
ST-TGR: Spatio-Temporal Representation Learning for Skeleton-Based Teaching Gesture Recognition


Abstract
:1. Introduction
- (i)
- To mitigate the difficulty of single-target dynamic gesture recognition in multi-person scenarios, we propose a gesture recognition algorithm based on skeleton keypoints. Our method mainly extracts the skeleton keypoint coordinates of the target through human pose estimation technology and then inputs information sequences of different scales into subsequent gesture recognition modules for gesture action classification.
- (ii)
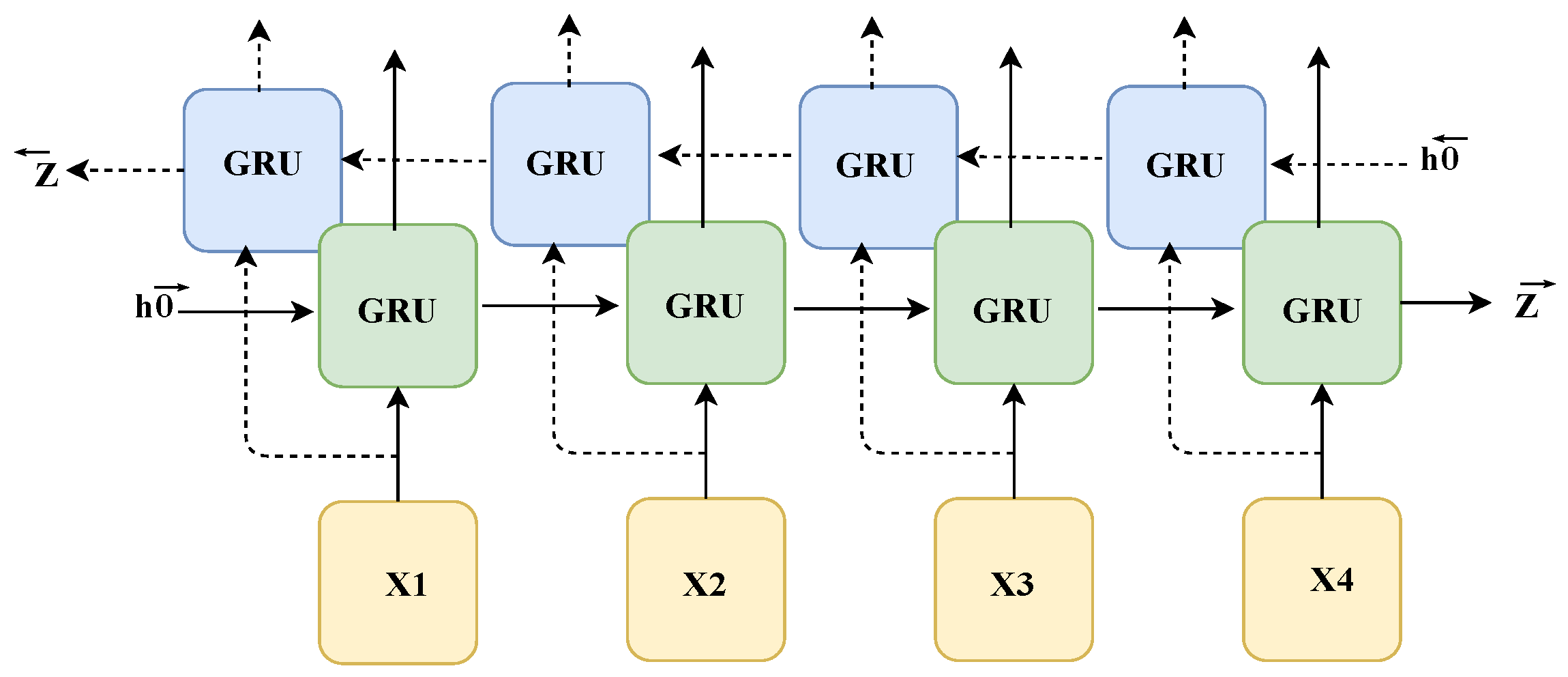
- A simple and efficient action recognition network module MoGRU is proposed in this paper, which integrates multi-scale bidirectional GRU modules and improved attention mechanism modules. It can achieve good action classification performance on different benchmark action datasets when only using target skeletal information, especially when dealing with small sample datasets. In addition, this module has a good balance between recognition speed and recognition accuracy, bringing possibilities for practical applications.
- (iii)
- To promote the application of gesture recognition in teaching, this article constructs a teaching gesture action dataset (TGAD) based on a real classroom teaching scenario, which includes four types of teaching gesture actions from different perspectives, totaling 400 samples. After model testing, our proposed method can achieve 93.5% recognition accuracy on this dataset.
2. Related Work
2.1. Skeleton-Based Action Recognition
2.2. 2D Multi-Person Pose Estimation
2.3. Attention Mechanism
3. Methods
3.1. Overview of ST-TGR Model
3.2. Skeleton Keypoint Extraction
3.3. Classification of Gesture Actions
4. Experimental Results and Analysis
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
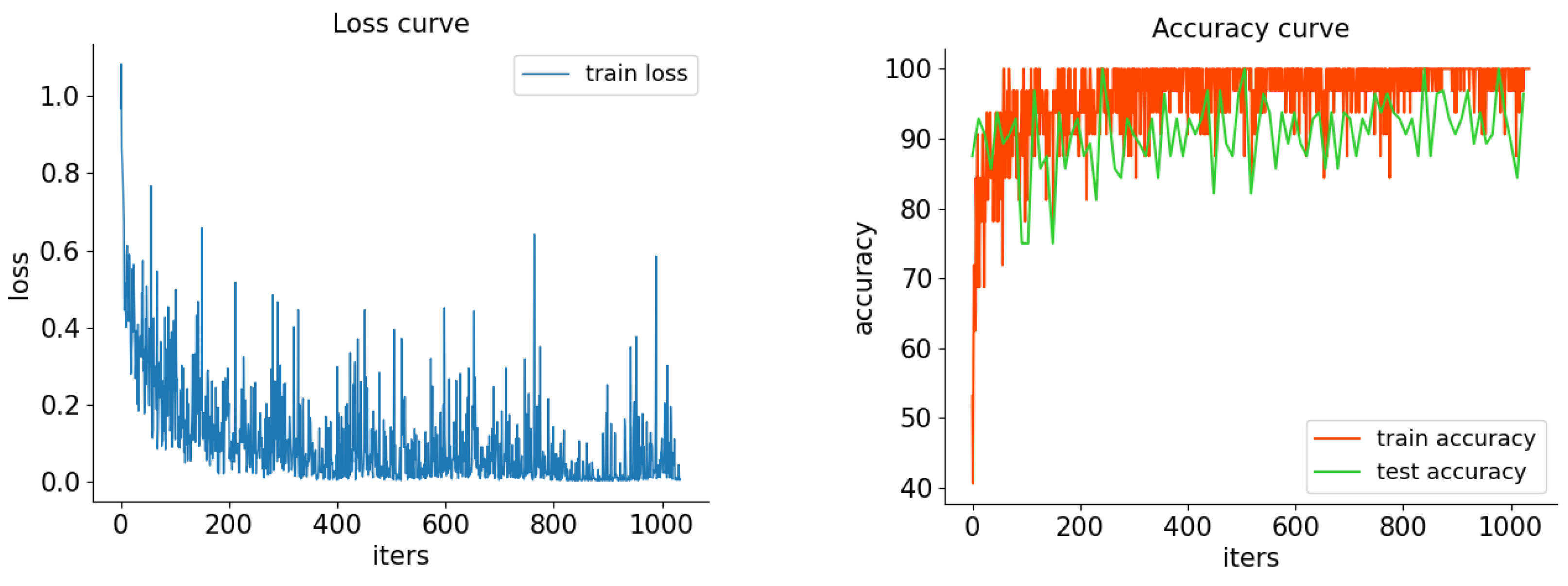
4.4. Results and Analysis
4.5. Baseline
4.6. Comparison with Baseline Methods
4.7. Ablation Experiments
4.7.1. Comparative Experiments of BiGRU
4.7.2. Comparative Experiments of Co-Attention
4.7.3. Comparative Experiments of RTMPose
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aldugom, M.; Fenn, K.; Cook, S.W. Gesture during math instruction specifically benefits learners with high visuospatial working memory capacity. Cogn. Res. Princ. Implic. 2020, 5, 27. [Google Scholar] [CrossRef] [PubMed]
- Ali, N.M.; Ali, M.S.M. Evaluation of Students’ Acceptance of the Leap Motion Hand Gesture Application in Teaching Biochemistry. In Proceedings of the 2019 2nd International Conference on new Trends in Computing Sciences (ICTCS), Amman, Jordan, 9–11 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wakefield, E.M.; Novack, M.A.; Congdon, E.L.; Franconeri, S.G.M.S. Gesture helps learners learn, but not merely by guiding their visual attention. Dev. Sci. 2018, 21, e12664. [Google Scholar] [CrossRef] [PubMed]
- Gu, Y.; Hu, J.; Zhou, Y.; Lu, L. Online Teaching Gestures Recognition Model Based on Deep Learning. In Proceedings of the 2020 International Conference on Networking and Network Applications (NaNA), Haikou City, China, 10–13 December 2020; pp. 410–416. [Google Scholar] [CrossRef]
- Qin, W.; Mei, X.; Chen, Y.; Zhang, Q.; Yao, Y.; Hu, S. Sign Language Recognition and Translation Method based on VTN. In Proceedings of the 2021 International Conference on Digital Society and Intelligent Systems (DSInS), Chengdu, China, 3–4 December 2021; pp. 111–115. [Google Scholar] [CrossRef]
- Luqman, H. An Efficient Two-Stream Network for Isolated Sign Language Recognition Using Accumulative Video Motion. IEEE Access 2022, 10, 93785–93798. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Chen, Y.; Zhang, Z.; Li, Y. EHPE: Skeleton Cues-based Gaussian Coordinate Encoding for Efficient Human Pose Estimation. IEEE Trans. Multimed. 2024, 24, 124–138. [Google Scholar] [CrossRef]
- Guo, X.; Xu, W.; Tang, W.; Wen, C. Research on Optimization of Static Gesture Recognition Based on Convolution Neural Network. In Proceedings of the 2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Hohhot, China, 24–26 October 2019; pp. 398–3982. [Google Scholar]
- Li, J.; Li, Z. Dynamic gesture recognition algorithm Combining Global Gesture Motion and Local Finger Motion for interactive teaching. IEEE Access 2021, 1. [Google Scholar] [CrossRef]
- Liu, H.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inform. 2022, 18, 4361–4371. [Google Scholar] [CrossRef]
- Mcbride, T.; Vandayar, N.; Nixon, K. A Comparison of Skin Detection Algorithms for Hand Gesture Recognition. In Proceedings of the Southern African Universities Power Engineering Conference/Robotics Mechatronics/Pattern Recognition Association of South Africa, Bloemfontein, South Africa, 28–30 January 2019; pp. 211–216. [Google Scholar]
- Wan, S.; Yang, L.; Ding, K.; Qiu, D. Dynamic Gesture Recognition Based on Three-Stream Coordinate Attention Network and Knowledge Distillation. IEEE Access 2023, 11, 50547–50559. [Google Scholar] [CrossRef]
- Mian, L.; Jiping, Z. Research on future Intelligent Classroom Teaching System Design—Using Gesture Recognition as Technical Support. China Electron. Educ. 2019, 14–21. [Google Scholar]
- Li, W.; Wen, L.; Chang, M.C.; Lim, S.N.; Lyu, S. Adaptive RNN tree for large-scale human action recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1453–1461. [Google Scholar]
- Gao, Y.; Li, C.; Li, S.; Cai, X.; Ye, M.; Yuan, H. Variable Rate Independently Recurrent Neural Network (IndRNN) for Action Recognition. Appl. Sci. 2022, 12, 3281. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Tu, J.H.; Liu, M.Y.; Liu, H. Skeleton-based human action recognition using spatial temporal 3d convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Li, M.; Sun, Q.M.; Rodino, L. 3D skeletal human action recognition using a CNN fusion model. Math. Probl. Eng. 2021, 2021, 6650632. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral Networks and Locally Connected Networks on Graphs. In Proceedings of the International Conference on Learning Representations (ICLR2014), CBLS, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI’18: AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February2018. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 13339–13348. [Google Scholar]
- Chi, H.G.; Ha, M.H.; Chi, S.; Lee, S.W.; Huang, Q.; Ramani, K. InfoGCN: Representation learning for human skeleton-based action recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 20154–20164. [Google Scholar]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton Aware Multi-modal Sign Language Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 3408–3418. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Yang, B.; Zhang, Z. LDCNet: Limb Direction Cues-aware Network for Flexible Human Pose Estimation in Industrial Behavioral Biometrics Systems. IEEE Trans. Ind. Inform. 2024, 1–11. [Google Scholar] [CrossRef]
- Liu, T.; Li, Y.; Liu, H.; Zhang, Z.; Liu, S. RISIR: Rapid Infrared Spectral Imaging Restoration Model for Industrial Material Detection in Intelligent Video Systems. IEEE Trans. Ind. Inform. 2023, 1. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative Poses Perception and Matrix Fisher Distribution for Head Pose Estimation. IEEE Trans. Multimed. 2022, 24, 2449–2460. [Google Scholar] [CrossRef]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-Person Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2018; Volume 11210. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 172–186. [Google Scholar]
- Nie, X.; Feng, J.; Xing, J.; Yan, S. Pose Partition Networks for Multi-Person Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. PifPaf: Composite Fields for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11969–11978. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, C.; Deng, Y.; Liu, T.; Zhang, Z.; Li, Y. Orientation Cues-Aware Facial Relationship Representation for Head Pose Estimation via Transformer. IEEE Trans. Image Process. 2023, 32, 6289–6302. [Google Scholar] [CrossRef] [PubMed]
- Girdhar, R.; Ramanan, D. Attentional pooling for action recognition. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 33–44. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Decoupled Spatial-Temporal Attention Network for Skeleton-Based Action-Gesture Recognition. In Proceedings of the Computer Vision—ACCV, Kyoto, Japan, 30 November–4 December 2020; Ishikawa, H., Liu, C., Pajdla, T., Shi, J., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2021; Volume 12626. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Smolic, A. ACTION-Net: Multipath Excitation for Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13214–13223. [Google Scholar]
- Jiang, T.; Lu, P.; Zhang, L.; Ma, N.; Han, R.; Lyu, C.; Li, Y.; Chen, K. RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.L.; Zhang, F.; Grundmann, M. BlazePose: On-device Real-time Body Pose tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. TokenPose: Learning Keypoint Tokens for Human Pose Estimation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11293–11302. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, L. Microsoft COCO: Common Objects in Context. In Proceedings of the ECCV, ECCV Ed. European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (ICCVW), Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (ICCVW), Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Seidenari, L.; Varano, V.; Berrett, S.; Bimbo, A.; Pala, P. Recognizing actions from depth cameras as weakly aligned multi-part bag-of-poses. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops (ICCVW), Portland, OR, USA, 23–28 June 2013; pp. 479–485. [Google Scholar]
- Kim, T.S.; Reiter, A. Interpretable 3D Human Action Analysis with Temporal Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1623–1631. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Koniusz, P.; Wang, L.; Cherian, A. Tensor Representations for Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 648–665. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2136–2145. [Google Scholar]
- Maghoumi, M.; LaViola, J.J. DeepGRU: Deep Gesture Recognition Utility. In Proceedings of the Advances in Visual Computing, Lake Tahoe, NV, USA, 7–9 October 2019; pp. 16–31. [Google Scholar]
- Luvizon, D.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; Volume 2. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J.; Taylor, G.W. Glimpse clouds: Human activity recognition from unstructured feature points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hedegaard, L.; Heidari, N.; Iosifidis, A. Continual spatio-temporal graph convolutional networks. Pattern Recognit. 2023, 140, 109528. [Google Scholar] [CrossRef]
- Lin, L.; Zhang, J.; Liu, J. Actionlet-Dependent Contrastive Learning for Unsupervised Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2363–2372. [Google Scholar]
- Ding, X.; Yang, K.; Chen, W. A Semantics-Guided Graph Convolutional Network for Skeleton-Based Action Recognition. In Proceedings of the 2020 the 4th International Conference on Innovation in Artificial Intelligence (ICIAI), Xiamen, China, 6–9 March 2020; pp. 130–136. [Google Scholar] [CrossRef]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Richly Activated Graph Convolutional Network for Robust Skeleton-Based Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1915–1925. [Google Scholar] [CrossRef]
- Yang, H.; Gu, Y.; Zhu, J.; Hu, K.; Zhang, X. PGCN-TCA: Pseudo Graph Convolutional Network with Temporal and Channel-Wise Attention for Skeleton-Based Action Recognition. IEEE Access 2020, 8, 10040–10047. [Google Scholar] [CrossRef]
- Baradel, F.; Wolf, C.; Mille, J. Pose-conditioned spatio-temporal attention for human action recognition. arXiv 2017, arXiv:1703.10106. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 816–833. [Google Scholar]
- Fan, Z.; Zhao, X.; Lin, T.; Su, H. Attention based multiview re-observation fusion network for skeletal action recognition. IEEE Trans. Multimed. 2018, 21, 363–374. [Google Scholar] [CrossRef]
- Anirudh, R.; Turaga, P.; Su, J.; Srivastava, A. Elastic functional coding of human actions: From vector-fields to latent variables. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3147–3155. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. R3DG features: Relative 3D geometry-based skeletal representations for human action recognition. Comput. Vis. Image Underst. 2016, 152, 155–166. [Google Scholar] [CrossRef]
- Paoletti, G.; Cavazza, J.; Beyan, C.; Bue, A.D. Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6035–6042. [Google Scholar]
- Liu, J.; Wang, G.; Duan, L.; Abdiyeva, K.; Kot, A.C. Skeleton-based human action recognition with global context-aware attention lstm networks. IEEE Trans. Image Process. 2018, 27, 1586–1599. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy |
|---|---|
| Deep LSTM [41] | 85.4 |
| TCN [45] | 86.7 |
| Lie Group [46] | 88.3 |
| SCK + DCK [47] | 89.2 |
| VA-LSTM [48] | 90.5 |
| DeepGRU [49] | 91.2 |
| MoGRU | 93.5 |
| Modality | Method | Accuracy | |
|---|---|---|---|
| C-Sub | C-View | ||
| Image | Multi-task DL [50] | 84.6 | - |
| Glimpse Clouds [51] | 86.6 | 93.2 | |
| Pose + Image | Hands Attention [57] | 84.8 | 90.6 |
| Multi-task DL [50] | 85.5 | - | |
| Pose | VA-LSTM [48] | 79.4 | 87.6 |
| ST-GCN [20] | 86.0 | 93.4 | |
| CoAGCN [52] | 84.1 | 92.6 | |
| 3s-ActCLR [53] | 84.3 | 88.8 | |
| CoAGCN (2-stream) [52] | 86.0 | 93.1 | |
| Sem-GCN [54] | 86.2 | 94.2 | |
| CoS-TR [52] | 86.3 | 92.4 | |
| CoST-GCN [52] | 86.3 | 93.8 | |
| 3s RA-GCN [55] | 87.3 | 93.6 | |
| PGCN-TCA [56] | 88.0 | 93.6 | |
| MoGRU | 88.5 | 93.7 | |
| Modality | Method | Accuracy |
|---|---|---|
| Image | Hands Attention [57] | 72.0 |
| Pose + Image | Hands Attention [57] | 94.1 |
| Pose | Hands Attention [57] | 90.5 |
| ST LSTM + Trust Gates [58] | 93.3 | |
| GCA-LSTM [63] | 94.1 | |
| LSTM + FA + VF [59] | 95.0 | |
| VA-LSTM [48] | 97.2 | |
| MoGRU | 96.3 |
| Method | Accuracy |
|---|---|
| ST LSTM + Trust Gates [58] | 97.0 |
| Lie Group [46] | 97.1 |
| SCK + DCK [47] | 98.2 |
| GCA-LSTM [63] | 98.5 |
| Temporal Subspace Clustering [62] | 99.5 |
| MoGRU | 99.7 |
| Method | Accuracy |
|---|---|
| Elastic Functional Coding [60] | 89.6 |
| Relative 3D geometry [61] | 90.7 |
| Lie Group [46] | 90.9 |
| SCK + DCK [47] | 95.2 |
| Temporal Subspace Clustering [62] | 95.8 |
| MoGRU | 96.3 |
| Unit | Stacked | Time (s) | Accuracy |
|---|---|---|---|
| LSTM | 3 | 213 | 94.2 |
| LSTM | 5 | 453 | 94.9 |
| BiLSTM | 3 | 549 | 95.6 |
| BiLSTM | 5 | 627 | 96.7 |
| GRU | 3 | 145 | 93.8 |
| GRU | 5 | 399 | 94.4 |
| BiGRU | 3 | 517 | 96.4 |
| BiGRU | 5 | 564 | 96.0 |
| Module | Accuracy |
|---|---|
| Fully Connected (Not Using Attn) | 90.2 |
| Self-Attention | 96.6 |
| Multi-Head Attention | 97.5 |
| Co-attention | 99.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Huang, W.; Liu, H.; Wang, Z.; Wen, Y.; Wang, S. ST-TGR: Spatio-Temporal Representation Learning for Skeleton-Based Teaching Gesture Recognition. Sensors 2024, 24, 2589. https://doi.org/10.3390/s24082589
Chen Z, Huang W, Liu H, Wang Z, Wen Y, Wang S. ST-TGR: Spatio-Temporal Representation Learning for Skeleton-Based Teaching Gesture Recognition. Sensors. 2024; 24(8):2589. https://doi.org/10.3390/s24082589
Chicago/Turabian StyleChen, Zengzhao, Wenkai Huang, Hai Liu, Zhuo Wang, Yuqun Wen, and Shengming Wang. 2024. "ST-TGR: Spatio-Temporal Representation Learning for Skeleton-Based Teaching Gesture Recognition" Sensors 24, no. 8: 2589. https://doi.org/10.3390/s24082589
APA StyleChen, Z., Huang, W., Liu, H., Wang, Z., Wen, Y., & Wang, S. (2024). ST-TGR: Spatio-Temporal Representation Learning for Skeleton-Based Teaching Gesture Recognition. Sensors, 24(8), 2589. https://doi.org/10.3390/s24082589