
An Aerial Image Detection Algorithm Based on Improved YOLOv5

Abstract
:1. Introduction
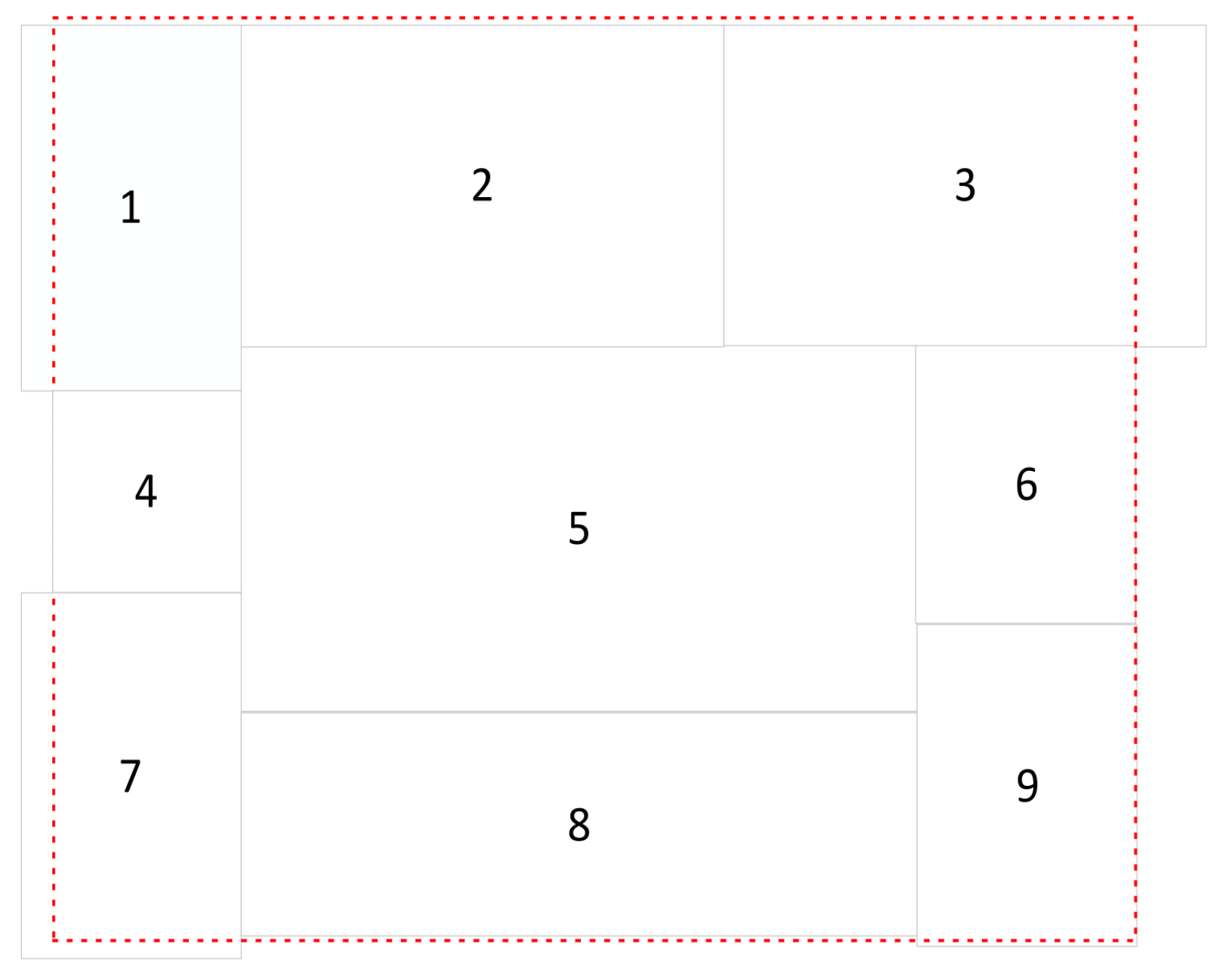
- We propose an improved Mosaic algorithm to solve the redundant black-and-white boundary problem due to the different scales of the pictures.
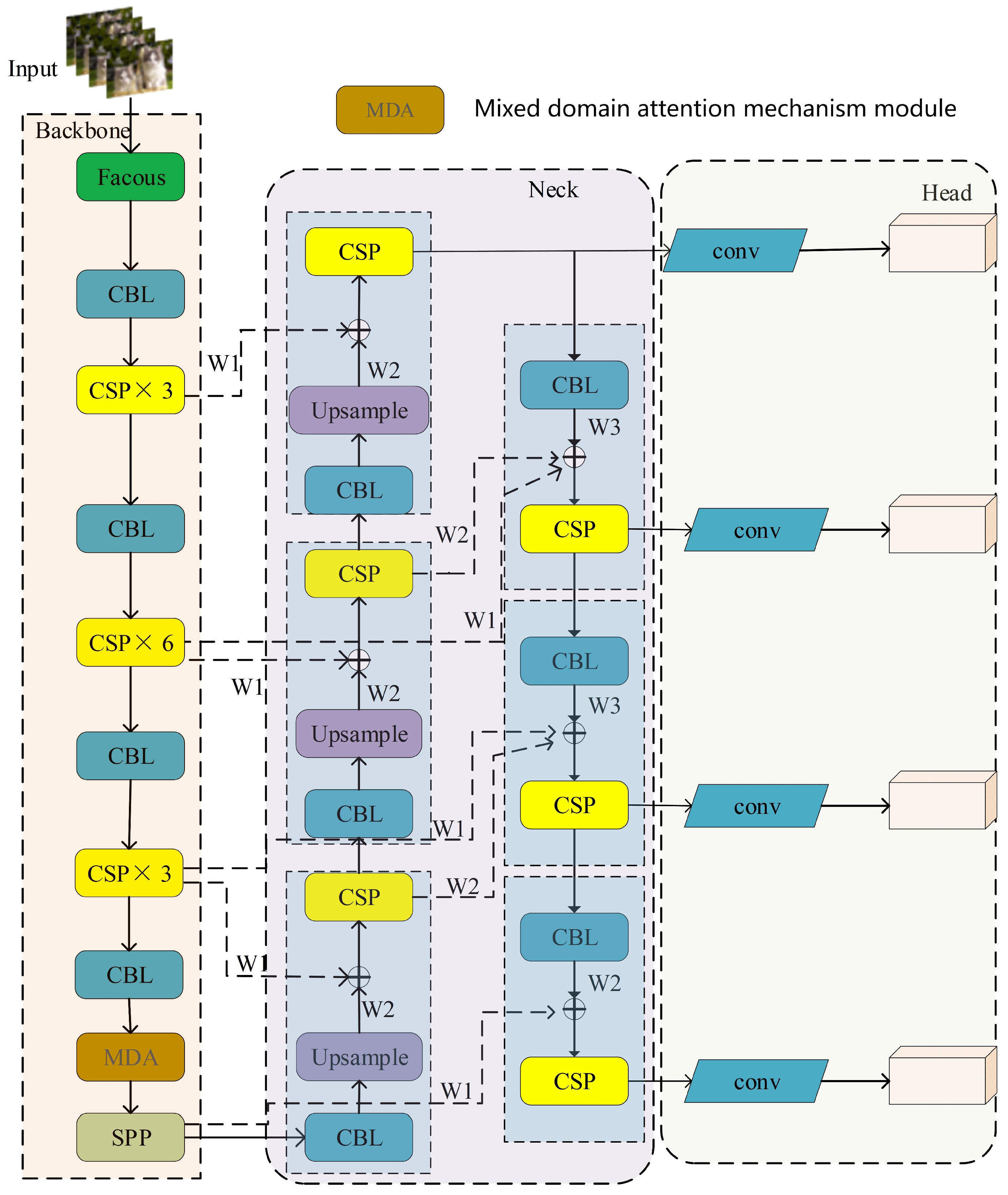
- The hybrid domain attention module is added to the backbone network to improve the ability of feature extraction
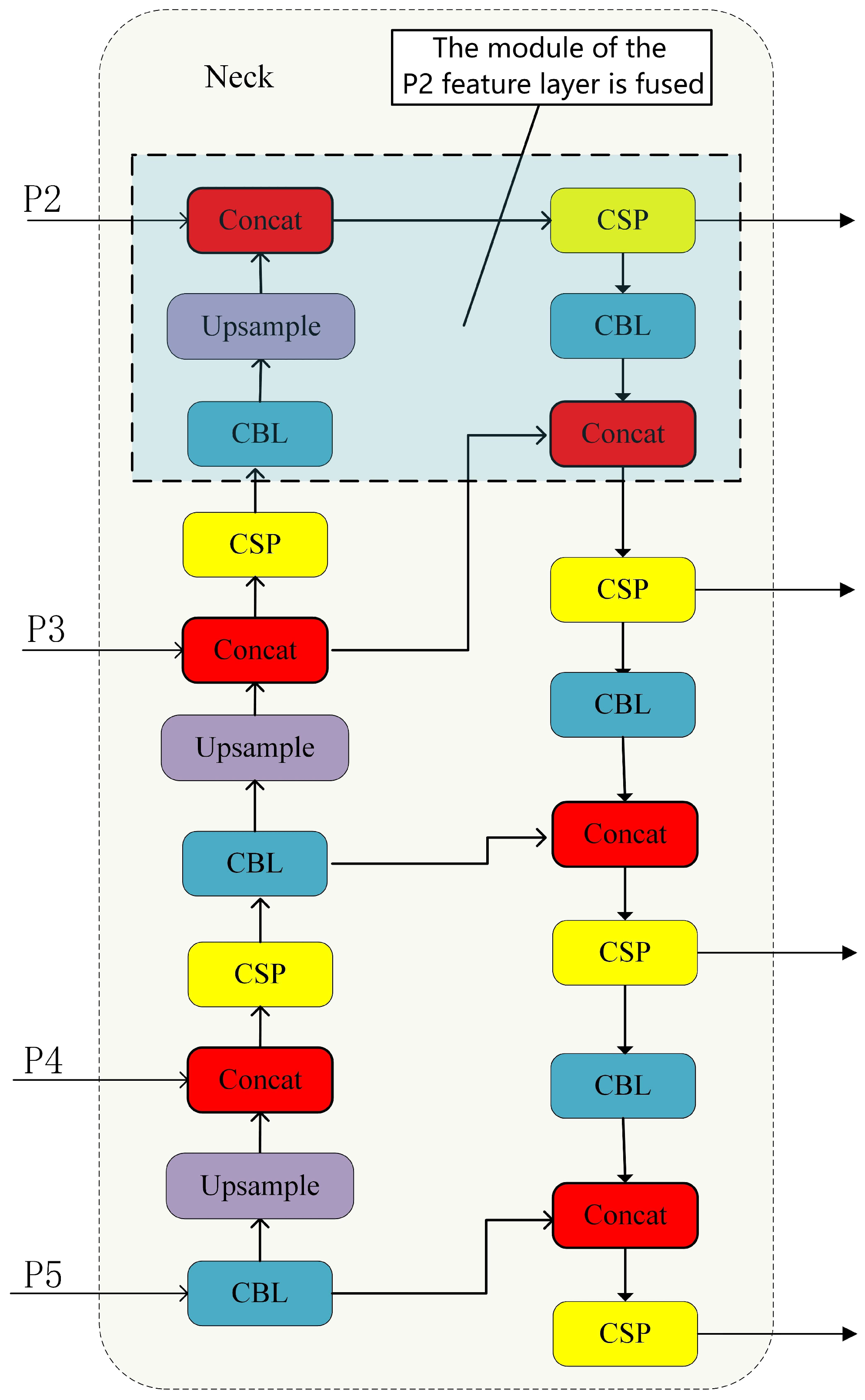
- The feature fusion layer fused with P2 is added to the neck network, and the improved BiFPN network structure is adopted to improve the detection accuracy and network robustness.
- Finally, the VisDrone [16] dataset is used for detection, and it is experimentally proved that the improved algorithm improves the mAP by 6.1% compared with the original algorithm while meeting the real-time requirements.
2. The Principle of YOLOv5 Algorithm
3. Improvements to the YOLOv5 Algorithm
- Data Preprocessing: The Mosaic algorithm is enhanced by aggregating nine images instead of four, thereby enhancing the model’s generalization and robustness.
- Efficient Feature Extraction: The final CSP module of the backbone network is substituted with a hybrid-domain attention module to enable a more efficient extraction of meaningful feature information from the images.
- Small Object Detection: To address the challenge of accurately detecting numerous small objects in aerial images, a prediction branch with a feature fusion layer incorporating P2 features is specifically added for small object detection.
- Robustness Enhancement: To mitigate the loss of deep semantic information resulting from the incorporation of the small object detection layer, the FPN + PANet structure of the feature fusion network is eliminated. Instead, a simplified BiFPN [24] network structure is introduced to enhance the robustness of the network.
3.1. Improvements to Mosaic Algorithm
- Increased diversity: By splicing more images together, the model can expose itself to a wider range of background and contextual information during a single training session. This aids the model in acquiring a greater diversity of features, thereby enhancing its ability to generalize across various aerial image scenarios.
- Enriching the target distribution: More spliced images result in more target instances and a more comprehensive target distribution. This assists the model in better understanding the characteristics of the target, such as shape, size, orientation, and occlusion, thereby enhancing detection performance.
- Possible increase in noise: However, increasing the number of stitched images may also introduce more noise and interference. If there are significant disparities between the spliced images or if they are not spliced in a rational manner, it may cause the model to incorporate some extraneous noise features, potentially impeding its generalization ability.
- Increased computation: Stitching together more images results in larger input sizes and more complex computational graphs. This results in a greater computational demand for each iteration, consequently prolonging the training duration.
- Elevated memory demands: Larger input sizes and more complex computational graphs correspondingly escalate the memory requirements of the model. In the case of limited hardware resources, certain optimization measures may prove necessary, such as reducing the batch size or implementing more efficient computational strategies.
- Requirement for hardware acceleration: To address this heightened demand for computation and memory, it may be necessary to utilize more potent GPUs or other hardware accelerators to expedite the training process.
3.2. Improvements to the Backbone Network
- Computational efficiency:
- Parallelized processing: Hybrid attention modules are typically designed to be lightweight in order to enhance model performance while imposing minimal computational overhead. Certain efficient implementations enable parallel computation of channel attention and spatial attention, thereby fully leveraging hardware resources and reducing computation time.
- Optimization strategies: The integration of hybrid attention modules can further enhance computational efficiency through various optimization techniques, including depth-separable convolution, group convolution, or low-rank decomposition, aimed at reducing the number of parameters and computational complexity.
- Dynamic adjustment: The hybrid attention module can also be dynamically adjusted based on the input feature map’s dynamic characteristics to avoid unnecessary computation. For instance, for simpler inputs, the model may require less attention computation to achieve optimal performance.
- Validity:
- Feature selection: The hybrid attention module effectively focuses on crucial features in both channel and spatial dimensions, enhancing the model’s ability to capture key information in complex scenes and improving target recognition accuracy.
- Robustness Improvement: Through adaptive adjustment in feature map weights, the hybrid attention module enhances the model’s robustness to various noises and interferences, which is particularly crucial for target detection tasks in real-world applications [33].
- Performance improvement: Experiments conducted on multiple benchmark datasets demonstrate that integrating the hybrid attention module into the backbone network typically leads to significant improvements in the performance of the target detection model, including metrics such as accuracy, recall, and mAP.
3.3. Neck Network with Fusion of P2 Features
- Better small target detection: By fusing high-resolution features from the P2 layer, the model can better capture and detect small-sized objects in the image.
- Multi-scale information fusion: Combining feature information from different scales can help the model to better deal with scale variations, thus improving detection performance.
- Information richness: Fusing features from different layers can provide the model with richer semantic information and spatial details, which helps to improve detection accuracy and robustness.
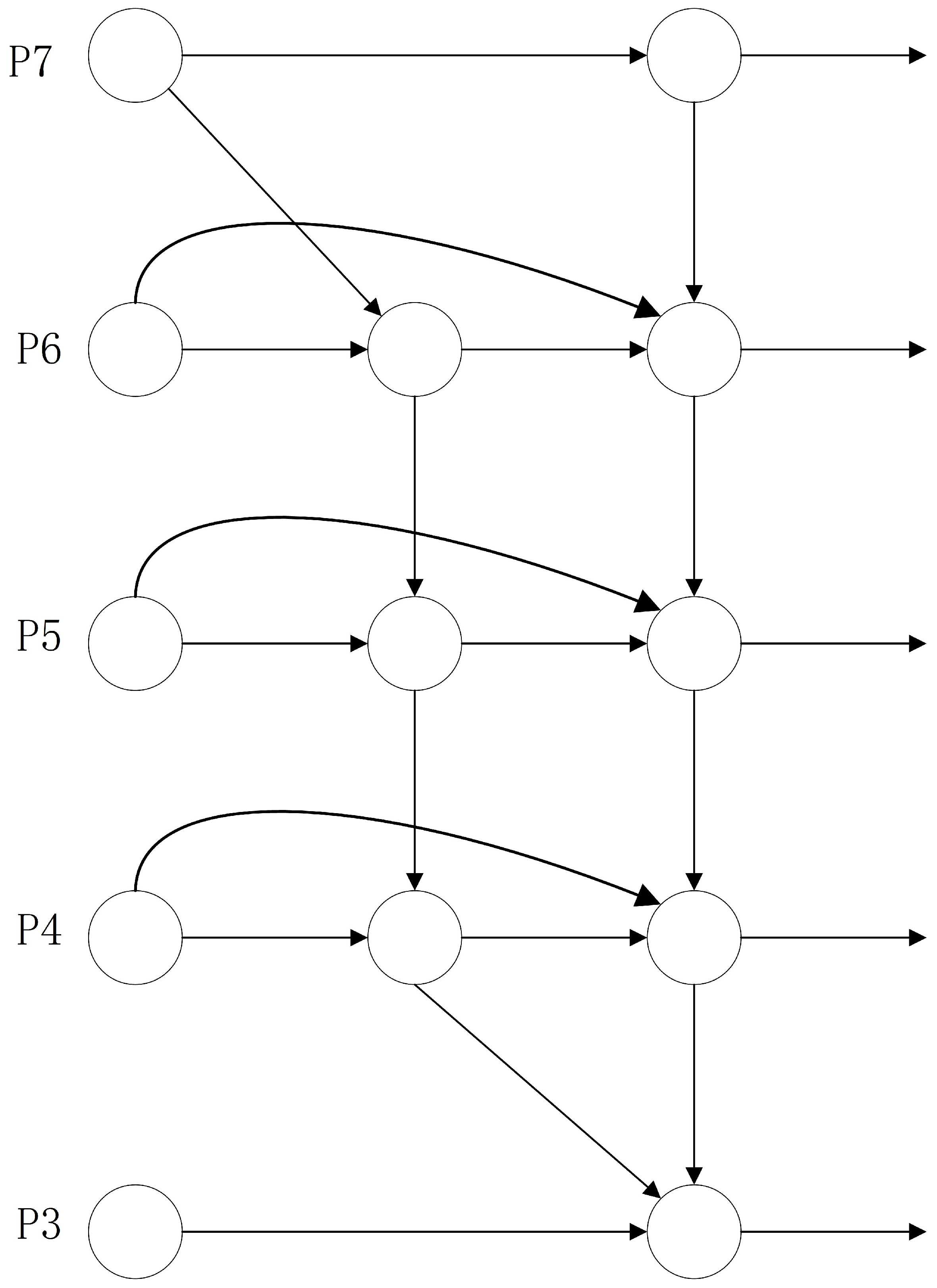
3.4. BiFPN and Its Simplifications
- Elimination of unilateral inputs to reduce computational complexity.
- Incorporation of residual connections for feature layers at the same scale to enhance feature representation capability.
- Allocation of a weight to each feature layer involved in fusion, indicating their respective contributions to the fusion process.
- Cross-scale connectivity optimization: The BiFPN facilitates more comprehensive feature integration between different layers through top-down and bottom-up pathways, in contrast to traditional FPNs and PANs, which primarily employ top-down feature propagation. The optimized BiFPN enhances these cross-scale connections, thereby improving feature fusion efficiency.
- Weighted feature fusion: BiFPN introduces learnable weights for each connected edge, enabling the model to dynamically adjust fusion based on different features. This weighted approach optimizes the fusion effect of multi-scale features, enhancing the accuracy of feature representation. In an optimized BiFPN, these weights may be fine-tuned using more refined training strategies or regularization methods.
- Removal of redundant feature layers: Reducing the complexity and computational burden of the model can be achieved by eliminating one feature layer in the BiFPN and concentrating on fusing the P2–P5 feature layers. This decision preserves the most critical feature layers while eliminating those that may have less impact on performance.
- Fusion strategy adjustment: When integrating the P2–P5 feature layers, various fusion strategies can be employed, including element-wise summation, element-wise product, or channel cascading. The optimized BiFPN may select the fusion strategy most suitable for the task to maximize the impact of feature fusion.
4. Experiments and Results Analysis
4.1. UAV Aerial Dataset
4.2. Experimental Environment and Training Methods
4.3. Ablation Experiments
4.4. Comparative Experiments
4.5. Demonstration of Experimental Results
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ji, X.; Shi, Y.; Wang, Y.; Tian, X. D-S theory multi-classifier fusion optical remote sensing image multi-target recognition. J. Electron. Meas. Instrum. 2020, 34, 127–132. [Google Scholar]
- Wang, L.; Xiang, L.; Tang, L.; Jiang, H. A Convolutional Neural Network-Based Method for Corn Stand Counting in the Field. Sensors 2021, 21, 507. [Google Scholar] [CrossRef]
- Li, Z.; Li, J.; Zhang, X.; Peng, X. Optimal grasping attitude detection method for robots based on deep learning. Chin. J. Sci. Instrum. 2020, 41, 108–117. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, X.; Wang, M.; Yang, L.; Zhuo, L. Coarse-to-fine object detection in unmanned aerial vehicle imagery using lightweight convolutional neural network and deep motion saliency. Neurocomputing 2020, 398, 555–565. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Mecca, A.; Pannone, D.; Piciarelli, C. MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images. Remote Sens. 2021, 13, 1670. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, QC, Canada, 10–17 October 2021; pp. 2778–2788. [Google Scholar]
- Du, Y.; Wan, J.; Zhao, Y.; Zhang, B.; Tong, Z.; Dong, J. GIAOTracker: A Comprehensive Framework for MCMOT with Global Information and Optimizing Strategies in VisDrone 2021. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, QC, Canada, 10–17 October 2021; pp. 2809–2819. [Google Scholar]
- Khan, H.; Huy, B.Q.; Abidin, Z.U.; Yoo, J.; Lee, M.; Seo, K.W.; Hwang, D.Y.; Lee, M.Y.; Suhr, J.K. A Modified YoloV4 Network with Medium-Scale Challenging Benchmark for Efficient Animal Detection. In Proceedings of the Korean Institute of Next Generation Computing, Changwon, Republic of Korea, June 2023; pp. 183–186. [Google Scholar]
- Huang, T.; Zhu, J.; Yao, L.; Yu, T. UAV aerial image target detection based on BLUR-YOLO. Remote Sens. Lett. 2023, 14, 186–196. [Google Scholar] [CrossRef]
- Du, D.; Wen, L.; Zhu, P.; Fan, H.; Hu, Q.; Ling, H.; Shah, M.; Pan, J.; Axenopoulos, A.; Schumann, A.; et al. VisDrone-DET2020: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 692–712. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode; ChristopherSTAN; Liu, C.; Laughing; Tkianai; YxNONG; Hogan, A.; et al. ultralytics/yolov5: V4.0-nn.SiLU() Activations, Weights & Biases Logging, PyTorch Hub Integration, 2021, Software Version v4.0, Zenodo, Online platform. 2021. Available online: https://ui.adsabs.harvard.edu/abs/2021zndo...4418161J(accessed on 5 January 2021). [CrossRef]
- Ultralytics. YOLOv5: Object Detection. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2020).
- Chen, Z.; Wu, R.; Lin, Y.; Li, C.; Chen, S.; Yuan, Z.; Chen, S.; Zou, X. Plant Disease Recognition Model Based on Improved YOLOv5. Agronomy 2022, 12, 365. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, B.; Peng, J.; Zhang, Z. Research on the Use of YOLOv5 Object Detection Algorithm in Mask Wearing Recognition. World Sci. Res. J. World Sci. Res. J. 2020, 6, 276–284. [Google Scholar]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Y.; Yi, P.; Zhou, D.; Yang, X.; Yang, D.; Zhang, Q.; Wei, X. CSANet: Channel and Spatial Mixed Attention CNN for Pedestrian Detection. IEEE Access 2020, 8, 76243–76252. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Sun, G.; Wang, S.; Xie, J. An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5. Electronics 2023, 12, 1515. [Google Scholar] [CrossRef]
- Khan, H.; Hussain, T.; Khan, S.U.; Khan, Z.A.; Baik, S.W. Deep multi-scale pyramidal features network for supervised video summarization. Expert Syst. Appl. 2024, 237, 121288. [Google Scholar] [CrossRef]
- Chen, J.; Mai, H.; Luo, L.; Chen, X.; Wu, K. Effective Feature Fusion Network in BIFPN for Small Object Detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 699–703. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. SAR Ship Detection Based on YOLOv5 Using CBAM and BiFPN. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 2147–2150. [Google Scholar] [CrossRef]
- He, L.; Wei, H.; Wang, Q. A New Target Detection Method of Ferrography Wear Particle Images Based on ECAM-YOLOv5-BiFPN Network. Sensors 2023, 23, 6477. [Google Scholar] [CrossRef]
- Khan, H.; Ullah, M.; Al-Machot, F.; Cheikh, F.A.; Sajjad, M. Deep learning based speech emotion recognition for Parkinson patient. Image 2023, 298, 2. [Google Scholar] [CrossRef]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection. arXiv 2021, arXiv:2103.09136. [Google Scholar] [CrossRef]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Leng, J.; Mo, M.; Zhou, Y.; Gao, C.; Li, W.; Gao, X. Pareto Refocusing for Drone-View Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1320–1334. [Google Scholar] [CrossRef]
- Muzammul, M.; Algarni, A.; Ghadi, Y.Y.; Assam, M. Enhancing UAV Aerial Image Analysis: Integrating Advanced SAHI Techniques with Real-Time Detection Models on the VisDrone Dataset. IEEE Access 2024, 12, 21621–21633. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP (0.5) | GFLOPs | FPS (Frame/s) | Quantity of Participants (M) |
|---|---|---|---|---|
| YOLOv5l | 46.4% | 109.3 | 89.65 | 46.56 |
| Mosaic improvements | 47.4% | 109.3 | 89.34 | 46.56 |
| Backbone network improvements | 48.5% | 109.5 | 88.12 | 46.69 |
| Addition of P2 layer | 50.9% | 140.5 | 82.33 | 52.76 |
| Fusion BiFPN | 52.5% | 152.1 | 80.12 | 54.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, D.; Yang, Z.; Wang, X.; Meng, X.; Zhang, G. An Aerial Image Detection Algorithm Based on Improved YOLOv5. Sensors 2024, 24, 2619. https://doi.org/10.3390/s24082619
Shan D, Yang Z, Wang X, Meng X, Zhang G. An Aerial Image Detection Algorithm Based on Improved YOLOv5. Sensors. 2024; 24(8):2619. https://doi.org/10.3390/s24082619
Chicago/Turabian StyleShan, Dan, Zhi Yang, Xiaofeng Wang, Xiangdong Meng, and Guangwei Zhang. 2024. "An Aerial Image Detection Algorithm Based on Improved YOLOv5" Sensors 24, no. 8: 2619. https://doi.org/10.3390/s24082619
APA StyleShan, D., Yang, Z., Wang, X., Meng, X., & Zhang, G. (2024). An Aerial Image Detection Algorithm Based on Improved YOLOv5. Sensors, 24(8), 2619. https://doi.org/10.3390/s24082619