
Enhanced Lightweight YOLOX for Small Object Wildfire Detection in UAV Imagery


Abstract
:1. Introduction
- Designing a multi-level-feature-extraction structure CSP-ML to improve the detection accuracy of the algorithm for small-target-fire areas.
- Optimizing the neck network structure by embedding the CBAM attention mechanism to reduce the interference caused by background noise and irrelevant information.
- Optimizing the YOLOX network-feature-fusion mechanism by introducing an adaptive-feature-extraction module to avoid problems such as the loss of important feature information during the feature-fusion process and enhance the feature-learning ability of the network.
- Adopting the CIoU loss function to replace the original loss function, improving the problems of excessive optimization of negative samples and poor gradient-descent direction in the original function, and strengthening the effective recognition of positive samples by the network.
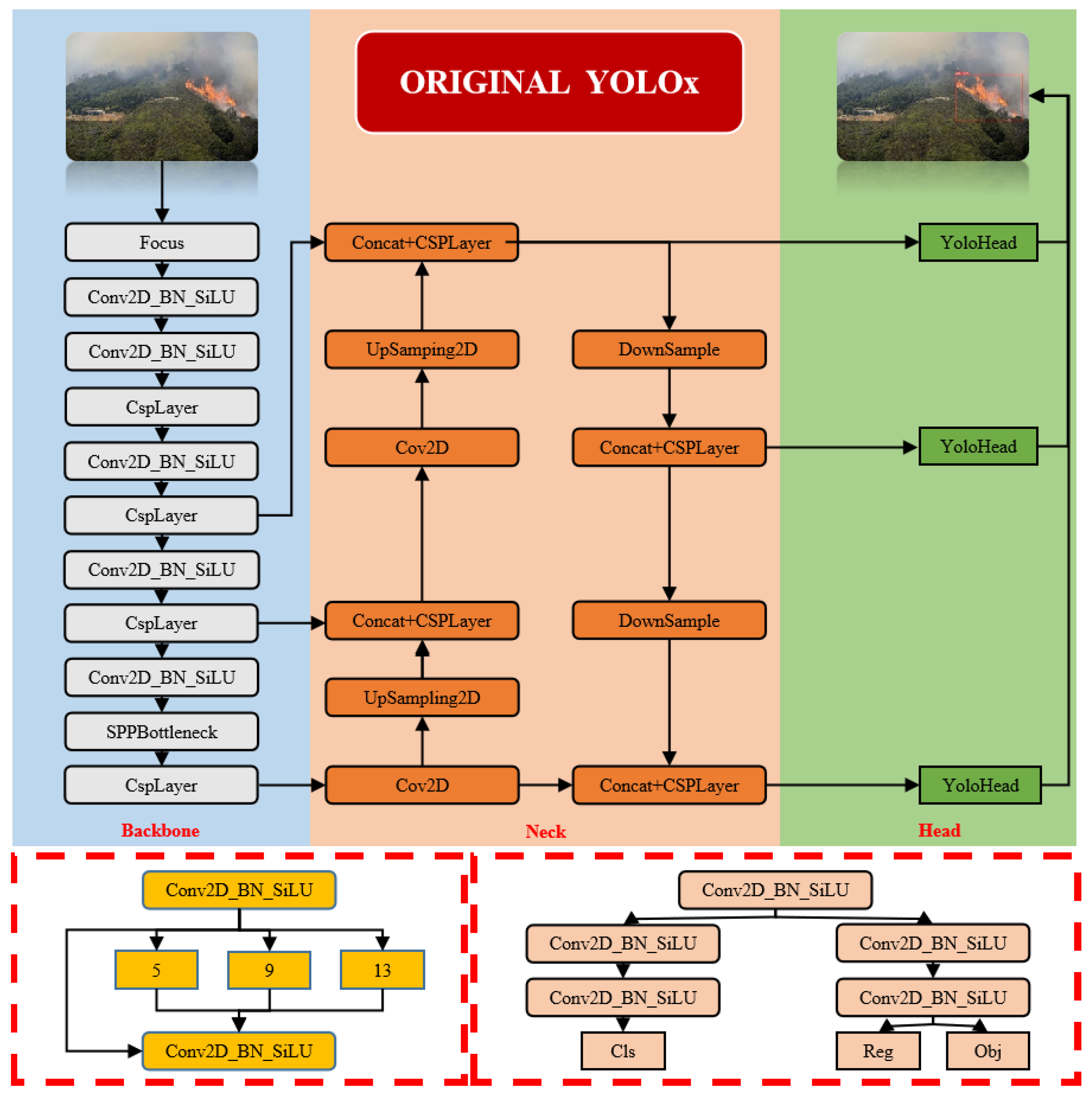
2. The YOLOX Network Architecture
- UAV aerial images cover wide areas with abundant miscellaneous information and a high proportion of small, dense targets, which complicates feature extraction such that critical fire-scene information may be overlooked by the model.
- The background information in fire scenes is complex. In UAV images, the distribution of positive sample information, such as flames and smoke, against background elements like trees, mountains, and skies, is uneven. The original structure’s IoU loss cannot balance positive and negative samples adequately, instead over-optimizing for negative samples and neglecting positive sample recognition and severely impacting detection accuracy.
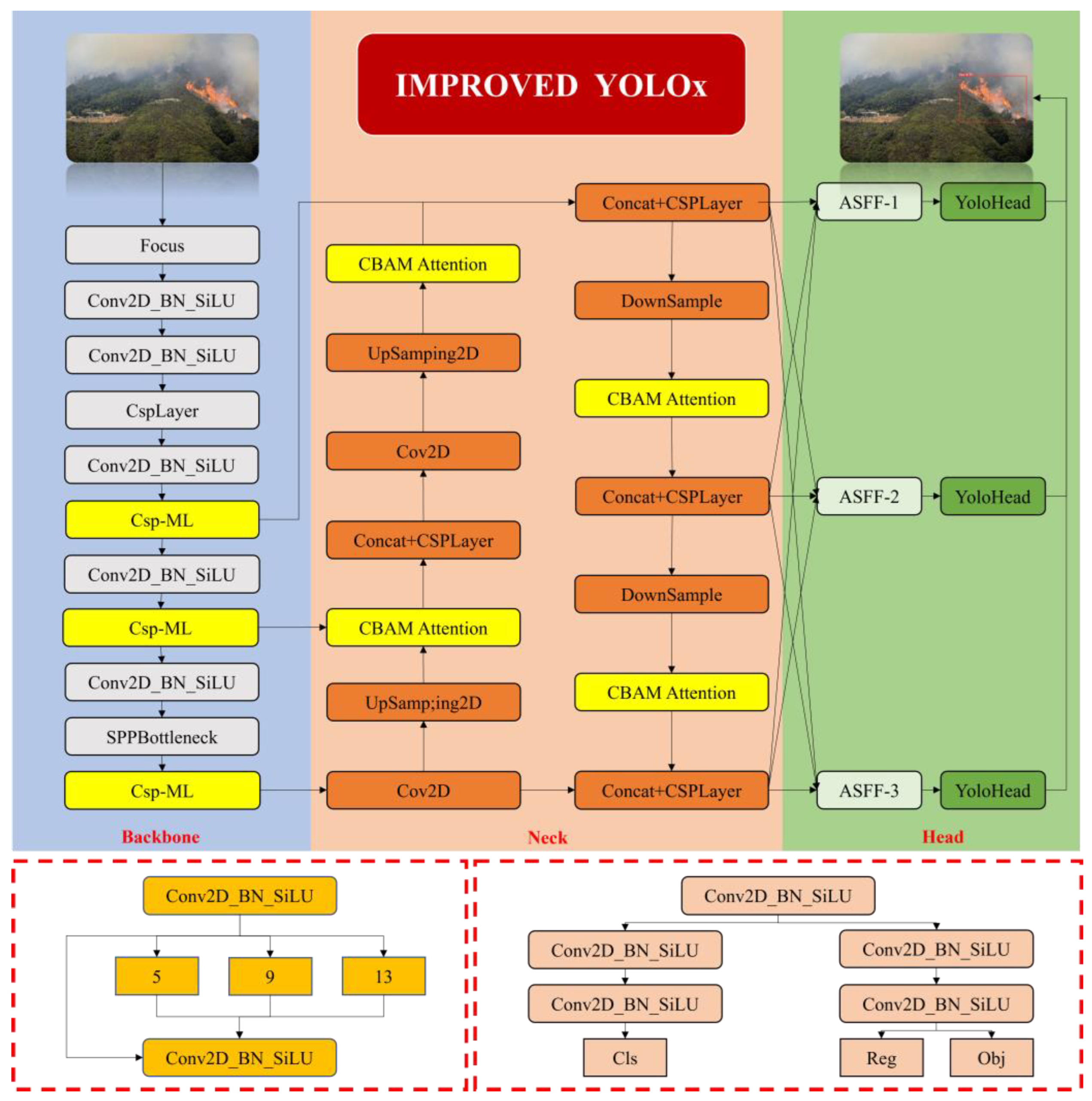
3. Improvements and Optimization Network
3.1. Multi-Level-Feature-Extraction Structure: CSP-ML
3.2. Attention Mechanism: CBAM
3.3. Feature Fusion: ASFF

3.4. Improved Loss Function
4. Experimental Results and Analysis
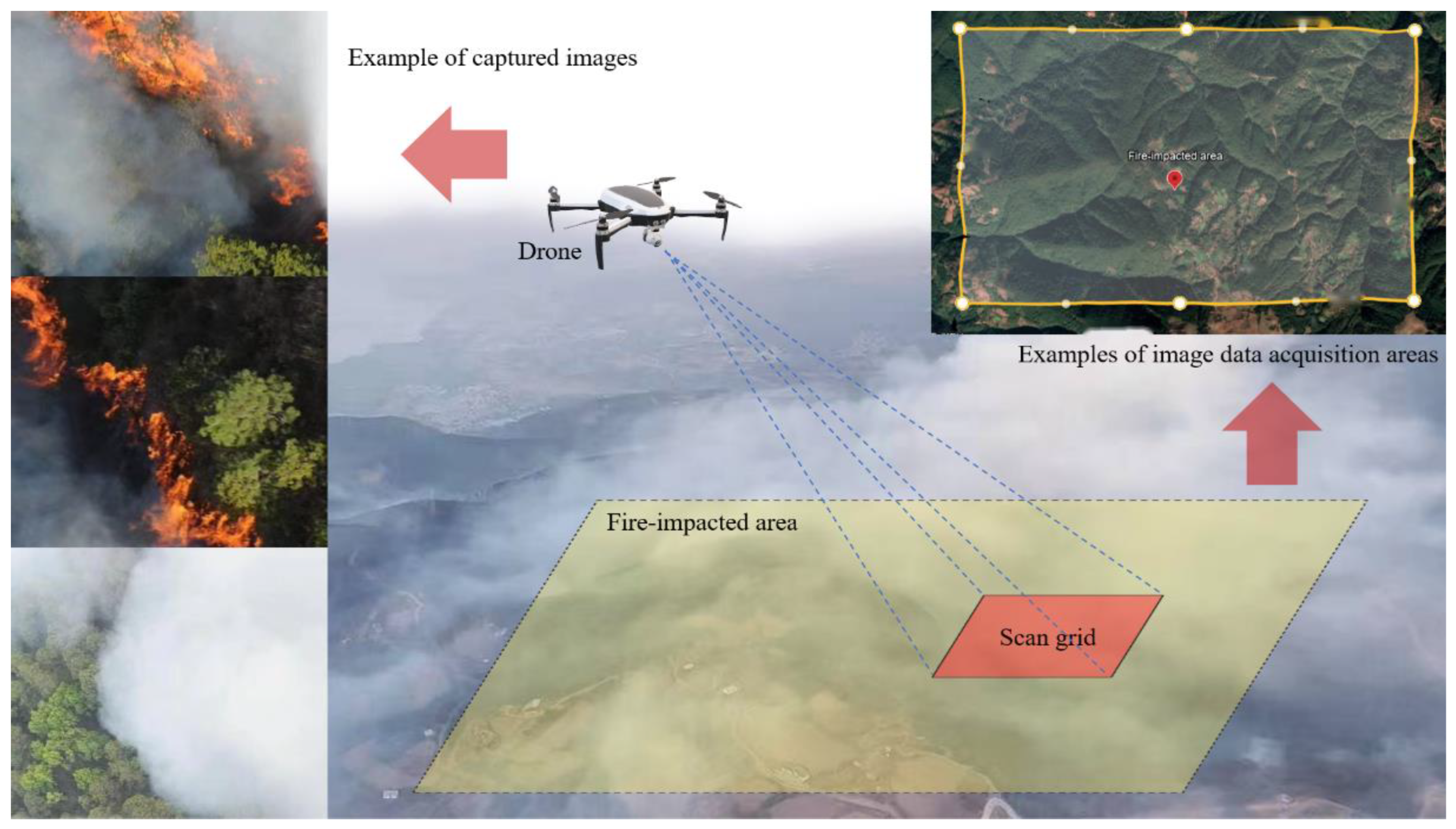
4.1. Experimental Dataset
- Convert the input RGB images into single-channel grayscale images and apply Gaussian blur for filtering.
- Randomly change the height and width of input images, allowing the dimensions of a single image to vary in multiple ratios.
- Rotate the input images to several different angles.
4.2. Experimental Environment
4.3. Evaluation Metrics
- Precision: This is a fundamental metric for measuring the performance of a model in classification tasks. It represents the ratio of correctly identified positive samples to all positive samples detected by the model. The calculation process is shown in Equation (12):
- Recall: Recall refers to the ratio of true positive samples correctly detected by the model to all positive samples in the dataset. The calculation process is illustrated as follows:
- F1-score: The F1-score is the harmonic mean of precision and recall, which serves as a comprehensive indicator of the model’s accuracy and robustness. The calculation process for the F1-score is as follows:
- AP (Average Precision): AP represents the average of precision values across all levels of recall for a specific category, reflecting the overall accuracy of the model’s detection performance on that category. The calculation process is outlined as follows:
- mAP (mean Average Precision): mAP is the mean of the AP (Average Precision) values across all categories, and it offers a comprehensive measure of the model’s performance across all classes. If there are N classes, then mAP can be calculated as follows:
- FPS: Frame Per Second is one of the key indicators for evaluating the real-time performance of an algorithm, and it represents the number of frames an algorithm can process per second. In real-time video image processing applications, FPS directly relates to the system’s response speed and processing capability for continuous video streams or image sequences. Conventional UAV monitoring platforms or fire-monitoring towers equipped with image acquisition devices typically have a video frame rate of 30 fps. For autonomous driving or high-speed-moving-target-capture scenarios, the video fps can reach 60 fps. In engineering applications, an FPS ≥ 5 is generally sufficient to meet the recognition criteria requirements [30]. To meet the target monitoring requirements in real mountain-fire scenarios, this paper selects the higher value among the aforementioned metrics. Specifically, when the algorithm processes images with a resolution of 1200 × 800 and achieves an FPS ≥ 60, it satisfies the real-time-target-detection standard.
- Model size: Model size refers to the amount of storage space occupied by the YOLO model when stored and deployed, which is usually measured in megabytes (MB) or gigabytes (GB). It includes the model’s parameters (such as weights and biases) as well as the additional storage required for the model structure. The calculation process for model size is as follows:
- N represents the total number of parameters in the model, represents the number of parameter, and represents the size of the parameter, usually in megabytes. For example, for a YOLO model with M convolutional layers and K fully connected layers, the number of parameters can be expressed as:
- and represent the input and output channel numbers of the convolutional layer, respectively. represents the convolution kernel size of the convolution layer, and and represent the width and height of the weight matrix of the fully connected layer, respectively.
4.4. Results Analysis
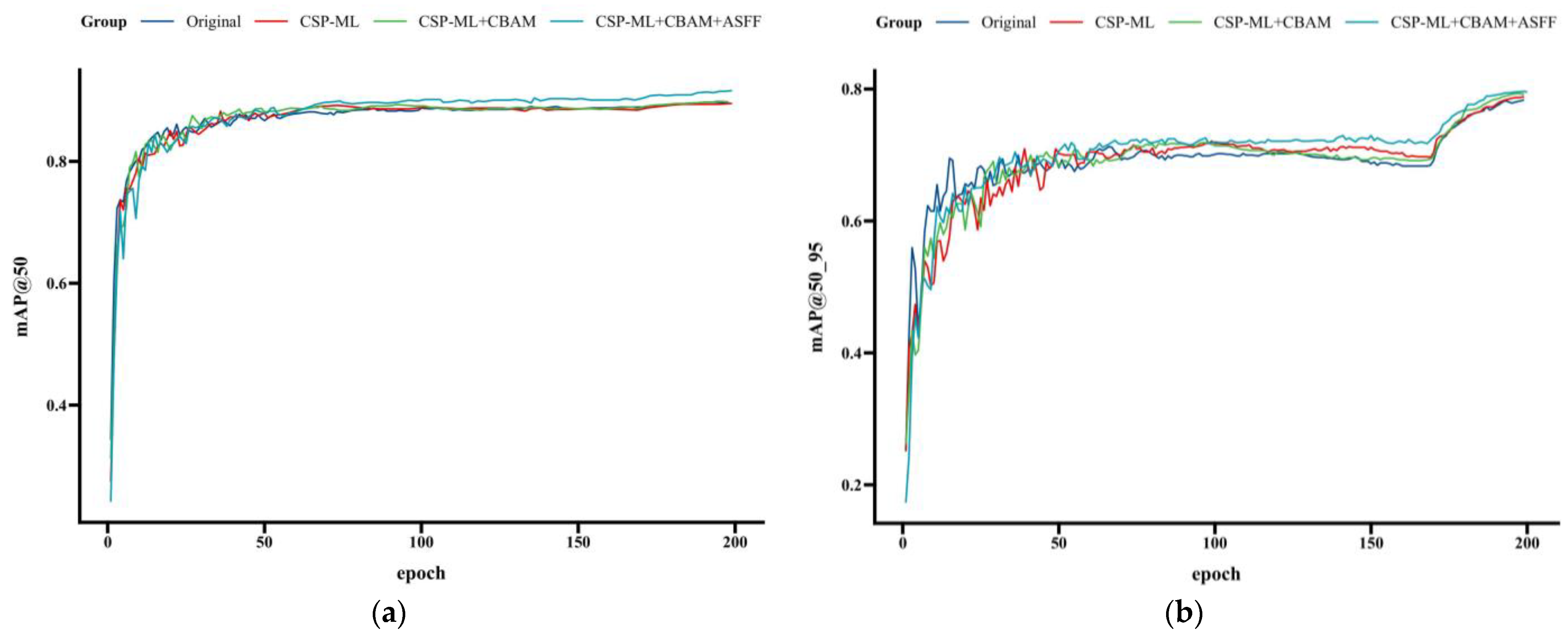
4.4.1. Comparison of Models’ Loss Curves
4.4.2. Ablation Study
Validation of the CSP-ML Multi-Level-Feature-Extraction Structure
Analysis of Ablation Test Results
4.4.3. Comparative Experiment
4.4.4. Comparison of Scene Applications
5. Discussion
- Discussion of results
- 2.
- Limitation analysis
6. Conclusions
- Design of a multi-level-feature-extraction module, (CSP-ML): A novel multi-level-feature-extraction module, CSP-ML, was designed and integrated with the CBAM attention mechanism within the neck network. This effectively reduces background noise and enhances the detection accuracy of small-target-fire areas. Additionally, an adaptive feature-fusion module was introduced that utilizes the CIoU loss function to boost the network’s feature-learning capability and mitigate issues such as the excessive optimization of negative samples and poor gradient-descent direction. Compared to the traditional YOLOX network, this resulted in improvements of 6.4% in mAP@50 and 2.17% in mAP@50_95.
- Multi-scenario application testing: In tests involving multiple fire scenarios, such as multi-target flames and small-target flames, the improved YOLOX network demonstrated higher detection accuracy and stronger anti-interference capabilities than deep learning algorithms like Faster R-CNN, SSD, and YOLOv5. It proved to be suitable for detecting various forms of fire information in complex forest- and mountain-fire scenes, showcasing its strong practicality and high application value.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Le Maoult, Y.; Sentenac, T.; Orteu, J.J.; Arcens, J.P. Fire detection: A new approach based on a low cost CCD camera in the near infrared. Process Saf. Environ. Prot. 2007, 85, 193–206. [Google Scholar] [CrossRef]
- Ko, B.C.; Cheong, K.H.; Nam, J.Y. Fire detection based on vision sensor and support vector machines. Fire Saf. J. 2009, 44, 322–329. [Google Scholar] [CrossRef]
- Toulouse, T.; Rossi, L.; Celik, T.; Akhloufi, M. Automatic fire pixel detection using image processing: A comparative analysis of rule-based and machine learning-based methods. Signal Image Video Process. 2016, 10, 647–654. [Google Scholar] [CrossRef]
- Alves, J.; Soares, C.; Torres, J.M.; Sobral, P.; Moreira, R.S. Automatic forest fire detection based on a machine learning and image analysis pipeline. In New Knowledge in Information Systems and Technologies: Volume 2; Springer International Publishing: New York, NY, USA, 2019; pp. 240–251. [Google Scholar]
- Arul, A.; Prakaash, R.S.H.; Raja, R.G.; Nandhalal, V.; Kumar, N.S. Fire detection system using machine learning. J. Phys. Conf. Ser. 2021, 1916, 012209. [Google Scholar] [CrossRef]
- Goyal, S.; Shagill, M.; Kaur, A.; Vohra, H.; Singh, A. A yolo based technique for early forest fire detection. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 1357–1362. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Wang, S.; Chen, T.; Lv, X.; Zhao, J.; Zou, X.; Zhao, X.; Xiao, M.; Wei, H. Forest fire detection based on lightweight Yolo. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 1560–1565. [Google Scholar]
- Wu, Z.; Xue, R.; Li, H. Real-time video fire detection via modified YOLOv5 network model. Fire Technol. 2022, 58, 2377–2403. [Google Scholar] [CrossRef]
- Du, H.; Zhu, W.; Peng, K.; Li, W. Improved high speed flame detection method based on yolov7. Open J. Appl. Sci. 2022, 12, 2004–2018. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Zhang, J.; Ke, S. Improved YOLOX fire scenario detection method. Wirel. Commun. Mob. Comput. 2022, 2022, 9666265. [Google Scholar] [CrossRef]
- Al-Smadi, Y.; Alauthman, M.; Al-Qerem, A.; Aldweesh, A.; Quaddoura, R.; Aburub, F.; Mansour, K.; Alhmiedat, T. Early wildfire smoke detection using different yolo models. Machines 2023, 11, 246. [Google Scholar] [CrossRef]
- Wang, T.; Wang, J.; Wang, C.; Lei, Y.; Cao, R.; Wang, L. Improving YOLOX network for multi-scale fire detection. Vis. Comput. 2023, 1–13. [Google Scholar] [CrossRef]
- Ju, Y.; Gao, D.; Zhang, S.; Yang, Q. A real-time fire detection method from video for electric vehicle-charging stations based on improved YOLOX-tiny. J. Real-Time Image Process. 2023, 20, 48. [Google Scholar] [CrossRef]
- Li, C.; Li, G.; Song, Y.; He, Q.; Tian, Z.; Xu, H.; Liu, X. Fast Forest Fire Detection and Segmentation Application for UAV-Assisted Mobile Edge Computing System. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Huang, J.; He, Z.; Guan, Y.; Zhang, H. Real-time forest fire detection by ensemble lightweight YOLOX-L and defogging method. Sensors 2023, 23, 1894. [Google Scholar] [CrossRef] [PubMed]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2017; pp. 7132–7141. [Google Scholar]
- Chen, W.; Lu, Y.; Ma, H.; Chen, Q.; Wu, X.; Wu, P. Self-attention mechanism in person re-identification models. Multimed. Tools Appl. 2021, 81, 4649–4667. [Google Scholar] [CrossRef]
- Li, X.; Hu, X.; Yang, J. Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the Integration of Self-Attention and Convolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2021; pp. 805–815. [Google Scholar]
- Li, Y.; Wang, S. HAR-Net: Joint Learning of Hybrid Attention for Single-Stage Object Detection. IEEE Trans. Image Process. 2019, 29, 3092–3103. [Google Scholar] [CrossRef]
- Bastidas, A.; Tang, H. Channel Attention Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 881–888. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, ARXIV-CS.CV, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, Y.; Xue, J.; Zhang, M.; Yin, J.; Liu, Y.; Qiao, X.; Zheng, D. YOLOv5-ASFF: A Multistage Strawberry Detection Algorithm Based on Improved YOLOv5. Agronomy 2023, 13, 1901. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Di, W.; Cao, L.; Li, N. Research on Technologies of Infrared Small Target Detection Based on Multimodal Features. Ph.D. Thesis, Chinese Academy of Sciences, Changchun, China, 2023. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Taheri Tajar, A.; Ramazani, A.; Mansoorizadeh, M. A lightweight Tiny-YOLOv3 vehicle detection approach. J. Real-Time Image Process. 2021, 18, 2389–2401. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, J.; Qiu, Y.; Ni, X.; Shi, B.; Liu, H. Fast Detection of Railway Fastener Using a New Lightweight Network Op-YOLOv4-Tiny. IEEE Trans. Intell. Transp. Syst. 2023, 25, 133–143. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; TaoXie; Fang, J.; Imyhxy; et al. ultralytics/yolov5: v7.0—YOLOv5 SOTA Realtime Instance Segmentation (v7.0). Zenodo. 2022. Available online: https://zenodo.org/records/7347926 (accessed on 29 February 2024).
- Wan, F.; Sun, C.; He, H.; Lei, G.; Xu, L.; Xiao, T. YOLO-LRDD: A lightweight method for road damage detection based on improved YOLOv5s. EURASIP J. Adv. Signal Process. 2022, 2022, 98. [Google Scholar] [CrossRef]
- Cheng, Q.; Bai, Y.; Chen, L. Compression of YOLOX object detection network and deployment on FPGA. Proc. SPIE 2022, 12174, 121740J. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, Y.; Qiao, Y.; Hu, X.; Huang, Y. Real-time detection of winter jujubes based on improved YOLOX-nano network. Remote Sens. 2022, 14, 4833. [Google Scholar] [CrossRef]
- Guo, Q.; Liu, J.; Kaliuzhnyi, M. YOLOX-SAR: High-Precision Object Detection System Based on Visible and Infrared Sensors for SAR Remote Sensing. IEEE Sens. J. 2022, 22, 17243–17253. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv8: Ultralytics YOLO Series—Cutting-Edge Advancements for Object Detection [EB OL]. 2023. Available online: https://github.com/ultralytics/ (accessed on 1 December 2023).
- Ma, B.; Hua, Z.; Wen, Y.; Deng, H.; Zhao, Y.; Pu, L.; Song, H. Using an improved lightweight YOLOv8 model for real-time detection of multi-stage apple fruit in complex orchard environments. Artif. Intell. Agric. 2024, 11, 70–82. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A real-time apple targets detection method for picking robot based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A lightweight YOLOv8 tomato detection algorithm combining feature enhancement and attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]
- Ma, S.; Lu, H.; Wang, Y.; Xue, H. YOLOX-Mobile: A target detection algorithm more suitable for mobile devices. J. Phys. Conf. Ser. 2022, 2203, 012030. [Google Scholar] [CrossRef]
- Lim, J.; Jobayer, M.; Baskaran, V.; Lim, J.; See, J.; Wong, K. Deep multi-level feature pyramids: Application for non-canonical firearm detection in video surveillance. Eng. Appl. Artif. Intell. 2021, 97, 104094. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application Scenario | Quantity |
|---|---|
| Daylight | 9080 |
| Darkness | 7737 |
| Fire-like | 1500 |
| Smoke-like | 2500 |
| Model | Model Size | Classified as Lightweight Model | Model | Model Size | Classified as Lightweight Model |
|---|---|---|---|---|---|
| YOLOv1 | 753 MB | No | YOLOv6-N [31] | 4.3 MB | Yes |
| YOLOv2 | 193 MB | No | YOLOv6-S [31] | 15.0 MB | Yes |
| Tiny YOLOv2 [32] | 60 MB | Yes | YOLOv6-M [31] | 34.9 MB | Yes |
| YOLOv3 | 246 MB | No | YOLOv6-L | 58.5 MB | No |
| Tiny YOLOv3 [33,34] | 34 MB | Yes | YOLOv6-L-ReLU | 58.5 MB | No |
| YOLOv4 | 245 MB | No | YOLOv7-Tiny [35] | 6.2 MB | Yes |
| YOLOv4-Tiny [36,37] | 23 MB | Yes | YOLOv7 [35] | 36.9 MB | Yes |
| YOLOv5s [38,39] | 14 MB | Yes | YOLOv7-X | 71.3 MB | No |
| YOLOv5m [38,39] | 42 MB | Yes | YOLOv7-W6 | 70.8 MB | No |
| YOLOv5l | 90 MB | No | YOLOv7-E6 | 97.2 MB | No |
| YOLOv5x | 168 MB | No | YOLOv7-D6 | 133.4 MB | No |
| YOLOX-Nano [40,41] | 0.91 MB | Yes | YOLOv7-E6E | 151.7 MB | No |
| YOLOX-Tiny [40,41,42] | 5.06 MB | Yes | YOLOv8n [43,44] | 6.1 MB | Yes |
| YOLOX-S [40,41,42,45] | 9.0 MB | Yes | YOLOv8s [43,44,46] | 21.6 MB | Yes |
| YOLOX-M [40,41,42,45,47] | 25.3 MB | Yes | YOLOv8m | 50.7 MB | No |
| YOLOX-L | 54.2 MB | No | YOLOv8l | 104.0 MB | No |
| YOLOX-X | 99.1 MB | No | YOLOv8x | 218.0 MB | No |
| Model | Backbone | Precision (%) | Recall (%) | mAP0.5 (%) | F1 Score (%) | FPS/Hz |
|---|---|---|---|---|---|---|
| YOLOX | DarkNet-53 | 93.89 | 93.69 | 89.9 | 93.97 | 117 |
| YOLOX | ShuffleNetv2 | 87.65 | 85.34 | 76.58 | 78.96 | 224 |
| YOLOX | Improved CSP-ML in DarkNet-53 | 94.21 | 93.97 | 91.1 | 94.51 | 189 |
| Network | mAP@50 (%) | mAP@50_95 (%) | FPS/Hz | Parameters/M |
|---|---|---|---|---|
| Original YOLOX | 89.9 | 81.64 | 117 | 8.94 |
| CSP-ML | 91.1 | 81.75 | 189 | 14.38 |
| CSP-ML + CBAM | 91.2 | 82.37 | 176 | 14.40 |
| CSP-ML + CBAM + ASFF | 93.7 | 82.45 | 155 | 14.48 |
| Improved YOLOX | 96.3 | 83.81 | 155 | 14.48 |
| Network | mAP (%) | Precision (%) | Recall (%) | F1 Score | FPS/Hz | Parameters/M | Gflops/G |
|---|---|---|---|---|---|---|---|
| Original YOLOX | 89.9 | 93.89 | 93.69 | 93.97 | 117 | 8.94 | 26.8 |
| Faster R-CNN | 62.8 | 46.2 | 72.47 | 56.33 | 65 | 137 | 185.1 |
| SSD | 88.6 | 78.38 | 93.75 | 85.33 | 72 | 26.29 | 140.9 |
| YOLOv5 | 89.3 | 84.91 | 91.33 | 81 | 109 | 7.1 | 16.5 |
| Improved YOLOX | 96.3 | 95.33 | 94.94 | 94.13 | 155 | 14.4 | 35.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luan, T.; Zhou, S.; Zhang, G.; Song, Z.; Wu, J.; Pan, W. Enhanced Lightweight YOLOX for Small Object Wildfire Detection in UAV Imagery. Sensors 2024, 24, 2710. https://doi.org/10.3390/s24092710
Luan T, Zhou S, Zhang G, Song Z, Wu J, Pan W. Enhanced Lightweight YOLOX for Small Object Wildfire Detection in UAV Imagery. Sensors. 2024; 24(9):2710. https://doi.org/10.3390/s24092710
Chicago/Turabian StyleLuan, Tian, Shixiong Zhou, Guokang Zhang, Zechun Song, Jiahui Wu, and Weijun Pan. 2024. "Enhanced Lightweight YOLOX for Small Object Wildfire Detection in UAV Imagery" Sensors 24, no. 9: 2710. https://doi.org/10.3390/s24092710
APA StyleLuan, T., Zhou, S., Zhang, G., Song, Z., Wu, J., & Pan, W. (2024). Enhanced Lightweight YOLOX for Small Object Wildfire Detection in UAV Imagery. Sensors, 24(9), 2710. https://doi.org/10.3390/s24092710