1. Introduction
In real-world settings, anomalies are both ubiquitous and potentially detrimental, yet challenging to identify. Fraudulent activities pose significant threats to the robust functioning of society, not only in economic terms but also by adversely impacting societal trust and fairness. Anomaly detection, also referred to as fraud detection, is assuming an increasingly crucial role in contemporary society. Its applications range from detecting fake news [
1] to identifying fraudulent reviews [
2].
In academia, “anomaly” is commonly abstracted as a set of data that deviates from the majority [
3]. Despite the development of numerous techniques in recent years for uncovering outliers and anomalies in unstructured sets of multi-dimensional points, the scarcity of anomalous behavior, high labeling costs, and privacy protection policies result in a paucity of data samples labeled as anomalous [
3].
We observe that graphs in the current graph anomaly detection domain mainly exhibit the following three characteristics.
Nodes are Labeled as well as Featured. Nodes in graphs often possess both label and feature properties. Node labels can propagate and aggregate along the edges of the graph, while node features can propagate along the edges and undergo transformations through neural network layers. Both label and feature propagation are beneficial for predicting node behavior. The effective combination of these two propagation aspects warrants attention.
Edges Contain Rich Information. In the field of GAD, the topology and structure of the graph contain a wealth of information. The attributes and directions of edges imply that even in isomorphic graphs, there are multiple types of connections (i.e., edges) between different nodes. For instance, relationships between users may include transfer and recipient relationships, loan and borrower relationships, as well as familial relationships. This information can assist in better classification, thereby identifying anomalous nodes. However, this information is often overlooked by other methods.
The Proportion of Anomalous Data is Extremely Low. While fraud incidents do occur, the majority of users in reality are normal users. The proportion of fraudulent users is significantly smaller than that of normal users, making fraud detection a classic example of imbalanced data. In machine learning model training, achieving a relatively balanced distribution of various sample classes is crucial for optimal performance. When there is a substantial difference in the proportions of different classes, the trained model tends to exhibit characteristics more aligned with the majority class, thereby neglecting features associated with minority class samples.
The inherent suitability of graph structures for analyzing relationships and connectivity patterns in networks has propelled GAD to the forefront. GAD abstracts traditional streaming data into graph structures, where nodes represent entities and edges signify relationships between entities. The interconnected nodes form edges that convey structural information about the graph, information that can be stored using an adjacency matrix [
4]. GAD aims to detect anomalies by leveraging the structural information inherent in the network, combining it with classic anomaly detection approaches. Considering fraud scenarios, fraudulent activities often exhibit associations and collaboration. The connections between fraud groups are typically closer than those between normal users, and the behaviors demonstrate a certain level of similarity. This also explains why graph analysis can be employed to detect anomalous behaviors in practical scenarios. According to the different basic graph algorithms, GAD algorithms can be classified into several types, including community detection, feature discovery, pattern mining, and GCN. This paper focuses on the GCN-based GAD algorithm.
Due to divergent definitions of “anomaly” in academic and industrial contexts, coupled with the variability in identifying anomalous data across different scenarios, the precise characterization of what constitutes an “anomaly” proves challenging [
3]. This paper abstains from delving into the root cause behind the classification of specific data as anomalous or enumerating the features that render data anomalous. Instead, our focus remains exclusively on the handling of datasets with anomaly ground-truth. Leveraging information from node features, edge features, and graph structures, we seek to infer potential label values for unlabeled nodes based on existing positive and negative labels. The objective is to simplify the model into a semi-supervised learning classification task rooted in graph neural networks, and the main task is to determine whether a node on the graph is an anomaly or not. This classification approach is also often employed in GAD tasks [
5].
We propose a unified model capable of addressing the aforementioned three challenges in graphs to make full use of the information in the nodes and edges to improve the performance of the algorithm. The primary contributions of this paper include the following.
We analyzed the theoretical relationship between the feature convolution process of GCN and the label propagation process of LPA, demonstrating that using LPA as an auxiliary regularization term in the GCN loss function can train edge weights and thereby improve GCN performance. Building on this theoretical analysis, we introduced a learnable edge weight into GCN and trained it using LPA. This method modifies the convolution process of GCN, making full use of node labels.
Considering the heterogeneity of edges, we analyzed the impact of edge information on GAD tasks. Firstly, we embedded edge direction and attribute information to generate edge features. Then, we aggregated these edge features with node features to generate co-embedding. This method conducted feature extraction, fully utilizing the information on edges.
Based on the co-embedding, we designed separate trainable GCN weights for node features and co-embedding features, projecting them into different feature spaces, greatly enhancing the model’s generalization ability.
We conducted experiments on the publicly available DGraph [
6] dataset, selecting MLP, Node2Vec [
7], LPA [
8], GCN [
9], GAT [
10], GATv2 [
11], GraphSAGE [
12], and UniMP [
13] as baseline models, with AUC serving as the evaluation metric, which refers to the area under the ROC curve. The ROC (Receiver Operating Characteristic) curve is a graphical visualization that provides an intuitive representation of a model’s performance. As a numeric value, the AUC can directly and intuitively exhibit the goodness or poorness of a model’s performance. The results indicate that our proposed method outperforms the baselines in terms of AUC. Our model proves feasible in addressing GAD tasks, providing valuable insights for applications in scenarios with scarce data.
The remaining sections of this paper are organized as follows.
Section 2 discusses related work in the field of anomaly detection.
Section 3 defines the mathematical model of the problem, analyzing the theoretical connection between GCN’s convolution on node features and LPA’s propagation on node labels, providing a mathematical basis for incorporating node labels into the GCN model.
Section 4 introduces our GCN-based GAD model, which is achieved through three enhancements to the GCN network.
Section 5 presents experimental results on public datasets, comparing the performance with baseline models, indicating that our method exhibits the best AUC performance on datasets with extremely low proportions of anomalous nodes. Finally, in
Section 6, we summarize the key contributions of this paper, as well as directions for future improvement.
3. Problem Formulation
We start with some notation. Assume that there is a graph, directed or undirected, , in which denote the sets of subjects to be detected. Each node has a P-dimensional feature, the i-th node’s feature is represented by . The arrangement of all features in a row by node orders the results in the feature matrix . is the binary adjacency matrix, the -th entry of A means whether there is an edge from to , and vice versa. Number the elements of A from the first row to the n-th row as ; therefore, A can be flattened into a two-dimensional array , called the edge index matrix, where the first row represents the source node and the second row represents the target node. c is the number of non-zero elements in the matrix A, as well as the number of edges in the graph. Partition A into two triangular matrices, and . For an undirected graph, the first elements of , correspond to the ith non-zero element in ; the last elements of correspond to the i-th non-zero element in . D is the diagonal degree matrix, and is the normalized adjacency matrix.
For graph
G, each edge comprises two elements: edge direction and attribution. Matrices
E and
Z, are organized based on the corresponding order of edges. That is to say,
E and
Z shares the same topology as
. The matrix
stores the directions of the edges, where 0 and 1 represent incoming edges and outgoing edges. The matrix
stores the attributes of the edges, where different values of element
represent different attributes of the edges.
Figure 1 shows the process of mapping the adjacency matrix
A to the edge index matrix
, as well as the construction of the edge direction matrix
E and the edge attribution matrix
Z. In (a), the first non-zero element in
A is read, which is located in the first row and third column. Therefore, it represents that the corresponding edge has a source node of index 1 and a target node of index 3. Consequently, the first column of the edge index matrix
, denoted as
, has 1 in the row above (representing the source node) and 3 in the row below (representing the target node). For the edge direction matrix, since this element is located in the upper triangular matrix
, the first element of the edge direction matrix
is 0, indicating an incoming edge. The first element of the edge attribution matrix
stores attribute 3 of this edge. Following this procedure, we iterate through the other non-zero elements in
A to construct
,
E, and
Z.
We can transform the directed graph G into an undirected graph through a simple symmetric operation. This involves processing the elements in matrices A with the transformation
Consequently, A becomes symmetric matrices.
In GAD tasks, the node set V is divided into a disjoint set of unlabeled nodes and labeled nodes, while only the first m nodes have labels from a label set . Here, 1 represents normal nodes, and 2 represents anomalous nodes. The label is stored by a one-hot-encoding matrix .
Finally, V is divided into three sets in proportion: training set , validation set , and test set . Our objective is to learn the features of nodes with labels, propagate their labels, and then infer the labels of the remaining nodes, given G, X, Y. Training is performed on , validation is conducted on , and testing is carried out on .
Table 2 summarizes the symbols used in this paper along with their corresponding meanings.
3.1. Label Propagation Algorithm
LPA is based on the assumption that two connected nodes are correlated because of the homophily and influence. LPA utilizes node labels as its input.
We construct a one-hot-encoding label matrix
to store labels. The
i-th row
stores the predicted label of node
after
k times label propagation. The label matrix
is initialized with the rule
. In the label propagation process during the
k-th iteration, all nodes propagate their labels to neighboring nodes with Equation (
1). From the perspective of nodes, node
will choose the community of its neighbor with the highest membership count as its new community:
Labels are propagated from each other nodes through a normalized adjacency matrix
. Subsequently, all nodes are reset back to their initial labels
, before proceeding to the
-th iteration:
LPA is an iterative computation process and does not guarantee convergence. Approximately five iterations are often sufficient to achieve convergence [
8], striking a balance between accuracy and performance. This will be the chosen number of iterations in our study. Consequently, for node
v, the probability of category
l is calculated as:
where
represents the edge from
v to its neighbor
u.
Figure 2 illustrates an LPA process executed on an unweighted, undirected graph.
In case of an undirected graph, the final representation of node i is the weighted average of its neighboring nodes , represented by .
3.2. Graph Convolutional Neural Networks
GCN [
9] is one of the most popular GAD models based on the Laplacian smoothing assumption. GCN utilizes node features as its input. In general, GCN employs a sum aggregator as an aggregation function, the discussions in this paper are based on it. We begin our derivation from the spatial representation of GCN. (The connection between LPA and GCN is observed in their spatial representations, both of which have the form of
. The original derivation of GCN starts from the spectral domain of graph convolution, and the spatial representation of GCN is an approximation using Weisfeiler-Lehman on the spectral domain of graph convolution. However, for LPA, the original paper directly provides a spatial representation without a spectral domain expression. Reference [
34] introduces energy to represent information propagation and then considers energy Laplacian, but its form differs significantly from the spectral domain expression of GCN.)
The feature propagation scheme of GCN in layer
l can be formulaed as:
where
is an non-linear activation function,
denotes the GCN trainable weight in the
l-th layer, and
is the
l-th layer representations of nodes with
for the input layer. To avoid neglecting the node’s own features, self-loops are added when updating the node itself. This involves combining the node’s own features with the features of its neighbors during the node update process. The normalized adjacency matrix will be
, where
, and
is the diagonal degree matrix for
with entries
. Of particular note is the adjacency matrix
, which here remains fixed, and depends on the topological structure of the constructed graph. Meanwhile, the weight
mentioned is the trainable weight of GCN, which is different from our learnable edge weight.
By stacking GCN, features for nodes in an
l-dimensional space can be obtained. In GAD tasks, the final layer of GCN is set to an output dimension of 2, allowing for the classification of all nodes into normal/abnormal binary categories. Generally, stacking two layers of GCN already yields satisfactory results [
9], and this will be the number of GCN layers used in this paper. At this point, the features of nodes after two layers of GCN are represented as:
Similar to LPA, in the case of an undirected graph and sum aggregator, the final representation of a node i is the weighted sum of its neighboring nodes , represented by .
3.3. Relationship between LPA and GCN
According to analysis before, on the label side
L, LPA can propagate and aggregate node labels along edges; along feature side
V, GCN can convolute and transform node features along edges. We can also observe that Equations (
1) and
4 share similarities in their forms. In this section, we attempt to answer two questions: What is the relationship between the label propagation of LPA and the feature convolution of GCN? Why can LPA serve as edge weights for training GCN?
Consider two nodes
and
in a graph;
is unlabeled while
is labeled. We study the relationship between LPA and GCN from the perspective of label influence and feature influence. Especially, if the initial label (feature) of
changes, how does the output label (feature) of
change. The label (feature) influence can be measured by the gradient (Jacobian) of the output label (feature) of
with respect to the initial label (feature) of
[
35,
36]. The label influence of
on
after
k iterations of LPA is:
Due to the iterative nature of the LPA algorithm, the influence of
on
accumulates, and can eventually be expressed as:
On the other hand, denote
as the
k-th layer embedding of
in GCN, and
represents the initial embedding of
. The feature influence of
on
after
k-layers of GCN is the L1-norm of the expected Jacobian matrix [
30], as:
where the expectation is taken under the transformation matrix
. The feature influence should be normalized as:
Assume that the ReLU function serves as the activation function
of GCN, and
denotes the fraction of unlabeled nodes. Consequently, the relationship between the label propagation of LPA and the feature convolution of GCN can be concluded, which can be expressed as:
The details of the proof for Equation (
10) can be found in Reference [
30]. With this, the first question posed in this section is answered: the relationship between label propagation and feature convolution is that if the label of node
has a sufficiently large influence on the label of node
, then the initial features of node
will also have an equally large impact on the output features of node
. In other words, the influence of all nodes labeled as
c on the label of node
, i.e.,
is proportional to the probability of node
being classified as
c by LPA as Equation (
3), i.e.,
From the above derivation, we can conclude that label influence can serve as a substitute for feature influence, which is the answer to the second question. This provides a theoretical basis for us to use LPA to assist in training edge weights for GCN and to establish a GCN model where edge weights are learnable.
4. Our Unified GCN-Based GAD Model
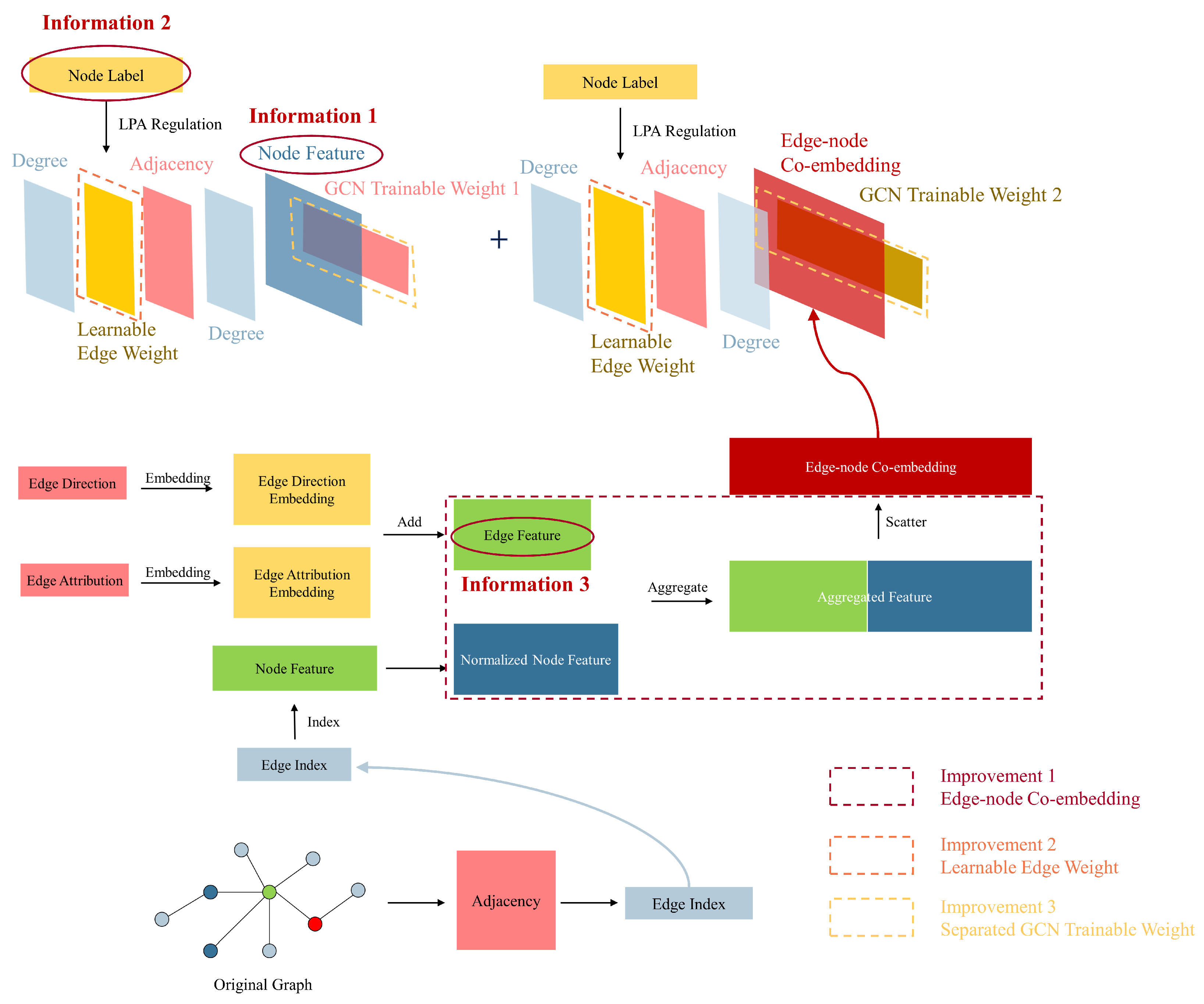
This section will introduce our unified GCN-based GAD model, primarily consisting of three clever enhancements built upon the GCN network: learnable edge weights, edge-node co-embedding, and separate trainable GCN weight. Learnable edge weights introduce node label information through LPA, edge-node co-embedding incorporates information from edges, and separate trainable GCN weights enhance the model’s expressive ability. We aim to leverage the improvements mentioned above to fully utilize node feature information, node label information, and edge information in the GAD graph, thereby enhancing the algorithm’s performance in scenarios with extremely low proportions of anomalous data.
Figure 3 illustrates the overall architecture of our unified GCN-based GAD model. In contrast,
Figure 4 illustrates the structure of a classical GCN network.
4.1. Learnable Edge Weight
To ensure narrative coherence, we first introduce the concept of learnable edge weights.
Building upon traditional GCN networks, as in Equation (
4), a learnable edge weight parameter
is introduced. With this addition, the GCN network can be rewritten as:
where
represents the edge weight parameter for layer
l, ∘ is the symbol of the Hadamard product. It is important to note that the matrix
in the equation is constant and solely dependent on the adjacency relations of the input nodes, with its values remaining unchanged throughout the training process.
represents the weights of the graph neural network (not our learnable edge weight).
Figure 5 illustrates our first improvement, which is introducing node label information by adding learnable edge weights. The number of columns in the GCN trainable weight layer, denoted as C, is variable. It is set to 2 in the final GCN layer (meeting the binary classification requirements of our GAD task), while in other layers, it is set to the number of hidden units.
The next question becomes how to train the weight matrix
to optimize its performance. Combining Equations (
11) and (
12), we can conclude that when the loss function of LPA
is minimized, the optimal edge weight
is achieved, as:
Cross entropy can measure the distance between predicted values
and ground truth
. Therefore, the above expression can be rewritten as:
where
J is the cross entropy loss.
As a GAD task, as analyzed in
Section 1, fraudulent activities exhibit correlations and organizational characteristics. Fraudulent groups often have close connections, and their behaviors show certain similarities. This implies that neighboring nodes in the graph often have the same labels, and their feature vectors are also similar (as the node feature vectors in the GAD task are derived from real user behavior). Given that neighboring nodes have similar labels and feature vectors, cross entropy can effectively encourage adjacent nodes to be similar, learning an effective mapping from feature vectors to labels. Therefore, the loss function for traditional GCN is defined as follows: cross entropy is also used to compute the distance, and the loss of predicted labels by GCN
minimized to learn the optimal transformation matrix
in the GCN:
The final question is how to determine the loss function for the unified model. For a graph semi-supervised learning task, we can utilize both node features and graph structure information. Therefore, we can optimize both loss functions together and incorporate L2 regularization [
9]:
where
represents the loss function based on labeled data,
represents the loss function based on graph structure information,
is the L2 regularizer, and
and
are hyperparameters that respectively adjust the relative importance of
and
. Data loss
considers the distance between the predicted values and the ground truth, which is the supervised loss. As a regularization penalty term,
only considers the loss induced by the weight coefficients
.
As per
Section 3.3, it is evident that LPA has the ability to replace GCN in training edge weights. Therefore, the loss of LPA (Equation (
15)) can replace the regularization penalty term
in Equation (
17) for training, thereby updating
W (Equation (
13)), which is the proposed learnable edge weight. The data loss in Equation (
17) is composed of the loss of traditional GCN (Equation (
16)). Ultimately, the loss function can be written as:
where
m is the number of labeled nodes in the graph. The first term corresponds to the segment of GCN that learns the edge weights
W and the trainable matrix
. Meanwhile, the second term corresponds to the label propagation segment, which can be seen as imposing constraints on the edge weights
W. The second term can be viewed as a regularization on
W to assist GCN in learning edge weights.
The above process is implemented using Algorithm 1. First, we initialize a trainable edge weight matrix
as a matrix of ones (line 2). Then, we utilize GCN to perform feature convolution, setting the output dimension of the last GCN layer to 2 for binary classification, obtaining the GCN’s label predictions
(lines 4–8). The computation of LPA is similar to GCN, resulting in the LPA’s label predictions
(lines 9–12). Subsequently, the cross-entropy losses between
and ground truth
y are calculated, as well as
and
y, to obtain the total loss
(line 13). Finally, the GCN training weights
and the learnable edge weight
W are updated using gradient descent.
| Algorithm 1 Learnable edge weight. |
- Input:
Graph ; adjacency matrix A; label matrix Y; degree matrix D; number of GCN layers L; number of LPA iterations K; square matrix W, with the size equal to the number of edges in E, where all elements are ones.
- Output:
Predicted abnormal nodes . - 1:
for number of edges in E do - 2:
Set to 1 - 3:
end for - 4:
for
L
do - 5:
- 6:
GCN convolution with Equation ( 4); - 7:
end for - 8:
Set output dimension of GCN to 2; - 9:
for
K
do - 10:
- 11:
LPA propagation with Equations ( 1) and ( 2); - 12:
end for - 13:
Calculated loss with Equation ( 18); - 14:
Backpropagation; - 15:
Update and W - 16:
return
|
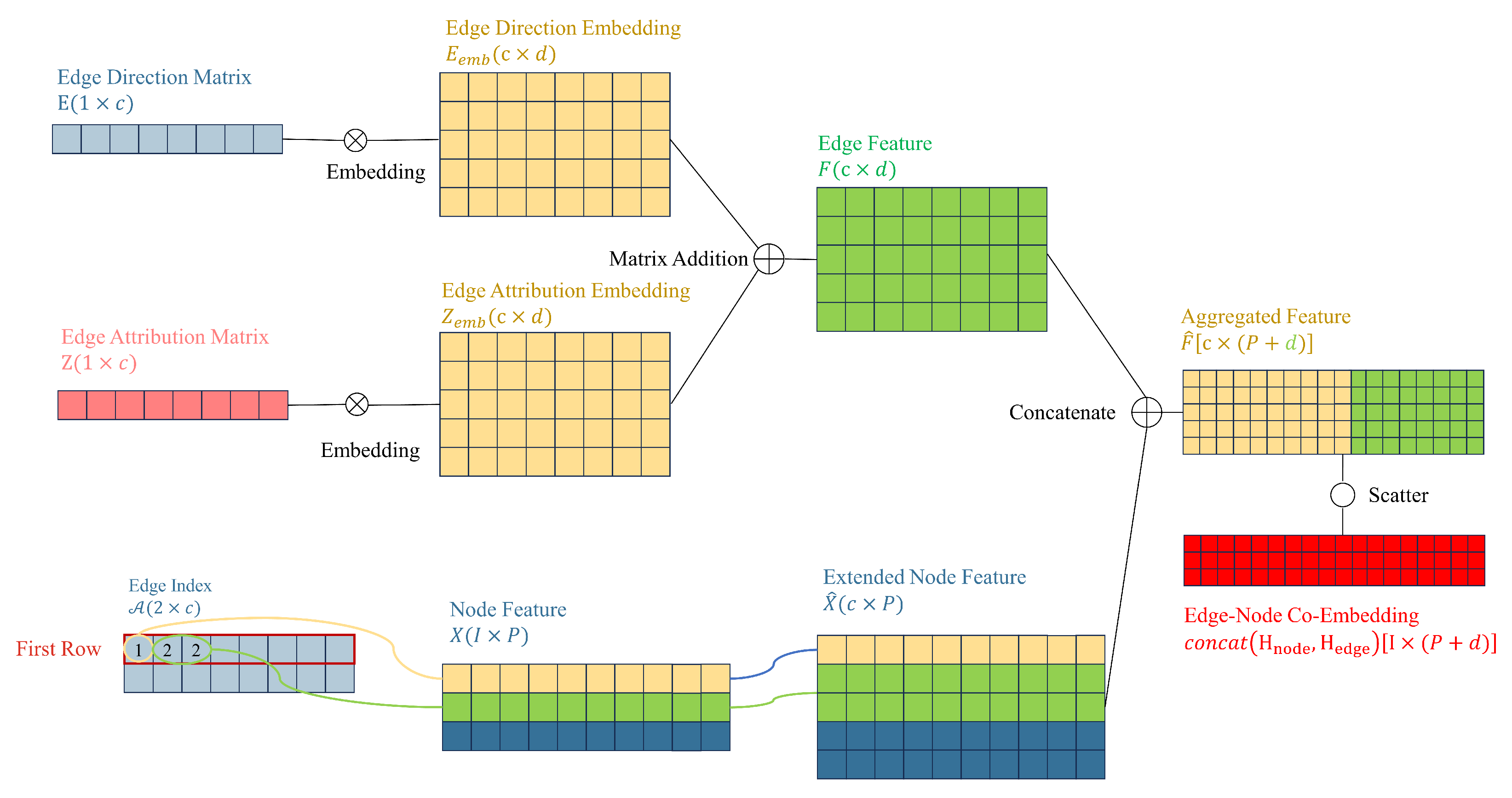
4.2. Co-Embedding of Edge and Node Features
This section will focus on constructing edge embeddings and aggregating them with node embeddings. The amount of information contained in
H directly determines the feature influence of a node on its neighboring nodes (as described in Equation (
9)). We start by considering increasing the information contained in
H. By adding the embeddings of edge direction and properties and generating edge features, we introduce a method to aggregate node features and edge features into a co-embedding feature.
As discussed in
Section 3, each edge consists of two elements: edge direction and attribution. Reiterating the definition provided, matrix
stores the direction of the edges, and matrix
stores the attribution of the edges.
Once the edge direction and edge attributes are defined as matrices, they can be aggregated using an additive approach for propagation [
37]. Although this simple aggregation calculation is computationally efficient, it fails to capture dependencies between different relationships and interactions between node and edge features [
38].
To ensure uniform dimensions between node feature matrices and edge feature matrices, while also reflecting the relationship between node and edge features, incorporating edge features into node features is needed. This involves performing aggregation operations on both node features and edge features.
First, we map the high-dimensional discrete features
E and
Z to continuous low-dimensional vector spaces, obtaining dense vectors, which enables the model to better handle information from
E and
Z. The embedding layer maps each node with values (both
e and
z) to a
d-dimensional dense vector representation, denoted as
and
. The calculation process of the embedding layer can be expressed as:
where
is the weight matrix of the embedding layer. For the edge direction matrix and edge attribute matrix,
v is 2 and
n, respectively, representing the dimensionality of the input space for the embedding layer. Now, we have obtained matrices
and
after the embedding operation, and perform matrix addition to obtain the edge features:
where
.
Secondly, we expand the node feature matrix X to . We index the node feature vector based on the elements stored in the first row (source node) of the edge index matrix . The elements in correspond to the row numbers in X. Since the same element value may appear multiple times in (because the out-degree of a specific node may be greater than one, i.e., it may act as a source node multiple times), there will be duplicate rows in the extended node feature matrix . Each row in the extended node feature matrix is a copy of the corresponding row in the node feature matrix X. For example, if element 2 appears twice in , then the row corresponding to will also appear twice in . Ultimately, is expanded to , where c is the number of edges in the graph and P is the dimensionality of the node features.
Thirdly, concatenate F with to obtain the aggregated feature matrix , where c is the number of edges in the graph, and is the sum of the dimensions of the edge embedding and the extended node feature.
Finally,
is scattered to transform edge features into node features.
is set as the input tensor, and scatter indices are specified at target node positions from the second row of
. We specify the output tensor size as the number of nodes (the dimension of adjacency matrix
A, denoted by
I), and aggregate the data using the sum method. Ultimately, we obtain the co-embedding matrix
of node features and edge features.
Figure 6 illustrates the process of generating co-embeddings by embedding edge direction and edge attributes, combining them with extended node features to generate aggregated features, and then scattering to obtain edge-node co-embeddings.
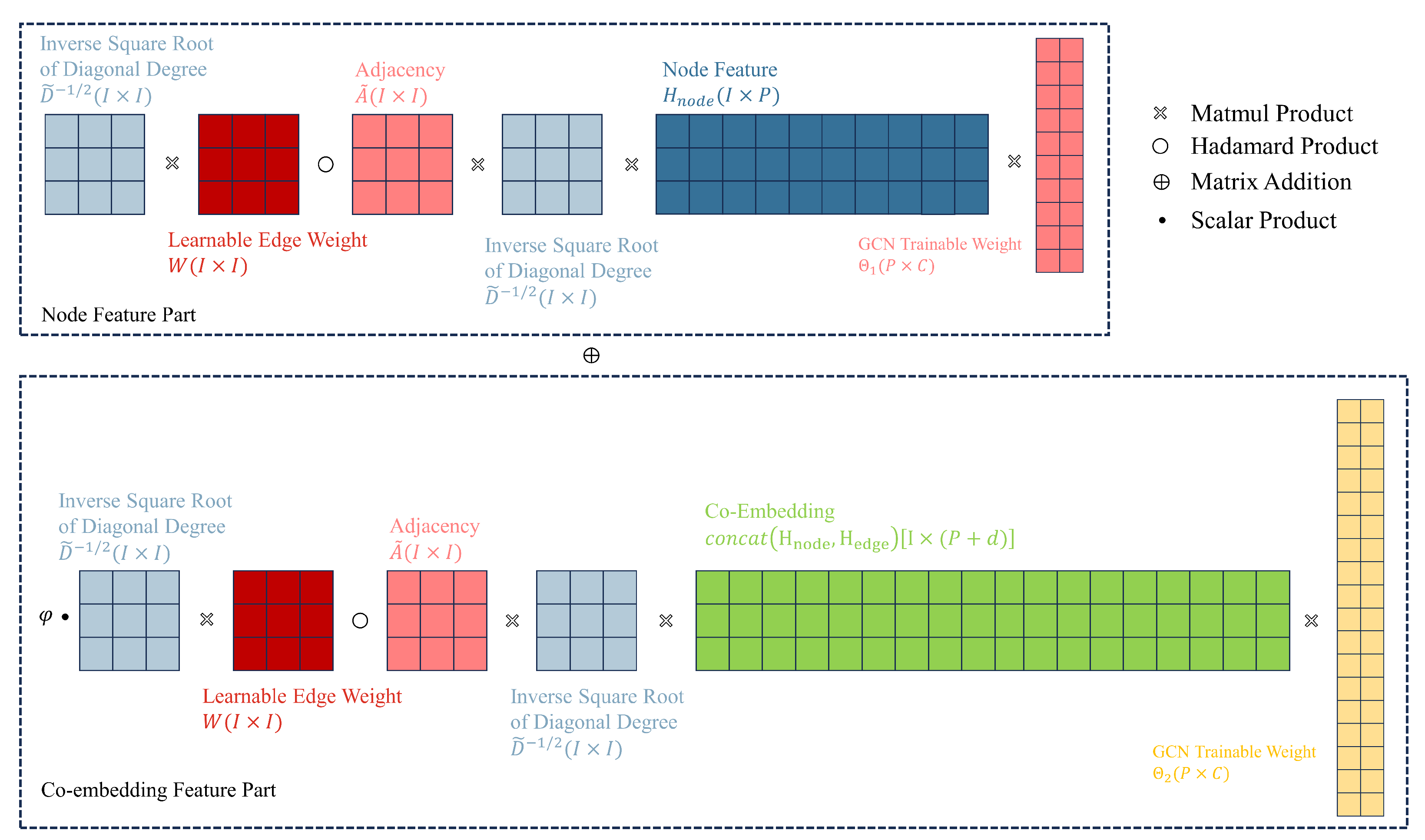
4.3. Separate Trainable GCN Weights
In this section, we design separate trainable GCN weights for node features and co-embedding features. The term “separate trainable GCN weights” refers to splitting the original trainable weight in GCN into two weights, and . These weights are used to transform node embeddings and co-embeddings in their respective feature spaces before combining them through weighted summation.
In theory, our method extracts high-dimensional information from the neighborhood of graph nodes by dimensionality reduction into dense vector embeddings. These embeddings can be provided to downstream machine learning systems to accomplish the GAD task. In graph analysis tasks, edge embeddings have been proven to be highly useful as input features for GAD [
39].
Our discussion still starts with the traditional GCN. For the sake of simplicity in exposition, we rewrite Equation (
4) in a more concise form:
In the above equation, the activation function and normalized adjacency matrix are omitted, and only one layer of GCN is considered, which does not affect the construction of our aggregation function. The equation can be seen as the transformation of node embeddings H to obtain new embeddings through trainable weight , where .
To cleverly combine node embedding
and co-embedding
, we designed different
for
and
, projecting them into different feature spaces. This helps enhance the model’s expressive ability, which can be written as follows:
here,
W is the learnable edge weight discussed in
Section 4.1, which is incorporated into the edge embedding network,
is a hyperparameter that adjusts the relative importance.
By substituting the co-embeddings into Equation (
23),
and
can be trained separately.
Figure 7 illustrates our third improvement, which is designing separate GCN trainable weights to enhance the model’s expressive power, and Algorithm 2 outlines the process of our co-embedding and separate training algorithm. First, we perform embedding operations separately on the directional and attribute information of the edges (lines 1–2). Then, we add the obtained embedding matrices to obtain the edge feature matrix (line 3). We redistribute the node feature matrix to obtain the extended node feature matrix (line 4). Next, we aggregate the edge feature matrix and the node feature matrix (line 5), and obtain the edge-node co-embedding through scatter operations (line 6). Finally, we project node features and edge-node co-embedding into different spaces using different GCN trainable weights (line 7).
| Algorithm 2 Node-edge co-embedding and separate training. |
- Input:
Graph G; edge direction E; edge attribution Z; edge index ; node feature X. - Output:
Predicted Abnormal Nodes . - 1:
Embed edge direction with Equation ( 19); - 2:
Embed edge attribution with Equation ( 20); - 3:
; - 4:
Redistribute the rows of X according to ; - 5:
; - 6:
; - 7:
Convolute with Equation ( 23) using Algorithm 1 - 8:
return
|
5. Experiments
5.1. Datasets
We selected the publicly available dataset, DGraph [
6], a real-world GAD graph in the finance domain, as our test sample. This dataset comprises a directed, unweighted graph that represents a social network among users. In this graph, each node represents a user, and the node features, derived from basic personal profiles, consist of a 17-dimensional vector. Each dimension corresponds to a different element of the individual’s profile, primarily including the following aspects: (1) basic personal information, such as age, gender, and location; (2) past borrowing behavior, including agreed-upon repayment due dates and actual repayment dates; (3) emergency contact-related information, such as the existence of emergency contacts. An edge from one user to another signifies a different type of connection, with a total of 12 distinct types of connections. It is noteworthy that DGraph is highly sparse, containing approximately 3 million nodes and 4 million edges. The number of nodes in DGraph is 17.1 times that of Elliptic [
40], making it the largest publicly available dataset in the GAD domain to date.
As a financial dataset, DGraph originates from real-world borrowing and lending behaviors. The determination of whether a node is classified as normal or anomalous depends on its borrowing and lending activities, summarized briefly as follows. All labeled nodes in DGraph have engaged in borrowing or lending at least once. Nodes that are registered but have not engaged in borrowing or lending are classified as unlabeled nodes. Among the labeled nodes, those classified as anomalous are users who have failed to repay their loans for a considerable period after the loan’s due date, disregarding repeated reminders from the platform. According to the aforementioned criteria, 15,509 users are classified as anomalous. Among these nodes, normal users account for 22.07% (nodes labeled as 0), while abnormal users account for 0.26%. The ratio of positive to negative samples is approximately 85:1, indicating a significant class imbalance in the dataset. The nodes are randomly split into training/validation/test sets with a ratio of 70:15:15.
Table 3 lists the key parameters of DGraph.
Table 4 summarizes the comparison of parameters between DGraph and mainstream anomaly detection datasets. Compared to other datasets, DGraph is closer to real-world applications because it has a minimum percentage of anomalous nodes and a diluted network, which is a common phenomenon in real GAD task. At the same time, the label data proportion in DGraph is also very low. Compared to DGraph, YelpChi is constructed using a Yelp Review Filter [
41], making it not the real ground truth. The ratio of edges to nodes (in other words, the degree of the nodes) in the Amazon dataset is approximately 368:1, creating a graph that is too dense to be common in the GAD field. Elliptic is the closest to our scenario, but it treats edges as homogeneous, meaning that edges do not have attributes. In real GAD scenarios, however, the connections between users are diverse. Excessive features also reduce the usability of Elliptic. This is the reason why DGraph was chosen as the dataset for this study.
It is important to note that, for privacy protection purposes, the features of the nodes in DGraph are anonymously provided and not ordered by importance. This anonymity of features prevents this paper from visualizing the dataset in the same manner as other datasets, where the first two features are typically chosen for the x-axis and y-axis in plots. The anonymous provision of features also limits our ability to further explain which features contribute more significantly to node anomalies. (The DGraph provider anonymizes users by removing personal identifiers and randomizing transaction details, making it impossible to trace back to user IDs. Furthermore, since user features are not unique, users cannot be identified from the dataset, ensuring DGraph’s anonymity.)
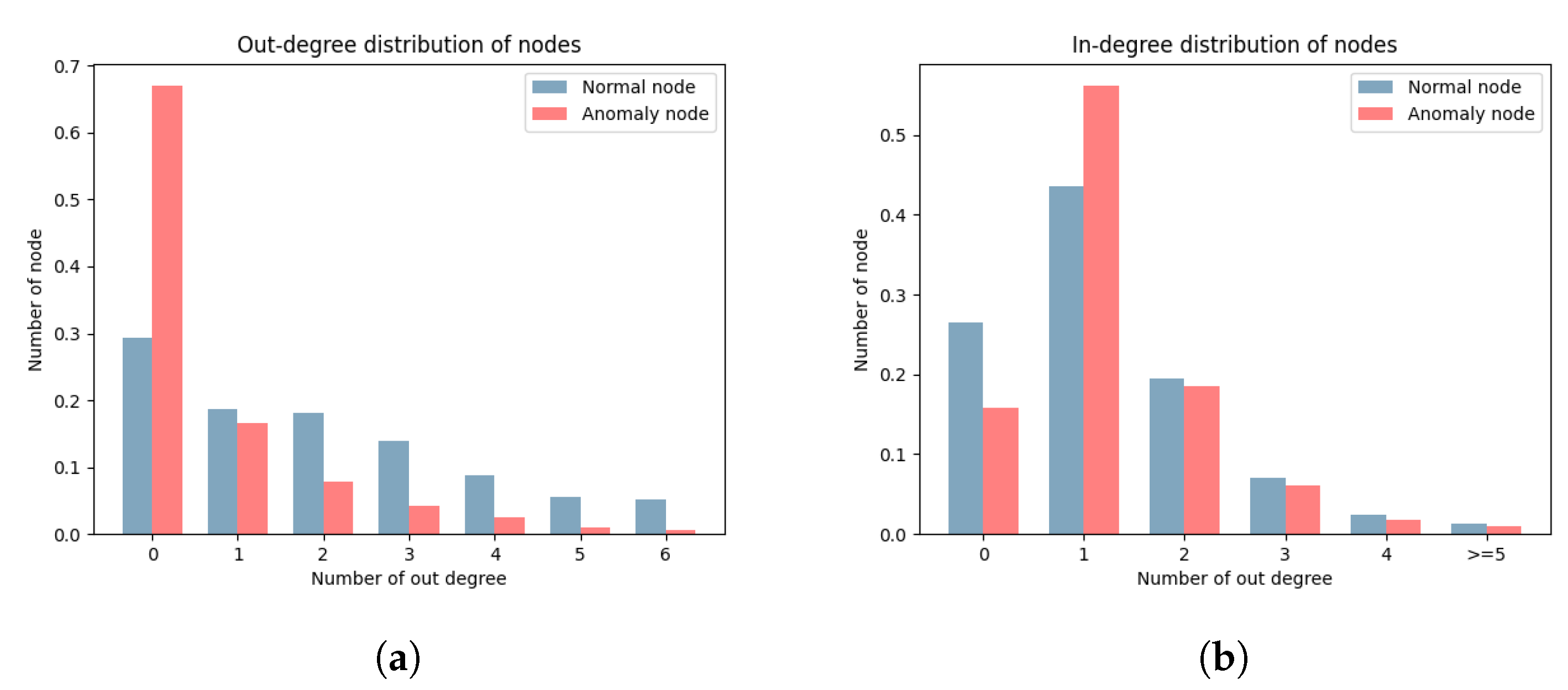
Figure 8 lists the distribution of node out-degrees and in-degrees. There is a significant difference in the distributions of out-degrees and in-degrees for the two types of nodes. According to the definition of DGraph, each node represents a user. The out-degree represents the completeness of information for a user, where the higher out-degree indicates higher information completeness. The in-degree represents the trust relationship of a user, where a higher in-degree indicates higher trust from other users. The out-degree of a node is determined by the user, while the in-degree is not. The significant difference between node out-degrees and in-degrees provides a basis for our edge direction embedding. The edge direction treats the out-degree and in-degree of nodes differently, accurately distinguishing between the two types of nodes.
Background nodes are an important attribute of the DGraph dataset. [
6] These nodes refer to entities that lack borrowing and lending activities, are not the target of anomaly detection, but play a crucial role in maintaining the connectivity of DGraph. Throughout our experiments, we adhere to the following assumption: retain all background nodes but only perform anomaly detection on labeled nodes (normal or anomalous).
5.2. Baselines
We have selected eight methods as our baseline approaches, comprising one baseline method (MLP), two generic graph methods (Node2Vec and LPA), and five GCN-based methods (GCN, GAT, GATv2, GraphSAGE, and UniMP). We adopt AUC as the evaluation metric, which is extremely useful in the scenario of data imbalance where abnormal data sets are scarce while normal data sets are extremely abundant. The higher the AUC value, the better the model’s performance. For example, in DGraph, abnormal users only account for 1.16% of the dataset. Therefore, even if the model predicts all samples as normal, the accuracy would still be as high as 99%. However, it is evident that the model’s predictive performance is poor. Moreover, in GAD scenarios, the losses incurred by predicting fraudulent users as normal would be far greater than predicting normal users as fraudulent. Hence, for our GAD task, AUC is more crucial.
5.3. Experimental Setup
The experimental environment for all experiments remained consistent. The GPU utilized was an NVIDIA V100 (32 GB NVLink memory, single GPU with 5120 CUDA Cores), the CPU consisted of 12 Intel Xeon processors (Platinum 8163 (Skylake) @2.50 GHz), and the system had 92 GB of RAM. For each method, five runs were executed, with each run comprising 500 epochs, and the best-performing value was selected. Unless otherwise specified, all experiments are conducted on undirected graphs.
In implementing all algorithms, we utilized PyTorch Geometric. During the implementation process, we employed one trick: we replaced the storage of the matrix containing the source and target nodes of edges with a sparse adjacency matrix. This significantly accelerated computation speed, except for GAT, GATv2, and co-embedding, as they require explicit edge propagation.
All the hyper-parameters are listed below:
5.4. Comparison with Baselines
Table 5 presents the results of the comparison between our unified model and the baseline algorithms in terms of the AUC metric. The hyperparameters used here are: LPA weight
and co-embedding weight
. In the table, “WL” refers to the first improvement module, which is the edge weight learnable module in our model; “CE” refers to the second improvement module, which is the edge-node co-embedding module.
From
Table 5, we observe that the MLP baseline, which does not utilize any graph information, achieved good results. Among the generic graph methods, Node2Vec, which only utilizes graph structure, and LPA, which only utilizes node labels, did not achieve high AUC scores. This suggests that in the GAD task on DGraph, the primary information lies within the node features. Among the GCN-based models, classical GCN and GAT performed similarly, while GraphSAGE showed significant improvement in performance. This is because GraphSAGE designs different trainable features for neighboring nodes. GATv2 improves upon GAT and exhibits noticeable performance gains. UniMP, incorporating attention mechanisms into GCN models, achieved very significant improvements.
Our edge-weight-learnable method, which is an improvement of GCN utilizing LPA to incorporate node labels, achieved higher AUC compared to traditional GCN. This demonstrates that both node features and node labels contain rich information, and LPA can act as a regularization penalty to aid training.
In terms of model training time, the general graph methods LPA and Node2Vec do not involve explicit “training” and therefore do not have training time. The MLP model, being the smallest in scale and simplest in architecture, naturally has the shortest training time. Among the methods employing the sparse matrix trick, our edge weight learnable method has the second shortest training time, only slightly longer than the classical GCN method. This is because our edge weight learnable method does not increase the model’s dimensionality; it only introduces node labels (which are also used in traditional GCN-based methods) and achieves a good trade-off between time and performance. Methods that do not use the sparse matrix trick—such as GAT, GATv2, and our co-embedding method—require significantly longer training times. This is because the edge information needs to be explicitly propagated along the edges and cannot be represented using sparse matrices to reduce computation. Additionally, extracting edge features and the growth in model size both require more time. It is worth noting that both GraphSAGE and GAT have corresponding mini-batch methods, which can reduce the size of each batch to improve speed. However, for the sake of fairness, we did not use mini-batch training in this study.
The method incorporating edge-node co-embedding and improving the convolution operator achieved significant progress in performance. This indicates that the direction and attributes of edges are helpful in enhancing the ability of GAD to detect anomalies. Additionally, designing different trainable weights for node features and co-embedding features contributes to improving algorithm expressiveness.
5.5. Infuence of LPA Regularization
To study the effectiveness of LPA regularization, we varied the LPA weight
from 0 to 5 in the weight-learnable algorithm, without adding co-embedding. We observed the performance changes, as shown in
Table 6.
From the table, it can be observed that when
is non-zero (i.e., after adding learnable weight), the performance is better than before adding learnable weight. This demonstrates the effectiveness of our LPA regularization strategy. However, when
is too large, the term
in Equation (
17) becomes greater than the term
. In the computation of the loss, the loss function based on labeled data
is more important, as it determines the direction of gradient descent, while the regularization penalty
serves as an auxiliary factor.
5.6. Impact of Edge and Node Co-Embedding
To investigate the influence of co-embedding, we fixed
to 1 and varied the weight
of the co-embedding term from 0 to 2, observing the performance changes.
Table 7 reflects this variation. It can be seen from the table that the inclusion of edge directionality and attribute information leads to significant performance improvements, despite the fact that there are only two types of directional information and 12 types of edge attribute information. This demonstrates the effectiveness of our co-embedding method. Additionally, designing different trainable weights for node features and co-embedding features, projecting different features into different feature spaces, greatly enhances the model’s expressive ability. However, overly large
values can lead to performance degradation. We believe this is because most of the information in the graph is contained within the node features, and the fundamental purpose of the GCN algorithm is to find neighboring nodes based on the similarity of node features, with edge information serving as an auxiliary.
Including reverse edges can increase the density of edges and provide more directional information, which can greatly improve performance when edge information is required for co-embedding. To demonstrate this, we fixed
to 1 and tested the performance under the same conditions on a directed graph (i.e., without adding reverse edges).
Table 7 reflects this variation. It can be observed that as the co-embedding weight
increases, the performance gain from reverse edges decreases. We believe that when the co-embedding weight is low, the information contained in the graph’s topological structure is more prominent, while undirected graphs contain more topological structures. However, as the co-embedding weight increases, the directional and attribute information carried by the edges becomes more important.
To demonstrate the effectiveness of the learnable edge weight strategy, we fixed
to 1 and removed the learnable edge weight on an undirected graph; the AUC decreased from 79.45% to 79.03%. This demonstrates that although the second term
in Equation (
23) is composed of node features
and edge features
co-embedded, it is still a feature matrix aggregated based on node dimensions. Therefore, using the loss term from the LPA algorithm instead of the regularization penalty in GCN, as derived in Equation (
18), still improves the algorithm’s performance.
6. Conclusions
This research contributes to advancing the field of graph anomaly detection, offering a robust framework for future studies and applications.
Firstly, by establishing the relationship between label propagation and feature convolution, we have shown that the LPA can function as a regularization penalty term for GCN, thereby facilitating training and enabling the learning of edge weights. Secondly, our node and edge feature co-embedding method fully utilizes the directional and attribute information inherent in the edges, increasing the spatial dimensionality of the model. Finally, we employ separate trainable GCN weights to handle node features and co-embedding features, enabling the projection of different features into separate feature spaces, greatly enhancing the model’s generalization capability.
Experimental results on the DGraph dataset have demonstrated superior AUC performance compared to baseline models, underscoring the feasibility and effectiveness of our proposed approach in tackling GAD tasks.
The method proposed in this paper currently incurs relatively high time and memory costs, requiring significant computational resources. This limitation hinders the application of the proposed method in larger-scale scenarios. Future work includes exploring techniques such as downsampling to reduce time and memory overhead while maintaining algorithm performance, making it more responsive to the rapid growth of data brought about by the Industry 4.0 era.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}