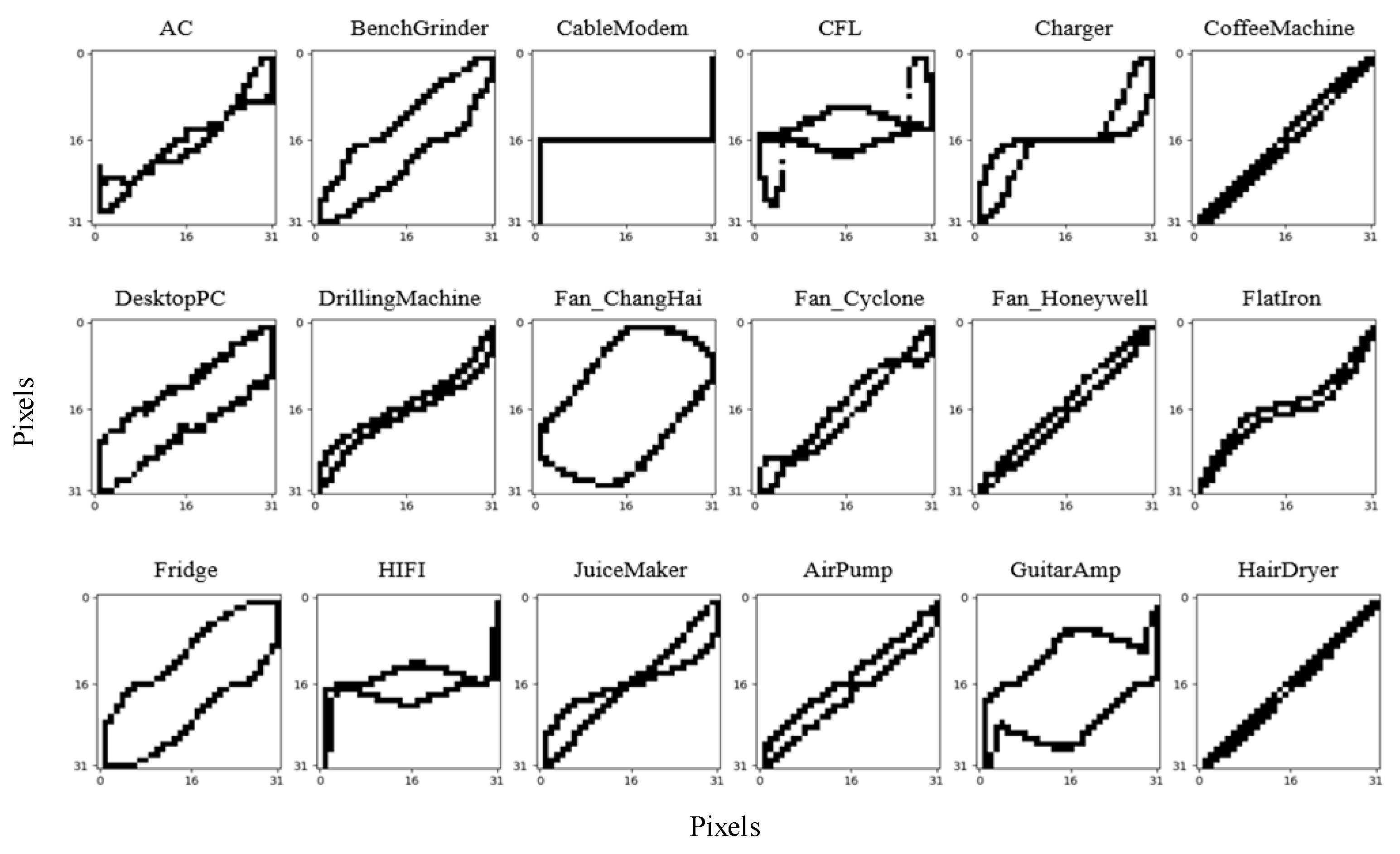
4.1. Experiment Results Using the WHITED Dataset
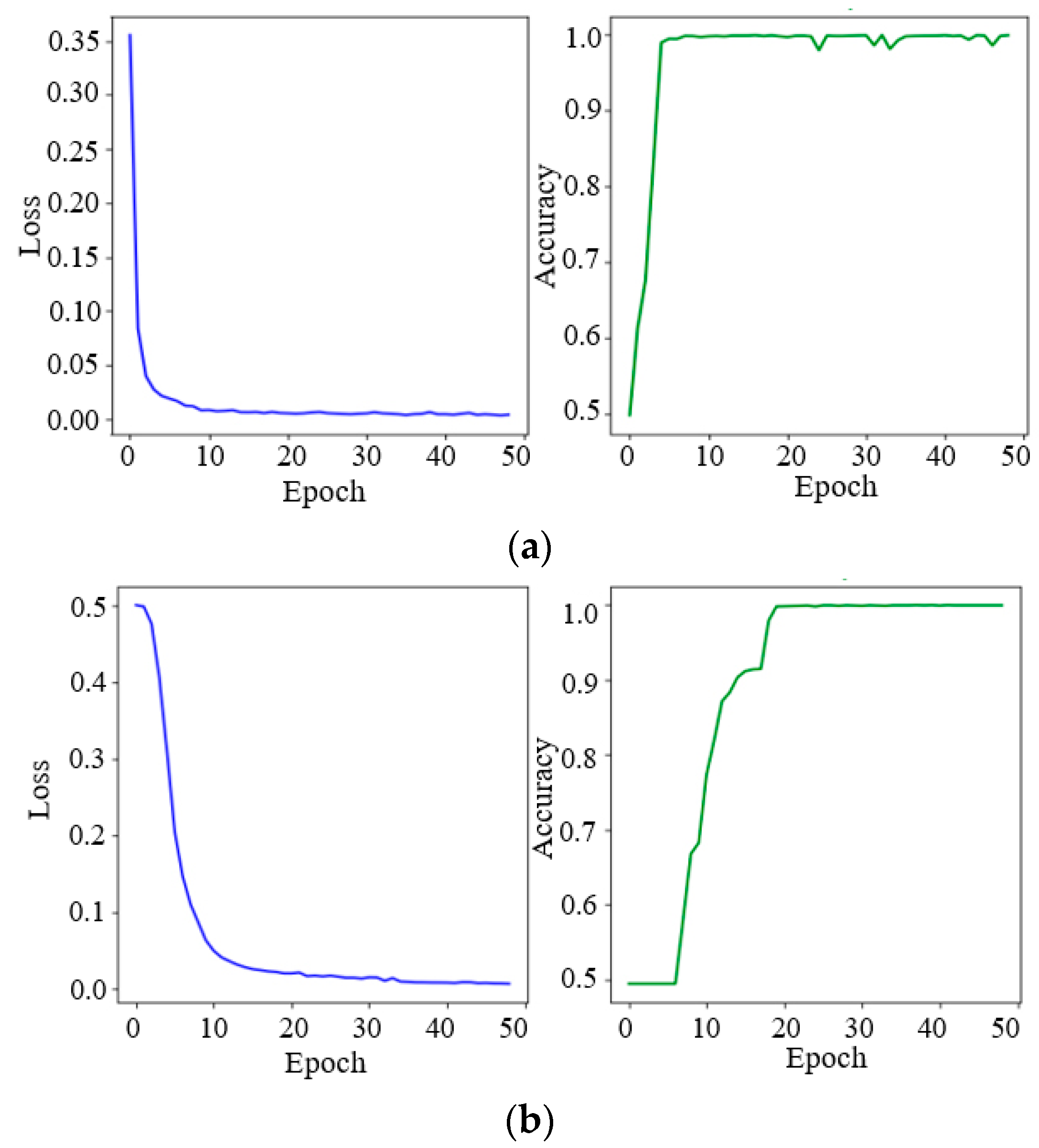
4.1.1. Siamese Network Pre-Training and Feature Database Construction
4.1.2. Retraining of the BP Networks
4.1.3. Identification Results
4.2. Experiment Result using the PLAID Database
4.3. Validation in the Real-House Environment Using the Embedded Linux System
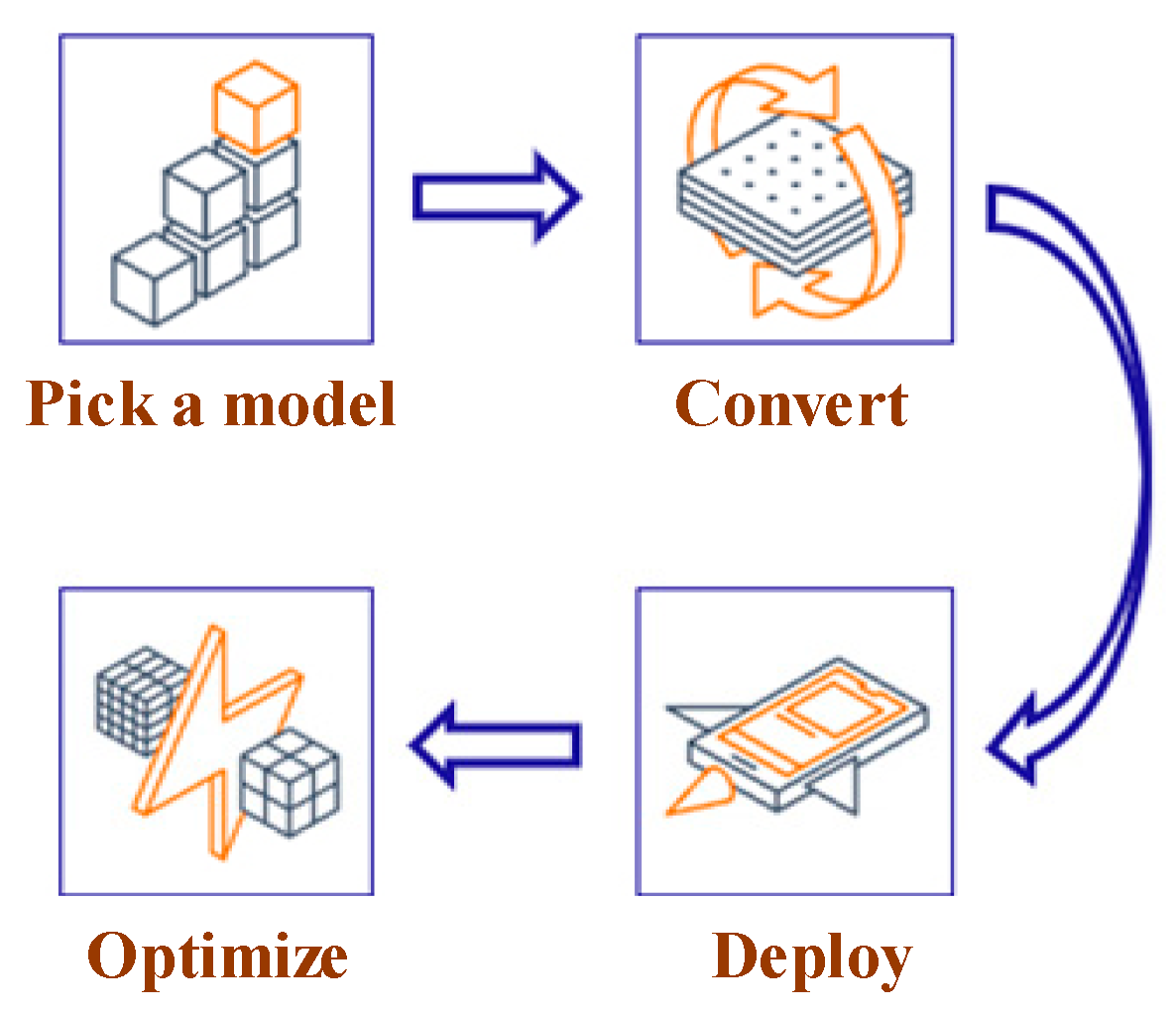
4.3.1. TensorFlow Lite
- Model selection: Select a new model or retrain an existing one;
- Conversion: Convert a TensorFlow model into a compressed flat buffer through the TensorFlow Lite Converter;
- Deployment: Load the compressed “.tflite” file into a mobile or embedded device;
- Optimization: Quantize by converting 32-bit floats to more efficient 8-bit integers or run on GPU.
4.3.2. Deployment of NILM Model
4.4. Comparison with Other Algorithms
5. Conclusions and Future Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qureshi, M.; Ghiaus, C.; Ahmad, N. A Blind Event-Based Learning Algorithm for Non-Intrusive Load Disaggregation. Int. J. Electr. Power Energy Syst. 2021, 129, 106834. [Google Scholar] [CrossRef]
- Himeur, Y.; Alsalemi, A.; Bensaali, F.; Amira, A. Smart Non-Intrusive Appliance Identification Using a Novel Local Power Histogramming Descriptor with an Improved k-Nearest Neighbors Classifier. Sustain. Cities Soc. 2021, 67, 102764. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; You, W. Non-Intrusive Load Monitoring by Voltage–Current Trajectory Enabled Transfer Learning. IEEE Trans. Smart Grid 2019, 10, 5609–5619. [Google Scholar] [CrossRef]
- Jia, Z.; Yang, L.; Zhang, Z.; Liu, H.; Kong, F. Sequence to Point Learning Based on Bidirectional Dilated Residual Network for Non-Intrusive Load Monitoring. Int. J. Electr. Power Energy Syst. 2021, 129, 106837. [Google Scholar] [CrossRef]
- Wang, C.; Wu, Z.; Peng, W.; Liu, W.; Xiong, L.; Wu, T.; Yu, L.; Zhang, H. Adaptive Modeling for Non-Intrusive Load Monitoring. Int. J. Electr. Power Energy Syst. 2022, 140, 107981. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Yang, D.; Gao, X.; Kong, L.; Pang, Y.; Zhou, B. An Event-Driven Convolutional Neural Architecture for Non-Intrusive Load Monitoring of Residential Appliance. IEEE Trans. Consum. Electron. 2020, 66, 173–182. [Google Scholar] [CrossRef]
- Drenker, S.; Kader, A. Nonintrusive Monitoring of Electric Loads. IEEE Comput. Appl. Power 1999, 12, 47–51. [Google Scholar] [CrossRef]
- Buddhahai, B.; Wongseree, W.; Rakkwamsuk, P. An Energy Prediction Approach for a Nonintrusive Load Monitoring in Home Appliances. IEEE Trans. Consum. Electron. 2020, 66, 96–105. [Google Scholar] [CrossRef]
- Luan, W.; Yang, F.; Zhao, B.; Liu, B. Industrial Load Disaggregation Based on Hidden Markov Models. Electr. Power Syst. Res. 2022, 210, 108086. [Google Scholar] [CrossRef]
- Gillis, J.M.; Morsi, W.G. Non-Intrusive Load Monitoring Using Semi-Supervised Machine Learning and Wavelet Design. IEEE Trans. Smart Grid 2017, 8, 2648–2655. [Google Scholar] [CrossRef]
- Yang, Y.; Zhong, J.; Li, W.; Gulliver, T.A.; Li, S. Semisupervised Multilabel Deep Learning Based Nonintrusive Load Monitoring in Smart Grids. IEEE Trans. Ind. Inform. 2020, 16, 6892–6902. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Wang, B.; Zhao, J.; Huang, J. A Practical Solution for Non-Intrusive Type II Load Monitoring Based on Deep Learning and Post-Processing. IEEE Trans. Smart Grid 2020, 11, 148–160. [Google Scholar] [CrossRef]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-Point Learning With Neural Networks for Non-Intrusive Load Monitoring. Proc. AAAI Conf. Artif. Intell. 2018, 32, 2604–2611. [Google Scholar] [CrossRef]
- Yang, W.; Pang, C.; Huang, J.; Zeng, X. Sequence-to-Point Learning Based on Temporal Convolutional Networks for Nonintrusive Load Monitoring. IEEE Trans. Instrum. Meas. 2021, 70, 2512910. [Google Scholar] [CrossRef]
- Xiong, C.; Cai, Z.; Liu, S.; Luo, J.; Tu, G. An Improved Sequence-to-Point Learning for Non-Intrusive Load Monitoring Based on Discrete Wavelet Transform. IEEE Trans. Instrum. Meas. 2023, 72, 2524516. [Google Scholar] [CrossRef]
- Varanasi, L.N.S.; Karri, S.P.K. Enhancing Non-Intrusive Load Monitoring with Channel Attention Guided Bi-Directional Temporal Convolutional Network for Sequence-to-Point Learning. Electr. Power Syst. Res. 2024, 228, 110088. [Google Scholar] [CrossRef]
- Le, T.-T.-H.; Heo, S.; Kim, H. Toward Load Identification Based on the Hilbert Transform and Sequence to Sequence Long Short-Term Memory. IEEE Trans. Smart Grid 2021, 12, 3252–3264. [Google Scholar] [CrossRef]
- Yu, H.; Pang, C.; Xuan, Y.; Chen, Y.; Zeng, X. Sequence-to-Sequence-Based Beta-VAE Combined With IECA Attention Mechanism for Energy Disaggregation Algorithm. IEEE Trans. Instrum. Meas. 2023, 72, 2530913. [Google Scholar] [CrossRef]
- Wang, A.L.; Chen, B.X.; Wang, C.G.; Hua, D. Non-Intrusive Load Monitoring Algorithm Based on Features of V–I Trajectory. Electr. Power Syst. Res. 2018, 157, 134–144. [Google Scholar] [CrossRef]
- De Baets, L.; Ruyssinck, J.; Develder, C.; Dhaene, T.; Deschrijver, D. Appliance Classification Using VI Trajectories and Convolutional Neural Networks. Energy Build. 2018, 158, 32–36. [Google Scholar] [CrossRef]
- Gao, J.; Giri, S.; Kara, E.C.; Bergés, M. PLAID: A Public Dataset of High-Resoultion Electrical Appliance Measurements for Load Identification Research: Demo Abstract. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings, Memphis, TN, USA, 3–6 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 198–199. [Google Scholar]
- Kahl, M.; Haq, A.; Kriechbaumer, T.; Jacobsen, H. WHITED-A Worldwide Household and Industry Transient Energy Data Set. In Proceedings of the 3rd International Workshop on Non-Intrusive Load Monitoring, Vancouver, BC, Canada, 14–15 May 2016. [Google Scholar]
- Jia, D.; Li, Y.; Du, Z.; Xu, J.; Yin, B. Non-Intrusive Load Identification Using Reconstructed Voltage–Current Images. IEEE Access 2021, 9, 77349–77358. [Google Scholar] [CrossRef]
- Houidi, S.; Fourer, D.; Auger, F.; Sethom, H.B.A.; Miègeville, L. Comparative Evaluation of Non-Intrusive Load Monitoring Methods Using Relevant Features and Transfer Learning. Energies 2021, 14, 2726. [Google Scholar] [CrossRef]
- Lu, J.; Zhao, R.; Liu, B.; Yu, Z.; Zhang, J.; Xu, Z. An Overview of Non-Intrusive Load Monitoring Based on V-I Trajectory Signature. Energies 2023, 16, 939. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, L.; Qiu, J.; Lu, J.; Wang, W. Unsupervised Domain Adaptation for Nonintrusive Load Monitoring Via Adversarial and Joint Adaptation Network. IEEE Trans. Ind. Inform. 2022, 18, 266–277. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, X.; Ng, W.W.Y.; Lai, C.S.; Lai, L.L. New Appliance Detection for Nonintrusive Load Monitoring. IEEE Trans. Ind. Inform. 2019, 15, 4819–4829. [Google Scholar] [CrossRef]
- Yin, B.; Zhao, L.; Huang, X.; Zhang, Y.; Du, Z. Research on Non-Intrusive Unknown Load Identification Technology Based on Deep Learning. Int. J. Electr. Power Energy Syst. 2021, 131, 107016. [Google Scholar] [CrossRef]
- De Baets, L.; Develder, C.; Dhaene, T.; Deschrijver, D. Detection of Unidentified Appliances in Non-Intrusive Load Monitoring Using Siamese Neural Networks. Int. J. Electr. Power Energy Syst. 2019, 104, 645–653. [Google Scholar] [CrossRef]
- Yu, M.; Wang, B.; Lu, L.; Bao, Z.; Qi, D. Non-Intrusive Adaptive Load Identification Based on Siamese Network. IEEE Access 2022, 10, 11564–11573. [Google Scholar] [CrossRef]
- Faustine, A.; Pereira, L.; Klemenjak, C. Adaptive Weighted Recurrence Graphs for Appliance Recognition in Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2021, 12, 398–406. [Google Scholar] [CrossRef]
- Kang, J.-S.; Yu, M.; Lu, L.; Wang, B.; Bao, Z. Adaptive Non-Intrusive Load Monitoring Based on Feature Fusion. IEEE Sens. J. 2022, 22, 6985–6994. [Google Scholar] [CrossRef]
- Tabanelli, E.; Brunelli, D.; Acquaviva, A.; Benini, L. Trimming Feature Extraction and Inference for MCU-Based Edge NILM: A Systematic Approach. IEEE Trans. Ind. Inform. 2022, 18, 943–952. [Google Scholar] [CrossRef]
- Hassan, T.; Javed, F.; Arshad, N. An Empirical Investigation of V-I Trajectory Based Load Signatures for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2014, 5, 870–878. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y. Dual-Path Siamese CNN for Hyperspectral Image Classification With Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2021, 18, 518–522. [Google Scholar] [CrossRef]
- Satyagama, P.; Widyantoro, D.H. Low-Resolution Face Recognition System Using Siamese Network. In Proceedings of the 2020 7th International Conference on Advance Informatics: Concepts, Theory and Applications (ICAICTA), Tokoname, Japan, 8–9 September 2020; pp. 1–6. [Google Scholar]
- Zhou, X.; Liang, W.; Shimizu, S.; Ma, J.; Jin, Q. Siamese Neural Network Based Few-Shot Learning for Anomaly Detection in Industrial Cyber-Physical Systems. IEEE Trans. Ind. Inform. 2021, 17, 5790–5798. [Google Scholar] [CrossRef]
- Fang, K.; Huang, Y.; Huang, Q.; Yang, S.; Li, Z.; Cheng, H. An Event Detection Approach Based on Improved CUSUM Algorithm and Kalman Filter. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October–1 November 2020; pp. 3400–3403. [Google Scholar]
- Lin, Y.-H.; Tsai, M.-S. An Advanced Home Energy Management System Facilitated by Nonintrusive Load Monitoring With Automated Multiobjective Power Scheduling. IEEE Trans. Smart Grid 2015, 6, 1839–1851. [Google Scholar] [CrossRef]
- Çimen, H.; Bazmohammadi, N.; Lashab, A.; Terriche, Y.; Vasquez, J.C.; Guerrero, J.M. An Online Energy Management System for AC/DC Residential Microgrids Supported by Non-Intrusive Load Monitoring. Appl. Energy 2022, 307, 118136. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Feature | Model | Real-Time Operation | Unknown Load Detection | Model Real-Time Updating | Computing Support from PC or Server in Operation |
|---|---|---|---|---|---|---|
| [10] | Power | HMM | Disable | Disable | Disable | Necessary |
| [14] | Power | Seq2point | Disable | Disable | Disable | Necessary |
| [13] | Weighted V-I image | CNN | Enable | Disable | Disable | Unnecessary |
| [16] | Reconstructed V-I image | CNN | Enable | Disable | Disable | Unnecessary |
| [3] | Colored V-I image | AlexNet | Enable | Disable | Disable | Necessary |
| [22] | Binary V-I image | Siamese Model | Enable | Enable | Disable | Unnecessary |
| [23] | Binary V-I image + Power | Siamese Model | Enable | Enable | Disable | Necessary |
| [25] | Binary V-I image + FFT | Autoencoder + TOPSIS | Enable | Enable | Disable | Unnecessary |
| [21] | Current | 1D-LeNet Siamese Model | Enable | Enable | Enable | Necessary |
| Proposed | Binary V-I image + Power | Retrainable Siamese Model | Enable | Enable | Enable | Unnecessary |
| Label | Name | (P, Q) | Label | Name | (P, Q) |
|---|---|---|---|---|---|
| Load 1 | AC | (330, 43) | Load 16 | Air Pump | (100, 18) |
| Load 2 | Bench Grinder | (370, 140) | Load 17 | Guitar Amp | (17, 20) |
| Load 3 | Cable Modem | (4, 2) | Load 18 | Hair Dryer | (1940, 135) |
| Load 4 | CFL | (13, 2) | Load 19 | Kitchen Hood | (110, 155) |
| Load 5 | Charger | (70, 17) | Load 20 | Iron | (1430, 110) |
| Load 6 | Coffee Machine | (790, 65) | Load 21 | Led Light | (35, 11) |
| Load 7 | Desktop PC | (100, 45) | Load 22 | Microwave | (1340, 270) |
| Load 8 | Drilling Machine | (310, 45) | Load 23 | Monitor | (55, 18) |
| Load 9 | Fan_ChingHai | (25, 40) | Load 24 | Power Supply | (12, 15) |
| Load 10 | Fan_Cyclone | (280, 42) | Load 25 | Sewing Machine | (150, 60) |
| Load 11 | Fan_Honeywell | (136, 15) | Load 26 | Vacuum Cleaner | (705, 60) |
| Load 12 | Flat Iron | (280, 30) | Load 27 | Rice Cooker | (330, 7) |
| Load 13 | Fridge | (560, 285) | Load 28 | Network Switch | (2, 0.5) |
| Load 14 | HIFI | (29, 17) | Load 29 | Laptop | (67, 20) |
| Load 15 | Juice Maker | (220, 45) | Load 30 | Water Pump | (450, 75) |
| Label | Unknown Load Detection | Without Retraining | With Retraining | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | ||
| Load 19 | 100% | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Load 20 | 100% | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Load 21 | 100% | 85.00% | 68.00% | 0.7556 | 97.96% | 96.00% | 0.9697 |
| Load 22 | 100% | 100.00% | 78.00% | 0.8764 | 100.00% | 96.00% | 0.9796 |
| Load 23 | 100% | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Load 24 | 100% | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Load 25 | 100% | 73.33% | 88.00% | 0.8000 | 96.08% | 98.00% | 0.9703 |
| Load 26 | 100% | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Load 27 | 100% | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Load 28 | 100% | 100.00% | 96.00% | 0.9796 | 100.00% | 100.00% | 1.0000 |
| Load 29 | 100% | 100.00% | 92.00% | 0.9583 | 100.00% | 100.00% | 1.0000 |
| Load 30 | 100% | 81.97% | 100.00% | 0.9009 | 96.15% | 100.00% | 0.9804 |
| Name | Without Retraining | With Retraining | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Compact Fluorescent Lamp | 95.92% | 94.00% | 0.9495 | 98.04% | 100.00% | 0.9901 |
| Hairdryer | 100.00% | 98.00% | 0.9899 | 100.00% | 98.00% | 0.9899 |
| Microwave | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Air Conditioner | 98.04% | 100.00% | 0.9901 | 100.00% | 100.00% | 1.0000 |
| Laptop | 94.12% | 96.00% | 0.9505 | 100.00% | 98.00% | 0.9899 |
| Vacuum | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Incandescent Light Bulb | 98.00% | 98.00% | 0.9800 | 98.04% | 100.00% | 0.9901 |
| Washing Machine | 86.67% | 78.00% | 0.8211 | 100.00% | 100.00% | 1.0000 |
| Fan | 100.00% | 96.00% | 0.9796 | 100.00% | 100.00% | 1.0000 |
| Fridge | 77.19% | 88.00% | 0.8224 | 100.00% | 100.00% | 1.0000 |
| Name | Active Power (W) | Reactive Power (Var) |
|---|---|---|
| Microwave | 566 | 100 |
| Fridge | 30 | 10 |
| Heater1 | 156 | 5 |
| Heater2 | 304 | 12 |
| Hairdryer1 | 156 | 5 |
| Hairdryer2 | 200 | 5 |
| Laptop | 16 | 10 |
| Iron | 605 | 14 |
| Name | Without Retraining | With Retraining | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Microwave | 100.00% | 70.00% | 0.8235 | 100.00% | 100.00% | 1.0000 |
| Fridge | 90.57% | 96.00% | 0.9320 | 92.45% | 98.00% | 0.9515 |
| Heater1 | 80.00% | 100.00% | 0.8889 | 100.00% | 100.00% | 1.0000 |
| Heater2 | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Hairdryer1 | 100.00% | 75.00% | 0.8571 | 100.00% | 100.00% | 1.0000 |
| Hairdryer2 | 100.00% | 100.00% | 1.0000 | 100.00% | 100.00% | 1.0000 |
| Laptop | 95.74% | 90.00% | 0.9278 | 97.87% | 92.00% | 0.9485 |
| Iron | 76.92% | 100.00% | 0.8696 | 100.00% | 100.00% | 1.0000 |
| Ref. | Feature | Model | Dataset | Accuracy (%) | Unknown Load Detection | Deployment Difficulty | |
|---|---|---|---|---|---|---|---|
| [21] | Binary V-I image | CNN | All loads in PLAID | 78.50 | 0.7760 | Disable | Easy |
| [3] | Colored V-I image | AlexNet | All loads in PLAID | 98.04 | 0.9540 | Disable | Difficult |
| [31] | Binary V-I image + Power | Siamese Model | House6 in PLAID | / | 0.9788 | Enable | Difficult |
| [29] | Current | 1D-LeNet Siamese Model | 6 loads in PLAID | 99.80 | / | Enable | Difficult |
| [30] | Binary V-I image | Siamese Model | 11 loads in PLAID | 99.40 | 0.8990 | Enable | Easy |
| [33] | Binary V-I image + FFT | Autoencoder + TOPSIS | 11 loads in PLAID | 97.60 | / | Enable | Easy |
| Pro-posed | Binary V-I + Power | Retrainable Siamese Model | 10 loads in PLAID | 99.60 | 0.9920 | Enable | Easy |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, L.; Kang, J.-S.; Meng, F.; Yu, M. Non-Intrusive Load Identification Based on Retrainable Siamese Network. Sensors 2024, 24, 2562. https://doi.org/10.3390/s24082562
Lu L, Kang J-S, Meng F, Yu M. Non-Intrusive Load Identification Based on Retrainable Siamese Network. Sensors. 2024; 24(8):2562. https://doi.org/10.3390/s24082562
Chicago/Turabian StyleLu, Lingxia, Ju-Song Kang, Fanju Meng, and Miao Yu. 2024. "Non-Intrusive Load Identification Based on Retrainable Siamese Network" Sensors 24, no. 8: 2562. https://doi.org/10.3390/s24082562
APA StyleLu, L., Kang, J. -S., Meng, F., & Yu, M. (2024). Non-Intrusive Load Identification Based on Retrainable Siamese Network. Sensors, 24(8), 2562. https://doi.org/10.3390/s24082562