Nostoc edaphicum CCNP1411 from the Baltic Sea—A New Producer of Nostocyclopeptides

 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Results and Discussion
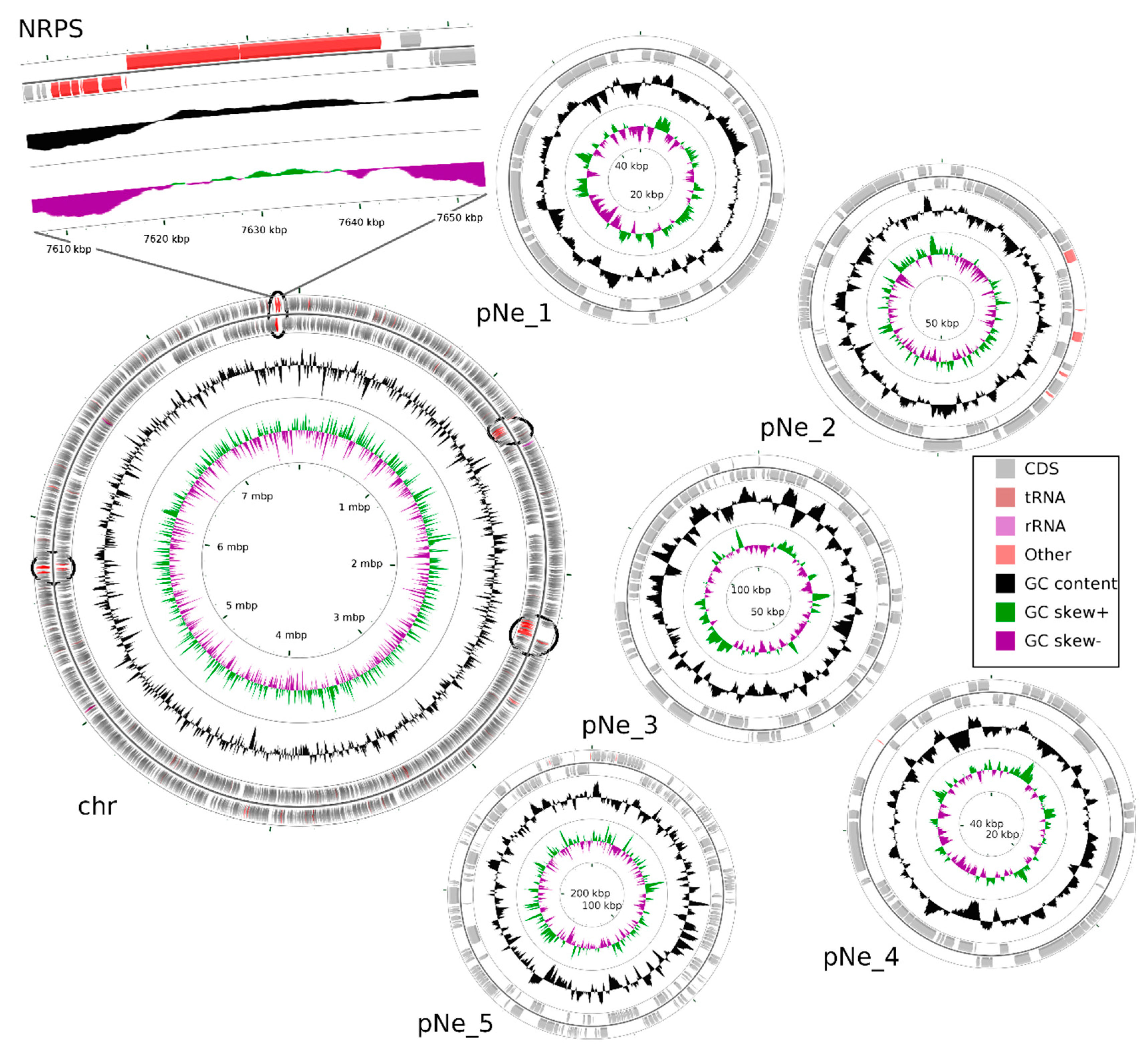
2.1. Analysis of N. edaphicum CCNP1411 Genome
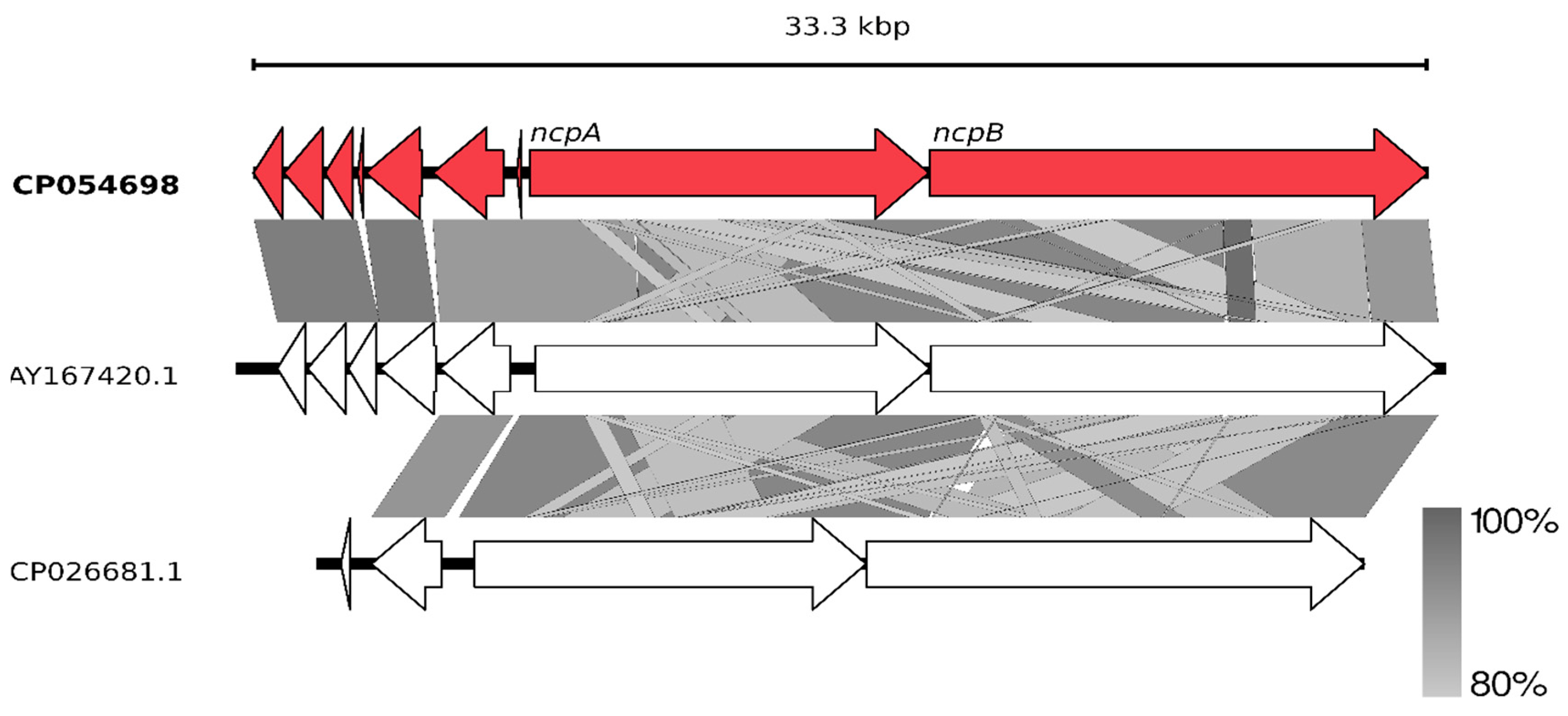
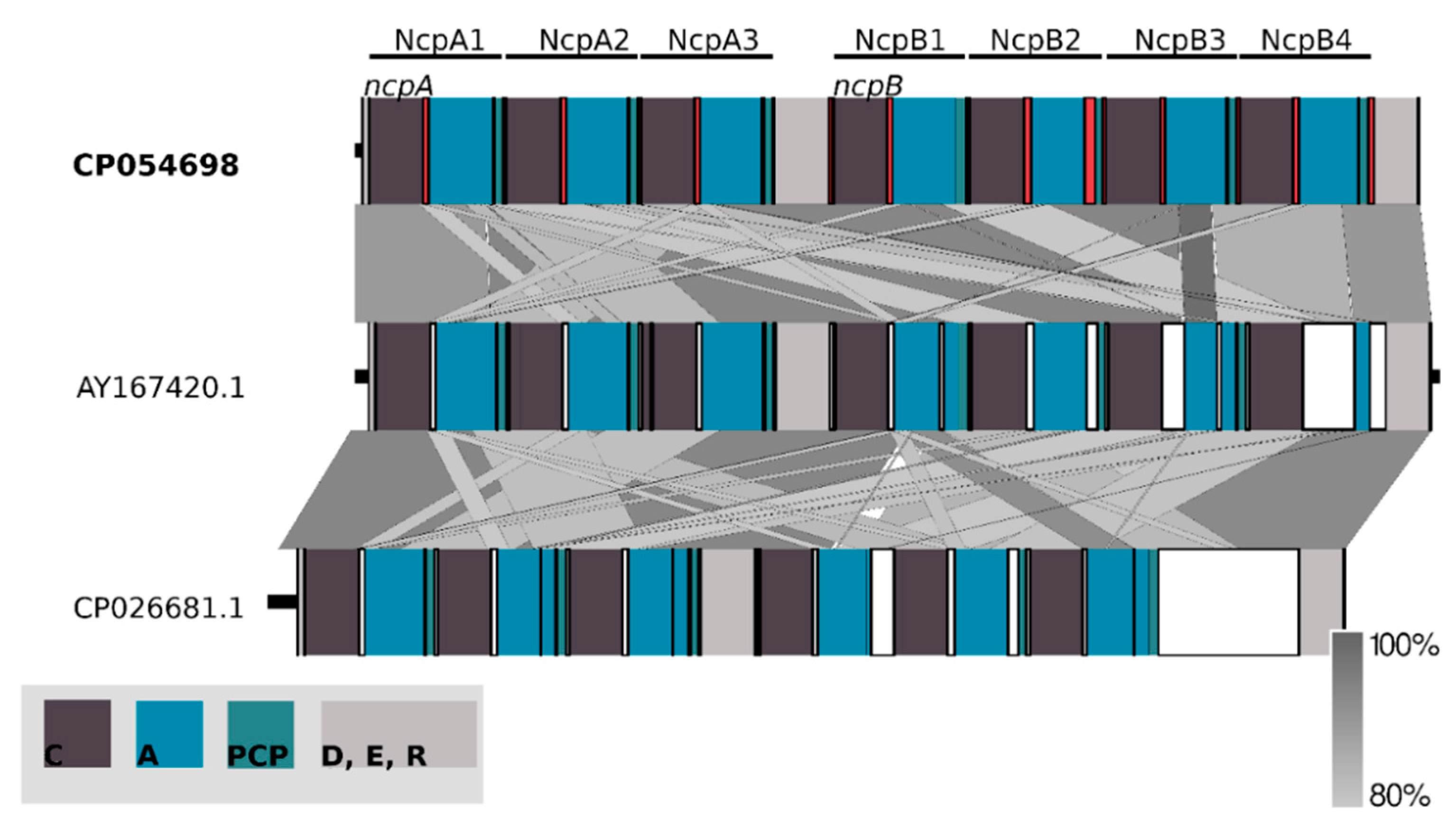
2.2. Non-Ribosomal Peptide Synthetase (NRPS) Gene Cluster of Nostocyclopeptides
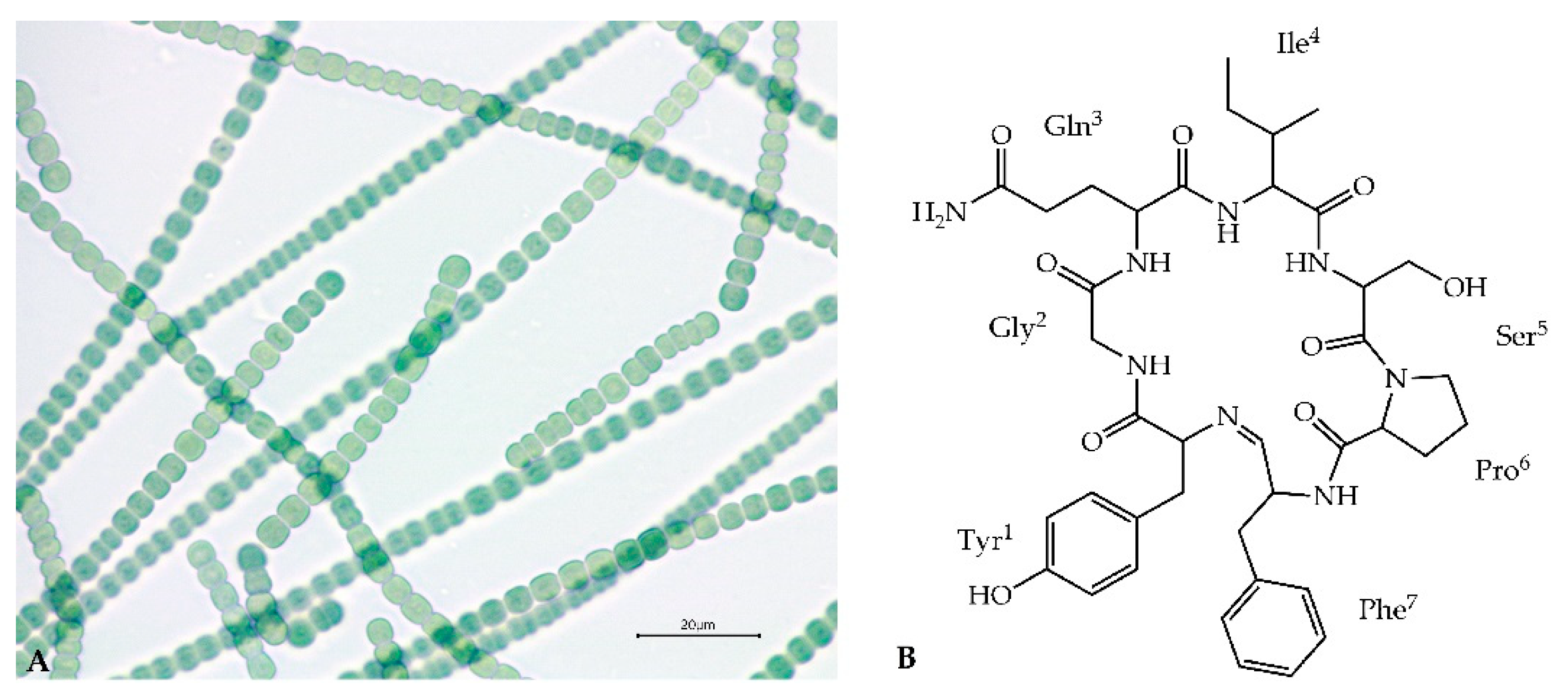
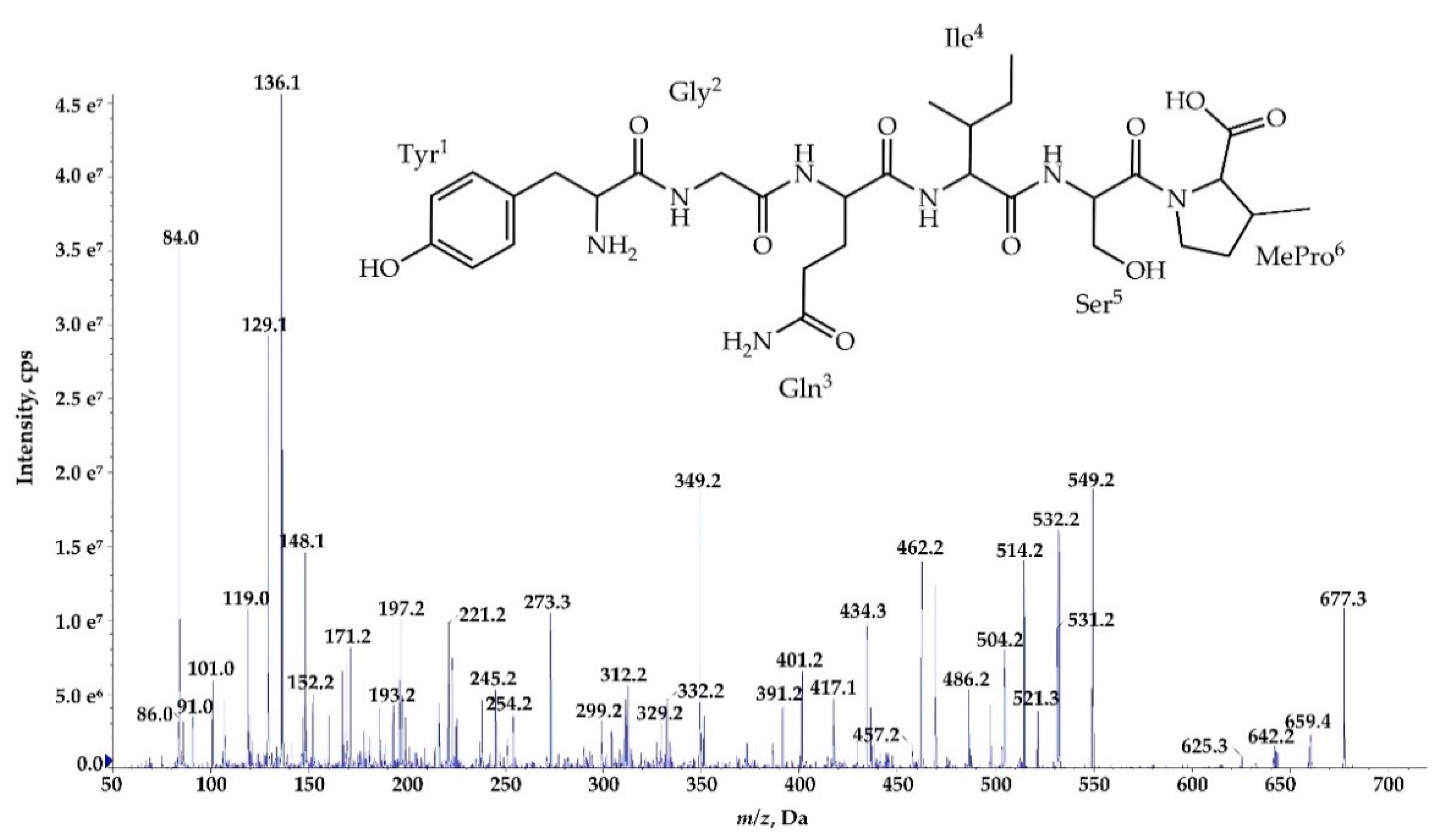
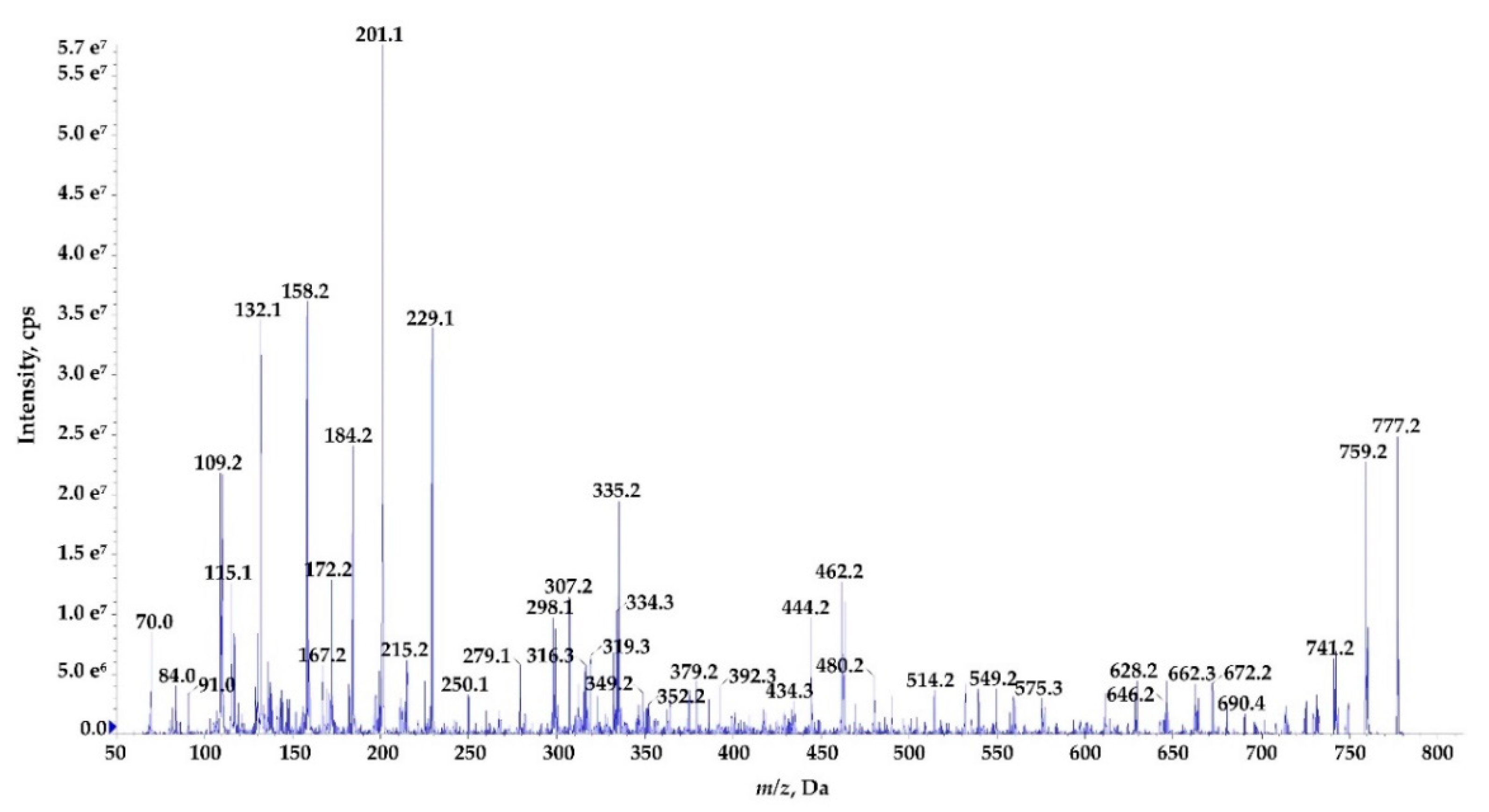
2.3. Structure Characterization of Ncps Produced by N. edaphicum CCNP1411
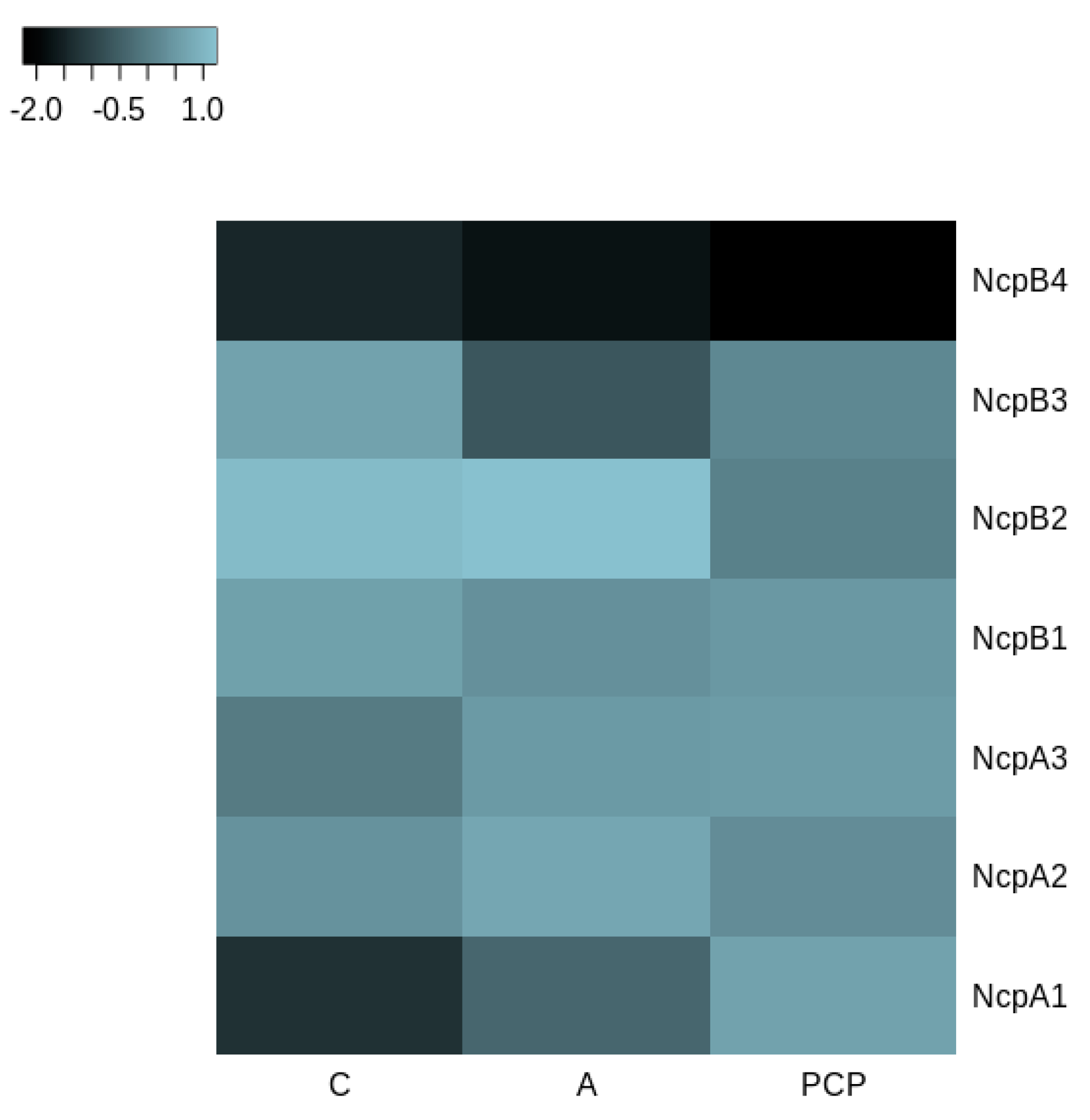
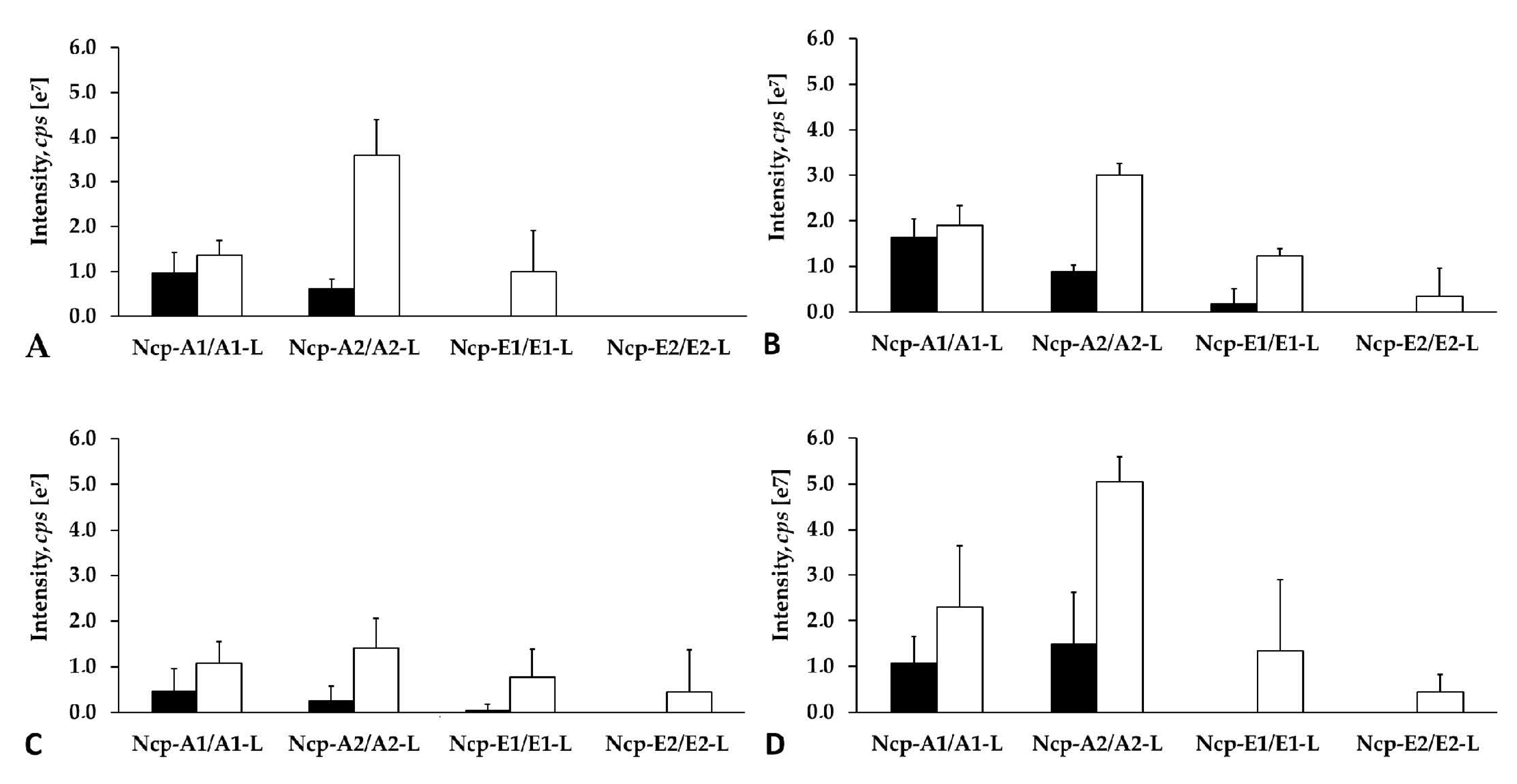
2.4. Production of Ncps by N. edaphicum CCNP1411
3. Materials and Methods
3.1. Isolation, Purification and Culturing of Nostoc CCNP1411
3.2. Isolation and Sequencing of Genomic DNA
3.3. Genome Assembling
3.4. Genome and NRPS Alignment
3.5. Data Deposition
3.6. Extraction and LC-MS/MS Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Moore, R. Cyclic peptides and depsipeptides from cyanobacteria: A review. J. Ind. Microbiol. 1996, 16, 134–143. [Google Scholar] [CrossRef] [PubMed]
- Golakoti, T.; Ogino, J.; Heltzel, C.; Le Husebo, T.; Jensen, C.; Larsen, L.; Patterson, G.; Moore, R.; Mooberry, S.; Corbett, T.; et al. Structure determination, conformational analysis, chemical stability studies, and antitumor evaluation of the cryptophycins. Isolation of new 18 analogs from Nostoc sp. strain GSV 224. J. Am. Chem. Soc. 1995, 117, 12030–12049. [Google Scholar] [CrossRef]
- Boyd, M.; Gustafson, K.; McMahon, J.; Shoemaker, R.; O’Keefe, B.; Mori, T.; Gulakowski, R.; Wu, L.; Rivera, M.; Laurencot, C.; et al. Discovery of cyanovirin-N, a novel human immunodeficiency virus-inactivating protein that binds viral surface envelope glycoprotein gp120: Potential applications to microbicide development. Antimicrob. Agents Chemother. 1997, 41, 1521–1530. [Google Scholar] [CrossRef] [Green Version]
- Ploutno, A.; Carmeli, S. Nostocyclyne A, a novel antimicrobial cyclophane from the cyanobacterium Nostoc sp. J. Nat. Prod. 2000, 63, 1524–1526. [Google Scholar] [CrossRef]
- El-Sheekh, M.; Osman, M.; Dyan, M.; Amer, M. Production and characterization of antimicrobial active substance from the cyanobacterium Nostoc muscorum. Environ. Toxicol. Pharmacol. 2006, 21, 42–50. [Google Scholar] [CrossRef] [PubMed]
- Mazur-Marzec, H.; Fidor, A.; Cegłowska, M.; Wieczerzak, E.; Kropidłowska, M.; Goua, M.; Macaskill, J.; Edwards, C. Cyanopeptolins with trypsin and chymotrypsin inhibitory activity from the cyanobacterium Nostoc edaphicum CCNP1411. Mar. Drugs 2018, 16, 220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Řezanka, T.; Dor, I.; Dembitsky, V. Fatty acid composition of six freshwater wild cyanobacterial species. Folia Microbiol. 2003, 48, 71–75. [Google Scholar] [CrossRef]
- Schwartz, R.; Hirsch, C.; Sesin, D.; Flor, J.; Chartrain, M.; Fromtling, R.; Harris, G.; Salvatore, M.; Liesch, J.; Yudin, K. Pharmaceuticals from cultured algae. J. Ind. Microbiol. 1990, 5, 113–124. [Google Scholar] [CrossRef]
- Gustafson, K.; Sowder, R.; Henderson, L.; Cardellina, J.; McMahon, J.; Rajamani, U.; Pannell, L.; Boyd, M. Isolation, primary sequence determination, and disulfide bond structure of cyanovirin-N, an anti-HIV (Human Immunodeficiency Virus) protein from the cyanobacterium Nostoc ellipsosporum. Biochem. Biophys. Res. Commun. 1997, 238, 223–228. [Google Scholar] [CrossRef]
- Okino, T.; Qi, S.; Matsuda, H.; Murakami, M.; Yamaguchi, K. Nostopeptins A and B, elastase inhibitors from the cyanobacterium Nostoc minutum. J. Nat. Prod. 1997, 60, 158–161. [Google Scholar] [CrossRef]
- Kaya, K.; Sano, T.; Beattie, K.; Codd, G. Nostocyclin, a novel 3-amino-6-hydroxy-2-piperidone containing cyclic depsipeptide from the cyanobacterium Nostoc sp. Tetrahedron Lett. 1996, 37, 6725–6728. [Google Scholar] [CrossRef]
- Mehner, C.; Müller, D.; Kehraus, S.; Hautmann, S.; Gütschow, M.; König, G. New peptolides from the cyanobacterium Nostoc insulare as selective and potent inhibitors of human leukocyte elastase. ChemBioChem 2008, 9, 2692–2703. [Google Scholar] [CrossRef] [PubMed]
- Golakoti, T.; Yoshida, W.; Chaganty, S.; Moore, R. Isolation and structure determination of nostocyclopeptides A1 and A2 from the terrestrial cyanobacterium Nostoc sp. ATCC53789. J. Nat. Prod. 2001, 64, 54–59. [Google Scholar] [CrossRef] [PubMed]
- Nowruzi, B.; Khavari-Nejad, R.; Sivonen, K.; Kazemi, B.; Najafi, F.; Nejadsattari, T. Indentification and toxigenic potential of Nostoc sp. Algae 2012, 27, 303–313. [Google Scholar] [CrossRef]
- Liaimer, A.; Jensen, J.; Dittmann, E. A genetic and chemical perspective on symbiotic recruitment of cyanobacteria of the genus Nostoc into the host plant Blasia pusilla L. Front. Microbiol. 2016, 7, 1963. [Google Scholar] [CrossRef] [PubMed]
- Jokela, J.; Herfindal, L.; Wahlsten, M.; Permi, P.; Selheim, F.; Vasconçelos, V.; Døskeland, S.; Sivonen, K. A novel cyanobacterial nostocyklopeptide is a potent antitoxin against Microcystis. ChemBioChem 2010, 11, 1594–1599. [Google Scholar] [CrossRef]
- Becker, J.; Moore, R.; Moore, B. Cloning, sequencing, and biochemical characterization of the nostocycyclopeptide biosynthetic gene cluster: Molecular basis for imine macrocyclization. Gene 2004, 325, 35–42. [Google Scholar] [CrossRef]
- Hoffmann, D.; Hevel, J.; Moore, R.; Moore, B. Sequence analysis and biochemical characterization of the nostopeptolide A biosynthetic gene cluster from Nostoc sp. GSV224. Gene 2003, 311, 171–180. [Google Scholar] [CrossRef]
- Kopp, F.; Mahlet, C.; Grünewald, J.; Marahiel, M. Peptide macrocyclization: The reductase of the nostocyclopeptide synthetase triggers the self-assembly of a macrocyclic imine. J. Am. Chem. Soc. 2006, 128, 16478–16479. [Google Scholar] [CrossRef]
- Enck, S.; Kopp, F.; Marahiel, M.; Geyer, A. The entropy balance of nostocyclopeptide macrocyclization analysed by NMR spectroscopy. ChemBioChem 2008, 9, 2597–2601. [Google Scholar] [CrossRef]
- Herfindal, L.; Myhren, L.; Kleppe, R.; Krakstad, C.; Selheim, F.; Jokela, J.; Sivonen, K.; Døskeland, S. Nostocyclopeptide-M1: A potent, nontoxic inhibitor of the hepatocyte drug trasporters OATP1B3 and OATP1B1. Mol. Pharm. 2011, 8, 360–367. [Google Scholar] [CrossRef]
- Lee, W.; Belkhiri, A.; Lockhart, A.; Merchant, N.; Glaeser, H.; Harris, E.; Washington, M.; Brunt, E.; Zaika, A.; Kim, R.; et al. Overexpression of OATP1B3 confers apoptotic resistance in colon cancer. Cancer Res. 2008, 68, 10315–10323. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nishizawa, T.; Ueda, A.; Nakano, T.; Nishizawa, A.; Miura, T.; Asayama, M.; Fuji, K.; Harada, K.; Shirai, M. Characterization of the locus of genes encoding enzymes producing heptadepsipeptide micropeptin in the unicellular cyanobacterium Microcystis. J. Biochem. 2011, 149, 475–485. [Google Scholar] [CrossRef] [PubMed]
- Rouhiainen, L.; Jokela, J.; Fewer, D.; Urmann, M.; Sivonen, K. Two alternative starter modules for the non-ribosomal biosynthesis of specific anabaenopeptin variants in Anabaena (cyanobacteria). Chem. Biol. 2010, 17, 265–273. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luesch, H.; Hoffmann, D.; Hevel, J.; Becker, J.; Golakoti, T.; Moore, R. Biosynthesis of 4-Methylproline in Cyanobacteria: Cloning of nosE and nosF and biochemical characterization of the encoded dehydrogenase and reductase activities. J. Org. Chem. 2003, 68, 83–91. [Google Scholar] [CrossRef] [PubMed]
- Lambalot, R.; Walsh, C. Cloning, Overproduction, and Characterization of the Escherichia coli Holo-acyl Carrier Protein Synthase. J. Biol. Chem. 1995, 270, 24658–24661. [Google Scholar] [CrossRef] [Green Version]
- Marchler-Bauer, A.; Derbyshire, M.; Gonzales, N.; Lu, S.; Chitsaz, F.; Geer, L.; Geer, R.; He, J.; Gwadz, M.; Hurwitz, D.; et al. CDD: NCBI’s conserved domain database. Nucleic Acids Res. 2015, 43, d222–d226. [Google Scholar] [CrossRef] [Green Version]
- Stachelhaus, T.; Mootz, H.; Marahiel, M. The specificity-conferring code of adenylation domains in nonribosomal peptide synthetases. Chem. Biol. 1999, 6, 493–505. [Google Scholar] [CrossRef] [Green Version]
- Challis, G.; Ravel, J.; Townsend, C. Predictive, structure-based model of amino acid recognition by nonribosomal peptide synthetase adenylation domains. Chem. Biol. 2000, 7, 211–224. [Google Scholar] [CrossRef] [Green Version]
- Stein, T.; Vater, J.; Kruft, V.; Otto, A.; Wittmann-Liebold, B.; Franke, P.; Panico, M.; McDowell, R.; Morris, H. The multiple carrier model of nonribosomal peptide biosynthesis at modular multienzymatic templates. J. Biol. Chem. 1996, 271, 15428–15435. [Google Scholar] [CrossRef] [Green Version]
- Dehling, E.; Volkmann, G.; Matern, J.; Dörner, W.; Alfermann, J.; Diecker, J.; Mootz, H. Mapping of the Communication-Mediating Interface in Nonribosomal Peptide Synthetases Using a Genetically Encoded Photocrosslinker Supports an Upside-Down Helix-Hand Motif. J. Mol. Biol. 2016, 428, 4345–4360. [Google Scholar] [CrossRef]
- Hacker, C.; Cai, X.; Kegler, C.; Zhao, L.; Weickhmann, K.; Wurm, J.; Bode, H.; Wöhnert, J. Structure-based redesign of docking domain interactions modulates the product spectrum of a rhabdopeptide-synthesizing NRPS. Nat. Commun. 2018, 9, 4366. [Google Scholar] [CrossRef] [Green Version]
- Richter, C.; Nietlispach, D.; Broadhurst, R.; Weissman, K. Multienzyme docking in hybrid megasynthetases. Nat. Chem. Biol. 2008, 4, 75–81. [Google Scholar] [CrossRef] [PubMed]
- Haese, A.; Schubert, M.; Herrmann, M.; Zocher, R. Molecular characterization of the enniatin synthetase gene encoding a multifunctional enzyme catalysing N-methyldepsipeptide formation in Fusarium scirpi. Mol. Biol. 1993, 7, 905–914. [Google Scholar] [CrossRef]
- Marahiel, M.; Stachelhaus, T.; Mootz, H. Modular peptide synthetases involved in nonribosomal peptide synthesis. Chem. Rev. 1997, 97, 2651–2674. [Google Scholar] [CrossRef]
- Chang, C.; Lohman, J.; Huang, T.; Michalska, K.; Bigelow, L.; Rudolf, J.; Jędrzejczak, R.; Yan, X.; Ma, M.; Babnigg, G.; et al. Structural Insights into the Free-Standing Condensation Enzyme SgcC5 Catalyzing Ester-Bond Formation in the Biosynthesis of the Enediyne Antitumor Antibiotic C-1027. Biochemistry 2018, 57, 3278–3288. [Google Scholar] [CrossRef]
- Du, L.; Lou, L. PKS and NRPS release mechanisms. Nat. Prod. Rep. 2010, 27, 255–278. [Google Scholar] [CrossRef] [PubMed]
- Koketsu, K.; Minami, A.; Watanabe, K.; Oguri, H.; Oikawa, H. Pictet-Spenglerase involved in tetrahydroisoquinoline antibiotic biosynthesis. Curr. Opin. Chem. Biol. 2012, 16, 142–149. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Jokela, J.; Herfindal, L.; Wahlsten, M.; Sinkkonen, J.; Permi, P.; Fewer, D.; Døskeland, S.; Sivonen, K. 4-Methylproline guided natural product discovery: Co-occurrence of a 4-hydroxy- and 4-methtylprolines in nostoweipeptins and nostopeptolides. ACS Chem. Biol. 2014, 9, 2646–2655. [Google Scholar] [CrossRef]
- Bouaïcha, N.; Miles, C.; Beach, D.; Labidi, Z.; Djabri, A.; Benayache, N.; Nguyen-Quang, T. Structural diversity, characterization and toxicology of microcystins. Toxins 2019, 11, 714. [Google Scholar] [CrossRef] [Green Version]
- Jones, M.; Pinto, E.; Torres, M.; Dörr, F.; Mazur-Marzec, H.; Szubert, K.; Tartaglione, L.; Dell’Aversano, C.; Miles, C.; Beach, D.; et al. Comprehensive database of secondary metabolites from cyanobacteria. BioRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Meyer, S.; Kehr, J.; Mainz, A.; Dehm, D.; Petras, D.; Süssmuth, R.; Dittmann, E. Biochemical dissection of the natural diversification of microcystin provides lessons for synthetic biology of NRPS. Cell. Chem. Biol. 2016, 23, 462–471. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kondratyeva, N.V. Novyi vyd synio-zelenykh vodorostey—Nostoc edaphicum sp. n. [A new species of blue-green algae—Nostoc edapicum sp. n. Ukr. Bot. J. 1962, 19, 58–65. [Google Scholar]
- Komárek, J. Süsswasserflora von Mitteleuropa. Cyanoprokaryota: 3rd Part: Heterocystous Genera; Springer Spectrum: Berlin/Heidelberg, Germany, 2013; Volume 19, pp. 1–1130. [Google Scholar]
- Kotai, J. Instructions for Preparation of Modified Nutrient Solution Z8 for Algae; Publication: B-11/69; Norwegian Institute for Water Research: Oslo, Norway, 1972; p. 5. [Google Scholar]
- Bertani, G. Studies on lysogenesis. I. The mode of phage liberation by lysogenic Escherichia Coli. J. Bacteriol. 1951, 62, 293–300. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nowak, R.; Jastrzębski, J.; Kuśmirek, W.; Sałamatin, R.; Rydzanicz, M.; Sobczyk-Kopcioł, A.; Sulima-Celińska, A.; Paukszto, Ł.; Makowaczenko, K.; Płoski, R.; et al. Hybrid de novo whole genome assembly and annotation of the model tapeworm Hymenolepis diminuta. Sci. Data 2019, 6, 302. [Google Scholar] [CrossRef] [Green Version]
- Wilson, K. Preparation of genomic DNA from bacteria. In Current Protocols in Molecular Biology; Ausubel, R., Bent, R.E., Eds.; Kingston: Fountain Valley, CA, USA; Wiley & Sons: New York, NY, USA, 1987; pp. 2.10–2.12. [Google Scholar]
- Andrews, S. Babraham Bioinformatics, FastQC—A Quality Control Application for High Throughput Sequence Data. 2010. Available online: http://www.bioinformatics.babraham.ac.uk/projects/fastqc/ (accessed on 11 February 2020).
- De Coster, W.; D’Hert, S.; Schultz, D.; Cruts, M.; Van Broeckhoven, C. NanoPack: Visualizing and processing long–read sequencing data. Bioinformatics 2018, 34, 2666–2669. [Google Scholar] [CrossRef]
- Kolmogorov, M.; Yuan, J.; Lin, Y.; Pevzner, P. Assembly of long, error–prone reads using repeat graphs. Nat. Biotechnol. 2019, 37, 540–546. [Google Scholar] [CrossRef]
- Tatusova, T.; DiCuccio, M.; Badretdin, A.; Chetvernin, V.; Nawrocki, E.; Zaslavsky, L.; Lomsadze, A.; Pruitt, K.; Borodovsky, M.; Ostell, J. NCBI prokaryotic genome annotation pipeline. Nucleic Acids Res. 2016, 44, 6614–6624. [Google Scholar] [CrossRef]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef]
- Grant, J.; Arantes, A.; Stothard, P. Comparing thousands of circular genomes using the CGView comparison tool. BMC Genom. 2012, 13, 202. [Google Scholar] [CrossRef] [Green Version]
- Altschul, S.; Madden, T.; Schäffer, A.; Zhang, J.; Zhang, Z.; Miller, W.; Lipman, D. Gapped BLAST and PSI–BLAST: A new generation of protein database search programs. Nucleic Acids Res. 1997, 25, 3389–3402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Medema, M.; Blin, K.; Cimermanic, P.; de Jager, V.; Zakrzewski, P.; Fischbach, M.; Weber, T.; Takano, E.; Breitling, R. antiSMASH: Rapid identification, annotation and analysis of secondary metabolites biosynthesis gene clusters in bacterial and fungal genome sequences. Nucleic Acids Res. 2011, 39, w339–w346. [Google Scholar] [CrossRef]
- Marchler-Bauer, A.; Lu, S.; Anderson, J.; Chitsaz, F.; Derbyshire, M.; DeWesse-Scott, C.; Fong, J.; Geer, L.; Geer, R.; Gonzales, N.; et al. CDD: A conserved database for the functional annotation of proteins. Nucleic Acids Res. 2011, 39, d225–d229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Yan, R.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I–TASSER Suite: Protein structure and function prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bachmann, B.; Ravel, J. Methods for in silico prediction of microbial polyketide and nonribosomal peptide biosynthetic pathways from DNA sequence data. Methods Enzymol. 2009, 458, 181–217. [Google Scholar]
- Kumar, S.; Stecher, G.; Li, M.; Knyaz, C.; Tamura, K. MEGA X: Molecular Evolutionary Genetics Analysis across computing platforms. Mol. Biol. Evol. 2018, 35, 1547–1549. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Replicon | Accession Number | Length (bp) | Topology | G+C Content (%) | Coverage (x) Nanopore Data | Coverage (x) Illumina Data |
|---|---|---|---|---|---|---|
| pNe_1 | CP054693.1 | 44,503 | Circular | 42.3 | 115.5 | 244.8 |
| pNe_2 | CP054694.1 | 99,098 | Circular | 40.2 | 168.4 | 135.3 |
| pNe_3 | CP054695.1 | 120,515 | Circular | 41.3 | 256.4 | 177.1 |
| pNe_4 | CP054696.1 | 53,840 | Circular | 41.6 | 102.4 | 211.5 |
| pNe_5 | CP054697.1 | 264,855 | Circular | 41.0 | 226.3 | 160.7 |
| chr | CP054698.1 | 7,733,505 | Circular | 41.6 | 160.7 | 116.9 |
| NRPS Module | Adenylation Domain Residue Position | Proposed Substrate | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 235 | 236 | 239 | 278 | 299 | 301 | 322 | 330 | 331 | ||
| NcpA1 | D | A | S | T | [I] | A | A | V | C | Tyr |
| NcpA2 | D | I | L | Q | L | G | L | I | W | Gly |
| NcpA3 | D | A | W | Q | F | G | L | I | D | Gln |
| NcpB1 | D | A | F | F | L | G | V | T | F | Ile/Val |
| NcpB2 | D | V | W | H | I | S | L | I | D | Ser |
| NcpB3 | D | V | Q | [F] | I | A | H | V | A | Pro/MePro |
| NcpB4 | D | A | W | [T] | I | G | [A] | V | C | Phe/Tyr/Leu |
| Compound | Structure | m/z [M+H]+ | Retention Time [min] | |
|---|---|---|---|---|
| Cyclic | Linear–COH | |||
| Ncp-A1 | cyclo[Tyr+Gly+Gln+Ile+Ser+MePro+Leu] | 757 | 7.1 | |
| Ncp-A1-L | Tyr+Gly+Gln+Ile+Ser+MePro+Leu | 775 | 5.8 | |
| Ncp-A2 | cyclo[Tyr+Gly+Gln+Ile+Ser+MePro+Phe] | 791 | 6.0 | |
| Ncp-A2-L | Tyr+Gly+Gln+Ile+Ser+MePro+Phe | 809 | 5.6 | |
| Ncp-E1 | cyclo[Tyr+Gly+Gln+Ile+Ser+Pro+Phe] | 777 [T] | 7.2 | |
| Ncp-E1-L | Tyr+Gly+Gln+Ile+Ser+Pro+Phe | 795 | 5.7 | |
| Ncp-E2 | cyclo[Tyr+Gly+Gln+Ile+Ser+Pro+Leu] | 743 [T] | 6.3 | |
| Ncp-E2-L | Tyr+Gly+Gln+Ile+Ser+Pro+Leu | 761 | 5.1 | |
| Ncp-E3 | cyclo[Tyr+Gly+Gln+Val+Ser+MePro+Leu] | 743 [T] | 7.0 | |
| * Ncp-E4-L | [Tyr+Gly+Gln+Ile+Ser+MePro] | 677 [T] | 6.0 | |
| ** Ncp-M1 | cyclo[Tyr+Tyr+HSe+Pro+Val+MePro+Tyr] | 882 | 27.5 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fidor, A.; Grabski, M.; Gawor, J.; Gromadka, R.; Węgrzyn, G.; Mazur-Marzec, H. Nostoc edaphicum CCNP1411 from the Baltic Sea—A New Producer of Nostocyclopeptides. Mar. Drugs 2020, 18, 442. https://doi.org/10.3390/md18090442
Fidor A, Grabski M, Gawor J, Gromadka R, Węgrzyn G, Mazur-Marzec H. Nostoc edaphicum CCNP1411 from the Baltic Sea—A New Producer of Nostocyclopeptides. Marine Drugs. 2020; 18(9):442. https://doi.org/10.3390/md18090442
Chicago/Turabian StyleFidor, Anna, Michał Grabski, Jan Gawor, Robert Gromadka, Grzegorz Węgrzyn, and Hanna Mazur-Marzec. 2020. "Nostoc edaphicum CCNP1411 from the Baltic Sea—A New Producer of Nostocyclopeptides" Marine Drugs 18, no. 9: 442. https://doi.org/10.3390/md18090442
APA StyleFidor, A., Grabski, M., Gawor, J., Gromadka, R., Węgrzyn, G., & Mazur-Marzec, H. (2020). Nostoc edaphicum CCNP1411 from the Baltic Sea—A New Producer of Nostocyclopeptides. Marine Drugs, 18(9), 442. https://doi.org/10.3390/md18090442