Mining Facebook Data of People with Rare Diseases: A Content-Based and Temporal Analysis

 ,
,  and
and
Abstract
:1. Introduction
- Early onset in life (two out of three appear before the age of two);
- Chronic pain (one in five patients);
- The development of motor, sensory or intellectual deficit in half of the cases, which give rise to a disability in autonomy (one in three cases); and
- In almost half of cases, a vital prognosis is at stake, since rare diseases have a rate of 35% of deaths before one year, 10% between one and five years and 12% between five and fifteen years.
2. Materials and Methods
- A pre-selection of groups was carried out from the Facebook search engine, containing the words in Spanish of “Syndrome” or “Association of”.
- The first 10 groups of each of the two searches were preselected.
- The groups had to comply with the following terms: they are Spanish associations, they have presence in FEDER (i.e., representing one or more rare diseases), they have more than 300 participations, they have at least 10 different people participating, they have groups in Spanish, and they affect children.
3. Results and Discussion
3.1. Content-Based Analysis
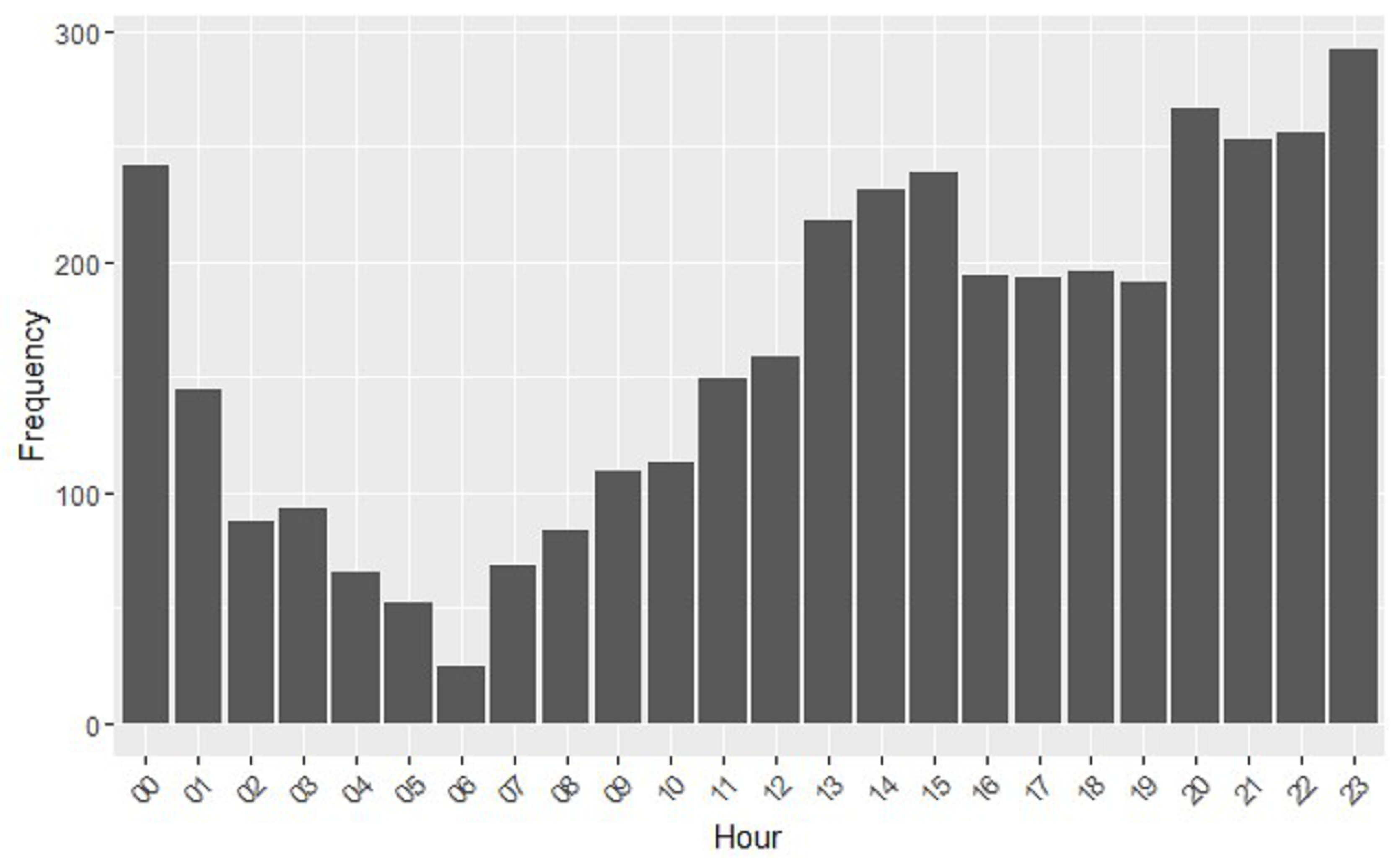
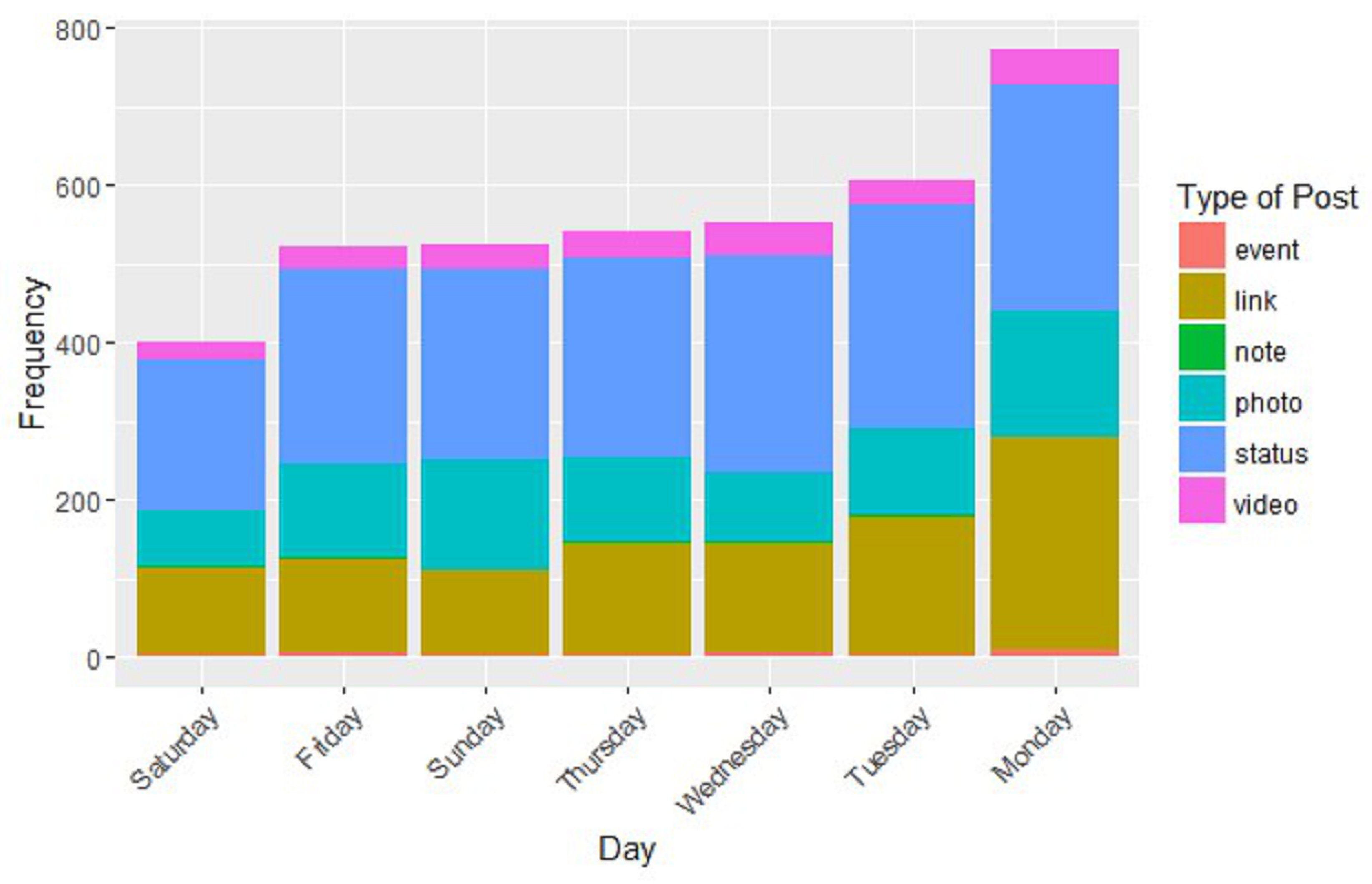
3.2. Temporal Analysis
4. Conclusions
4.1. Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Henrard, S.; Arickx, F. Negotiating Prices of Drugs for Rare Diseases. Available online: http://www.who.int/bulletin/volumes/94/10/15-163519/en (accessed on 1 January 2016).
- FEDER. Decalogue of Priorities. Available online: http://www.enfermedades-raras.orgimages/dia_mundial/pdf/Decalogoprioridades.pdf (accessed on 1 January 2015).
- Davies, W. Insights into rare diseases from social media surveys. Orphanet J. Rare Dis. 2016, 11, 151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hand, R.; Kenne, D.; Wolfram, T.; Abram, J.; Fleming, M. Assessing the Viability of Social Media for Disseminating Evidence-Based Nutrition Practice Guideline Through Content Analysis of Twitter Messages and Health Professional Interviews: An Observational Study. J. Med. Internet Res. 2016, 18, e295. [Google Scholar] [CrossRef] [PubMed]
- Reguera, N.; Subirats, L.; Armayones, M. Mining Facebook Data of People with Rare Diseases. In Proceedings of the 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), Thessaloniki, Greece, 22–24 June 2017; pp. 588–593. [Google Scholar] [CrossRef]
- Reguera, N. Las Enfermedades Raras en Grupos de Facebook: Evaluación de la Línea de Actuación de FEDER Mediante Minería de Textos. Master’s Thesis, Universitat Oberta de Catalunya, Barcelona, Spain, 2017. [Google Scholar]
- Rooney, E. How to Promote Your Rare Disease Story through Social Media. Available online: https://globalgenes.org/wp-content/uploads/2016/02/GG_toolkit_social-mediastorytelling_021016_WEB.pdf (accessed on 1 January 2016).
- Chempetitive Group. Rare Diseases: The Role of Social Media in Patient Recruitment. Available online: https://chempetitive.com/chemunity/rare-diseases-role-social-media-patient-recruitment (accessed on 1 January 2016).
- Smale, F. Social Media and the Rare Disease Community. Available online: http://www.orphan-drugs.org/2015/01/29/social-media-rare-disease-community (accessed on 1 January 2015).
- Armayones, M.; Requena, S.; Gómez-Zúñiga, B.; Pousada, M.; Bañón, A.M. El uso de facebook en asociaciones españolas de enfermedades raras: cómo y para qué lo utilizan? Gac. Sanit. 2014, 29, 335–340. [Google Scholar] [CrossRef] [PubMed]
- Subirats, L.; Ceccaroni, L.; Lopez-Blazquez, R.; Miralles, F.; García-Rudolph, A.; Tormos, J.M. Circles of Health: Towards an advanced social network about disabilities of neurological origin. J. Biomed. Inform. 2013, 46, 1006–1029. [Google Scholar] [CrossRef] [PubMed]
- Subirats, L.; Lopez-Blazquez, R.; Ceccaroni, L.; Gifre, M.; Miralles, F.; García-Rudolph, A.; Tormos, J.M. Monitoring and Prognosis System Based on the ICF for People with Traumatic Brain Injury. Int. J. Environ. Res. Public Health 2015, 12, 9832–9847. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palomino, M.; Taylor, T.; Göker, A.; Isaacs, J.; Warber, S. The Online Dissemination of Nature–Health Concepts: Lessons from Sentiment Analysis of Social Media Relating to “Nature-Deficit Disorder”. Int. J. Environ. Res. Public Health 2016, 13, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larsen, M.; Boonstra, T.; Batterham, P.; ODea, B.; Paris, C.; Christensen, H. We feel: Mapping emotion on twitter. IEEE J. Biomed. Health Inform. 2015, 19, 1246–1252. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Lee, A.; Kuo, S. Mining health social media with sentiment analysis. J. Med. Syst. 2016, 40, 236. [Google Scholar] [CrossRef] [PubMed]
- Lasker, J.; Sogolow, E.; Sharim, R. The role of an online community for people with a rare disease: Content analysis of messages posted on a primary biliary cirrhosis mailinglist. J. Med. Internet Res. 2005, 7, e10. [Google Scholar] [CrossRef] [PubMed]
- Jacobs, R.; Boyd, L.; Brennan, K.; Sinha, C.; Giuliani, S. The importance of social media for patients and families affected by congenital anomalies: A facebook cross-sectional analysis and user survey information platform. J. Pediatr. Surg. 2016, 51, 1766–1771. [Google Scholar] [CrossRef] [PubMed]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Greaves, F.; Ramirez-Cano, D.; Millett, C.; Darzi, A.; Donaldson, L. Use of sentiment analysis for capturing patient experience from free-text comments posted online. J. Med. Internet Res. 2013, 15, e239. [Google Scholar] [CrossRef] [PubMed]
- Tai, C.H.; Tan, Z.H.; Chang, Y.S. Systematical Approach for Detecting the Intention and Intensity of Feelings on Social Network. IEEE J. Biomed. Health Inform. 2016, 20, 987–995. [Google Scholar] [CrossRef] [PubMed]
- Akay, A.; Dragomir, A.; Erlandsson, B. Network-Based Modeling and Intelligent Data Mining of Social Media for Improving Care. IEEE J. Biomed. Health Inform. 2015, 19, 210–218. [Google Scholar] [CrossRef] [PubMed]
- Rayson, P.; Garside, R. Comparing corpora using frequency profiling. In Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics (ACL 2000), Hong Kong, China, 7 October 2000; pp. 1–6. [Google Scholar]
- Gabrielatos, C.; Marchi, A. Keyness: Appropriate metrics and practical issues. In Proceedings of the CADS International Conference, Bologna, Italy, 13–14 September 2012. [Google Scholar]
- Wilson, A. Embracing Bayes Factors for Key Item Analysis in Corpus Linguistics; Language Competence and Language Awareness in Europe; Peter Lang: Bern, Switzland, 2013; pp. 3–11. [Google Scholar]
- Johnston, J.; Berry, K.; Mielke, P. Measures of effect size for chi-squared and likelihood-ratio goodness-of-fit tests. Percept. Mot. Skills 2006, 103, 412–414. [Google Scholar] [CrossRef] [PubMed]
- Diakopoulos, N.; Elgesem, D.; Salway, A.; Zhang, A.; Hofland, K. Compare Clouds: Visualizing Text Corpora to Compare Media Frames. In Proceedings of the IUI Workshop on Visual Text Analytics, Atlanta, GA, USA, 29 March 2015. [Google Scholar]
- Scanfeld, D.; Scanfeld, V.; Larson, E.L. Dissemination of health information through social networks: Twitter and antibiotics. Am. J. Infect. Control 2010, 38, 182–188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Townsend, L.; Wallace, C. Social Media Research: A Guide to Ethics; Technical Report, ESRC Grant Report; University of Aberdeen: Aberdeen, UK, 2016. [Google Scholar]
- Beel, J.; Gipp, B.; Langer, S.; Breitinger, C. Research-paper recommender systems: A literature survey. Int. J. Digit. Libr. 2015, 17, 305–338. [Google Scholar] [CrossRef]
- Pojanapunya, P.; Todd, R.W. Log-likelihood and odds ratio: Keyness statistics for different purposes of keyword analysis. Corpus Linguist. Linguist. Theory 2016, 14, 133–167. [Google Scholar] [CrossRef]
- Ramírez-Tinoco, F.J.; Alor-Hernández, G.; Sánchez-Cervantes, J.L.; Olivares-Zepahua, B.A.; Rodríguez-Mazahua, L. A Brief Review on the Use of Sentiment Analysis Approaches in Social Networks. In Trends and Applications in Software Engineering; Mejia, J., Muñoz, M., Rocha, Á., Quiñonez, Y., Calvo-Manzano, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 263–273. [Google Scholar]
- Smedt, T.D.; Daelemans, W. Pattern for Python. J. Mach. Learn. Res. 2012, 13, 2031–2035. [Google Scholar]
- Sabate, F.; Berbegal-Mirabent, J.; Cañabate, A.; Lebherz, P.R. Factors influencing popularity of branded content in Facebook fan pages. Eur. Manag. J. 2014, 32, 1001–1011. [Google Scholar] [CrossRef]
- Pletikosa-Cvijikj, I.; Michahelles, F. Online engagement factors on Facebook brand pages. Soc. Netw. Anal. Min. 2013, 3, 843–861. [Google Scholar] [CrossRef]
- Burke, M.; Kraut, R.E. Growing Closer on Facebook: Changes in Tie Strength Through Social Network Site Use. In Proceedings of the 32nd Annual ACM Conference on Human Factors in Computing Systems (CHI’14), Toronto, ON, Canada, 26 April–1 May 2014; ACM: New York, NY, USA, 2014; pp. 4187–4196. [Google Scholar] [CrossRef]
- Leiva, V.; Freire, A. Towards Suicide Prevention: Early Detection of Depression on Social Media. In Lecture Notes in Computer Science, Proceedings of the Internet Science (INSCI 2017), Thessaloniki, Greece, 22–24 November 2017; Springer: New York, NY, USA, 2017; Volume 10673, p. 10673. [Google Scholar]
- Montoyo, A.; Martínez-Barco, P.; Balahur, A. Subjectivity and sentiment analysis: An overview of the current state of the area and envisaged developments. Decis. Support Syst. 2012, 53, 675–679. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decalogue | Total | ||
|---|---|---|---|
| Frequency of word | a | b | |
| Frequency of other words | |||
| Total | c | d |
| Attribute | Event | Link | Note | Photo | Status | Video | Total |
|---|---|---|---|---|---|---|---|
| Likes | 3.8 (4.3) | 5.2 (6.1) | 2.3 (3.2) | 12.0 (12.8) | 4.6 (6.5) | 6.1 (6.4) | 6.4 (8.6) |
| Comments | 0.3 (0.6) | 0.8 (1.9) | 0.4 (1.0) | 2.6 (5.3) | 2.9 (5.9) | 0.8 (1.8) | 2.1 (4.9) |
| Reactions | 3.9 (4.3) | 5.3 (6.3) | 2.3 (3.2) | 12.2 (13.1) | 4.7 (6.6) | 6.1 (6.5) | 6.5 (8.7) |
| Shares | 4.1 (9.7) | 0.0 (0.4) | 0.0 (0.0) | 0.9 (4.9) | 0.1 (1.4) | 0.4 (3.0) | 0.3 (2.7) |
| Engagement | 8.3 (9.5) | 6.2 (6.9) | 2.8 (3.6) | 15.6 (17.4) | 7.7 (10.3) | 7.3 (9.4) | 8.9 (11.8) |
| Instances | 34 | 1063 | 9 | 792 | 1787 | 232 | 3917 |
| Word | LL Score | Times in Facebook | Times in the Decalogue |
|---|---|---|---|
| nacional (national) | 20.2 | 32 | 9 |
| discapacidad (disability) | 13.4 | 53 | 9 |
| nivel (level) | 7.8 | 28 | 5 |
| ayuda (help) | 7.5 | 195 | 1 |
| profesionales (professionals) | 6.1 | 23 | 4 |
| referencia (reference) | 5.0 | 28 | 4 |
| vida (life) | 4.3 | 190 | 2 |
| frecuentes (frequents) | 3.8 | 35 | 4 |
| enfermedades (diseases) | 3.3 | 192 | 12 |
| ser (to be) | 3.2 | 167 | 2 |
| personas (people) | 3.0 | 206 | 3 |
| hijo (son) | 3.0 | 112 | 1 |
| Word | LL Score | Times in Facebook | Times in the Decalogue |
|---|---|---|---|
| causa (cause) | 0.063 | 48 | 2 |
| social (social) | 0.051 | 36 | 1 |
| difundir (promulgate) | 0.047 | 23 | 1 |
| medio (middle/way) | 0.031 | 24 | 1 |
| experiencias (experiences) | 0.027 | 34 | 1 |
| forma (form) | 0.021 | 52 | 2 |
| general (general) | 0.01 | 32 | 1 |
| cuanto (how much) | 0.01 | 26 | 1 |
| todas (all) | 0.007 | 91 | 3 |
| dice (says) | 0.000014 | 29 | 1 |
| Text | Polarity | Subjectivity |
|---|---|---|
| Again, my daughter with her crises. This is already once a month, isn’t it dreadful to know that she can not be like the rest of her friends or brothers?? | −1 | 1 |
| Happy day Cri Du Chat dear family!!! | 1 | 1 |
| This article provides rehabilitation exercises for cerebellar ataxia think it may be interesting for patients with Wolfram. | 0.5 | 0.5 |
| I will attach separate interviews. The next one is aimed at parents. | 0 | 0 |
| Attribute | Likes | Comments | Reactions | Shares | Engagement |
|---|---|---|---|---|---|
| Polarity | 0.10 | 0.04 | 0.10 | 0.02 | 0.08 |
| Subjectivity | 0.07 | 0.11 | 0.07 | 0.03 | 0.10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Subirats, L.; Reguera, N.; Bañón, A.M.; Gómez-Zúñiga, B.; Minguillón, J.; Armayones, M. Mining Facebook Data of People with Rare Diseases: A Content-Based and Temporal Analysis. Int. J. Environ. Res. Public Health 2018, 15, 1877. https://doi.org/10.3390/ijerph15091877
Subirats L, Reguera N, Bañón AM, Gómez-Zúñiga B, Minguillón J, Armayones M. Mining Facebook Data of People with Rare Diseases: A Content-Based and Temporal Analysis. International Journal of Environmental Research and Public Health. 2018; 15(9):1877. https://doi.org/10.3390/ijerph15091877
Chicago/Turabian StyleSubirats, Laia, Natalia Reguera, Antonio Miguel Bañón, Beni Gómez-Zúñiga, Julià Minguillón, and Manuel Armayones. 2018. "Mining Facebook Data of People with Rare Diseases: A Content-Based and Temporal Analysis" International Journal of Environmental Research and Public Health 15, no. 9: 1877. https://doi.org/10.3390/ijerph15091877
APA StyleSubirats, L., Reguera, N., Bañón, A. M., Gómez-Zúñiga, B., Minguillón, J., & Armayones, M. (2018). Mining Facebook Data of People with Rare Diseases: A Content-Based and Temporal Analysis. International Journal of Environmental Research and Public Health, 15(9), 1877. https://doi.org/10.3390/ijerph15091877