1. Introduction
The gradual popularization of private cars in cities has provided great convenience for citizens to travel, but at the same time, it has also brought severe traffic congestion problems [
1]. Normalized traffic congestion results in an exponential increase in travel time, contributing to driver fatigue and a higher risk of traffic accidents in complex traffic environments. Autonomous vehicles, equipped to handle driving tasks autonomously, offer a solution to alleviate human driving stress and enhance safety and accuracy, particularly in monotonous traffic scenarios. The decision-making layer unit is the pivotal component of the autonomous driving algorithm, equivalent to human decision-making.
Ongoing research explores various decision-making algorithms, focusing on learning-based and rule-based approaches. While rule-based algorithms [
2,
3,
4] exhibit better stability, they reveal limitations when dealing with rich perceptual information. Decision-making algorithms based on reinforcement learning are extensively explored in autonomous driving scenarios, featuring various methods such as the DQN [
5,
6], DDPG [
7], and AC [
8]. However, due to inherent algorithmic characteristics, traditional reinforcement learning-based algorithms pose significant uncertainties in autonomous driving tasks. Consequently, some studies focus on enhancing the safety and robustness of these algorithms. Maldonado et al. analyze the impact of negative feedback on risk evaluation and decision processes in diverse driving contexts [
9]. Peng et al. emphasize enhancing traffic safety with an automatic lane-change mechanism for self-driving articulated trucks [
10]. They propose a novel safety lane-change path-planning and tracking-control method. Wang et al. propose a prediction method based on a fuzzy inference system (FIS) and a long short-term memory (LSTM) neural network [
11]. Some studies address the issue of uncertainty by training directional models. Zhang et al. introduce a knowledge model with a problem-description layer and a problem-solving knowledge layer [
12]. There are also studies based on intelligent connected vehicles for vehicle decision control [
13]. While various decision-making algorithms show promising results, many are tailored to specific simplified traffic scenarios, predominantly highways [
14].
The algorithm excels in simple scenarios but struggles with generalization to diverse test scenes. Its application is often confined to specific scenarios, like straight roads or single intersections, and learning-based effectiveness diminishes in complex situations. Furthermore, the algorithms rely heavily on ideal perceptual information and are tailored for V2X-enabled intelligent transportation systems. In real-world scenarios, the impracticality of seamless interconnectivity challenges algorithm performance. Hence, improving adaptability to incomplete global information is a crucial area of focus in autonomous driving research, which can be manifested in the algorithm’s ability to process raw sensor data.
End-to-end driving is a promising paradigm as it circumvents the drawbacks associated with modular systems [
15]. End-to-end learning-based algorithms can theoretically cope with the type of information provided by existing mature perception systems (e.g., cameras [
16], lidar [
17,
18], etc.). Shao et al. present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene [
19]. Hu et al. introduce a dynamic graph learning method, TAM-GCN, for the overtaking strategy, which outperforms existing methods in accuracy and safety [
20]. Yang et al. further enhance decision-making in autonomous driving with the SGRL algorithm, which incorporates interactive information between agents and demonstrates superior convergence and efficiency [
21]. These studies collectively highlight the potential of end-to-end learning-based algorithms in autonomous driving.
The end-to-end algorithm, which takes the image class as the input and directly outputs the vehicle’s actual action, is significantly impacted by the unpredictable nature of the model’s output. This susceptibility is a common characteristic of intricate end-to-end network structures. The fundamental challenge stems from the intricate nature of this network, seamlessly merging diverse stages of the initial process into a unified, inscrutable entity. This amalgamation transforms the model into a black box, eluding a comprehensive analysis, which introduces uncertainties about the model’s real-world performance, creating potential risks such as fatal logical errors and serious traffic accidents. As a result, the algorithm is presently confined to theoretical research, bound by its inherent mystery and the associated risks that arise when applied in real-world scenarios. The advent of convolutional neural networks (CNNs) [
22] has made it feasible to directly process large-scale data such as images, point clouds, and more. With the development of dedicated image-processing networks (VGG16 [
23], ResNet50 [
24], and EfficientNetB7 [
25]), the current target detection algorithm has been able to achieve high accuracy. Al batat et al. successfully developed an end-to-end Automated License Plate Recognition (ALPR) system utilizing YOLO for vehicle and license plate detection, achieving remarkable accuracy [
26].
The modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction, and planning. In order to perform a wide diversity of tasks and achieve advanced-level intelligence, contemporary approaches either deploy standalone models for individual tasks or design a multi-task paradigm with separate heads [
27]. Planning is a crucial aspect among them. Huang et al. introduced a predictive behavior-planning framework that learns to predict and evaluate from human driving data [
28]. In [
29], the mixture-of-experts approach is utilized to learn from human driving trajectory data to construct a multimodal motion planner. Inspired by these works and the hierarchical classification method for decision-making [
30], this paper proposes a hierarchical decision-making framework. The hierarchical framework ensures superior control and stability compared to existing end-to-end algorithms. The key contributions and innovations include the following:
This algorithm framework integrates the pre-trained target-detection model into the perceptual information preprocessing stage—the data encoder, transforming intricate image data into a state matrix conducive to decision-making networks. Adding orientation coordinates to the state matrix during construction enhances the algorithm’s adaptability to perceptual information, improving its ability to comprehend scene details.
A state machine based on a time series GCN is introduced to align temporal concepts with the real-time dynamics of driving scenarios. The GCN outperforms the traditional CNN in capturing temporal relationships, a key enhancement that significantly boosts the algorithm’s scene-understanding capabilities.
In contrast to the traditional end-to-end model, this algorithm adopts a hierarchical framework, rendering the entire process of perception data preprocessing, driving state classification, and action generation observable and controllable. This framework ensures enhanced stability and interpretability, unlike the opaque nature of the traditional end-to-end black-box model.
Compared to traditional end-to-end decision algorithms, this hierarchical approach exhibits superior generalization capabilities across various application scenarios, meeting the demands of autonomous driving tasks for predetermined trajectories on standardized roads.
The paper unfolds as follows:
Section 2 provides a detailed introduction to the proposed hierarchical decision-making framework.
Section 3 introduces the implementation of the experiment.
Section 4 summarizes and compares the algorithm’s experimental results and evaluation indexes in the autonomous driving task. Finally,
Section 5 derives the conclusion and proposes future improvement directions.
2. Methods
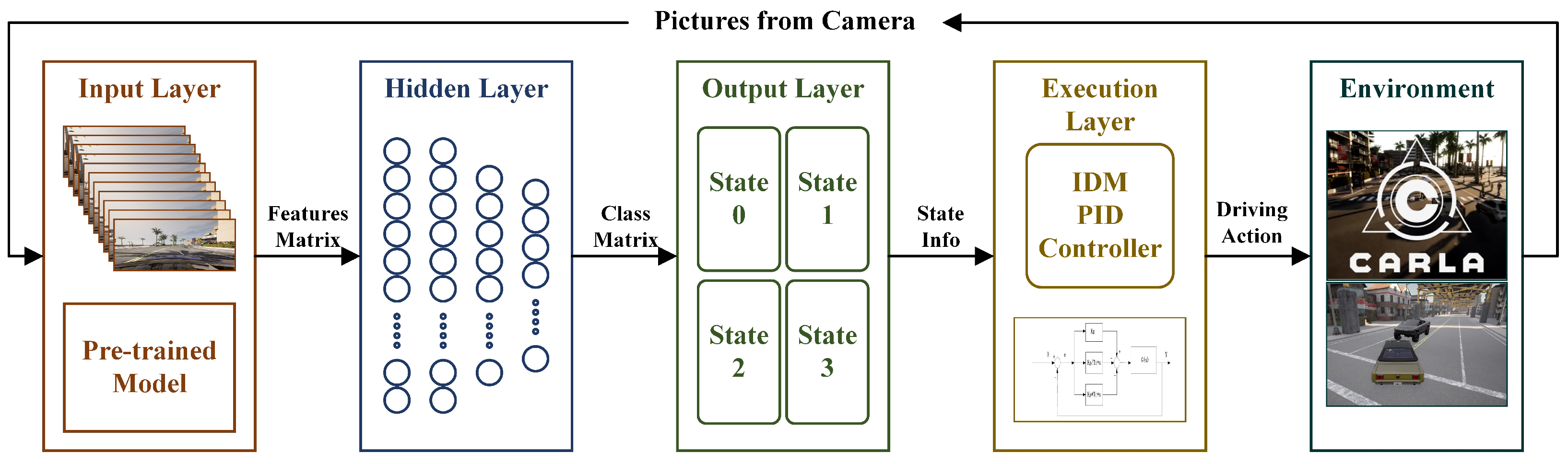
The hierarchical framework presented in this paper is structured into four layers, functioning sequentially in the information flow essential for vehicle autonomous driving. The depiction of this hierarchical framework is presented in
Figure 1.
2.1. Input Layer—Image Preprocessing and Encoder
In the context of human drivers, the eyes serve as the primary source of environmental information. Hence, it is commonplace to equip autonomous vehicles with cameras. Images offer a distinct advantage regarding the abundance and richness of information, providing a comprehensive view of the driving environment. To ensure an ample supply of information, the algorithm captures camera data from four directions around the vehicle. This framework breaks the algorithm’s dependency on global network information by using an array of images as the input for determining the vehicle’s driving state.
2.1.1. Model-Based Image Preprocessing
Traditional algorithms employing image information as the input often utilize convolutional neural networks (CNNs) as the processors. While these algorithms have demonstrated success in image recognition, their direct application in autonomous driving is primarily in the end-to-end form, posing challenges related to convergence and high training costs.
Some existing image-recognition algorithms can extract all target types and their occupied pixel panes in the image, corresponding to the visual information preprocessing in autonomous driving. YOLO [
31] is a mature multi-target-recognition algorithm that offers several pre-trained models. The latest version of YOLO v9 [
32] is currently the new SOTA for target detection. Utilizing this model for image preprocessing allows for the direct extraction of pertinent targets in the image and their position information in the field of view.
2.1.2. Encoder and State Matrix Construction
The image data processed by YOLO are transformed into a series of state information distinct from the original pixel points. This information encompasses the identified target type, the pixel position of the target in the image, and the confidence information associated with the identification. Additionally, based on the input image number, it becomes possible to differentiate the camera information corresponding to each target. This information, in turn, signifies the directional position of the target relative to the vehicle. To facilitate the subsequent network’s input process, it is imperative to establish standardized coding rules for generating a state matrix.
The specification of the state matrix hinges on the effective number of targets identified in the images captured from all directions. In the
Carla simulation platform, 100 autonomous NPC vehicles and 50 NPC pedestrians are introduced into the town map, which has a side length of 500 m, thus simulating high-density traffic scenes. By tallying the number of targets identified by the four cameras during the agent vehicle’s drive over a simulation time of 5 h, a total of 18,000 frames of data are obtained. The average number of targets in the image is calculated to be 10.107. Consequently, the specification of the state matrix can be configured as depicted in
Figure 2.
2.2. Hidden Layer—Network Structure
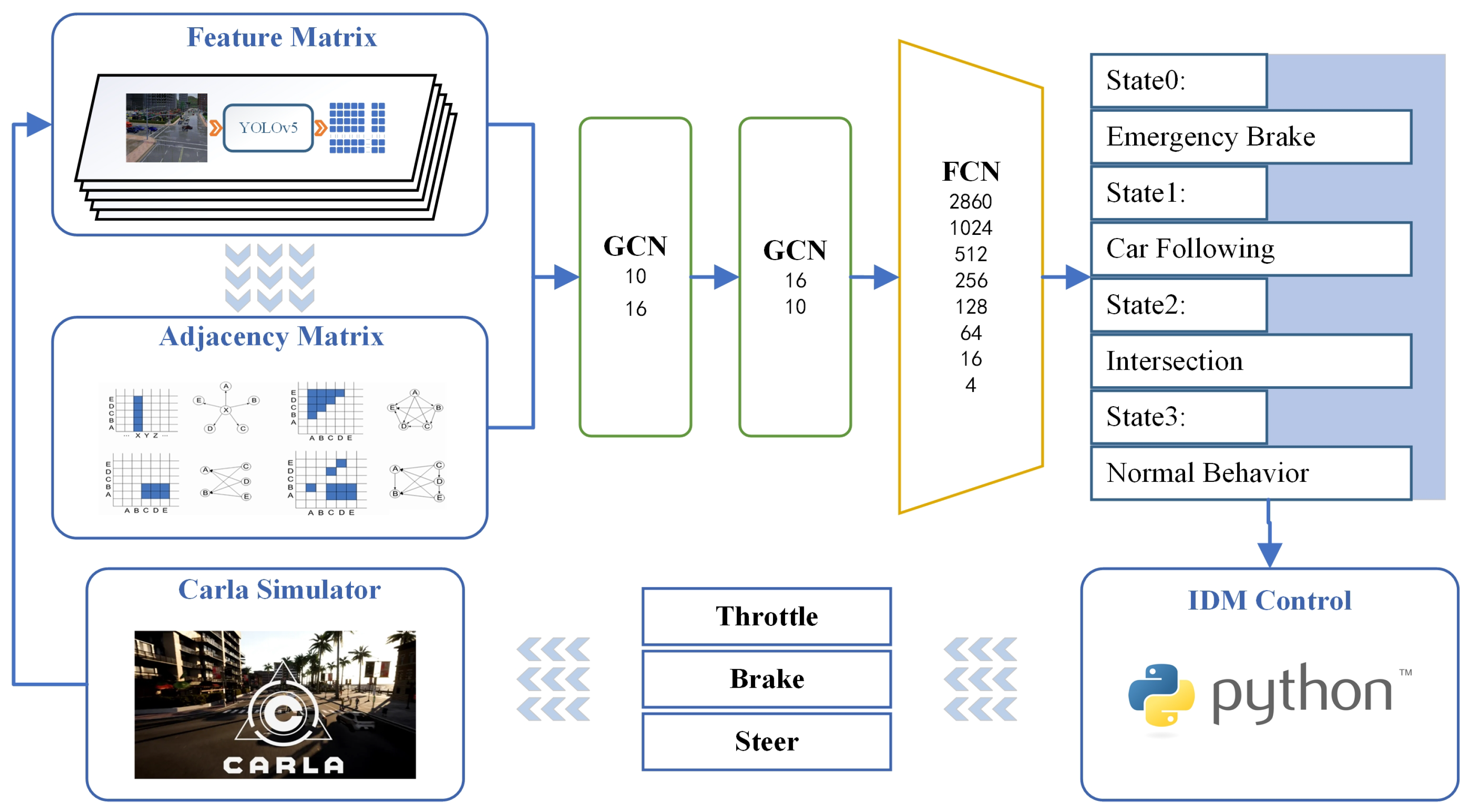
The feature matrix obtained by preprocessing has been significantly simplified regarding the dimensions and specifications for the original image data. However, it still contains much information and is unsuitable for direct driving state determination. Recognizing the outstanding capabilities of neural networks in handling large-scale information, this algorithm leverages them to analyze the state matrix. Since vehicle driving is continuous, historical information becomes crucial in current decision-making. Hence, the algorithm innovatively introduces a GCN based on time series information. The overall structure of the neural network hidden layer is depicted in
Figure 3.
2.2.1. Time Series GCN
Time series data inherently contain temporal dependencies, meaning that the value of a variable at one-time point is often dependent on its previous values, which is necessary for the driving state determination. GCNs can effectively capture these dependencies by incorporating information from neighboring time points in the graph structure, allowing them to model temporal relationships more effectively than traditional neural networks.
GCNs can directly operate on graphs and utilize their structural information. This concept is transplanted from the image field to the graph field. However, images typically exhibit a fixed structure, whereas the structure of a graph is more flexible and intricate. The fundamental idea behind GCNs is to consider all neighboring nodes and the feature information embedded in each node. This approach enables convolutional calculations on the topology graph. If the information is treated as a node at each moment, the time series information essentially forms a distinct topology, as illustrated in
Figure 4.
In the GCN section, each time series’s state matrix is treated as an individual node, and the temporal relationships can be likened to the configuration of an adjacency matrix. (In the model proposed in this paper, the adjacency matrix is a 10-dimensional square matrix with a diagonal and sub-diagonal of 1, as shown in
Figure 4. This implies that the current time and the initial nine timestamps carry equal significance, with interactions occurring solely between adjacent timestamps). Through graph convolution, the state matrix, when coupled with timing information, can be effectively processed. This approach proves more focused than a regular fully connected neural network when analyzing the sequential relationships among states. A 10-16-10 graph convolutional structure was chosen for the graph neural network segment.
2.2.2. Fully Connected Neural Network
The feature matrix computed by the GCN requires a detection head for the final classification output, which can be achieved using a fully connected neural network. There is no rigid standard for the depth of the network and the number of nodes in each layer. Consequently, the ultimate network structure must be determined through a series of comparative experiments. Considering that the number of output features in the GCN section is
, a control group can be established as outlined in
Table 1 based on empirical considerations.
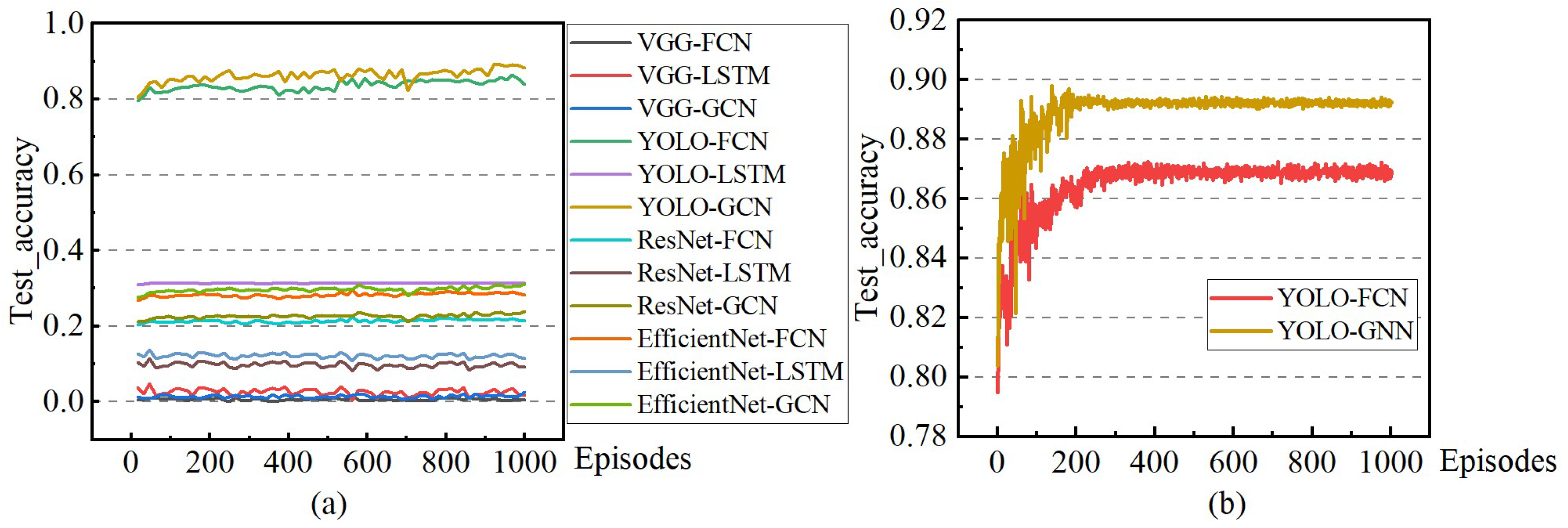
The groups mentioned above undergo separate training, with the total length of the training dataset amounting to 81,268. Following each iteration of traversing the dataset, the model’s prediction accuracy is evaluated using the testing dataset comprising 19,068 instances. The experimental results are illustrated in
Figure 5. Notably, starting from Group 3, there is a significant increase in the model’s prediction accuracy, albeit accompanied by a gradual rise in the time required for a single training episode. Subsequent experiments (Groups 4 to 6) exhibit spikes in the computing time due to the deepening of the networks, but the corresponding improvements in accuracy are not as pronounced. Therefore, it is deemed more appropriate to preliminarily determine the network structure parameters based on the configuration of Group 3, which has been utilized in the proposed framework outlined in this paper.
2.3. Output Layer—Determination of State Machine
The vehicle typically follows a predetermined route by default throughout the driving process to ensure it reaches its destination. However, in actual driving scenarios, occasional disturbances arise due to interactions with the external environment. The classification of a driving state machine can characterize these disturbances. Drawing inspiration from the driving behavior of human drivers on urban roads, vehicle driving states can be classified as follows. This classification also determines the dimension (four) of the model output layer:
Conventional driving state: The vehicle is driving on a conventional road section without traffic signal restrictions and maintains a safe distance from surrounding vehicles.
Car-following state: In a scene with a large traffic flow, the vehicle needs to follow the front vehicle and keep a fixed safe distance.
Traffic intersection driving state: There are interactive behaviors generated by reverse and vertical vehicles in the future driving area of the target vehicle, which includes all intersection types such as crossroads, T-junctions, and roundabouts, with traffic signal lights.
Emergency braking state: The vehicle performs emergency braking before the imminent collision and the violation of traffic rules such as running a red light.
The classification of driving states utilized in our study has been carefully considered to simultaneously meet the requirements of the comprehensive coverage of urban driving tasks and distinct differentiation of the control parameters. Any driving task in urban settings can be entirely composed of these four states.
2.4. Execution Layer—Rule-Based Vehicle Motion Control
Rule-based vehicle motion control essentially constitutes a path-tracking algorithm that considers various driving states. The end-to-end learning-based autonomous driving algorithm exhibits serious instability. For the subsequent verification experiment, this paper opts for a rule-based algorithm to execute the vehicle’s specific driving actions (throttle, steering, braking, etc.). Considering the characteristics of the rule-based algorithm, its control logic must be designed distinctively for various driving states. By simplifying the driving task into four predefined driving states for the output, the previous algorithm facilitates this aspect significantly.
2.4.1. PID-Based IDM Control Algorithm
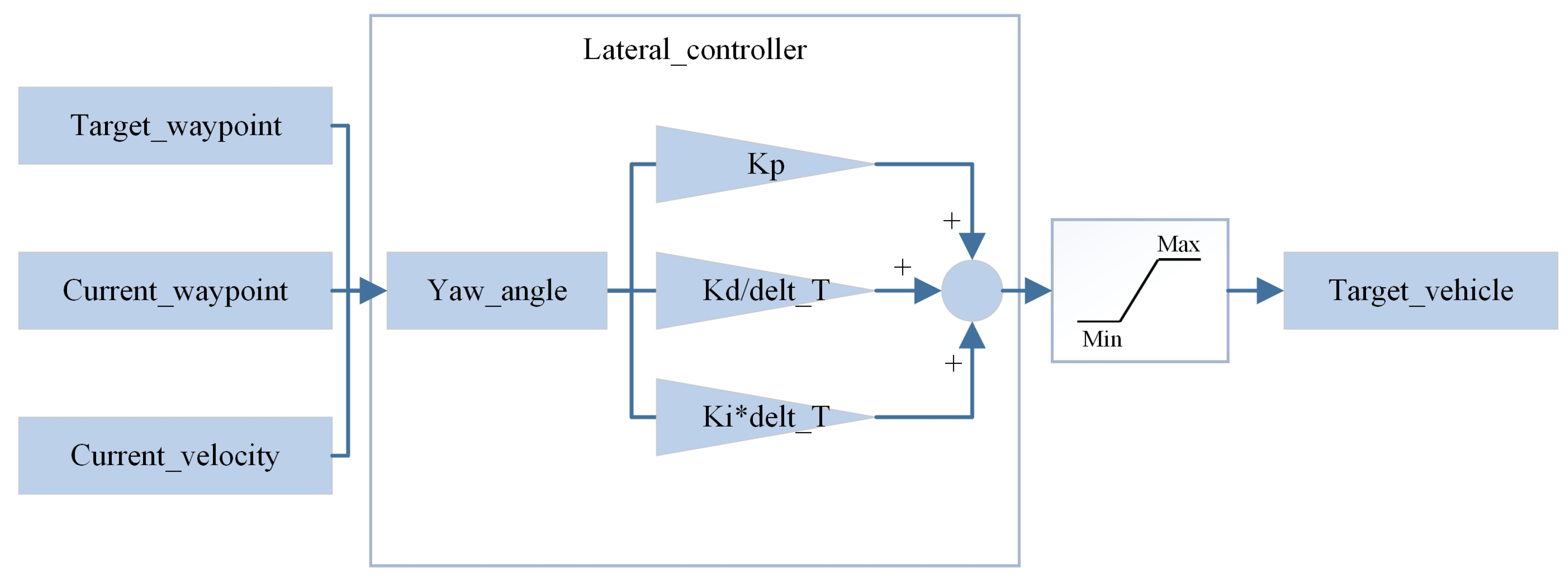
The principle of the PID-based IDM control algorithm mentioned above is illustrated below. The PID control process is divided into two components: lateral control and longitudinal control and generating the steering wheel angle and throttle/brake control signals, respectively, as depicted in
Figure 6 and
Figure 7.
During the experiment, adjusting the parameters of the PID controller is a primary task. Adjusting the PID parameters is an empirical process typically involving experimentation and observing the system’s response. After the first set of PID parameters is stabilized and the agent is controlled to accelerate beyond 50 km/h, it became evident that the control effectiveness was notably compromised. In the case of the speed exceeding 50 km/h, the PID parameters are re-calibrated. The adjustment ensures stable operation in the speed range of 50 to 100 km/h, and the upper limit setting refers to the maximum allowable speed of the Beijing Expressway. Recognizing the direct correlation between vehicle control stability and speed, this paper designates the speed of 50 km/h as the critical point and establishes two different sets of PID parameter configurations, as outlined in
Table 2.
2.4.2. Conventional Driving State
| Algorithm 1. Acceleration Control of the Conventional Driving State
|
| 1. . | |
| 2. | |
| 3. | |
| 4. if | |
| | |
| 5. else | |
| | |
| Algorithm 2. Steering Control of the Conventional Driving State
|
| 1. |
| 2. |
| 3. |
| 4. |
2.4.3. Car-Following State
Target speed: as shown in Algorithm 3.
Throttle control: The throttle and steering wheel angle calculation in this state is completely consistent with that of the conventional driving state, except for the target speed.
| Algorithm 3. Target Speed of Car-Following State
|
| 1. |
| 2. |
| 3. |
| 4. if |
|
| 5. else if |
|
|
| 6. else |
|
2.4.4. Traffic Intersection Driving State
When the vehicle is navigating a traffic intersection environment, there is a higher likelihood of overlapping with the anticipated trajectories of multiple vehicles compared to a conventional environment. Hence, it becomes necessary to reduce the speed. The control algorithm in this mode mirrors the conventional driving state, with the only difference being a reduction in the target speed by 5 km/h.
2.4.5. Emergency Braking State
5. Conclusions
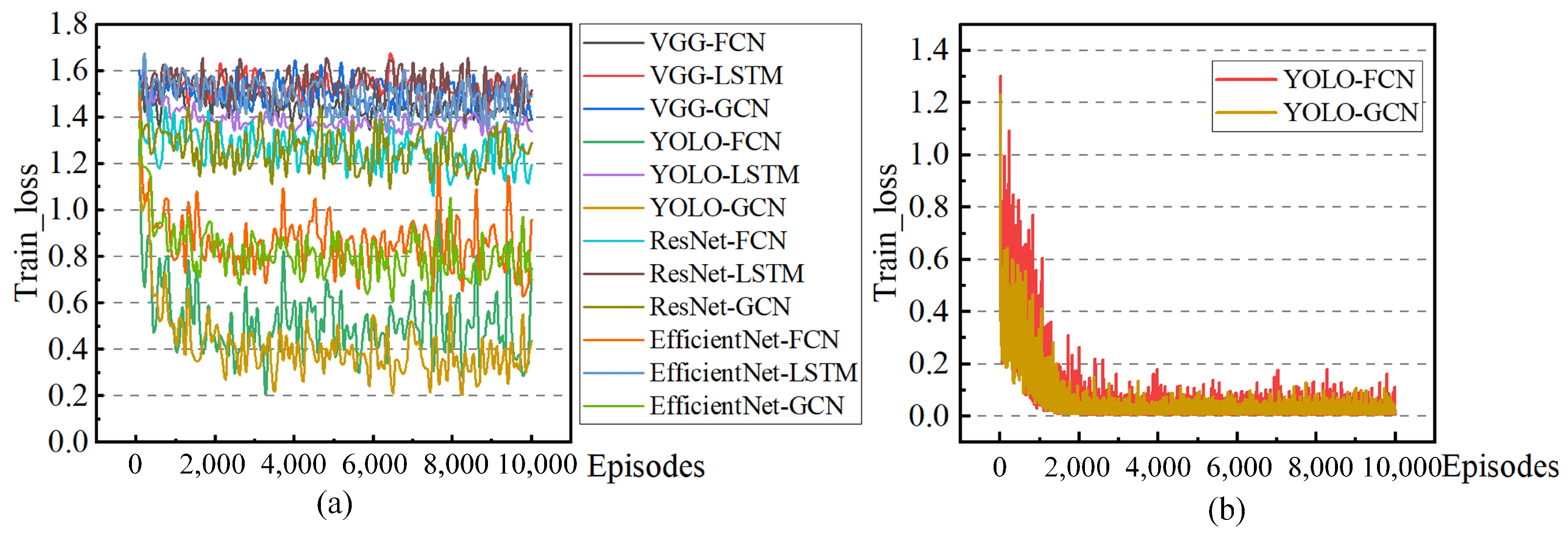
This paper introduces a hierarchical framework for autonomous vehicle driving tasks in non-networked scenarios, which can execute autonomous driving tasks in different environments without relying on global network information. Given the safety constraints of real vehicle experiments, validation experiments based on Carla, which can fully simulate real-world scenarios, represent the most convincing simulation approach currently available. The comparative experiment section validated the effectiveness of each of these innovations individually. The YOLO pre-training model achieved nearly a 90% recognition accuracy for vehicle driving states under identical training conditions. This level of accuracy surpasses what can be achieved by the basic FCN and the well-established VGG16, ResNet50, and EfficientNetB7. Incorporating the time series GCN network resulted in a 2% enhancement in recognition accuracy compared to the non-sequential FCN structure. Additionally, it outperformed the LSTM algorithm significantly in terms of processing timing information.
Indeed, with the current model achieving a prediction accuracy of around 90%, future work could explore the application of additional image preprocessing models to further enhance the prediction accuracy and overall performance of the autonomous driving algorithm. Investing in a more robust training hardware platform and allocating ample model training time can contribute to achieving superior training results. Additionally, incorporating actual vehicle experiments could provide a more thorough validation of the algorithm’s effectiveness in real-world scenarios. To directly validate the model algorithm, actual vehicle experiments can be arranged for direct verification once the security of the future algorithm is further improved.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}