
Emotion Classification Based on Pulsatile Images Extracted from Short Facial Videos via Deep Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- In this study, we used a DL-based classification model that achieved an overall accuracy of 47.36% using a single input feature map that can be obtained from a regular RGB camera, which has improved upon the previous work that achieved an overall accuracy of 44% that was trained with a block of seven input feature maps obtained from multispectral signals that also included the thermal and the NIR cameras. This means a better applicability in terms of the cost and complexity of the setup.
- Unlike the previous work, here we achieve an estimated heart rate by first performing skin region segmentation, which effectively focuses only on the area of interest and provides more reliable results in estimating the heart rate.
- In the previous work, the heartbeat signal’s peaks and troughs were determined from raw temporal local video signals using a peak detection algorithm with two thresholds. Here, peak and trough detection is obtained from extracted pulsatile signals, after applying a band pass filter, as in a basic PPG measurement system [23]. This approach provides more accurate detection.
- Furthermore, an increased spatial resolution of the physiological features inserted into the classifier has the potential to capture information about micro-expressions.
2. Dataset Formation and Management
3. Method
3.1. Initial Processing and Heart Rate Estimation
3.1.1. Facial ROI Cropping
3.1.2. Skin Segmentation
3.1.3. Removing Video Records with Head Movements
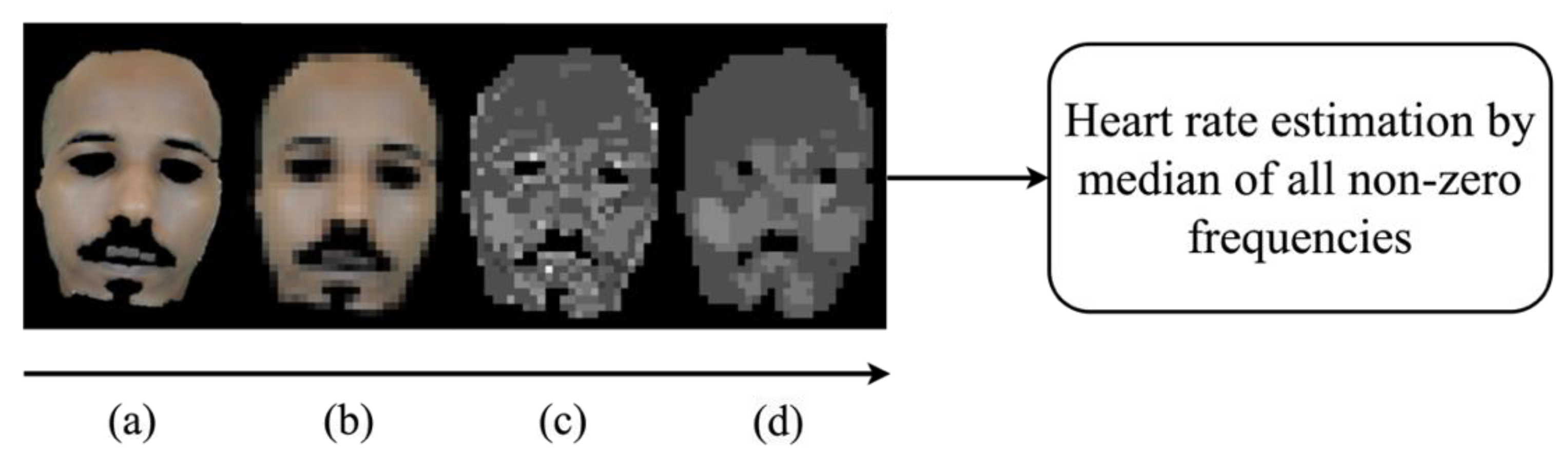
3.1.4. Estimation of Heart Rate
3.2. Physiological Feature Extraction Process
3.2.1. Reshaping to Fixed Image Sizes and Noisiness Reduction
3.2.2. Pulsatile Signal Peaks and Troughs Detection
3.2.3. Physiological Feature Formation
- Maximum signal amplitude (at the peaks): pixel’s gray level during the diastolic phase for wavelength (arterial diameters are minimized; thus, absorbance is minimized while the amount of light detected is maximized) => .
- Minimum signal amplitude (at the troughs): pixel’s gray level during the systolic phase for wavelength (arterial diameters are maximized; thus, absorbance is maximized while the amount of light detected is minimized) => .Based on the above pulsatile images, the following features, found to be the most effective for emotion classification, were used in this study.
- The amplitude of the pulsatile signal iswhere
- The absorption amplitude that eliminates the effect of static absorbers iswhere
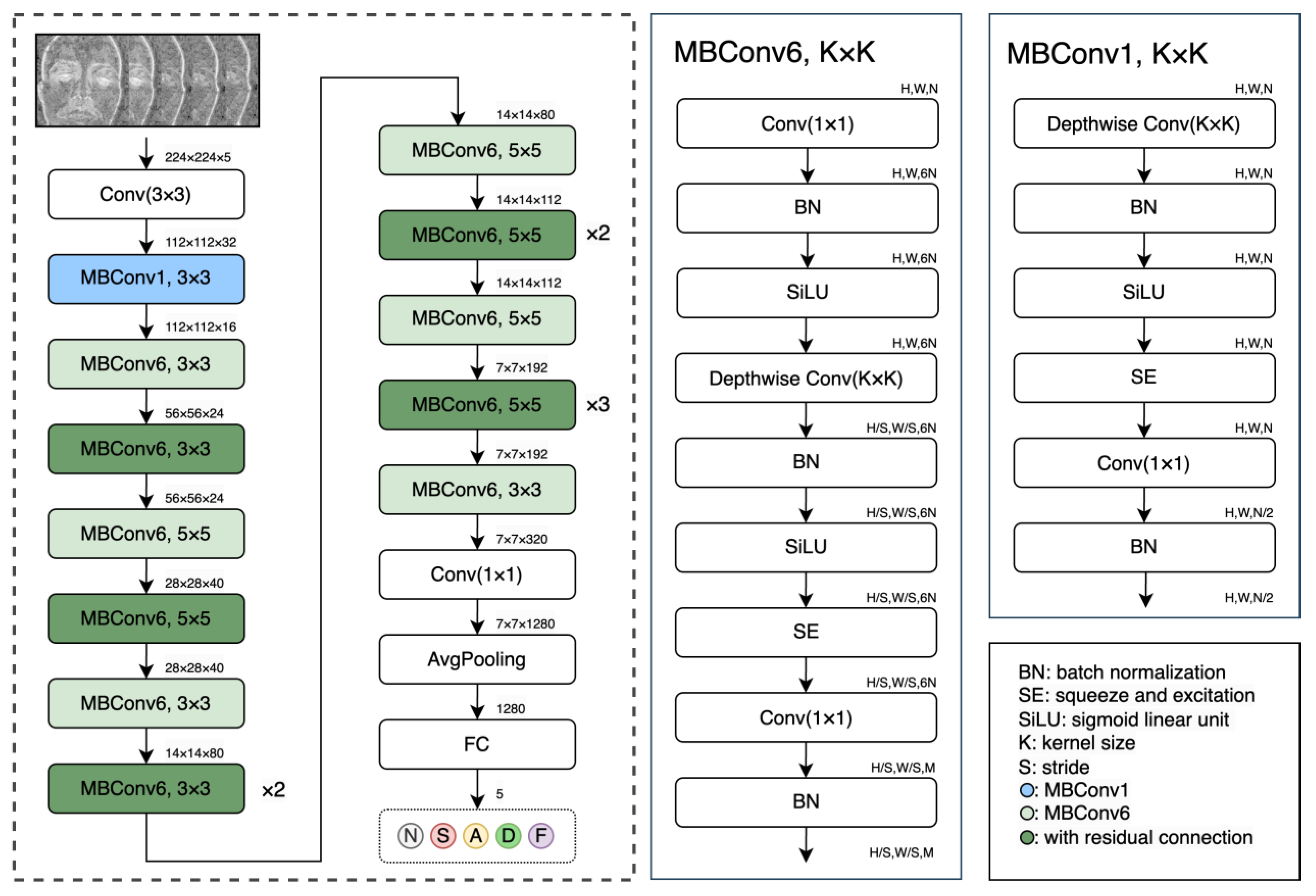
3.3. Emotion Classification Models
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Šimić, G.; Tkalčić, M.; Vukić, V.; Mulc, D.; Španić, E.; Šagud, M.; Olucha-Bordonau, F.E.; Vukšić, M.; Hof, P.R. Understanding Emotions: Origins and Roles of the Amygdala. Biomolecules 2021, 11, 823. [Google Scholar] [CrossRef]
- Chowdary, K.; Nguyen, T.; Hemanth, D.J. Deep learning-based facial emotion recognition for human–computer interaction applications. Neural Comput. Appl. 2021, 35, 23311–23328. [Google Scholar] [CrossRef]
- Canal, F.Z.; Müller, T.R.; Matias, J.C.; Scotton, G.G.; Junior, A.R.d.S.; Pozzebon, E.; Sobieranski, A.C. A survey on facial emotion recognition techniques: A state-of-the-art literature review. Inf. Sci. 2022, 582, 593–617. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Jawad, M.; Ebrahimi-Moghadam, A. Speech Emotion Recognition: A Comprehensive Survey. Wirel. Pers. Commun. 2023, 129, 2525–2561. [Google Scholar] [CrossRef]
- Kreibig, S.D. Autonomic nervous system activity in emotion: A review. Biol. Psychol. 2010, 84, 394–421. [Google Scholar] [CrossRef]
- Levenson, R.W. The Autonomic Nervous System and Emotion. Emot. Rev. 2014, 6, 100–112. [Google Scholar] [CrossRef]
- Lin, W.; Li, C. Review of Studies on Emotion Recognition and Judgment Based on Physiological Signals. Appl. Sci. 2023, 13, 2573. [Google Scholar] [CrossRef]
- Phan, K.L.; Wager, T.; Taylor, S.F.; Liberzon, I. Functional Neuroanatomy of Emotion: A Meta-Analysis of Emotion Activation Studies in PET and fMRI. NeuroImage 2002, 16, 331–348. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.S.; Lee, Y.K.; Pae, D.S.; Lim, M.T.; Kim, D.W.; Kang, T.K. Fast Emotion Recognition Based on Single Pulse PPG Signal with Convolutional Neural Network. Appl. Sci. 2019, 9, 3355. [Google Scholar] [CrossRef]
- Molinaro, N.; Schena, E.; Silvvestru, S.; Bonotti, F.; Aguzzi, D.; Viola, E.; Buccolini, F.; Massaroni, C. Contactless Vital Signs Monitoring From Videos Recorded With Digital Cameras: An Overview. Front. Physiol. 2022, 13, 801709. [Google Scholar] [CrossRef]
- Wang, E.J.; Li, W.; Hawkins, D.; Gernsheimer, T.; Norby-Slycord, C.; Patel, S.N. HemaApp: Noninvasive blood screening of hemoglobin using smartphone cameras. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 593–604. [Google Scholar] [CrossRef]
- Baranoski, G.V.G.; Krishnaswamy, A. CHAPTER 4-Bio-Optical Properties of Human Skin. In Light & Skin Interactions; Baranoski, G.V.G., Krishnaswamy, A., Eds.; Morgan Kaufmann: Boston, MA, USA, 2010; pp. 61–79. [Google Scholar] [CrossRef]
- Alhallak, K.; Omran, D.; Tomi, S.; Abdulhafid, A. Skin, Light and their Interactions, an In-Depth Review for Modern Light-Based Skin Therapies. J. Clin. Derm. Ther. 2021, 7, 081. [Google Scholar] [CrossRef]
- Wang, E.J.; Li, W.; Zhu, J.; Rana, R.; Patel, S.N. Noninvasive hemoglobin measurement using unmodified smartphone camera and white flash. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Republic of Korea, 11–15 July 2017; pp. 2333–2336. [Google Scholar] [CrossRef]
- Abdallah, O.; Natsheh, M.; Alam, K.A.; Qananwah, Q.; Nabulsi, A.A.; Bolz, A. Concentrations of hemoglobin fractions calculation using modified Lambert-Beer law and solving of an ill-posed system of equations. In Biophotonics: Photonic Solutions for Better Health Care II; SPIE: Bellingham, WA, USA, 2010; pp. 277–284. [Google Scholar] [CrossRef]
- Shvimmer, S.; Simhon, R.; Gilead, M.; Yitzhaky, Y. Classification of emotional states via transdermal cardiovascular spatiotemporal facial patterns using multispectral face videos. Sci. Rep. 2022, 12, 11188. [Google Scholar] [CrossRef]
- Benezeth, Y.; Li, P.; Macwan, R.; Nakamura, K.; Gomez, R.; Yang, F. Remote heart rate variability for emotional state monitoring. In Proceedings of the 2018 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Las Vegas, NV, USA, 4–7 March 2018; pp. 153–156. [Google Scholar] [CrossRef]
- Mellouk, W.; Handouzi, W. CNN-LSTM for automatic emotion recognition using contactless photoplythesmographic signals. Biomed. Signal Process. Control 2023, 85, 104907. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, K.; Mazhar, S.; Fu, X.; Kong, J. Trusted emotion recognition based on multiple signals captured from video. Expert Syst. Appl. 2023, 233, 120948. [Google Scholar] [CrossRef]
- Zhou, K.; Schinle, M.; Stork, W. Dimensional emotion recognition from camera-based PRV features. Methods 2023, 218, 224–232. [Google Scholar] [CrossRef]
- Liu, J.; Luo, H.; Zheng, P.; Wu, S.J.; Lee, K. Transdermal optical imaging revealed different spatiotemporal patterns of facial cardiovascular activities. Sci. Rep. 2018, 8, 10588. [Google Scholar] [CrossRef]
- Park, J.; Seok, H.S.; Kim, S.-S.; Shin, H. Photoplethysmogram Analysis and Applications: An Integrative Review. Front. Physiol. 2021, 12, 808451. [Google Scholar] [CrossRef]
- Cowen, A.S.; Keltner, D. Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proc. Natl. Acad. Sci. USA 2017, 114, E7900–E7909. [Google Scholar] [CrossRef]
- Ekman, P. Are there basic emotions? Psychol. Rev. 1992, 99, 550–553. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019. [Google Scholar] [CrossRef]
- Wang, W.; den Brinker, A.; Stuijk, S.; Haan, G. Algorithmic Principles of Remote-PPG. IEEE Trans. Biomed. Eng. 2016, 64, 1479–1491. [Google Scholar] [CrossRef]
- de Haan, G.; Jeanne, V. Robust Pulse Rate From Chrominance-Based rPPG. IEEE Trans. Biomed. Eng. 2013, 60, 2878–2886. [Google Scholar] [CrossRef]
- Ray, D.; Collins, T.; Woolley, S.; Ponnapalli, P. A Review of Wearable Multi-Wavelength Photoplethysmography. IEEE Rev. Biomed. Eng. 2023, 16, 136–151. [Google Scholar] [CrossRef]
- Shchelkanova, E.; Shchelkanov, A.; Shchapova, L.; Shibata, T. An Exploration of Blue PPG Signal Using a Novel Color Sensorbased PPG System. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2020, 2020, 4414–4420. [Google Scholar] [CrossRef]
- Simchon, R.; Meiran, N.; Shvimmer, S.; Yitzhaky, Y.; Rosenblatt, J.; Gilad, M. Beyond Valence and Arousal: Distributed facial patterns linked to specific emotions cannot be reduced to core affect. Affect. Sci. 2024. submitted. [Google Scholar]
- Long, N.M.H.; Chung, W.-Y. Wearable Wrist Photoplethysmography for Optimal Monitoring of Vital Signs: A Unified Perspective on Pulse Waveforms. IEEE Photonics J. 2022, 14, 3717717. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. Available online: https://proceedings.mlr.press/v97/tan19a.html (accessed on 4 February 2024).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Gholamiangonabadi, D.; Kiselov, N.; Grolinger, K. Deep Neural Networks for Human Activity Recognition With Wearable Sensors: Leave-One-Subject-Out Cross-Validation for Model Selection. IEEE Access 2020, 8, 133982–133994. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Nice, France, 2019; Available online: https://proceedings.neurips.cc/paper_files/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html (accessed on 4 February 2024).
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020. [Google Scholar] [CrossRef]
- Kosonogov, V.; De Zorzi, L.; Honoré, J.; Martínez-Velázquez, E.S.; Nandrino, J.-L.; Martinez-Selva, J.M.; Sequeira, H. Facial thermal variations: A new marker of emotional arousal. PLoS ONE 2017, 12, e0183592. [Google Scholar] [CrossRef]
- Bradley, M.M.; Codispoti, M.; Cuthbert, B.N.; Lang, P.J. Emotion and motivation I: Defensive and appetitive reactions in picture processing. Emotion 2001, 1, 276–298. [Google Scholar] [CrossRef]
- Lang, P.J.; Bradley, M.M. Emotion and the motivational brain. Biol. Psychol. 2010, 84, 437–450. [Google Scholar] [CrossRef]
- Mirabella, G.; Grassi, M.; Mezzarobba, S.; Bernardis, P. Angry and happy expressions affect forward gait initiation only when task relevant. Emotion 2023, 23, 387–399. [Google Scholar] [CrossRef]
- Montalti, M.; Mirabella, G. Unveiling the influence of task-relevance of emotional faces on behavioral reactions in a multi-face context using a novel Flanker-Go/No-go task. Sci. Rep. 2023, 13, 20183. [Google Scholar] [CrossRef]
- Dupré, D.; Krumhuber, E.G.; Küster, D.; McKeown, G.J. A performance comparison of eight commercially available automatic classifiers for facial affect recognition. PLoS ONE 2020, 15, e0231968. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talala, S.; Shvimmer, S.; Simhon, R.; Gilead, M.; Yitzhaky, Y. Emotion Classification Based on Pulsatile Images Extracted from Short Facial Videos via Deep Learning. Sensors 2024, 24, 2620. https://doi.org/10.3390/s24082620
Talala S, Shvimmer S, Simhon R, Gilead M, Yitzhaky Y. Emotion Classification Based on Pulsatile Images Extracted from Short Facial Videos via Deep Learning. Sensors. 2024; 24(8):2620. https://doi.org/10.3390/s24082620
Chicago/Turabian StyleTalala, Shlomi, Shaul Shvimmer, Rotem Simhon, Michael Gilead, and Yitzhak Yitzhaky. 2024. "Emotion Classification Based on Pulsatile Images Extracted from Short Facial Videos via Deep Learning" Sensors 24, no. 8: 2620. https://doi.org/10.3390/s24082620
APA StyleTalala, S., Shvimmer, S., Simhon, R., Gilead, M., & Yitzhaky, Y. (2024). Emotion Classification Based on Pulsatile Images Extracted from Short Facial Videos via Deep Learning. Sensors, 24(8), 2620. https://doi.org/10.3390/s24082620