1. Introduction
How can me make sense out of a complex visual scene having no or only little prior knowledge about its contents and the objects therein? Such problems occur, for example, if we wish to learn cause-effects in an hitherto unknown environment. Vice versa, many object definitions are only meaningful within the context of a given scenario and a set of possible actions.
Object tracking,
i.e., the assignment of consistent labels to objects in different frames of a video, is important for solving various tasks in the field of computer vision, including automatic surveillance, human-computer interaction and traffic monitoring [
1]. Most object tracking algorithms require that predefined objects of interests are detected in the first frame or in every frame of the movie. However, in an unknown scenario, the tracking of image segments, presumably representing parts of objects, allows to postpone object definition to a later step of the visual-scene analysis. Several approaches for segment tracking have been proposed in the context of video segmentation [
2–
9]. Some approaches rely on segmenting each frame independently, e.g., by classifying pixels into regions based on similarity in the feature space, followed by a segment matching step based on their low-level features [
2–
5]. Other methods use motion projection to link segments,
i.e., the position of a segment in a future frame is estimated from its current position and motion features [
6–
9]. Cremers (2003) tracked motion segments by jointly solving motion segmentation and motion estimation by minimizing a single energy functional [
10].
In the works described above, assumptions of the nature of objects being tracked or the data itself is being made either in the tracking procedure itself (matching assumptions) or already in the segmentation step, for example by assuming a priori a data model of some kind. In our work, we aim to reduce a priori assumptions on the data by choosing a data-driven method, i.e., superparamagnetic clustering of data, for the segmentation procedure.
Superparamagnetic clustering finds the equilibrium states of a ferromagnetic Potts model defined by an energy function in the superparamagnetic phase [
11–
17]. The Potts model [
11] is a generalization of the Ising model [
18] which describes a system of interacting granular ferromagnets or spins, that can be in
q different states, characterizing the pointing direction of the respective spin vectors. Depending on the temperature,
i.e., disorder introduced to the system, the spin system can be in the paramagnetic, the superparamagnetic, or the ferromagnetic phase. In the ferromagnetic phase, all spins are aligned, while in the paramagnetic phase the system is in a state of complete disorder. In the superparamagnetic phase regions of aligned spins coexists. Blatt
et al. (1998) applied the Potts model to the image segmentation problems in a way that in the superparamagnetic phase regions of aligned spins correspond to a natural partition of the image data [
15]. Finding the image partition corresponds to the computation of the equilibrium states of the Potts model. Importantly, the energy function used here only consists of interaction terms and does not contain a data term, hence no prior data model needs to be assumed, e.g. total number of segments or a priori defined pixel-label assignments. In this sense, the method is model free. In contrast, methods which find solutions by computing the minimum of an energy function usually require a data term—otherwise only trivial solutions are obtained. Hence, the equilibrium-state approach to the image segmentation problem has to be considered as fundamentally different from approaches finding the minimum energy configuration of energy functions in Markov random fields [
19,
20]. As a consequence, the method is non-parametric and thus more generic, only requiring a pixel-pixel similarity criterium, e.g., gray value, color or texture, to be defined without making any further prior assumptions about the data.
The equilibrium states of the Potts model have been approximated in the past using the Metropolis-Hastings algorithm with annealing [
21] and the methods on cluster updating, which are known to accelerate the equilibration of the system by shortening the correlation times between distant spins. Prominent algorithms are Swendsen-Wang [
22], Wolff [
23], and energy-based cluster updating (ECU) [
16,
17]. In addition, the ECU algorithm has been shown to provide stable segmentation results over a larger temperature range (which is the main control parameter) than Swendsen-Wang [
16,
17]. All of these methods obey detailed balance, ensuring convergence of the system to the equilibrium state. However, convergence has only been shown to be polynomial for special cases of the Potts model. The Potts model is known to be NP hard in the general case. The relaxation processes which can be emulated in spin-lattice models are often being used as approximations for synchronization processes within neural assemblies [
12–
17].
In our method, tracking of segments is accomplished through simultaneous segmentation of adjacent frames which are linked using local correspondence information, e.g., computed via standard algorithms for optic flow [
24]. By performing motion projection and image segmentation within a single process we do not require any explicit matching of image segments, thus further reducing a priori assumptions that have to be made about the data. Synchronizing the segmentation process of adjacent frames has further the advantage that partitioning instabilities can be reduced. Usually, the segmentation (or partition) of an image is sensitive to global and local changes of the image,
i.e., small changes in illumination, the appearance/disappearance of objects parts, causing the partition to change from one frame to the next. To further stabilize segment tracking in the case of long image sequences, we developed a feedback control mechanism, which allows segmentation instabilities, e.g., sudden disappearances of segments, to be detected and removed by adjusting a control parameter of the segmentation algorithm.
Thus, the main contribution here is the development of a data-driven, model-free tracking algorithm,
i.e., no prior object knowledge is required in order to track image segments from frame to frame. Potential applications include moving object detection and tracking, and action recognition and classification from movies [
25].
The paper is structured as follows: In Section 2, we extend the method of superparamagnetic clustering in spin models to the temporal dimension and introduce the controller algorithm. We also discuss the method in front of the background of energy minimization methods in Markov random fields. In Section 3, we first verify the core algorithm using short image sequences because these are more suitable to introduce and test the method. We further investigate the sensitivity of the algorithm to system parameters and noise. Then, we demonstrate that segment tracking can be achieved for real movies. The performance of the method is quantified in terms of partitioning consistency along an artificial image sequence. In Section 4, the results are discussed.
2. Algorithmic Framework
Segment tracking can be roughly divided into the following subtasks: (i) image segmentation, (ii) linking (tracking), and (iii) stabilization (tracking). The third point acknowledges that segments, unlike objects, are not per se stable entities, but are sensitive to changes in the visual scene. Subtasks (i–ii) will be solved using a conjoint spin-relaxation process emulated in an n-dimensional (n-D) lattice, which defines the core algorithm (Section 2.1). Local correspondence information for linking is obtained using standard algorithms for either stereo or optic flow [
24,
26]. The conjoint segmentation approach has the advantage that the spin-relaxation processes of adjacent images synchronize, reducing partitioning instabilities.
Since simultaneous segmentation of long image sequences is practically impossible due to the high computational costs, we usually split the image sequence into a sequence of pairs. For example, the subsequent frames t0, t1 and t2 are split into two pairs {t0, t1} and {t1, t2}, where the last frame of previous pair is identical to the first frame of the next pair. If a segment of the last frame of {t0, t1} and a segment of the first frame of {t1, t2} occupy the same image region, we can assign the same segment label to both segments. This way segments can be tracked through the entire sequence. Since the algorithm preserves detailed balance (Section 2.1), spins can be transferred from one frame to the next, greatly reducing the number of iterations required to achieve a stable segmentation.
We further stabilize segment tracking by introducing a feedback controller (Section 2.2). In long image sequences, partitioning instabilities are likely to arise at some point during the tracking process. Thus, segments may be lost due to merging or splitting of segments. The feedback controller detects these kind of instabilities and adjusts a control parameter of the core algorithm to recover the original segments.
2.1. Core Algorithm
The method of superparamagnetic clustering has been previously used to segment single images [
15–
17]. Applying this framework to image sequences requires spin interactions to take place across frames. Due camera and object motion the images undergo changes during the course of time. To connect different frames, the mapping from one frame to the next needs to be known at least in some approximation. We solve this problem in the following way: Point correspondences, derived using algorithms for disparity or optic-flow computation, can be incorporated into the Potts model [
11] by allowing spins belonging to different frames of the image sequence to interact if the respective pixels belong to locally corresponding image points. Then, spins belonging to the different frames of the sequences are relaxed simultaneously, resulting in a synchronized segmentation of the images of the sequence. The inter-frame spin interactions cause the spins of corresponding image regions to align, and, thus, they will be assigned to the same segment. Since the formation of segments is a collective process, the point correspondences do not have to be very accurate nor does the algorithm require point correspondences for each pixel. It is usually sufficient if the available correspondences capture the characteristics of the scene only roughly.
The aim of this work is to find corresponding image regions in image sequences,
i.e., stereo pairs and motion sequences. The segment tracking task is formulated as follows. Given an image sequence
S containing points
p(
x, y, t) with coordinates (
x, y, t) as elements, where
x and
y label the position within each image, while
t labels the frame number, then we want to find a partitioning
P =
P1, ..,
PM of
S in
M groups such that
Pi ∩ Pj = 0 and Pi ≠ Ø for all groups
if point p ∈ Pi, then s(p, Pi) > s(p, Pj), where s is a function measuring the average distance of a point to the elements of a group and i ≠ j
if p(xi, yi, ti) ∈ Pr, then p(xi + △xi, yi + △yi, ti + 1) ∈ Pr, where △xi and △yi are the shifts of point p(xi, yi, ti) along the x and y axes, respectively, from frame ti to frame ti + 1.
To perform this task, we assign a spin variable
σi (or label) to each pixel (or site)
i of the image sequence. To incorporate constraints in the form of local correspondence information, we distinguish between neighbors within a single frame (2D bonds) and neighbors across frames (n-D bonds). We create a 2D bond (
i, k)
2D between two pixels within the same frame with coordinates (
xi, yi, ti) and (
xk, yk,tk) if
where
ε2D is the 2D-interaction range of the spins, a parameter of the system. Across frames, we create a n-D bond (
i, j)
nD between two spins
i and
j if
where
εnD is the n-D interaction range. The values
and
are the shifts of the pixels between frames
ti and
tj along the axis
x and
y, respectively, obtained from the optic-flow map or disparity map. The parameters
aij ∈ [0, 1] are the respective amplitudes (or confidences) of the optic-flow or stereo algorithm. A large amplitude suggests a large confidence in the computed local correspondence. Parameter
τ is a threshold, removing all local correspondences having a small amplitude.
We define for every bond on the lattice the distance
where
gi and g
j are the feature vectors, e.g., gray value, color, or texture, of the pixels
i and
j, respectively. The mean distance △̄ is obtained by averaging over all bonds. We further define an interaction strength
The spin model is now implemented such a way that neighboring spins with similar color have the tendency to align. We use a
q-state Potts model [
11] with the Hamiltonian
Here, 〈
ik〉
2D and 〈
ij〉
nD denote that
i, k and
i, j are connected by bonds (
i, k)
2D and (
i, j)
nD, respectively The Kronecker
δ function is defined as
δ(
a)
= 1 if
a = 0 and zero if otherwise. The segmentation problem is then solved by finding clusters of correlated spins in the low temperature equilibrium states of the Hamiltonian
H. The temperature parameter determines the amount of disorder introduced to the system. The spin states have to be observed over several iterations to identify clusters as groups of correlated spins. The total number
M of segments is then determined by counting the computed segments. The spin states
σi can take integer values between 1 and
q, where
q is a parameter of the algorithm. The number of segments is not constrained by the parameter
q. Please note that segment labels are not identical to spin states. Spins which belong to the same segment are always in the same spin state, however, the reverse is not necessarily true. Note that the local correspondences used in the algorithm to create n-D bonds are precomputed and are not altered or optimized when computing the equilibrium state. The computation of local correspondences is not the aim of this paper.
We find the equilibrium spin configuration using a clustering algorithm. In a first step, “satisfied” bonds,
i.e., bonds connecting spins having identical spin values
σi =
σj, are identified. Then, in a second step, the satisfied bonds are “frozen” with a some probability
Pij. Pixels connected by frozen bonds define a cluster, which are updated by assigning to all spins inside the same clusters the same new value [
22]. In the method of superparamagnetic clustering proposed by Blatt
et al. (1996) [
15] this is done independently for each cluster. In this paper, we will employ the method of energy-based cluster updating (ECU), where new values are assigned in consideration of the energy gain calculated for a neighborhood of the regarded cluster [
16,
17]. A schematic of the spin system of an image sequence is depicted in
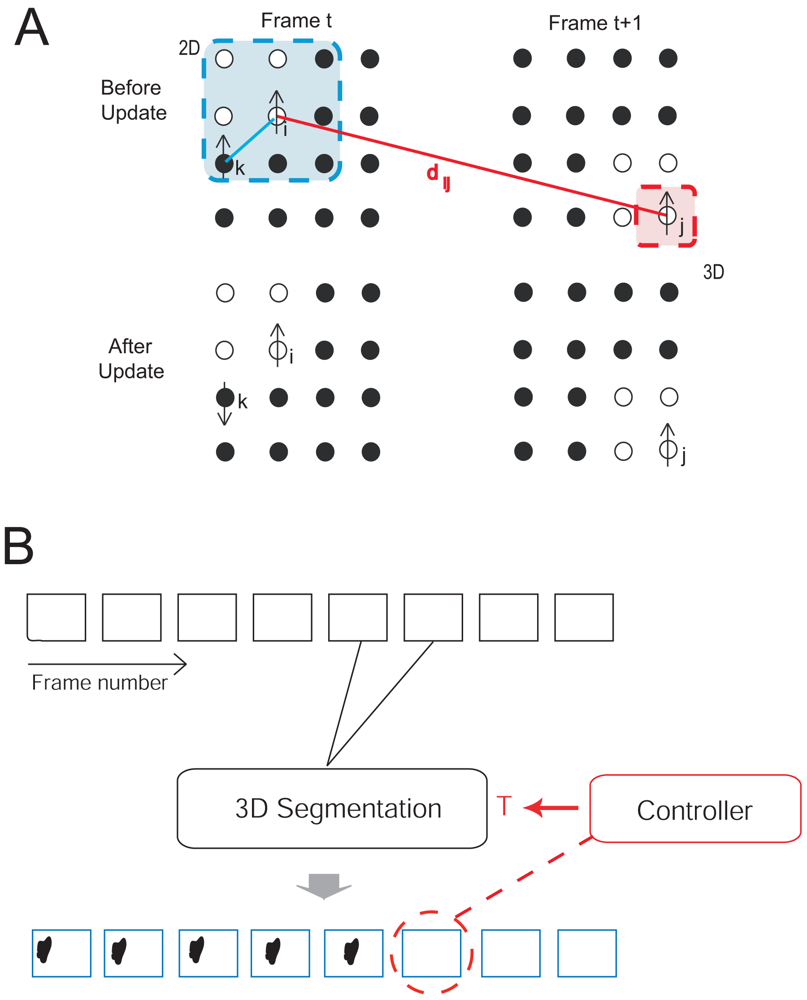
Figure 1A.
The ECU algorithm computing the equilibrium of
H consists of the following steps:
Initialization: A spin value σi between 1 and q is assigned randomly to each spin i. Each spin represents a pixel of the image sequence.
Computing bond freezing probabilities: If two spins
i and
j are connected by a bond and are in the same spin state
σi =
σj, then the bond is frozen with a probability
Negative probabilities are set to zero.
Cluster identification: Pixels which are connected by frozen bonds define a cluster. A pixel belonging to a cluster u has by definition no frozen bond to a pixel belonging to a different cluster v.
Cluster updating: We perform a Metropolis update [
22,
27] that updates all spins of each cluster simultaneously to a common new spin value. The new spin value for a cluster
c is computed considering the energy gain obtained from a cluster update to a new spin value
wk, where the index
k denotes the possible spin values between 0 and
q, respectively Note that this new spin value is, once chosen, a constant and has to be distinguished from the spin variables
σi. Updating the respective cluster to the new value results in a new spin configuration
.
The probability for the choosing the new spin value
wk for cluster c is computed by considering the interactions of all spins in the cluster
c with those outside the cluster, assuming that all spins of the cluster are updated to the new spin value
wk, giving an energy
where 〈
ik〉
2D,
ck ≠
cj and 〈
ij〉
nD,
ck ≠
cj are the noncluster neighborhoods of spin
i. Here,
N is the total number of pixels of the image sequence. The constant
η is chosen to be 0.5.
Similar to a Gibbs sampler, the selecting probability
for choosing the new spin value to be
wk is given by
Iteration: The new spin states are returned to step 2 of the algorithm, and steps 2–5 are repeated, until the total number of clusters stabilizes,
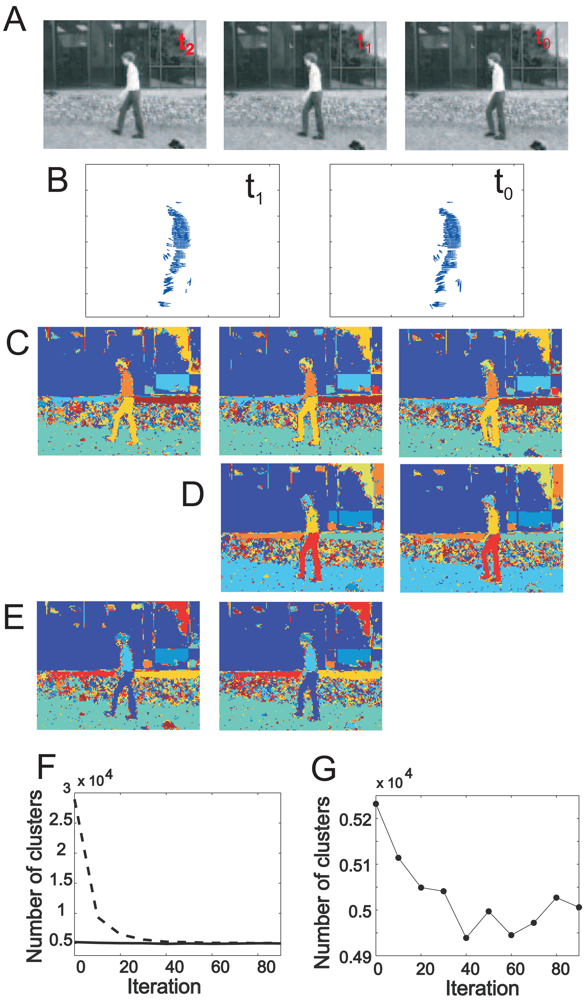
i.e., the change of the number of clusters is small compared to the change of the number clusters during the first ten iterations (see also
Figure 5F). In practice, we usually use a fixed number of iterations.
Segments are defined as groups of correlated spins and can be extracted using a thresholding procedure. All pairs of pixels connected by a bond (i, j) with c(σi, σj) > θ are considered to be friends, i.e., they must belong to the same segment. The function c computes the correlation of the spin states of i and j over several iterations. Then, all mutual friends are assigned to the same segment. Finally, M is determined by counting the total number of segments. In practice, we find it sufficient to take the clusters found in the last iteration as segments.
In an earlier study we had provided evidence that this algorithm obeys
detailed balance. The full proof shall not be repeated here and can be found in [
16]. Detailed balance assures that the proposed algorithm computes an equilibrium spin configuration of the energy function and that this is Boltzmann distributed. However, the equilibrium might not be found in polynomial time (see Section 2.3).
The consequence of detailed balance is that spin states can be transferred across image pairs, where spins are being calculated for one pair (the first pair) and then pixels in the next two frames (the second pair) are just assigned these spins from where on a new relaxation process starts (see
Figure 5 for an example). Hence, the relaxation process for the second pair (and all to follow) is much faster when using spin transfer and the system will always arrive at the thermodynamic equilibrium making spin-transfer based segmentation concordant across frames. Note, this property allows consistent segment tracking across many frames without additional assumptions (see
Figure 5), which requires more effort with other methods.
The following should be noted. In this method, bonds between adjacent frames are created from the precomputed optic-flow or disparity maps and frozen with a probability that depends on the feature similarity of the respective corresponding pixels. Whether these bonds are frozen in the final configuration (
i.e., the respective proposed point correspondences are accepted), and thus promote the formation of a certain segment correspondence, is decided inherently by finding the equilibrium state of
Equation 10. This procedure makes the method more robust against errors in the optic-flow or disparity map.
2.2. Feedback Control
Segmentation instabilities arising during the tracking process can be partly removed by adjusting the temperature parameter of the core algorithm. The temperature choice affects the formation of segments, hence, a segment which has been lost in a previous frame can sometimes be recovered by increasing the temperature for a certain period.
The feedback controller tracks the size of the segments and reacts if the size of a segment changes suddenly. The first controller function
measures the probability of change of segment
j, where
Sj(
t) is the size of segment
j at frame
t and △
Sj(
t) =
Sj(
t) −
Sj(
t − 1), and
α, β, τ1 are constant parameters. The history of segment
j in terms of occurrence is captured by the second controller function
with
Hj(
t) = 1 if
Sj(
t) > 0 and zero otherwise.
Segmentation instabilities may cause a segment to be lost, for example through segment merging or splitting. We define two threshold parameters
τ2 and
τ3. An unexpected segment loss is detected by the controller if the conditions
are fulfilled. An unexpected segment appearance is detected by the controller if the conditions
are fulfilled. The identities of the affected segments are stored by the controller. The temperature of the core algorithm is varied using predefined temperature steps △
T. The segmentation is repeated at the new temperature
T + △
T only for the affected segments of the frames. If the lost segments can be recovered at one of these temperatures, the affected segments are relabeled accordingly. Furthermore, the new temperature
T + △
T values of the affected segments are inherited to the next frame in order to prevent the same segmentation error. Note that the temperature value can be increased to a predefined maximum value, otherwise undesired artifacts might be observed.
A schematic of the entire system,
i.e., core algorithm with feedback control, is presented in
Figure 1B.
2.3. Comparison with Energy-Minimization-Based Methods in Markov Random Fields
The method described in this paper is compared with energy minimization in Markov random fields. Similarities and differences of the approaches are analyzed and summarized in this section. Particular attention is given to combinatorial graph cuts methods, which have provided powerful computer vision algorithms for stereo, motion, image restoration, and image segmentation in recent years [
19,
20].
The image segmentation problem has been previously formulated in terms of finding a discrete labeling
f that minimizes the Potts energy function
where the data term
measures how well label
fp fits the pixel
p given the observed data, and the interaction term
where
T(·) is one if the statement inside is true and zero otherwise [
19]. Note that the formulation of the Potts interaction energy is slightly different from the standard ferromagnetic case used by us. The energies here are positive and
T(·) is zero if two pixels have the same labels. The data term has to be included in the energy function, because otherwise the energy minimum would be found at a configuration where all pixels have the same label, and thus
Esmooth = 0. We are assuming
Jp,q to be positive for all
p, q (otherwise the system would describe a spin glass or an antiferromagnet). Hence, some knowledge about the solution needs to be provided when defining the data term, and as such the method is
model driven. This constitutes a major difference to the method used in this paper. Superparamagnetic clustering requires no data term,
i.e., no knowledge about the solution needs to be provided in the beginning, expect from a pixel-pixel similarity criterium.
Various techniques have been proposed to find the minimum energy configuration, e.g., simulated annealing [
21], belief propagation [
28], the Swendsen-Wang-based method of Barbu and Zhu [
22,
29] and graph cuts [
20]. Combinatorial graph-cut techniques have received a lot of attention in recent years because they provide polynomial-time algorithms for the two-label problem [
20]. However, finding the minimum of the energy function of
Equation 21 is known to be NP hard for more than two labels [
19,
20]. For the multi-label problem graph cuts can be used iteratively [
19]. In the
α/
β swap algorithm groups of pixels are assigned a new label simultaneously, while the new best move is computed used using graph cuts while considering only two labels
α and
β at a time.
The method of superparamagnetic clustering also formulates an energy function (see
Equation 10) describing a Potts model, which is a specific example of a Markov Random Field. Here,
no energy minimum is computed. Instead, the equilibrium state at a given temperature (in the superparamagnetic regime) is approximated using similar techniques as used for energy miminization, e.g., simulated annealing [
21] and cluster-update algorithms, such as Swendsen-Wang [
22], Wolff [
30], and ECU [
16,
17]. Note that combinatorial graph cuts is not applicable here. Our model does not contain a data term, which would be required to define the connections of the graph nodes to the two special nodes called the source and the sink of min-cut/max-flow algorithms. If simulated annealing is employed, one starts at a high temperature and slowly reduces the temperature until one reaches the target temperature. Cluster-update algorithms however do not require annealing to approximate the equilibrium spin configuration and are much more efficient than Metropolis simulations using single moves only [
16,
17]. Similar to the
α/β swap algorithm and the algorithm of Barbu and Zhu [
19,
20,
29], the ECU algorithm moves groups of pixels simultaneously to reach faster convergence and also selects “best moves”.
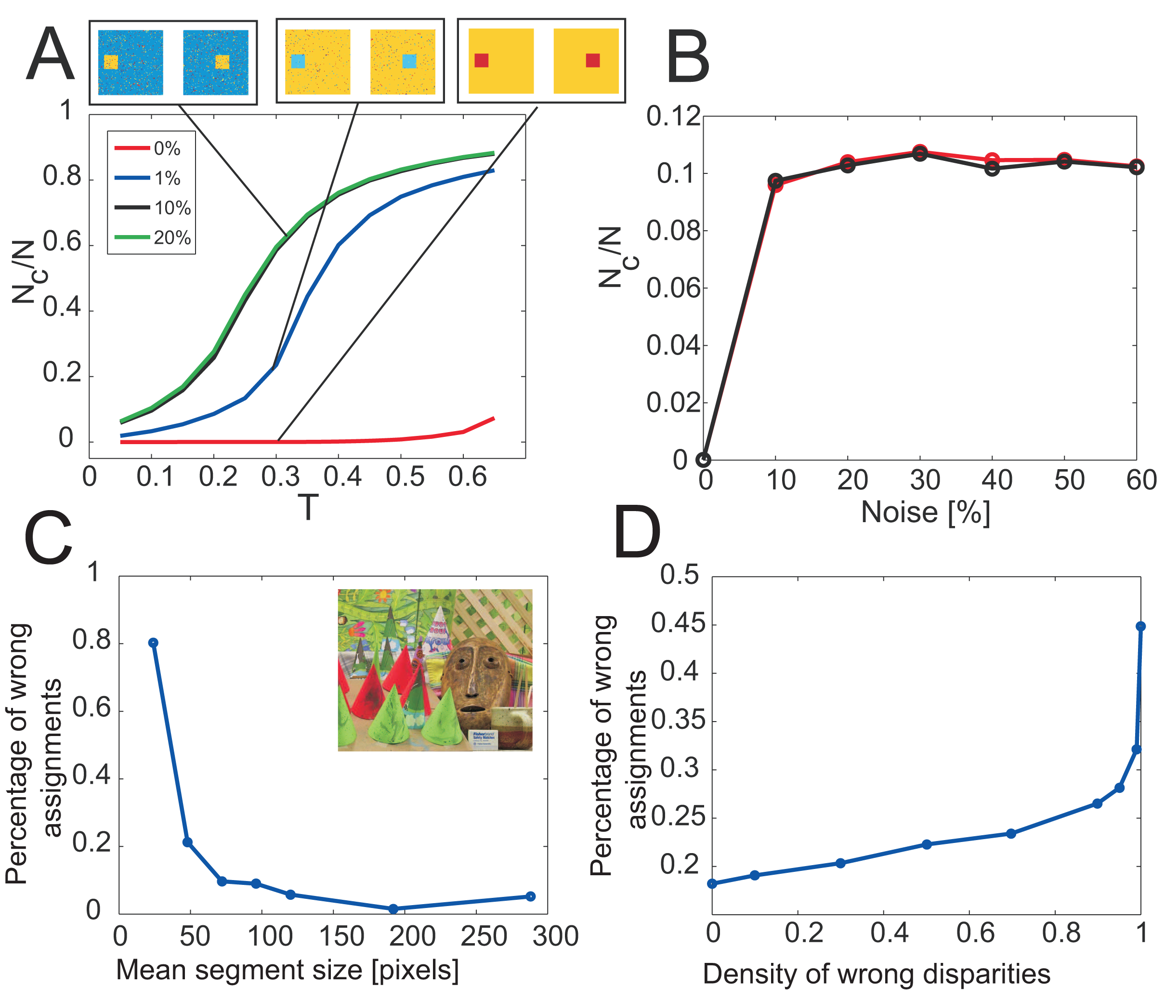
Finding the equilibrium states in the Potts model is in general NP hard. In practice, the Swendsen-Wang algorithm often shows fast convergence to the equilibrium state, unlike the Metropolis-Hastings algorithm, which usually requires exponential time. For certain instances of the Potts model, rapid mixing,
i.e., polynomial-time convergence to the equilibrium state, has been proven for the Swendsen-Wang process [
31]. In the general case, however, Swendsen-Wang shows exponential mixing [
32]. It remains an open question whether ECU mixes rapidly for special cases of the Potts models.
For the 2D Ising model without an external field,
i.e., two-label Potts model, polynomial-time algorithms for computing the partition function exist. Nobel laureate Lars Onsager was the first who obtained a closed-form solution of the partition function for the 2D Ising model on a square lattice [
33]. However, three-dimensional models and the 2D case with external field are also assumed to be NP hard.
4. Discussion
We presented an algorithm for model-free segment tracking based on a novel, conjoint framework, combining local correspondences and image segmentation to synchronize the segmentation of adjacent images. The algorithm provides a partitioning of the image sequence in segments, such that points in a segment are more similar to each other than to points in another segment, and such that corresponding image points belong to the same segment. We tested the method on various synthetic and real image sequences, and showed stable and reliable results overall, thus fulfilling the most important requirement of segmentation algorithms. The method leads to the formation of stable region correspondences despite largely incomplete disparity or optic-flow maps. Similar algorithms for the extraction of region correspondences could potentially be constructed using other image segmentation algorithms,
i.e., methods based on agglomerative clustering [
36,
37]. We decided to use physics-based model for its conceptual simplicity which allowed us to integrate local correspondence information in a straightforward way. It further has the advantage that the interacting parts are inherently converging to the equilibrium state and thus are not being trapped in local extrema (detailed balance). As a consequence, the result is independent of the initial conditions, allowing us to apply the algorithm to long image sequences via spin-states transfer. This allows for consistent segment tracking across many frames without additional assumptions, which is most of the time not immediately possible with other methods. In addition, no assumptions about the underlying data are required, e.g. the number of segments, leading to a model-free segmentation. This has the consequence that a single pixel of distinct gray value (compared to its neighbors) might define a single segment. In algorithms, which partition the image into a fixed and usually small number of segments, this phenomenon does not occur. This, however, is a problem as in all realistic situations one never knows how many segments exist and self-adjustment of the total number of segments is, thus, usually desired as compared to a pre-defined maximal number.
We further introduced a feedback controller which allows to detect segmentation instabilities, i.e., merging and splitting of segments. The feedback controller adjusts the control parameter of the core algorithm in order to recover the original segments. This allows keeping track of segment even in long movies.
Segment tracking has been performed previously in the context of video segmentation [
2–
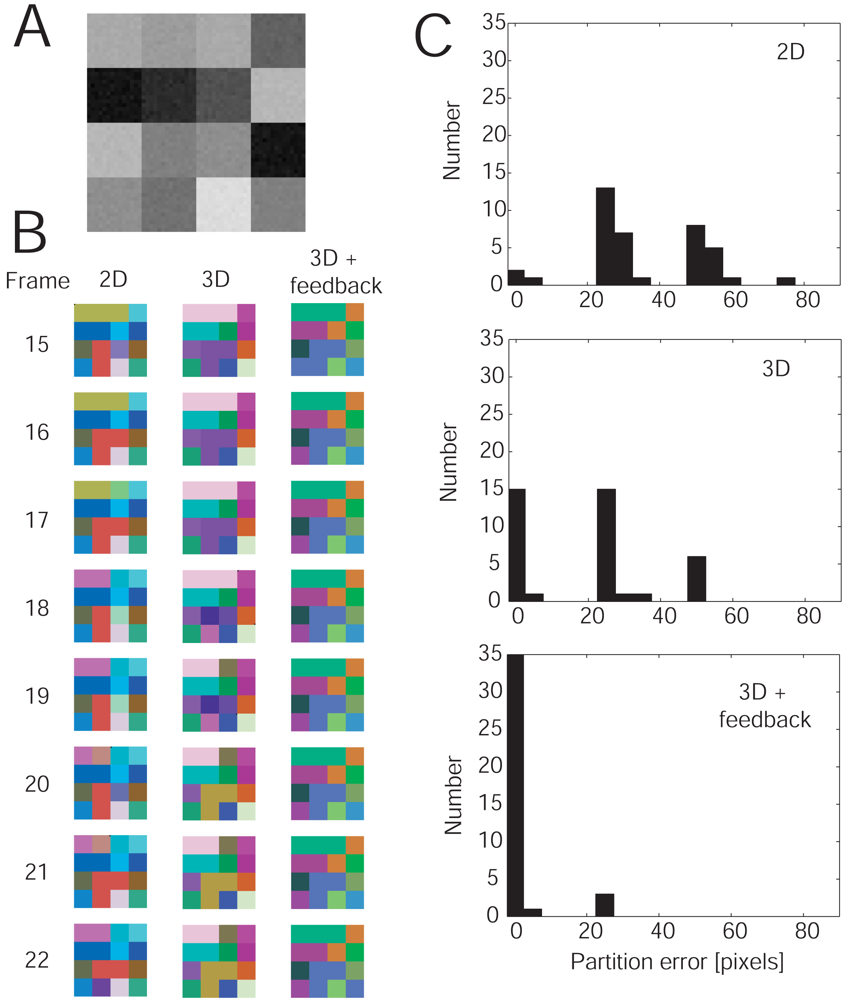
9]. Our method differs from these approaches in the choice of the segmentation algorithm, the way linking is achieved, and the addition of a feedback controller which detects segmentation instabilities. Superparamagnetic clustering allows a model-free unsupervised segmentation of the image sequences, including a self-adjustment of the total number of segments. Linking is introduced trough local correspondence information which synchronizes the spin-relaxation process of adjacent images. This approach has the advantage that the partitions of adjacent images are less prune to partitioning instabilities (see also
Figure 8). Further, our method does not require corresponding regions to fulfill any segment similarity criterium. Finally, feedback control allows segmentation instabilities occurring in long sequences to be removed by assuming that “good” segments change their size in a continuous “predictable” manner.
There have been a few other approaches combining image segmentation with correspondence information. The work by Toshev
et al. [
38] uses a joint-image graph containing edges representing intra-image similarities and inter-image feature matches to compute matching regions. Joint segmentation has also been employed by Rother
et al. [
39] using histogram matching.
The controller employed in this model serves the detection and removal of segmentation instabilities. No assumptions about the objects giving rise to the measurements,
i.e., segments, are made here, except from that they cannot appear and disappear all of a sudden (object constancy) and are thus in some way predictable. Predictable behavior of objects provides the basis for tracking methods using optimal filters such as the Kalman filter [
40], interacting multiple models [
41], or particle filters [
42]. In these cases however stronger assumptions about the nature of the objects are being made. Both some knowledge of the dynamics of objects (as then reflected by the measurements) and their appearance is assumed [
43]. In the context of specific applications as for example the tracking of moving objects, Kalman-filter-based motion could potentially be combined with our method. Kumar
et al. (2006) proposed a method for multitarget tracking in which blobs,
i.e., connected regions obtained from segmenting moving foreground objects via a background substraction method, are tracked with a Kalman filter while handling splits and merges between blobs. Certain elements of this approach may provide a means for further advancing the segment-tracking procedure described in this paper.
The method described here is related to energy minimization in Markov random fields which has been used to solve vision problems many times before [
19,
29,
44–
47] (see also Section 2.3). While the algorithmic procedures used to find the energy minimum share features with the ones employed by our method, fundamental differences exist between the methods. Superparamagnetic clustering aims at finding the equilibrium states of a Potts model without external field or data energy term at a certain temperature, and
not a global energy minimum. Formulating vision problems in terms of energy minimization requires a data penalty term (or external field), necessitating some prior knowledge about the data that is being modeled. Hence, the solutions have to be considered less generic and quite different to ours by nature.
The algorithm has potential applications in model-free moving object detection and tracking by merging coherently moving segments (Gestalt law of common fate). The method is further applicable to action-recognition tasks, where certain characteristic action patterns are inferred from the spatiotemporal relationships of segments. First results for this problem are reported in [
25]. In the future, texture cues may be incorporated into the algorithm to allow tracking of segments defined by texture.
Currently, the algorithm requires ≈ 4-5 s per frame for images of size 160 × 140 pixels and ≈ 43 s per frame for images of size 360 × 240 pixels (Taking-an-apple sequence) on an Intel Dual Core CPU with 3.16 GHz RAM (for each core). Since our goal is the development of a vision-front end for real-time video segment tracking on top of which other algorithms,
i.e., moving-object detection/tracking and action recognition, can be applied, we are currently investigating ways to improve computation time. Faster processing on a CPU could be achieved by improving the cluster identification step using a faster algorithm [
48] and by applying the algorithm not to the pixels itself, but to atomic regions obtained from Canny edge detection followed by edge tracing and contour closing. The latter technique has been used before to improve speed in energy minimization [
29]. Furthermore we are currently developing a parallel implementation on GPUs. So far, we reached frame rates between ≈ 10 – 23 frames/s for images of size 360 × 240 pixels (certain algorithmic procedures of the method have been replaced by alternative computation schemes to match the requirements of the parallel architecture).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







