XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction




Abstract
:1. Introduction
- Proposing an efficient extreme gradient boosting (XGBoost) based framework incorporated with the hybrid feature selection (HFS) method for smoking–induced noncommunicable diseases (SiNCDs) prediction.
- Applying the XGBoost based framework to real-world NHANES datasets of South Korea and the United States. Our empirical comparison analysis shows that the proposed model outperformed existing baseline models.
- Findings are expected to contribute toward achieving good health and wellbeing (ultimate targets of SDGs of UN).
2. Materials Methods
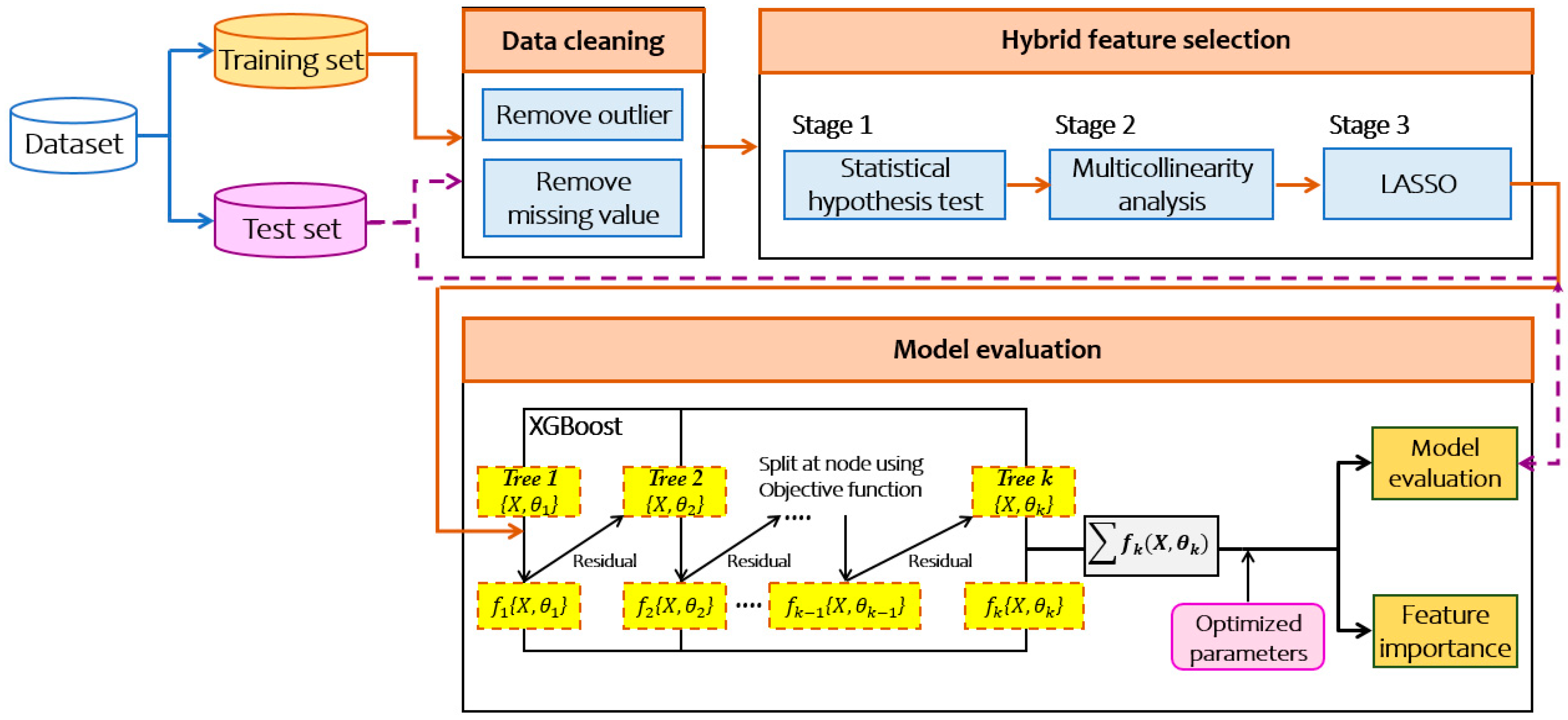
2.1. Proposed Framework
2.1.1. Three-Stage HFS
- Step 1: Statistical Hypothesis Test (t-test and p-value)The first stage excludes redundant and irrelevant features in order to reduce the complexity for training model. For this purpose, it assesses chi-square test for categorical features and t-test for continuous features to accept or reject the alternative hypothesis. After the test, if deemed significant, features are stored for the first stage filtering. Otherwise, such features are excluded.
- Step 2: Multicollinearity AnalysisThe key assumption behind the multicollinearity analysis [20] is that it indicates the correlation between independent features. The value of variance inflation factor is used to verify multicollinearity in regression analysis. In essence, this step takes the complete set of features and loops through all of them applying the appropriate test.
- Step 3: Least Absolute Shrinkage and Selection Operator (LASSO)LASSO [21] has been extensively used in both fields of statistics and machine learning. Several studies [22,23] proposed the LASSO method for estimating the causal effect to identify their outcomes. A rational decision is taken to execute the LASSO in order to select a group of features simultaneously for a given task. During the feature selection process, LASSO penalizes the coefficients of the regression features, regularizing some of them to zero. On the contrary, features that still have a non-zero coefficient after the regularizing process remain to be part of the training model. This stage allows us to prevent the predictive of the causal inference problem.
2.1.2. XGBoost Classifier
2.2. Experimental Setup
2.2.1. Experimental Environment
2.2.2. Baseline Models
3. Experimental Results and Discussion
3.1. Dataset
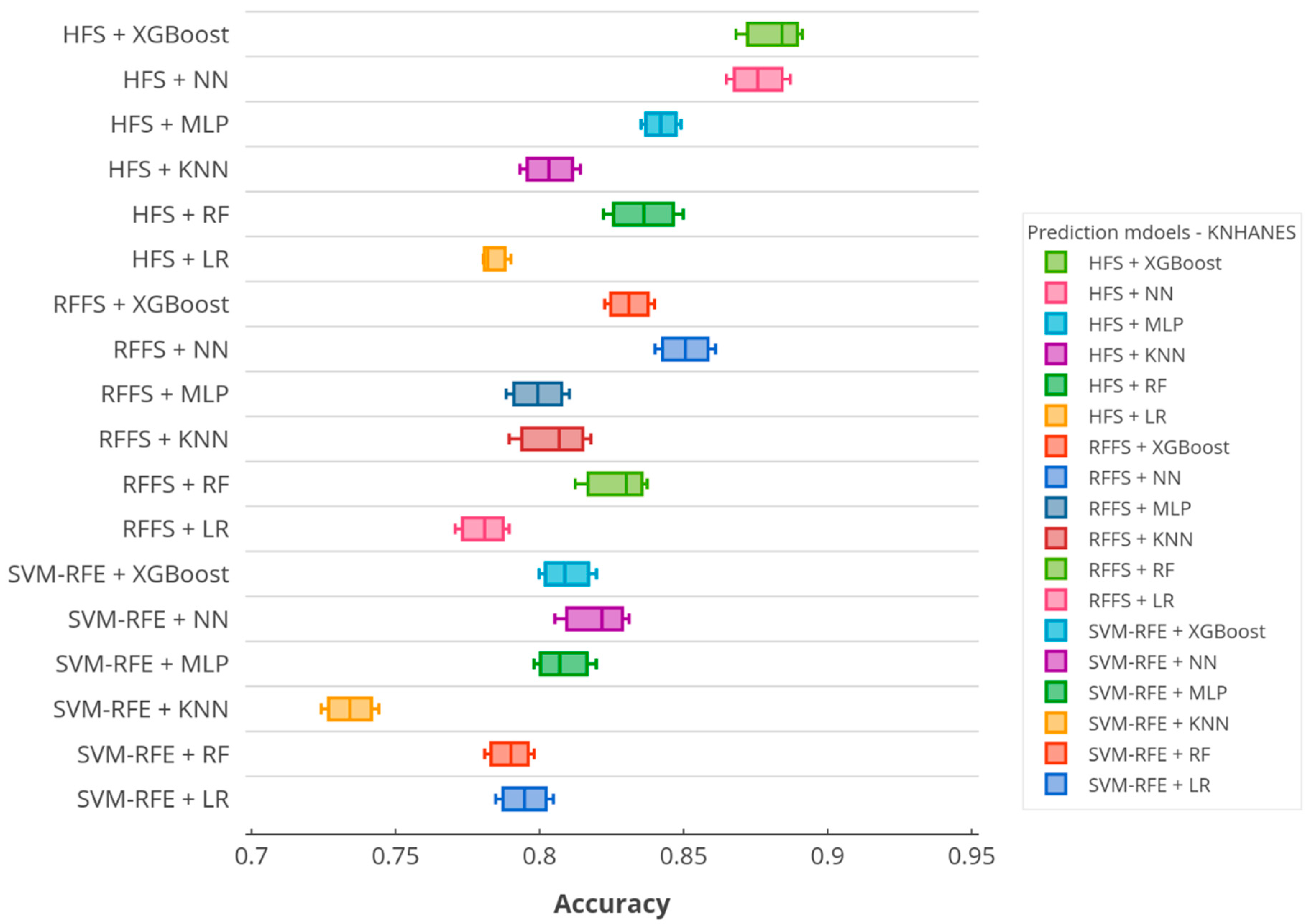
3.2. The Results of Hybrid Feature Selection (HFS)
3.3. The Results of the Comparative Analysis
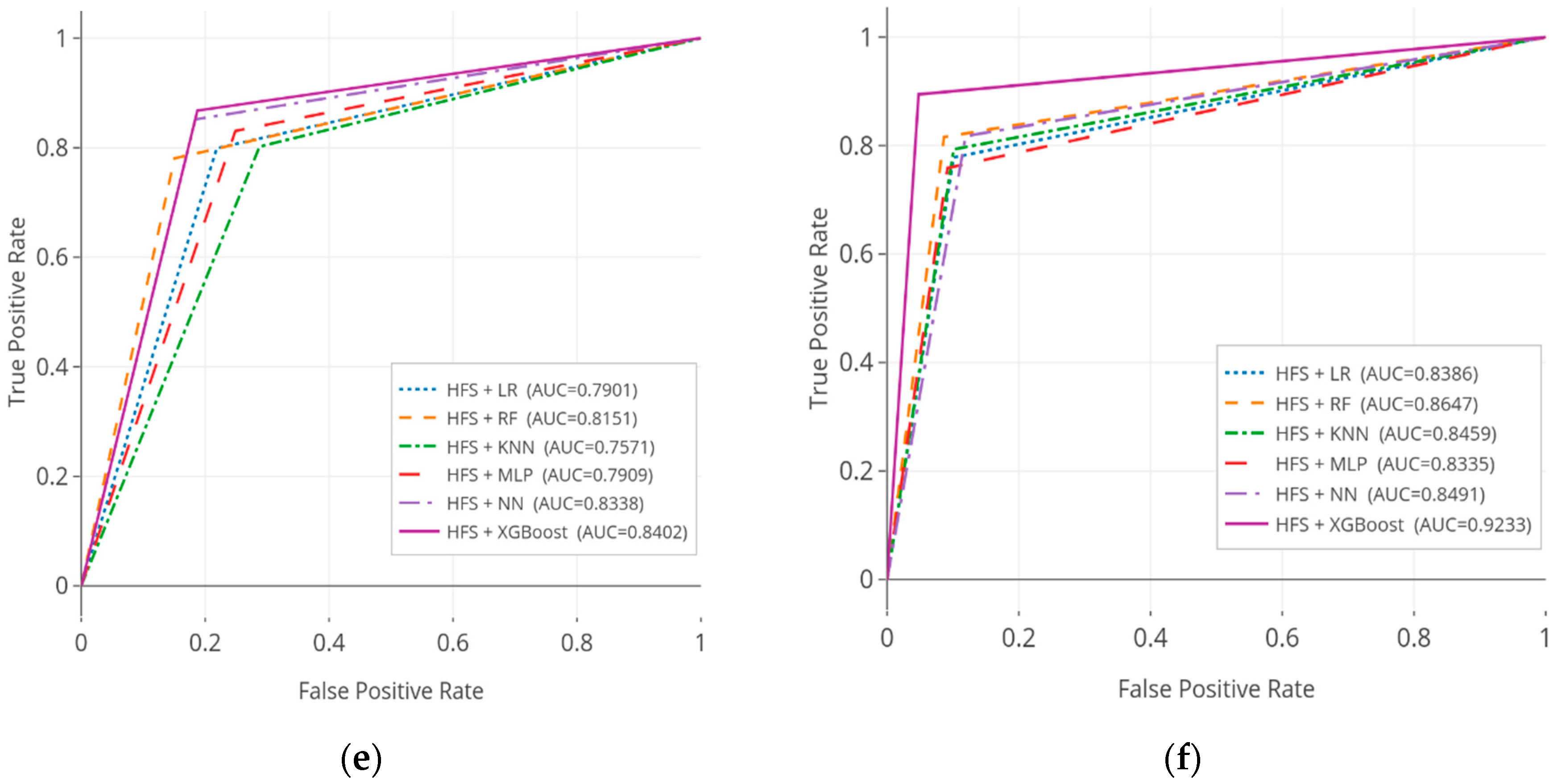
3.4. Interpretability of Predictive Model
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section/Topic | Item | Checklist Item | Page | |
|---|---|---|---|---|
| Title and abstract | ||||
| Title | 1 | D; V | Identify the study as developing and/or validating a multivariable prediction model, the target population, and the outcome to be predicted. | 1 |
| Abstract | 2 | D; V | Provide a summary of objectives, study design, setting, participants, sample size, predictors, outcome, statistical analysis, results, and conclusions. | 2 |
| Introduction | ||||
| Background and objectives | 3a | D; V | Explain the medical context (including whether diagnostic or prognostic) and rationale for developing or validating the multivariable prediction model, including references to existing models. | 2–3 |
| 3b | D; V | Specify the objectives, including whether the study describes the development or validation of the model or both. | 3–5 | |
| Methods | ||||
| Source of data | 4a | D; V | Describe the study design or source of data (e.g., randomized trial, cohort, or registry data), separately for the development and validation datasets, if applicable. | 6–7 |
| 4b | D; V | Specify the key study dates, including start of accrual; end of accrual; and, if applicable, end of follow-up. | 6–7 | |
| Participants | 5a | D; V | Specify key elements of the study setting (e.g., primary care, secondary care, general population), including number and location of centers. | 6–7 |
| 5b | D; V | Describe eligibility criteria for participants. | 6–7 Figure 3 and Figure 4 | |
| 5c | D; V | Give details of treatments received, if relevant. | n/a | |
| Outcome | 6a | D; V | Clearly define the outcome that is predicted by the prediction model, including how and when assessed. | 8–12 |
| 6b | D; V | Report any actions to blind assessment of the outcome to be predicted. | 9–12 | |
| Predictors | 7a | D; V | Clearly define all predictors used in developing the multivariable prediction model, including how and when they were measured. | 7–8 |
| 7b | D; V | Report any actions to blind assessment of predictors for the outcome and other predictors. | 7–8 | |
| Sample size | 8 | D; V | Explain how the study size was arrived at. | 7–8 |
| Missing data | 9 | D; V | Describe how missing data were handled (e.g., complete-case analysis, single imputation, multiple imputation) with details of any imputation method. | 7 |
| Statistical analysis methods | 10a | D | Describe how predictors were handled in the analyses. | 7–8 |
| 10b | D | Specify type of model, all model-building procedures (including any predictor selection), and method for internal validation. | 4–5, 8 Figure 1 | |
| 10c | V | For validation, describe how the predictions were calculated. | 8 | |
| 10d | D; V | Specify all measures used to assess model performance and, if relevant, to compare multiple models. | 8 Figure 2 | |
| 10e | V | Describe any model updating (e.g., recalibration) arising from the validation, if done. | 8 | |
| Risk groups | 11 | D; V | Provide details on how risk groups were created, if done. | 7 |
| Development vs. validation | 12 | V | For validation, identify any differences from the development data in setting, eligibility criteria, outcome, and predictors. | 8 |
| Results | ||||
| Participants | 13a | D; V | Describe the flow of participants through the study, including the number of participants with and without the outcome and, if applicable, a summary of the follow-up time. A diagram may be helpful. | Figure 3 and Figure 4 |
| 13b | D; V | Describe the characteristics of the participants (basic demographics, clinical features, available predictors), including the number of participants with missing data for predictors and outcome. | Figure 3 and Figure 4 | |
| 13c | V | For validation, show a comparison with the development data of the distribution of important variables (demographics, predictors, and outcome). | Table A2 and Table A3 | |
| Model development | 14a | D | Specify the number of participants and outcome events in each analysis. | 7–8 |
| 14b | D | If done, report the unadjusted association between each candidate predictor and outcome. | 8–9 | |
| Model specification | 15a | D | Present the full prediction model to allow predictions for individuals (i.e., all regression coefficients, and model intercept or baseline survival at a given time point). | 10 |
| 15b | D | Explain how to use the prediction model. | 8–12 | |
| Model performance | 16 | D; V | Report performance measures (with CIs) for the prediction model. | 11 Table 4 |
| Model-updating | 17 | V | If done, report the results from any model updating (i.e., model specification, model performance). | 12–13 |
| Discussion | ||||
| Limitations | 18 | D; V | Discuss any limitations of the study (such as non-representative sample, few events per predictor, missing data). | 15 |
| Interpretation | 19a | V | For validation, discuss the results with reference to performance in the development data, and any other validation data. | 13–14 |
| 19b | D; V | Give an overall interpretation of the results, considering objectives, limitations, results from similar studies, and other relevant evidence. | 14–15 | |
| Implications | 20 | D; V | Discuss the potential clinical use of the model and implications for future research. | 14–15 |
| Other information | ||||
| Supplementary information | 21 | D; V | Provide information about the availability of supplementary resources, such as study protocol, web calculator, and datasets. | 16–18 |
| Funding | 22 | D; V | Give the source of funding and the role of the funders for the present study. | 15 |
Appendix B
| Features | p-Value | Multicollinearity Coefficient | |
|---|---|---|---|
| 1 | Gender | <0.01 | 1.081 |
| 2 | Age | <0.01 | 1.523 |
| 3 | Household income | <0.01 | 2.901 |
| 4 | Education | <0.01 | 1.125 |
| 5 | Occupation | <0.01 | 2.016 |
| 6 | Marital status | <0.01 | 3.553 |
| 7 | Subjective health status | <0.01 | 1.778 |
| 8 | Depression diagnosis | <0.01 | 1.286 |
| 9 | Health checkup status | <0.01 | 1.047 |
| 10 | Athletic ability | <0.01 | 1.124 |
| 11 | Self-management | 0.16 | ~ |
| 12 | Daily activities | 0.58 | ~ |
| 13 | Pain/discomfort | <0.01 | 2.229 |
| 14 | Anxious/Depressed | <0.01 | 4.345 |
| 15 | EQ-5D index | <0.01 | 2.473 |
| 16 | Economic activity status | 0.50 | ~ |
| 17 | Weight control: exercise | <0.01 | 3.329 |
| 18 | Lifetime drinking experience | <0.01 | 1.171 |
| 19 | Start drinking age | <0.01 | 1.003 |
| 20 | Frequency of drinking for 1 year | <0.01 | 1.532 |
| 21 | Monthly drinking rate | <0.01 | 3.152 |
| 22 | Stress level | <0.01 | 3.033 |
| 23 | Indoor indirect smoking exposure | <0.01 | 1.221 |
| 24 | The usual time spent sitting (day) | <0.01 | 1.096 |
| 25 | Walk duration (hours) | <0.01 | 1.114 |
| 26 | Family history of chronic disease | <0.01 | 1.087 |
| 27 | Body mass index (kg/m2) | <0.01 | 1.048 |
| 28 | Obesity prevalence | <0.01 | 2.675 |
| 29 | Fasting blood sugar | <0.01 | 2.536 |
| 30 | Total cholesterol | <0.01 | 1.151 |
| 31 | Flexible exercise days per week | <0.01 | 1.038 |
| 32 | Residence area | <0.01 | 1.547 |
| Features | p-Value | Multicollinearity Coefficient | |
|---|---|---|---|
| 1 | Gender | <0.01 | 2.005 |
| 2 | Age | <0.01 | 1.008 |
| 3 | Body mass index (kg/m2) | <0.01 | 3.005 |
| 4 | Pulse regular or irregular? | 0.19 | ~ |
| 5 | Systolic: blood pressure | <0.01 | 2.015 |
| 6 | Diastolic: blood pressure | <0.01 | 1.875 |
| 7 | Education level | <0.01 | 1.076 |
| 8 | Marital status | <0.01 | 3.092 |
| 9 | Total number of people in the household | 0.32 | ~ |
| 10 | Annual household income | <0.01 | 5.312 |
| 11 | Health risk for diabetes (among family history) | <0.01 | 3.533 |
| 12 | Taking insulin or not | <0.01 | 1.453 |
| 13 | Number of healthcare counseling over past year | <0.01 | 2.027 |
| 14 | Salt usage level | 0.12 | ~ |
| 15 | Total sugars (gm) | <0.01 | 1.298 |
| 16 | Alcohol (gm) | <0.01 | 2.479 |
| 17 | Frequency of alcohol usage | <0.01 | 2.204 |
| 18 | High cholesterol level | <0.01 | 1.340 |
| 19 | General health condition | <0.01 | 1.199 |
| 20 | #times receive healthcare over past year | <0.01 | 1.249 |
| 21 | Received hepatitis A vaccine | <0.01 | 2.012 |
| 22 | Family monthly poverty level category | <0.01 | 1.004 |
| 23 | Doctor ever said you were overweight | <0.01 | 1.012 |
| 24 | Doctor told you to exercise | <0.01 | 1.004 |
| 25 | Feeling down, depressed, or hopeless | <0.01 | 1.012 |
| 26 | Feeling tired or having little energy | <0.01 | 1.004 |
| 27 | Poor appetite or overeating | <0.01 | 5.005 |
| 28 | Trouble concentrating on things | <0.01 | 2.292 |
| 29 | Description of job/work situation | 0.13 | ~ |
| 30 | Ever told doctor had trouble sleeping? | <0.01 | 1.012 |
| 31 | Number of people who live here smoke tobacco? | <0.01 | 1.035 |
| 32 | Number of people who smoke inside this home? | <0.01 | 1.424 |
| 33 | Last 7-d worked at job not at home? | <0.01 | 2.404 |
| 34 | Last 7-d at job someone smoked indoors? | <0.01 | 1.205 |
| 35 | Last 7-d in other indoor area? | <0.01 | 2.108 |
References
- Forouzanfar, M.H.; Afshin, A.; Alexander, L.T.; Anderson, H.R.; Bhutta, Z.A.; Biryukov, S.; Cohen, A.J. Global, regional, and national comparative risk assessment of 79 behavioural, environmental and occupational, and metabolic risks or clusters of risks, 1990–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lancet 2016, 388, 1659–1724. [Google Scholar] [CrossRef] [Green Version]
- Kathirvel, S. Sustainable development goals and noncommunicable diseases: Roadmap till 2030–A plenary session of world noncommunicable diseases congress 2017. Int. J. Noncommunicable Dis. 2018, 3, 3. [Google Scholar] [CrossRef]
- World Health Organization. Action plan for the prevention and control of noncommunicable diseases in the WHO European Region. In Proceedings of the Regional Committee for Europe 66th Session, Copenhagen, Denmark, 12–15 September 2016. [Google Scholar]
- Vardavas, C.I.; Nikitara, K. COVID-19 and smoking: A systematic review of the evidence. Tob. Induc. Dis. 2020, 18. [Google Scholar] [CrossRef] [PubMed]
- Berlin, I.; Thomas, D.; Le Faou, A.L.; Cornuz, J. COVID-19 and smoking. Nicotine Tob. Res. 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoon, J.; Seo, H.; Oh, I.H.; Yoon, S.J. The non-communicable disease burden in Korea: Findings from the 2012 Korean Burden of Disease Study. J. Korean Med Sci. 2016, 31 (Suppl. 2), S158–S167. [Google Scholar] [CrossRef]
- Chen, S.; Kuhn, M.; Prettner, K.; Bloom, D.E. The macroeconomic burden of noncommunicable diseases in the United States: Estimates and projections. PLoS ONE 2018, 13, e0206702. [Google Scholar] [CrossRef]
- Hu, X.; Wang, Y.; Huang, J.; Zheng, R. Cigarette Affordability and Cigarette Consumption among Adult and Elderly Chinese Smokers: Evidence from A Longitudinal Study. Int. J. Environ. Res. Public Health 2019, 16, 4832. [Google Scholar] [CrossRef] [Green Version]
- Davagdorj, K.; Yu, S.H.; Kim, S.Y.; Huy, P.V.; Park, J.H.; Ryu, K.H. Prediction of 6 Months Smoking Cessation Program among Women in Korea. Int. J. Mach. Learn. Comput. 2019, 9, 83–90. [Google Scholar] [CrossRef] [Green Version]
- Ng, M.; Freeman, M.K.; Fleming, T.D.; Robinson, M.; Dwyer-Lindgren, L.; Thomson, B.; Murray, C.J. Smoking prevalence and cigarette consumption in 187 countries, 1980-2012. JAMA 2014, 311, 183–192. [Google Scholar] [CrossRef] [Green Version]
- Davagdorj, K.; Lee, J.S.; Park, K.H.; Ryu, K.H. A machine-learning approach for predicting success in smoking cessation intervention. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Al-Obaide, M.A.; Ibrahim, B.A.; Al-Humaish, S.; Abdel-Salam, A.S.G. Genomic and bioinformatics approaches for analysis of genes associated with cancer risks following exposure to tobacco smoking. Front. Public Health 2018, 6, 84. [Google Scholar] [CrossRef] [Green Version]
- Kondo, K.; Ohfuji, S.; Watanabe, K.; Yamagami, H.; Fukushima, W.; Ito, K. Japanese Case-Control Study Group for Crohn’s disease. The association between environmental factors and the development of Crohn’s disease with focusing on passive smoking: A multicenter case-control study in Japan. PLoS ONE 2019, 14, e0216429. [Google Scholar] [CrossRef] [PubMed]
- Breckenridge, C.B.; Berry, C.; Chang, E.T.; Sielken Jr, R.L.; Mandel, J.S. Association between Parkinson’s disease and cigarette smoking, rural living, well-water consumption, farming and pesticide use: Systematic review and meta-analysis. PLoS ONE 2016, 11, e0151841. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, R.; Lin, J. Identification of feature risk pathways of smoking-induced lung cancer based on SVM. PLoS ONE 2020, 15, e0233445. [Google Scholar] [CrossRef] [PubMed]
- Amaral, J.L.; Lopes, A.J.; Jansen, J.M.; Faria, A.C.; Melo, P.L. An improved method of early diagnosis of smoking-induced respiratory changes using machine learning algorithms. Comput. Methods Programs Biomed. 2013, 112, 441–454. [Google Scholar] [CrossRef] [Green Version]
- Piao, Y.; Piao, M.; Ryu, K.H. Multiclass cancer classification using a feature subset-based ensemble from microRNA expression profiles. Comput. Biol. Med. 2017, 80, 39–44. [Google Scholar] [CrossRef]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Zihni, E.; Madai, V.I.; Livne, M.; Galinovic, I.; Khalil, A.A.; Fiebach, J.B.; Frey, D. Opening the black box of artificial intelligence for clinical decision support: A study predicting stroke outcome. PLoS ONE 2020, 15, e0231166. [Google Scholar] [CrossRef] [Green Version]
- Salmerón Gómez, R.; García Pérez, J.; López Martín, M.D.M.; García, C.G. Collinearity diagnostic applied in ridge estimation through the variance inflation factor. J. Appl. Stat. 2016, 43, 1831–1849. [Google Scholar] [CrossRef]
- Meier, L.; Van De Geer, S.; Bühlmann, P. The group lasso for logistic regression. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2008, 70, 53–71. [Google Scholar] [CrossRef] [Green Version]
- Belloni, A.; Chernozhukov, V.; Hansen, C. High-dimensional methods and inference on structural and treatment effects. J. Econ. Perspect. 2014, 28, 29–50. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, D.; Zhu, Y.; Coffman, D.L. Penalized regression procedures for variable selection in the potential outcomes framework. Stat. Med. 2015, 34, 1645–1658. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, New York, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Vanderplas, J. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28–30 June 2010. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; Géron, A., Ed.; O’Reilly Media Inc.: Seastopol, CA, USA, 2019. [Google Scholar]
- Bagley, S.C.; White, H.; Golomb, B.A. Logistic regression in the medical literature: Standards for use and reporting, with particular attention to one medical domain. J. Clin. Epidemiol. 2001, 54, 979–985. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Tan, P.N. Introduction to Data Mining, Pearson Education India; Indian Nursing Council: New Delhi, India, 2018.
- Lisboa, P.J. A review of evidence of health benefit from artificial neural networks in medical intervention. Neural Netw. 2002, 15, 11–39. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance. Neural Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef] [Green Version]
- Lin, X.; Yang, F.; Zhou, L.; Yin, P.; Kong, H.; Xing, W.; Xu, G. A support vector machine-recursive feature elimination feature selection method based on artificial contrast variables and mutual information. J. Chromatogr. B 2012, 910, 149–155. [Google Scholar] [CrossRef]
- Qi, Y. Random forest for bioinformatics. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 307–323. [Google Scholar]
- Collins, G.S.; Reitsma, J.B.; Altman, D.G.; Moons, K.G. Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD) The TRIPOD Statement. Circulation 2015, 131, 211–219. [Google Scholar] [CrossRef] [Green Version]
- Korea Centers for Disease Control & Prevention. Available online: http://knhanes.cdc.go.kr (accessed on 7 September 2020).
- Centers for Disease Control and Prevention. Available online: https://www.cdc.gov/nchs/nhanes (accessed on 7 September 2020).
- Davagdorj, K.; Lee, J.S.; Pham, V.H.; Ryu, K.H. A Comparative Analysis of Machine Learning Methods for Class Imbalance in a Smoking Cessation Intervention. Appl. Sci. 2020, 10, 3307. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Altman, D.G.; Bland, J.M. Diagnostic tests. 1: Sensitivity and specificity. BMJ Br. MedJ. 1994, 308, 1552. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Elshawi, R.; Al-Mallah, M.H.; Sakr, S. On the interpretability of machine learning-based model for predicting hypertension. BMC Med. Inform. Decis. Mak. 2019, 19, 146. [Google Scholar] [CrossRef] [Green Version]
- Wakabayashi, M.; McKetin, R.; Banwell, C.; Yiengprugsawan, V.; Kelly, M.; Seubsman, S.A. Thai Cohort Study Team. Alcohol consumption patterns in Thailand and their relationship with non-communicable disease. BMC Public Health 2015, 15, 1297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, H.C.; Oh, S.M. Noncommunicable diseases: Current status of major modifiable risk factors in Korea. J. Prev. Med. Public Health 2013, 46, 165. [Google Scholar] [CrossRef]
- Kilpi, F.; Webber, L.; Musaigner, A.; Aitsi-Selmi, A.; Marsh, T.; Rtveladze, K.; Brown, M. Alarming predictions for obesity and non-communicable diseases in the Middle East. Public Health Nutr. 2014, 17, 1078–1086. [Google Scholar] [CrossRef] [Green Version]
- Kinra, S.; Bowen, L.J.; Lyngdoh, T.; Prabhakaran, D.; Reddy, K.S.; Ramakrishnan, L.; Smith, G.D. Sociodemographic patterning of non-communicable disease risk factors in rural India: A cross sectional study. BMJ 2010, 341, c4974. [Google Scholar] [CrossRef] [Green Version]
- Dan, H.; Kim, J.; Kim, O. Effects of gender and age on dietary intake and body mass index in hypertensive patients: Analysis of the korea national health and nutrition examination. Int. J. Environ. Res. Public Health 2020, 17, 4482. [Google Scholar] [CrossRef]
- Maimela, E.; Alberts, M.; Modjadji, S.E.; Choma, S.S.; Dikotope, S.A.; Ntuli, T.S.; Van Geertruyden, J.P. The prevalence and determinants of chronic non-communicable disease risk factors amongst adults in the Dikgale health demographic and surveillance system (HDSS) site, Limpopo Province of South Africa. PLoS ONE 2016, 11, e0147926. [Google Scholar] [CrossRef] [Green Version]










| Parameters | Symbol | Search Space |
|---|---|---|
| Maximum tree depth | 2, 4, 6, 8 | |
| Minimum child weight | 2, 3, 4, 5 | |
| Early stop round | e | 100 |
| Learning rate | 0.1 | |
| Number of boost | N | 60 |
| Maximum delta step | 0.4, 0.6, 0.8, 1 | |
| Subsample ratio | 0.9, 0.95, 1 | |
| Column subsample ratio | 0.9, 0.95, 1 | |
| Gamma | 0, 0.001 |
| Feature Selection | Classifier | Accuracy | Sensitivity | Specificity | Precision | F-Score |
|---|---|---|---|---|---|---|
| SVM-RFE | LR | 0.7948 | 0.7818 | 0.7532 | 0.7676 | 0.7746 |
| RF | 0.7890 | 0.7989 | 0.7984 | 0.8115 | 0.8052 | |
| KNN | 0.7342 | 0.6958 | 0.7381 | 0.7961 | 0.7426 | |
| MLP | 0.8070 | 0.7936 | 0.7791 | 0.8016 | 0.7976 | |
| NN | 0.8197 | 0.8274 | 0.8203 | 0.8387 | 0.8330 | |
| XGBoost | 0.8098 | 0.8108 | 0.8310 | 0.8533 | 0.8315 | |
| RFFS | LR | 0.7804 | 0.7371 | 0.7422 | 0.8024 | 0.7684 |
| RF | 0.8264 | 0.7699 | 0.7338 | 0.8236 | 0.7958 | |
| KNN | 0.8048 | 0.7128 | 0.7661 | 0.7753 | 0.7427 | |
| MLP | 0.7994 | 0.7808 | 0.7396 | 0.8115 | 0.7959 | |
| NN | 0.8507 | 0.8871 | 0.8902 | 0.8522 | 0.8693 | |
| XGBoost | 0.8311 | 0.8782 | 0.7984 | 0.8626 | 0.8703 | |
| HFS | LR | 0.7834 | 0.7989 | 0.7813 | 0.7959 | 0.7974 |
| RF | 0.8362 | 0.7805 | 0.8496 | 0.8115 | 0.7957 | |
| KNN | 0.8032 | 0.8018 | 0.7123 | 0.7872 | 0.7944 | |
| MLP | 0.8421 | 0.8305 | 0.7513 | 0.8257 | 0.8281 | |
| NN | 0.8758 | 0.8518 | 0.8158 | 0.8691 | 0.8604 | |
| XGBoost | 0.8812 | 0.8677 | 0.8126 | 0.8737 | 0.8707 |
| Feature Selection | Classifier | Accuracy | Sensitivity | Specificity | Precision | F-Score |
|---|---|---|---|---|---|---|
| SVM-RFE | LR | 0.7349 | 0.6969 | 0.8874 | 0.7086 | 0.7027 |
| RF | 0.8522 | 0.7904 | 0.8805 | 0.8157 | 0.8029 | |
| KNN | 0.8118 | 0.7432 | 0.8608 | 0.8105 | 0.7754 | |
| MLP | 0.8002 | 0.7171 | 0.8759 | 0.6816 | 0.6989 | |
| NN | 0.8339 | 0.7659 | 0.8397 | 0.7609 | 0.7634 | |
| XGBoost | 0.8248 | 0.7707 | 0.8512 | 0.8066 | 0.7882 | |
| RFFS | LR | 0.8356 | 0.7169 | 0.8685 | 0.6938 | 0.7052 |
| RF | 0.8741 | 0.7863 | 0.9065 | 0.7356 | 0.7601 | |
| KNN | 0.8444 | 0.7716 | 0.8635 | 0.7594 | 0.7655 | |
| MLP | 0.8221 | 0.7043 | 0.8949 | 0.6842 | 0.6941 | |
| NN | 0.8639 | 0.7651 | 0.9003 | 0.7534 | 0.7592 | |
| XGBoost | 0.9029 | 0.8507 | 0.9379 | 0.8264 | 0.8384 | |
| HFS | LR | 0.7903 | 0.7781 | 0.8990 | 0.7732 | 0.7756 |
| RF | 0.8961 | 0.8157 | 0.9136 | 0.7857 | 0.8004 | |
| KNN | 0.8363 | 0.7928 | 0.8990 | 0.7981 | 0.7954 | |
| MLP | 0.7918 | 0.7586 | 0.9083 | 0.7635 | 0.7610 | |
| NN | 0.8553 | 0.8173 | 0.8808 | 0.7934 | 0.8052 | |
| XGBoost | 0.9309 | 0.8944 | 0.9522 | 0.8874 | 0.8909 |
| Feature Selection | Classifier | KNHANES Dataset | NHANES Dataset | ||||
|---|---|---|---|---|---|---|---|
| AUC | CI 95% | p-Value | AUC | CI 95% | p-Value | ||
| SVM-RFE | LR | 0.7675 | 0.7474–0.7896 | <0.001 | 0.7922 | 0.7731–0.8088 | <0.001 |
| RF | 0.7987 | 0.7869–0.8118 | <0.001 | 0.8355 | 0.8254–0.8668 | <0.001 | |
| KNN | 0.7170 | 0.7094–0.7390 | <0.001 | 0.8020 | 0.7818–0.8210 | <0.001 | |
| MLP | 0.7864 | 0.7703–0.8001 | <0.001 | 0.7965 | 0.7851–0.8180 | <0.001 | |
| NN | 0.8239 | 0.8017–0.8405 | <0.001 | 0.8028 | 0.7981–0.8447 | <0.001 | |
| XGBoost | 0.8209 | 0.8097–0.8327 | <0.001 | 0.8110 | 0.8041–0.8315 | <0.001 | |
| RFFS | LR | 0.7397 | 0.7713–0.7971 | <0.001 | 0.7927 | 0.7806–0.8197 | <0.001 |
| RF | 0.7519 | 0.7683–0.8111 | <0.001 | 0.8464 | 0.8359–0.8637 | <0.001 | |
| KNN | 0.7395 | 0.7570–0.8037 | <0.001 | 0.8176 | 0.8070–0.8308 | <0.001 | |
| MLP | 0.7602 | 0.7721–0.8267 | <0.001 | 0.7996 | 0.7872–0.8135 | <0.001 | |
| NN | 0.8887 | 0.8659–0.9005 | <0.001 | 0.8327 | 0.8206–0.8492 | <0.001 | |
| XGBoost | 0.8383 | 0.8245–0.8567 | <0.001 | 0.8943 | 0.8757–0.9013 | <0.001 | |
| HFS | LR | 0.7901 | 0.7812–0.8253 | <0.001 | 0.8386 | 0.8234–0.8539 | <0.001 |
| RF | 0.8151 | 0.7947–0.8286 | <0.001 | 0.8647 | 0.8564–0.8859 | <0.001 | |
| KNN | 0.7571 | 0.7401–0.7796 | <0.001 | 0.8459 | 0.8284–0.8653 | <0.001 | |
| MLP | 0.7909 | 0.7846–0.8243 | <0.001 | 0.8335 | 0.8195–0.8506 | <0.001 | |
| NN | 0.8338 | 0.8249–0.8494 | <0.001 | 0.8491 | 0.8310–0.8588 | <0.001 | |
| XGBoost | 0.8402 | 0.8384–0.8635 | <0.001 | 0.9233 | 0.9073–0.9345 | <0.001 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davagdorj, K.; Pham, V.H.; Theera-Umpon, N.; Ryu, K.H. XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction. Int. J. Environ. Res. Public Health 2020, 17, 6513. https://doi.org/10.3390/ijerph17186513
Davagdorj K, Pham VH, Theera-Umpon N, Ryu KH. XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction. International Journal of Environmental Research and Public Health. 2020; 17(18):6513. https://doi.org/10.3390/ijerph17186513
Chicago/Turabian StyleDavagdorj, Khishigsuren, Van Huy Pham, Nipon Theera-Umpon, and Keun Ho Ryu. 2020. "XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction" International Journal of Environmental Research and Public Health 17, no. 18: 6513. https://doi.org/10.3390/ijerph17186513
APA StyleDavagdorj, K., Pham, V. H., Theera-Umpon, N., & Ryu, K. H. (2020). XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction. International Journal of Environmental Research and Public Health, 17(18), 6513. https://doi.org/10.3390/ijerph17186513